

目标检测(一)
一、目标检测的概念和区别
1、图像分类 目标检测 语义分割 实例分割

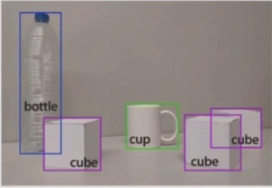
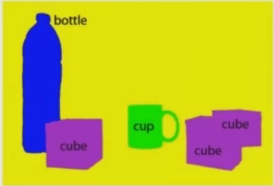
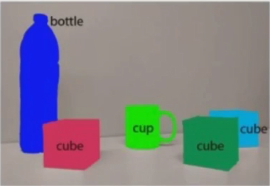
图像分类:在图像分类中仅仅对图像所属的类别进行判断。
目标检测:除了对图像的类别进行判断外,还需要对图像中目标的位置进行判定,并通过置信度的设定过滤掉一些误检目标。
语义分割:找出图像中同一类物体目标所在的具体位置。
实例分割:不仅要区分语义分割中的位置外,还要区分同一类目标的位置。
二、目标检测的发展
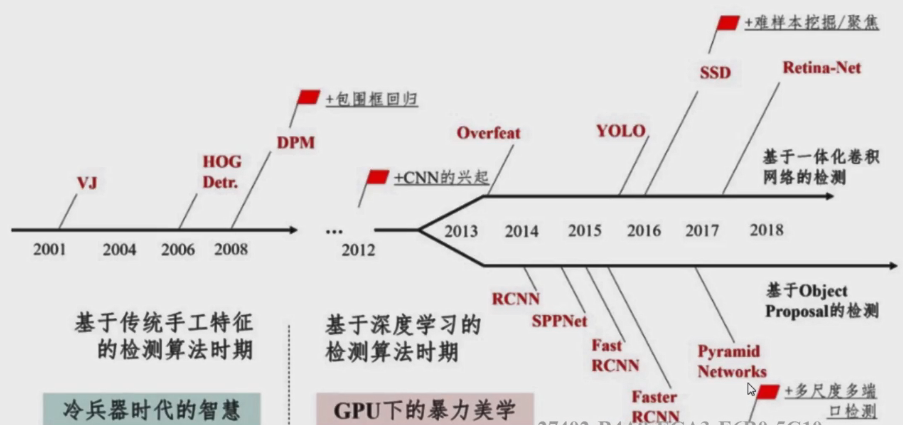
算法的流程:
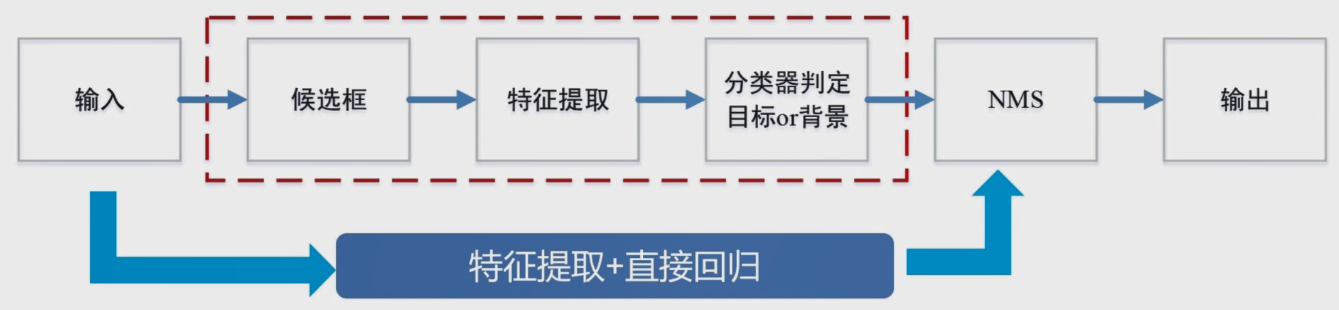
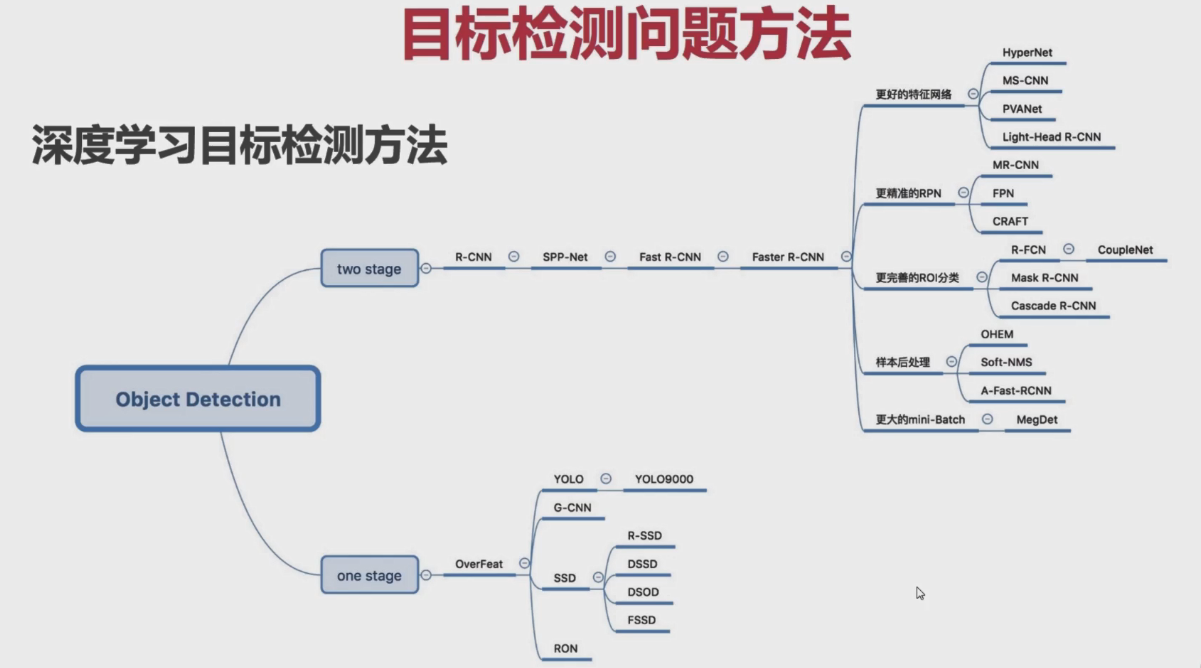
传统的目标检测与深度学习目标检测算法的区别就在于,候选框在进行特征提取时时使用了手动的特征还是使用了通过学习得到的特征。手动进行特征提取的候选框就是传统的目标检测算法,例如:VJ(通过积分图特征结合Adaboost分类器进行人脸检测,基于纹理特征)、HOG+SVM(行人检测,基于纹理特征)、DPM(其实也是基于HOG特征进行的,但是其中加入了一些策略来提升检测的准确性,在传统的目标检测中,该方法是目标效果最好的方法。)等。通过学习得到的特征就是深度学习的目标检测算法,现阶段的目标检测算法主要分为one-stage、two-stage两种。one-stage检测算法主要有YOLO、SSD系列,在算法中通过直接回归目标位置的方式进行目标的检测;而two-stage检测算法主要包括RCNN、Fast-R-CNN、Faster-R-CNN等,在算法中要经过两个阶段,即首先通过利用RPN网络进行候选区域的提取,然后再对候选目标进行位置和类别的预测。
传统检测方法和深度学习目标检测算法的区别

从特征提取的角度上讲: 传统的检测算法首先是通过手动提取图像的特征,设计的特征可能会存在鲁棒性的问题。而深度学习网络算法是通过不同的网络结构提取图像的特征,特征会更加的鲁棒。
从候选目标选择上讲:传统的目标检测算法是通过滑动窗口的策略得到候选目标,而深度学习网络算法则是通过proposal的RPN网络或者直接回归的方式获取候选目标,因此深度学习的学习效率会更高。
从目标分类的角度上讲:传统的目标检测算法是通过传统的分类器完成,分类器的学习是通过之前设计的特征完成的,特征的不鲁棒就会导致分类器在分类中的不鲁棒。而深度学习目标检测算法则是通过深度网络来完成分类任务。
从检测方式上讲:传统的目标检测算法不仅需要设计相应的特征,也需要设计相应的分类器(比如:在Haar特征+Adaboost级联分类器中),因此在整个的学习过程中需要通过多步骤进行目标的检测。而深度学习目标检测算法则是通过深度网络来完成,相较于传统的学习方法,深度学习方法更加的端到端。
从准确性和实时性上讲:深度学习的方法准确性和实时性更好。
三、one-stage VS two-stage
one-stage
优点:速度快
避免背景错误,产生false positive(也就是说误检率低)
学到物体的泛化特征
缺点:精度低(定位、检出率)
小物体检测效果不好
two-stage
优点:精度高(定位、检出率)
Anchor机制(提高模型性能的一个重要机制,能够考虑到不同尺度的区域)
共享计算量(作用就是减小网络模型,相当于对模型进行了正则化,对于防止模型的过拟合和模型的训练都有一定的意义)
缺点:速度慢
训练时间长
误报高
