





Spark详解
什么是Spark
Spark是一个用于大规模数据处理的统一计算引擎
注意:Spark不仅仅可以做类似于MapReduce的离线数据计算,还可以做实时数据计算,并且它还可以实现类似于Hive的SQL计算,所以说它是一个统一的计算引擎
既然说到了Spark,那就不得不提一下Spark里面最重要的一个特性:内存计算
Spark中一个最重要的特性就是基于内存进行计算,从而让它的计算速度可以达到MapReduce的几十倍甚至上百倍
Spark的特点
Speed:速度快
由于Spark是基于内存进行计算的,所以它的计算性能理论上可以比MapReduce快100倍
Spark使用最先进的DAG调度器、查询优化器和物理执行引擎,实现了高性能的批处理和流处理。
注意:批处理其实就是离线计算,流处理就是实时计算,只是说法不一样罢了,意思是一样的
Easy of Use:易用性
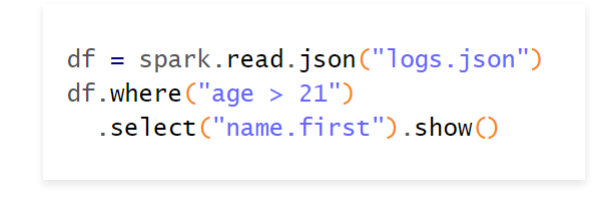
Spark的易用性主要体现在两个方面
- 可以使用多种编程语言快速编写应用程序,例如Java、Scala、Python、R和SQL
- Spark提供了80多个高阶函数,可以轻松构建Spark任务。
Generality:通用性
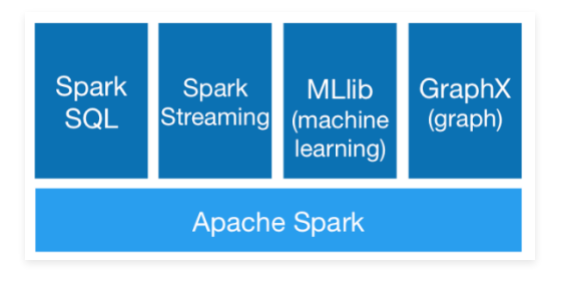
Spark提供了Core、SQL、Streaming、MLlib、GraphX等技术组件,可以一站式地完成大数据领域的离线批处理、SQL交互式查询、流式实时计算,机器学习、图计算等常见的任务
从这可以看出来Spark也是一个具备完整生态圈的技术框架,它不是一个人在战斗。
Runs Everywhere:到处运行
你可以在Hadoop YARN、Mesos或Kubernetes上使用Spark集群。并且可以访问HDFS、Alluxio、Apache Cassandra、Apache HBase、Apache Hive和数百个其它数据源中的数据。
Spark vs Hadoop
综合能力
Spark是一个综合性质的计算引擎,Hadoop既包含MapReduce(计算引擎),还包含HDFS(分布式存储)和Yarn(资源管理)
所以说他们两个的定位是不一样的。从综合能力上来说,hadoop是完胜spark的
计算模型
Spark 任务可以包含多个计算操作,轻松实现复杂迭代计算
而Hadoop中的MapReduce任务只包含Map和Reduce阶段,不够灵活
从计算模型上来说,spark是完胜hadoop的
处理速度
Spark 任务的数据是基于内存的,计算速度很快
而Hadoop中MapReduce 任务是基于磁盘的,速度较慢
从处理速度上来说,spark也是完胜hadoop的
总结
之前有一种说法,说Spark将会替代Hadoop,这个说法是错误的,其实它们两个的定位是不一样的。
Spark是一个通用的计算引擎,而Hadoop是一个包含HDFS、MapRedcue和YARN的框架,所以说Spark就算替代也只是替代Hadoop中的MapReduce,也不会整个替代Hadoop,因为Spark还需要依赖于Hadoop中的HDFS和YARN。
所以在实际工作中Hadoop会作为一个提供分布式存储和分布式资源管理的角色存在,Spark会在它之上去执行。所以在工作中就会把spark和hadoop结合到一块来使用
Spark+Hadoop
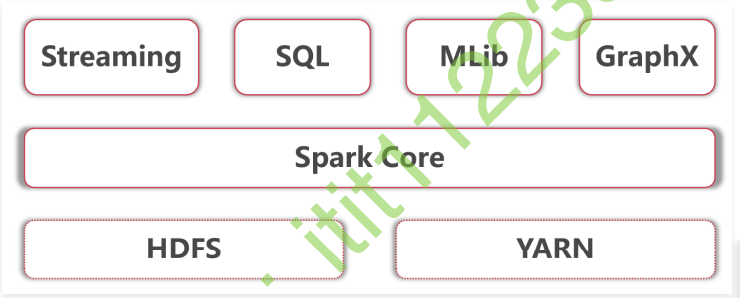
- 底层是Hadoop的HDFS和YARN
- Spark core指的是Spark的离线批处理
- Spark Streaming指的是Spark的实时流计算
- SparkSQL指的是Spark中的SQL计算
- Spark Mlib指的是Spark中的机器学习库,这里面集成了很多机器学习算法
- 最后这个Spark GraphX是指图计算
其实这里面这么多模块,针对大数据开发岗位主要需要掌握的是Spark core、streaming、sql这几个模块,其中Mlib主要是搞算法的岗位使用的,GraphX这个要看是否有图计算相关的需求,所以这两个不是必须要掌握的。
Spark的应用场景
Spark主要应用在以下这些应用场景中
- 低延时的海量数据计算需求,这个说的就是针对Spark core的应用
- 低延时SQL交互查询需求,这个说的就是针对Spark SQL的应用
- 准实时(秒级)海量数据计算需求,这个说的就是Spark Streaming的应用
Spark集群安装部署
Spark集群有多种部署方式,比较常见的有Standalone模式和ON YARN模式
- Standalone模式就是说部署一套独立的Spark集群,后期开发的Spark任务就在这个独立的Spark集群中执行
- ON YARN模式是说使用现有的Hadoop集群,后期开发的Spark任务会在这个Hadoop集群中执行,此时这个Hadoop集群就是一个公共的了,不仅可以运行MapReduce任务,还可以运行Spark任务,这样集群的资源就可以共享了,并且也不需要再维护一套集群了,减少了运维成本和运维压力,一举两得。
所以在实际工作中都会使用Spark ON YARN模式。
下载地址,这里我们使用2.4.3版本,因为我们使用Spark的时候一般都是需要和Hadoop交互的,所以需要下载带有Hadoop依赖的安装包。
Standalone
重命名spark-env.sh.template
mv spark-env.sh.template spark-env.sh
修改 spark-env.sh,在文件末尾增加这两行内容,指定JAVA_HOME和主节点的主机名
export JAVA_HOME=/root/test_hadoop/jdk8
export SPARK_MASTER_HOST=bigdata01
重命名slaves.template
mv slaves.template slaves
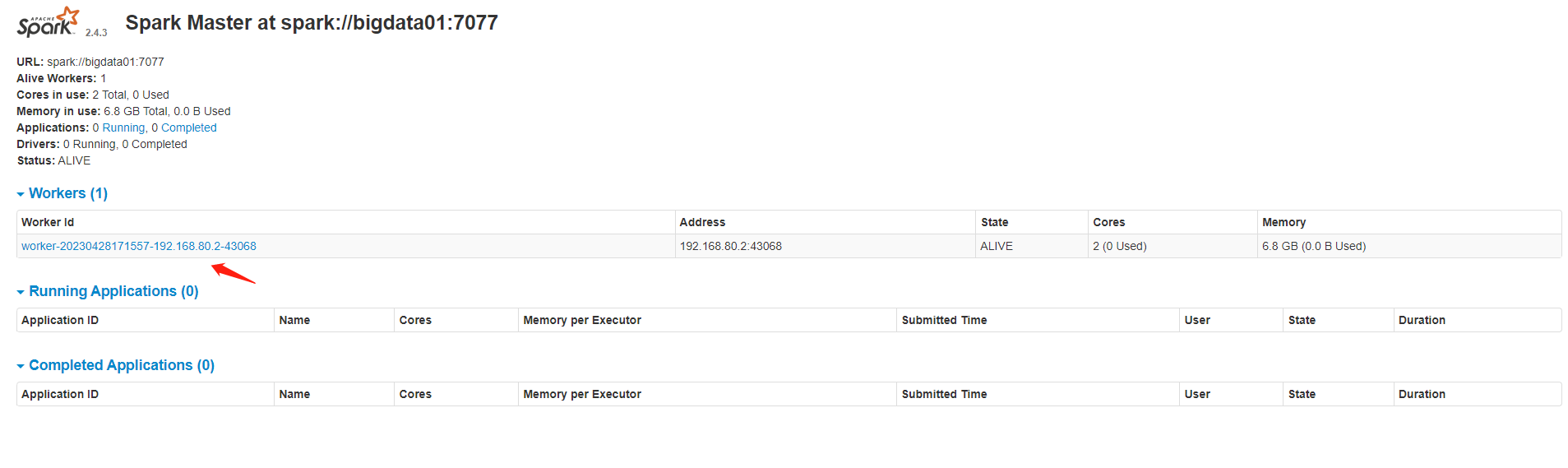
启动Spark集群,访问 http://ip:8080/ 查看集群信息,jps可以看到Master和Worker进程
sbin/start-all.sh
提交任务,详细文档地址
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://bigdata01:7077 \
examples/jars/spark-examples_2.11-2.4.3.jar \
2
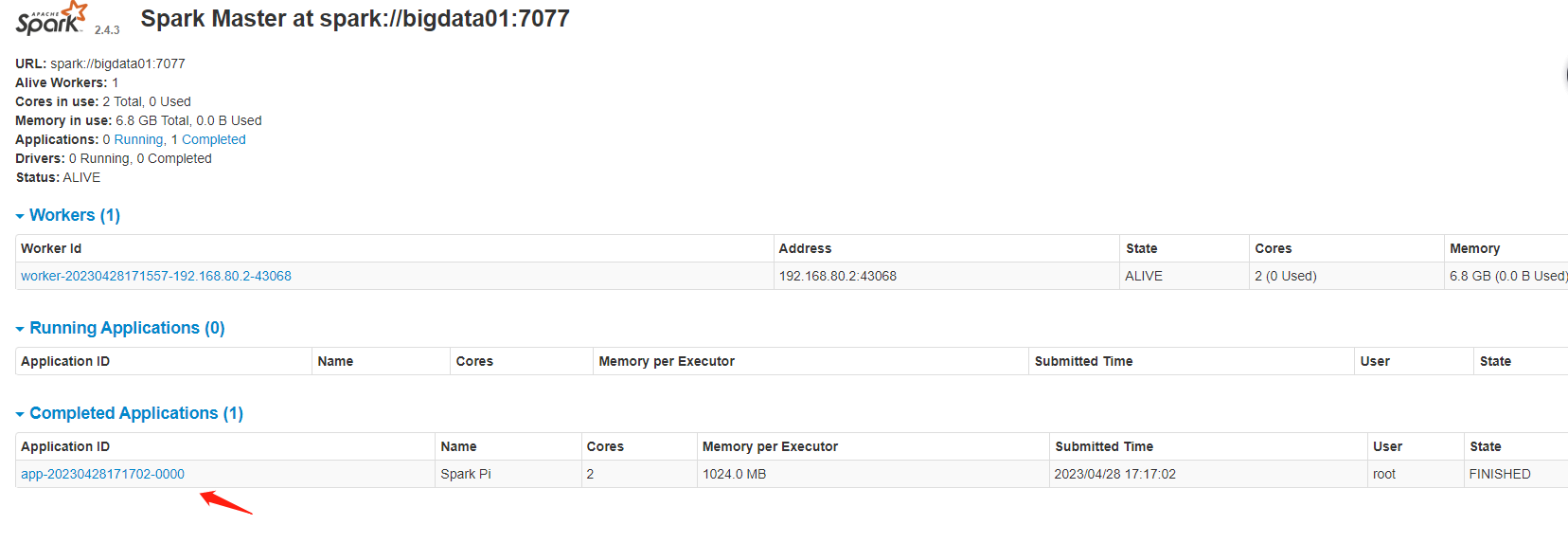
停止Spark集群
sbin/stop-all.sh
ON YARN
先保证有一个Hadoop集群,然后只需要部署一个Spark的客户端节点即可,不需要启动任何进程
注意:Spark的客户端节点同时也需要是Hadoop的客户端节点,因为Spark需要依赖于Hadoop
重命名spark-env.sh.template
mv spark-env.sh.template spark-env.sh
修改 spark-env.sh,在文件末尾增加这两行内容,指定JAVA_HOME和Hadoop的配置文件目录
export JAVA_HOME=/root/test_hadoop/jdk8
export HADOOP_CONF_DIR=/root/test_hadoop/hadoop3.2/etc/hadoop
重启spark集群,提交任务
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
examples/jars/spark-examples_2.11-2.4.3.jar \
2
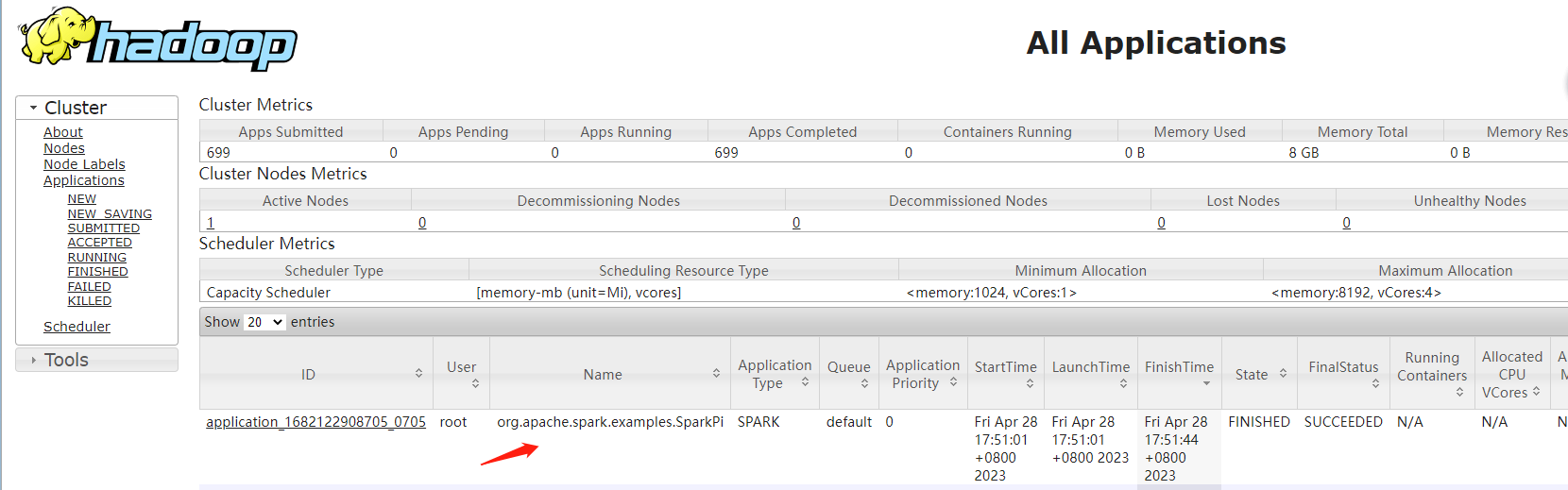
可以到YARN的8088界面查看提交上去的任务信息
Spark的工作原理
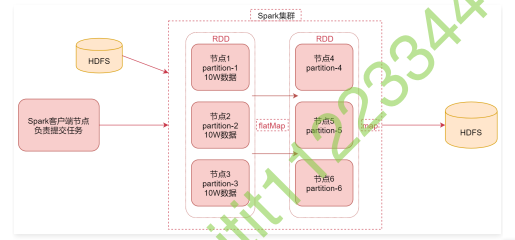
看中间是一个Spark集群,可以理解为是Spark的 standalone集群,集群中有6个节点
左边是Spark的客户端节点,这个节点主要负责向Spark集群提交任务,假设在这里我们向Spark集群提交了一个任务
那这个Spark任务肯定会有一个数据源,数据源在这我们使用HDFS,就是让Spark计算HDFS中的数据。当Spark任务把HDFS中的数据读取出来之后,它会把HDFS中的数据转化为RDD,RDD其实是一个弹性分布式数据集,它其实是一个逻辑概念,在这你先把它理解为是一个数据集合就可以了,后面我们会详细分析这个RDD。
在这里这个RDD你就可以认为是包含了我们读取的HDFS上的数据。其中这个RDD是有分区这个特性的,也就是一整份数据会被分成多份,
假设我们现在从HDFS中读取的这份数据被转化为RDD之后,在RDD中分成了3份,那这3份数据可能会分布在3个不同的节点上面,对应这里面的节点1、节点2、节点3
这个RDD的3个分区的数据对应的是partiton-1、partition-2、partition-3
这样的好处是可以并行处理了,后期每个节点就可以计算当前节点上的这一个分区的数据。这个计算思想是不是类似于MapReduce里面的计算思想啊,本地计算,但是有一点区别就是这个RDD的数据是在内存中的。
假设现在这个RDD中每个分区中的数据有10w条
那接下来我们就想对这个RDD中的数据进行计算了,可以使用一些高阶函数进行计算,例如:flatMap、map之类的
- 那在这我们先使用flatMap对数据进行处理,把每一行数据转成多行数据,此时flatMap这个函数就会在节点1、节点2和节点3上并行执行了。计算之后的结果还是一个带有分区的RDD,那这个RDD我们假设存在节点4、节点5和节点6上面。此时每个节点上面会有一个分区的数据,我们给这些分区数据起名叫partition-4、partition-5、partition-6。正常情况下,前面节点1上的数据处理之后会发送到节点4上面,另外两个节点也是一样的。
- 此时经过flatmap计算之后,前面RDD的数据传输到后面节点上面这个过程是不需要经过shuffle的,可以直接在内存中通过网络拷贝过去。后面可能还会通过map、或者其它的一些高阶函数对数据进行处理,当处理到最后一步的时候是需要把数据存储起来的,在这我们选择把数据存储到hdfs上面,其实在实际工作中,针对这种离线计算,大部分的结果数据都是存储在hdfs上面的,当然了也可以存储到其它的存储介质中
首先通过Spark客户端提交任务到Spark集群,然后Spark任务在执行的时候会读取数据源HDFS中的数据,将数据加载到内存中,转化为RDD,然后针对RDD调用一些高阶函数对数据进行处理,中间可以调用多个高阶函数,最终把计算出来的结果数据写到HDFS中。
什么是RDD
RDD通常通过Hadoop上的文件,即HDFS文件进行创建,也可以通过程序中的集合来创建
RDD是Spark提供的核心抽象,全称为Resillient Distributed Dataset,即弹性分布式数据集
- 弹性:RDD数据默认情况下存放在内存中,但是在内存资源不足时,Spark也会自动将RDD数据写入磁盘
- 分布式:RDD在抽象上来说是一种元素数据的集合,它是被分区的,每个分区分布在集群中的不同节点上,从而让RDD中的数据可以被并行操作
- 容错性:RDD最重要的特性就是提供了容错性,可以自动从节点失败中恢复过来
如果某个节点上的RDD partition,因为节点故障,导致数据丢了,那么RDD会自动通过自己的数据来源重新计算该partition的数据。
Spark架构相关进程
注意:在这里是以Spark的standalone集群为例进行分析
Driver
我们编写的Spark程序就在Driver(进程)上,由Driver进程负责执行
Driver进程所在的节点可以是Spark集群的某一个节点或者就是我们提交Spark程序的客户端节点
具体Driver进程在哪个节点上启动是由我们提交任务时指定的参数决定的,这个后面我们会详细分析
Master
集群的主节点中启动的进程,主要负责集群资源的管理和分配,还有集群的监控等
Worker
集群的从节点中启动的进程,主要负责启动其它进程来执行具体数据的处理和计算任务
Executor
此进程由Worker负责启动,主要为了执行数据处理和计算
Task
是一个线程,由Executor负责启动,它是真正干活的
Spark架构原理
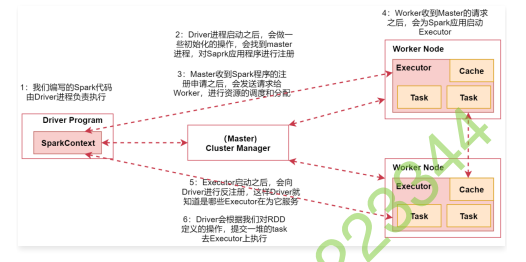
- 首先我们在spark的客户端机器上通过driver进程执行我们的Spark代码,当我们通过spark-submit脚本提交Spark任务的时候Driver进程就启动了。
- Driver进程启动之后,会做一些初始化的操作,会找到集群master进程,对Spark应用程序进行注册
- 当Master收到Spark程序的注册申请之后,会发送请求给Worker,进行资源的调度和分配
- Worker收到Master的请求之后,会为Spark应用启动Executor进程,会启动一个或者多个Executor,具体启动多少个,会根据你的配置来启动
- Executor启动之后,会向Driver进行反注册,这样Driver就知道哪些Executor在为它服务了
- Driver会根据我们对RDD定义的操作,提交一堆的task去Executor上执行,task里面执行的其实就是具体的map、flatMap这些操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号