CMU15-445 Lab3 Query Execution全记录
写在前面
一周前写完了15-445的lab3。
相比lab2,lab3的难度有所降低,但是工作量更大。主要难点在于理清各个类之间的交互方式。
可以说,这是一次面向对象编程的训练。
lab概述
这次lab需要我们实现:
1个catalog,以及下面9个executor:
SEQUENTIAL SCAN
INDEX SCANS
INSERT
UPDATE
DELETE
NESTED LOOP JOIN
INDEX NESTED LOOP JOIN
AGGREGATION
LIMIT
数据模型采用Iterator Model。
Catalog
catalog记录了整个数据库中的table和index信息。
有了catalog,我们就可以从table/index的名字或id,找到这个table/index的指针,以及各种metadata。
因此,catalog中就包含了一些unordered_map,还有一些储存metadata的结构体。
catalog的实现比较简单。一个值得注意的点是unordered_map的[]运算符与at()方法之间的区别:
当键不存在时,调用前者会创建一个键值对,其中值利用默认构造函数构造;调用后者会报std::out_of_range error。
因此在实现这个类时,需要使用at()方法。
Executors
在开始这些Executor之前,有必要对整个项目的结构进行一下梳理。
在做lab的过程中,往往会遇到这样的情况:需要做一件事情,但不知道该去调用哪个类的哪个方法。弄清楚该调用哪个方法之后,又不知道该传什么样的参数。
因此,理清各个类之间的交互方式,是完成本次lab的重点和前提。
整体逻辑
Execution Layer的整体逻辑如下图所示:
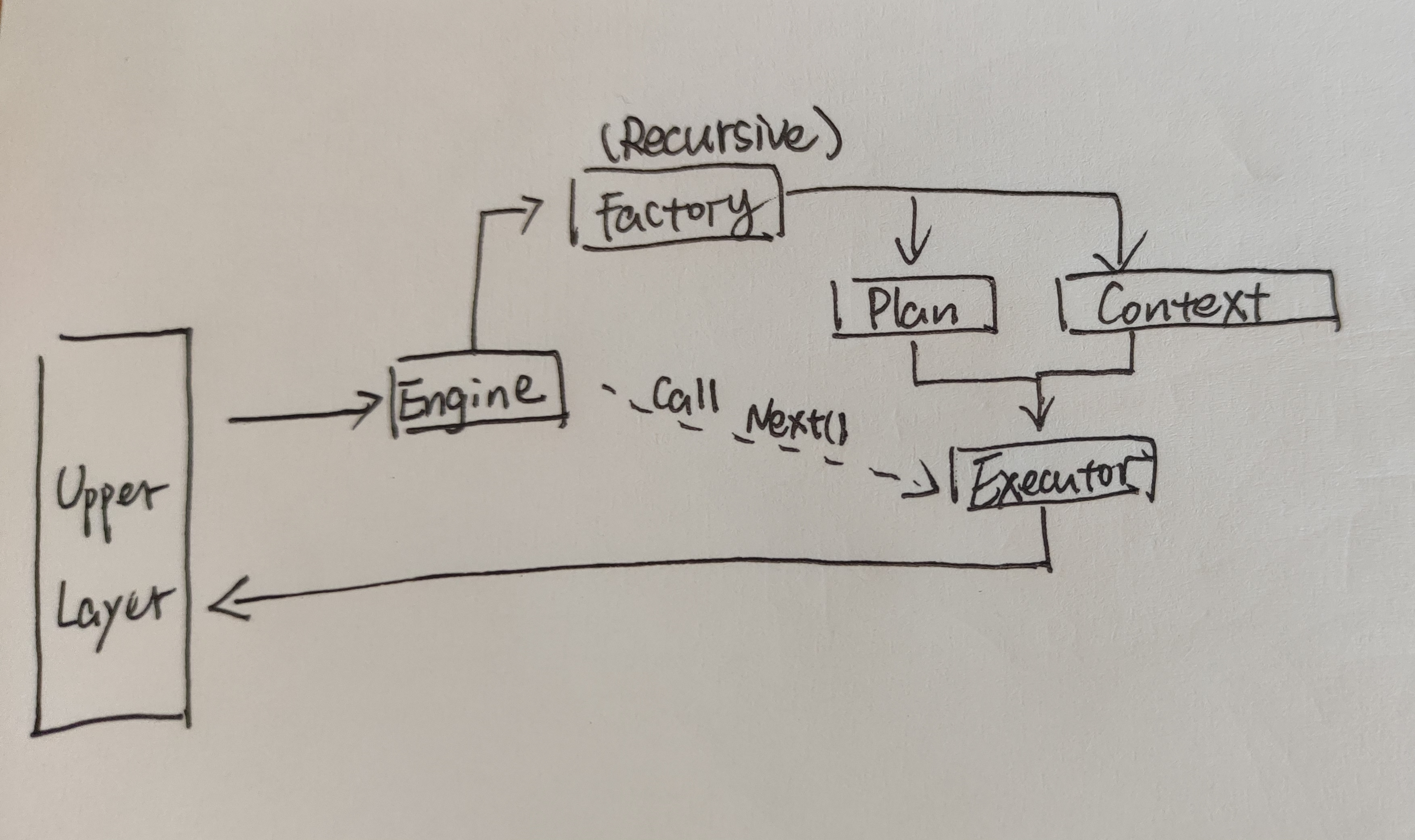
上层组件与Execution Engine交互。
在Execution Engine中,首先调用Execution Factory递归创建Executor。然后不断调用Executor的Next()方法,生成Tuple。
在创建Executor时,需要提供Execution Plan与Execution Context。前者可以看作是Executor Type Specific的创建参数(包含children、predicate、table_oid等),后者可以看作是Executor Type Irrelavent的创建参数(包含各种manager、catalog等)。
重要的类以及其交互关系
下图展示了各个重要的类之间的交互关系。包括:Index, TableHeap, TableHeapIterator, Schema, Column, Tuple, Value, RID, Expression。
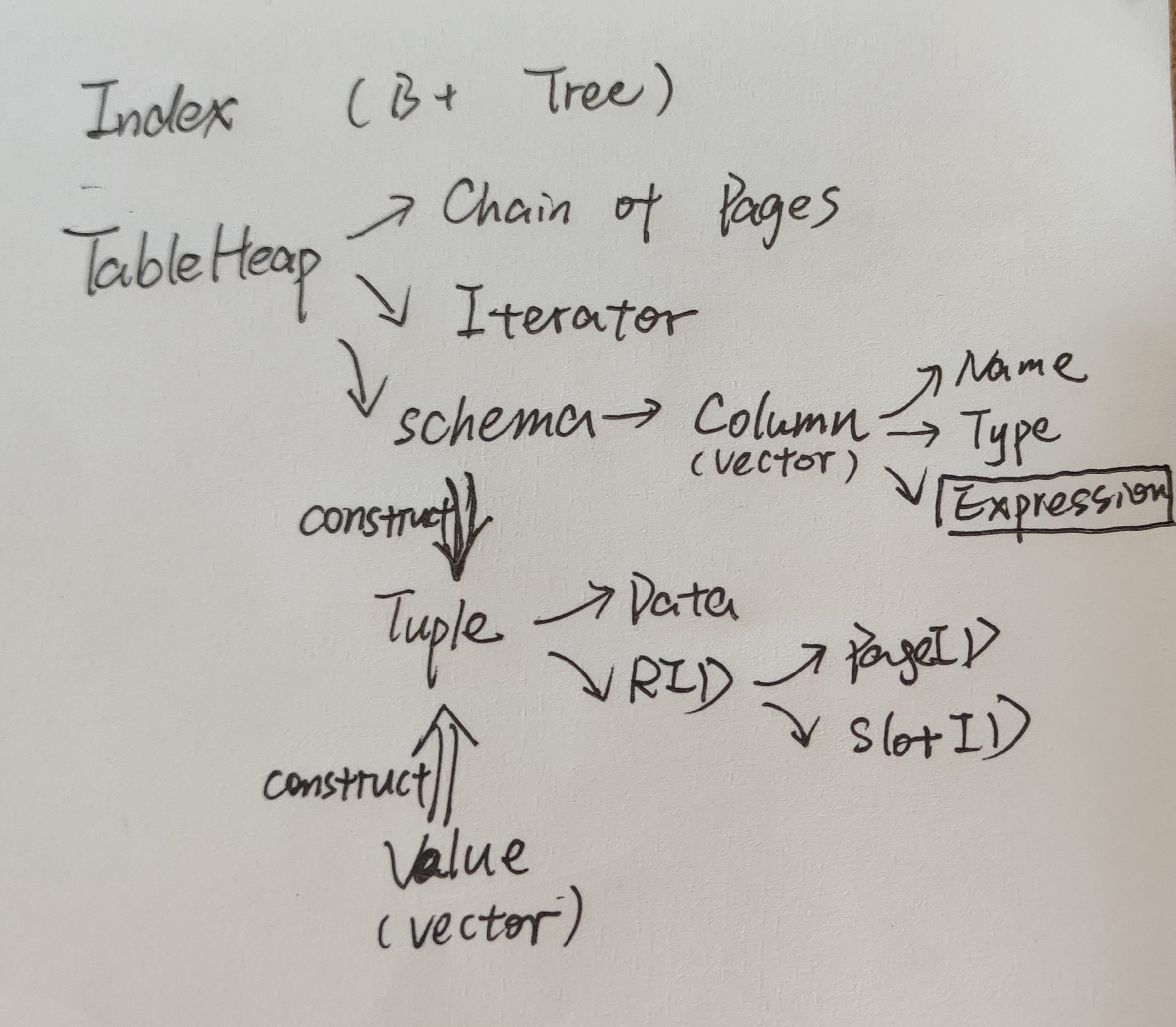
Index是对lab2中B+ Tree Index的套壳,不做赘述。
TableHeap本质上是由Page组成的链表。在每个page中,按slot存储tuple中的data。TableHeap类本身并不存储schema,schema存储在catalog中。
TableHeapIterator用于对TableHeap进行遍历。它本仅存储一个当前Tuple。在取*时返回该tuple;在递增(++)时,取出该tuple中的rid,在table中定位对应的slot。然后逐slot向下遍历,直至找到下一个valid rid。
Schema的本质是vector of columns。它描述了一个tuple内存储的数据。
Column包含该column的名字、类型,以及一个Expression(optional),描述该column如何构造。注意这个Expression的类型应为ColumnExpression,在执行projection时用到。
Tuple存储了一行数据。它包含Data和RID。注意,tuple中不存储schema;TableHeap中不直接在page中保存tuple,而是保存serialize后的tuple data。
Value表示一个值(Int、Char、Varchar等)。用一个Value vector和一个schema,可以构建一个tuple。
RID记录tuple的存储位置。包括page id+slot id。
Expression以树的形式递归地表示一个表达式。Expression共包含Const、Comparison、Column、Aggregation四种类型,分别用于不同的场合。下面加以详细阐述:
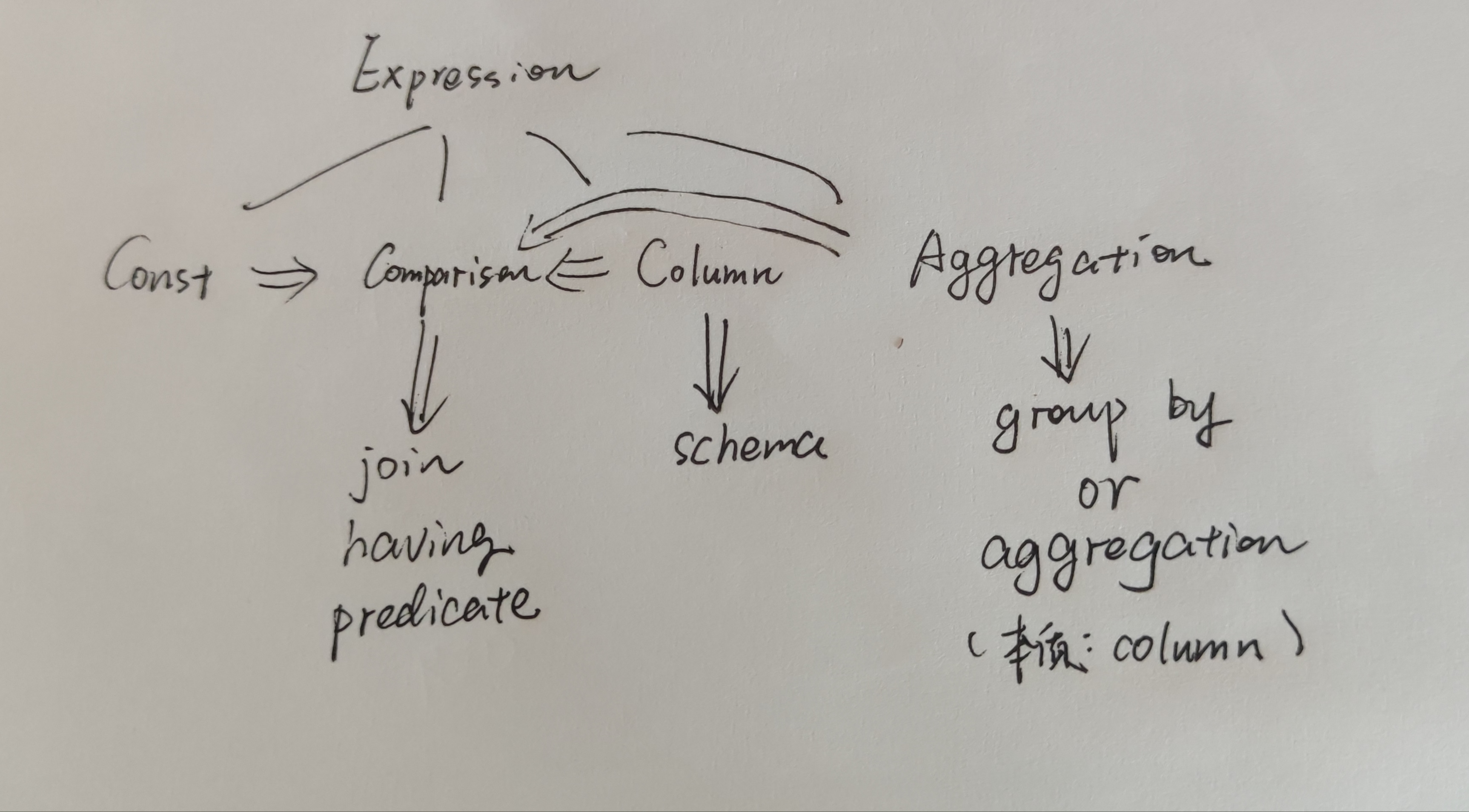
Expression不支持AND/OR,也不支持四则运算。只支持最基本的Comparison类型。
Const Expression最简单,永远返回一个常数。
Column Expression接受一个tuple做参数,返回这个tuple中特定column处的值。此外,Column Expression还用在Column类中,用于实现projection。
Aggregate Expression既可以表示一个GroupBy值(如Col2),也可以表示一个Aggregation值(如Max(Col1)、Sum(Col2)等)。
Const、Column、Aggregation 三种Expression负责给Comparison Expression提供操作数。
SeqScan
最基础的Executor。遍历TableHeap,顺序输出。
使用TableIterator类,可以容易地实现SeqScan Executor。
SeqScan Executor中需要保存一个TableIterator对象作为私有成员。需要在构造函数中初始化这个对象。否则会因为这个对象中的悬空指针造成内存越界问题。
需要注意predicate可能为null,要对此进行判断,否则会有内存越界问题。
值得注意的一点是,我们并不能直接把TableHeapIterator返回的Tuple作为最终结果输出。我们必须要考虑:plan中的out_schema可能仅仅是TableHeapIterator返回的Tuple的一个projection。
因此,我们需要遍历out_schema中的每一列,构造相应的column value,进而构造一个新的tuple。
上面的描述可能有些晦涩。下图是对应的代码:

这个操作在后面的每个executor中都会出现。
那么问题来了:为什么不增加一个专门的Projection Executor,而是要利用output_schema来实现projection呢?
我认为,对于seqscan这种简单的executor,两种方式的确差不多。所以的确可以针对这些简单executor实现一个专门的Projection Executor。
但是对于类似join这种需要将中间结果存储在临时table中的复杂executor,如果能及时地进行projection操作,可以大大减少存储开销。因此对于这些executor,不适合使用Projection Executor。
IndexScan
IndexScan与SeqScan很相似。区别在于把TableIterator换成IndexIterator。从IndexIterator中获取到RID,然后再去相应的TableHeap中获取Tuple。
根据lab指导,这里我们可以认为Index只可能是
BPlusTreeIndex<GenericKey<8>, RID, GenericComparator<8>>
这一种类型。这大大降低了难度,因为不需要考虑复杂的C++泛型和模板机制了。(真是太好了!)
Insert/Delete/Update
这三个操作符非常相似,放在一起说。它们都需要更新TableHeap以及相关的Index。
在获取index时,要注意可能这个TableHeap并没有相关的index。这时候就要捕获并处理访问catalog时产生的std::out_of_range error。在捕获error时注意要写成引用( catch (std::out_of_range &e) ),才能通过clang check。
NestedLoopJoin
最基本的join executor。
和之前的executor最大的不同点是:这个executor需要建立一个临时的TableHeap,用来存储join的结果。
我觉得单纯的NestedLoopJoin太简单,没意思。因此我在这里实现了一个略微复杂一些的BlockNestedLoopJoin,即每次从left child executor中读取一个block数量的tuple进入内存,并与right child executor的所有tuple进行join。
但是在lab中,seqscan executor和indexscan executor的语义都是获取TableHeap中tuple的复制,而不是获取引用。这样做的好处在于可以及时释放TableHeap的锁,有利于减少并发访问的冲突。但是增加了存储开销。
因此我们不能在原TableHeap的Page上进行操作,必须新开辟一块空间,用来存储一个block数量的tuple的复制。我选择在堆上开辟这样一块空间,称为left_buffer_,令其大小可以容纳10个tuple。
在NestedLoopJoin executor中,需要多次遍历right child executor。我们不想在每次重新遍历right child executor时,都重新构造一次它的结果(如果right child executor本身也是一个join executor,每次都重新执行join开销太大。)。因此在NestedLoopJoin executor完成一次之后,我们置位is_done flag。在后续再次遍历NestedLoopJoin executor时,我们直接从临时的TableHeap中返回结果。
IndexNestedLoopJoin
稍微高级一些的join executor。
与NestedLoopJoin executor最大的不同点在于,right child executor不再存在。我们遍历left child executor,对每个left tuple构造right index key,在right index中进行查找以获取right tuple。
仔细思考可以发现,这时创建left_buffer_不再有意义。
实现这个executor的难点在于如何使用left tuple构造right index key。由于我们只考虑“对左右executor的各一个column做join”这一种情况,可以暴力强行获取左右的column index,然后构造key。如下图代码所示。当然如果join的情况更复杂,可能需要考虑其它更general的实现方式。

Aggregation
aggregation是所有executor里最复杂的一个。
lab指导中只要求实现最简单的aggregation。但我觉得这样没有意思,于是按照课上所讲,实现了一个hash aggregation。
hash aggregation的流程如下:
遍历child executor ----> 根据groupby key,构造多个partition(均为tableheap) ----> 对第一个partition构造hash table ----> 遍历构造完成的hash table,将结果写入临时tableheap ----> 对第二个partition构造hash table ----> ......
当没有groupby时,不需要构造partition,临时tableheap中只有一个tuple作为结果。
构造partition tableheap时,需要根据plan中的groupby和aggregate,构造一个schema。
注意在“遍历构造完成的hash table,将结果写入临时tableheap”这一步中,需要检查having clause。
需要注意考虑corner case:可能有某一个partition没有任何tuple。
在实现Aggregation的过程中,我遇到clang误报的情况。讲道理这可以通过在出问题的代码行后面加上 // NOLINT 加以解决。但偏偏这个误报是通过函数的层层调用,最终发生在不提交到gradescope的文件当中。因此这个办法就不好用了。
经过大量查找,我发现可以将导致问题的函数调用前后加上:
#ifndef __clang_analyzer__ target code #endif
这样可以让clang直接跳过target code这一行,不将其纳入分析的范围内。采用这种方式,误报问题得以解决。
总体来看,实现aggregation的代码量是最大的,实现的逻辑难度也比先前的所有executor都大上一大截。在完成这个executor之后,我整体的代码水平又有了相当的提高。
Limit
这个executor是最简单的一个。只需执行特定数量的child_executor->Next()方法即可。
值得注意的是plan->offset这个变量,它要求我们跳过前offset个输出。
只要细心地使用iterator,很容易实现Limit executor。
写在最后
lab3终于完成,进度已经比预期的落后了很多。
但是在这次实验中,我收获很多,代码能力大有长进,C++水平有所提升,面向对象编程更加熟练,对数据库中Query execution的实现方式有了深入清晰的理解。
继续加油!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号