java对象的序列化以及反序列化详解
一、概念
序列化:把创建出来的对象(new出来的对象),以及对象中的成员变量的数据转化为字节数据,写到流中,然后存储到硬盘的文件中。
反序列化:可以把序列化后的对象(硬盘上的文件中的对象数据),读取到内存中,然后就可以直接使用对象。这样做的好处是不用再一次创建对象了,直接反序列化就可以了。
使用场景:
- 在创建对象并给所创建的对象赋予了值后,当前创建出来的对象是存放在堆内存中的,当JVM停止后,堆中的对象也被释放了,如果下一次想要继续使用之前的对象,需要再次创建对象并赋值。然而使用序列化对象,就可以把创建出来的对象及对象中数据存放到硬盘的文件中,下次使用的时候不用在重新赋值,而是直接读取使用即可。
- 对象直接转换为字节的形式进行网络传输
二、相关API介绍
序列化
序列化对象所属的类是ObjectOutputStream,如下图所示:
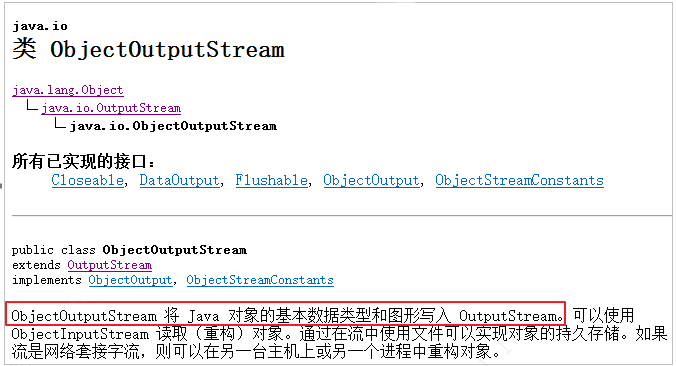
说明:ObjectOutputStream类可以把对象及其数据写入到流中或网络中。
构造函数如下图所示:

写出功能:

反序列化
反序列化对象所属的类是ObjectInputStream类:
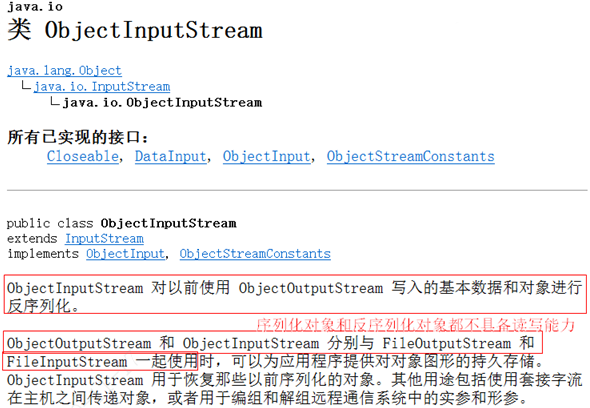
说明:序列化输出流对象和反序列化输出流对象都不具备读写能力,分别依赖FileOutputStream和FileInputStream类来进行读写文件。
构造函数如下图所示:

读取功能:

三、实战
序列化
需求:把Student类创建的对象持久化保存。
分析和步骤:
1)自定义一个Student类,并定义name和age属性;
2)定义一个测试类,在这个测试类中创建Student类的对象s;
3)创建序列化对象objectOutputStream,同时创建输出流并关联硬盘上的文件;
4)使用序列化对象objectOutputStream调用writeObject()函数持久化保存学生对象s;
5)释放序列化对象流的资源;
Student类如下:
需要实现序列化接口Serializable,它是一个标记性接口。这个接口中没有任何的方法,这种接口称为标记型接口!它仅仅是一个标识。只有具备了这个接口标识的类才能通过Java中的序列化和反序列化流操作这个对象。

/**
* 为了保证学生对象可以被序列化,我们让Student类来实现Serializable接口
*/
public class Student implements Serializable {
private String name;
private Integer age;
//省略Getter and Setter、toString和构造方法
}
测试类如下:
/**
* 将学生对象序列化持久到硬盘文件中
*/
public class ObjectOutputStreamDemo {
public static void main(String[] args) throws IOException {
//创建学生对象
Student student = new Student("张三", 13);
//把创建出来的学生对象持久化保存在硬盘中
//创建序列化对象 创建输出流对象并关联目标文件
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("D:\\student.txt"));
//使用序列化对象中的方法持久化学生对象
objectOutputStream.writeObject(student);
//关闭资源
objectOutputStream.close();
}
}
序列化成功后在会在D盘生成一个student.txt文件。
注意:序列化对象如果没有实现序列化接口Serializable,则会抛出如下异常

反序列化
需求:把硬盘文件中的序列化的对象,再进行反序列操作。
分析和步骤:
1)创建反序列化对象,指定一个字节输入流,关联硬盘上的文件;
2)使用反序列对象调用函数readObject()函数,进行反序列操作,获得Student类的对象s;
3)使用对象s调用函数来获取Student类的name和age属性;
4)释放资源;
测试类如下:
/**
* 演示反序列化操作
*/
public class ObjectInputStreamDemo {
public static void main(String[] args) throws IOException, ClassNotFoundException {
//创建反序列化对象,指定一个字节输入流用来读取文件
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("D:\\student.txt"));
//使用反序列化对象调用函数来进行读取数据
Student student = (Student) objectInputStream.readObject();
System.out.println(student.getName() + "," + student.getAge());
//关闭资源
objectInputStream.close();
}
}
结果:
张三,13
这里如果我们对Student类做了一些简单的修改,无关紧要的修改。例如给Student类添加一个属性字段或者函数都可以,再次反序列化,就出问题了,报如下图所示的异常:

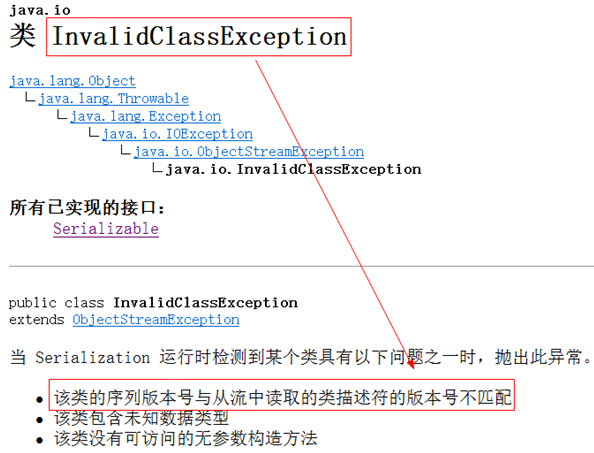
问题:什么是该类的序列版本号呢?
在序列化时将类的各个方面(如类的成员变量、成员函数、修饰符、函数返回值类型等)计算成为该类的默认 serialVersionUID值(版本号)。然后在序列化的时候,这个版本号会随着对象一起被序列化到本地文件中。serialVersionUID 称为序列版本编号(标记值)。类要进行序列化操作时,需要实现Serializable接口(Serializable接口也称为标记接口),实现了标记接口的类,该类会存在一个标记值。在反序列化的时候,从流中也就是硬盘文件中读取数据及原来存储的版本号。同时,再次根据类的内容计算当前的版本号。然后这两个版本号进行对比,如果不一致,认为类发生了改变,则抛出InvalidClassException异常。上述代码如果在反序列化之前修改Student类时,会在报的异常中出现如下图所示的提示信息:
local class incompatible: stream classdesc serialVersionUID = 8434462772094727595, local class serialVersionUID = 2117687252335805572
stream classdesc serialVersionUID = 8434462772094727595, 表示从流中读取的版本号(反序列化时)
local class serialVersionUID = 2117687252335805572 ,表示Student类的序列版本号(序列化时)
上述两个版本号不一致,所以报异常。
通过以上分析,可以得到一个结论:
如果可以保证反序列化对象和序列化对象的标记值相同,就可以避免异常的发生。
那么我们如何做才能保证反序列化对象和序列化对象的标记值相同呢?
我们修改Student类是无关紧要的。在我们修改Student类的时候,我们不希望它抛异常。我们可以给类定义一个默认的版本号,即给Student类添加标记值也就是版本号serialVersionUID。这样一来,添加的标记值即版本号会随着对象的序列化持久保存。无论是序列化,还是反序列化,都不会再根据类的各个方面计算版本号了。序列化和反序列化的版本号会永远一致,所以不会抛出异常,这样就可以避免InvalidClassException异常的发生了。
但是,这样一来,类的安全问题,只能自己来维护。因为已经将类的对象序列化之后,由于类中已经显示定义了版本号,那么反序列化的时候即使修改了Student类,也不会报异常了。
使用idea给自定义类Student添加版本号方法如下图所示:

注意:
在使用序列化操作时,不是所有的成员都可以进行序列化操作:
1)静态成员不会进行序列化操作;
2)瞬态成员也不会进行序列化操作;
瞬态成员:在进行序列化操作时,如果希望某些成员不被序列化,而该成员又不能是静态成员(不希望随着类加载而存在,和对象有关系),就使用关键字transient把成员变为瞬态成员。
代码如下所示:

反序列化的结果:
null,null
说明:由于name和age属性分别被静态和瞬态修饰了,所以都不能被序列化到硬盘上,所以反序列化都是默认值。
记住:
1、当一个对象需要被序列化 或 反序列化的时候对象所属的类需要实现Serializable接口。
2、被序列化的类中需要添加一个serialVersionUID。
序列化的细节:
序列化的时候,只能把对象在堆中的所有数据持久保存到持久设备上。静态的成员变量不会被序列化。
有时我们在序列化的时候某些非静态成员变量也不想被序列化的时候,我们可以使用瞬态关键字(transient)修饰。
四、serialVersionUID的取值
serialVersionUID的取值是Java运行时环境根据类的内部细节自动生成的。如果对类的源代码作了修改,再重新编译,新生成的类文件的serialVersionUID的取值有可能也会发生变化。
类的serialVersionUID的默认值完全依赖于Java编译器的实现,对于同一个类,用不同的Java编译器编译,有可能会导致不同的 serialVersionUID,也有可能相同。为了提高serialVersionUID的独立性和确定性,强烈建议在一个可序列化类中显示的定义serialVersionUID,为它赋予明确的值。
显式地定义serialVersionUID有两种用途:
- 在某些场合,希望类的不同版本对序列化兼容,因此需要确保类的不同版本具有相同的serialVersionUID;
- 在某些场合,不希望类的不同版本对序列化兼容,因此需要确保类的不同版本具有不同的serialVersionUID。
五、什么时候需要序列化对象
一:对象序列化可以实现分布式对象。
主要应用例如:RMI(即远程调用Remote Method Invocation)要利用对象序列化运行远程主机上的服务,就像在本地机上运行对象时一样。
二:java对象序列化不仅保留一个对象的数据,而且递归保存对象引用的每个对象的数据。
可以将整个对象层次写入字节流中,可以保存在文件中或在网络连接上传递。利用对象序列化可以进行对象的"深复制",即复制对象本身及引用的对象本身。序列化一个对象可能得到整个对象序列。
三:序列化可以将内存中的类写入文件或数据库中。
比如:将某个类序列化后存为文件,下次读取时只需将文件中的数据反序列化就可以将原先的类还原到内存中。也可以将类序列化为流数据进行传输。总的来说就是将一个已经实例化的类转成文件存储,下次需要实例化的时候只要反序列化即可将类实例化到内存中并保留序列化时类中的所有变量和状态。
四: 对象、文件、数据,有许多不同的格式,很难统一传输和保存。
序列化以后就都是字节流了,无论原来是什么东西,都能变成一样的东西,就可以进行通用的格式传输或保存,传输结束以后,要再次使用,就进行反序列化还原,这样对象还是对象,文件还是文件
正常来说是很少需要用到的,大部分情况下我们都是使用json或者xml格式来进行数据传输,如果只是转换为字符串的形式与网络打交道,那么就不需要实现Serializable接口。
本博客文章均已测试验证,欢迎评论、交流、点赞。
部分文章来源于网络,如有侵权请联系删除。
转载请注明原文链接:https://www.cnblogs.com/sueyyyy/p/13994824.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号