CNN网络的基本介绍(二)
四、激活函数
激活函数又称非线性映射,顾名思义,激活函数的引入是为了增加整个网络的表达能力(即非线性)。若干线性操作层的堆叠仍然只能起到线性映射的作用,无法形成复杂的函数。常用的函数有sigmoid、双曲正切、线性修正单元函数等等。 使用一个神经网络时,需要决定使用哪种激活函数用隐藏层上,哪种用在输出节点上。
比如,在神经网路的前向传播中,![]() 这两步会使用到sigmoid函数。sigmoid函数在这里被称为激活函数。
这两步会使用到sigmoid函数。sigmoid函数在这里被称为激活函数。
sigmoid函数
之前在线性回归中,我们用过这个函数,使我们的输出值平滑地处于0~1之间。
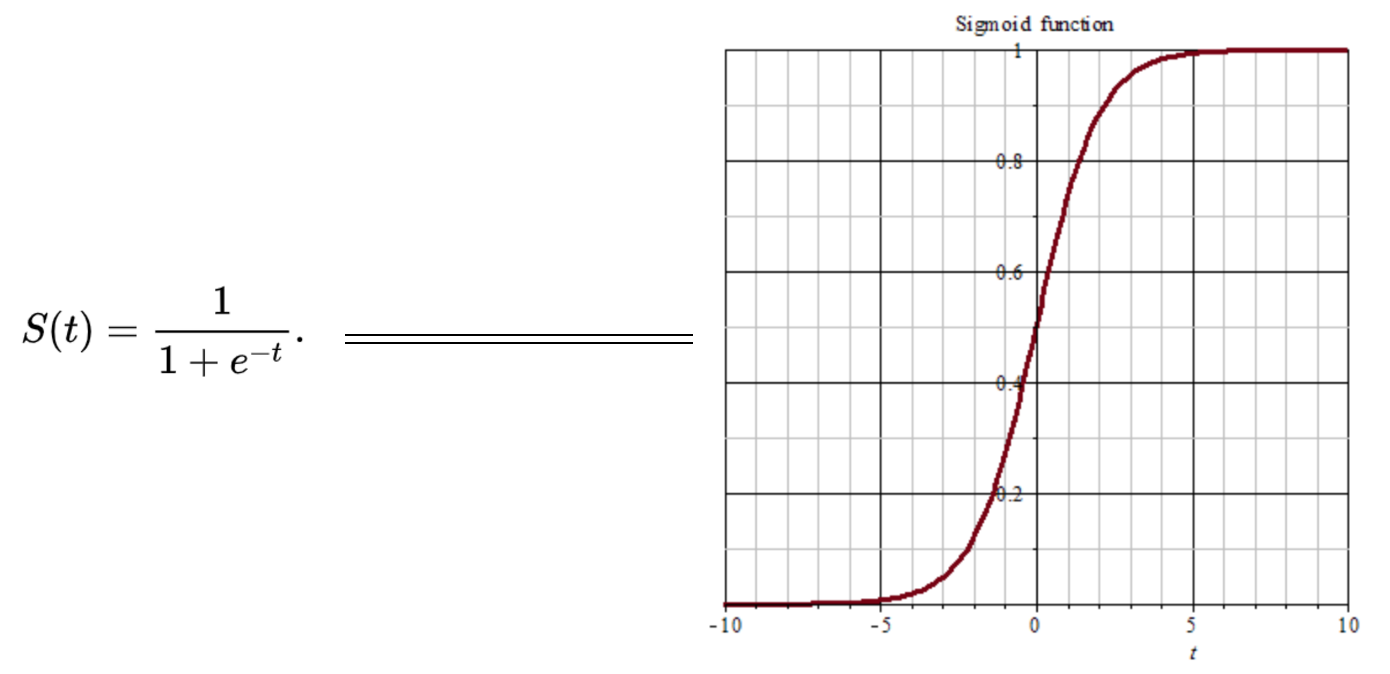
观察图形我们发现,当大于5或者小于-5的值无论多大或多小都会被压缩到1或0。如此便带来一个严重问题,即梯度的“饱和效应”。大于5或者小于-5部分的梯度接近0,这回导致在误差反向传播过程中导数处于该区域的误差就很难甚至根本无法传递至前层,进而导致整个网络无法训练(导数为0将无法跟新网络参数)。
此外,在参数初始化的时候还需要特别注意,要避免初始化参数直接将输出值带入这一区域,比如初始化参数过大,将直接引发梯度饱和效应而无法训练。
说明:除非输出层是一个二分类问题否则基本不会用它。
双曲正切函数
tanh函数是sigmoid的向下平移和伸缩后的结果。对它进行了变形后,穿过了原点,并且值域介于+1和-1之间。
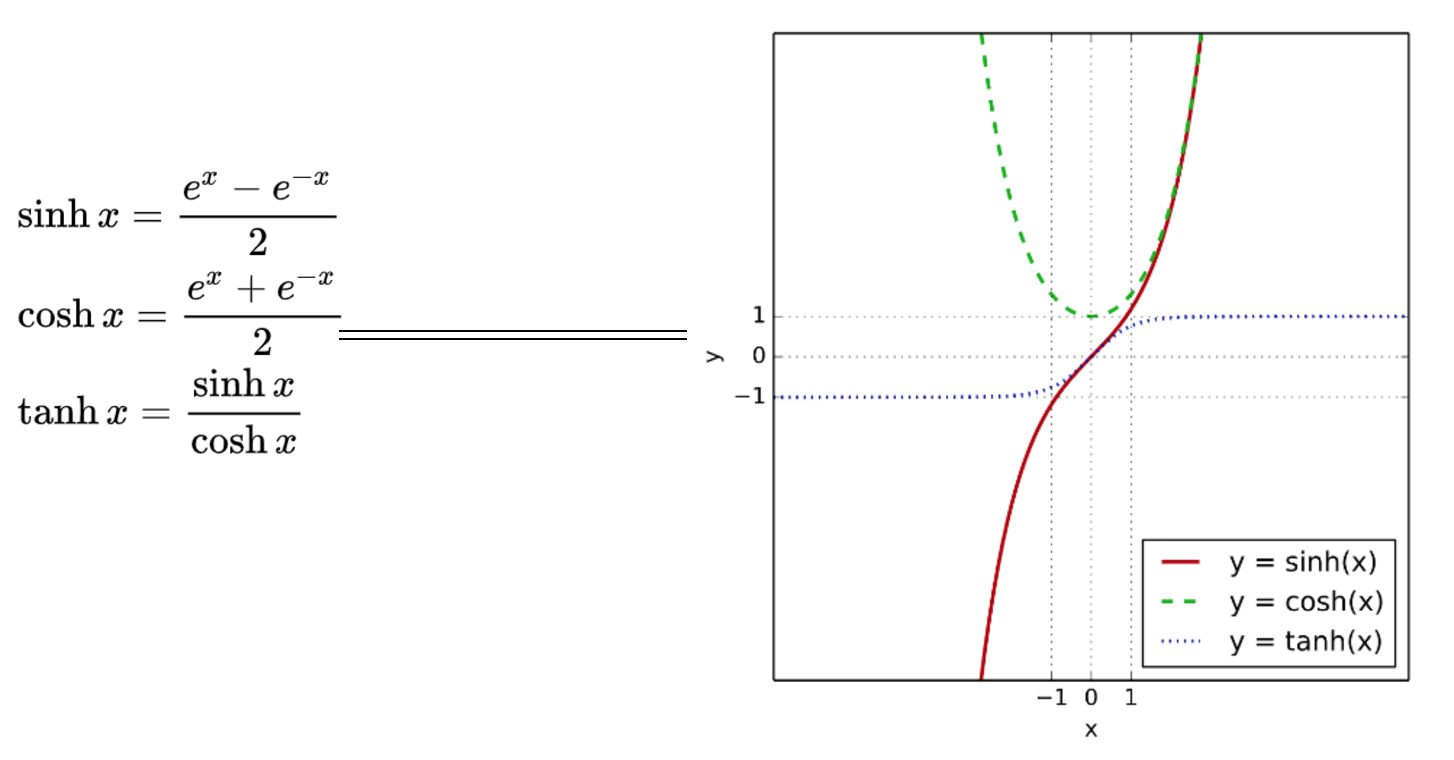
结果表明,如果在隐藏层上使用函数tanh效果总是优于sigmoid函数。因为函数值域在-1和+1的激活函数,其均值是更接近零均值的。在训练一个算法模型时,如果使用tanh函数代替sigmoid函数中心化数据,使得数据的平均值更接近0而不是0.5.
说明:tanh是非常优秀的,几乎适合所有场合
修正线性单元的函数(ReLu)
sigmoid函数与双曲正切函数都有一个共同的问题,在Z特别大或者特别小的情况下,导致梯度或者函数的斜率变得特别小,最后就会接近于0,导致降低梯度下降的速度。
线性整流函数(Rectified Linear Unit, ReLU),又称修正线性单元, 是一种人工神经网络中常用的激活函数(activation function),通常指代以斜坡函数及其变种为代表的非线性函数。
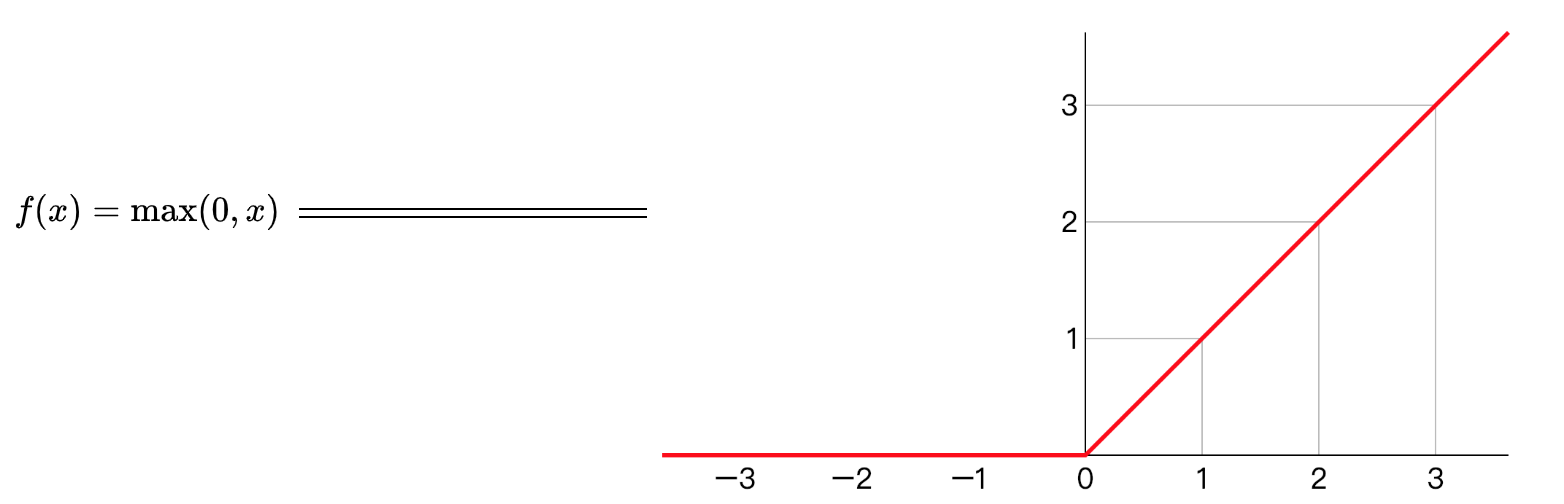
Relu作为神经元的激活函数,定义了该神经元在线性变换 


只要是WTX+b正值的情况下,导数恒等于1,当WTX+b是负值的时候,导数恒等于0。从实际上来说,当使用的导数时,WTX+b=0的导数是没有定义的。
选择激活函数的经验法则:
如果输出是0、1值(二分类问题),则输出层选择sigmoid函数,然后其它的所有单元都选择Relu函数。
最常用的默认函数,,如果不确定用哪个激活函数,就使用ReLu或者Leaky ReLu
带泄露线性整流函数(Leaky ReLU)
在输入值 为负的时候,带泄露线性整流函数(Leaky ReLU)的梯度为一个常数 

五、卷积运算
卷积是一种有效提取图片特征的方法。一般用一个正方形卷积核,遍历图片上的每一个像素点。图片与卷积核重合区域内相对应的每一个像素值乘卷积核 、内相对应点的权重,然后求和,再加上偏置后,最后得到输出图片中的一个像素值。
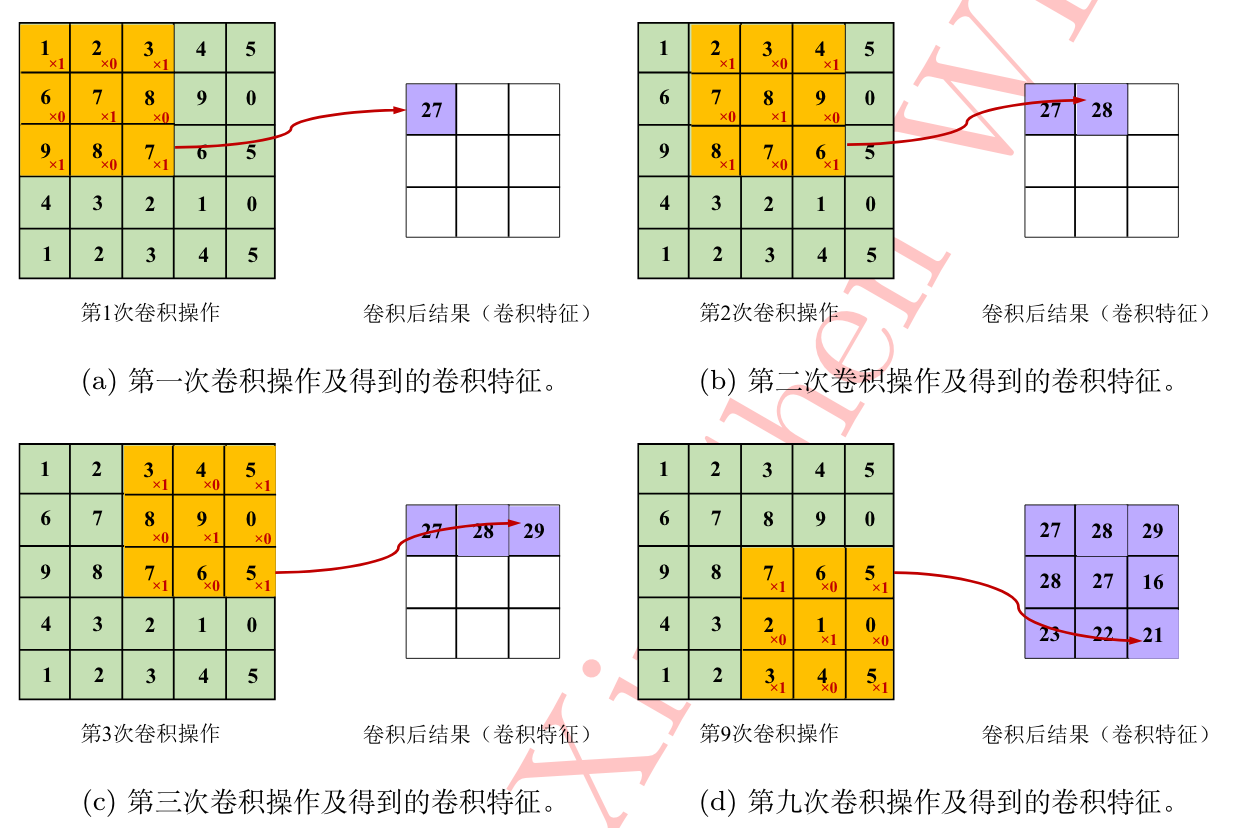
卷积操作的作用
卷积是一种局部操作,通过一定大小的卷积核作用于局部图像区域获得图像的局部信息。
我们现在使用三种边缘卷积核(亦称滤波器),整体边缘滤波器、横向边缘滤波器和纵向边缘滤波器。
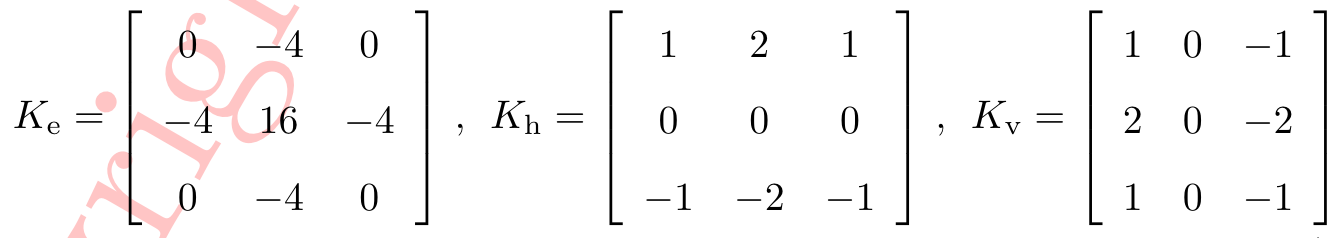
对立方体卷积
所谓的立方体卷积是指对多通道色彩的图形进行卷积操作。
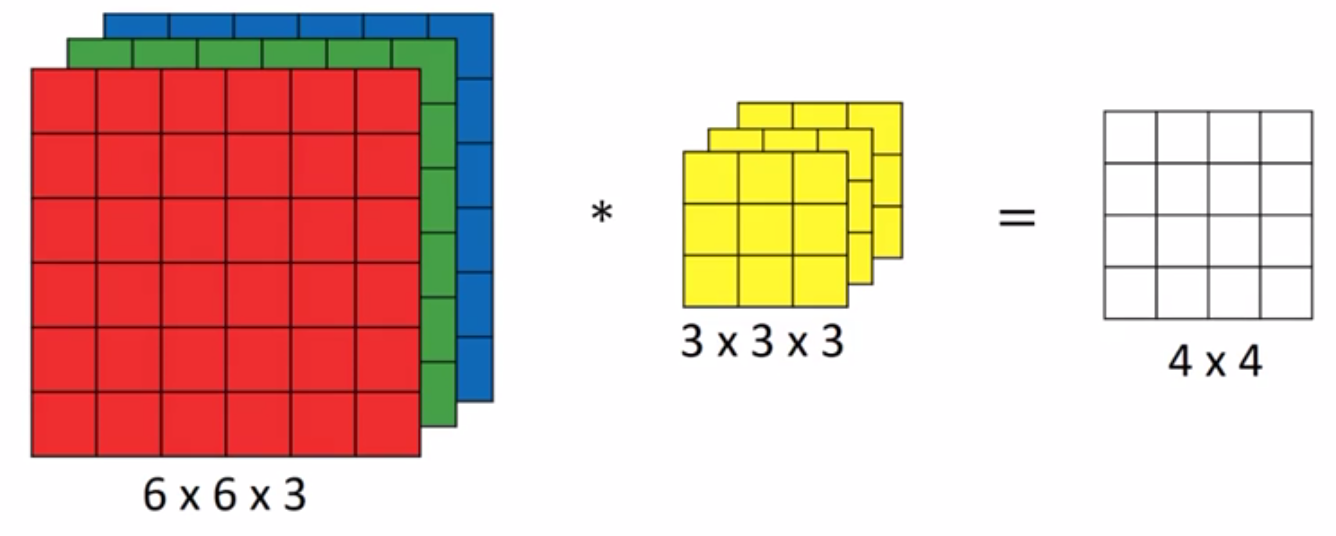
我们需要有对应通道数的卷积层,此处为3层,每一层处理一个通道,按照卷积操作执行,最后会生成27个数据,将其合计后填入输出矩阵中即可。
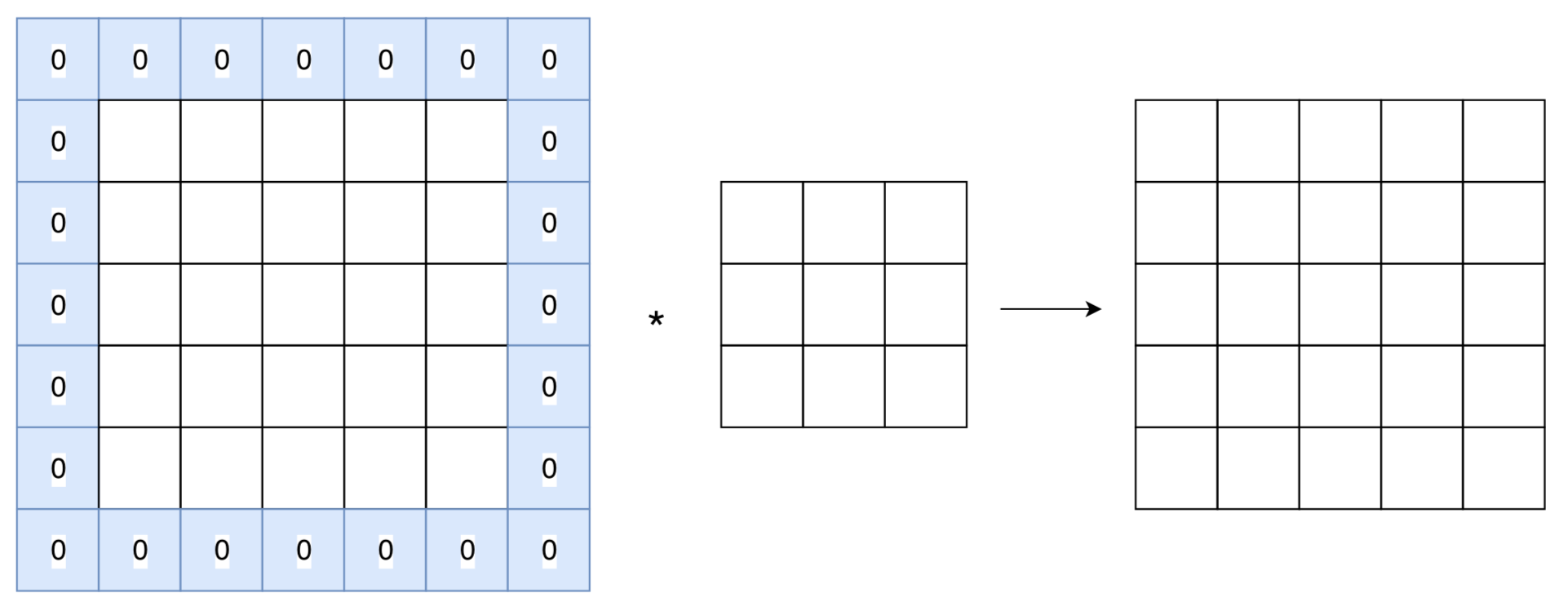
填充Padding
在卷积操作中,卷积后的图形将会小于原始图形,并且图形缩小会导致丢失一些边缘信息,我们可以卷积操作之前对输入图形周围进行全零填充,来保证输出图形的尺寸和输入图形的尺寸一致。
设置步长
在上述的卷积过程中,卷积层在原始图形中沿着水平方向每次移动一格,最后输出图形的大小为5*5,当然我们也可以设置移动的间隔,比如为2.这样生成的输出图形的大小就会减小到3*3。
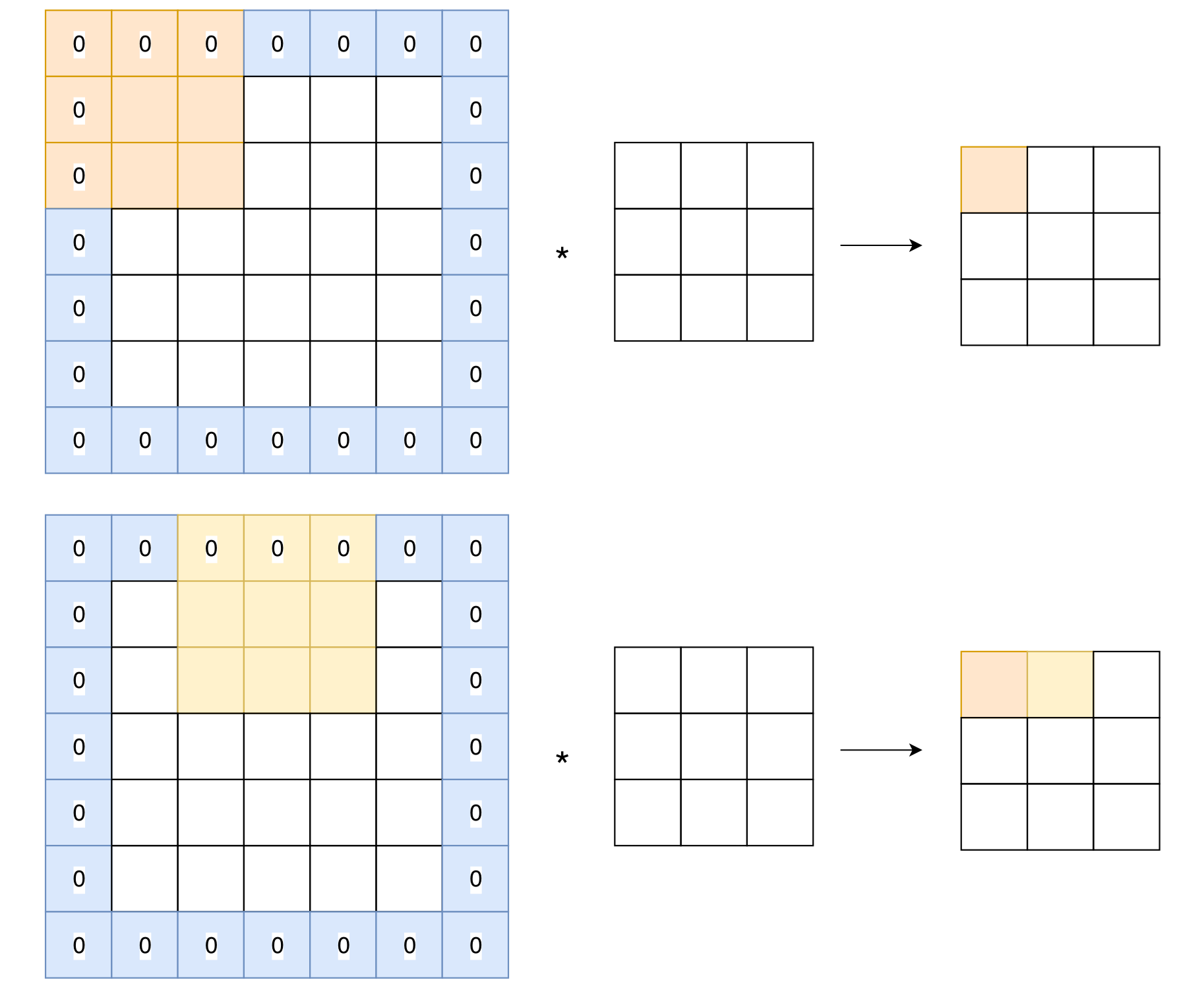
计算公式是这样的:(原始图形大小+2*填充厚度)/步长+1.
六、池化
池化(Pooling)是卷积神经网络中另一个重要的概念,它实际上是一种形式的降采样。有多种不同形式的非线性池化函数,而其中“最大池化(Max pooling)”是最为常见的。它是将输入的图像划分为若干个矩形区域,对每个子区域输出最大值。直觉上,这种机制能够有效地原因在于,在发现一个特征之后,它的精确位置远不及它和其他特征的相对位置的关系重要。池化层会不断地减小数据的空间大小,因此参数的数量和计算量也会下降,这在一定程度上也控制了过拟合。通常来说,CNN的卷积层之间都会周期性地插入池化层。
池化层通常会分别作用于每个输入的特征并减小其大小。当前最常用形式的池化层是每隔2个元素从图像划分出2*2的区块,然后对每个区块中的4个数取最大值。这将会减少75%的数据量。
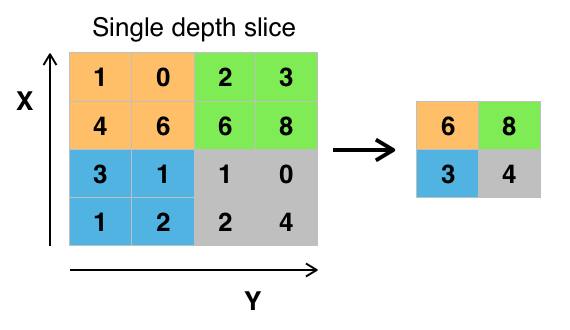
池化的作用
池化操作后的结果相比其输入缩小了。池化层的引入是仿照人的视觉系统对视觉输入对象进行降维和抽象。在卷积神经网络过去的工作中,研究者普遍认为池化层有如下三个功效:
1.特征不变形:池化操作是模型更加关注是否存在某些特征而不是特征具体的位置。
2.特征降维:池化相当于在空间范围内做了维度约减,从而使模型可以抽取更加广范围的特征。同时减小了下一层的输入大小,进而减少计算量和参数个数。
3.在一定程度上防止过拟合,更方便优化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号