
hive总结
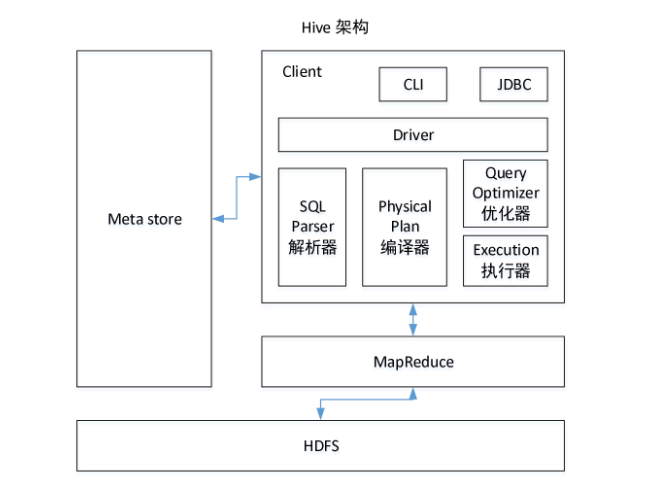
AST (Abstract Syntax Tree)是抽象语法树的英文简称。 命令行界面(英语:command-line interface,缩写:CLI)
1.客户通过命令行界面或者JDBC访问hive
2.第二步通过SQL解析器把输入的HQL语句解析。 再通过编译器翻译成MapReduce任务。 然后优化器对生成的MapReduce任务进行优化。
3.通过执行器提交给Yarn 执行任务,执行任务的时候会访问元数据去从HDFS找对应数据。通过MR去执行,最终给我们返回一个结果。
Hive和数据库比较
Hive 和数据库除了拥有类似的查询语言,再无类似之处。
1)数据存储位置
Hive 存储在 HDFS 。数据库将数据保存在块设备或者本地文件系统中。(块设备是i/o设备中的一类,是将信息存储在固定大小的块中,每个块都有自己的地址,还可以在设备的任意位置读取一定长度的数据,例如硬盘,U盘,SD卡等。)
2)数据更新
Hive中不建议对数据的改写。而数据库中的数据通常是需要经常进行修改的,
3)执行延迟
Hive 执行延迟较高。数据库的执行延迟较低。当然,这个是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive的并行计算显然能体现出优势。
4)数据规模
Hive支持很大规模的数据计算;数据库可以支持的数据规模较小。
内部表和外部表
1)管理表(内部表默认创建的表):当我们删除一个管理表时,Hive也会删除这个表中数据。管理表不适合和其他工具共享数据。
2)外部表:删除该表并不会删除掉原始数据,删除的是表的元数据
4个By区别
1) order by : 对全局进行排序;reduce 个数为1个。
2)sort by: 区内排序。 (在sort by之前我们还要配置属性: set mapreduce.job.reduces=2; 配置两个ruduce默认一个,不然sort by是没有用处的。)
如果不指定分区字段,只指定reduce个数那么会造成数据随机分配到不同的reduce里面然后进行排序。
3)Distrbute By:类似MR中Partition,进行分区,结合sort by使用。默认用哈希器来分区 (注意,Hive要求DISTRIBUTE BY语句要写在SORT BY语句之前。)
Distrbute By sort by 直接打印输出是看不到效果的,要打印到文件中。
hive (default)> insert overwrite local directory '/opt/module/datas/distribute-result' select * from emp distribute by deptno sort by empno desc;
4) Cluster By:当Distribute by和Sorts by字段相同时,可以使用Cluster by方式。Cluster by除了具有Distribute by的功能外还兼具Sort by的功能。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。
1)以下两种写法等价
hive (default)> select * from emp cluster by deptno; hive (default)> select * from emp distribute by deptno sort by deptno;
注意:按照部门编号分区,不一定就是固定死的数值,可以是20号和30号部门分到一个分区里面去。因为有可能 6个部门 3个reduce。
开窗函数
over()开窗函数,其括号内部主要有两种形式,固定搭配,不能更改:
over(distribute by…sort by…) 和 over(partition by…order by…)
两种开窗方式区别
patition by是按照一个reduce去处理数据的,所以要使用全局排序order by
distribute by是按照多个reduce去处理数据的,所以对应的排序是局部排序sort by
开窗函数的窗口大小问题
窗口大小:hive的窗口大小默认是从起始行到当前行的
(2)查询顾客的购买明细及月购买总额
select name,orderdate,cost,sum(cost) over(partition by month(orderdate) order by name ) from business order by name,orderdate;
select name,orderdate,cost,sum(cost) over(distribute by month(orderdate) sort by name ) from business order by name,orderdate;
窗口函数
1.相关函数说明 OVER():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变化 CURRENT ROW:当前行 n PRECEDING:往前n行数据 n FOLLOWING:往后n行数据 UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING表示到后面的终点 select name,orderdate,cost, sum(cost) over() as sample1,--所有行相加 sum(cost) over(partition by name) as sample2,--按name分组,组内数据相加 sum(cost) over(partition by name order by orderdate) as sample3,--按name分组,组内数据累加 -- 组内从开始到结束累加,然后按照日期排序 前面从起点到当前行 sum(cost) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and current row ) as sample4 , -- 组内 前面一行和当前行 sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and current row) as sample5, --组内 当前行和前边一行及后面一行 sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING AND 1 FOLLOWING ) as sample6, --组内 当前行和后面所有行 sum(cost) over(partition by name order by orderdate rows between current row and UNBOUNDED FOLLOWING ) as sample7 --当前行及后面所有行 from business; 下面的是over() 外面用的 LAG(col,n):往前第n行数据 LEAD(col,n):往后第n行数据 NTILE(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型。 (4)查看顾客上次的购买时间 和下次购买时间 如果为NUll就赋予一个值 select name,orderdate,cost, lag(orderdate,1,'1900-01-01') over(partition by name order by orderdate ) as time1,
lead(orderdate,1,'9999-99-99') over (partition by name order by orderdate) as time2
from business;
(5)查询前20%时间的订单信息
select * from (
select name,orderdate,cost, ntile(5) over(order by orderdate) sorted
from business
) t where sorted = 1;
Rank 1.函数说明 RANK() 排序相同时会重复,总数不会变 1 1 3 4 DENSE_RANK() 排序相同时会重复,总数会减少 1 1 2 3 ROW_NUMBER() 会根据顺序计算 1 2 3 4 就跟行号一样 不会有重复的 2.数据准备 表6-7 数据准备 name subject score 孙悟空 语文 87 孙悟空 数学 95 孙悟空 英语 68 大海 语文 94 大海 数学 56 大海 英语 84 宋宋 语文 64 宋宋 数学 86 宋宋 英语 84 婷婷 语文 65 婷婷 数学 85 婷婷 英语 78 3.需求 计算每门学科成绩排名。 4.创建本地movie.txt,导入数据 [atguigu@hadoop102 datas]$ vi score.txt 5.创建hive表并导入数据 create table score( name string, subject string, score int) row format delimited fields terminated by "\t"; load data local inpath '/opt/module/datas/score.txt' into table score; 6.按需求查询数据 select name, subject, score, rank() over(partition by subject order by score desc) rk, dense_rank() over(partition by subject order by score desc) drk, row_number() over(partition by subject order by score desc) rmk from score; name subject score rp drp rmp 孙悟空 数学 95 1 1 1 宋宋 数学 86 2 2 2 婷婷 数学 85 3 3 3 大海 数学 56 4 4 4 宋宋 英语 84 1 1 1 大海 英语 84 1 1 2 婷婷 英语 78 3 2 3 孙悟空 英语 68 4 3 4 大海 语文 94 1 1 1 孙悟空 语文 87 2 2 2 婷婷 语文 65 3 3 3 宋宋 语文 64 4 4 4
分桶表:x代表从哪个桶开始抽,后面的桶号为 当前桶+y;
- 分桶规则:对分桶字段值进行哈希,哈希值除以桶的个数求余,余数决定了该条记录在哪个桶中,也就是余数相同的在一个桶中。
- 优点:1、提高join查询效率 2、提高抽样效率
- 分区针对的是数据的存储路径;分桶针对的是数据文件。
-
创建分桶表
create table stu_buck(id int, name string)
clustered by(id)
into 4 buckets
row format delimited fields terminated by '\t';
(3)查看表结构
hive (default)> desc formatted stu_buck;
Num Buckets: 4
load 命令其实 是 直接put的 HDFS上面的。直接load data不会有分桶的效果
- FAILED: SemanticException [Error 10061]: Numerator should not be bigger than denominator in sample clause for table stu_buck
比如16个桶(0-15)z=16 , x=1 y=4 ;下一个桶就是 5、9、13;(以y为间隔数)
求:最后一个桶号: 1 + [ (16/4) -1 ] = 13 x+ [ (z/y) -1 ] y = x+z-y x
y代表每个桶抽多少。
注意:x的值必须小于等于y的值,否则
Hive优化
笼统的说,Hive中的Join可分为Common Join(Reduce阶段完成join)和Map Join(Map阶段完成join)。
Hive Common Join
如果不指定MapJoin或者不符合MapJoin的条件,那么Hive解析器会将Join操作转换成Common Join,即:在Reduce阶段完成join.
整个过程包含Map、Shuffle、Reduce阶段。
- 1)MapJoin
MapJoin顾名思义,就是在Map阶段进行表之间的连接。而不需要进入到Reduce阶段才进行连接。这样就节省了在Shuffle阶段时要进行的大量数据传输。从而起到了优化作业的作用。
如果不指定MapJoin或者不符合MapJoin的条件,那么Hive解析器会将Join操作转换成Common Join,即:在Reduce阶段完成join。容易发生数据倾斜。可以用MapJoin把小表全部加载到内存在map端进行join,避免reducer处理。
- 2)行列过滤
列处理:在SELECT中,只拿需要的列,如果有,尽量使用分区过滤,少用SELECT *。
行处理:在分区剪裁中,当使用外关联时,如果将副表的过滤条件写在Where后面,那么就会先全表关联,之后再过滤。
- 3)采用分桶技术
- 4)采用分区技术
- 5)合理设置Map数
(1)通常情况下,作业会通过input的目录产生一个或者多个map任务。
主要的决定因素有:input的文件总个数,input的文件大小,集群设置的文件块大小。
(2)是不是map数越多越好?
答案是否定的。如果一个任务有很多小文件(远远小于块大小128m),则每个小文件也会被当做一个块,用一个map任务来完成,而一个map任务启动和初始化的时间远远大于逻辑处理的时间,就会造成很大的资源浪费。而且,同时可执行的map数是受限的。
(3)是不是保证每个map处理接近128m的文件块,就高枕无忧了?
答案也是不一定。比如有一个127m的文件,正常会用一个map去完成,但这个文件只有一个或者两个小字段,却有几千万的记录,如果map处理的逻辑比较复杂,用一个map任务去做,肯定也比较耗时。
针对上面的问题2和3,我们需要采取两种方式来解决:即减少map数和增加map数;
- 6)小文件进行合并
在Map执行前合并小文件,减少Map数:CombineHiveInputFormat具有对小文件进行合并的功能(系统默认的格式)。HiveInputFormat没有对小文件合并功能。
- 7)合理设置Reduce数
Reduce个数并不是越多越好
(1)过多的启动和初始化Reduce也会消耗时间和资源;
(2)另外,有多少个Reduce,就会有多少个输出文件,如果生成了很多个小文件,那么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题;
在设置Reduce个数的时候也需要考虑这两个原则:处理大数据量利用合适的Reduce数;使单个Reduce任务处理数据量大小要合适;
- 8)常用参数
// 输出合并小文件
SET hive.merge.mapfiles = true; -- 默认true,在map-only任务结束时合并小文件
SET hive.merge.mapredfiles = true; -- 默认false,在map-reduce任务结束时合并小文件
SET hive.merge.size.per.task = 268435456; -- 默认256M
SET hive.merge.smallfiles.avgsize = 16777216; -- 当输出文件的平均大小小于该值时,启动一个独立的map-reduce任务进行文件merge
视频链接:https://www.ixigua.com/i6817441039163326990/
Rank
1.函数说明
RANK() 排序相同时会重复,总数不会变
DENSE_RANK() 排序相同时会重复,总数会减少
ROW_NUMBER() 会根据顺序计算
2.数据准备
表6-7 数据准备
|
name |
subject |
score |
|
孙悟空 |
语文 |
87 |
|
孙悟空 |
数学 |
95 |
|
孙悟空 |
英语 |
68 |
|
大海 |
语文 |
94 |
|
大海 |
数学 |
56 |
|
大海 |
英语 |
84 |
|
宋宋 |
语文 |
64 |
|
宋宋 |
数学 |
86 |
|
宋宋 |
英语 |
84 |
|
婷婷 |
语文 |
65 |
|
婷婷 |
数学 |
85 |
|
婷婷 |
英语 |
78 |
3.需求
计算每门学科成绩排名。
4.创建本地movie.txt,导入数据
[atguigu@hadoop102 datas]$ vi score.txt
5.创建hive表并导入数据
|
create table score( name string, subject string, score int) row format delimited fields terminated by "\t"; load data local inpath '/opt/module/datas/score.txt' into table score; |
6.按需求查询数据
|
select name, subject, score, rank() over(partition by subject order by score desc) rp, dense_rank() over(partition by subject order by score desc) drp, row_number() over(partition by subject order by score desc) rmp from score;
name subject score rp drp rmp 孙悟空 数学 95 1 1 1 宋宋 数学 86 2 2 2 婷婷 数学 85 3 3 3 大海 数学 56 4 4 4 宋宋 英语 84 1 1 1 大海 英语 84 1 1 2 婷婷 英语 78 3 2 3 孙悟空 英语 68 4 3 4 大海 语文 94 1 1 1 孙悟空 语文 87 2 2 2 婷婷 语文 65 3 3 3 宋宋 语文 64 4 4 4 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号