单列数据的频率分布直方图
from matplotlib import pyplot as plt # 计算组数 d = 800 # 组距 num_bins = int((max(a) - min(a)) // d) print(max(a), min(a), max(a) - min(a)) print(num_bins) # 设置图形大小 plt.figure(figsize=(20, 13), dpi=80) # 绘制直方图 plt.hist(a, num_bins) # 设置x轴的刻度 plt.xticks(range(int(min(a)), int(max(a)) + d, d)) plt.grid() plt.show()
np.histogram()分箱的使用
from matplotlib import pyplot as plt import pandas as pd import numpy as np rawdata = pd.read_csv('./data/svr_result.csv') rawdata=rawdata["test"] print(rawdata.head()) # 计算组数 d = 0.5 # 组距 num_bins = np.histogram(rawdata)[1].size print(num_bins) # 设置图形大小 plt.figure(figsize=(20, 13), dpi=180) # 绘制直方图 plt.hist(rawdata, num_bins) # 设置x轴的刻度 plt.xticks(np.histogram(rawdata)[1]) plt.grid() plt.show()
自动化使用plt绘图
from matplotlib import pyplot as plt import pandas as pd import numpy as np
plt.rcParams['font.sans-serif']=['SimHei'] rawdata = pd.read_csv('./data/svr_result.csv') rawdata=rawdata["test"] print(rawdata.head()) n, bins, patches = plt.hist(x=rawdata, bins='auto', color='#0504aa', alpha=0.7, rwidth=0.85) plt.grid(axis='y', alpha=0.75) plt.xlabel('Value') plt.ylabel('Frequency') plt.title('测试集分布直方图') # plt.text(23, 45, r'$\mu=15, b=3$')for a,b in zip(x,y): # plt.text(a, b+0.05, '%.0f' % b, ha='center', va= 'bottom',fontsize=7)#设置标签 maxfreq = n.max() # 设置y轴的上限 plt.ylim(ymax=np.ceil(maxfreq / 10) * 10 if maxfreq % 10 else maxfreq + 10) plt.show()
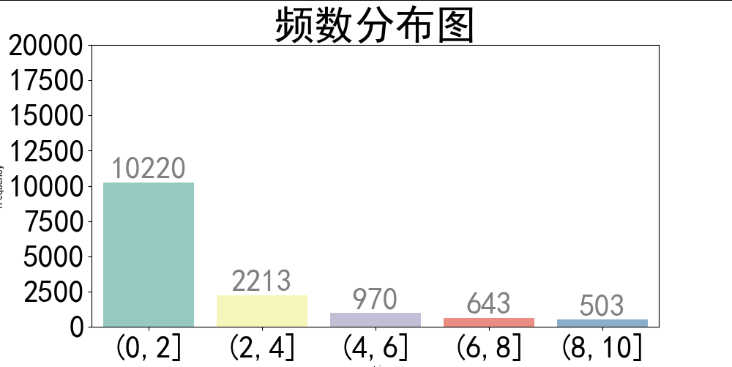
seaborn方式(强推荐)
import matplotlib.pyplot as plt import matplotlib as mpl import pandas as pd import numpy as np import seaborn as sns # 制作频数分布表 # 分割区间 data_split = pd.cut(rawdata, [0, 2, 4, 6, 8, 10], labels=[u"(0,2]", u"(2,4]", u"(4,6]", u"(6,8]", u"(8,10]"]) #计算每个区间的频数并按上面的labels调整顺序 freq_chart = data_split.value_counts() freq_chart = freq_chart.sort_index() #保存为一个频率分布字典 freq_dict= {'section': freq_chart.index, 'frequency': freq_chart.values} #将对应的频率分布字典转化为pd文件 freq_data = pd.DataFrame(freq_dict) ax = plt.figure(figsize=(10, 5)).add_subplot(111) sns.barplot(x="section", y="frequency", data=freq_data, palette="Set3") # palette设置颜色 #设置y轴高度 y轴高度最好为最大都轴超20% ax.set_ylim([0, 20000]) ax.set_title('频数分布图', size=40) #设置字体大小 plt.xticks(fontsize=30) plt.yticks(fontsize=30) #设置数据标签 for x, y in zip(range(5), freq_data.frequency): ax.text(x, y, '%d' % y, ha='center', va='bottom', fontsize=30, color='grey') plt.show()
import matplotlib.pyplot as plt import pandas as pd import seaborn as sns #只用调整bin_list分布方式即可自绘图 # 制作频数分布表 bin_list = [0.0,0.05,0.10,0.15,0.20] plt.rcParams["font.sans-serif"] = ["SimHei"] rawdata = pd.read_excel("./data/train_result.xlsx") print(rawdata.describe()) rawdata = rawdata['result'] # 分割区间 split_str = [] for i in range(len(bin_list)): if (i < len(bin_list) - 1): split_str.append(str(bin_list[i]) + '~' + str(bin_list[i + 1])) else: break data_split = pd.cut(rawdata, bin_list, labels=split_str) # 计算每个区间的频数并按上面的labels调整顺序 freq_chart = data_split.value_counts() freq_chart = freq_chart.sort_index() # 保存为一个频率分布字典 freq_dict = {'section': freq_chart.index, 'frequency': freq_chart.values} # 将对应的频率分布字典转化为pd文件 freq_data = pd.DataFrame(freq_dict) ax = plt.figure(figsize=(100, 35)).add_subplot(111) sns.barplot(x="section", y="frequency", data=freq_data, palette="Set3") # palette设置颜色 # 设置y轴高度 y轴高度最好为最大都轴超20% ax.set_ylim([0, max(int(freq_data["frequency"]+0.2*freq_data["frequency"]))]) ax.set_title('总体训练集预测频数0-0.2分布', size=100) # 设置字体大小 plt.axhline(y=2000, ls=":", c="red", lw=4, label='2000分界线') # 添加水平直线 lw粗细 plt.legend() plt.xticks(fontsize=50) plt.yticks(fontsize=50) # 设置数据标签 for x, y in zip(range(len(bin_list)), freq_data.frequency): ax.text(x, y, '%d' % y, ha='center', va='bottom', fontsize=50, color='black') plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号