Python 基础知识笔记
Python的好些知识点好久没碰了,有些淡忘,今天勤快点整理和复习,重新拾起这门语言。这篇笔记并不系统,只是暂时记录了些希望自己记住的内容,故可能对读者没有参考意义。
字符串与常用数据结构
多行字符串
s3 = """
hello,
world!
"""
可以使用 + 运算符来实现字符串的拼接,可以使用 * 运算符来重复一个字符串的内容,可以使用 in 和 not in 来判断一个字符串是否包含另外一个字符串。
常见字符串方法见该博客。
字符串格式化
a, b = 5, 10
print('%d * %d = %d' % (a, b, a * b))
a, b = 5, 10
print('{0} * {1} = {2}'.format(a, b, a * b))
Python 3.6以后,可在字符串前加上字母 f,使用下面的语法糖来简化上面的代码
a, b = 5, 10
print(f'{a} * {b} = {a * b}')
面向对象编程
类中的 __init__ 用于在创建对象时进行初始化操作。
在Python中,属性和方法的访问权限只有两种,也就是公开的和私有的,如果希望属性是私有的,在给属性命名时可以用两个下划线作为开头。
Python并没有从语法上严格保证私有属性或方法的私密性,它只是给私有的属性和方法换了一个名字来妨碍对它们的访问,事实上如果你知道更换名字的规则仍然可以访问到它们。
在实际开发中,我们并不建议将属性设置为私有的,因为这会导致子类无法访问(后面会讲到)。所以大多数Python程序员会遵循一种命名惯例就是让属性名以单下划线开头来表示属性是受保护的,本类之外的代码在访问这样的属性时应该要保持慎重。
面向对象有三大支柱:封装、继承和多态。
爬虫
什么是爬虫?按照一定规则自动浏览互联网从中获取网页信息的脚本或程序。
爬虫广泛应用于搜索引擎。
互联网世界已经通过自己的游戏规则建立起一定的道德规范(Robots协议)。大多数网站都会定义robots.txt文件。
如果爬虫就像浏览器一样获取的是前端显示的数据(网页上的公开信息)而不是网站后台的私密敏感信息,就不太担心法律法规的约束,因为目前大数据产业链的发展速度远远超过了法律的完善程度。
在爬取网站的时候,需要限制自己的爬虫遵守Robots协议,同时控制网络爬虫程序的抓取数据的速度;在使用数据的时候,必须要尊重网站的知识产权。
工具
-
builtwith库:识别网站所用技术的工具
-
robotparser模块:解析robots.txt的工具
上面两个工具的demo见这篇博客。
一个基本的爬虫通常分为数据采集(网页下载)、数据处理(网页解析)和数据存储(将有用的信息持久化)三个部分的内容,当然更为高级的爬虫在数据采集和处理时会使用并发编程或分布式技术,这就需要有调度器(安排线程或进程执行对应的任务)、后台管理程序(监控爬虫的工作状态以及检查数据抓取的结果)等的参与。
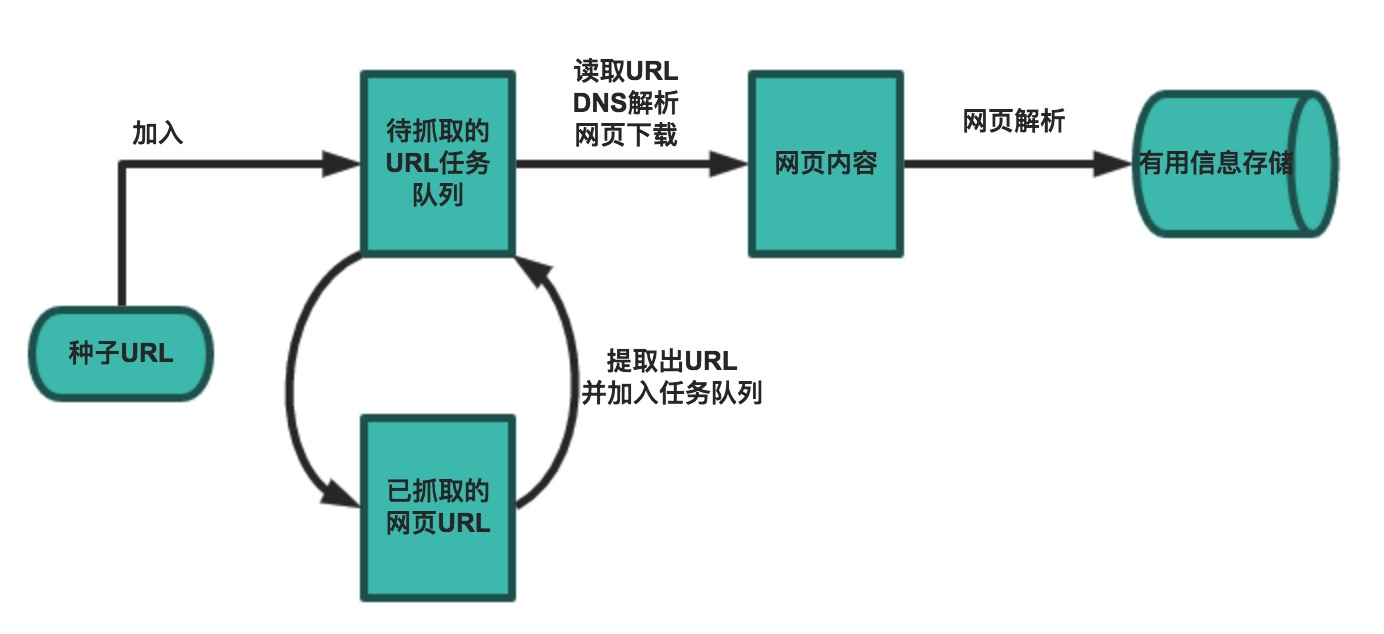
一般来说,爬虫的工作流程包括以下几个步骤:
-
设定抓取目标(种子页面/起始页面)并获取网页。
-
当服务器无法访问时,按照指定的重试次数尝试重新下载页面。
-
在需要的时候设置用户代理或隐藏真实IP,否则可能无法访问页面。
-
对获取的页面进行必要的解码操作然后抓取出需要的信息。
-
在获取的页面中通过某种方式(如正则表达式)抽取出页面中的链接信息。
-
对链接进行进一步的处理(获取页面并重复上面的动作)。
-
将有用的信息进行持久化以备后续的处理。
参考
https://github.com/jackfrued/Python-100-Days/blob/master/Day01-15/08.面向对象编程基础.md
https://github.com/jackfrued/Python-100-Days/blob/master/Day61-65/61.网络爬虫和相关工具.md

 浙公网安备 33010602011771号
浙公网安备 33010602011771号