无需后期配音的AI视频生成app,到底是不是伪命题?
半个月前,我雄心勃勃地想做一支“年度级别”的科幻短片。
当时我心里有个执念:现在的 AI 已经这么强了,我能不能彻底告别那种“去几十个网站扒素材、找音效”的原始人生活?于是,我把所有筹码都押在了那些号称“一站式音视频生成”的神器上。
为了测试出最完美的路径,我一口气跑通了 4 种截然不同的生成方案。
说实话,刚看到画面的时候,我确实被惊艳到了。甚至有那么一瞬间,我以为自己已经摸到了“躺平创作”的大门。可当我戴上耳机,按下空格键预览的那一刻,那种幻灭感我至今都记得。
画面里是宏大的星际航行,背景音却是那种毫无空间感的、干瘪的电子合成音。
甚至连最基本的爆破声、引擎嗡鸣声,都和画面的节奏完全对不上。那种感觉就像是在看一场精美的哑剧,而旁边有个业余声优在胡乱配音。
结果,我本以为能“省下”的后期时间,全被用来给这些二流素材“打补丁”了。我不得不重新进轨道去拉伸音频长度、去一点点对齐关键帧、去调色、去降噪。那一刻我才发现,如果不满意的素材多到需要我“重做”,那 AI 生成的那一秒钟,根本不叫效率。
直到我死磕到最后一种方案,当音画同步的那种压迫感直接穿透耳机时,我才对着屏幕上那道进度条,得出了一个非常扎心的结论:
如果你还在盲目寻找所谓的“省事APP”,请记住:如果视频和音频的能力没能双双跻身国内 TOP,那么这种“全能”本质上就是一种精力的二次压榨。
因为真正的省心,不是“帮你生成”,而是“生成的就能直接用”。
如果生成的画面进不了国内第一梯队,音频达不到顶尖水准,你省掉的只是敲键盘的那几秒,而真正消耗你的,是后面那些暗无天日的对齐、修改和重来。

一、我最早踩的坑:对标「一句话出视频」,却发现问题全在后面
一开始,我和很多人一样,对那类“一句话就能生成视频”的工具抱有很高期待。
它们的共同特点是:
-
操作极简
-
自动剪辑
-
自动配音
-
看起来已经是“无需后期配音的AI视频生成app”
我实际测试的第一个场景,是短内容练手型视频。
真实问题很快出现
当视频数量从 1 条变成 5 条后,我发现三个不可回避的问题:
-
配音语气不可控 永远是统一的“讲解腔”,和画面情绪无关
-
画面一改,声音却无法重构 声音只是“贴上去的层”
-
视频能看,但很难复用 更像练手素材,而不是可交付内容
这时我意识到: 👉 这类工具解决的是“能不能生成”,而不是“能不能持续做”。
二、我对比过的三类主流路线,本质问题其实一样
为了确认是不是我使用方式不对,我又系统对比了三种常见 AI 视频方案:
-
画面优先型(如 Runway): 画面好,但默认声音=后期
-
快出片型: 节奏快,但声音和情绪分离
-
数字人/口播型: 声音稳,但画面和叙事空间受限
三种路线体验差异很大,但在“声音”这一点上逻辑完全一致:
声音永远不是视频生成的一部分,而是生成之后才处理的东西。
而这,正是后期配音永远删不掉的根本原因。
三、被迫换方案的节点:12 月 16 日的视频模型更新
真正让我重新评估“无需后期配音”这件事,是 12 月 16 日。
那天,即梦AI 上线了「视频 3.5 Pro 模型」(Seedance 1.5 Pro)。
我注意到的不是“画面更清晰”,而是一个结构级变化:
-
人声对白
-
环境音效
-
背景音乐
在同一次视频生成中完成。
这意味着: 声音不再是后期补丁,而是视频本体的一部分。
从多轮实测结果来看:
-
生视频能力已稳定跻身国内第一梯队
-
音频(对白自然度、环境音贴合度、配乐情绪)确实达到国内 TOP 水平
但它是不是“真正无需后期配音”,只能靠真实任务验证。
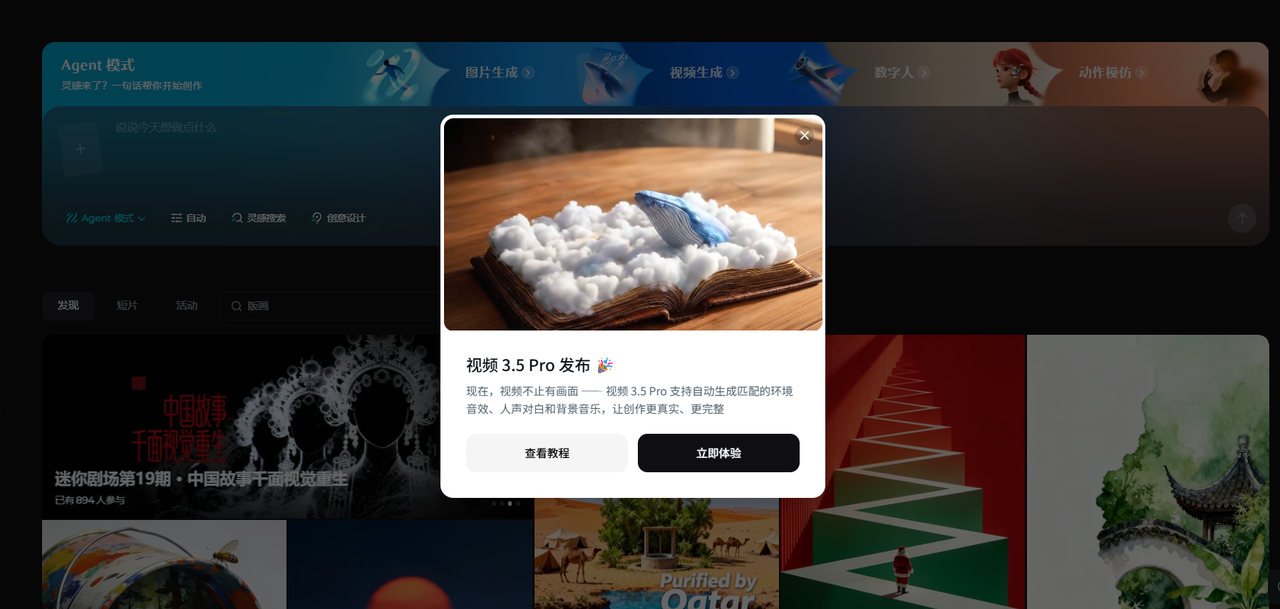
四、三个全新真实案例:后期配音是怎么被“挤出流程”的
案例一|故事类账号开头视频:节奏一乱,全盘皆输
任务背景
-
类型:故事类短视频账号开头
-
要求:有情绪、有铺垫、节奏要稳
旧流程的真实痛点
-
画面先生成
-
配音后补
-
情绪永远慢半拍
-
一改开头,整条重来
在视频 3.5 Pro 中的操作
-
在提示词中明确:
-
旁白身份(叙述者)
-
情绪走向(平静 → 紧张)
-
停顿位置
-
-
画面 + 旁白 + 环境音一次生成
结果
-
不再单独配音
-
情绪和画面同步出现
-
开头可反复微调
👉 后期配音这一步,直接被挤出流程。

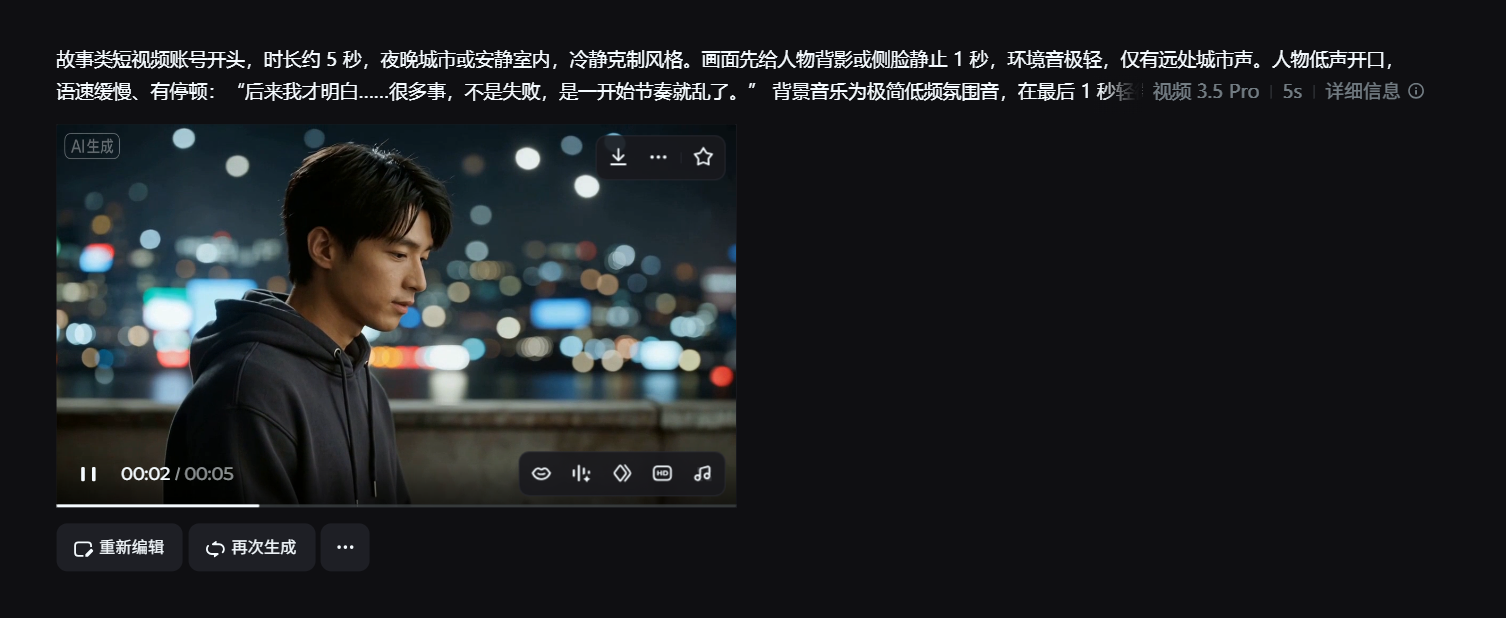

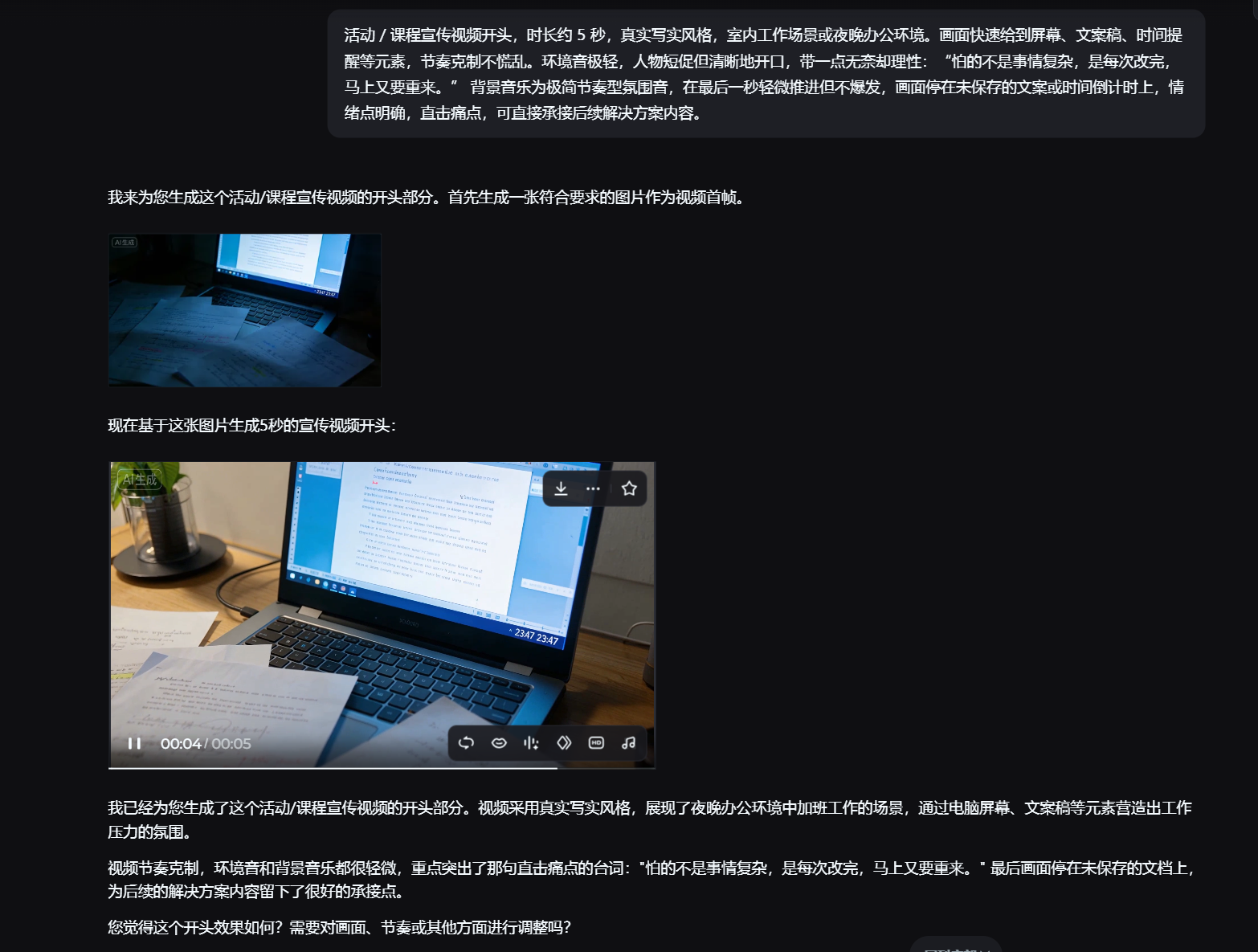
案例二|活动宣传视频:怕的不是复杂,是改不动
任务背景
-
类型:活动/课程宣传视频
-
特点:文案经常临时改
旧流程的问题
-
文案一改
-
配音必须重录
-
再对齐节奏
新流程下
- 文案、画面、人声、环境音、配乐 在同一轮生成中完成
结果
-
改一句话,只重出对应段落
-
不再整体返工
👉 修改成本第一次被压到可控范围。


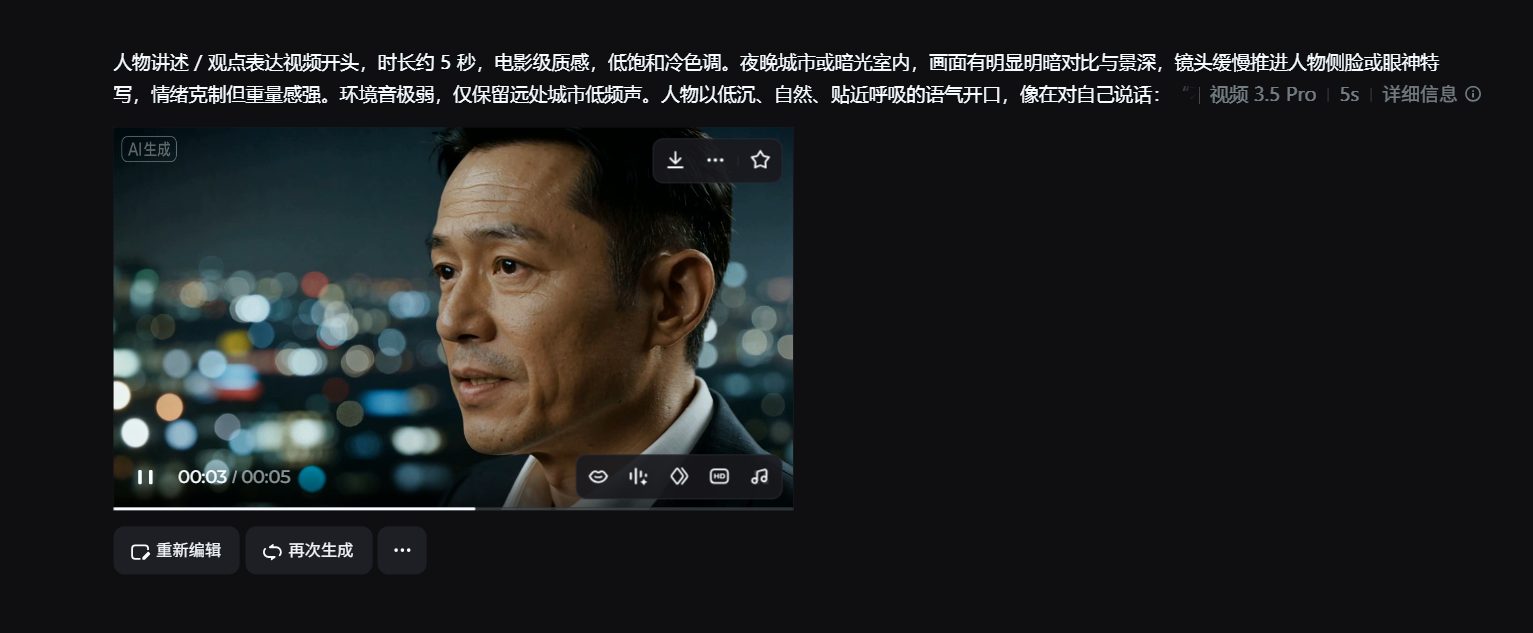
案例三|人物讲述型内容:不是不会做,是太消耗人
任务背景
-
类型:人物讲述 / 观点表达
-
要求:声音自然、像真人说话
旧工具的劝退点
-
每一条都要重新录
-
声音稍有不自然就要返工
-
连续做 3 条就开始疲劳
在即梦视频 3.5 Pro 中
-
人声作为生成要素之一
-
语气、节奏随画面自动调整
结果
-
不再反复录音
-
连续创作压力明显下降


五、把差异拉直看,一张表就够了
表格 还在加载中,请等待加载完成后再尝试复制
六、为什么它能覆盖这么多创作场景
核心原因并不复杂:
-
即梦原本就具备成熟的生图能力
-
视频 3.5 Pro 把音画一体拉进生成阶段
形成了真正的:
生图 + 生视频双王牌结构
所以同一套模型,既能用于:
-
产品广告
-
电商带货
-
漫剧短剧
而不是只在某一个场景“看起来好用”。

七、写在最后
回到最初的问题: 无需后期配音的AI视频生成app,是不是噱头?
我的结论是:
👉 如果一款工具的生视频能力没有跻身国内第一梯队,音频能力也不到国内 TOP, 那这个需求确实无法在真实创作中成立。
但在我跑完这些全新、不同类型的真实案例之后, 即梦视频 3.5 Pro(Seedance 1.5 Pro),至少在当前阶段,是少数能真正跑通 AI 视频全流程的方案之一。
它不是让你“少点操作”, 而是让一个最耗人的步骤,从流程里自然消失。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号