
102302142罗伟钊第三次作业
作业①:
– 要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取。
1)代码内容:
SingleThreadImageDownloader.py
--------------------------------------------------
点击查看代码
import requests
from bs4 import BeautifulSoup
import os
import time
from urllib.parse import urljoin, urlparse
class SingleThreadImageDownloader:
def __init__(self, base_url, download_dir="images"):
self.base_url = base_url
self.download_dir = download_dir
self.session = requests.Session()
self.session.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
})
def create_download_directory(self):
"""创建下载目录"""
if not os.path.exists(self.download_dir):
os.makedirs(self.download_dir)
print(f"创建目录: {self.download_dir}")
def is_valid_image_url(self, url):
"""检查是否为有效的图片URL"""
if not url or url.startswith('data:'):
return False
# 检查文件扩展名
valid_extensions = ['.jpg', '.jpeg', '.png', '.gif', '.bmp', '.webp']
parsed_url = urlparse(url)
path = parsed_url.path.lower()
return any(path.endswith(ext) for ext in valid_extensions)
def download_image(self, img_url, filename):
"""下载单个图片"""
try:
response = self.session.get(img_url, stream=True, timeout=10)
response.raise_for_status()
filepath = os.path.join(self.download_dir, filename)
with open(filepath, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
if chunk:
f.write(chunk)
print(f"✓ 下载成功: {img_url} -> {filepath}")
return True
except Exception as e:
print(f"✗ 下载失败: {img_url} - 错误: {str(e)}")
return False
def extract_image_urls(self, url):
"""从网页中提取图片URL"""
try:
response = self.session.get(url, timeout=10)
response.raise_for_status()
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
img_tags = soup.find_all('img')
image_urls = []
for img in img_tags:
src = img.get('src') or img.get('data-src')
if src:
# 转换为绝对URL
full_url = urljoin(url, src)
if self.is_valid_image_url(full_url):
image_urls.append(full_url)
return list(set(image_urls)) # 去重
except Exception as e:
print(f"提取图片URL失败: {str(e)}")
return []
def run(self):
"""运行单线程下载"""
print("=" * 60)
print("开始单线程图片下载")
print("=" * 60)
self.create_download_directory()
image_urls = self.extract_image_urls(self.base_url)
print(f"找到 {len(image_urls)} 张图片")
print("-" * 60)
success_count = 0
start_time = time.time()
for i, img_url in enumerate(image_urls, 1):
# 生成文件名
filename = f"image_{i}_{hash(img_url) % 10000:04d}.jpg"
# 下载图片
if self.download_image(img_url, filename):
success_count += 1
end_time = time.time()
elapsed_time = end_time - start_time
print("-" * 60)
print(f"单线程下载完成!")
print(f"总图片数: {len(image_urls)}")
print(f"成功下载: {success_count}")
print(f"失败: {len(image_urls) - success_count}")
print(f"耗时: {elapsed_time:.2f} 秒")
print(f"图片保存位置: {os.path.abspath(self.download_dir)}")
return success_count
--------------------------------------------------
MultiThreadImageDownloader.py
--------------------------------------------------
点击查看代码
import threading
from concurrent.futures import ThreadPoolExecutor, as_completed
import queue
from SingleThreadImageDownloader import SingleThreadImageDownloader
import time
import os
class MultiThreadImageDownloader(SingleThreadImageDownloader):
def __init__(self, base_url, download_dir="images", max_workers=5):
super().__init__(base_url, download_dir)
self.max_workers = max_workers
self.downloaded_count = 0
self.lock = threading.Lock()
def download_image_thread(self, args):
"""多线程下载图片的包装函数"""
img_url, filename = args
result = self.download_image(img_url, filename)
with self.lock:
if result:
self.downloaded_count += 1
return result
def run(self):
"""运行多线程下载"""
print("=" * 60)
print("开始多线程图片下载")
print("=" * 60)
self.create_download_directory()
image_urls = self.extract_image_urls(self.base_url)
print(f"找到 {len(image_urls)} 张图片")
print(f"使用 {self.max_workers} 个线程")
print("-" * 60)
self.downloaded_count = 0
start_time = time.time()
# 准备任务参数
tasks = []
for i, img_url in enumerate(image_urls, 1):
filename = f"image_{i}_{hash(img_url) % 10000:04d}.jpg"
tasks.append((img_url, filename))
# 使用线程池执行下载任务
with ThreadPoolExecutor(max_workers=self.max_workers) as executor:
future_to_task = {
executor.submit(self.download_image_thread, task): task
for task in tasks
}
# 等待所有任务完成
for future in as_completed(future_to_task):
try:
future.result()
except Exception as e:
print(f"任务执行异常: {e}")
end_time = time.time()
elapsed_time = end_time - start_time
print("-" * 60)
print(f"多线程下载完成!")
print(f"总图片数: {len(image_urls)}")
print(f"成功下载: {self.downloaded_count}")
print(f"失败: {len(image_urls) - self.downloaded_count}")
print(f"耗时: {elapsed_time:.2f} 秒")
print(f"图片保存位置: {os.path.abspath(self.download_dir)}")
return self.downloaded_count
--------------------------------------------------
image_downloader.py
--------------------------------------------------
点击查看代码
from SingleThreadImageDownloader import SingleThreadImageDownloader
from MultiThreadImageDownloader import MultiThreadImageDownloader
def main():
# 目标网站
base_url = "http://www.weather.com.cn"
print("中国气象网图片爬虫")
print("目标网站:", base_url)
print()
# 单线程下载
single_downloader = SingleThreadImageDownloader(base_url, "images_single")
single_success = single_downloader.run()
print("\n" + "=" * 80 + "\n")
# 多线程下载
multi_downloader = MultiThreadImageDownloader(base_url, "images_multi", max_workers=5)
multi_success = multi_downloader.run()
print("\n" + "=" * 80)
print("下载总结:")
print(f"单线程: 成功下载 {single_success} 张图片")
print(f"多线程: 成功下载 {multi_success} 张图片")
print("=" * 80)
if __name__ == "__main__":
main()
--------------------------------------------------

多线程代码使用了线程池执行下载任务,系统不会为每张图片都创建一个新线程,具有复用性。
输出结果:
2)心得体会:
在单线程中,图片一定是从第1张下载到最后一张。但在多线程中,完成顺序是不确定的。
作业②:
– 要求:熟练掌握 scrapy中Item, Pipeline 数据的序列化输出方法; Scrapy+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
– 网站:东方财富网:https://www.eastmoney.com/
1)代码内容:
eastmoney.py
--------------------------------------------------
点击查看代码
import scrapy
import json
from stock_scrapy.items import StockItem
class EastmoneySpider(scrapy.Spider):
name = 'eastmoney'
allowed_domains = ['eastmoney.com']
# Base URL without the callback parameter to get pure JSON if possible,
# or we handle the jQuery wrapper.
# Removing 'cb' usually returns pure JSON.
base_url = "https://push2.eastmoney.com/api/qt/clist/get"
def start_requests(self):
# Crawl first 5 pages as an example
for page in range(1, 6):
params = {
'fid': 'f3',
'po': '1',
'pz': '20',
'pn': str(page),
'np': '1',
'fltt': '2',
'invt': '2',
'ut': 'fa5fd1943c7b386f172d6893dbfba10b',
'fs': 'm:0 t:6,m:0 t:80,m:1 t:2,m:1 t:23',
'fields': 'f12,f13,f14,f1,f2,f4,f3,f152,f5,f6,f7,f15,f18,f16,f17,f10,f8,f9,f23',
}
# Construct URL with parameters
import urllib.parse
url = f"{self.base_url}?{urllib.parse.urlencode(params)}"
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
try:
data = json.loads(response.text)
if data.get('data') and data['data'].get('diff'):
items = data['data']['diff']
# diff can be a list or a dict depending on the page/api version,
# usually list for this endpoint but let's handle both as in the reference code
if isinstance(items, dict):
items = items.values()
for item_data in items:
item = StockItem()
item['bStockNo'] = item_data.get('f12')
item['bStockName'] = item_data.get('f14')
item['latest_price'] = item_data.get('f2')
# Format percentage
f3 = item_data.get('f3')
item['change_percent'] = f"{f3}%" if f3 is not None else "-"
item['change_amount'] = item_data.get('f4')
# Format volume (万/亿) - keeping raw number or formatting?
# The prompt image shows "26.13万", "7.6亿".
# I will implement a helper to format it similar to the prompt.
item['volume'] = self.format_number(item_data.get('f5'))
item['turnover'] = self.format_number(item_data.get('f6'), is_currency=True)
item['amplitude'] = f"{item_data.get('f7')}%" if item_data.get('f7') is not None else "-"
item['high'] = item_data.get('f15')
item['low'] = item_data.get('f16')
item['open'] = item_data.get('f17')
item['prev_close'] = item_data.get('f18')
yield item
except json.JSONDecodeError:
self.logger.error(f"Failed to decode JSON from {response.url}")
def format_number(self, num, is_currency=False):
if num is None:
return "0"
try:
num = float(num)
if is_currency:
# Turnover usually in Yuan
if num > 100000000:
return f"{num/100000000:.2f}亿"
elif num > 10000:
return f"{num/10000:.2f}万"
return f"{num:.2f}"
else:
# Volume usually in Hands (100 shares) or just number
# The API returns volume in 'hands' usually for stocks?
# Or raw shares? f5 is usually volume in hands.
# Let's assume the API returns raw count or hands.
# Based on reference code: f"{x / 10000:.2f}万手"
if num > 10000:
return f"{num/10000:.2f}万"
return str(num)
except:
return str(num)
--------------------------------------------------
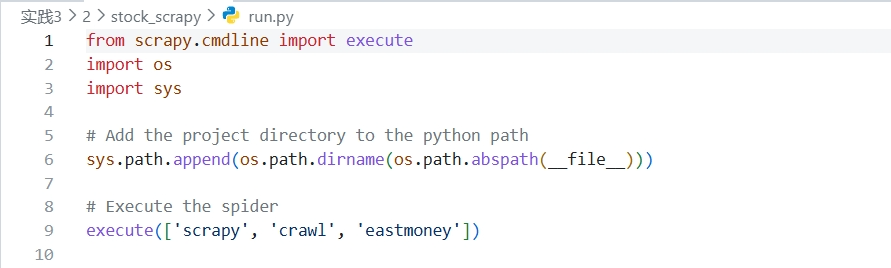
以上为run.py文件,这段代码是一个启动脚本,它的主要作用是通过运行一个 Python 文件来启动 Scrapy 爬虫。
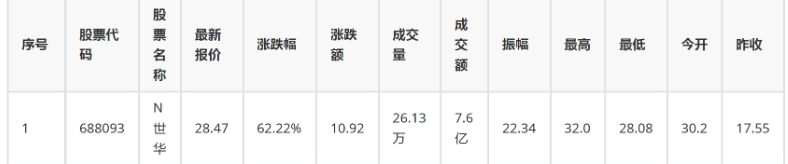
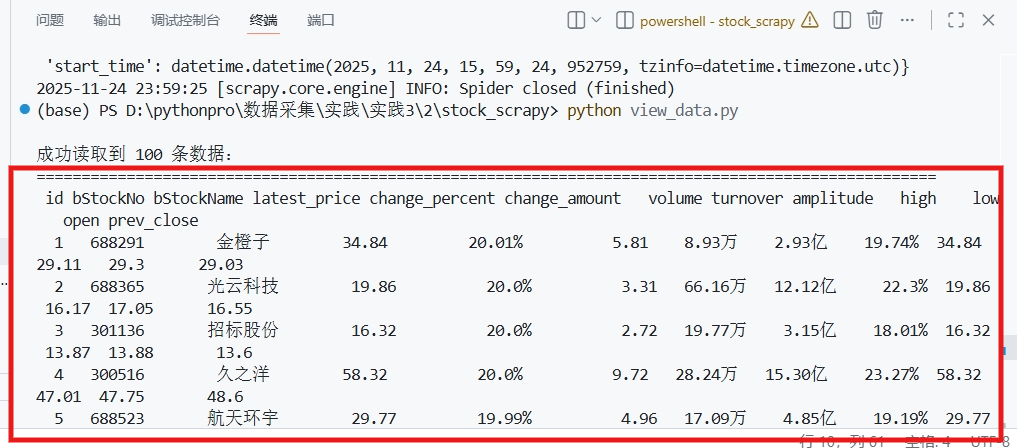
输出结果:
2)心得体会:
在本次针对东方财富网的股票数据采集实践中,我深入理解了 Scrapy 框架的运行机制,并重点掌握了从数据抓取到持久化存储的完整流程。
作业③:
– 要求::熟练掌握 scrapy中Item, Pipeline 数据的序列化输出方法; 采用 Scrapy 框架、XPath 以及 MySQL 数据库存储技术路线,对外汇网站进行爬取操作。
– 候选网站:招商银行网: https://www.boc.cn/sourcedb/whpj/
1)代码内容:
boc.py
--------------------------------------------------
点击查看代码
import scrapy
from currency_scrapy.items import CurrencyItem
class BocSpider(scrapy.Spider):
name = 'boc'
allowed_domains = ['boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
# The table is usually inside a div with class 'publish' or just the main table
# Let's try to find the table rows.
# Structure: <table> <tr> <th>...</th> </tr> <tr> <td>...</td> </tr> ... </table>
# Using XPath to select rows, skipping the header row (usually the first one)
# The table is often the second table in the publish div or just identified by structure.
# Let's look for rows that have <td> elements.
rows = response.xpath('//div[@class="publish"]//table//tr')
# If the class "publish" is not found, try a more generic table search
if not rows:
rows = response.xpath('//table//tr')
for row in rows:
# Check if it's a data row (has td)
tds = row.xpath('./td')
if len(tds) < 6:
continue
item = CurrencyItem()
# Extract text and strip whitespace
# Column 1: Currency Name
item['currency'] = tds[0].xpath('string(.)').get().strip()
# Column 2: TBP (现汇买入价)
item['tbp'] = tds[1].xpath('string(.)').get().strip()
# Column 3: CBP (现钞买入价)
item['cbp'] = tds[2].xpath('string(.)').get().strip()
# Column 4: TSP (现汇卖出价)
item['tsp'] = tds[3].xpath('string(.)').get().strip()
# Column 5: CSP (现钞卖出价)
item['csp'] = tds[4].xpath('string(.)').get().strip()
# Column 7 or 8: Time
# Usually: Currency, TBP, CBP, TSP, CSP, Middle, PubDate, PubTime
# Let's check the number of columns.
# If 8 columns: 0=Name, 1=TBP, 2=CBP, 3=TSP, 4=CSP, 5=Middle, 6=Date, 7=Time
if len(tds) >= 8:
pub_time = tds[7].xpath('string(.)').get().strip()
# Sometimes we might want date too, but the requirement says "Time" and shows "11:27:14"
item['time'] = pub_time
elif len(tds) >= 7:
# Maybe combined or different structure
item['time'] = tds[-1].xpath('string(.)').get().strip()
else:
item['time'] = ""
# Filter out empty rows or header rows that might have slipped through
if item['currency'] and item['currency'] != "货币名称":
yield item
--------------------------------------------------
以上为可视化的代码,对数据库的内容进行输出
输出结果:

2)心得体会:
在本次针对中国银行外汇牌价数据的采集实践中,我深刻体会到了 Scrapy 框架结合 XPath 解析的强大之处。通过使用 XPath 选择器,我能够精准地定位到表格中的每一行数据,并利用相对路径提取出货币名称、现汇买入价、现钞买入价等具体字段,这让我意识到在处理非结构化网页数据时,掌握 XPath 语法是多么重要且高效。
代码路径:https://gitee.com/sui123feng/20251015/tree/master/102302142罗伟钊_实践3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号