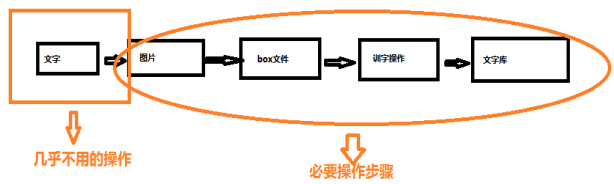
tesseract图像识别训练
1,项目背景介绍
该项目是一个监控类型的项目,其实有通过摄像头识别设备上液晶屏显示的温度,有A、B、C三类温度轮流在液晶屏上展示。
如图所示:

为了保证识别准确进行切片处理


再处理一下
img = img1.convert("L")

# 再处理一下
def img_to_binaryzation(img, threshold):
img = img.convert("L")
# 用设定的阈值建议一个映射表
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
# 通过映射表将图片转为二值图
img = img.point(table, "1")
return img
img = img_to_binaryzation(img1, 130)
img

用python做一个批量处理,把所有的从摄像头拿到的图片做一个切片

2,环境搭建
2.1 tesserac图像识别工具
2.1.1

- Mac
brew install tesseract-lang
2.1.2设置环境变量
# 添加进环境变量不写
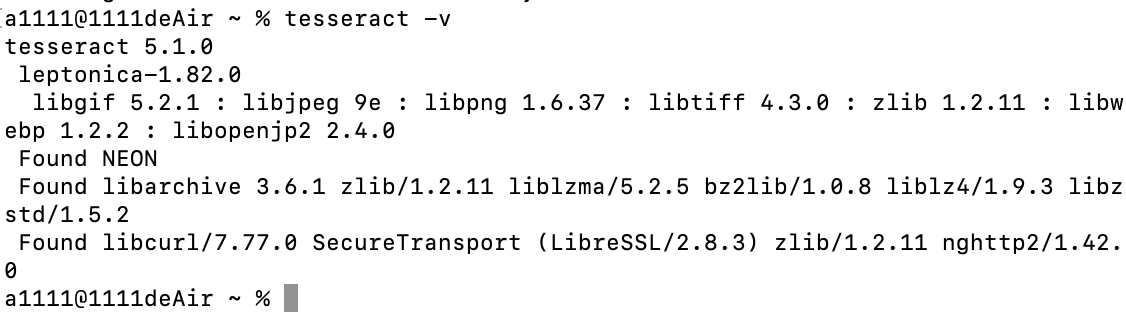
tesseract -v
# 出现上图中即可视作安装成功
2.2 jTessBoxEditor图像识别训练工具
https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
无需安装,直接解压
但是使用jTessBoxEditor需要先安装java8。
2.3 Java8
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
3 简单使用说明
3.1 tesseract
3.1.1 tesseract简单使用
新建一个文件夹,选择一张示例图片。
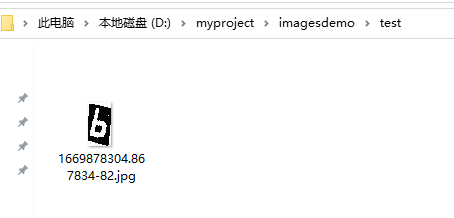
tesseract 1669878304.867834-82.jpg 166 -l num --psm 10

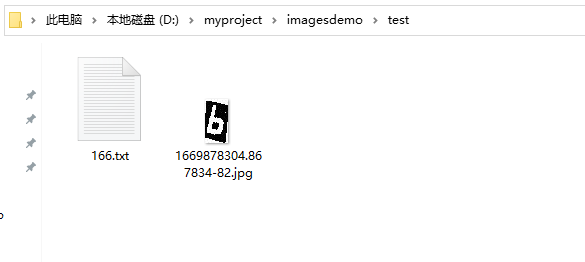
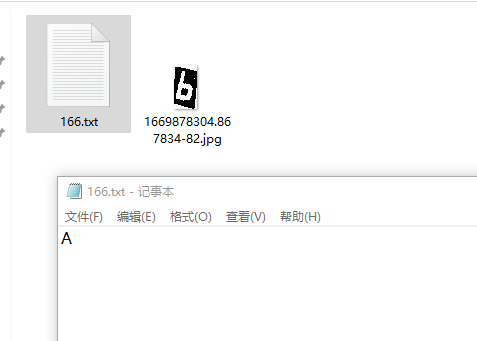
Tesseract 命令行前面的两个是识别的图片,以及识别输出的文件名,文件名符合变量命名规范即可。
-l num 其中num是自定义的语言,只要该语言在tessdata文件夹里面有对应的.traineddata文件就可以用,训练语言主要也是为了生成这个文件
--psm 10 以整张图片视作一个文字进行识别
Tesseract 命令行参数最重要的三个是 -l, --oem, --psm。
-l:控制输入文本的语言,用 eng 表示英文(默认语言),用 chi_sim 表示中文简体,用 chi_tra 表示中文繁体。
--oem:OCR Engine modes,Tesseract 有两个OCR引擎,使用 -oem 选择算法类型,有四种操作模式可供选择。
3.1.1 jTessBoxEditor简单使用
jTessBoxEditor使用必须安装java8
点击任意一个即可
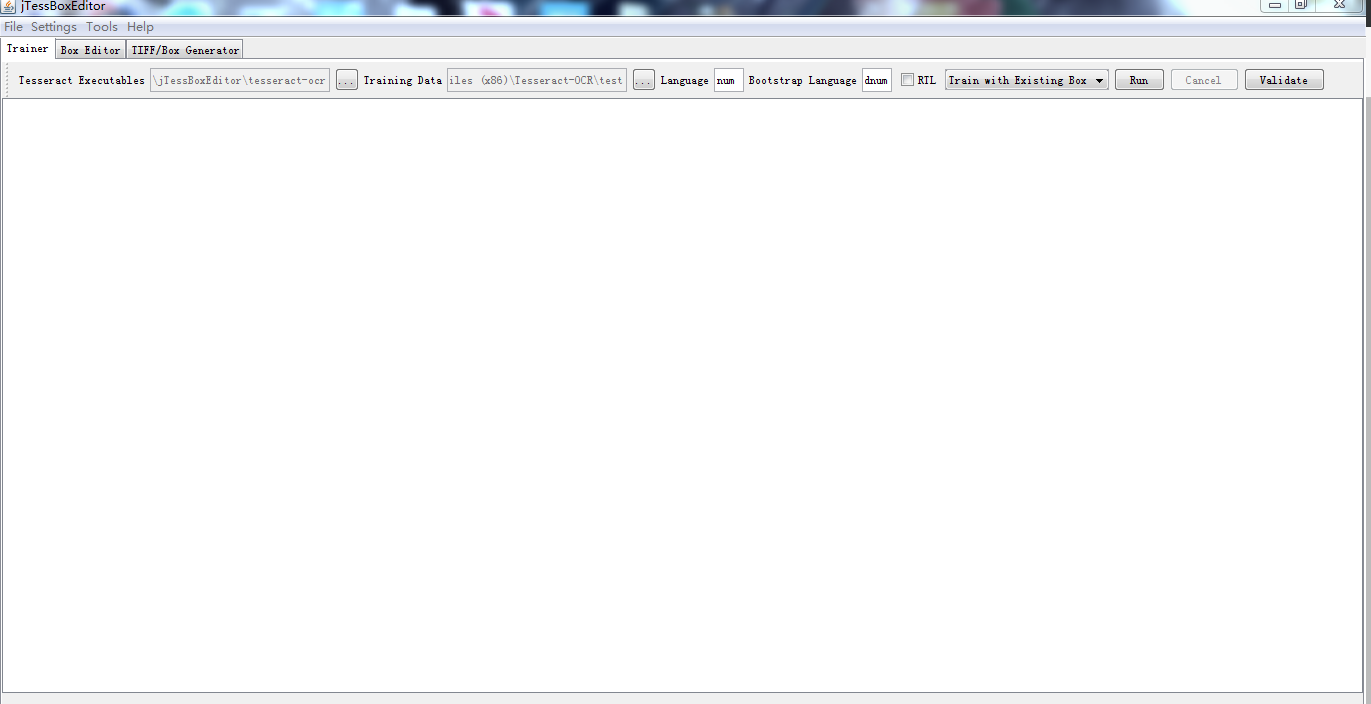
使用步骤
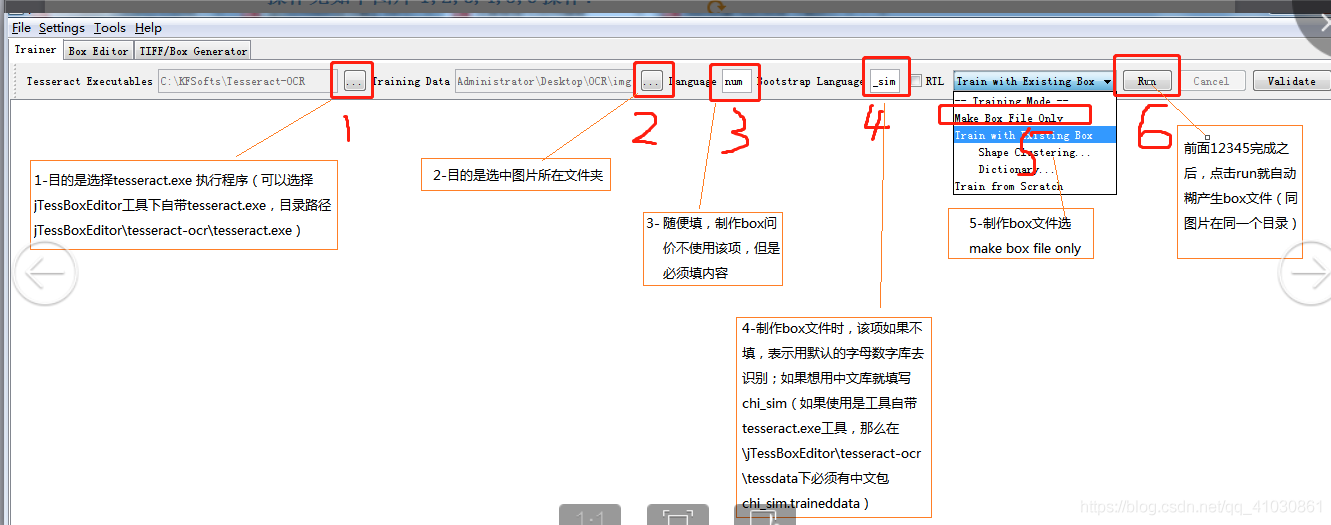
在实际训练中使用起来并不好用,不如使用命令行的形式
4简单训练一次
4.1 合并样本文件
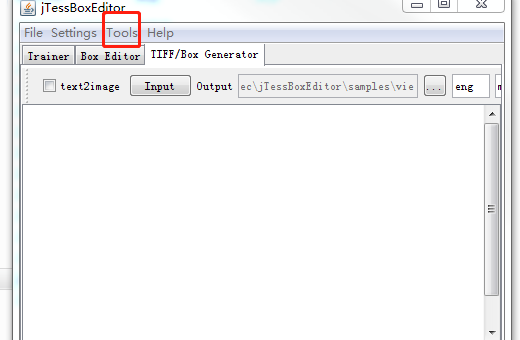
jTessBoxEditor ---> Tiils --->Merge TIFF
# 合并的样本文件格式不限,合并结果必须是tif或者tiff格式
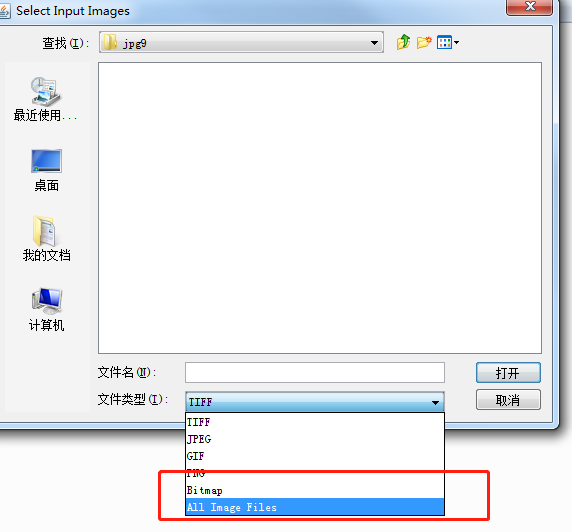
选择文件类型----> 全部类型
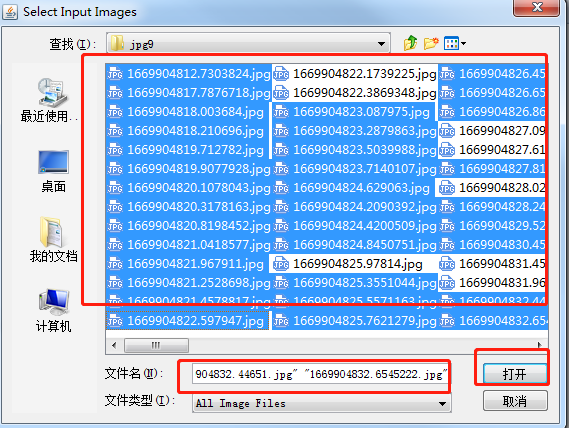
Ctrl + 鼠标左键 尽可能多的多选择样本文件,点击打开
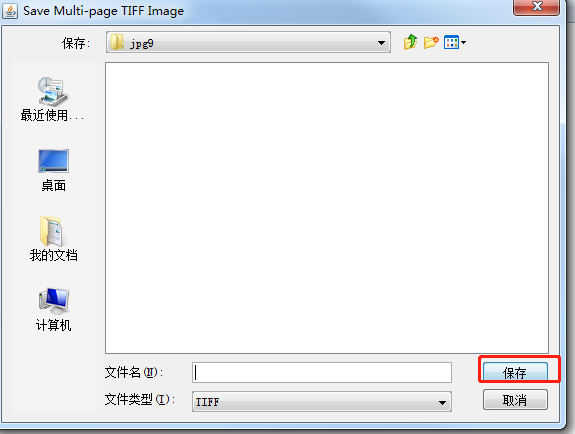
还在当前窗口, 文件名称写num.font.exp0.tif,点击保存
4.2 生成box文件
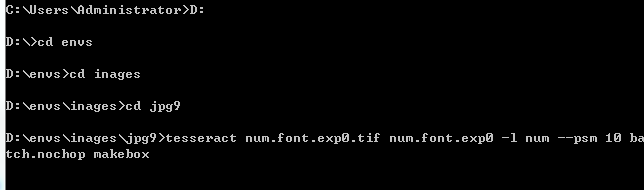
使用cmd切换到样本文件目录下
tesseract num.font.exp0.tif num.font.exp0 -l num --psm 10 batch.nochop makebox
这是在上一次的训练的基础上再次进行训练
tesseract num.font.exp0.tif num.font.exp0 batch.nochop makebox
也可以重新训练,或者在其他语言的基础上进行训练
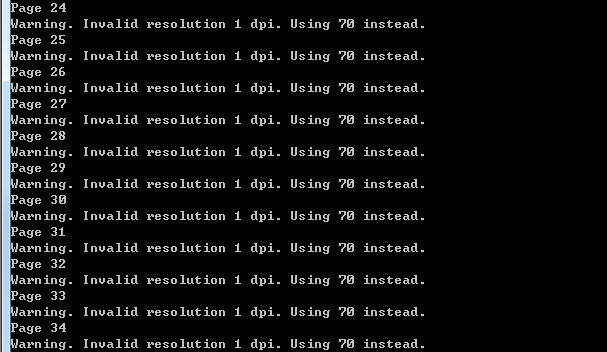
自动生成了box文件
4.3 修改识别结果
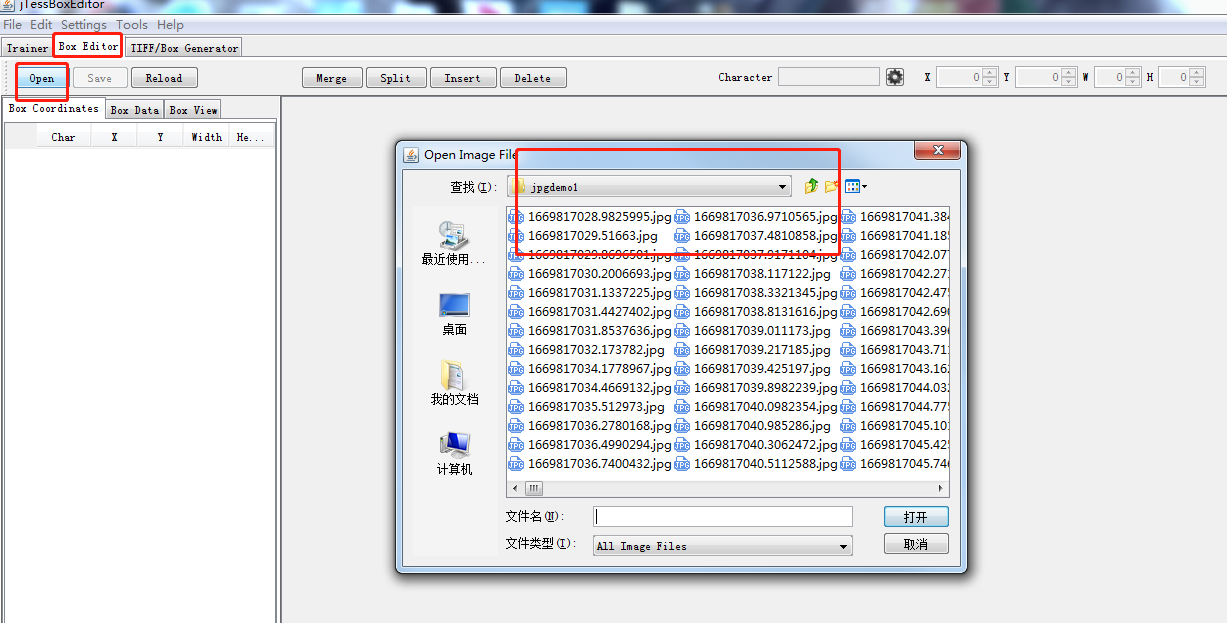
使用jTessBoxEditor ---> Box Editor ---> open 打开num.font.exp0.tif,会自动关联到box文件
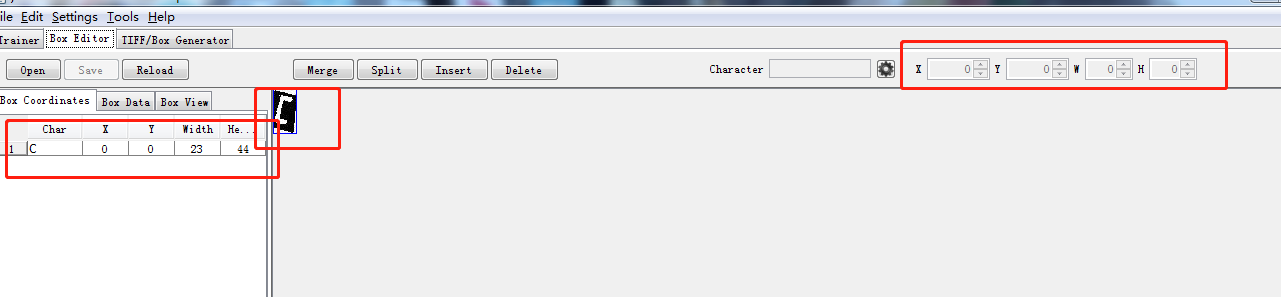
这是正常打开的box文件,右边是坐标轴,以整张图片进行识别基本不需要修改,左边的char需要根据实际图片内容进行修改。
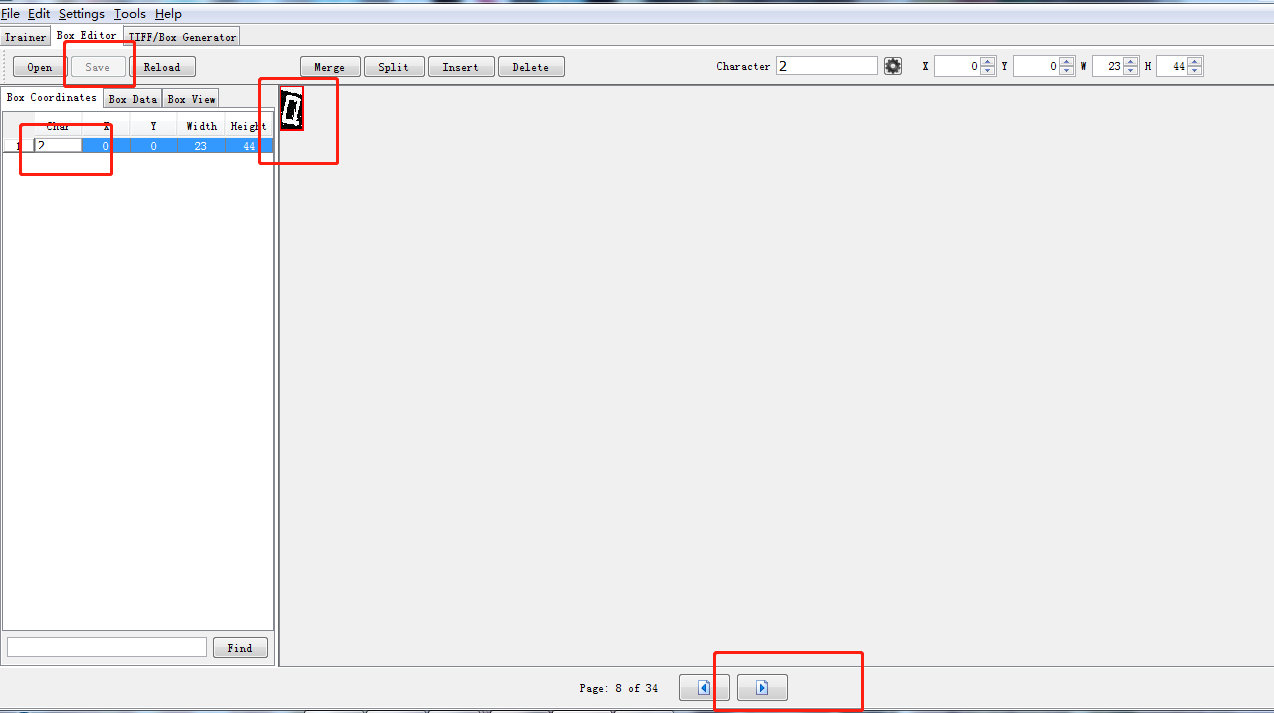
如这张图片, 2需要修改为0, 修改完成后点击save保存一下,然后切换下一张。
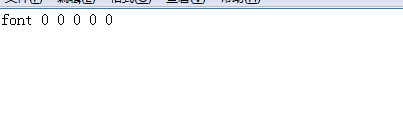
4.3 手动创建font_properties文件
先创建font_properties.txt,文件里面写font 0 0 0 0 0 然后去掉txt后缀
font 0 0 0 0 0
其中font 与 num.font.exp0.tif中font对应,如果num.font.exp0.tif中改了,font也要改。
4.3 制作批量操作脚本
先手动创建do.txt文件,
echo Run Tesseract for Training..
tesseract.exe num.font.exp0.tif num.font.exp0 -l num --psm 10 nobatch box.train
echo Compute the Character Set..
unicharset_extractor.exe num.font.exp0.box
mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp0.tr
echo Clustering..
cntraining.exe num.font.exp0.tr
echo Rename Files..
rename normproto num.normproto
rename inttemp num.inttemp
rename pffmtable num.pffmtable
rename shapetable num.shapetable
echo Create Tessdata..
combine_tessdata.exe num.
echo. & pause
也可以手动一行行输入命令,操作上会比较繁琐。
其中tesseract.exe num.font.exp0.tif num.font.exp0 -l num --psm 10 nobatch box.train 根据实际情况是否携带参数
如果之前有训练文件一定要在参数中加进去,不然新训练的结果会误差极大
unicharset、mftraining,可以使用多个box文件,比如unicharset_extractor.exe num.font.exp0.box num.font.exp1.box等,只要后面统一修改即可,但是之前的必须分开
# 示例:
tesseract.exe num.font.exp0.tif num.font.exp0 -l num --psm 10 nobatch box.train
tesseract.exe num.font.exp1.tif num.font.exp1 -l num --psm 10 nobatch box.train
unicharset_extractor.exe num.font.exp0.box num.font.exp1.box
mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp0.tr num.font.exp1.tr
cntraining.exe num.font.exp0.tr num.font.exp1.tr
4.4,生成最终的traineddata文件
找到Tesseract中的tessdata文件夹替换即可使用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号