
四 Oracle 里的查询转换
oracle里的查询转换的作用
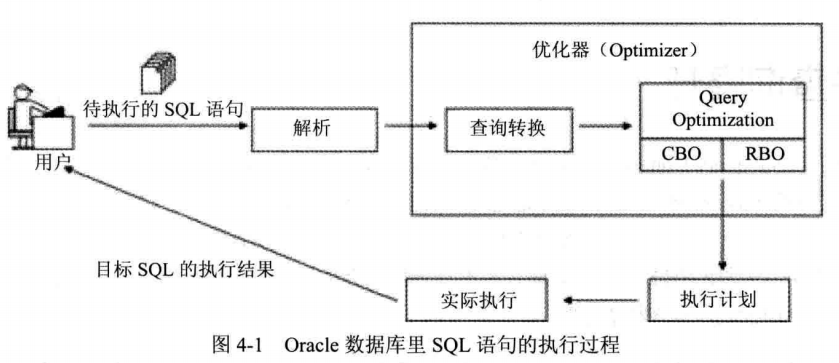
oracle里查询转换,又称查询改写,它是Oracle在解析目标SQL的过程中的重要一步,其含义是指Oracle在解析目标SQL时可能会对其做等价改写,目的是为了能更高效地执行目标SQL,即Oracle可能会将目标SQL改写成语义上完全等价但执行效率却更高的形式。Oracle数据库里SQL语句的执行过程可以如下表示:
4.2 子查询展开
它是指优化器不再将目标SQL中的子查询当作一个独立的处理的单元来单独执行,而是将该子查询转换为它自身和外部查询之间等价的表连接。这种等价表连接转换
要么是:
1.将子查询拆开(即将该子查询中的表、视图从子查询中拿出来,然后和外部查询中的表、视图做表连接),
要么是:
2.不拆开但是会把该子查询转换为一个内嵌视图,然后再和外部查询中的表、视图做表连接。
有的子查询做不了子查询展开的话,此时Oracle还会将该子查询当作一个独立的处理单元来单独执行。
oracle数据库里子查询前的where条件如果是如下这些条件之一,那么这种类型的目标SQL在满足一定的条件后就可以做子查询展开:
- SINGLE-ROW(即=、<、>、<=、>=和<>)
- EXISTS
- NOT EXISTS
- IN
- NOT IN
- ANY
- ALL
如果是SINGLE-ROW则子查询返回一条,其他的返回可以包含多条。
情形1:
select t1.CUST_LAST_NAME,t1.CUST_ID from sh.CUSTOMERS t1
where CUST_ID in (select /*+no_unnest*/ CUST_ID from sh.SALES t2 where t2.AMOUNT_SOLD>700);
不做子查询展开:


Plan hash value: 3295561841 -------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop | -------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 13 | 425K (6)| 01:25:09 | | | |* 1 | FILTER | | | | | | | | | 2 | TABLE ACCESS FULL | CUSTOMERS | 55500 | 704K| 254 (1)| 00:00:04 | | | | 3 | PARTITION RANGE ALL| | 2 | 20 | 10 (10)| 00:00:01 | 1 | 28 | |* 4 | TABLE ACCESS FULL | SALES | 2 | 20 | 10 (10)| 00:00:01 | 1 | 28 | -------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter( EXISTS (SELECT /*+ NO_UNNEST */ 0 FROM "SH"."SALES" "T2" WHERE "CUST_ID"=:B1 AND "T2"."AMOUNT_SOLD">700)) 4 - filter("CUST_ID"=:B1 AND "T2"."AMOUNT_SOLD">700)
去掉hint,做子查询展开
SQL> select t1.CUST_LAST_NAME,t1.CUST_ID from sh.CUSTOMERS t1 where CUST_ID in (select CUST_ID from sh.SALES t2 where t2.AMOUNT_SOLD>700); 已选择4739行。 执行计划 ---------------------------------------------------------- Plan hash value: 2448612695 -------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop | -------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 7059 | 158K| 579 (5)| 00:00:07 | | | |* 1 | HASH JOIN SEMI | | 7059 | 158K| 579 (5)| 00:00:07 | | | | 2 | TABLE ACCESS FULL | CUSTOMERS | 55500 | 704K| 253 (1)| 00:00:04 | | | | 3 | PARTITION RANGE ALL| | 560K| 5469K| 321 (7)| 00:00:04 | 1 | 28 | |* 4 | TABLE ACCESS FULL | SALES | 560K| 5469K| 321 (7)| 00:00:04 | 1 | 28 | -------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - access("CUST_ID"="CUST_ID") 4 - filter("T2"."AMOUNT_SOLD">700) 统计信息 ---------------------------------------------------------- 1 recursive calls 0 db block gets 3492 consistent gets 0 physical reads 0 redo size 117719 bytes sent via SQL*Net to client 3984 bytes received via SQL*Net from client 317 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 4739 rows processed
情形2:
先将子查询转换为内嵌视图,然后和外部查询中的表、视图做表连接:
SQL> set autotrace traceonly SQL> select t1.CUST_LAST_NAME,t1.CUST_ID from sh.CUSTOMERS t1 2 where CUST_ID in 3 (select t2.CUST_ID from sh.SALES t2 join sh.PRODUCTS t3 on t2.PROD_ID=t3.PROD_ID where t2.AMOUNT_SOLD>700); 已选择4739行。 执行计划 ---------------------------------------------------------- Plan hash value: 2552061582 ------------------------------------------------------------------------------------------------------ | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop | ------------------------------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 7059 | 179K| 585 (6)| 00:00:08 | | | |* 1 | HASH JOIN SEMI | | 7059 | 179K| 585 (6)| 00:00:08 | | | | 2 | TABLE ACCESS FULL | CUSTOMERS | 55500 | 704K| 253 (1)| 00:00:04 | | | | 3 | VIEW | VW_NSO_1 | 560K| 7110K| 326 (8)| 00:00:04 | | | |* 4 | HASH JOIN | | 560K| 9844K| 326 (8)| 00:00:04 | | | | 5 | INDEX FULL SCAN | PRODUCTS_PK | 72 | 288 | 1 (0)| 00:00:01 | | | | 6 | PARTITION RANGE ALL| | 560K| 7657K| 321 (7)| 00:00:04 | 1 | 28 | |* 7 | TABLE ACCESS FULL | SALES | 560K| 7657K| 321 (7)| 00:00:04 | 1 | 28 | ------------------------------------------------------------------------------------------------------ Predicate Information (identified by operation id): --------------------------------------------------- 1 - access("CUST_ID"="CUST_ID") 4 - access("T2"."PROD_ID"="T3"."PROD_ID") 7 - filter("T2"."AMOUNT_SOLD">700) 统计信息 ---------------------------------------------------------- 1 recursive calls 0 db block gets 3493 consistent gets 0 physical reads 0 redo size 117719 bytes sent via SQL*Net to client 3984 bytes received via SQL*Net from client 317 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 4739 rows processed
4.3 视图合并
它是指优化器不再将目标SQL中视图的定义SQL语句当作一个独立的处理单元来单独执行,而是会将其拆开,把其定义SQL语句中的基表拿出来与外部查询中的表合并,这样合并后的SQL将只剩下外部查询中的表和原视图中的基表,不再会有视图出现。当然,不是所有的视图都能做视图合并,有些视图是不能做视图合并的,这种情况下Oracle就会将该视图的定义SQL语句当作一个独立的处理单元来单独执行。
分为:简单视图合并、外连接视图合并和复杂视图合并三种类型。
4.3.1 简单视图合并
简单视图合并是指那些不含外连接,以及所带视图的视图定义SQL语句中不含distinct、group by等聚合函数的目标SQL的视图合并。
目的是让优化器有更多的执行路径可以选择。
例子:
create or replace view SH.view_1 as select T2.PROD_ID from sh.SALES t2 join sh.CUSTOMERS t3 on t2.CUST_ID=t3.CUST_ID where t3.CUST_GENDER='MALE'; SELECT t1.PROD_ID,t1.PROD_NAME FROM sh.PRODUCTS t1 join sh.view_1 on t1.PROD_ID=view_1.PROD_ID and t1.PROD_LIST_PRICE>1000;
SQL> SELECT t1.PROD_ID,t1.PROD_NAME FROM 2 sh.PRODUCTS t1 3 join sh.view_1 on t1.PROD_ID=view_1.PROD_ID 4 and t1.PROD_LIST_PRICE>1000; 未选定行 执行计划 ---------------------------------------------------------- Plan hash value: 192254587 ----------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop | ----------------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 213K| 10M| 443 (6)| 00:00:06 | | | |* 1 | HASH JOIN | | 213K| 10M| 443 (6)| 00:00:06 | | | |* 2 | VIEW | index$_join$_005 | 27236 | 186K| 120 (2)| 00:00:02 | | | |* 3 | HASH JOIN | | | | | | | | | 4 | BITMAP CONVERSION TO ROWIDS| | 27236 | 186K| 2 (0)| 00:00:01 | | | |* 5 | BITMAP INDEX SINGLE VALUE | CUSTOMERS_GENDER_BIX | | | | | | | | 6 | INDEX FAST FULL SCAN | CUSTOMERS_PK | 27236 | 186K| 146 (1)| 00:00:02 | | | |* 7 | HASH JOIN | | 213K| 9160K| 321 (6)| 00:00:04 | | | |* 8 | TABLE ACCESS FULL | PRODUCTS | 17 | 595 | 3 (0)| 00:00:01 | | | | 9 | PARTITION RANGE ALL | | 918K| 8075K| 311 (4)| 00:00:04 | 1 | 28 | | 10 | TABLE ACCESS FULL | SALES | 918K| 8075K| 311 (4)| 00:00:04 | 1 | 28 | ----------------------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - access("T2"."CUST_ID"="T3"."CUST_ID") 2 - filter("T3"."CUST_GENDER"='MALE') 3 - access(ROWID=ROWID) 5 - access("T3"."CUST_GENDER"='MALE') 7 - access("T1"."PROD_ID"="T2"."PROD_ID") 8 - filter("T1"."PROD_LIST_PRICE">1000) 统计信息 ---------------------------------------------------------- 8 recursive calls 0 db block gets 2 consistent gets 0 physical reads 0 redo size 407 bytes sent via SQL*Net to client 508 bytes received via SQL*Net from client 1 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 0 rows processed
表连接顺序变成了CUSTOMERS-->(PRODUCTS-->SALES)
oracle对包含视图的目标SQL做简单视图合并也是有前提条件的,该SQL所包含视图的视图定义SQL语句中一定不能出现如下内容(包括但不限于):
- 集合运算符(UNION,UNION ALL, INITERSECT,MINUS)
- CONNECT BY 子句
- ROWNUM
- .......
不能做视图合并的例子:
create or replace view SH.view_1_union as select T2.PROD_ID from sh.SALES t2 join sh.CUSTOMERS t3 on t2.CUST_ID=t3.CUST_ID where t3.CUST_GENDER='MALE' union all select PROD_ID from sh.sales t2 where t2.amount_sold<700; SELECT t1.PROD_ID,t1.PROD_NAME FROM sh.PRODUCTS t1 join sh.view_1_union on t1.PROD_ID=view_1_union.PROD_ID and t1.PROD_LIST_PRICE>1000;
SQL> SELECT t1.PROD_ID,t1.PROD_NAME FROM 2 sh.PRODUCTS t1 3 join sh.view_1_union on t1.PROD_ID=view_1_union.PROD_ID 4 and t1.PROD_LIST_PRICE>1000; 未选定行 执行计划 ---------------------------------------------------------- Plan hash value: 3296476988 -------------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop | -------------------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 296K| 13M| 771 (7)| 00:00:10 | | | |* 1 | HASH JOIN | | 296K| 13M| 771 (7)| 00:00:10 | | | |* 2 | TABLE ACCESS FULL | PRODUCTS | 17 | 595 | 3 (0)| 00:00:01 | | | | 3 | VIEW | VIEW_1_UNION | 1277K| 15M| 759 (6)| 00:00:10 | | | | 4 | UNION-ALL | | | | | | | | |* 5 | HASH JOIN | | 918K| 14M| 438 (5)| 00:00:06 | | | |* 6 | VIEW | index$_join$_005 | 27236 | 186K| 120 (2)| 00:00:02 | | | |* 7 | HASH JOIN | | | | | | | | | 8 | BITMAP CONVERSION TO ROWIDS| | 27236 | 186K| 2 (0)| 00:00:01 | | | |* 9 | BITMAP INDEX SINGLE VALUE | CUSTOMERS_GENDER_BIX | | | | | | | | 10 | INDEX FAST FULL SCAN | CUSTOMERS_PK | 27236 | 186K| 146 (1)| 00:00:02 | | | | 11 | PARTITION RANGE ALL | | 918K| 8075K| 311 (4)| 00:00:04 | 1 | 28 | | 12 | TABLE ACCESS FULL | SALES | 918K| 8075K| 311 (4)| 00:00:04 | 1 | 28 | | 13 | PARTITION RANGE ALL | | 358K| 3153K| 321 (7)| 00:00:04 | 1 | 28 | |* 14 | TABLE ACCESS FULL | SALES | 358K| 3153K| 321 (7)| 00:00:04 | 1 | 28 | -------------------------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - access("T1"."PROD_ID"="VIEW_1_UNION"."PROD_ID") 2 - filter("T1"."PROD_LIST_PRICE">1000) 5 - access("T2"."CUST_ID"="T3"."CUST_ID") 6 - filter("T3"."CUST_GENDER"='MALE') 7 - access(ROWID=ROWID) 9 - access("T3"."CUST_GENDER"='MALE') 14 - filter("T2"."AMOUNT_SOLD"<700)
4.3.2 外连接视图合并
外连接视图合并是指针对那些使用了外连接,以及所带视图的视图定义SQL语句中不包含distinct、group by等聚合函数的目标SQL的视图合并。这里“使用外连接”的含义是指外部查询的表和视图之间使用了外连接,或者该视图的视图定义SQL语句中使用了外连接。
关于外连接视图合并有一个很常用的限制,即当目标视图在和外部查询的表做外连接时,该目标视图可以做外连接视图合并的前提条件是,
- 要么该视图被作为外连接的驱动表,
- 要么该视图虽然被作为外连接的被驱动表但它的视图定义SQL语句中只包含一个表。
4.3.3 复杂视图合并
指针对那些所带视图的视图定义SQL语句中含有group by或distinct的目标SQL的视图合并。
意味着把其定义SQL语句拆开,并把其中的基表拿出来和外部查询中的表合并。这通常意味着上述视图定义SQL语句中的group by或distinct操作会被推迟执行,也就是说,这种情况下通常会先做表连接,再做group by或distinct操作,而不是像未做复杂视图合并时那样先在视图内部做完group by或distinct操作,然后才和外部查询中的表做表连接。
例子:
create view view_3 as select CUST_ID,PROD_ID,sum(QUANTITY_SOLD) as total from sh.sales group by CUST_ID,PROD_ID;; select /*+merge(t3)*/t1.CUST_ID,t1.CUST_LAST_NAME from sh.CUSTOMERS t1 join view_3 t3 on t1.CUST_ID=t3.CUST_ID join sh.PRODUCTS t2 on t2.PROD_ID=t3.CUST_ID where t3.TOTAL>700 and t2.PROD_CATEGORY='Hardware' and t1.CUST_YEAR_OF_BIRTH=1977 and t1.CUST_MARITAL_STATUS='married';
SQL> select /*+merge(t3)*/t1.CUST_ID,t1.CUST_LAST_NAME 2 from sh.CUSTOMERS t1 3 join view_3 t3 on t1.CUST_ID=t3.CUST_ID 4 join sh.PRODUCTS t2 on t2.PROD_ID=t3.CUST_ID 5 where t3.TOTAL>700 6 and t2.PROD_CATEGORY='Hardware' 7 and t1.CUST_YEAR_OF_BIRTH=1977 8 and t1.CUST_MARITAL_STATUS='married'; 未选定行 执行计划 ---------------------------------------------------------- Plan hash value: 3109664783 ------------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop | ------------------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 4 | 320 | 442 (6)| 00:00:06 | | | |* 1 | FILTER | | | | | | | | | 2 | HASH GROUP BY | | 4 | 320 | 442 (6)| 00:00:06 | | | |* 3 | HASH JOIN | | 77 | 6160 | 441 (6)| 00:00:06 | | | | 4 | TABLE ACCESS BY INDEX ROWID | CUSTOMERS | 46 | 1610 | 115 (0)| 00:00:02 | | | | 5 | BITMAP CONVERSION TO ROWIDS| | | | | | | | | 6 | BITMAP AND | | | | | | | | |* 7 | BITMAP INDEX SINGLE VALUE| CUSTOMERS_YOB_BIX | | | | | | | |* 8 | BITMAP INDEX SINGLE VALUE| CUSTOMERS_MARITAL_BIX | | | | | | | |* 9 | HASH JOIN | | 1874 | 84330 | 326 (8)| 00:00:04 | | | | 10 | TABLE ACCESS BY INDEX ROWID| PRODUCTS | 14 | 462 | 3 (0)| 00:00:01 | | | |* 11 | INDEX RANGE SCAN | PRODUCTS_PROD_CAT_IX | 14 | | 1 (0)| 00:00:01 | | | | 12 | PARTITION RANGE ALL | | 918K| 10M| 316 (6)| 00:00:04 | 1 | 28 | | 13 | TABLE ACCESS FULL | SALES | 918K| 10M| 316 (6)| 00:00:04 | 1 | 28 | ------------------------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter(SUM("QUANTITY_SOLD")>700) 3 - access("T1"."CUST_ID"="CUST_ID") 7 - access("T1"."CUST_YEAR_OF_BIRTH"=1977) 8 - access("T1"."CUST_MARITAL_STATUS"='married') 9 - access("T2"."PROD_ID"="CUST_ID") 11 - access("T2"."PROD_CATEGORY"='Hardware') 统计信息 ---------------------------------------------------------- 8 recursive calls 0 db block gets 1997 consistent gets 0 physical reads 0 redo size 412 bytes sent via SQL*Net to client 508 bytes received via SQL*Net from client 1 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 0 rows processed
下面是没做视图合并
SQL> select t1.CUST_ID,t1.CUST_LAST_NAME 2 from sh.CUSTOMERS t1 3 join view_3 t3 on t1.CUST_ID=t3.CUST_ID 4 join sh.PRODUCTS t2 on t2.PROD_ID=t3.CUST_ID 5 where t3.TOTAL>700 6 and t2.PROD_CATEGORY='Hardware' 7 and t1.CUST_YEAR_OF_BIRTH=1977 8 and t1.CUST_MARITAL_STATUS='married'; 未选定行 执行计划 ---------------------------------------------------------- Plan hash value: 215761499 --------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop | --------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 57 | 377 (21)| 00:00:05 | | | | 1 | NESTED LOOPS | | | | | | | | | 2 | NESTED LOOPS | | 1 | 57 | 377 (21)| 00:00:05 | | | | 3 | NESTED LOOPS | | 1 | 34 | 376 (21)| 00:00:05 | | | | 4 | VIEW | VIEW_3 | 1 | 13 | 375 (21)| 00:00:05 | | | |* 5 | FILTER | | | | | | | | | 6 | HASH GROUP BY | | 1 | 12 | 375 (21)| 00:00:05 | | | | 7 | PARTITION RANGE ALL | | 918K| 10M| 316 (6)| 00:00:04 | 1 | 28 | | 8 | TABLE ACCESS FULL | SALES | 918K| 10M| 316 (6)| 00:00:04 | 1 | 28 | |* 9 | TABLE ACCESS BY INDEX ROWID| PRODUCTS | 1 | 21 | 1 (0)| 00:00:01 | | | |* 10 | INDEX UNIQUE SCAN | PRODUCTS_PK | 1 | | 0 (0)| 00:00:01 | | | |* 11 | INDEX UNIQUE SCAN | CUSTOMERS_PK | 1 | | 0 (0)| 00:00:01 | | | |* 12 | TABLE ACCESS BY INDEX ROWID | CUSTOMERS | 1 | 23 | 1 (0)| 00:00:01 | | | --------------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 5 - filter(SUM("QUANTITY_SOLD")>700) 9 - filter("T2"."PROD_CATEGORY"='Hardware') 10 - access("T2"."PROD_ID"="T3"."CUST_ID") 11 - access("T1"."CUST_ID"="T3"."CUST_ID") 12 - filter("T1"."CUST_YEAR_OF_BIRTH"=1977 AND "T1"."CUST_MARITAL_STATUS"='married') 统计信息 ---------------------------------------------------------- 8 recursive calls 0 db block gets 1720 consistent gets 0 physical reads 0 redo size 412 bytes sent via SQL*Net to client 508 bytes received via SQL*Net from client 1 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 0 rows processed
4.4 星型转换
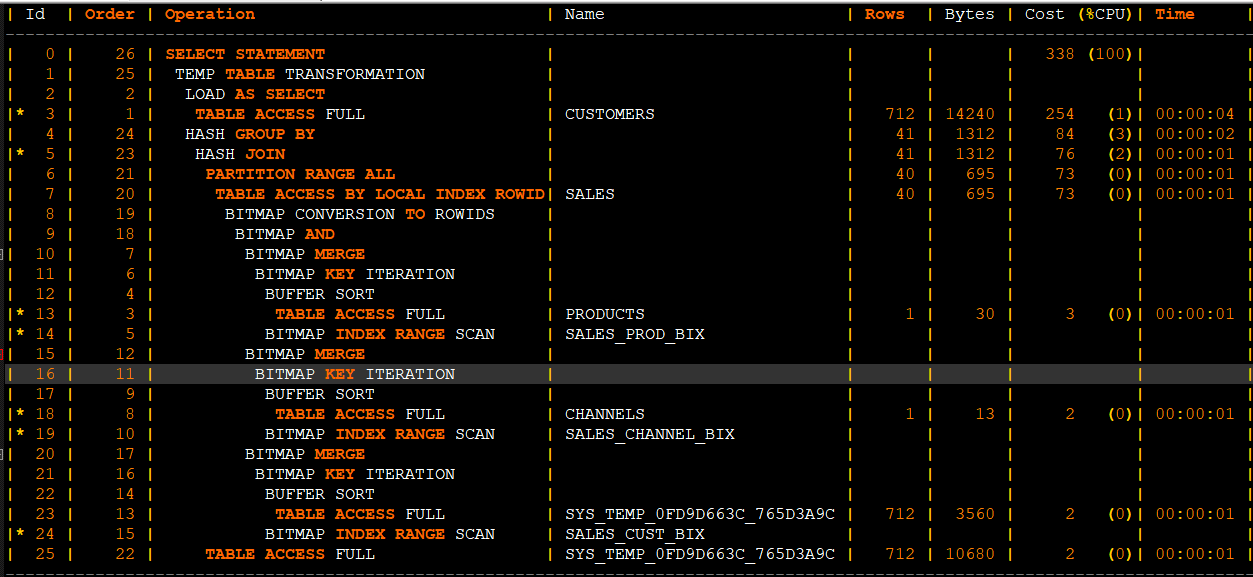
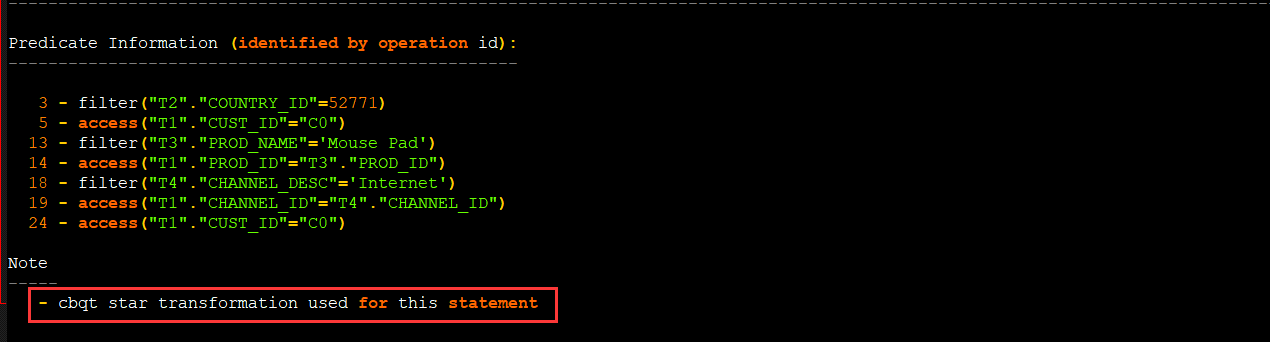
它的核心是将原星型连接中针对各个维度表的限制条件,通过等价改写的方式以额外的子查询施加到事实表上,然后通过对事实表上各连接列上已存在的位图索引间的位图操作(如按位与、按位或等),来达到有效减少事实表上待访问的数据量,避免对事实表做全表扫描的目的,这就可以有效缩短原SQL的执行时间,提高其执行效率。
例子:
select /*cs1*/t2.CUST_CITY,sum(t1.AMOUNT_SOLD) as AMOUNT_SOLD_total from sh.SALES t1 ,sh.CUSTOMERS t2,sh.PRODUCTS t3,sh.CHANNELS t4 where t1.CUST_ID=t2.CUST_ID and t1.PROD_ID=t3.PROD_ID and t1.CHANNEL_ID=t4.CHANNEL_ID and t2.COUNTRY_ID=52771 and t3.PROD_NAME='Mouse Pad' and t4.CHANNEL_DESC='Internet' group by t2.CUST_CITY
4.5 连接谓词推入
它是指虽然优化器还是会把该SQL中视图的定义SQL语句当作一个独立的处理单元来单独执行,但此时优化器会把原本处于该视图外部查询中和该视图之间的连接条件推入到该视图的定义SQL语句内部 ,这样做是为了能使用上该视图内部相关基表上的索引,进而能走出基于索引的嵌套循环连接。
Oracle能否能做连接谓词推入与目标视图的类型、该视图与外部查询之间的连接类型以及连接方法有关。到目前为止,Oracle仅仅支持如下类型的视图做连接谓词推入。
- 视图定义SQL语句中包含UNION ALL/UNION 的视图
- 视图定义SQL语句中包含DISTINCT的视图
- 视图定义SQL语句中包含GROUP BY的视图
- 和外部查询之间的连接类型是外连接的视图
- 和外部查询之间的连接方法是反连接的视图
- 和外部查询之间的连接方法是半连接的视图
4.6 连接因式分解
它是指优化器在处理以UNION ALL连接的目标SQL的各个分支时,不再原封不动地分别重复执行每个分支,而是会把各个分支中公共的部分提出来作为一个单独的结果集,然后再和原UNION ALL中剩下的部分做表连接。
连接因式分解在Oracle 11gR2中才被引入,它的好处是显而易见的。如果不把UNION ALL中公共的部分提出来,则意味着这些公共部分中所包含的表会在UNION ALL的各个分支中被重复访问;而连接因式分解则能够在最大程度上避免这种重复访问现象的产生,当UNION ALL的公共部分所包含的表的数据量很大时,即便只是减少依次对大表的重复访问,那也意味着执行效率的巨大提升。
在Oracle 11gR2及其后续的版本中,即使由于在视图定义SQL语句中包含了集合运算符UNION ALL而导致Oracle不能对其做视图合并,Oracle也不一定会把该视图的定义SQL语句当作一个整体来单独运行,因为此时Oracle还可能会对其做连接因式分解。
4.7 表扩展
针对分区表
它是指当目标SQL中分区表的某个局部分区索引由于某种原因在某些分区上变得不可用(索引状态为UNUSABLE)时,Oracle能将原目标SQL等价改写成按分区UNION ALL的形式,这样除了那些不可用的分区所对应的UNION ALL分支之外,其他分区所对应的UNION ALL分支还是可以正常使用该局部分区索引。
表扩展在Oracle 11gR2中才被引入,它的好处是显而易见的。如果不做表扩展,则对于上述局部分区索引而言,只要在一个分区上它的状态为UNUSABLE,则整个目标SQL就不能使用该局部分区索引。
4.8 表移除
它是指优化器会把虽然在目标SQL中存在,但是其存在与否对最终执行结果没有影响的表从该目标SQL中移除,这样优化器至少可以做一次表连接,进而就提高了原目标SQL的执行效率。
4.9 Oralce如何处理SQL语句中的IN
在Oralce数据库里,IN和OR是等价的,优化器在处理带IN的目标SQL时实际上会将其转换为带OR的等价改写SQL,也就是,本节介绍的处理带IN的目标SQL的方法也同样适用于带OR的目标SQL。
优化器在处理带IN的目标SQL时,通常会采用如下这四种方法:
- 使用IN-List Iterator。
- 使用IN-List Expansion。
- 使用IN-List Filter。
- 对IN做子查询展开,或者既做子查询展开又做视图合并。
4.9.1 IN-List Iterator
IN-List Iterator是针对IN后面是常量集合的一种处理方法。此时优化器会遍历目标SQL中IN后面的常量集合中的每一个值,然后去做比较,看目标结果集中是否存在和这个值匹配的记录。如果存在匹配记录,则这个记录就会成为该SQL的最终返回结果集中的一员;如果不存在匹配记录,则优化器会继续遍历IN后面的常量集合中的下一个值,直到该常量集合遍历完毕。
关于IN-List Iterator,有如下几点需要注意:
- IN-List Iterator是Oracle针对目标SQL的IN后面是常量集合的首先处理方法,它的处理效率通常都会比IN-List Expansion高。
- Oracle能用IN-List Iterator来处理IN的前提条件是IN所在的列上一定要有索引。
- 不能强制让Oracle走IN-List Iterator类型的执行计划,Oracle里也没有相关的强制走IN-List Iterator的Hint,但可以通过联合设置10142和10157事件来禁掉IN-List Iterator。
select * from emp_test where DEPTNO in (10,20,30) Plan hash value: 3233926416 -------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | -------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 14 |00:00:00.01 | 5 | | 1 | INLIST ITERATOR | | 1 | | 14 |00:00:00.01 | 5 | | 2 | TABLE ACCESS BY INDEX ROWID| EMP_TEST | 3 | 14 | 14 |00:00:00.01 | 5 | |* 3 | INDEX RANGE SCAN | IDX_EMP_TEST_DEPTNO | 3 | 1 | 14 |00:00:00.01 | 3 | -------------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 3 - access(("DEPTNO"=10 OR "DEPTNO"=20 OR "DEPTNO"=30)) Note ----- - dynamic sampling used for this statement (level=2)
4.9.2 IN-List Expansion/OR Expansion
IN-List Expansion/OR Expansion(IN-List Expansion又称为OR Expansion,两者等价)是针对IN后面是常量集合的另外一种处理方法,它是指优化器会把目标SQL中IN后面的常量集合拆开,把里面的每个常量都提出来形成一个分支,各分支之间用UNION ALL来连接,即IN-List Expansion的本质是把带IN的目标SQL等价改写成以UNION ALL连接的各个分支。
IN-List Expansion的好处是改成成以UNION ALL连接的分支后,各个分支就可以各自走索引、分区修剪(Partition Pruning)、表连接等相关的执行计划而互不干扰。坏处就是要分别解析分支。
SQL> select /*+use_concat*/ * from emp_test where deptno=20 or mgr=7902; 执行计划 ---------------------------------------------------------- Plan hash value: 1144971629 ---------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ---------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 5 | 435 | 2 (0)| 00:00:01 | | 1 | CONCATENATION | | | | | | | 2 | TABLE ACCESS BY INDEX ROWID| EMP_TEST | 1 | 87 | 1 (0)| 00:00:01 | |* 3 | INDEX RANGE SCAN | IDX_EMP_TEST_MGR | 1 | | 1 (0)| 00:00:01 | |* 4 | TABLE ACCESS BY INDEX ROWID| EMP_TEST | 4 | 348 | 1 (0)| 00:00:01 | |* 5 | INDEX RANGE SCAN | IDX_EMP_TEST_DEPTNO | 1 | | 1 (0)| 00:00:01 | ---------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 3 - access("MGR"=7902) 4 - filter(LNNVL("MGR"=7902)) 5 - access("DEPTNO"=20) Note ----- - dynamic sampling used for this statement (level=2)
4.9.3 IN-List Filter
IN-List Filter是针对IN后面是子查询的一种处理方法,优化器会把IN后面的子查询所对应的结果集当作过滤条件,并且走Filter类型的执行计划。
需要满足以下两个条件:
目标SQL的IN后面是子查询而不是常量的集合。
Oracle未对目标SQL的IN后面的子查询做子查询展开。
SQL> select * from emp where DEPTNO in (select /*+no_unnest*/ deptno from dept where LOC='CHICAGO'); 已选择6行。 执行计划 ---------------------------------------------------------- Plan hash value: 2809975276 ---------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ---------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 5 | 195 | 6 (0)| 00:00:01 | |* 1 | FILTER | | | | | | | 2 | TABLE ACCESS FULL | EMP | 14 | 546 | 3 (0)| 00:00:01 | |* 3 | TABLE ACCESS BY INDEX ROWID| DEPT | 1 | 11 | 1 (0)| 00:00:01 | |* 4 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 (0)| 00:00:01 | ---------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter( EXISTS (SELECT /*+ NO_UNNEST */ 0 FROM "DEPT" "DEPT" WHERE "DEPTNO"=:B1 AND "LOC"='CHICAGO')) 3 - filter("LOC"='CHICAGO') 4 - access("DEPTNO"=:B1)
4.9.4 对IN做子查询展开/视图合并
指优化器对目标SQL的IN后面的子查询做子查询展开,或者既做子查询展开又做视图合并。
能对IN做子查询展开/视图合并,意味着目标SQL要满足如下前提条件。
- 目标SQL的IN后面是子查询而不是常量的集合。
- Oracle能对目标SQL的IN后面的子查询做子查询展开。
- IN后面的子查询不包含视图,Oracle对其做了子查询展开。
- IN后面的子查询包含视图,但由于该视图不能做视图合并,所以Oracle只能对其做子查询展开。
- IN后面的子查询包含视图,但由于该视图可以做视图合并,所以Oracle既对其做了子查询展开,又对其做了视图合并。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号