JamesFramework官方文档翻译笔记(.conti)
文本所有内容以及插图均来自 http://www.jamesframework.org/docs/
Javadoc API
完整的核心模块、扩展模块的API文档
最新的稳定api
[旧版本
开发快照
问题说明
JAMES 框架将问题说明和搜索过程有效地拆分开来,从而让现有的算法可以轻松获取到问题的解。每一个问题都有一个特定的解类型,以及一个可以创建这类解从而解决问题的搜索过程。搜索过程可以与问题交互随机地产生一系列解(如,用于局部搜索的默认初始解),并且对这些解进行评估与验证。
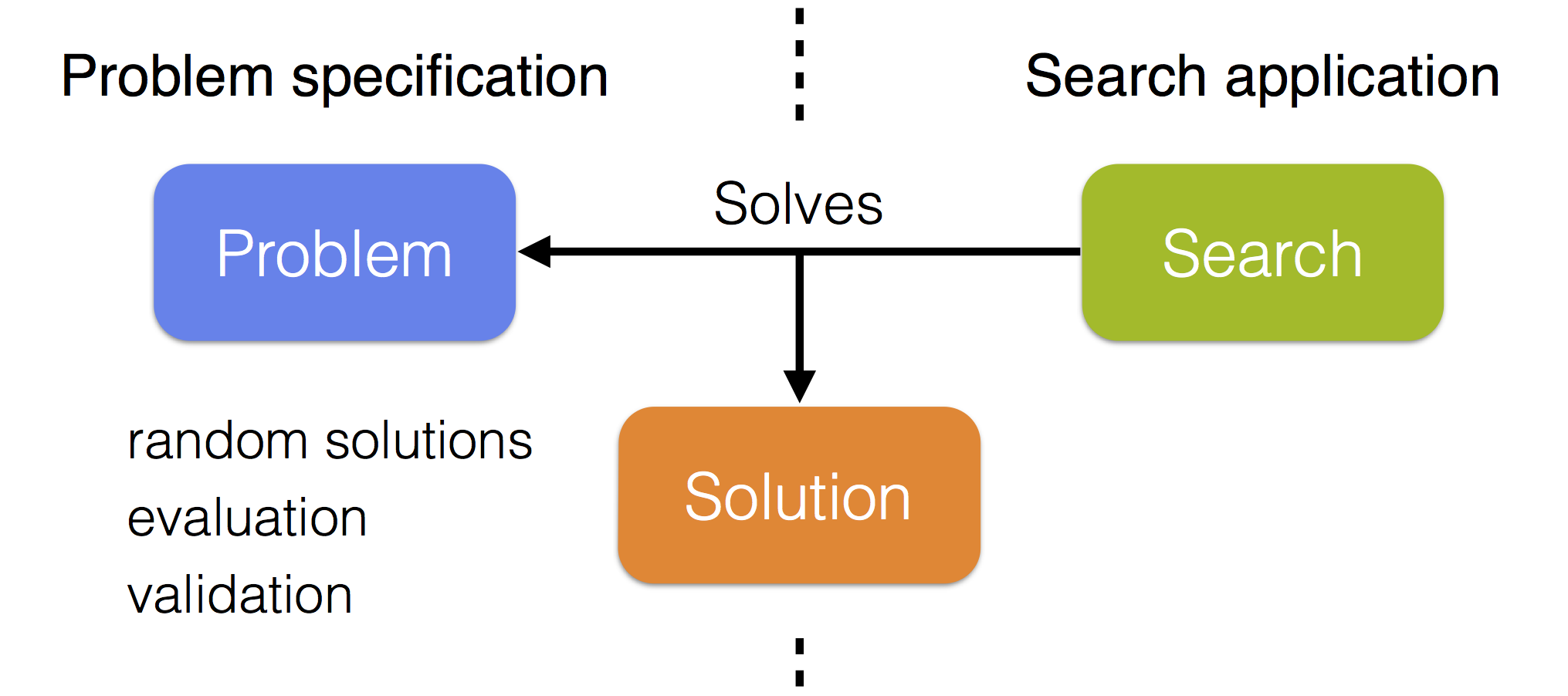
一些实用方案可以帮助我们把问题划分成数据、目标、任意数量的约束以及一个随机解的生成器。目标和约束分别负责使用数据进行解的评估与验证的工作。基本上可用的优化算法都是局部搜索算法,它可以重复修改并改进当前解,同时,想要进行搜索,必须至少提供一个邻域,该邻域用于当前解的转移,邻域类型和解类型应该兼容。
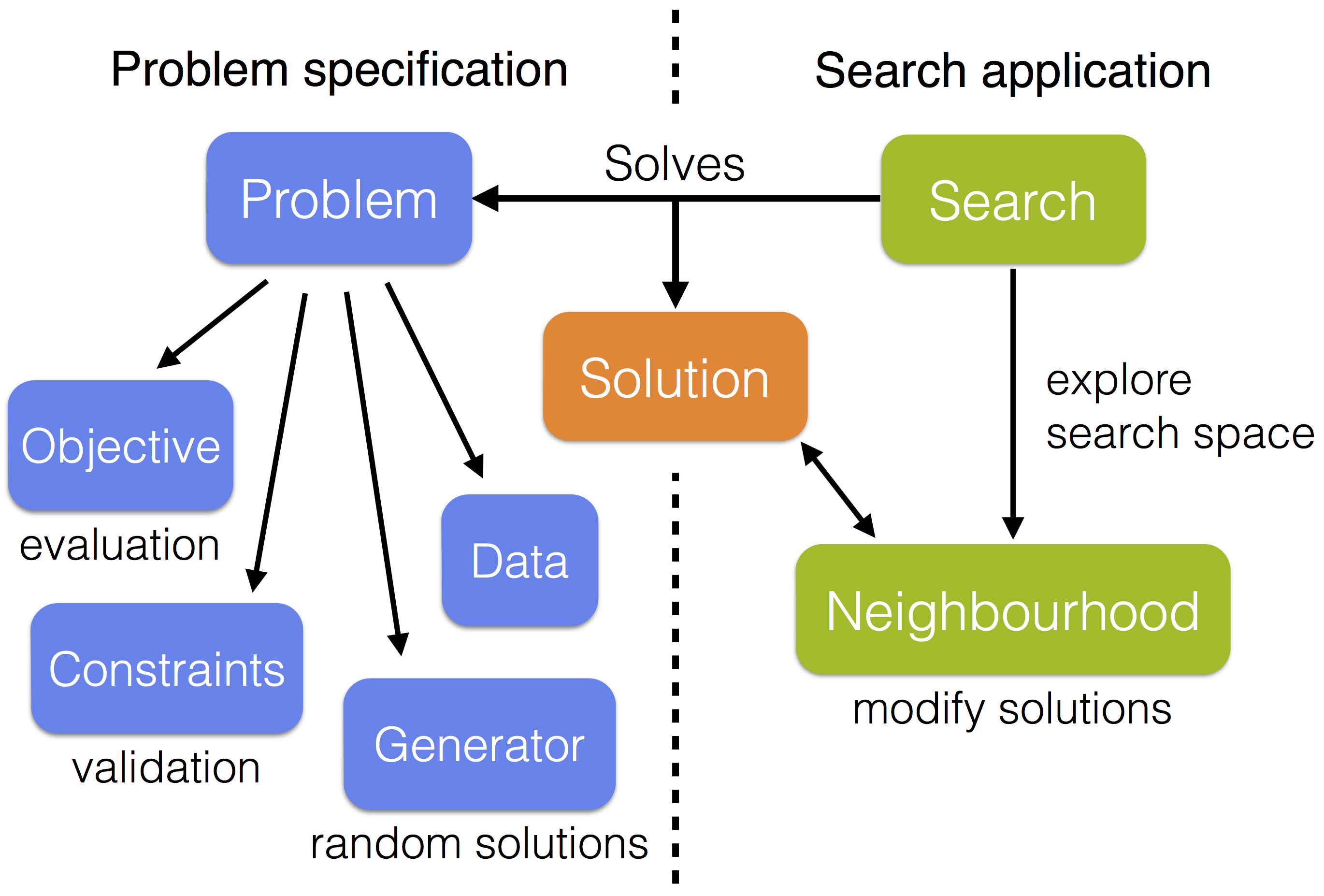
核心模块包括了子集选择问题的预定义组件,包括一个预定义的解类型、一个具有内置的随机子集生成器的高级问题规范,以及若干子集邻居。其他类型的问题也可以构造相似的组件。有一些组件也在扩展模块中。
子集选择
子集选择组件要求数据集中的每一个对象都要有一个唯一的ID,任何子集选择问题就可以转化成ID集合的选择问题。实现子集选择问题的步骤如下:
-
实现
IntergetIdentifiedData接口来自定义一个数据类(MyData)。该接口定义了一个getIDs()方法来返回数据集中所有对象的ID。此外,也要自定义一些重要的方法来根据ID访问对象属性。 -
实现
Objective接口来定义目标函数。这是一个具有两种类型参数的通用接口:解类型和数据类型。将解类型定义为SubsetSolution,数据类型就是MyData。使用底层数据实现评估解的方法,并且说明评估是最大化问题还是最小化问题。此外,还可以一同一个有效的delta评估方法,这种方法基于本次评估结果和解的移动行为来评价某次局部搜索中当前解的某个邻居。 -
实现
Constraint和/或PenalizingConstraint接口来声明约束(如果有的话),对应问题定义中的强制约束和惩罚约束。违背了强制约束的解会被剔除,违背了惩罚约束的解,其评估结果会得到相应的惩罚,但是仍然视为一个有效的解。两接口都有一个通用的解类型和数据类型也就是SubsetSolution和MyData。也支持delta评估。 -
在
SubsetProblem中将数据、目标、约束整合起来,其中,需要规定子集大小的限制(最大值、最小值、固定值)。数据和目标都是必需的,而且要在构造时设置,而强制约束和惩罚约束不需要在一开始就定义,而是使用addMandatoryConstraint(c)和addPenalizingConstraint(c)在后期定义
问题定义可以被传递到任一次局部搜索来进行选择优化。也存在若干预定义的邻居子集,他们可以添加或删除选择中的某些ID来调整当前解。注意,一些搜搜可能需要指定额外的参数或者组件,可以通过例子查看细节
其他
其他类型的问题也可以建模解决
-
扩展抽象类
Solution定义一个解类型MySolution -
自定义一个数据类Mydata,包裹评估验证和随机解生成需要的数据。数据类型没有强制要求,也就是说是接口实现还是类扩展是无所谓的,完全自定义即可
-
实现目标和约束,与前文步骤相同
-
实现
RandomSolutionGenerator接口定义一个随机解生成器,应用局部搜索时,生成的随机解可以被用来作为默认初始解 -
在
GenericProblem里组合数据、目标、约束和随机解生成器 -
使用
Mysolution实现至少一个Neighbourhood接口,邻域会生成可应用于修改当前解的移动,不成功时返回前一个当前解。所有的移动需要实现Move`接口
组合问题现在可以通过任何可用的局部搜索来解决,使用定义的定义的邻域在修改解。注意,有一些搜索可能需要额外的参数或者组件,可查看示例
优化算法
所有可用的特定问题求解的算法都列在下方了。大多数算法都是局部搜索元启发式算法,但是也有少数例外,比如穷举搜索和一种专门为子集采样设计的启发式算法。还提供了一些用于混合(并行)搜索的基本构建块。
如果你不知道什么是局部搜索元启发式算法,阅读这个内容
大多数局部搜索算法从一个随机(或者人工定义)的初始解,使用一个或者多个邻域去探索搜索空间。一个邻域定义了与当前解相似的、可以通过对当前解进行很小的修改(移动)而得到的候选解的集合。这样的移动会重复应用于当前解上,从而对当前解进行优化。所以,被选择的邻域很大程度上影响了搜索算法的性能表现。
随机下降算法(Random descent)
随机下降是最基本的局部搜索算法(也叫随机爬山法),在每一步中,当前解的一个随机邻居会被评估,如果他有效并且优于当前解,那么会被选中成为新的当前解。
随机下降算法不会在内部终止,所以应该指定停止条件,例如最大步数或者最大运行时间。默认情况下,搜索从随机初始解开始,或者可以自定义初始解方案,任何与解类型兼容的邻域都可以应用。
最陡下降算法(Steepest descent)
最陡下降算法(也叫爬山法)总是接收邻域中最好的有效邻居作为新的当前解,直到没有新的优化方法了。
算法默认从随机初始解开始,也可以自定义初始解。任何与问题解类型兼容的邻域都可以应用。
禁忌搜索策略 (Tabu search)
禁忌搜索是基于最陡下降的,但是并不需要在每一步中都完成优化。当前解的最佳有效非禁忌邻居会被接收成为新的当前解,这使得搜索可能从局部最优解中跳出。
为了避免重复访问某些相同的解(在解空间中遍历循环),邻域会被禁忌空间动态修改。这部分空间跟踪保存了最近访问的解、解中是否存在某种特征以及最近发生的移动。根据这些信息,特定的解会被声明为禁忌,从邻域中剔除,从而倾向于搜索未访问的区域。
当当前解的所有有效邻居都是禁忌时,搜索会发生內部停止。然而,这种情况可能并不会发生,所以最好制定一个停止条件来保证搜索会终止,默认情况下,搜索从随机初始解开始,也可以自定义初始解,任何与解类型兼容的邻域都可以应用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号