


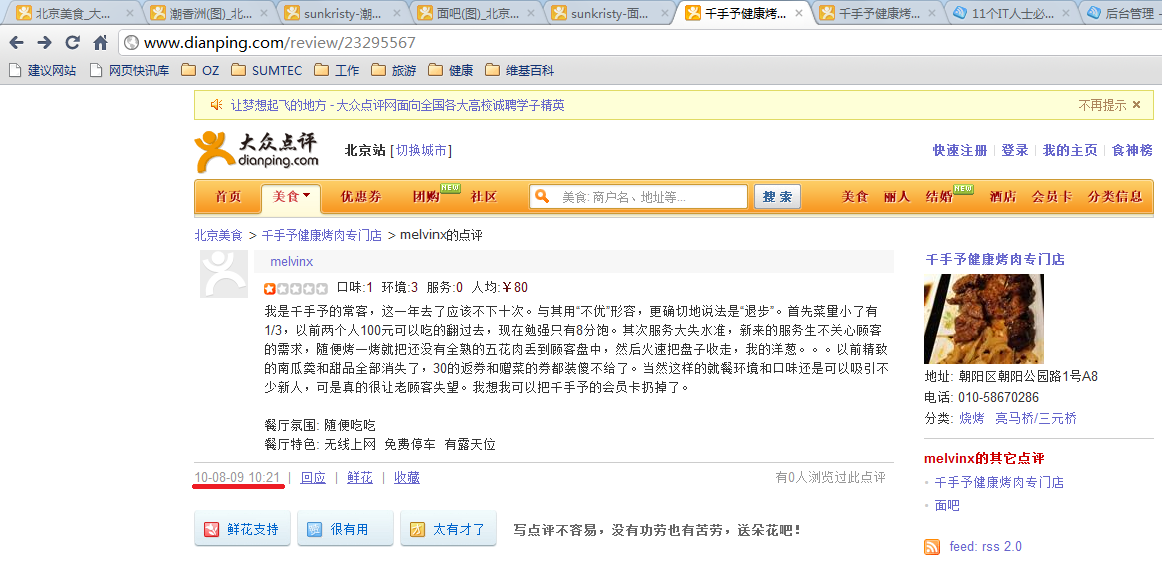
今天为了挑选一个合适的地方去吃晚餐,上了大众点评网。结果没想到偶然间发现了一个其实可能大家都知道的秘密:商家可以通过某种手段消除对其不利的内容,也许这是点评的一个盈利方式吧。啥也不说,上图:
------------------------图片的无聊分割线---------------------------------
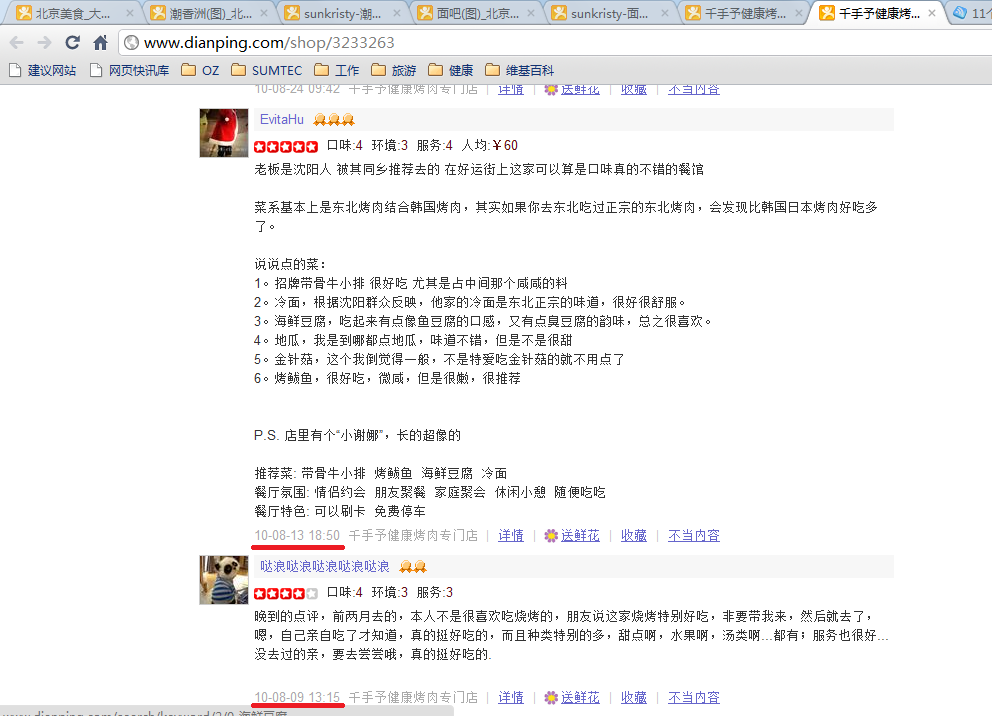
本来就觉得很奇怪,为什么有些店的评价是一堆的4、5星中间参杂着2、3星的评论,感觉就像是一有人给比较差的评价,就会有若干写手上来写东西外加评个4星半5星的评价。这个也就算了,毕竟还可以识别一下,没想到还有直接把这么差的评价给删掉的做法。其实百度不也有这种服务么,美其名曰公关服务,只不过从个人角度看这是一种丧失商业道德的做法。我没想到的是,点评网的道德在向百度靠拢。看来中国确实是一个没有什么道德可言的地方,或者说可以光明正大的出卖道德换取金钱的地方。这和出卖肉体不是在一个层次上吗?我认为不是的,应该是更下作。出卖肉体好歹还让人爽了一下(或者都爽了),可你这种行为是把你的爽建立在我的痛苦之上:我花了那么多时间在你的网站上逛,给你带来潜在的商业收益,你却在引导我去一个可能服务很糟糕,口味极差,甚至可能有食品安全问题的地方(这里面的例子是,肉没有烤熟)。而且,显而易见,你在引导我们去和你同样没有商业道德的地方——装傻不给券。
原本我还想写一个程序来抓某个店的评价,计算方差,来看看是否存在写手。现在看来光这么干是不够的,要抓整个网站,看看某个店是否存在删除差评的行为。
------------------------后来的分割线-------------------------------------
如何鉴别一个店的实际评价呢?我这里先把想法记上,有想法的请回复。
如果一个店的评分有假,那么作假方式目前看到的有两种:
1、找托去评分,往高了评,于是平均分就上去了。可是如果实际上不好,那么总会有人来给差评,那么结果就会导致标准差很高。举两个例子说明:如果总共有100个评价,50个4星,50个5星,那么数学期望值为4.5星,标准差为0.5;但是如果同样100个评价,平均分也是4.5,但是25个3星,75个5星,则标准差就变成了0.86了。后者即便没有托,你也很有可能会出现比前者糟糕的感受,或者直白的说,你有可能回来之后也给一个3星的评价,而不是4星。当然了,还有更糟糕的比如10个1星,90个5星,平均分还4.6呢,可是标准差却高达1.2。
解决方案1:做个爬虫,爬一下指定的店,很容易就可以得出这个结论了。
方案1对抗方案:通过大量的托来抹平标准差,比如说上面最后的一个4.6分例子,如果使用托的数量不是90个,而是990个,那么平均分为4.96,标准差却缩小到0.4。当然了,发起这种作弊还是很困难的,那是因为10个糟糕的评价可能并不算多,却要用大量的假评价来淹没实际数据。试想一个实际上不火的店,出现这么多评价,那也着实太假了。就算有不明真相的群众果然上当受骗了,那么引来的差评会更多。
解决方案2:还是一个爬虫,把每一个给出评价的人,爬他们所有的评价,计算标准差。一般正常的人,不可能每一个店都给出极高的评价,总有比较糟糕的印象。同时也不可能每一个都很糟糕,否则此人运气也太糟糕了。因此,标准差约低,说明是托的可能性越高。当然了,如果样本数量不高,那也很难说明是否真的就是托,但至少可以作为一个指标来衡量该用户的评价是否可信。比如一个非托用户,一共就只有1个5分的评价,你能确定他的这个5分到低含义是什么吗?也许只相当于我的3分。简单的做法是,以用户评价标准差D作为权重值,乘以该用户对该店的评分作为加权评分,接着对所有用户的加权评分求和,除以所有用户标准差之和。该计算结果是为加权平均分。如果加权平均分和非加权平均分相差较远,那么就需要值得注意了。如果想要更敏感一点,可以将标准插改为计算分数*100之后的方差。
方案2对抗方案:这个要对抗起来比较难,因为一个有效的托就变成需要有好评有差评才行。否则如果只有一大堆的好评,那么这个用户的标准差必定很低,甚至为0。与此同时,也不能通过大量生成托用户,每个托用户仅给出少量评价来逃避群众的法眼(我看到有一个神奇的用户,在某天的1个小时之内,连续发了10个评论,该用户总共的评价数量有百来页)。因为少量的评价只要不是由好评有差评,标准差还是会很低。要有效对抗,要么就是托用户也给差评,比如给一些名不见经传的小店差评(可能店主不关心甚至不知道,或者知道了也没有什么办法),要么就是走另一种途径,删除非托用户的评价,或者说剔出权重值高,但是分数低的评价。后一种对抗会比较麻烦。
解决方案3:还是爬虫,爬每一个给出评价的用户,评估该用户在其它店的评分情况。比如说,设该店评分数学期望值为E,该店评分数学期望值为d,该用户在该点的评分为x,计算y=[(x-E)/d]^2。y越大,表明该用户的在该店的评分越有价值。再计算y的数学期望值Y,在联合方案2的标准差值D,来作为更准确的权重值。比方说,用户权重值K=(Y+D^2)/2。又或者,可以用该方法来影响D的计算过程,即,统计的是用户对各点的y加权评分的标准差D',以D'作为用户在该店评分的加权。
公式中需要除以d的原因是,我们需要计算的是某用户的评分,在该店评分标准差的什么位置。或者说,某用户在两个不同店的(x-E)值都是0.1,店A的标准差为1,店B的标准差为0.1,显然该用户在店B的评分更具有价值。
方案3对抗方案:这个更不好搞,因为所有托在各店的评分总是倾向于一致(无论是要搞香还是搞臭),换句话说,参与某特定店的托们,他们的分总是倾向一致的,并且要达到影响平均分的效果。而且根据前面最开始的例子,我们可以看到要达到良好的效果(淹没差评),需要大量的酱油好评,因此实际上数学期望值E会倾向托所给出的分数。因此,尽管托的Y值不可能会是零,但也肯定不会高。而真实用户评价则更有可能与某店评分的数学期望值E有较大差距,例如给某平均分4的店评了一个1分。对于托来说,大部分的评价都趋向于不真实,所以他们的y值得平均值Y会很低,即便偶尔或真实或为了对抗分析而胡乱给出的评价,也会被淹没。(托用假评把真评淹没,只要我们能找到鉴别假评的方法,他就很难在不淹没真评的情况下,不被我们发现。)此时,有效的对抗可能就只剩下剔除有效评价这一种办法了。
2、另一种作假的方式,就是剔除差评。当然了,也可以为了搞臭某店,也可以剔除好评。这种方式的危害极大,因为很难找到有效信息,或者方法很麻烦。
解决方案4:还是爬虫,但是要做出针对某店的评估可能会很难,除非爬出所有的数据并进行整理和分析。以上面的图作为例子,我们就可以看出来,其实这些信息并非彻底消失了,而是在某人的个人页面中。因此,如果我们爬了所有用户页面之后,就可以分析出有哪些店都删除了哪些差评。这些差评所给的分数,应该给一个比较高的系数,例如100。因为既然被删除,通常是因为这是一个真实情况,但是店家不想让你我知道,于是就删了。
方案4对抗方案:这个嘛,两种思路。要么彻底蒸发该消息,要么避免被爬。前者基本上是一个很不好的体验,因为这样用户必然会发现自己的评价会消失,也就不再信任该站点。后者嘛,相对比较好实现,例如在一段时间内如果访问数量超过多少,则出现“你是机器人吗”画面。不过这个嘛,效果真不好说,因为验证过程完全可以做成分布式的。还有另一种方法就是使用法律武器,不过这个也不见得好使,因为举证并不见得容易,过程也未必迅速。更重要是,通过法律途径等于将“占领道德制低点”这个目标公开化,未必对网站的前途有好处。
解决方案5:还是爬虫,对给出该店评价的用户进行分析(如方案2和3),通过计算有多少潜在的托来给出该店分数是否具有价值,或者计算该店的道德指数。这个方案虽然不是直接针对剔除差评的问题,但是通常这种店不会单独选择剔除差评这种作弊方式。因为剔的太多用户肯定会知道,所以还需要通过补充好评来达到目的。该方案的另一个缺点是,无法给出有效分数,只能给出另一个和“口感、环境、服务”等都没有关系的“可信度”指标,而且这个指标的实际含义还不是特别清晰。比如有可能会产生错误的结果。
方案5对抗方案:基本上无解,除了使用法律武器。不过方案5的威胁有可能也不是很大,因为本身的准确性和有效性就不一定可靠。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号