小白学Java:RandomAccessFile
前文传送门:小白学Java:I/O流
小白学Java:RandomAccessFile
之前我们所学习的所有的流在对数据操作的时候,都是只读或者只写的,使用这些流打开的文件很难进行更新。Java提供了RandomAccessFile类,允许在文件的任意位置上进行读写。
概述
官方文档的解释是这样的:
Instances of this class support both reading and writing to a random access file.
- 支持对文件进行读写,可以认为这是一个双向流。
A random access file behaves like a large array of bytes stored in the file system.
- 在操作文件的时候,将文件看作一个大型的字节数组。
There is a kind of cursor, or index into the implied array, called the file pointer; input operations read bytes starting at the file pointer and advance the file pointer past the bytes read
-
有个叫做文件指针(file pointer)的玩意儿作为数组索引。在读取的时候,从文件指针开始读取字节,读取完后,将文件指针移动到读取的字节之后。
-
其实很好理解,就像我们打字的时候光标,光标在哪,就从哪开始打字,这就是输出的过程。读取的过程差不多意思,相当于选中要读取的内容,这使光标就移动到选中的最后一个字节的后面。
继承与实现
RandomAccessFile直接继承自Object类,看上去就不像是我们之前学习的那么多的输入输出流,都继承于抽象基类。但是,RandomAccessFile通过接口的实现,便能够完成对文件的输入与输出:
public class RandomAccessFile implements DataOutput, DataInput, Closeable
- 实现了
Closeable的接口,Closeable接口又继承了AutoCloseable接口,能够实现流的自动关闭。 - 实现了
DataOutput接口,提供了输出基本数据类型和字符串的方法,如 writeInt,writeDouble,writeChar,writeBoolean,writeUTF。 - 实现了
DataInput接口,提供了读取基本数据类型和字符串的方法,同理对应的把write改成read即可。
我们在查看官方文档的时候看到许多类似的话,我们以read方法举例:
Although RandomAccessFile is not a subclass of InputStream, this method behaves in exactly the same way as the InputStream.read() method of InputStream.
大致意思就是:虽然RandomAccessFile并不是InputStream的子类,但该方法的行为与InputStream.read()方法完全相同。
我们就可以推断出,read和write等相关方法和我们之前学习过的读写操作是一样的。
构造器
我们先来看看它提供的构造器:
RandomAccessFile(File file, String mode)
RandomAccessFile(String name, String mode)
只有这俩构造器,意思是创建一个支持随机访问文件的流,mode是设置访问方式的参数,前者传入File对象,后者传入路径名。
模式设置
| 模式 | 解释 |
|---|---|
| "r" | 只支持读,任何有关写的操作将会抛出异常 |
| "rw" | 支持读和写,如果文件不存在,将尝试创建 |
| "rws" | 类似于"rw",需要同步更新文件的内容或者元数据到底层存储设备上 |
| "rwd" | 类似于"rws",与"rws"不同的在于没有对元数据的要求 |
我对前两个尚且明白它们的作用,但是对"rws"和"rwd”,咱不懂啊,我只能粗略地看看官方地解释:
This is useful for ensuring that critical information is not lost in the event of a system crash.
大概能够明白,当我们写入数据量很大的时候,通常都会将数据先存入内存,然后再刻入底层存储设备,这样的话写入的数据会有不能及时存储的可能,比如突然停电啊等意外情况。"rwd"和"rws"能够保证写入的数据不经过内存,同步到底层存储,确保在系统崩溃时不会丢失关键信息。
文件指针
上面提到,存在着文件指针这么个玩意儿,可以控制读或写的位置,下面是几个与文件指针相关的方法:
//将指针位置设置为pos,即从流开始位置计算的偏移量,以字节为单位
public void seek(long pos)
//获取指针当前位置,以字节为单位
public native long getFilePointer()
//跳过n个字节的便宜量
public int skipBytes(int n)
注:以字节为单位是指:如果读取1个int类型的内容,读取之后,指针将会移动4个字节。
操作数据
读取数据
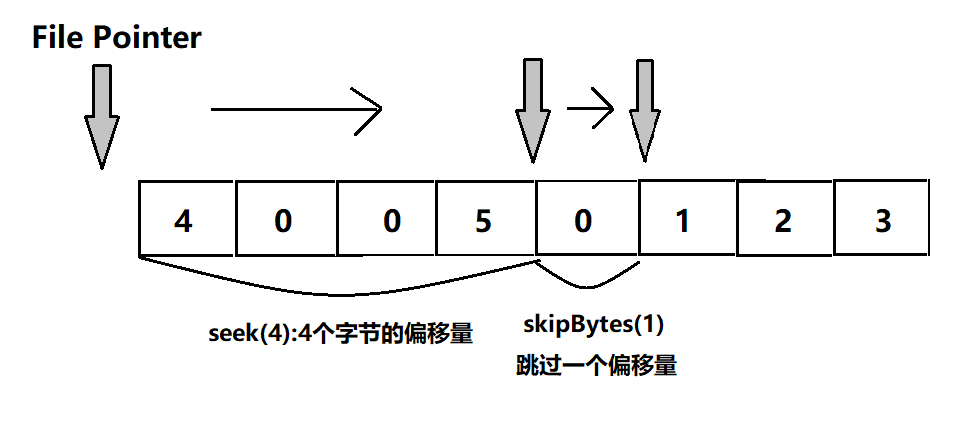
假设现在从只包含8个字节的文件中读取内容:
//指针测试
System.out.println("首次进入文件,文件指针的位置:"+raf.getFilePointer());//0
raf.seek(4);
System.out.println("seek后,现在文件指针的位置:"+raf.getFilePointer());//4
raf.skipBytes(1);
System.out.println("skipBytes后,现在文件指针的位置:"+raf.getFilePointer());//5
以下为测试方法:
public static void testFilePointerAndRead(String fileName){
//try-with-resource
try(RandomAccessFile raf = new RandomAccessFile(fileName,"r")){
//定义缓冲字节数组
byte[] bs = new byte[1024];
int byteRead = 0;
//read(bs) 读取bs.length个字节的数据到一个字节数组中
while((byteRead = raf.read(bs))!=-1){
System.out.println("读取的内容:"+new String(bs,0,byteRead));
}
} catch (IOException e) {
e.printStackTrace();
}
}
RandomAccessFile本身是实现Autocloseable接口的,可以利用JDK1.7提出的处理异常新方式try-with-resource,前篇已经学习过。- 在读取字节的时候,如果指定读取的字节超过文件本身的字节数,将会抛出
EOFException的异常。举个例子:假如现在我用readInt读取四个字节的int类型的值,但是文件本身的字节数小于4,就会出错。 - 区别于上面的例子,假如现在文件中是空的,我是用read()方法,由于达到了文件的尾部,将会返回-1,而不是抛出异常。
read(byte b[])与read()
read(byte b[])和read()方法的不同点(我其实是有些懵的,稍微整理一下):
public int read()
该方法的返回值是文件指针开始的下一个字节,字节作为整数返回,范围从0到255 (0x00-0x0ff)。如果到达文件的末尾,则为-1。当我将a字符以字节写入的时候,在文本文件中查看,却是完完整整的a,我明白这是内部发生了转化。
当我再调用read()方法时却还是会返回97,因为read返回值要求是int类型,要得到字符a必须进行相应的转换。
这些确实都没啥问题,但是,我们上面代码中在读取内容的时候,并没有在哪里进行转换啊,当然这是我一开始的想法。我们再来看看read(byte b[])这个方法,看过之后就明白了。
public int read(byte b[])
该方法的返回值是读入缓冲数组b的总字节数,如果没有更多的数据,则为-1,因为已经到达文件的末尾。
以我们的代码为例:我们上面定义了一个存储字节的数组bs,字节就是从文件中读取而来,我们专门定义了一个变量byteRead来表示该方法的返回值(即读入缓冲数组的字节数),如果是-1,说明达到末尾,这个没有异议。如果不是-1的话,就调用String的构造方法,从该字节数组的第0位开始,向后读取byteRead长度的字节,构造一个字符串。
Constructs a new String by decoding the specified array of bytes using the platform's default charset.
String这个构造器是有些讲究的,它将通过使用平台的默认字符集解码指定的字节数组,构造一个新字符串。其实这个构造器就已经完成了从字节数组到字符的转化。
总结
write方法中必须传入int类型的数,我们在写入数据的时候,假设传入的是97,最终其实是把97的低八位二进制传入,因为计算机只认识二进制。我们打开文件看到的完整的a其实已经时它根据对应得字符集根据二进制进行编码转化而来的。而在我们读取的时候,最初接收到的也是原来的低八位二进制,read方法返回的是int类型的值,所以返回值便是97。
知道了这些,我们在文本文件中写入97,再在程序中用read读取,返回的是57。而字符9正好对应的就是57,意思是我们写入的97在文本文件中其实是以'9'和'7'两个字符存储的。
扩展几个ASCII常见的转换:
| 二进制 | 十进制 | 十六进制 | 编写字符 |
|---|---|---|---|
| 00110000 | 48 | 0x30 | 0 |
| 01000001 | 65 | 0x41 | A |
| 01100001 | 97 | 0x61 | a |
追加数据
我们知道,在打开一个文件的时候,如果没有指定文件指针的位置,默认会从头开始。如果不设置文件指针的话,追加数据的操作将会覆盖原文件。那么,知道这个之后,问题就十分简单啦,追加数据嘛,考虑下面几步即可:
- 以
"rw"模式创建一个RandomAccessFile对象。 - 将文件指定定位到原文件尾部。
- 调用各种各样适合的write方法即可。
- 最后记得关流,当然可以采用新异常处理的方法。
/**
* 在指定文件尾部追加内容
* @param fileName 文件路径名
*/
public static void addToTail(String fileName){
//try-with-resource
try(RandomAccessFile raf = new RandomAccessFile(fileName,"rw")) {
//将文件指针指向文件尾部
raf.seek(raf.length());
//以字节数组的形式写入
raf.write("追加内容".getBytes());
} catch (IOException e) {
e.printStackTrace();
}
}
还有一个有趣的点,我们知道,写入数据的时候也是根据文件指针的位置来操作的,但是现在有一个问题,假如我文件中的字节数是4,我把文件指针设置到8的位置,再写入数据会怎么样呢?
既然都这么说了,那就肯定不会抛出异常,官方文档是这样说的:
Output operations that write past the current end of the implied array cause the array to be extended.
说实话,在没测试的时候,是感觉有些神奇的,我用我的大白话翻译一下:如果那把文件指针的位置设置到超过文件本身存储的数据字节数组的长度呢,数组会被扩展,而不会抛错。
插入数据
以下代码参考自:RandomAccessFile类使用详解
如果直接在指定地位置写入数据,还是会出现覆盖的情况。我们需要做以下操作:
- 找到插入位置,把插入位置之后的内容暂时保存起来
- 在插入位置写入要插入的内容。
- 最后顺势写入刚才保存到临时文件中的内容。
/**
* 插入文件指定位置的指定内容
* @param filePath 文件路径
* @param pos 插入文件的指定位置
* @param insertContent 插入文件中的内容
* @throws IOException
*/
public static void insert(String filePath,long pos,String insertContent)throws IOException{
RandomAccessFile raf=null;
//创建临时文件
File tmp= File.createTempFile("tmp",null);
tmp.deleteOnExit();
try {
// 以读写的方式打开一个RandomAccessFile对象
raf = new RandomAccessFile(new File(filePath), "rw");
//创建一个临时文件来保存插入点后的数据
FileOutputStream fileOutputStream = new FileOutputStream(tmp);
FileInputStream fileInputStream = new FileInputStream(tmp);
//把文件记录指针定位到pos位置
raf.seek(pos);
//------下面代码将插入点后的内容读入临时文件中保存-----
byte[] bbuf = new byte[64];
//用于保存实际读取的字节数据
int hasRead = 0;
//使用循环读取插入点后的数据
while ((hasRead = raf.read(bbuf)) != -1) {
//将读取的内容写入临时文件
fileOutputStream.write(bbuf, 0, hasRead);
}
//-----下面代码用于插入内容 -----
//把文件记录指针重新定位到pos位置
raf.seek(pos);
//追加需要插入的内容
raf.write(insertContent.getBytes());
//追加临时文件中的内容
while ((hasRead = fileInputStream.read(bbuf)) != -1) {
//将读取的内容写入临时文件
raf.write(bbuf, 0, hasRead);
}
}catch (Exception e){
throw e;
}
}
参考资料:
《Java编程思想》、《Java程序语言设计》
RandomAccessFile类使用详解

 浙公网安备 33010602011771号
浙公网安备 33010602011771号