
词频分析软件项目报告:
github项目地址:https://github.com/sumuyu/homework1
实验要求
基本功能
- 统计文件的字符数
- 统计文件的单词总数
- 统计文件的总行数
- 统计文件中各单词的出现次数
- 对给定文件夹及其递归子文件夹下的所有文件进行统计
- 统计两个单词(词组)在一起的频率,输出频率最高的前10个。
- 在Linux系统下,进行性能分析,过程写到blog中(附加题)
注意:
a) 空格,水平制表符,换行符,均算字符
b) 单词的定义:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
英文字母:A-Z,a-z
字母数字符号:A-Z,a-z,0-9
分割符:空格,非字母数字符号
例如:”file123”是一个单词,”123file”不是一个单词。file,File和FILE是同一个单词。
如果两个单词只有最后的数字结尾不同,则认为是同一个单词,例如,windows,windows95和windows7是同一个单词,iPhone4和IPhone5是同一个单词,但是,windows和windows32a是不同的单词,因为他们不是仅有数字结尾不同
输出按字典顺序,例如,windows95,windows98和windows2000同时出现时,输出windows2000
词组的定义:windows95 good, windows2000 good123,可以算是同一种词组。按照词典顺序输出。
c) 输入文件名以命令行参数传入
d) 输出文件result.txt
characters: number
words: number
lines: number
<word>: number
<word>为文件中真实出现的单词大小写格式,例如,如果文件中只出现了File和file,程序不应当输出FILE,且<word>按字典顺序(基于ASCII)排列,上例中程序应该输出File: 2
e) 根据命令行参数判断是否为目录
更多要求详见:第一次个人作业
分析:
1.首先要实现文件夹遍历,Windows条件下使用c++里的_findfirst和_findnext查找文件,需包含io.h头文件。具体方法参考: 遍历文件夹
2.读出判断是文件后,字符数,行数,用变量累加即可
3.单词的储存定位使用哈希表,可使用C++中unordered_map,关于map的使用参考: Map的使用 关于unordered_map使用参考unordered_map介绍及使用
| Development | 开发 | 1345 | 1395 |
| Planning | 计划 | 10 | 10 |
| Reporting | 报告 | 120 | 120 |
| · Analysis | · 需求分析 (包括学习新技术) | 360 | 420 |
| · Code Review | · 代码复审 | 30 | 40 |
| · Coding | · 具体编码 | 960 | 1000 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 10 |
| · Design | · 具体设计 | 30 | 30 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 5 | 5 |
| · Design Spec | · 生成设计文档 | 30 | 40 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 5 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 20 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 300 | 350 |
| · Test Report | · 测试报告 | 20 | 30 |
| 合计 | 1935 | 2090 |
性能分析:
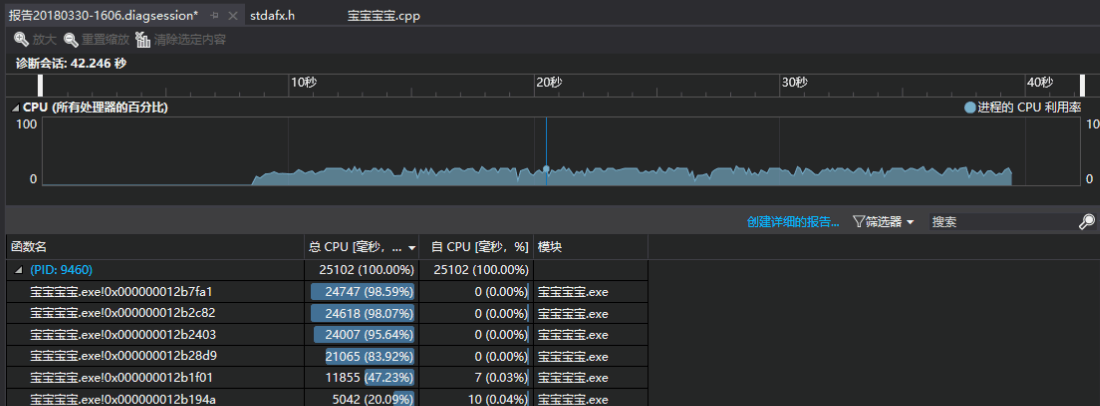

优化过程:
1.最初用多个函数,每做一次统计读一次文件,显然很慢,改为读文件时同时进行多项操作
2.起初用逐字符读进行处理,较慢改为逐行读
3.因为和别人交流过,选用了合适的数据结构,处理过前两个问题后Windows条件下可达30秒左右,便没在做过多优化
运行结果:
char_number:173669659 line_number:2278658 word_number:16669340 the top ten frequency of word: THAT 259186 SAID 208861 CLASS 192004 HARRY 184732 WITH 158745 THIS 152454 THEY 145945 Span 116118 HAVE 107383 FROM 105494 the top ten frequence of phrase: span class 62861 That Good 61427 span Span 41275 Class Reference 31289 internal href 26668 reference internal 26668 said Harry 24981 Class span 23075 href Leap 22567 Said Hermione 19193
前三个结果有一定差异,前四位一样,认为在误差允许范围内。单词词组正确。
过程:
周六晚19:00-22:00 阅读并思考题目,简单计划时间,同时软工组会研究了一下写法和细节
周日晚20:00-23:00 用C语言迅速写了字符,行数和单词数的程序,并在DeV下测试成功,在VS上测试除了无数小bug,debug烦了决定推翻改用C++
周一中午12:00-15:00 之前没用过C++,迅速刷了一遍菜鸟教程中的C++教程,重点是关于类的内容以及文件与流
15:00-19:00 开始做遍历文件夹,查了很多资料,试着写了一下,成功输出了遍历各文件夹的名字
19;00-20:00 用读逐字符方式读文件,统计字符与行数,测试时特别慢,于是在询问大佬之后改为用getline逐行读
20;00-22;30 成功读出字符数和行数,但和助教结果有差异,调试很久没改明白,问同学都和助教都不一样,遂准备开始统计单词数
周二12;00-13;00 实现了单词数统计
13;00-17;00 学习map和unordered_map使用方法
17:00-21:00 将单词插入到了map中,实现了单词的统计
21;00-23:00 思考词组的储存方式,以及如何词组定义map
周三 12:00-18:00 尝试词组的统计,基本实现,但词组的大小写始终和助教不匹配
18:00-21:00 Debug,修复词组大小写问题,但始终失败,后看同学说大小写可以不考虑,便放弃,开始做了性能分析报告
周四
早晨突然知道要移植才能测试,但电脑没安装Linux系统,一脸懵逼
下午13:00-15:30 做好了移植的代码,让同学帮忙测试,出了两屏幕的BUG
18:00-21:00 在学长的指导下发现bug 是编码问题,用VS2015修改了编码,运行成功,但发现结果和Windows下略有差别
21:00-22:00 提交
周五
18:00-23:00 撰写博客,发现插链接调字体好麻烦
总结
1要善于培养自学能力,本次实验中有各种各样的新知识,C++类的使用,map的使用,string的使用,文件移植的方法等等,需要大量的学习理解才能应用,耗费了很多时间,本篇前面部分给出了部分学习的连接,后续部分在结队作业做完后会进一步整理
2.善于向大佬请教问题,往往能很快解决一个问题,但在一定程度上会限制搜索自学的能力,善于在时间整体安排下求一个平衡;
3.要事先对程序的结构有一个大致的设计,本次中推翻重写了很多次,语言算法结构等,一定要在最开始时选择好
4.尽量早做,时间安排上尽量合理,本次周末开始做逃了好多课才做完
2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号