

102302142罗伟钊第一次作业
1. 作业①:
**1)、核心代码与输出 **
o 要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。

代码是一个大学排名数据爬虫,主要思路是通过网络请求获取软科2020年中国大学排名页面,然后使用BeautifulSoup解析HTML内容,提取出各个大学的排名、名称、所在省市、学校类型和总分等信息。程序将提取的数据进行整合,最后以整齐的表格形式在控制台输出展示。
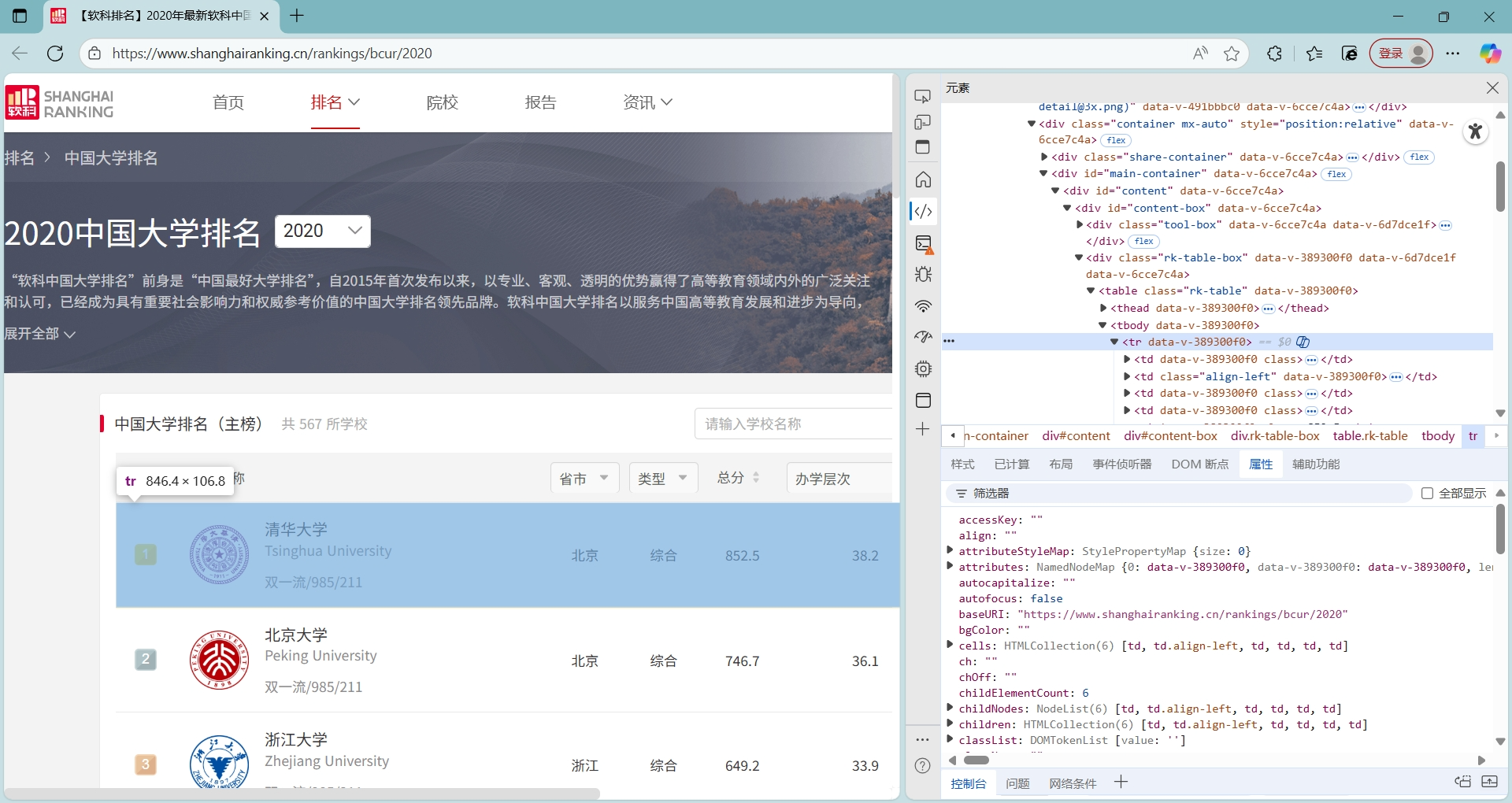
通过F12审查元素,再通过标签匹配相关的属性
###########-----------------------------------------------------------------------------
点击查看代码
def unversityList(self, html_content):
soup = BeautifulSoup(html_content, 'html.parser')
soup_tr=soup.find_all('tr', attrs={'data-v-389300f0': ''})
ranks,names,provinces,types,scores = [],[],[],[],[]
for div in soup.find_all("div",class_="ranking" ):
rank = div.get_text(strip=True)
ranks.append(rank)
for span in soup.find_all("span", class_="name-cn"):
name = span.get_text(strip=True)
names.append(name)
for tr in soup_tr[1:]:
tds = tr.find_all('td')
province = tds[2].get_text(strip=True)
type = tds[3].get_text(strip=True)
score = tds[4].get_text(strip=True)
# ranks.append(rank)
# names.append(name)
provinces.append(province)
types.append(type)
scores.append(score)
unversity_list = list(zip(ranks,names,provinces,types,scores))
return unversity_list
###########-----------------------------------------------------------------------------
排名与校名有着独特的标签div class="ranking top1" data-v-389300f0="" 和 span class="name-cn" data-v-2b687c30=""
而剩下所在省市、学校类型和总分标签完全一致,通过具体'td'标签的位置进行提取
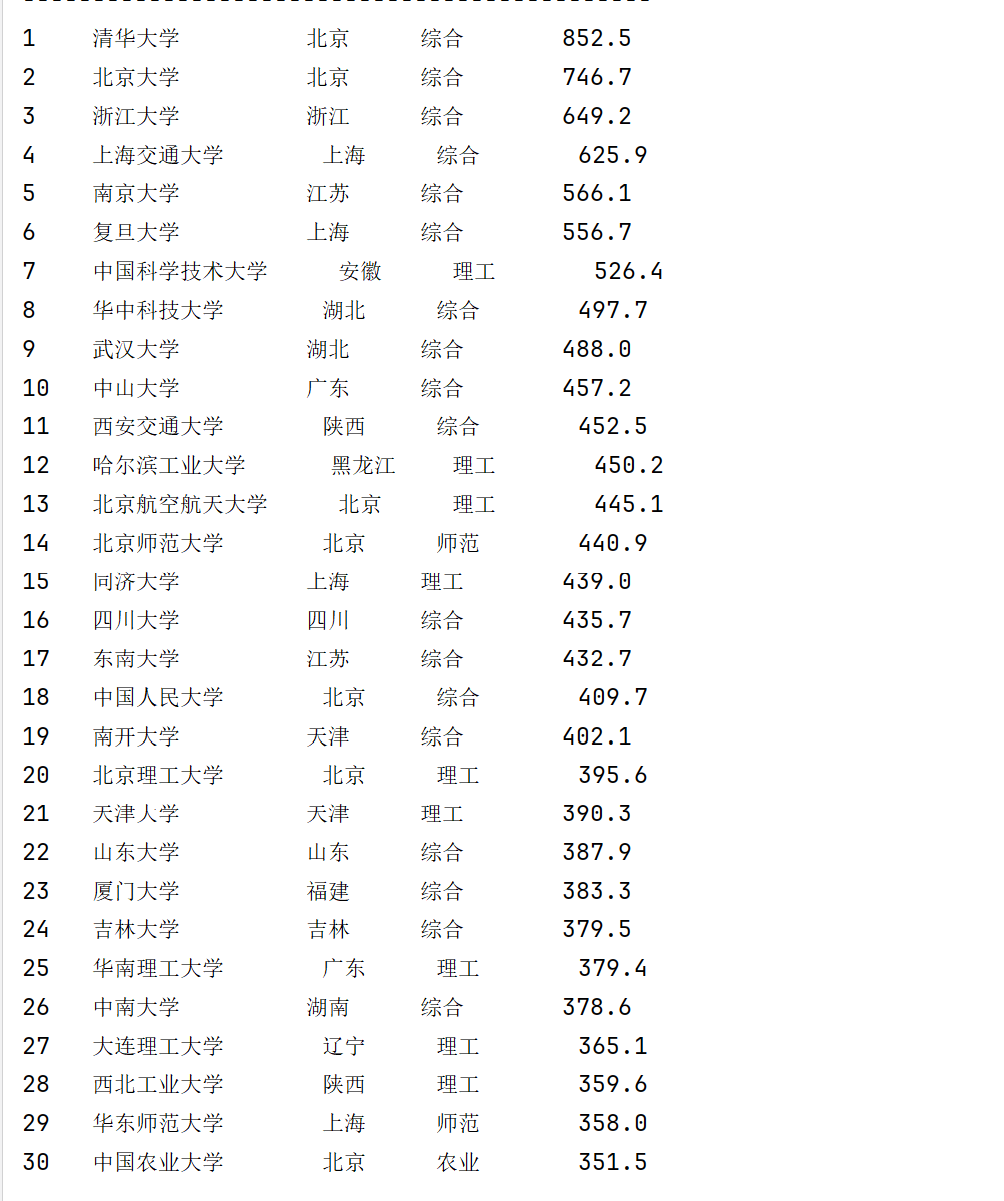
2)心得体会:
从使用requests库发送请求获取网页源码,到利用BeautifulSoup解析复杂的HTML结构并精准提取排名、校名、总分等字段,最后将数据清晰规整地输出。这个过程让我认识到,细致的标签定位和必要的数据清洗对保证数据质量至关重要。
2. 作业②:
1)、核心代码与输出
o 要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
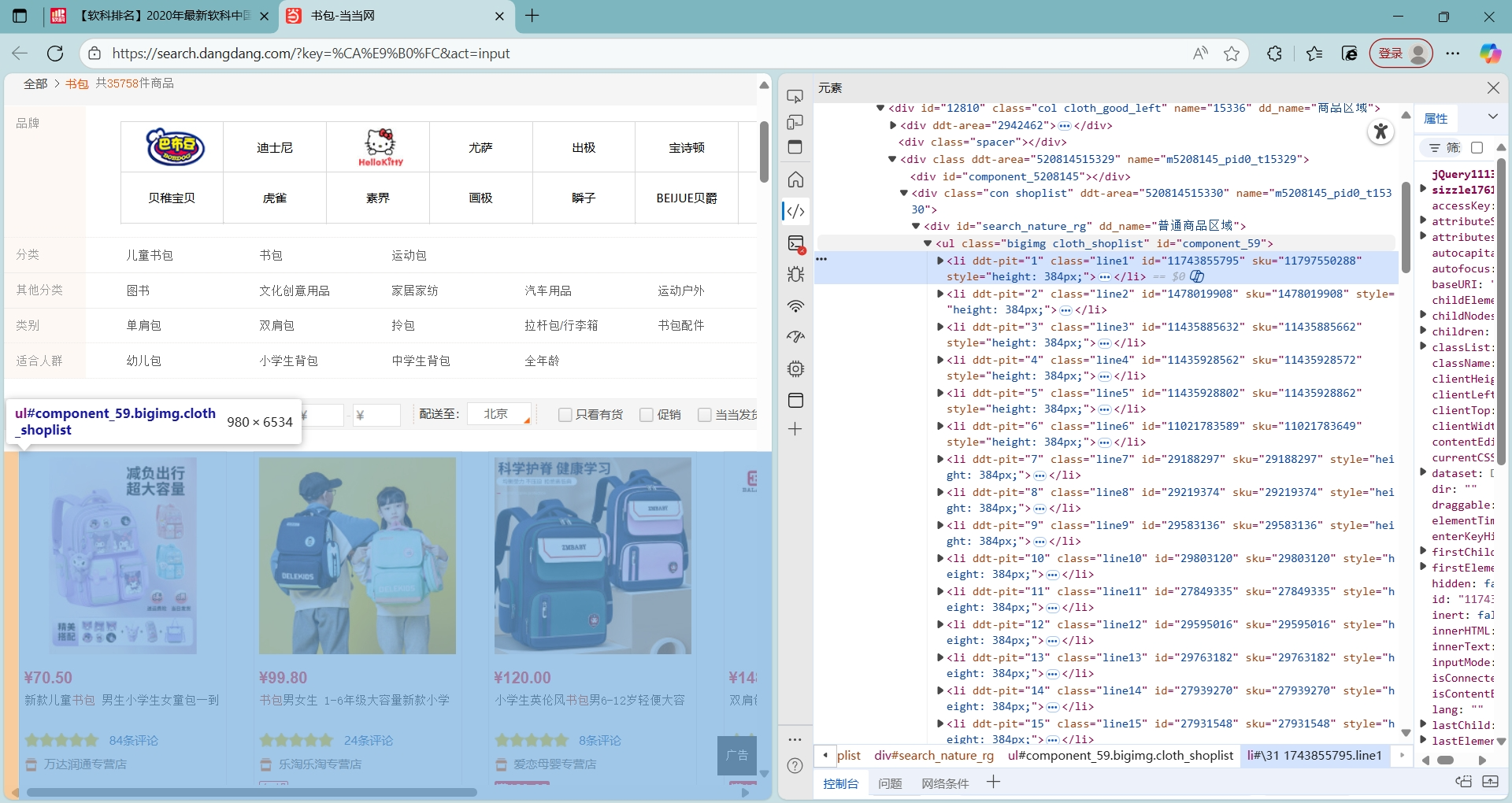
如上图,爬的是当当网,其网址的url较为规整,为https://search.dangdang.com/?key=%CA%E9%B0%FC&act=input&page_index=i ,易于爬取
###########-----------------------------------------------------------------------------
点击查看代码
from bs4 import BeautifulSoup
import requests
class DeduplicatedFZUImageCrawler:
def __init__(self):
self.page_url = "https://search.dangdang.com/?key=%CA%E9%B0%FC&act=input"
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Referer': self.page_url,
} #https://search.dangdang.com/?key=%CA%E9%B0%FC&act=input&page_index=2
self.session = requests.Session()
self.session.headers.update(self.headers)
def get_page_content(self):
response = self.session.get(self.page_url, headers=self.headers, timeout=10)
response.raise_for_status() # 检查请求是否成功
response.encoding = 'gbk'
return response.text
def schoolbag(self, html_content):
soup = BeautifulSoup(html_content, 'html.parser')
schoolbag_list = []
product_items = soup.find_all('li', class_=lambda x: x and 'line' in x)
for item in product_items:
name_tag = item.find('p', class_='name').find('a')
name = name_tag.get('title', '').strip()
price_tag = item.find('span', class_='price_n')
price = price_tag.get_text(strip=True)
schoolbag_list.append((price, name))
return schoolbag_list
def List(self,data):
headers = ['价格', '商品名']
# 打印表头
print(f"{'序号':<8} {headers[0]:<10} {headers[1]:<50}")
print("-" * 45) # 分隔线
# 打印数据行
for i,row in enumerate(data, start=1):
print(f"{i:<8} {row[0]:<10} {row[1]:<50}")
def crawl_and_download(self):
html_content = self.get_page_content()
schoolbag_list = self.schoolbag(html_content)
self.List(schoolbag_list)
# 使用示例
if __name__ == "__main__":
crawler = DeduplicatedFZUImageCrawler()
# 爬取6页内容
crawler.crawl_and_download()
###########-----------------------------------------------------------------------------
但值得注意的是网站的商品名对应标签是'gbk'形式的,一开始用'utf-8'显示乱码
输出结果如下:

2)心得体会:
在处理商品数据时,我意识到数据清洗的重要性。每个商品的名称和价格信息都需要精确提取,稍有偏差就会导致结果不准确。特别是在中文字符编码方面,正确设置gbk编码确保了商品名称的正常显示。
3.作业③
1)、核心代码与输出
o 要求:爬取一个给定网页(https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG、JPG或PNG格式图片文件
在该题中,我爬取的是福大的新闻网的数据,爬取图片不仅限与主栏中的图片,还包含有侧栏等的,诸如校徽的logo,重复出现的不再存,只要是属于(jpg|jpeg|png|gif|bmp|webp|svg)中的一种,当然,大部分都是jpg与png格式的图片,其中dif存在3张。
###########-----------------------------------------------------------------------------
点击查看代码
import urllib.request
import re
import os
import time
from urllib.parse import urljoin
class DeduplicatedFZUImageCrawler:
def __init__(self):
self.base_url = "http://news.fzu.edu.cn/yxfd"
self.downloaded_urls = set() # URL去重
def create_directories(self): #创建存储目录
if not os.path.exists("fzu_images"):
os.makedirs("fzu_images")
def get_page_urls(self, total_pages=6): #生成所有页面URL
page_urls = []
page_urls.append(f"{self.base_url}.htm")
for i in range(1, total_pages):
page_urls.append(f"{self.base_url}/{i}.htm")
return page_urls
def download_with_retry(self, url, max_retries=3):
for attempt in range(max_retries):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Referer': self.base_url
}
req = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(req, timeout=10)
return response
time.sleep(0.2) # 重试前等待
return None
def extract_image_urls_advanced(self, html_content, page_url): #re规范提取url
image_urls = []
patterns = [
# 匹配标准的img标签
r']*?src\s*=\s*["\']([^"\']*?\.(?:jpg|jpeg|png|gif|bmp|webp|svg))["\'][^>]*>',
]
for pattern in patterns:
matches = re.findall(pattern, html_content, re.IGNORECASE)
for img_url in matches:
# 转换为绝对URL
full_url = urljoin(page_url, img_url)
# 去重
if full_url not in self.downloaded_urls:
image_urls.append(full_url)
self.downloaded_urls.add(full_url)
return image_urls
def generate_safe_filename(self, img_url): #生成安全的文件名
parsed_url = urllib.parse.urlparse(img_url)
original_name = os.path.basename(parsed_url.path)
return original_name
def crawl_and_download(self, total_pages=6):
"""主爬虫函数"""
self.create_directories()
page_urls = self.get_page_urls(total_pages)
for page_num, page_url in enumerate(page_urls, 1):
# 下载页面
response = self.download_with_retry(page_url)
if not response:
continue
html_content = response.read().decode('utf-8')
# 提取图片URL
image_urls = self.extract_image_urls_advanced(html_content, page_url)
print(f"在第 {page_num} 页找到 {len(image_urls)} 张图片(URL去重后)")
for img_num, img_url in enumerate(image_urls, 1):
# 生成文件名
filename = self.generate_safe_filename(img_url)
filepath = os.path.join("fzu_images", filename)
# 检查文件是否已存在(文件名去重)
if os.path.exists(filepath):
continue
# 下载图片
img_response = self.download_with_retry(img_url)
# 保存图片
with open(filepath, 'wb') as f:
f.write(img_response.read())
# 图片间延迟
time.sleep(0.2)
# 页面间延迟
time.sleep(0.4)
if __name__ == "__main__":
crawler = DeduplicatedFZUImageCrawler()
# 爬取6页内容
crawler.crawl_and_download(total_pages=6)
###########-----------------------------------------------------------------------------
如上图,该题与上题略有不同的是需要生成文件名对图片进行存储。
2)心得体会:
通过完成这个福州大学新闻图片爬虫项目,我深刻体会到编写一个稳健的爬虫程序需要考虑诸多细节。在实现过程中,URL去重和文件去重机制让我意识到数据完整性的重要性,避免了重复下载造成的资源浪费。使用正则表达式提取图片链接虽然比HTML解析器更复杂,但让我对字符串匹配和模式识别有了更深的理解。
代码路径:https://gitee.com/sui123feng/20251015/tree/master/102302142罗伟钊_实践1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号