神经网络中的损失函数
tf.keras 有很多内置的损失函数,具体可见官方文档,这里介绍一部分。
MSE、MAE、BinaryCrossentropy、CategoricalCrossentropy...
1 回归问题
1.1 均方误差 (MeanSquaredError,MSE)

这是最简单也是最常用的损失函数,在线性回归中,可以通过极大似然估计 (MLE) 推导。
1.2 绝对值误差 (MeanAbsoluteError,MAE)

1.3 绝对值百分比误差 (MeanAbsolutePercentageError,MAPE)
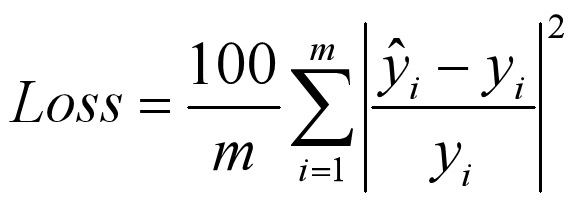
1.4 平方对数误差 (MeanSquaredLogarithmicError,MSLE)
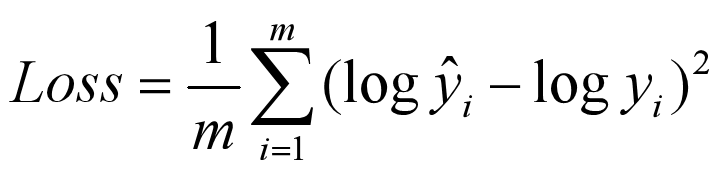
1.5 Hinge
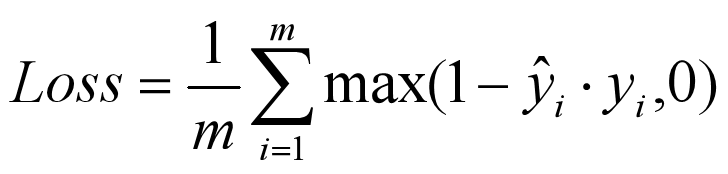
1.6 SquaredHinge
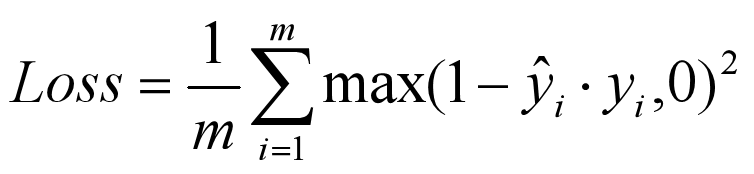
1.7 Huber
当预测偏差小于 δ 时,它采用平方误差;当预测偏差大于 δ 时,采用的线性误差。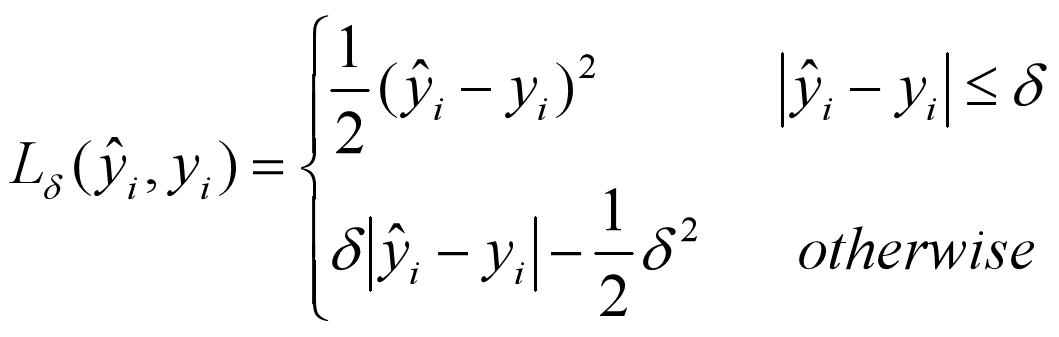
增强了 MSE 对离群点的鲁棒性。
2 分类问题
2.1 BinaryCrossentropy
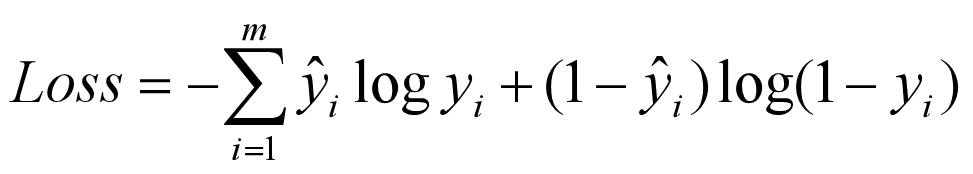
一般用于二分类,这是针对概率之间的损失函数,只有 yi 和 ˆyi 相等时,loss才为0,否则 loss 是一个正数,且概率相差越大,loss就越大,这种度量概率距离的方式称为交叉熵。一般最后一层使用 sigmoid 激活函数。
2.2 CategoricalCrossentropy
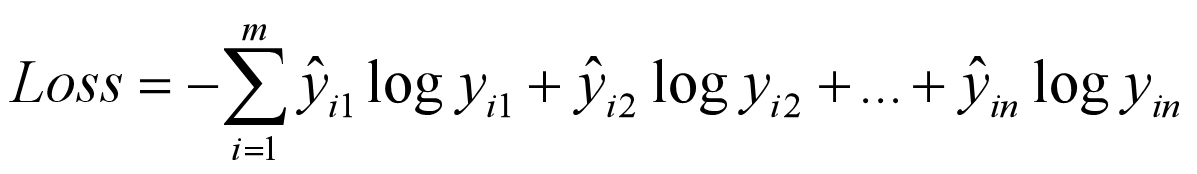
m 是样本数,n 是分类数。这是一个多输出的 loss 函数。一般最后一层使用 softmax 激活函数。
2.3 SparseCategoricalCrossentropy
SparseCategoricalCrossentropy 损失函数同 CategoricalCrossentropy 类似,唯一的区别在于输入的 y_true 是 one-hot 编码还是数字编码。
如果是 one-hot 编码,例如 [0, 0, 1], [1, 0, 0], [0, 1, 0],用 CategoricalCrossentropy;
如果是数字编码,例如 2, 0, 1,用 SparseCategoricalCrossentropy 。
关于参数 from_logits 的设置:如果输入的 y_pred 经过了 softmax 激活函数的处理,设置为 False;否则,设置为 True,表示该值为 logits,没有经过 softmax 激活函数的 fully connect 输出。
2.4 KLD (KL散度,相对熵)
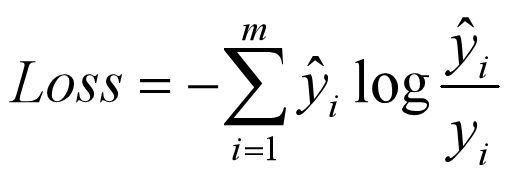

 浙公网安备 33010602011771号
浙公网安备 33010602011771号