(翻译 gafferongames) Networked Physics in Virtual Reality VR中的网络物理
https://gafferongames.com/post/networked_physics_in_virtual_reality/
Introduction
About a year ago, Oculus approached me and offered to sponsor my research. They asked me, effectively: “Hey Glenn, there’s a lot of interest in networked physics in VR. You did a cool talk at GDC. Do you think could come up with a networked physics sample in VR that we could share with devs? Maybe you could use the touch controllers?”
I replied “F*** yes!" cough “Sure. This could be a lot of fun!”. But to keep it real, I insisted on two conditions. One: the source code I developed would be published under a permissive open source licence (for example, BSD) so it would create the most good. Two: when I was finished, I would be able to write an article describing the steps I took to develop the sample.
Oculus agreed. Welcome to that article! Also, the source for the networked physics sample is here, wherein the code that I wrote is released under a BSD licence. I hope the next generation of programmers can learn from my research into networked physics and create some really cool things. Good luck!
引言
大约一年前,Oculus 找到我,提出要赞助我的研究。他们基本上是这么说的:
“嘿,Glenn,现在大家对 VR 中的网络物理很感兴趣。你在 GDC 上的演讲很酷。你觉得能不能做一个 VR 的网络物理示例,我们可以分享给开发者?也许你可以用 Touch 控制器?”
我回答说:“我***当然愿意!” 咳咳 “当然,这一定会很有趣!”
但为了确保事情靠谱,我坚持了两个条件:
-
我开发的源代码必须以一个宽松的开源许可证(比如 BSD)发布,这样才能带来最大的益处。
-
完成之后,我必须能写一篇文章,讲述我开发这个示例所经历的过程。
Oculus 同意了。于是,欢迎阅读这篇文章!
另外,网络物理示例的源码就在这里,我写的代码已基于 BSD 许可证开源。希望下一代程序员能从我关于网络物理的研究中学到一些东西,并做出真正酷炫的作品。祝你好运!
What are we building?
When I first started discussions with Oculus, we imagined creating something like a table where four players could sit around and interact with physically simulated cubes on the table. For example, throwing, catching and stacking cubes, maybe knocking each other’s stacks over with a swipe of their hand.
But after a few days spent learning Unity and C#, I found myself actually inside the Rift. In VR, scale is so important. When the cubes were small, everything felt much less interesting, but when the cubes were scaled up to around a meter cubed, everything had this really cool sense of scale. You could make these huge stacks of cubes, up to 20 or 30 meters high. This felt really cool!
It’s impossible to communicate visually what this feels like outside of VR, but it looks something like this…
当我与 Oculus 开始讨论时,我们想象的是创建一个类似桌子的环境,四个玩家可以围坐在桌旁,互动并与桌上的物理模拟立方体互动。比如说,投掷、接住和堆叠立方体,甚至可能通过挥手击倒对方的堆叠。
但在花了几天时间学习 Unity 和 C# 后,我竟然发现自己已经身处 Rift 中。在 VR 中,比例非常重要。当立方体很小时,一切感觉都没那么有趣,但当立方体的尺寸放大到大约一米立方时,整个场景就有了一种非常酷的尺度感。你可以堆出这些巨大的立方体堆积物,堆得高达 20 或 30 米。那种感觉真的很酷!
在 VR 外,很难传达这种感觉的视觉效果,但它看起来大概是这样的……

… where you can select, grab and throw cubes using the touch controller, and any cubes you release from your hand interact with the other cubes in the simulation. You can throw a cube at a stack of cubes and knock them over. You can pick up a cube in each hand and juggle them. You can build a stack of cubes and see how high you can make it go.
Even though this was a lot of fun, it’s not all rainbows and unicorns. Working with Oculus as a client, I had to define tasks and deliverables before I could actually start the work.
I suggested the following criteria we would use to define success:
-
Players should be able to pick up, throw and catch cubes without latency.
-
Players should be able to stack cubes, and these stacks should be stable (come to rest) and be without visible jitter.
-
When cubes thrown by any player interact with the simulation, wherever possible, these interactions should be without latency.
At the same time I created a set of tasks to work in order of greatest risk to least, since this was R&D, there was no guarantee we would actually succeed at what we were trying to do.
……你可以使用 Touch 控制器选择、抓取和投掷立方体,任何从你手中释放的立方体都会与模拟中的其他立方体互动。你可以将一个立方体投向一堆立方体,击倒它们。你可以一只手拿一个立方体,玩起抛接的把戏。你可以堆叠立方体,看看能堆多高。
尽管这非常有趣,但并不是一帆风顺的。在与 Oculus 合作作为客户时,我必须在开始工作之前定义任务和交付物。
我提出了以下的成功标准:
-
玩家应该能够在没有延迟的情况下拾取、投掷和接住立方体。
-
玩家应该能够堆叠立方体,而这些堆叠应当稳定(最终停稳),并且没有明显的抖动。
-
当任何玩家投掷的立方体与模拟互动时,尽可能地,这些互动应该没有延迟。
同时,我创建了一套任务列表,按照从最大风险到最小风险的顺序排列,因为这是一个研发项目,不能保证我们会成功实现我们所尝试的目标。
Network Models
First up, we had to pick a network model. A network model is basically a strategy, exactly how we are going to hide latency and keep the simulation in sync.
There are three main network models to choose from:
- Deterministic lockstep
- Client/server with client-side prediction
- Distributed simulation with authority scheme
I was instantly confident of the correct network model: a distributed simulation model where players take over authority of cubes they interact with. But let me share with you my reasoning behind this.
First, I could trivially rule out a deterministic lockstep network model, since the physics engine inside Unity (PhysX) is not deterministic. Furthermore, even if PhysX was deterministic I could still rule it out because of the requirement that player interactions with the simulation be without latency.
The reason for this is that to hide latency with deterministic lockstep I needed to maintain two copies of the simulation and predict the authoritative simulation ahead with local inputs prior to render (GGPO style). At 90HZ simulation rate and with up to 250ms of latency to hide, this meant 25 physics simulation steps for each visual render frame. 25X cost is simply not realistic for a CPU intensive physics simulation.
This leaves two options: a client/server network model with client-side prediction (perhaps with dedicated server) and a less secure distributed simulation network model.
Since this was a non-competitive sample, there was little justification to incur the cost of running dedicated servers. Therefore, whether I implemented a client/server model with client-side prediction or distributed simulation model, the security would be effectively the same. The only difference would be if only one of the players in the game could theoretically cheat, or all of them could.
For this reason, a distributed simulation model made the most sense. It had effectively the same amount of security, and would not require any expensive rollback and resimulation, since players simply take authority over cubes they interact with and send the state for those cubes to other players.
权威方案
虽然直觉上来说,获取你互动的物体的控制权(像服务器一样操作)能够隐藏延迟——毕竟,如果你是服务器,就不经历延迟,对吧?——但不那么明显的是如何解决冲突问题。
如果两个玩家同时与同一堆立方体互动会怎样?如果两个玩家因为延迟而同时抓住同一个立方体呢?在冲突的情况下:谁胜出,谁需要被修正,如何决定这一切?
在这一点上,我的直觉是,由于我会快速地交换物体的状态(每秒最多 60 次),因此最好将这作为在玩家之间通过我的网络协议交换的状态编码,而不是作为事件。
我思考了一段时间,得出了两个关键概念:
-
权威
-
所有权
每个立方体都会有权威,默认为默认值(白色),或者是最后与其互动的玩家的颜色。如果另一个玩家与该物体互动,权威将转移并更新为该玩家的颜色。我计划使用权威来处理抛掷物体与场景的互动。我设想,玩家 2 抛出的立方体可以对它互动的任何物体获取权威,进而递归地对这些物体互动的物体也获取权威。
所有权则稍有不同。一旦某个立方体被玩家拥有,其他玩家不能再获得该立方体的所有权,直到拥有的玩家放弃所有权。我计划使用所有权来处理玩家抓取立方体的情况,因为我不希望玩家在其他玩家抓取了立方体后能够将其从对方手中抢走。
我有一个直觉,认为我可以通过包含每个立方体两个不同的序列号来表示和传递权威和所有权:一个是权威序列号,另一个是所有权序列号。这一直觉最终被证明是正确的,但在实现上比我预期的要复杂得多。稍后会详细说明。
State Synchronization
Trusting I could implement the authority rules described above, my first task was to prove that synchronizing physics in one direction of flow could actually work with Unity and PhysX. In previous work I had networked simulations built with ODE, so really, I had no idea if it was really possible.
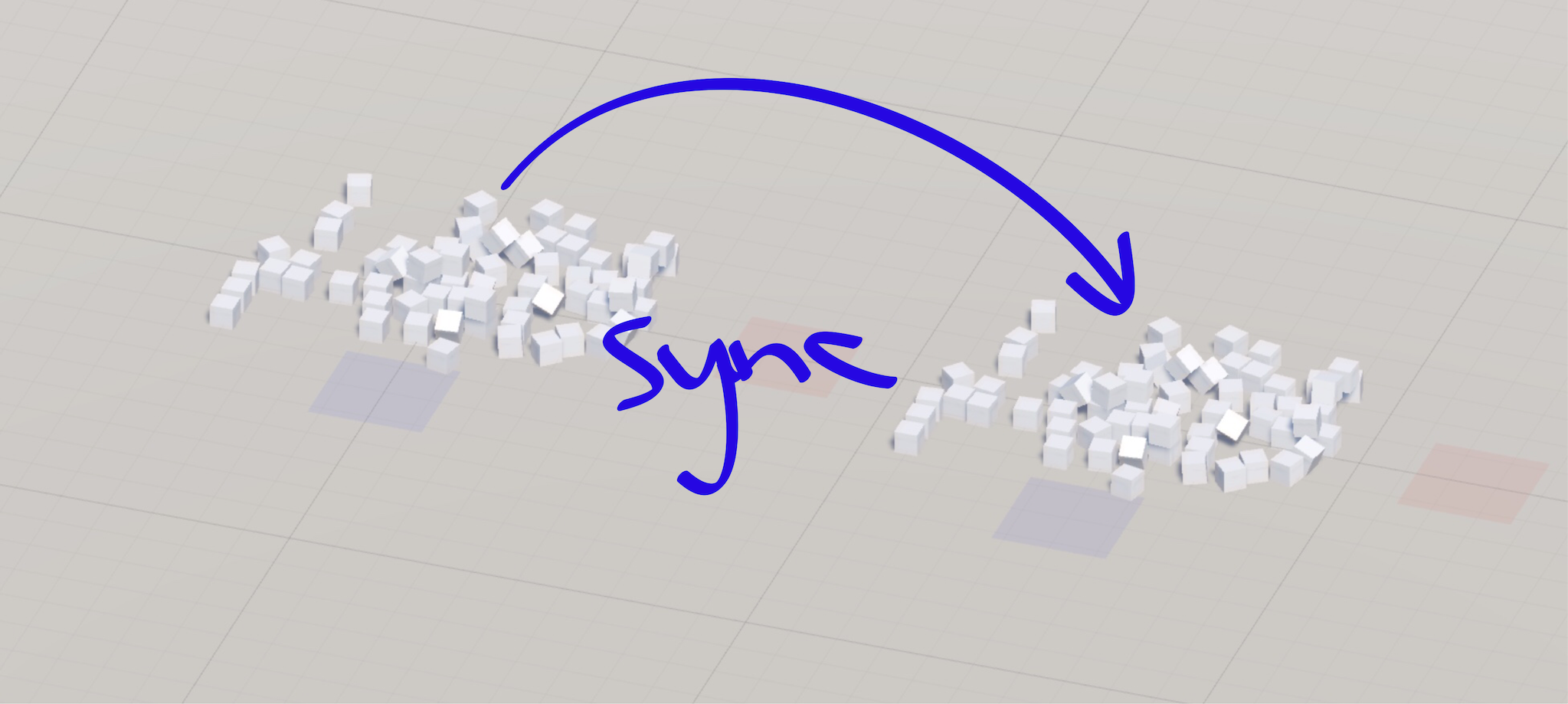
To find out, I setup a loopback scene in Unity where cubes fall into a pile in front of the player. There are two sets of cubes. The cubes on the left represent the authority side. The cubes on the right represent the non-authority side, which we want to be in sync with the cubes on the left.
状态同步
相信我能实现上述描述的权威规则,我的第一个任务是证明在 Unity 和 PhysX 中,单向流的物理同步实际上是可行的。在之前的工作中,我曾使用 ODE 构建过网络化模拟,因此说实话,我并不确定这是否真的可行。
为了验证这一点,我在 Unity 中设置了一个回环场景,模拟立方体掉落并堆积在玩家面前。场景中有两组立方体。左边的立方体代表权威端,而右边的立方体代表非权威端,目标是让右边的立方体与左边的立方体保持同步。

At the start, without anything in place to keep the cubes in sync, even though both sets of cubes start from the same initial state, they give slightly different end results. You can see this most easily from top-down:
一开始,在没有任何同步机制的情况下,尽管两组立方体从相同的初始状态开始,它们的最终结果却略有不同。最容易从俯视角度看到这一点:

This happens because PhysX is non-deterministic. Rather than tilting at non-determinstic windmills, I fight non-determinism by grabbing state from the left side (authority) and applying it to the right side (non-authority) 10 times per-second:
这种情况发生是因为 PhysX 是非确定性的。与其与非确定性的“风车”作斗争,我选择通过每秒 10 次从左侧(权威端)抓取状态,并将其应用到右侧(非权威端),来应对这种非确定性:
The state I grab from each cube looks like this:
struct CubeState { Vector3 position; Quaternion rotation; Vector3 linear_velocity; Vector3 angular_velocity; };
And when I apply this state to the simulation on the right side, I simply snap the position, rotation, linear and angular velocity of each cube to the state captured from the left side.
This simple change is enough to keep the left and right simulations in sync. PhysX doesn’t even diverge enough in the 1/10th of a second between updates to show any noticeable pops.
当我将这个状态应用到右侧的模拟时,我简单地将每个立方体的位置、旋转、线性速度和角速度强制同步到从左侧捕获的状态。
这个简单的修改足以保持左右两侧模拟的同步。PhysX 在每次更新之间的 1/10 秒内的偏差并不足以导致明显的跳动或不一致。
This proves that a state synchronization based approach for networking can work with PhysX. (Sigh of relief). The only problem of course, is that sending uncompressed physics state uses way too much bandwidth…
这证明了基于状态同步的网络方法可以与 PhysX 一起工作。(松了口气)当然,唯一的问题是,发送未压缩的物理状态会消耗太多带宽……
Bandwidth Optimization
To make sure the networked physics sample is playable over the internet, I needed to get bandwidth under control.
The easiest gain I found was to simply encode the state for at rest cubes more efficiently. For example, instead of repeatedly sending (0,0,0) for linear velocity and (0,0,0) for angular velocity for at rest cubes, I send just one bit:
带宽优化
为了确保网络化物理示例能够在互联网上流畅运行,我需要控制带宽。
我发现的最简单的优化方法是更加高效地编码处于静止状态的立方体的状态。例如,之前我一直在重复发送(0,0,0)的线性速度和(0,0,0)的角速度来表示静止的立方体,而现在,我只需发送一个位:
[position] (vector3) [rotation] (quaternion) [at rest] (bool) <if not at rest> { [linear_velocity] (vector3) [angular_velocity] (vector3) }
This is lossless technique because it doesn’t change the state sent over the network in any way. It’s also extremely effective, since statistically speaking, most of the time the majority of cubes are at rest.
To optimize bandwidth further we need to use lossy techniques. For example, we can reduce the precision of the physics state sent over the network by bounding position in some min/max range and quantizing it to a resolution of 1/1000th of a centimeter and sending that quantized position as an integer value in some known range. The same basic approach can be used for linear and angular velocity. For rotation I used the smallest three representation of a quaternion.
But while this saves bandwidth, it also adds risk. My concern was that if we are networking a stack of cubes (for example, 10 or 20 cubes placed on top of each other), maybe the quantization would create errors that add jitter to that stack. Perhaps it would even cause the stack to become unstable, but in a particularly annoying and hard to debug way, where the stack looks fine for you, and is only unstable in the remote view (eg. the non-authority simulation), where another player is watching what you do.
The best solution to this problem that I found was to quantize the state on both sides. This means that before each physics simulation step, I capture and quantize the physics state exactly the same way as when it’s sent over the network, then I apply this quantized state back to the local simulation.
Now the extrapolation from quantized state on the non-authority side exactly matches the authority simulation, minimizing jitter in large stacks. At least, in theory.
这是一种无损的技术,因为它不会以任何方式改变通过网络发送的状态。它非常有效,因为统计学上讲,大多数时候大多数立方体都是静止的。
为了进一步优化带宽,我们需要使用有损技术。例如,我们可以通过将位置限制在某个最小/最大范围内,并将其量化为 1/1000 毫米的分辨率,再将量化后的位置信息作为一个已知范围内的整数值发送,从而减少通过网络发送的物理状态的精度。同样的方法也可以用于线性和角速度。对于旋转,我使用了四元数的三个最小表示。
但是,虽然这种方法节省了带宽,它也带来了风险。我的担忧是,如果我们正在网络化一堆立方体(例如,10 或 20 个立方体堆叠在一起),那么量化可能会产生误差,从而导致该堆叠出现抖动。或许它甚至会导致堆叠不稳定,但以一种特别恼人且难以调试的方式表现出来——堆叠对你来说看起来没问题,但在远端视图(例如,非权威模拟中)中,它是完全不稳定的,其他玩家看到的与你的体验完全不同。
我找到的解决这个问题的最佳方法是,在两端都进行量化状态。这意味着,在每个物理模拟步骤之前,我以与通过网络发送时完全相同的方式捕获并量化物理状态,然后将这个量化的状态应用到本地模拟中。
现在,来自非权威端的量化状态的外推完全与权威模拟匹配,从而最大程度地减少了大堆叠中的抖动。至少,从理论上讲是这样。
Coming To America Rest
But quantizing the physics state created some very interesting side-effects!
-
PhysX doesn’t really like you forcing the state of each rigid body at the start of every frame and makes sure you know by taking up a bunch of CPU.
-
Quantization adds error to position which PhysX tries very hard to correct, snapping cubes immediately out of penetration with huge pops!
-
Rotations can’t be represented exactly either, again causing penetration. Interestingly in this case, cubes can get stuck in a feedback loop where they slide across the floor!
-
Although cubes in large stacks seem to be at rest, close inspection in the editor reveals that they are actually jittering by tiny amounts, as cubes are quantized just above surface and falling towards it.
There’s not much I could do about the PhysX CPU usage, but the solution I found for the depenetration was to set maxDepenetrationVelocity on each rigid body, limiting the velocity that cubes are pushed apart with. I found that one meter per-second works very well.
Getting cubes to come to rest reliably was much harder. The solution I found was to disable the PhysX at rest calculation entirely and replace it with a ring-buffer of positions and rotations per-cube. If a cube has not moved or rotated significantly in the last 16 frames, I force it to rest. Boom. Perfectly stable stacks with quantization.
Now this might seem like a hack, but short of actually getting in the PhysX source code and rewriting the PhysX solver and at rest calculations, which I’m certainly not qualified to do, I didn’t see any other option. I’m happy to be proven wrong though, so if you find a better way to do this, please let me know :)
优先级累加器
接下来,我进行的另一个重要带宽优化是每个数据包中仅发送一部分立方体。这使得我能够精确控制发送的带宽量,通过设置最大数据包大小,并且仅发送每个数据包中可以容纳的更新集。
以下是实际操作方式:
每个立方体都有一个优先级因子,在每帧计算。更高的值表示该立方体更有可能被发送。负值表示“不发送该立方体”。
如果优先级因子为正,则将其添加到该立方体的优先级累加器值中。这个值在模拟更新之间持续存在,因此优先级累加器在每帧递增,使得优先级较高的立方体比低优先级的立方体更快提升。
负的优先级因子会将优先级累加器清零,设置为 -1.0。
当数据包被发送时,立方体按照优先级累加器从高到低进行排序。前n个立方体成为可能包含在数据包中的立方体集合。优先级累加器值为负的对象会被排除。
数据包被写入,立方体按重要性顺序被序列化到数据包中。并不是所有的状态更新都会适配到数据包中,因为立方体的更新编码是可变的,具体取决于它们的当前状态(例如,静止状态与非静止状态等)。因此,数据包序列化时,会为每个立方体返回一个标志,指示它是否被包含在数据包中。
数据包中发送的立方体的优先级累加器值会被清零为 0.0,这样其他立方体就能公平地有机会被包括到下一个数据包中。
对于这个示例,我发现最近涉及高能碰撞的立方体可以提升优先级,因为高能碰撞是非确定性结果导致偏差的最大来源。我还提升了最近被玩家投掷的立方体的优先级。
有点违反直觉的是,减少静止立方体的优先级会导致不良结果。我的理论是,由于模拟在两侧都在运行,静止的立方体会稍微不同步,而且不会被快速纠正,导致当其他立方体与它们发生碰撞时出现偏差。
Delta Compression
Even with all the techniques so far, it still wasn’t optimized enough. With four players I really wanted to get the cost per-player down under 256kbps, so the entire simulation could fit into 1mbps for the host.
I had one last trick remaining: delta compression.
First person shooters often implement delta compression by compressing the entire state of the world relative to a previous state. In this technique, a previous complete world state or ‘snapshot’ acts as the baseline, and a set of differences, or delta, between the baseline and the current snapshot is generated and sent down to the client.
This technique is (relatively) easy to implement because the state for all objects are included in each snapshot, thus all the server needs to do is track the most recent snapshot received by each client, and generate deltas from that snapshot to the current.
However, when a priority accumulator is used, packets don’t contain updates for all objects and delta encoding becomes more complicated. Now the server (or authority-side) can’t simply encode cubes relative to a previous snapshot number. Instead, the baseline must be specified per-cube, so the receiver knows which state each cube is encoded relative to.
The supporting systems and data structures are also much more complicated:
-
A reliability system is required that can report back to the sender which packets were received, not just the most recently received snapshot #.
-
The sender needs to track the states included in each packet sent, so it can map packet level acks to sent states and update the most recently acked state per-cube. The next time a cube is sent, its delta is encoded relative to this state as a baseline.
-
The receiver needs to store a ring-buffer of received states per-cube, so it can reconstruct the current cube state from a delta by looking up the baseline in this ring-buffer.
But ultimately, it’s worth the extra complexity, because this system combines the flexibility of being able to dynamically adjust bandwidth usage, with the orders of magnitude bandwidth improvement you get from delta encoding.
增量压缩 (Delta Compression)
尽管迄今为止采用了所有这些技术,但仍然没有达到足够的优化。对于四个玩家,我希望将每个玩家的成本压缩到低于 256kbps,这样整个模拟就可以在 1mbps 内传输给主机。
我最后使用的技巧是:增量压缩。
增量压缩是一种常用于第一人称射击游戏的技术,通过相对于先前的状态压缩整个世界的状态。在这种技术中,一个之前的完整世界状态或“快照”作为基准,并生成一个差异集(或增量),这个差异集表示基准和当前快照之间的不同,然后将这些差异发送到客户端。
这种技术(相对来说)比较容易实现,因为每个快照中都包含了所有对象的状态,因此服务器只需要跟踪每个客户端接收到的最新快照,并从该快照生成增量。
然而,当使用优先级累加器时,数据包中并不包含所有对象的更新,这使得增量编码变得更加复杂。现在,服务器(或权威方)不能简单地相对于一个之前的快照编号来编码立方体。相反,必须为每个立方体指定基准,这样接收方就知道每个立方体相对于哪个状态进行编码。
支持这些系统和数据结构也变得更加复杂:
-
需要一个可靠性系统,能够报告回发送方哪些数据包已经收到,而不仅仅是最近接收到的快照编号。
-
发送方需要跟踪每个发送的数据包中包含的状态,以便它能够将数据包级别的确认(acks)映射到已发送的状态,并更新每个立方体的最新确认状态。下一次发送该立方体时,它的增量将相对于这个基准状态进行编码。
-
接收方需要存储一个每个立方体的环形缓冲区,以便通过查找环形缓冲区中的基准状态来重建当前的立方体状态。
但最终,这一额外的复杂性是值得的,因为这个系统结合了能够动态调整带宽使用的灵活性,以及通过增量编码获得的带宽提升的几个数量级。
Delta Encoding
Now that I have the supporting structures in place, I actually have to encode the difference of a cube relative to a previous baseline state. How is this done?
The simplest way is to encode cubes that haven’t changed from the baseline value as just one bit: not changed. This is also the easiest gain you’ll ever see, because at any time most cubes are at rest, and therefore aren’t changing state.
A more advanced strategy is to encode the difference between the current and baseline values, aiming to encode small differences with fewer bits. For example, delta position could be (-1,+2,+5) from baseline. I found this works well for linear values, but breaks down for deltas of the smallest three quaternion representation, as the largest component of a quaternion is often different between the baseline and current rotation.
Furthermore, while encoding the difference gives some gains, it didn’t provide the order of magnitude improvement I was hoping for. In a desperate, last hope, I came up with a delta encoding strategy that included prediction. In this approach, I predict the current state from the baseline assuming the cube is moving ballistically under acceleration due to gravity.
Prediction was complicated by the fact that the predictor must be written in fixed point, because floating point calculations are not necessarily guaranteed to be deterministic. But after a few days of tweaking and experimentation, I was able to write a ballistic predictor for position, linear and angular velocity that matched the PhysX integrator within quantize resolution about 90% of the time.
These lucky cubes get encoded with another bit: perfect prediction, leading to another order of magnitude improvement. For cases where the prediction doesn’t match exactly, I encoded small error offset relative to the prediction.
In the time I had to spend, I not able to get a good predictor for rotation. I blame this on the smallest three representation, which is highly numerically unstable, especially in fixed point. In the future, I would not use the smallest three representation for quantized rotations.
It was also painfully obvious while encoding differences and error offsets that using a bitpacker was not the best way to read and write these quantities. I’m certain that something like a range coder or arithmetic compressor that can represent fractional bits, and dynamically adjust its model to the differences would give much better results, but I was already within my bandwidth budget at this point and couldn’t justify any further noodling :)
增量编码 (Delta Encoding)
现在,我已经为增量编码准备好了支持的结构,接下来,我需要实际编码一个立方体相对于之前基准状态的差异。这是如何实现的呢?
最简单的方法是,如果立方体的状态没有发生变化,就用一个比特表示:未变化。这是你能看到的最简单的增益,因为大多数时候,大多数立方体都是静止的,因此状态没有变化。
一个更高级的策略是编码当前状态和基准状态之间的差异,目标是用更少的比特表示较小的差异。例如,增量位置可以表示为相对于基准位置的差值(-1, +2, +5)。我发现这种方法对线性值有效,但对于最小的三元数表示来说却无法正常工作,因为四元数的最大分量通常在基准和当前旋转之间会有所不同。
此外,尽管编码差异提供了一些增益,但它并没有提供我期望的数量级改进。在一次绝望的尝试中,我提出了一种包括预测的增量编码策略。在这个方法中,我预测立方体的当前状态,假设它在重力作用下作弹道运动。
预测问题的复杂性在于预测器必须以定点数编写,因为浮动点计算并不一定保证确定性。但经过几天的调整和实验,我最终编写出了一个预测器,可以将位置、线性速度和角速度的预测与PhysX积分器的结果进行匹配,大约90%的时间能达到量化精度。
这些幸运的立方体会得到一个额外的比特标记:完美预测,带来了另一个数量级的改进。对于预测不完全匹配的情况,我会编码相对于预测的小误差偏移。
在我有限的时间里,我没有能为旋转写出一个良好的预测器。我将其归因于最小的三元数表示,它在定点运算中非常不稳定,尤其是在数值计算上。未来,我不会为量化旋转使用最小的三元数表示。
在编码差异和误差偏移的过程中,我也痛苦地意识到,使用比特打包器并不是读取和写入这些数量的最佳方式。我相信像范围编码器或算术压缩器这样的工具,可以表示分数比特,并且动态调整其模型来处理差异,应该能获得更好的结果,但此时我的带宽预算已经耗尽,无法再进一步研究这些技术了 :)
Synchronizing Avatars
After several months of work, I had made the following progress:
- Proof that state synchronization works with Unity and PhysX
- Stable stacks in the remote view while quantizing state on both sides
- Bandwidth reduced to the point where all four players can fit in 1mbps
The next thing I needed to implement was interaction with the simulation via the touch controllers. This part was a lot of fun, and was my favorite part of the project :)
I hope you enjoy these interactions. There was a lot of experimentation and tuning to make simple things like picking up, throwing, passing from hand to hand feel good, even crazy adjustments to ensure throwing worked great, while placing objects on top of high stacks could still be done with high accuracy.
But when it comes to networking, in this case the game code doesn’t count. All the networking cares about is that avatars are represented by a head and two hands driven by the tracked headset and touch controller positions and orientations.
To synchronize this I captured the position and orientation of the avatar components in FixedUpdate along the rest of the physics state, and applied this state to the avatar components in the remote view.
But when I first tried this it looked absolutely awful. Why?
After a bunch of debugging I worked out that the avatar state was sampled from the touch hardware at render framerate in Update, and was applied on the other machine at FixedUpdate, causing jitter because the avatar sample time didn’t line up with the current time in the remote view.
To fix this I stored the difference between physics and render time when sampling avatar state, and included this in the avatar state in each packet. Then I added a jitter buffer with 100ms delay to received packets, solving network jitter from time variance in packet delivery and enabling interpolation between avatar states to reconstruct a sample at the correct time.
To synchronize cubes held by avatars, while a cube is parented to an avatar’s hand, I set the cube’s priority factor to -1, stopping it from being sent with regular physics state updates. While a cube is attached to a hand, I include its id and relative position and rotation as part of the avatar state. In the remote view, cubes are attached to the avatar hand when the first avatar state arrives with that cube parented to it, and detached when regular physics state updates resume, corresponding to the cube being thrown or released.
同步虚拟角色
经过几个月的工作,我取得了以下进展:
-
证明了在Unity和PhysX中,状态同步是可行的。
-
在远程视图中,量化两侧状态时,堆叠物体稳定。
-
带宽已经优化到足够低,所有四个玩家可以在1mbps的带宽下运行。
接下来,我需要实现与模拟的交互,特别是通过触控控制器进行交互。这部分非常有趣,也是我最喜欢的部分 :)
希望你能享受这些交互。为了让像捡起、投掷、手与手之间传递物体等简单操作感觉良好,我做了大量的实验和调优,甚至对投掷进行疯狂的调整,以确保投掷效果很好,同时在将物体放到高堆叠物体上时,仍能保持高精度。
但在网络同步方面,游戏代码本身并不重要。网络同步只关心虚拟角色的表示——一个由头部和两只手组成的虚拟角色,由追踪的头戴设备和触控控制器的位置与朝向驱动。
为了同步这些信息,我在FixedUpdate中捕捉了虚拟角色的各个组件的位置和朝向,并将这些状态应用到远程视图中的虚拟角色组件上。
但在我第一次尝试时,这种同步效果非常糟糕。为什么呢?
经过一番调试,我发现问题出在虚拟角色的状态是从触控硬件在渲染帧率下采样的,而在另一台机器上,虚拟角色状态是在FixedUpdate中应用的,这导致了抖动,因为虚拟角色的采样时间与远程视图中的当前时间并不对齐。
为了解决这个问题,我存储了采样虚拟角色状态时,物理更新与渲染更新之间的时间差,并将这个差值包含在每个数据包的虚拟角色状态中。然后,我为接收的数据包添加了一个100ms的延迟抖动缓冲区,这解决了由于数据包传输时间差异引起的网络抖动,并通过插值法在虚拟角色状态之间进行平滑过渡,以在正确的时间重建一个样本。
为了同步虚拟角色手中的物体,当一个物体被绑定到虚拟角色的手上时,我将物体的优先级因子设置为-1,这样它就不会与常规物理状态更新一起发送。当一个物体被附加到虚拟角色的手上时,我将其ID和相对位置、旋转作为虚拟角色状态的一部分。如果在远程视图中,虚拟角色的状态到达时该物体已经绑定到它的手上,它就会被视为附加在虚拟角色的手上;当常规物理状态更新恢复时,该物体就会被解除绑定,表示该物体被投掷或释放。
Bidirectional Flow
Now that I had player interaction with the scene working with the touch controllers, it was time to start thinking about how the second player can interact with the scene as well.
To do this without going insane switching between two headsets all the time (!!!), I extended my Unity test scene to be able to switch between the context of player one (left) and player two (right).
I called the first player the “host” and the second player the “guest”. In this model, the host is the “real” simulation, and by default synchronizes all cubes to the guest player, but as the guest interacts with the world, it takes authority over these objects and sends state for them back to the host player.
To make this work without inducing obvious conflicts the host and guest both check the local state of cubes before taking authority and ownership. For example, the host won’t take ownership over a cube already under ownership of the guest, and vice versa, while authority is allowed to be taken, to let players throw cubes at somebody else’s stack and knock it over while it’s being built.
Generalizing further to four players, in the networked physics sample, all packets flow through the host player, making the host the arbiter. In effect, rather than being truly peer-to-peer, a topology is chosen that all guests in the game communicate only with the host player. This lets the host decide which updates to accept, and which updates to ignore and subsequently correct.
To apply these corrections I needed some way for the host to override guests and say, no, you don’t have authority/ownership over this cube, and you should accept this update. I also needed some way for the host to determine ordering for guest interactions with the world, so if one client experiences a burst of lag and delivers a bunch of packets late, these packets won’t take precedence over more recent actions from other guests.
As per my hunch earlier, this was achieved with two sequence numbers per-cube:
- Authority sequence
- Ownership sequence
These sequence numbers are sent along with each state update and included in avatar state when cubes are held by players. They are used by the host to determine if it should accept an update from guests, and by guests to determine if the state update from the server is more recent and should be accepted, even when that guest thinks it has authority or ownership over a cube.
Authority sequence increments each time a player takes authority over a cube and when a cube under authority of a player comes to rest. When a cube has authority on a guest machine, it holds authority on that machine until it receives confirmation from the host before returning to default authority. This ensures that the final at rest state for cubes under guest authority are committed back to the host, even under significant packet loss.
Ownership sequence increments each time a player grabs a cube. Ownership is stronger than authority, such that an increase in ownership sequence wins over an increase in authority sequence number. For example, if a player interacts with a cube just before another player grabs it, the player who grabbed it wins.
In my experience working on this demo I found these rules to be sufficient to resolve conflicts, while letting host and guest players interact with the world lag free. Conflicts requiring corrections are rare in practice even under significant latency, and when they do occur, the simulation quickly converges to a consistent state.
双向流
现在,当我通过触控控制器实现了玩家与场景的交互后,下一步就是考虑第二个玩家如何与场景进行交互。
为了避免频繁切换头戴设备而精神崩溃(!!!),我扩展了我的Unity测试场景,使其能够在玩家一(左侧)和玩家二(右侧)之间切换上下文。
我将第一个玩家称为“主机”,第二个玩家称为“客人”。在这种模型中,主机是真正的模拟器,默认情况下将所有物体的状态同步给客人玩家,但当客人与世界互动时,它会对这些物体获得权威,并将物体的状态发送回主机玩家。
为了避免显著的冲突,主机和客人都在获取权威和所有权之前检查物体的本地状态。例如,主机不会对一个已经被客人占有的物体获取所有权,反之亦然,而在权威的获取上是允许的,这样玩家就可以朝其他玩家的堆叠投掷物体并在它被建造时击倒它。
将这个模型进一步推广到四个玩家的情况下,在这个网络化物理样例中,所有数据包都通过主机玩家进行传输,主机因此成为仲裁者。实际上,这种方式并非真正的对等网络,而是选择了一种拓扑结构,在这种结构下,所有客人都只与主机玩家通信。这让主机决定接受哪些更新,忽略哪些更新,并随之进行纠正。
为了应用这些纠正措施,我需要一种方式让主机可以覆盖客人的更新,强制其不再拥有某个物体的权威或所有权,并接受主机的更新。我还需要一种方式,让主机确定客人交互的顺序,以便在某个客户端出现大幅延迟并送达一大批迟到的数据包时,这些数据包不会比其他客人的更近期的操作优先。
正如我早前的直觉一样,这通过为每个物体设置两个序列号来实现:
-
权威序列号
-
所有权序列号
这些序列号随每次状态更新一起发送,并在虚拟角色抓住物体时包含在虚拟角色状态中。主机使用这些序列号来判断是否接受来自客人的更新,客人则通过这些序列号判断主机的更新是否更为近期,并应接受主机的更新,即便这个客人认为它已经对物体拥有权威或所有权。
-
权威序列号:每次玩家获得某个物体的权威时,权威序列号都会增加。当一个物体的权威归玩家所有且物体停止运动时,权威序列号也会增加。当一个物体在客机上拥有权威时,它会一直保持权威状态,直到收到主机的确认后才会恢复到默认权威状态。这确保了,即使在重大数据包丢失的情况下,客人玩家对物体的最终静止状态也能同步到主机。
-
所有权序列号:每次玩家抓住某个物体时,所有权序列号都会增加。所有权比权威更强,所有权序列号的增加会覆盖权威序列号的增加。例如,如果一个玩家在另一个玩家抓住物体之前与物体发生交互,那么该玩家获得所有权,而不是另一个玩家。
根据我在这次演示中的经验,这些规则足以解决冲突,同时允许主机和客人玩家以零延迟的方式与世界互动。即使在存在较大延迟的情况下,发生冲突并需要纠正的情况也是非常罕见的,当确实发生时,模拟会迅速恢复到一致的状态。
Conclusion
High quality networked physics with stable stacks of cubes is possible with Unity and PhysX using a distributed simulation network model.
This approach is best used for cooperative experiences only, as it does not provide the security of a server-authoritative network model with dedicated servers and client-side prediction.
Thanks to Oculus for sponsoring my work and making this research possible!
The source code for the networked physics sample can be downloaded here.
Conclusion
高质量的网络化物理模拟,尤其是能够保持稳定堆叠的立方体,在Unity和PhysX中使用分布式模拟网络模型是完全可行的。
这种方法最适合用于合作型体验,因为它没有像服务器授权网络模型那样提供安全保障,后者依赖于专用服务器和客户端预测。
感谢Oculus的赞助,使得这项研究得以实现!
网络化物理示例的源代码可以通过此处下载。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号