TensorFlow 2.0 搭建卷积神经网络 (CNN)
关于 CNN 基础理论可见:卷积神经网络
TensorFlow2.0 快速搭建神经网络:tf.keras
下面主要介绍:1.搭建卷积神经网络的主要模块:卷积、批标准化、激活、池化、全连接;
2.经典卷积网络的搭建:LeNet、AlexNet、VGGNet、InceptionNet、ResNet。
1 卷积神经网络主要模块
1.1 卷积 (Convolutional)
tf.keras.layers.Conv2D ( filters = 卷积核个数, kernel_size = 卷积核尺寸, #正方形写核长整数,或(核高h,核宽w) strides = 滑动步长, #横纵向相同写步长整数,或(纵向步长h,横向步长w),默认1 padding = “same” or “valid”, #使用全零填充是“same”,不使用是“valid”(默认) activation = “ relu ” or “ sigmoid ” or “ tanh ” or “ softmax”等 , #如有BN此处不写 input_shape = (高, 宽 , 通道数) #输入特征图维度,可省略 )
eg:
model = tf.keras.models.Sequential([ Conv2D(6, 5, padding='valid', activation='sigmoid'), MaxPool2D(2, 2), Conv2D(6, (5, 5), padding='valid', activation='sigmoid'), MaxPool2D(2, (2, 2)), Conv2D(filters=6, kernel_size=(5, 5),padding='valid', activation='sigmoid'), MaxPool2D(pool_size=(2, 2), strides=2), Flatten(), Dense(10, activation='softmax') ])
1.2 批标准化 (Batch Normalization,BN)
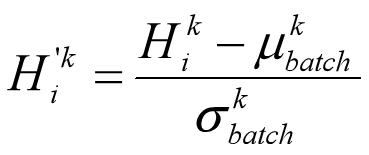
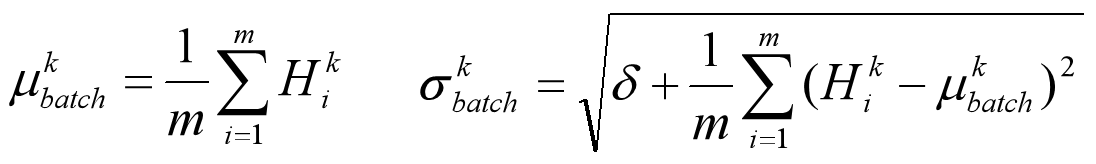
此外,还可以引入可训练参数 γ (缩放因子) 和 β (偏移因子),调整批归一化的力度:
![]()
BN 层位于卷积层之后,激活层之前,eg:
model = tf.keras.models.Sequential([ Conv2D(filters=6, kernel_size=(5, 5), padding='same'), # 卷积层 BatchNormalization(), # BN层 Activation('relu'), # 激活层 MaxPool2D(pool_size=(2, 2), strides=2, padding='same'), # 池化层 Dropout(0.2), # dropout层 ])
1.3 池化 (Pooling)
tf.keras.layers.MaxPool2D( pool_size=池化核尺寸,#正方形写核长整数,或(核高h,核宽w) strides=池化步长,#步长整数, 或(纵向步长h,横向步长w),默认为pool_size padding=‘valid’or‘same’ #使用全零填充是“same”,不使用是“valid”(默认) ) tf.keras.layers.AveragePooling2D( pool_size=池化核尺寸,#正方形写核长整数,或(核高h,核宽w) strides=池化步长,#步长整数, 或(纵向步长h,横向步长w),默认为pool_size padding=‘valid’or‘same’ #使用全零填充是“same”,不使用是“valid”(默认) )
eg:
model = tf.keras.models.Sequential([ Conv2D(filters=6, kernel_size=(5, 5), padding='same'), # 卷积层 BatchNormalization(), # BN层 Activation('relu'), # 激活层 MaxPool2D(pool_size=(2, 2), strides=2, padding='same'), # 池化层 Dropout(0.2), # dropout层 ])
1.4 舍弃 (Dropout)
model = tf.keras.models.Sequential([ Conv2D(filters=6, kernel_size=(5, 5), padding='same'), # 卷积层 BatchNormalization(), # BN层 Activation('relu'), # 激活层 MaxPool2D(pool_size=(2, 2), strides=2, padding='same'), # 池化层 Dropout(0.2), # dropout层 ])
1.5 卷积神经网络

model = tf.keras.models.Sequential([ Conv2D(filters=6, kernel_size=(5, 5), padding='same'), # 卷积层 BatchNormalization(), # BN层 Activation('relu'), # 激活层 MaxPool2D(pool_size=(2, 2), strides=2, padding='same'), # 池化层 Dropout(0.2), # dropout层 ])
1.6 卷积神经网络搭建示例
- C(核:6*5*5,步长:1,填充:same )
- B(Yes)
- A(relu)
- P(max,核:2*2,步长:2,填充:same)
- D(0.2)
- Flatten
- Dense(神经元:128,激活:relu,Dropout:0.2)
- Dense(神经元:10,激活:softmax)
数据集:Cifar10
import tensorflow as tf import os import numpy as np from matplotlib import pyplot as plt np.set_printoptions(threshold=np.inf) cifar10 = tf.keras.datasets.cifar10 (x_train, y_train), (x_test, y_test) = cifar10.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0class Baseline(tf.keras.Model): def __init__(self): super(Baseline, self).__init__() self.c1 = tf.keras.layers.Conv2D(filters=6, kernel_size=(5, 5), padding='same') self.b1 = tf.keras.layers.BatchNormalization() self.a1 = tf.keras.layers.Activation('relu') self.p1 = tf.keras.layers.MaxPool2D(pool_size=(2, 2), strides=2, padding='same') self.d1 = tf.keras.layers.Dropout(0.2) self.flatten = tf.keras.layers.Flatten() self.f1 = tf.keras.layers.Dense(128, activation='relu') self.d2 = tf.keras.layers.Dropout(0.2) self.f2 = tf.keras.layers.Dense(10, activation='softmax') def call(self, inputs): x = self.c1(inputs) x = self.b1(x) x = self.a1(x) x = self.p1(x) x = self.d1(x) x = self.flatten(x) x = self.f1(x) x = self.d2(x) y = self.f2(x) return y model = Baseline() model.compile(optimizer=tf.keras.optimizers.Adam(), loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False), metrics=[tf.keras.metrics.sparse_categorical_accuracy]) history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1) model.summary() # show acc = history.history['sparse_categorical_accuracy'] val_acc = history.history['val_sparse_categorical_accuracy'] loss = history.history['loss'] val_loss = history.history['val_loss'] plt.figure(figsize=(8, 8)) plt.subplot(1, 2, 1) plt.plot(acc, label='Training Accuracy') plt.plot(val_acc, label='Validation Accuracy') plt.title('Training and Validation Accuracy') plt.legend() plt.subplot(1, 2, 2) plt.plot(loss, label='Training loss') plt.plot(val_loss, label='Validation loss') plt.title('Training and Validation loss') plt.legend() plt.show()
2 经典卷积网络
2.1 LeNet
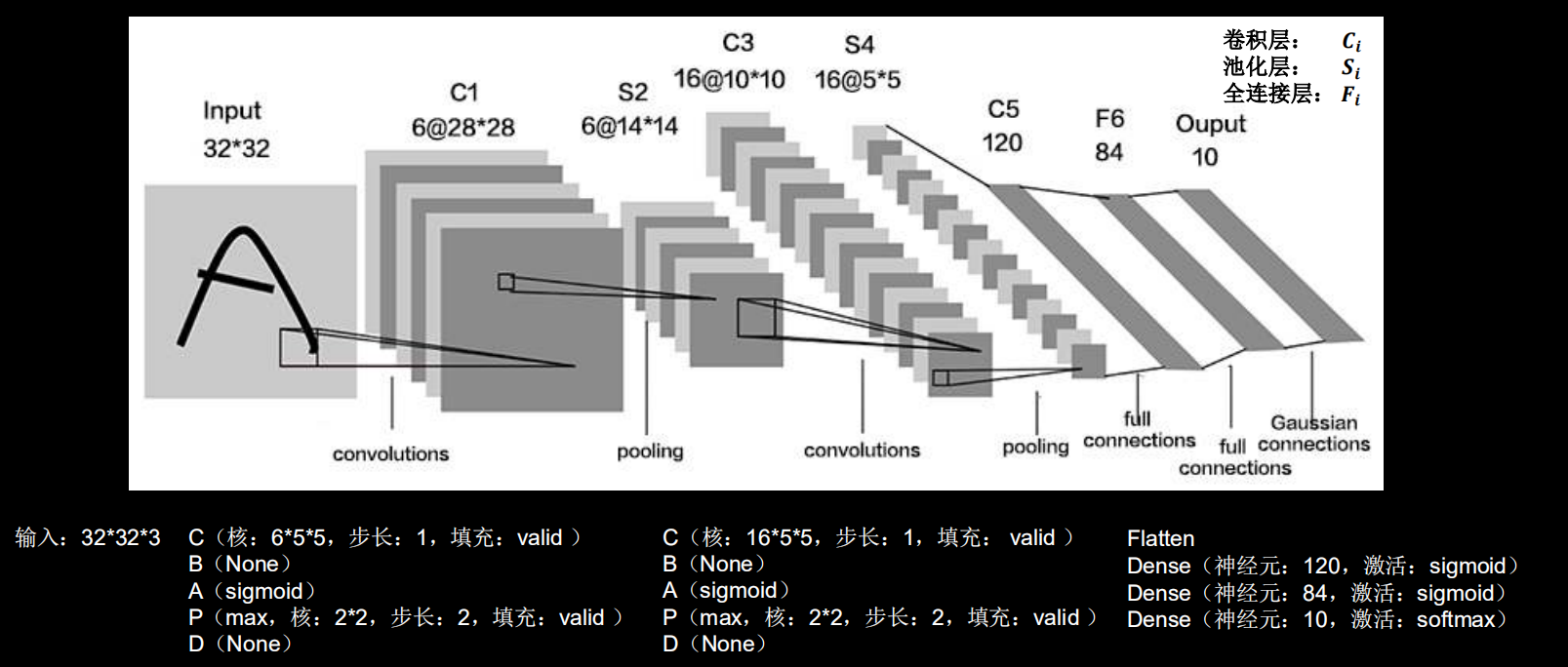

class LeNet5(tf.keras.Model): def __init__(self): super(LeNet5, self).__init__() self.c1 = tf.keras.layers.Conv2D(filters=6, kernel_size=(5, 5), activation='sigmoid') self.p1 = tf.keras.layers.MaxPool2D(pool_size=(2, 2), strides=2) self.c2 = tf.keras.layers.Conv2D(filters=16, kernel_size=(5, 5), activation='sigmoid') self.p2 = tf.keras.layers.MaxPool2D(pool_size=(2, 2), strides=2) self.flatten = tf.keras.layers.Flatten() self.f1 = tf.keras.layers.Dense(120, activation='sigmoid') self.f2 = tf.keras.layers.Dense(84, activation='sigmoid') self.f3 = tf.keras.layers.Dense(10, activation='softmax') def call(self, inputs): x = self.c1(inputs) x = self.p1(x) x = self.c2(x) x = self.p2(x) x = self.flatten(x) x = self.f1(x) x = self.f2(x) y = self.f3(x) return y
2.2 AlexNet

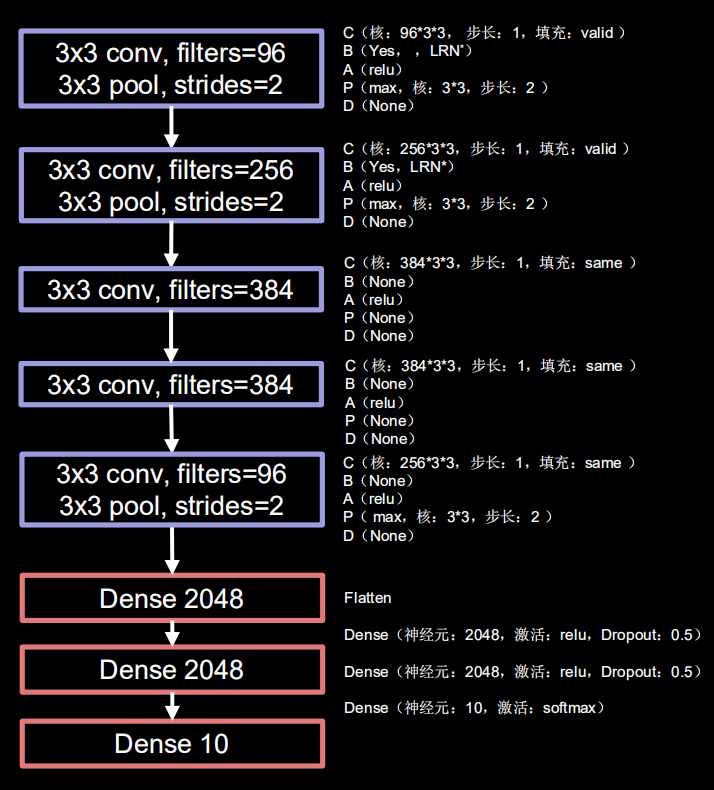
class AlexNet8(tf.keras.Model): def __init__(self): super(AlexNet8, self).__init__() self.c1 = tf.keras.layers.Conv2D(filters=96, kernel_size=(3, 3)) self.b1 = tf.keras.layers.BatchNormalization() self.a1 = tf.keras.layers.Activation('relu') self.p1 = tf.keras.layers.MaxPool2D(pool_size=(3, 3), strides=2) self.c2 = tf.keras.layers.Conv2D(filters=256, kernel_size=(3, 3)) self.b2 = tf.keras.layers.BatchNormalization() self.a2 = tf.keras.layers.Activation('relu') self.p2 = tf.keras.layers.MaxPool2D(pool_size=(3, 3), strides=2) self.c3 = tf.keras.layers.Conv2D(filters=384, kernel_size=(3, 3), padding='same', activation='relu') self.c4 = tf.keras.layers.Conv2D(filters=384, kernel_size=(3, 3), padding='same', activation='relu') self.c5 = tf.keras.layers.Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu') self.p3 = tf.keras.layers.MaxPool2D(pool_size=(3, 3), strides=2) self.flatten = tf.keras.layers.Flatten() self.f1 = tf.keras.layers.Dense(2048, activation='relu') self.d1 = tf.keras.layers.Dropout(0.5) self.f2 = tf.keras.layers.Dense(2048, activation='relu') self.d2 = tf.keras.layers.Dropout(0.5) self.f3 = tf.keras.layers.Dense(10, activation='softmax') def call(self, inputs): x = self.c1(inputs) x = self.b1(x) x = self.a1(x) x = self.p1(x) x = self.c2(x) x = self.b2(x) x = self.a2(x) x = self.p2(x) x = self.c3(x) x = self.c4(x) x = self.c5(x) x = self.p3(x) x = self.flatten(x) x = self.f1(x) x = self.d1(x) x = self.f2(x) x = self.d2(x) y = self.f3(x) return y
2.3 VGGNet
VGGNet 诞生于2014年,当年 ImageNet 竞赛的亚军,Top5错误率减小到7.3%。


class VGG16(tf.keras.Model): def __init__(self): super(VGG16, self).__init__() self.c1 = tf.keras.layers.Conv2D(filters=64, kernel_size=(3, 3), padding='same') self.b1 = tf.keras.layers.BatchNormalization() self.a1 = tf.keras.layers.Activation('relu') self.c2 = tf.keras.layers.Conv2D(filters=64, kernel_size=(3, 3), padding='same') self.b2 = tf.keras.layers.BatchNormalization() self.a2 = tf.keras.layers.Activation('relu') self.p1 = tf.keras.layers.MaxPool2D(pool_size=(2, 2), strides=2, padding='same') self.d1 = tf.keras.layers.Dropout(0.2) self.c3 = tf.keras.layers.Conv2D(filters=128, kernel_size=(3, 3), padding='same') self.b3 = tf.keras.layers.BatchNormalization() self.a3 = tf.keras.layers.Activation('relu') self.c4 = tf.keras.layers.Conv2D(filters=128, kernel_size=(3, 3), padding='same') self.b4 = tf.keras.layers.BatchNormalization() self.a4 = tf.keras.layers.Activation('relu') self.p2 = tf.keras.layers.MaxPool2D(pool_size=(2, 2), strides=2, padding='same') self.d2 = tf.keras.layers.Dropout(0.2) self.c5 = tf.keras.layers.Conv2D(filters=256, kernel_size=(3, 3), padding='same') self.b5 = tf.keras.layers.BatchNormalization() self.a5 = tf.keras.layers.Activation('relu') self.c6 = tf.keras.layers.Conv2D(filters=256, kernel_size=(3, 3), padding='same') self.b6 = tf.keras.layers.BatchNormalization() self.a6 = tf.keras.layers.Activation('relu') self.c7 = tf.keras.layers.Conv2D(filters=256, kernel_size=(3, 3), padding='same') self.b7 = tf.keras.layers.BatchNormalization() self.a7 = tf.keras.layers.Activation('relu') self.p3 = tf.keras.layers.MaxPool2D(pool_size=(2, 2), strides=2, padding='same') self.d3 = tf.keras.layers.Dropout(0.2) self.c8 = tf.keras.layers.Conv2D(filters=512, kernel_size=(3, 3), padding='same') self.b8 = tf.keras.layers.BatchNormalization() self.a8 = tf.keras.layers.Activation('relu') self.c9 = tf.keras.layers.Conv2D(filters=512, kernel_size=(3, 3), padding='same') self.b9 = tf.keras.layers.BatchNormalization() self.a9 = tf.keras.layers.Activation('relu') self.c10 = tf.keras.layers.Conv2D(filters=512, kernel_size=(3, 3), padding='same') self.b10 = tf.keras.layers.BatchNormalization() self.a10 = tf.keras.layers.Activation('relu') self.p4 = tf.keras.layers.MaxPool2D(pool_size=(2, 2), strides=2, padding='same') self.d4 = tf.keras.layers.Dropout(0.2) self.c11 = tf.keras.layers.Conv2D(filters=512, kernel_size=(3, 3), padding='same') self.b11 = tf.keras.layers.BatchNormalization() self.a11 = tf.keras.layers.Activation('relu') self.c12 = tf.keras.layers.Conv2D(filters=512, kernel_size=(3, 3), padding='same') self.b12 = tf.keras.layers.BatchNormalization() self.a12 = tf.keras.layers.Activation('relu') self.c13 = tf.keras.layers.Conv2D(filters=512, kernel_size=(3, 3), padding='same') self.b13 = tf.keras.layers.BatchNormalization() self.a13 = tf.keras.layers.Activation('relu') self.p5 = tf.keras.layers.MaxPool2D(pool_size=(2, 2), strides=2, padding='same') self.d5 = tf.keras.layers.Dropout(0.2) self.flatten = tf.keras.layers.Flatten() self.f1 = tf.keras.layers.Dense(512, activation='relu') self.d1 = tf.keras.layers.Dropout(0.2) self.f2 = tf.keras.layers.Dense(512, activation='relu') self.d2 = tf.keras.layers.Dropout(0.2) self.f3 = tf.keras.layers.Dense(10, activation='softmax')
2.4 InceptionNet
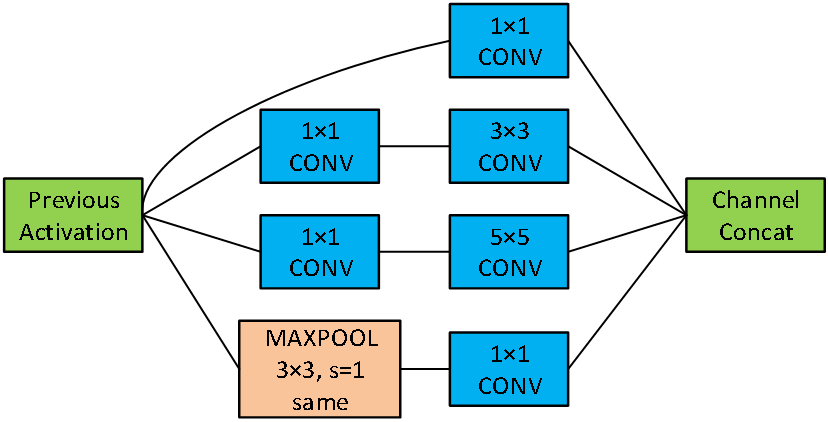
可以看到,InceptionNet 的基本单元中,卷积部分是比较统一的 C、B、A 典型结构,即卷积→BN→激活,激活均采用 Relu 激活函数,同时包含最大池化操作。
class ConvBNRelu(tf.keras.Model): def __init__(self, ch, kernelsz=3, strides=1, padding='same'): super(ConvBNRelu, self).__init__() self.model = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(ch, kernelsz, strides=strides, padding=padding), tf.keras.layers.BatchNormalization(), tf.keras.layers.Activation('relu') ]) def call(self, inputs): x = self.model(inputs) return x
class InceptionBlk(tf.keras.Model): def __init__(self, ch, strides=1): super(InceptionBlk, self).__init__() self.ch = ch self.strides = strides self.c1 = ConvBNRelu(ch, kernelsz=1, strides=strides) self.c2_1 = ConvBNRelu(ch, kernelsz=1, strides=strides) self.c2_2 = ConvBNRelu(ch, kernelsz=3, strides=strides) self.c3_1 = ConvBNRelu(ch, kernelsz=1, strides=strides) self.c3_2 = ConvBNRelu(ch, kernelsz=5, strides=strides) self.p4_1 = tf.keras.layers.MaxPool2D(3, strides=1, padding='same') self.c4_2 = ConvBNRelu(ch, kernelsz=1, strides=strides) def call(self, inputs): x1 = self.model(inputs) x2_1 = self.c2_1(inputs) x2_2 = self.c2_2(x2_1) x3_1 = self.c3_1(inputs) x3_2 = self.c3_2(x3_1) x4_1 = self.p4_1(inputs) x4_2 = self.c4_2(x4_1) x = tf.concat([x1, x2_2, x3_2, x4_2], axis=3) return x
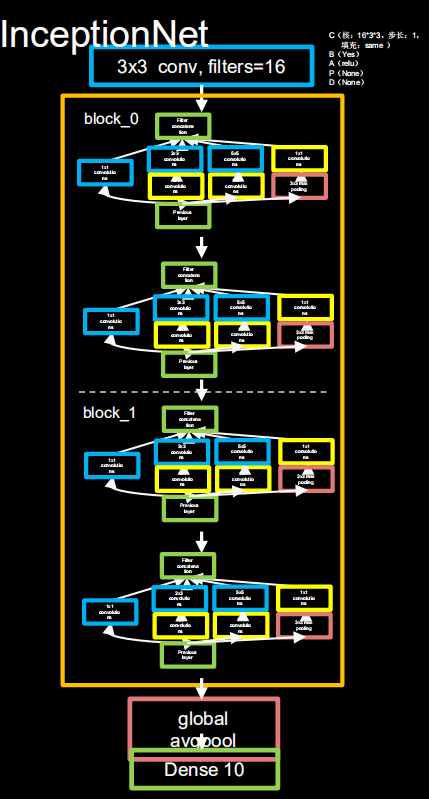
class Inception10(tf.keras.Model): def __init__(self, num_blocks, num_classes, init_ch=16, **kwargs): super(Inception10, self).__init__() self.in_channels = init_ch self.out_channels = init_ch self.num_blocks = num_blocks self.init_ch = init_ch self.c1 = ConvBNRelu(init_ch) self.blocks = tf.keras.Sequential() for block_id in range(num_blocks): for layer_id in range(2): if layer_id == 0: block = InceptionBlk(self.out_channels, strides=2) else: block = InceptionBlk(self.out_channels, strides=1) self.blocks.add(block) self.out_channels *= 2 self.p1 = tf.keras.layers.GlobalAveragePooling2D() self.f1 = tf.keras.layers.Dense(num_classes, activation='softmax') def call(self, inputs): x = self.c1(inputs) x = self.blocks(x) x = self.p1(x) y = self.f1(x) return y
2.5 ResNet
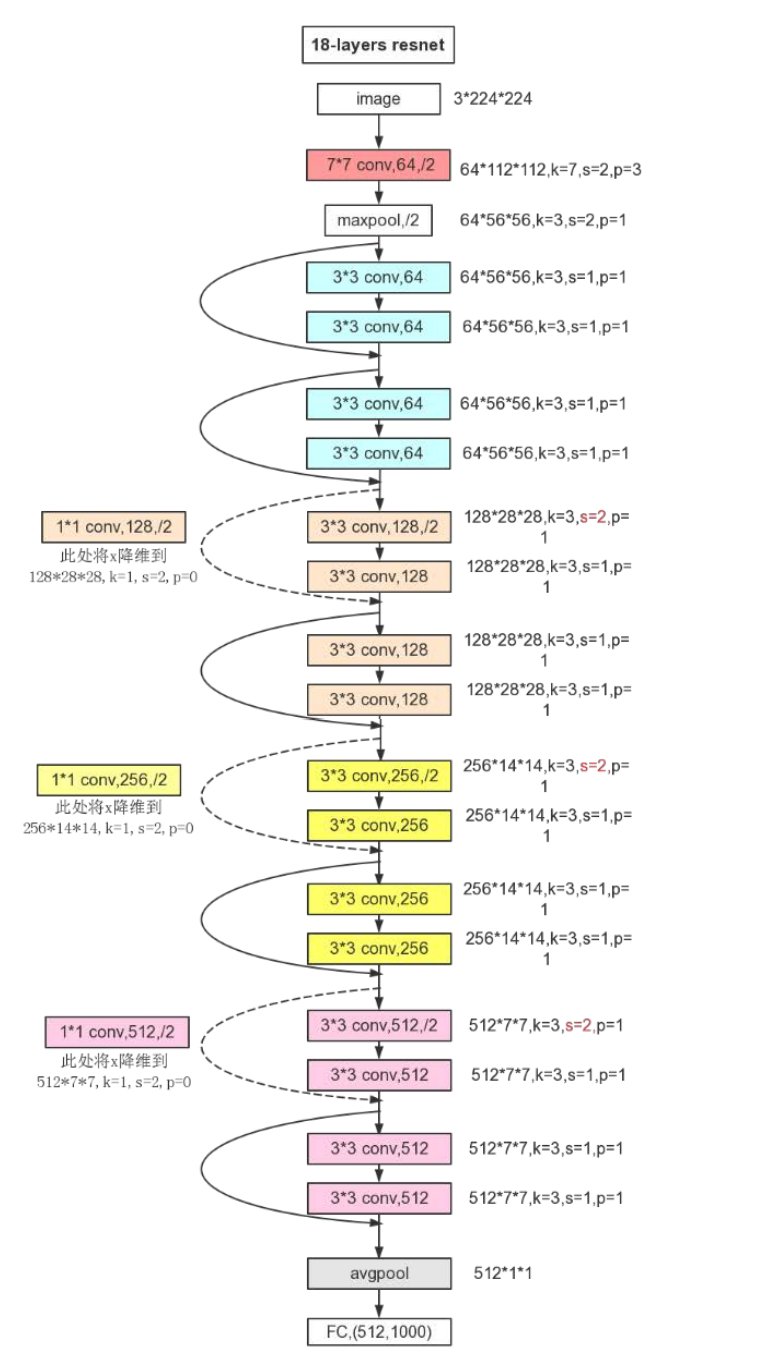 ResNet 的核心是残差结构,具体可见 CNN 理论基础。ResNet 引入残差结构最主要的目的是解决网络层数不断加深时导致的梯度消失问题,从之前介绍的 4 种 CNN 经典网络结构我们也可以看出,网络层数的发展趋势是不断加深的。这是由于深度网络本身集成了低层/中层/高层特征和分类器,以多层首尾相连的方式存在,所以可以通过增加堆叠的层数(深度)来丰富特征的层次,以取得更好的效果。
ResNet 的核心是残差结构,具体可见 CNN 理论基础。ResNet 引入残差结构最主要的目的是解决网络层数不断加深时导致的梯度消失问题,从之前介绍的 4 种 CNN 经典网络结构我们也可以看出,网络层数的发展趋势是不断加深的。这是由于深度网络本身集成了低层/中层/高层特征和分类器,以多层首尾相连的方式存在,所以可以通过增加堆叠的层数(深度)来丰富特征的层次,以取得更好的效果。
但如果只是简单地堆叠更多层数,就会导致梯度消失(爆炸)问题,它从根源上导致了函数无法收敛。然而,通过标准初始化(normalized initialization)以及中间标准化层(intermediate normalization layer),已经可以较好地解决这个问题了,这使得深度为数十层的网络在反向传播过程中,可以通过随机梯度下降(SGD)的方式开始收敛。
但是,当深度更深的网络也可以开始收敛时,网络退化的问题就显露了出来:随着网络深度的增加,准确率先是达到瓶颈(这是很常见的),然后便开始迅速下降。需要注意的是,这种退化并不是由过拟合引起的。对于一个深度比较合适的网络来说,继续增加层数反而会导致训练错误率的提升。ResNet 解决的正是这个问题。
class ResnetBlock(tf.keras.Model): def __init__(self, filters, strides=1, residual_path=False): super(ResnetBlock, self).__init__() self.filters = filters self.strides = strides self.residual_path = residual_path self.c1 = tf.keras.layers.Conv2D(filters, (3, 3), strides=strides, padding='same', use_bias=False) self.b1 = tf.keras.layers.BatchNormalization() self.a1 = tf.keras.layers.Activation('relu') self.c1 = tf.keras.layers.Conv2D(filters, (3, 3), strides=1, padding='same', use_bias=False) self.b1 = tf.keras.layers.BatchNormalization() if residual_path: self.down_c1 = tf.keras.layers.Conv2D(filters, (1, 1), strides=strides, padding='same', use_bias=False) self.down_b1 = tf.keras.layers.BatchNormalization() self.a2 = tf.keras.layers.Activation('relu') def call(self, inputs): residual = inputs x = self.c1(inputs) x = self.b1(x) x = self.a1(x) x = self.c2(x) y = self.b2(x) if self.residual_path: residual = self.down_c1(inputs) residual = self.down_b1(residual) out = self.a2(y + residual) return out class ResNet18(tf.keras.Model): def __init__(self, block_list, initial_filters=64): super(ResNet18, self).__init__() self.num_block = len(block_list) self.block_list = block_list self.out_filters = initial_filters self.c1 = tf.keras.layers.Conv2D(self.out_filters, (3, 3), strides=1, padding='same', use_bias=False, kernel_initializer='he_normal') self.b1 = tf.keras.layers.BatchNormalization() self.a1 = tf.keras.layers.Activation('relu') self.blocks = tf.keras.models.Sequential() for block_id in range(len(block_list)): # 第几个 resnet block for layer_id in range(block_list[block_id]): # 第几个卷积层 if block_id != 0 and layer_id == 0: block = ResnetBlock(self.out_filters, strides=2, residual_path=True) else: block = ResnetBlock(self.out_filters,residual_path=False) self.blocks.add(block) self.out_filters *= 2 # 下一个block的卷积核是上一个block的两倍 self.p1 = tf.keras.layers.GlobalAveragePooling2D() self.f1 = tf.keras.layers.Dense(10) def call(self, inputs): x = self.c1(inputs) x = self.b1(x) x = self.a1(x) x = self.blocks(x) x = self.p1(x) y = self.f1(x) return y model = ResNet18([2, 2, 2, 2])
对于 ResNet 的残差单元来说,除了这里采用的两层结构外,还有一种三层结构。两层残差单元多用于层数较少的网络,三层残差单元多用于层数较多的网络,以减少计算的参数量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号