PLE-实践小结-2308-cnblogs
某场景介绍
- 前状:三模型,权重融合
- 解决问题:融合目标行为,充分利用样本信息,节省资源开销。
当前效果
-
主场景人均真实曝光+0.26%,不显著;子场景人均真实曝光+0.35%,不显著
-
千曝互动+2.65%,显著;千曝互动uv+1.80%,显著;人均互动+0.87%,不显著
-
千曝点击+11.24%,显著;千曝点击uv+5.91%,显著;人均点击+5.08%,显著
-
去重千曝点击+6.37%,显著;去重千曝点击uv+5.62%,显著;人均去重有效点击+0.75%,显著
-
物料类型侧指标未见明显异常。实验符合预期,建议扩量。
-
粗估节省线上模型服务资源约40%。
场景二:
- 人均真实曝光-0.28%,不显著
- 千曝互动+5.35%,显著;人均互动+3.28%,显著; 互动uv+1.83%,显著性未知
- 千曝点击+3.79%,显著;人均点击+3.62%,显著;点击uv-0.25%,显著性未知
场景三:
ple模型:核心指标 +0.588% 显著,千曝点击 3.871% 显著
技术方案选型
- MMOE、SNR、PLE
- 整体思路一脉相承
- 选了最新的模型,能抄到的最全的作业 -》 PLE
- 参考:https://zhuanlan.zhihu.com/p/291406172
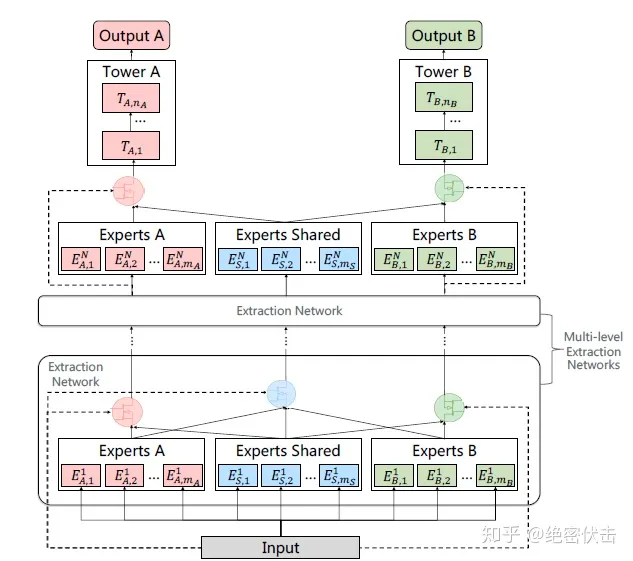
核心经验(特征和权重)
-
特征
- 样本label
- 特征准确度、特征覆盖度、特征相关性
-
目标权重、目标间相互影响程度、模型会不会被带偏
- 样本策略:六组策略,三个目标;交叉验证,20余组离线实验
- loss不同,反向传播差异极大
- 样本label调权
- 打分分布、归一化保证模型真正在work
- 离线物料打分分布、分位点;模型打分分布、分位点;
- 策略调权
-
底表、实时、无行为过滤样本、点击样本、点正文样本
- 反向归因:全量样本,即便未真实曝光,因策略、模型打分排出去,也认为是负样本
-
过滤策略:全量样本、真实阅读样本、真是阅读+位置样本
- 真实阅读平均位置,为5.0x;
- BEC、focalloss分别对比
- 三目标分别对比
- T+1验证,1、5、7、14、21天样本训练;观察auc diff。
特征
- 特征重筛(有效性、监控、误配置引入bug反查)
- 手动刷流,结合case系统,查样本数据;
- 样本特征覆盖度监控
- 相关性分析(pickup)
- 有正相关,有负相关;认为具有相关性即可,不论正负,具体作用交由模型学习
- 特征验证(推理性能、模型表现性能)
- 序列特征、ID类特征
- 剧烈影响模型推理性能,在模型表现影响不大情况下,适度删减
- 分桶优化(调整分桶、大维度hash)
- 全特征走hash,模型维度一度膨胀到100w亿。
- 反向归因:因为样本不足,id类embeding学习不充分,21天样本依然效果较差。
- 交叉特征(concathash、pickup)
- 全流程一致性梳理
label
- 点击指标爆炸、目标优化
- 用了label_click。auc能学到0.9+,但上线效果极差
- 用了label_click_valid,模型不收敛,bug修复后,恢复正常
- 模型不收敛
- 训练、评估使用label不匹配(点正文、混合label)
- label 歧义
- 物料类型分析、指标异常分析
- 极有效的辅助观测指标,各label交叉对比,能发现80%以上的问题
- 损失置0 (评估相关性)
- 部分loss不进入总loss
- loss置0
- 梯度置0、梯度丢弃
- stop_gradient
- 梯度裁剪
模型结构
- Dense层对比实验(128+32、128+64+32、256+128+64、256+128+64+32)
- 一定程度下,模型越复杂,效果越好(离线auc,线上指标变动不显著)
- 专家塔实验(40、64、32、20)
- 专家塔对单目标影响不大。多目标场景下效果较为显著,但没有显著的对应关系,得试。
- input_layer调整pooling操作,离线无显著收益。
- 模型跳连(skip-conn)
- 参考ResNet
- 特征交叉(concat、pooling)
- 参考DeepFM,最后一层与第一层进行操作
- gradient-stop (评估梯度)
- 在用,但效果未做对比。
- 多共享塔
- 同专家塔,比较玄学。个人未有显著结论。
- 基于tensorboard,trace graph,排查代码异常
- 极其有效的评估手段
- graph、projector、histograms、distributions
- 分别排查代码bug、embeding异常、训练过程异常、参数分布异常
- savedmodel 转文本,根据op回溯图,排查异常
- 极重要的一致性校验手段
- 参考代码,基本能回溯全图,并且部分了解tf、framework运行机制。
- predict score reshape导致协议不兼容
- 上线预览时发现的问题。上线前一定要预览,必要时加白名单刷case。
优化器(差异不大,均能收敛)
- adam
- adagrad
- sgd
loss
- 交叉熵(tf 实现有trick,建议深挖代码)
# Note that these two expressions can be combined into the following:
# max(x, 0) - x * z + log(1 + exp(-abs(x)))
# To allow computing gradients at zero, we define custom versions of max and
# abs functions.
- 加权交叉熵
- tf实现,支持自定义权重
reweight_value = 1.0
if("by_positive" == self.params['model_reweight_type'][0]):
reweight_value = float(params['model_reweight_type'][1])
tf.logging.info("suanec : real reweight value is : %d" % reweight_value)
print("suanec : real reweight value is : %d" % reweight_value)
weights = tf.where(tf.equal(labels, 1.0), tf.tile([reweight_value], tf.shape(labels)), tf.tile([1.], tf.shape(labels)))
tf.logging.info("suanec : model_func_remainder. done parse reweight_value .")
········
········
········
elif params['sample_label_column'] == "is_click":
print("params['sample_label_column'] == is_click | use click_label")
click_labels = self.click_label_cast(features=features)
labels = click_labels
loss = tf.losses.sigmoid_cross_entropy(labels, logits, weights=weights)
- focalloss
- 本质是加权 + 减权
- 整体loss 值会较小,适当缩放、调大学习率、调整权重等手段规避
- alpha-focalloss
- 自定义,删减了难样本学习功能,减少pow操作。减少变量、降低开销(理论上)
- loss 分析 [https://note.youdao.com/s/C5kbN5K9]
- 根据loss值、learning_rate,评估模型收敛情况,玄学凭感觉。
- L1、L2默认都加
- 具体加不加,怎么加,要先说服自己
打分融合策略
- 调和平均数(F1)
- 参考recall/precision 评估
- 均值
- 多目标共现,同贡献先验
- 乘积
- 参考CTCVR,概率角度考虑,后续粗排可以尝试(单理论分析)
- 固定权重
- 引入业务先验
- UWL
- Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics
- 简而言之就是:一个基于高斯分布先验的 log likelihood。
- 策略归一化
- 模型打分跟策略打分应该在一个维度,至少是一个量纲
- 打分一致性校验
- 一致性校验工具
- tf savedmodel_cli 工具
- 打分分位点评估
实时化
- 特征校验、schema有略微差异
- 评估shape不对
- 多目标评估打分是多个tensor,stream_evaluator配置有trick
- 模型不收敛
- 学习率问题
- 样本不够
- label不对
- loss函数 差异
- 实施评估数据错位导致auc异常
- 第二个目标评估数据错位,各项指标均异常。后对比离线发现,因数据错位导致。
- 新镜像已修复
case观感
- 视频贼少、视频贼多
- 召回层级分析
- 兴趣层减少
- 图文较多但热度低
- 互动指标加权大,导致影响较大
- 热度较高但兴趣差
- 筛选了行为样本,热度高物料学习充分
- 关注策略加权较重
- 分发控制、过已读等其他case
- 打点case
- 过已读case
- 模型超时 非合理推荐case
- 跨场景行为
- 互动过物料曝光case
- 样本和指标 向专业人士寻求帮助
监控数据
- 模型服务指标
- qps、rt、p99、参数服务p99、版本号、特征空值率
- titan引擎指标
- p99、错误率等
- 基于物料类型的分析
- 物料类型变化,及各项行为指标对比
- 基于位置的分析
- 同位置物料均值对比
- 模型打分监测:均值 + 分位点
- 一致性确认
- 造数据离线评估打分
遗留问题
- MTL+MDL todo
- 模型迁移实时 doing
- 参数预加载 doing
- 融合权重预置方式 (纯引擎,改为模型 + 策略 + 引擎) todo
后续规划
- pepnet + ple
- 参考DMT,+ attention
- UWL推理引入,配合实时训练,初版强化学习
小结
- 不浪费每一次错误,错误要改,还要尽量多的得出新结论;pivot 枢轴法
- 相信并依靠团队的力量
- 多目标任务,目标融合是关键
澄轶: suanec -
http://www.cnblogs.com/suanec/
友链:marsggbo
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
点个关注吧~
http://www.cnblogs.com/suanec/
友链:marsggbo
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
点个关注吧~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号