

利用接口识别验证码实现网站登录
利用接口识别验证码实现网站登录
一、背景
一些网站的登录流程中会设置各种验证码,本文将介绍如何通过请求验证码地址并进行识别,再将识别结果作为参数请求登录地址以实现自动登录。本文以图鉴网站为例,详细讲解整个过程。
我们现在需要使用的接口网站是:图鉴。
我们测试的网站是: 图鉴
图鉴
http://www.ttshitu.com/
二、介绍图鉴
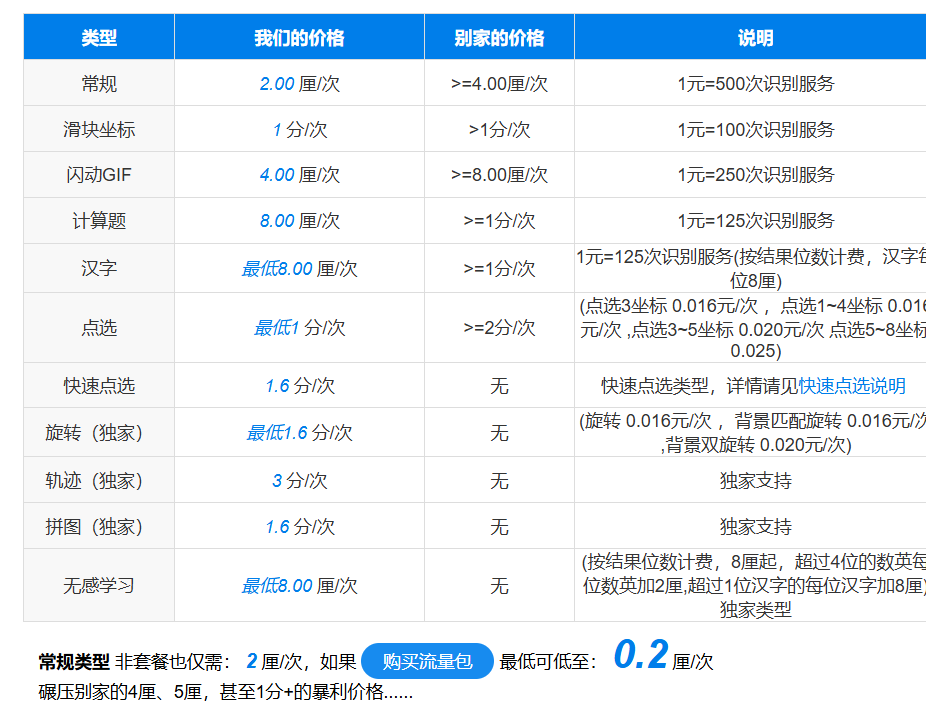
图鉴网站(http://www.ttshitu.com/)具有以下特点:
- 价格合理:提供具有竞争力的验证码识别服务价格。
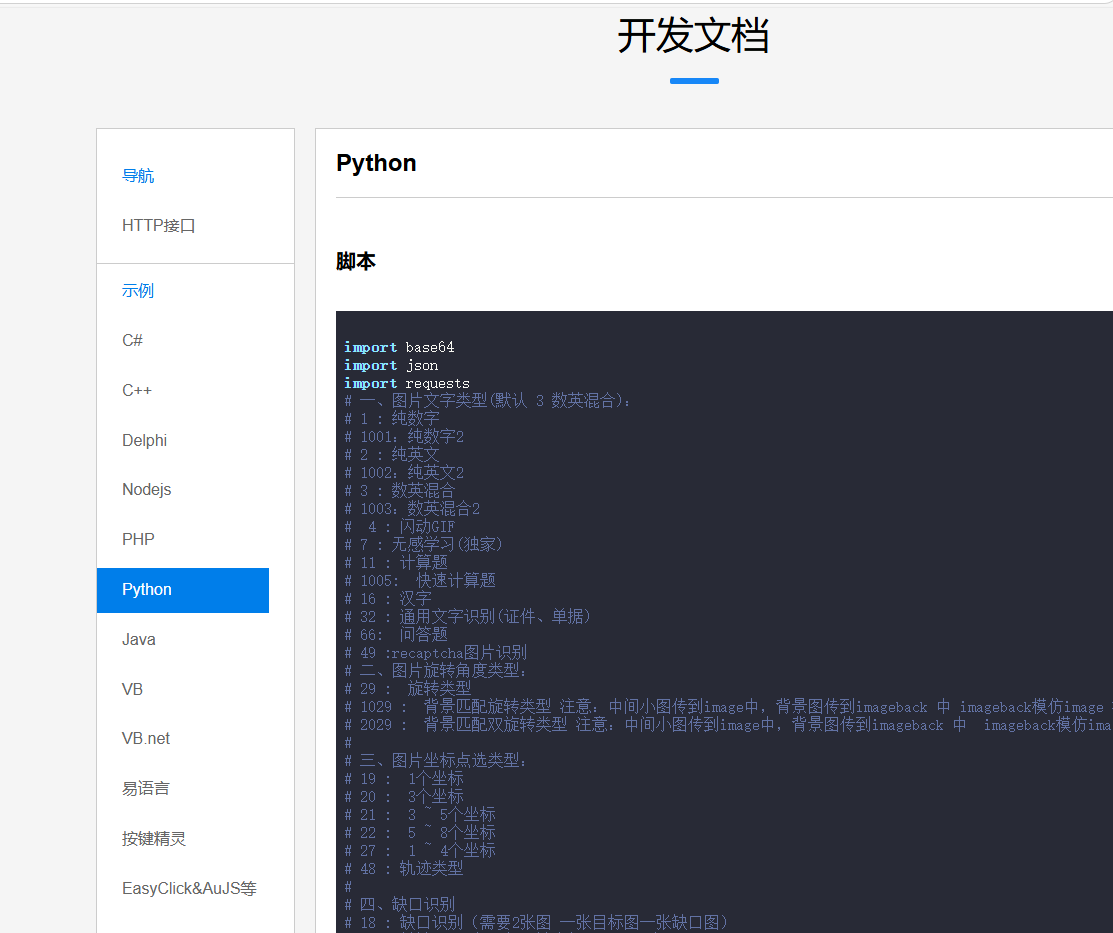
- 开发文档完善:全面的开发文档便于开发者快速上手。
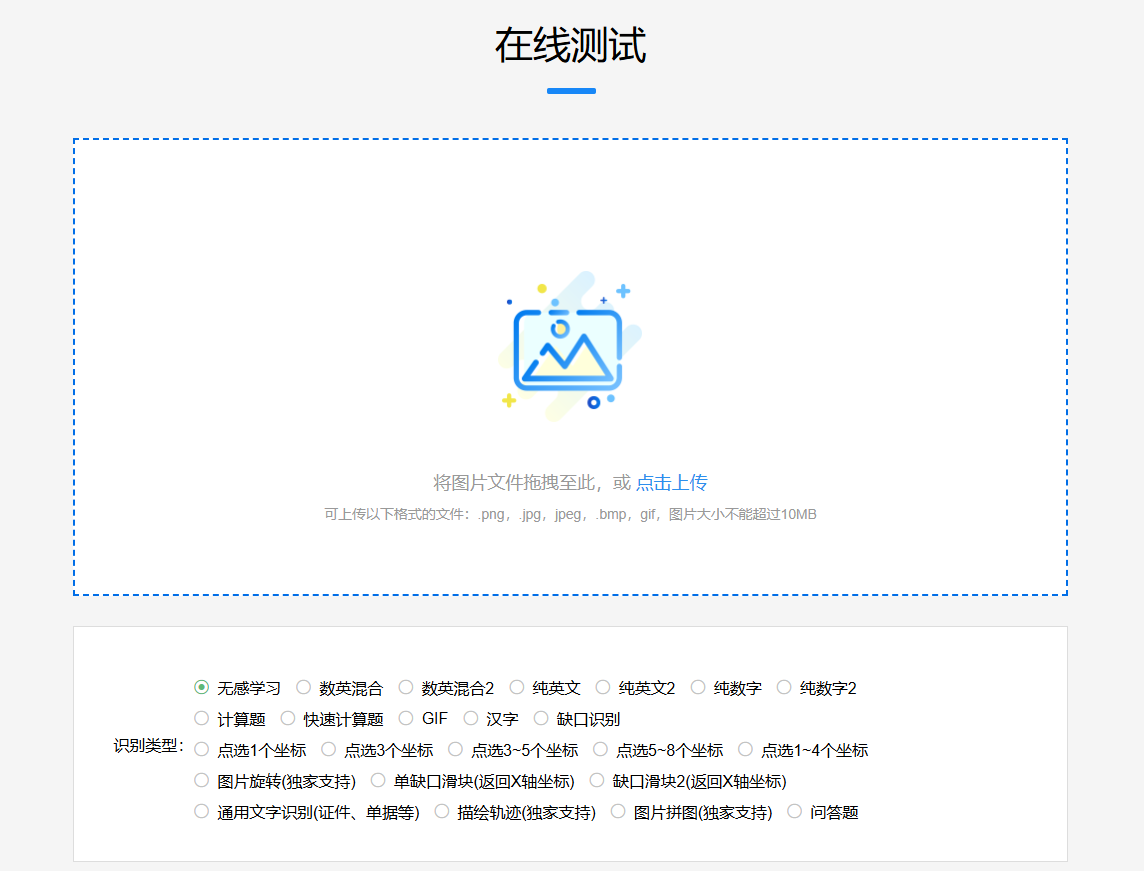
- 测试功能友好:如果不清楚验证码类型,可通过其测试网站进行识别。
三、登录图鉴
3.1 分析登录请求
当验证码输入错误时,需要重新请求登录接口。分析发现,我们需要处理captcha和imgid。
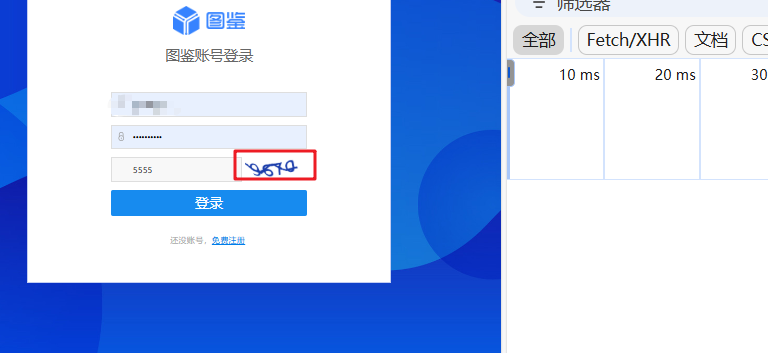
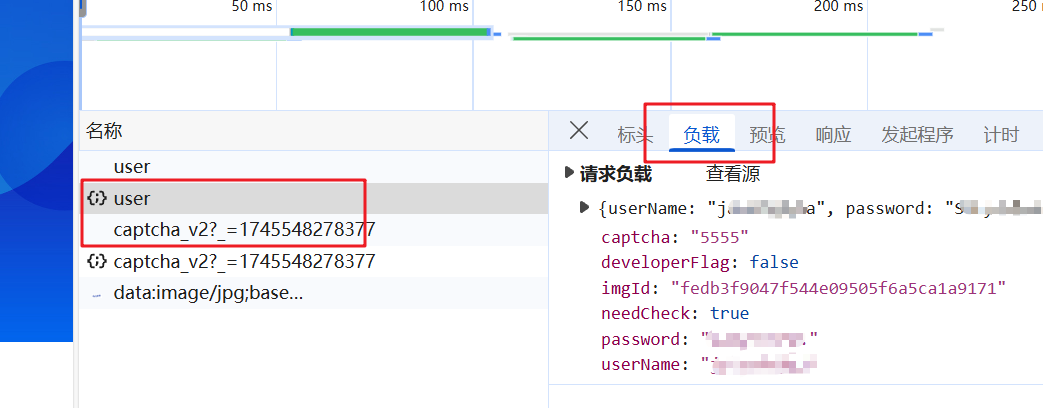
3.2 获取imgid参数
在登录请求中,有一个imgid参数。根据请求时间顺序推测可能是该参数,我们可以使用session请求来验证。
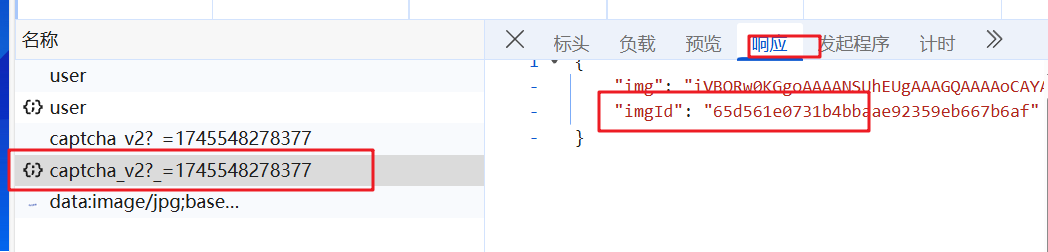
3.3 获取验证码
验证码的请求地址为https://admin.ttshitu.com/captcha_v2,使用毫秒级时间戳作为参数。以下是获取验证码并保存为本地图片的代码:
import json
import requests
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36 Edg/135.0.0.0',
}
import time
# 获取当前时间的毫秒级时间戳
timestamp = int(round(time.time() * 1000))
print(timestamp)
params = {
'_': timestamp,
}
response = requests.get('https://admin.ttshitu.com/captcha_v2', params=params, headers=headers)
data_ = json.loads(response.text)
img = data_['img']
imgid = data_['imgId']
import base64
base64_b = base64.b64decode(img)
with open('img.png', 'wb') as f:
f.write(base64_b)
这个验证码,我们需要进行base64解密
https://admin.ttshitu.com/captcha_v2
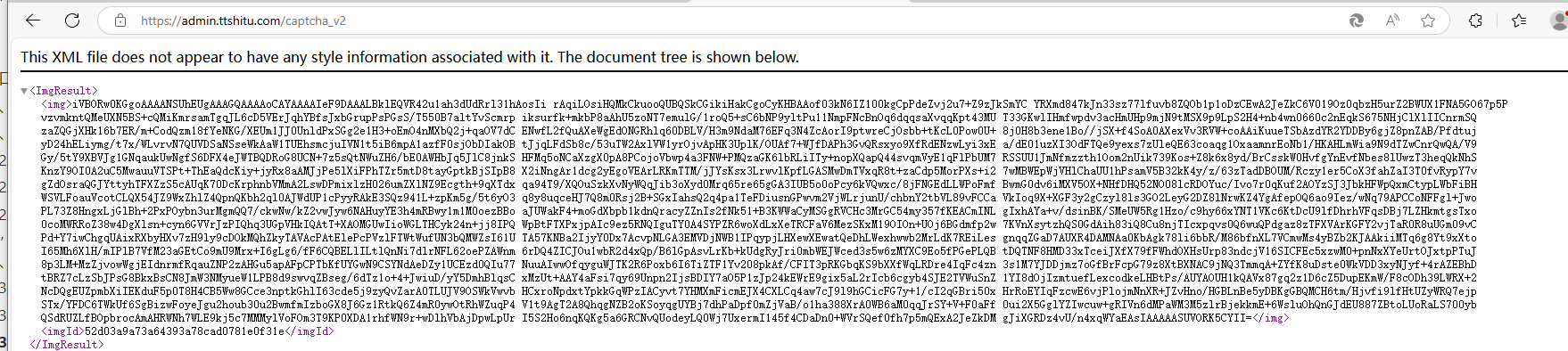
分析这个请求:
使用了一个时间磋
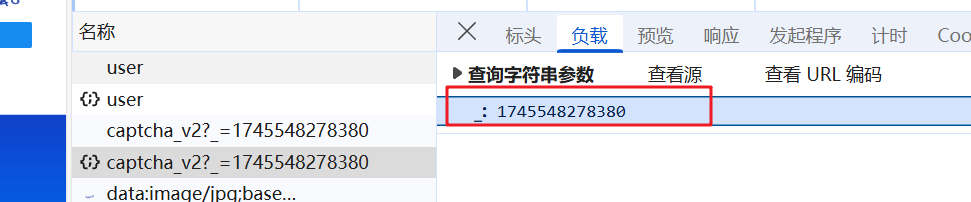
生产一个毫秒级别时间错
import time
# 获取当前时间的毫秒级时间戳
timestamp = int(round(time.time() * 1000))
print(timestamp)
base64 将编码转化为字节后写入 本地 ,方便之后验证码。这里有些网站直接返回 base64 的编码后数据,需要注意。是否包含一对引号。
{"img": "iVBORw0KGgoAAAAN"} 正常的。 直接转化为字典直接提取 img 数据。
有些网站 直接请求地址后获得的是包含引号的,需要注意
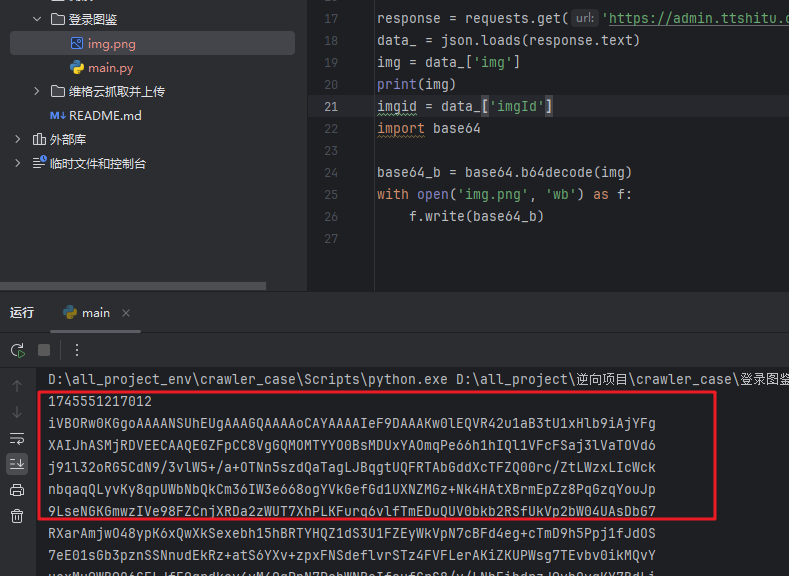
保存 验证码
import base64
base64_b = base64.b64decode(img)
with open('img.png', 'wb') as f:
f.write(base64_b)
3.4 验证码识别
以下是识别验证码的代码,通过调用图鉴的 API,传入图片路径、账号密码和验证码类型,返回识别结果:
import base64
import json
import requests
# 一、图片文字类型(默认 3 数英混合):
# 1 : 纯数字
# 1001:纯数字2
# 2 : 纯英文
# 1002:纯英文2
# 3 : 数英混合
# 1003:数英混合2
# 4 : 闪动GIF
# 7 : 无感学习(独家)
# 11 : 计算题
# 1005: 快速计算题
# 16 : 汉字
# 32 : 通用文字识别(证件、单据)
# 66: 问答题
# 49 :recaptcha图片识别
# 二、图片旋转角度类型:
# 29 : 旋转类型
# 1029 : 背景匹配旋转类型 注意:中间小图传到image中,背景图传到imageback 中 imageback模仿image 添加
# 2029 : 背景匹配双旋转类型 注意:中间小图传到image中,背景图传到imageback 中 imageback模仿image 添加
#
# 三、图片坐标点选类型:
# 19 : 1个坐标
# 20 : 3个坐标
# 21 : 3 ~ 5个坐标
# 22 : 5 ~ 8个坐标
# 27 : 1 ~ 4个坐标
# 48 : 轨迹类型
#
# 四、缺口识别
# 18 : 缺口识别(需要2张图 一张目标图一张缺口图)
# 33 : 单缺口识别(返回X轴坐标 只需要1张图)
# 34 : 缺口识别2(返回X轴坐标 只需要1张图)
# 五、拼图识别
# 53:拼图识别
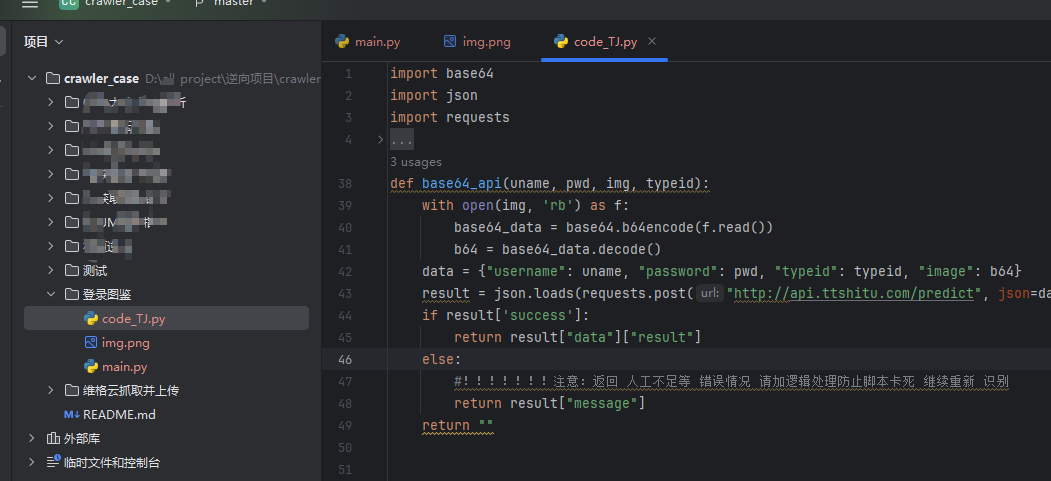
def base64_api(uname, pwd, img, typeid):
with open(img, 'rb') as f:
base64_data = base64.b64encode(f.read())
b64 = base64_data.decode()
data = {"username": uname, "password": pwd, "typeid": typeid, "image": b64}
result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text)
if result['success']:
return result["data"]["result"]
else:
#!!!!!!!注意:返回 人工不足等 错误情况 请加逻辑处理防止脚本卡死 继续重新 识别
return result["message"]
return ""
if __name__ == "__main__":
img_path = "C:/Users/Administrator/Desktop/file.jpg"
result = base64_api(uname='你的账号', pwd='你的密码', img=img_path, typeid=3)
print(result)
在文件导入后进行设置
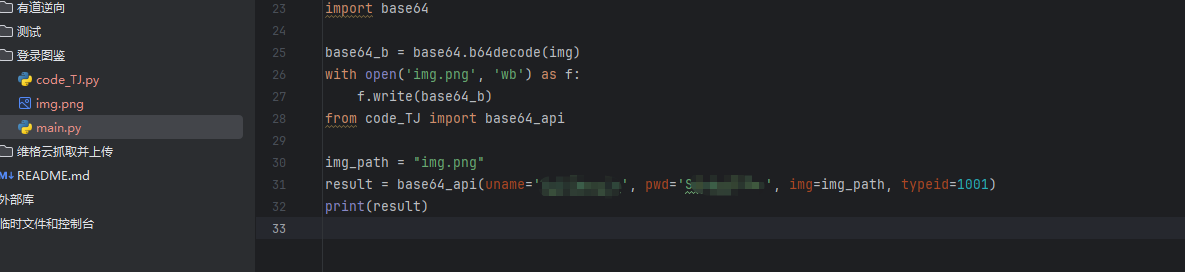
3.5 设置session 请求登录网站
使用session来保持登录状态,将验证码识别结果和获取到的imgid等参数组装成登录请求的 JSON 数据,发送 POST 请求进行登录。以下为完整代码:
import json
import requests
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36 Edg/135.0.0.0',
}
import time
# 获取当前时间的毫秒级时间戳
timestamp = int(round(time.time() * 1000))
print(timestamp)
params = {
'_': timestamp,
}
session = requests.Session()
response = session.get('https://admin.ttshitu.com/captcha_v2', params=params, headers=headers)
data_ = json.loads(response.text)
img = data_['img']
imgid = data_['imgId']
print(imgid)
import base64
base64_b = base64.b64decode(img)
with open('img.png', 'wb') as f:
f.write(base64_b)
from code_TJ import base64_api
img_path = "img.png"
result = base64_api(uname='1111', pwd='1111.', img=img_path, typeid=1001)
print(result)
json_data = {
'userName': '1111',
'password': '1111.',
'captcha': result ,
'imgId': imgid,
'developerFlag': False,
'needCheck': True,
}
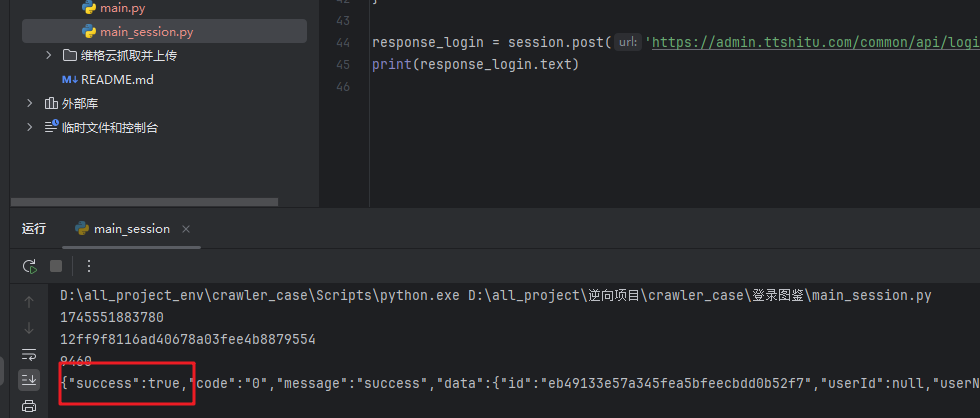
response_login = session.post('https://admin.ttshitu.com/common/api/login/user', headers=headers, json=json_data)
print(response_login.text)
登录请求
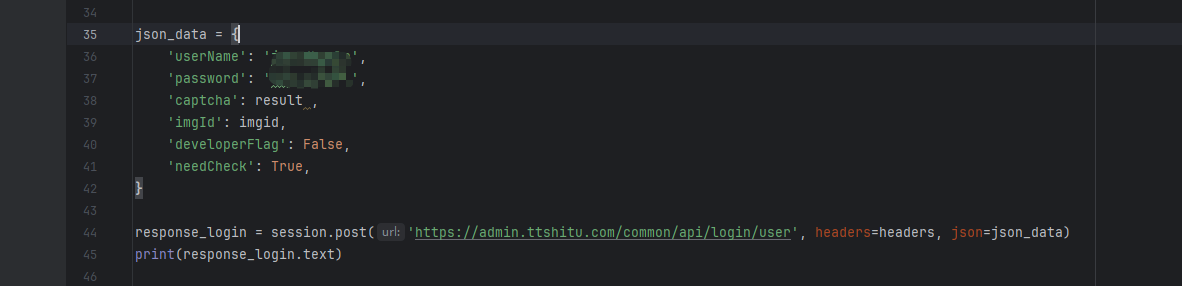
登录成功 ,之后就可以使用session 请求去请求其他数据了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号