
pytorch 版fasterrcnn 跑通代码增加保存xml的功能
1.下载(代码和预训练模型)
最近,领导说你找个pytorch版的fasterrcnn复现一下吧,以后都转到pytorch上来吧,他终于肯放弃公司自己dragon框架了吗。
问了同事说他有跑过一个代码,下载选择pytorch1.0的分支,和res101的预训练模型(又小又准)
2.环境,编译
cuda10.0 python3.7 pytorch 1.0
cd lib
python setup.py build develop3.数据预处理和预训练模型的放置
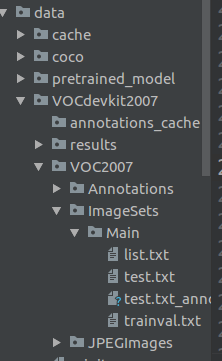
还是JPEGImages 文件夹放图片, Annotations 放voc的标注文件,ImageSets里面划分训练和测试集数据要放在data/VOCdevkit2007/VOC2007/路径下,如下图(代码中也可以自己指定数据路径,后文会写),预训练模型放在data/pretrained_model/路径下
4.开始训练
错误记录
4.1改好参数之后run trainval_net.py开始报错cannot import name '_mask' from 'lib.pycocotools
找了很多网上的解决方法
Just find out that you have to install the CoCO API.
cd data
git clone https://github.com/pdollar/coco.git cd coco/PythonAPI
我把整个coco文件夹复制覆盖到原来的代码中
删除lib下的build文件夹重新编译
python setup.py build develop
4.2继续run的时候又报错了UnboundLocalError: local variable 'pooled_feat' referenced before assignment
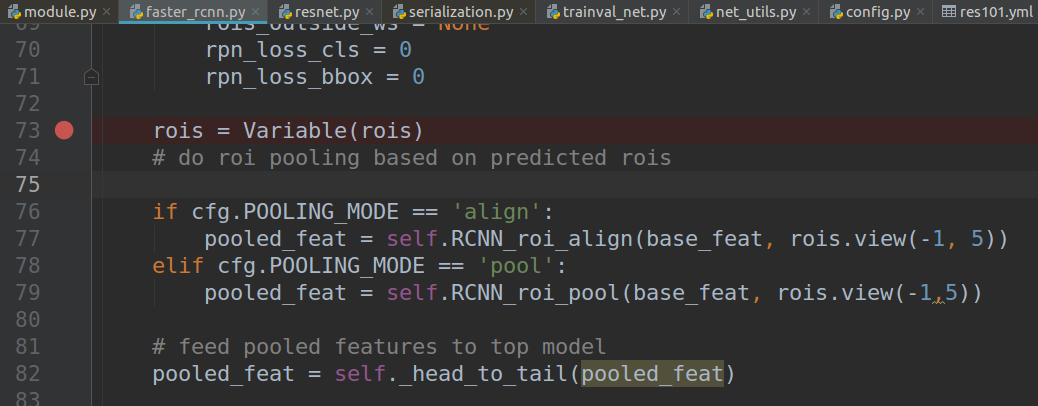
定位到faster_rcnn.py 82行,发现没有什么问题,debug时候发现上面的if判断语句都没有进,然而cfg文件中POOLING_MODE 明明给的是align,看下面的信息发现cfg文件根本没哟传过来,所以两种解决方法
1,cfg内容传递过来
2.如下图,去掉判断语句直接给pooled_feat赋值
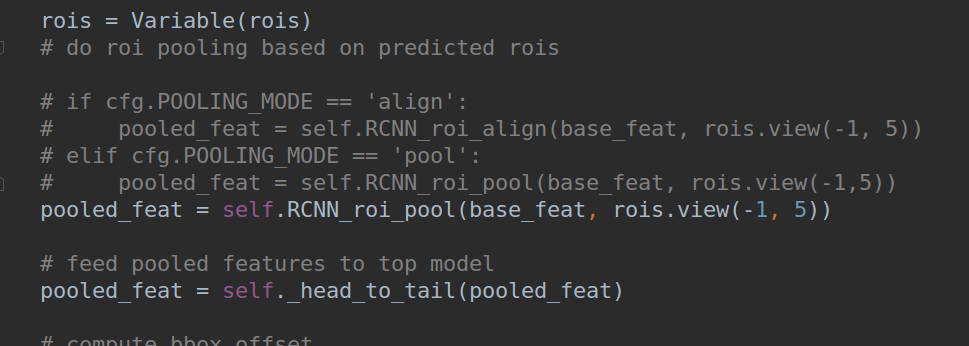
至此终于可以正常run了
5.改进
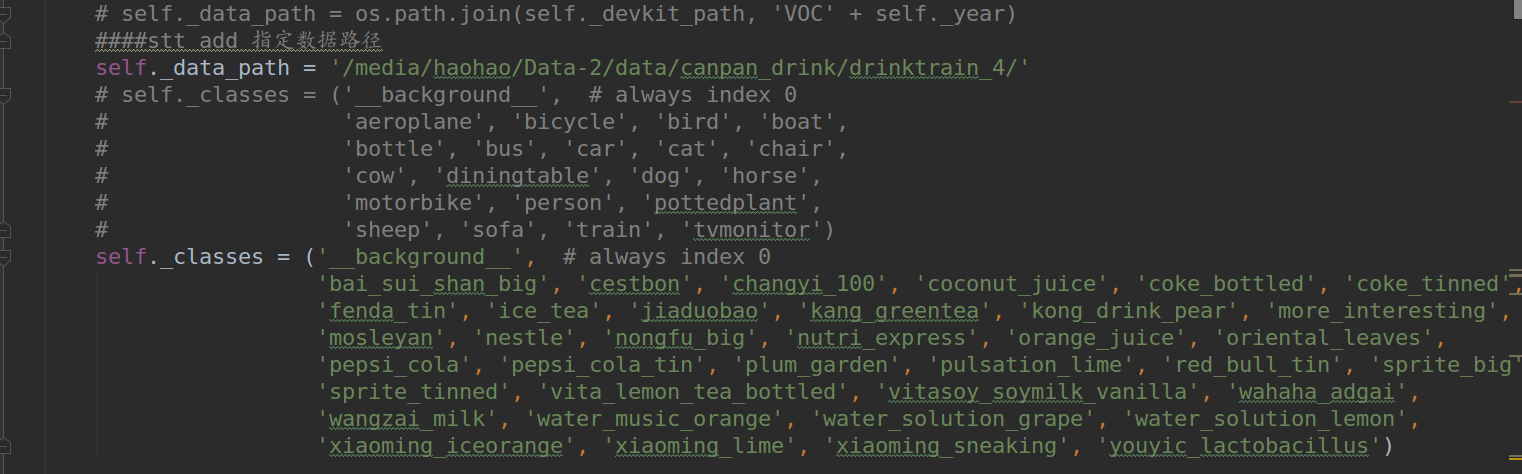
5.1很多时候我不想在数据代码混为一滩,数据读取路径可以直接赋值,在lib/datasets/pascal_voc.py中
把self._data_path修改为自己的数据路径,下面就是自己的数据类别
5.2demo.py中修改保存图片的路径,个人习惯吧,总是习惯把推断过后的图片另存一个文件夹
parse_args中新增一个output_images为存放新生成的预测后画框的图片
if vis and webcam_num == -1:
# cv2.imshow('test', im2show)
# cv2.waitKey(0)
result_path = os.path.join(args.output_images, imglist[num_images][:-4] + "_det.jpg") ###stt change output_images dir
cv2.imwrite(result_path, im2show)
5.2demo.py中修改保存图片的路径,预测后的图片xml文件保存出来(减少后期标注量)
新增较多
pred_det = []
for j in xrange(1, len(pascal_classes)):
inds = torch.nonzero(scores[:,j]>thresh).view(-1)
# if there is det
if inds.numel() > 0: ### stt 判断预测出来的类别中是否有框
cls_scores = scores[:,j][inds] ### stt预测出来的所有得分
_, order = torch.sort(cls_scores, 0, True)
if args.class_agnostic:
cls_boxes = pred_boxes[inds, :]
else:
cls_boxes = pred_boxes[inds][:, j * 4:(j + 1) * 4] ###stt 预测出来的所有框
cls_dets = torch.cat((cls_boxes, cls_scores.unsqueeze(1)), 1) ### stt框和得分降成1维
# cls_dets = torch.cat((cls_boxes, cls_scores), 1)
cls_dets = cls_dets[order]
# keep = nms(cls_dets, cfg.TEST.NMS, force_cpu=not cfg.USE_GPU_NMS)
keep = nms(cls_boxes[order, :], cls_scores[order], cfg.TEST.NMS) #### stt预测出来的框nms
cls_dets = cls_dets[keep.view(-1).long()]
### stt add
arr_2 =[]
np.set_printoptions(suppress=True) ###不以科学计数法保存
arr_cls_det = cls_dets.cpu().numpy() ###张量转数组
arr_cls_det.astype(float) ###列表数据转为float格式
for i in arr_cls_det:
arr_2.append(pascal_classes[j]) ###类别加入新的数组中
arr_2 += map(int, i.tolist()[:4]) ###预测出来的框(四个坐标点)加入数组中
pred_det.append(arr_2) ###类比,框保存为一个列表,每张图片可能有多个预测框
#print(arr_cls_det)
#print((np.round(cls_dets)))
if vis:
im2show = vis_detections(im2show, pascal_classes[j], cls_dets.cpu().numpy(), 0.5)
#print(pred_det)
#######stt add save_txt and xml
save_txt = True
save_xml = True
### Write results:
for i in pred_det:
if save_txt: # Write to file
img_name = im_file.split('/')[-1].split('.')[0]
txt_path = os.path.join(args.output_images, 'txt_path')
if not os.path.exists(txt_path):
os.makedirs(txt_path)
with open(txt_path + '/' + img_name + '.txt', 'a') as file:
file.write(('%s, %g , %g, %g, %g ' + '\n') % (i[0], i[1], i[2], i[3], i[4]))
txtfile = os.path.join(txt_path, img_name + '.txt')
###stt _add start write_xml
if save_txt and save_xml:
Anno_path = os.path.join(args.output_images, 'Annotations')
if not os.path.exists(Anno_path):
os.makedirs(Anno_path)
outdir = os.path.join(Anno_path,
img_name + '.xml')
txt2xml(pascal_classes, txtfile, im_file, outdir)
####stt add end
misc_toc = time.time()
nms_time = misc_toc - misc_tic
还有一个save_xml的文件夹放在下面链接中(自己修改过后代码)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号