
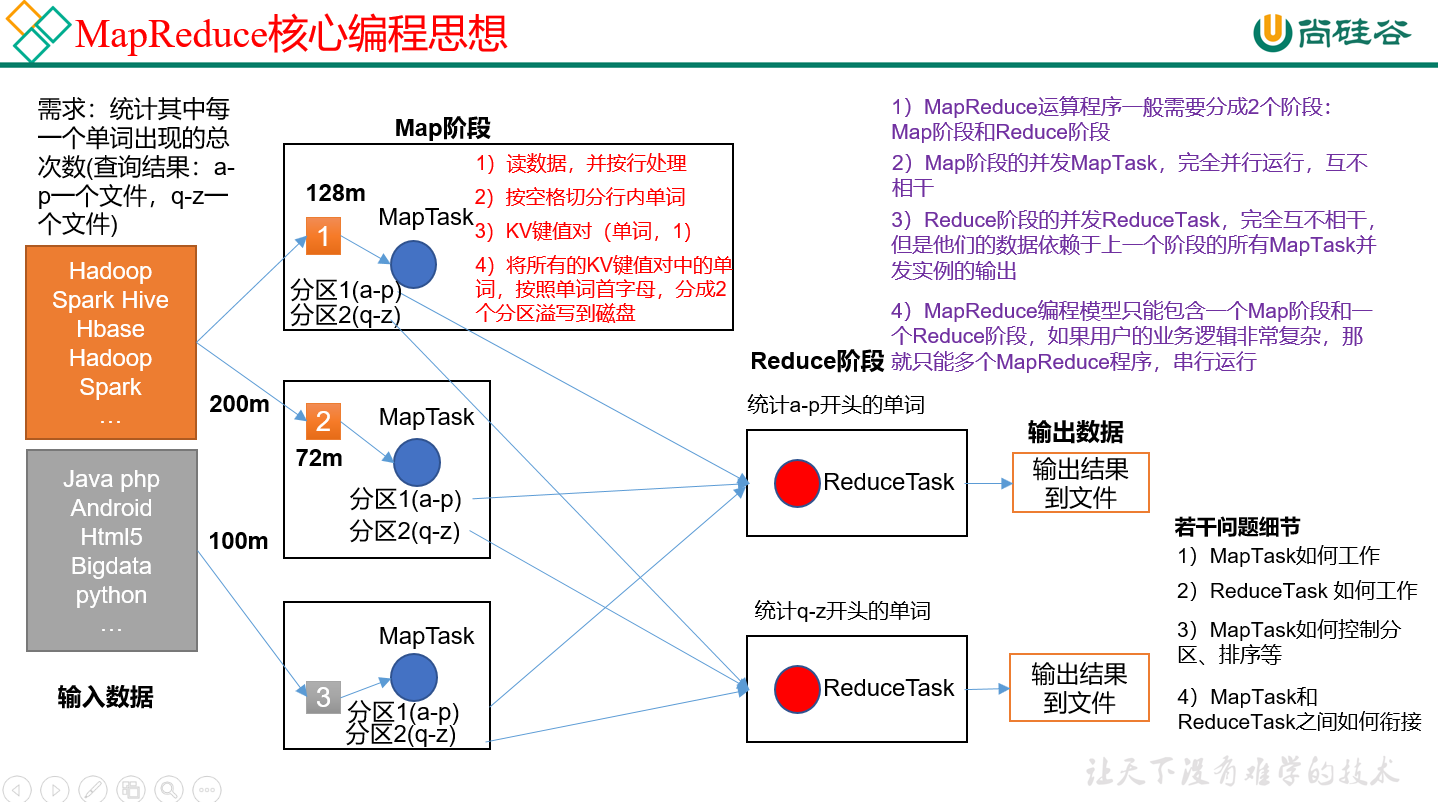
MapReduce的过程总结
MapReduce 分为:
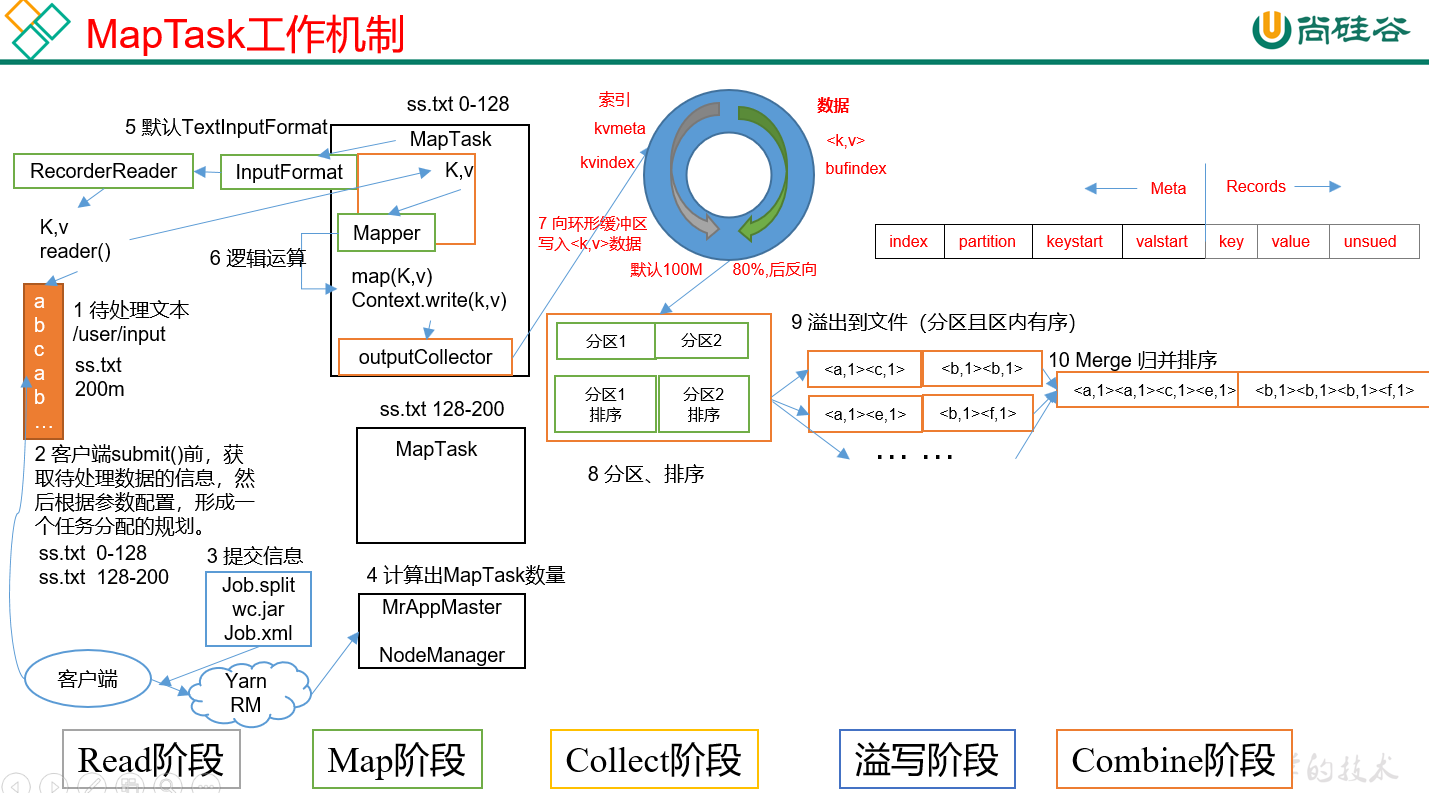
1) MapTask :
1.Read阶段:逻辑切片 128M / Maptask 读数据解析出一个个key/value。
2.Map阶段: 把key/value 写入到map中去(处理业务逻辑)
3.Collect阶段:将生成的key/value分区(调用Partitioner)排序,并写入一个环形内存缓冲区中。
4.溢写阶段:分区写入到文件且有序。
5.Combine阶段:归并排序,把众多小文件合并成大文件。
一个大文件逻辑切分成好多片(128mb一片),一片启动一个map, 多个map之间处理的数据有相同的分区但是处理的不同。有可能第二片里面也有分区1的数据。第一片里也有。
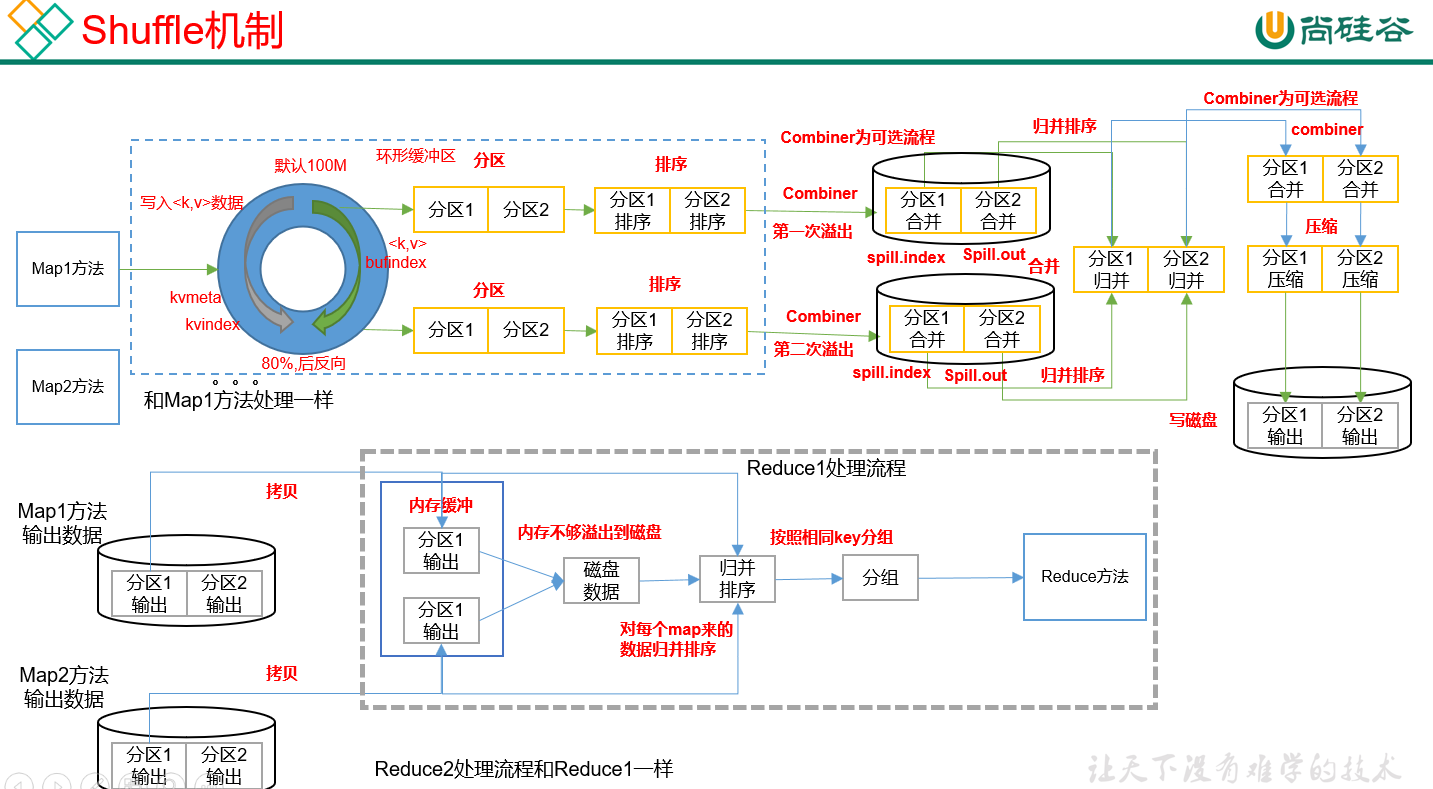
2)Shuffer:Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。(和两个有重合部分)
1.Map的shuffer过程:就是从Map里面写入到环形缓冲区中要先进行分区然后排序再百分之80的时候溢写到磁盘中,接着把map之间分区数据归并排序 (多个有序的小文件形成一个大的有序的文件)然后可压缩后 再溢写到磁盘对应的分区上。
2.Reduce的shuffer过程: 把分区数据拷贝到内存缓冲区中(如果不够就溢写到磁盘中 )然后进行归并排序,生成一个大的有序的文件。按照相同key分成一组!之后放到reduce里面去。 (进入到reduce里面的数据,key必须相同)
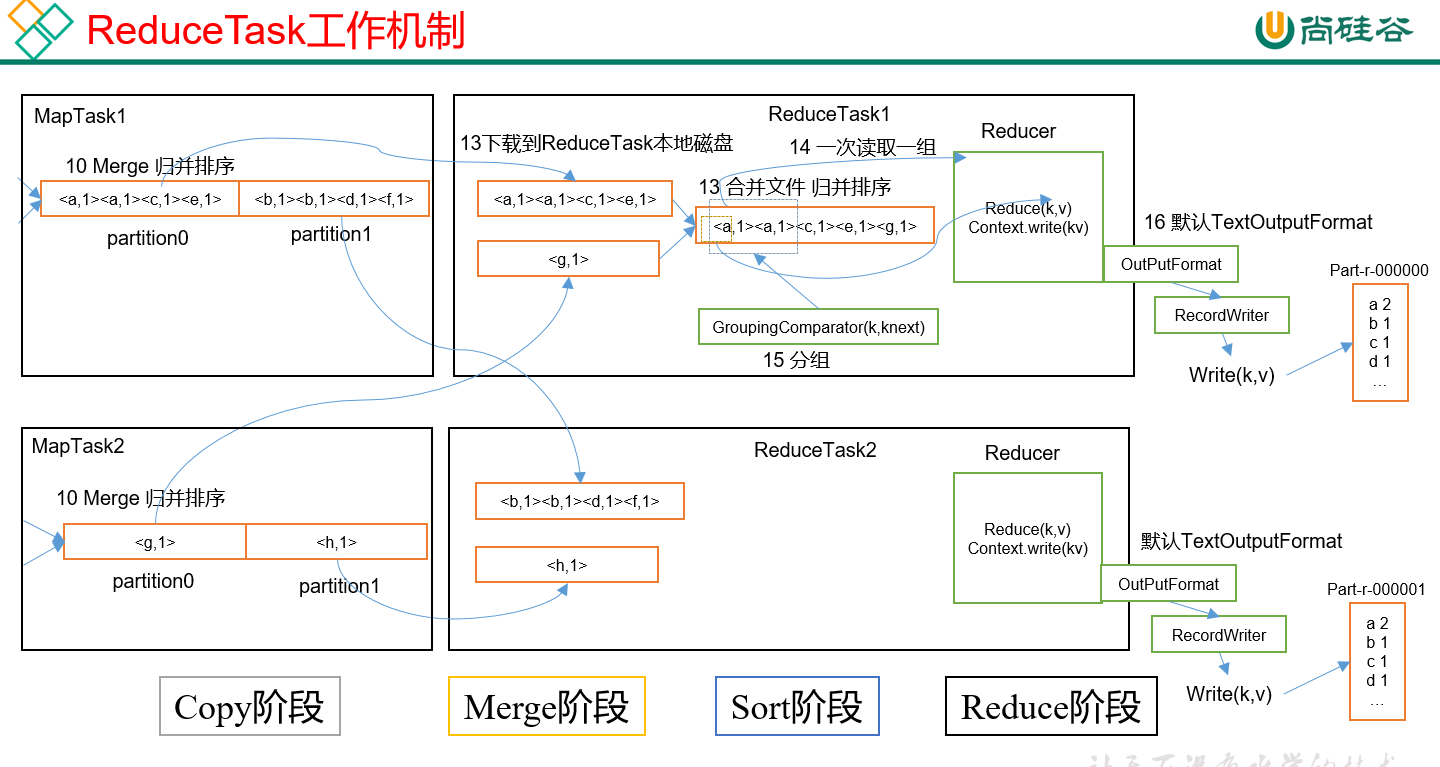
3)ReduceTask
1.Copy阶段:将对应分区下的数据拷贝到reduce,没有达到内存上限就存到内存当中,如果超过了就存到磁盘中。
2.Merge阶段: 多个文件合并成一个大的文件。
3.Sort阶段:然后将大文件排序。
4.Reduce阶段:将相同key的拷贝到一个reduce文件里面去,最终处理完输出。
数据倾斜:就是其他人忙的要死,他闲的要命。
combiner :在MAPtask的局部汇总操作,父类是Reducer 区别是combiner在map操作 reducer在reduce操作。(不适合求平均值 适合累加汇总操作)。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号