java8使用parallelStream并行流造成数据丢失或下标越界异常解决方案
描述
我们先看一段使用了并行流的代码
@Test
public void testStream() {
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 10000; i++) {
list.add(i);
}
System.out.println(list.size());
List<Integer> streamList = new ArrayList<>();
list.parallelStream().forEach(streamList::add);
System.out.println(streamList.size());
}
编译结果:
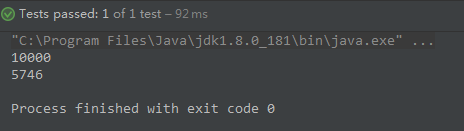
观察发现,原来集合中的数据有10000条,但是使用并行流遍历数据插入到新集合streamList中后,新的集合中只有5746条数据。并且会在多次之后可能会出现数组下标越界异常,显然这里的代码是不合逻辑的。
分析
parallelStream中使用的是ForkJobTask。Fork/Join的框架是通过把一个大任务不断fork成许多子任务,然后多线程执行这些子任务,最后再Join这些子任务得到最终结果。关于分支/合并框架的使用案例可以看我的这篇文章(用分支/合并框架执行并行求和)。从程序上看,就是先将list集合fork成多段,然后多线程添加到streamList的结合中,而streamList是ArrayList类型,它的add方法并不能保证原子性。
ArrayList的add方法源码如下:
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return <tt>true</tt> (as specified by {@link Collection#add})
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
可以看到add方法可以概括为以下两个步骤
- ensureCapacityInternal(),确认下当前ArrayList中的数组,是否还可以加入新的元素。如果不行,就会再申请一个:int newCapacity = oldCapacity + (oldCapacity >> 1) 大小的数组(这个容量相当于:1 + 1/2 = 1.5倍),然后将数据copy过去。
- elementData[size++] = e:添加元素到elementData数组中。
在并发情况下,如果同时有A、B两个线程同时执行add,在第一步ensureCapacityInternal校验数组容量时,A、B线程都发现当前容量还可以添加最有一个元素,不需扩容;因此进入第二步,此时,A线程先执行完,数组容量已满,然后B线程再对elementData赋值时,就会抛出“ArrayIndexOutOfBoundsException”。
解决方案
第一种:将parallelStream改成stream,或者直接使用foreach处理。这可以通过判断并发处理真实能带来多大的好处,做取舍。
@Test
public void testStream() {
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 10000; i++) {
list.add(i);
}
System.out.println(list.size());
List<Integer> streamList = new ArrayList<>();
//list.stream().forEach(streamList::add);
list.forEach(streamList::add);
System.out.println(streamList.size());
}
第二种:使用resultList =new CopyOnWriteArrayList<>(); 这是个线程安全的类。从源码上看,CopyOnWriteArrayList在add操作时,通过ReentrantLock进行加锁,防止并发写。不给过CopyOnWriteArrayList,每次add操作都是把原数组中的元素拷贝一份到新数组中,然后在新数组中添加新元素,最后再把引用指向新数组。这会导致频繁的对象创建,况且数组还是需要一块连续的内存空间,如果有大量add操作,慎用。
@Test
public void testStream() {
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 10000; i++) {
list.add(i);
}
System.out.println(list.size());
List<Integer> streamList = new CopyOnWriteArrayList<>();
list.parallelStream().forEach(streamList::add);
System.out.println(streamList.size());
}
第三种:使用包装类 resultList = Collections.synchronizedList(Arrays.asList());
@Test
public void testStream() {
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 10000; i++) {
list.add(i);
}
System.out.println(list.size());
List<Integer> streamList = Collections.synchronizedList(new ArrayList<>());
list.parallelStream().forEach(streamList::add);
System.out.println(streamList.size());
}
总结
在从stream和parallelStream方法中进行选择时,我们可以考虑以下几个问题:
1.是否需要并行?
2.任务之间是否是独立的?是否会引起任何竞态条件?
3.结果是否取决于任务的调用顺序?
对于问题1,在回答这个问题之前,你需要弄清楚你要解决的问题是什么,数据量有多大,计算的特点是什么?并不是所有的问题都适合使用并发程序来求解,比如当数据量不大时,顺序执行往往比并行执行更快。毕竟,准备线程池和其它相关资源也是需要时间的。但是,当任务涉及到I/O操作并且任务之间不互相依赖时,那么并行化就是一个不错的选择。通常而言,将这类程序并行化之后,执行速度会提升好几个等级。
对于问题2,如果任务之间是独立的,并且代码中不涉及到对同一个对象的某个状态或者某个变量的更新操作,那么就表明代码是可以被并行化的。
对于问题3,由于在并行环境中任务的执行顺序是不确定的,因此对于依赖于顺序的任务而言,并行化也许不能给出正确的结果。
本博客文章均已测试验证,欢迎评论、交流、点赞。
部分文章来源于网络,如有侵权请联系删除。
转载请注明原文链接:https://www.cnblogs.com/sueyyyy/p/13079525.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号