ctfshow-misc50
文件下载地址 https://www.lanzoui.com/i98c7zg
打开后是一张图片,在kali中使用foremost命令分离出一张图片和一个压缩包
用010打开图片,在图片的末尾发现一串字符
Sk5DVlM2Mk1NRjVIU1gyTk1GWEgyQ1E9Cg==
先base64解密,在base32解密得到
KEY{Lazy_Man}
打开压缩包发现提示
GEZDGNBVGYFA====
base32解密后得到密码
123456
打开txt里面的内容,是一堆数字。且3078重复出现。转为16进制就得到3078是0x
那么使用脚本,进行批量转换。得到一堆0x 0x的文本。
又发现字符串0x37 0x7a,发现37 7a 是7z压缩包的文件头。
那么思路来了:批量删除0x,转换为7z文件。
先上批量删除0x的代码
import re
def read_file(filepath):
with open(filepath) as fp:
content=fp.read();
return content
number = read_file('thienc.txt')
result = []
result.append(re.findall(r'.{2}', number))
result = result[0]
strings =''
for i in result:
y = bytearray.fromhex(i)
z = str(y)
z= re.findall("b'(.*?)'",z)[0]
strings += z
b= strings.split('0x')
strings=''
for i in b:
if len(i) ==1:
i= '0' + i
strings +=i
with open('te.txt', 'w') as f:
f.write(strings)
将得到的te.txt文本中的内容以16进制复制到010中打开并保存为1.7z
打开发现需要密码,那么之前得到的密码就有了用处
KEY{Lazy_Man}
输入密码得到一大串内容,结尾发现==,一次base64解密后还有=

猜想有多次的base解密
直接上代码
import base64
import re
def read_file(filepath):
with open(filepath) as fp:
content=fp.read();
return content
url = read_file('secenc.txt')
#url1= re.findall("b'(.*?)'",url)
#url=url1[0]
url = base64.b64decode(url)
print(url)
with open('test1.txt', 'w') as f:
f.write(str(url))
第一次解密需要将
#url1= re.findall("b'(.*?)'",url)
#url=url1[0]
注释掉,因为一开始的密文是没有 ‘,而运行脚本后有了
第二次运行脚本代码如下
import base64
import re
def read_file(filepath):
with open(filepath) as fp:
content=fp.read();
return content
url = read_file('test1.txt')
url1= re.findall("b'(.*?)'",url)
url=url1[0]
url = base64.b32decode(url)
print(url)
with open('test2.txt', 'w') as f:
f.write(str(url))
以此反复进行base32,base64解密。
最终经过16次的混合解密得到 test16.txt

使用记事本的替换功能,把 \n替换成空格
在线brain fuck/Ook!解密
先 Ook! to Text
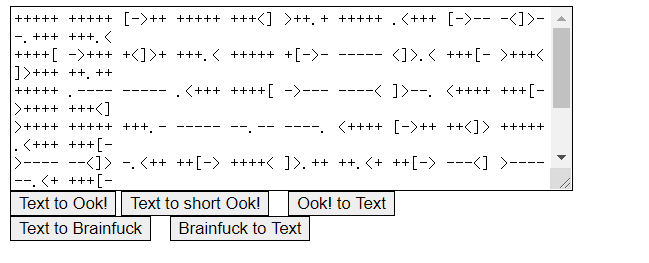
然后再 Brainfuck to Text,得出flag

flag
flag{Welc0me_tO_cTf_3how!}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号