【论文阅读】LLM4Decompile_ Decompiling Binary Code with Large Language Models
Title:
LLM4Decompile: Decompiling Binary Code with Large Language Models
Hanzhuo Tan1,2, Qi Luo1, Jing Li2,3, Yuqun Zhang1*, 1Department of Computer Science and Engineering, Southern University of Science and Technology, Shenzhen, China 2Department of Computing, The Hong Kong Polytechnic University, HKSAR, China 3 Research Centre for Data Science & Artificial Intelligence
摘要:
反编译的目标是将二进制代码转换为高级源代码,但传统工具(如 Ghidra)通常生成难以阅读和执行的结果。受大型语言模型(LLMs)最新进展的启发,我们提出了 LLM4Decompile ——首个也是目前最大的开源反编译语言模型系列(规模从 1.3B 到 33B)。我们优化了 LLM 的训练流程,并提出了 LLM4Decompile-End 模型,使其能够直接对二进制进行反编译。
所得模型在 HumanEval 和 ExeBench 基准测试中,在可重新执行率方面相比 GPT-4o 和 Ghidra 提升超过 100%。此外,我们改进了标准的 refinement(代码精炼)方法,对 LLM4Decompile-Ref 模型进行微调,使其能够有效优化来自 Ghidra 的反编译代码,并在 LLM4Decompile-End 的基础上进一步提升 16.2%。
LLM4Decompile 展现了利用 LLM 变革二进制反编译的潜力,在可读性与可执行性方面带来了显著提升,并可与传统工具互补,以获得最佳效果。
三点现象:
- 反编译是将二进制代码转换为高级源代码的逆向工程核心技术,广泛应用于漏洞挖掘、恶意软件分析、遗留软件迁移等场景。
- 传统工具(如 Ghidra、IDA Pro)生成的伪代码存在可读性差、语法错误多、无法直接执行等问题,难以满足实际应用需求。
- 近年来 LLMs 在代码处理领域展现潜力,但现有基于 LLM 的反编译方案存在模型规模小、训练数据有限、效果不佳等局限,亟需更高效的解决方案。
目标:
用于反编译的llm
简介:
现状下的不足:
- 传统反编译工具:(如IDA\Ghida)依赖控制流和数据流分析、模式匹配,输出伪代码缺乏高层语言结构(如循环、数组索引),可执行性差。

(如图,从源码到反编译代码,不可读)
- 基于 LLM 的反编译方案:
- 优化式反编译(Refined-Decompile):利用 LLM 优化传统工具输出,但未充分适配二进制数据特性。
- 端到端反编译(End2end-Decompile):直接微调 LLM 处理二进制,但现有开源模型仅 2 亿参数左右,训练数据有限。
主要贡献:
- 我们提出了 LLM4Decompile 系列模型,这是首个、也是目前最大的开源反编译 LLM(参数规模从 1.3B 到 33B),并在 150 亿(15B)标记上进行微调以适配反编译任务。
- 我们优化了 LLM 的训练流程,并提出 LLM4Decompile-End 模型,在直接二进制反编译方面树立了新的性能基准。在 HumanEval 和 ExeBench 基准测试中,其代码可重新执行率相比 GPT-4o 和 Ghidra 提升超过 100%。
- 我们改进了 Refined-Decompile 方法,对 LLM4Decompile-Ref 模型进行微调,使其能够有效优化来自 Ghidra 的反编译结果,并进一步将可重新执行率 提升 16.2%。
相关工作:
反编译:
- 传统反编译依赖于分析程序的控制流和数据流,采用匹配模式。但是这种反编译的输出主要是汇编代码的类源代码表示,而非原始的高级语言结构。
- 现行的两种主要大模型方法:
- 优化反编译(Refined-Decompile)和 端到端反编译(End2end-Decompile),模型是为了高级语言涉及的,二进制有效性不足;同时,开源的模型参数非常有限
目标:
首个最开源的LLM4Decomplie
对端对端进行优化,训练了LLM4Decomplie-End模型,证明对直接反编译二进制文件的有效性
改进了优化反编译框架,和Ghidra结合以实现增强效果。
LLM4Decompile:
LLM4Decomplie-End:
End2end-Decompile 框架介绍(端对端):
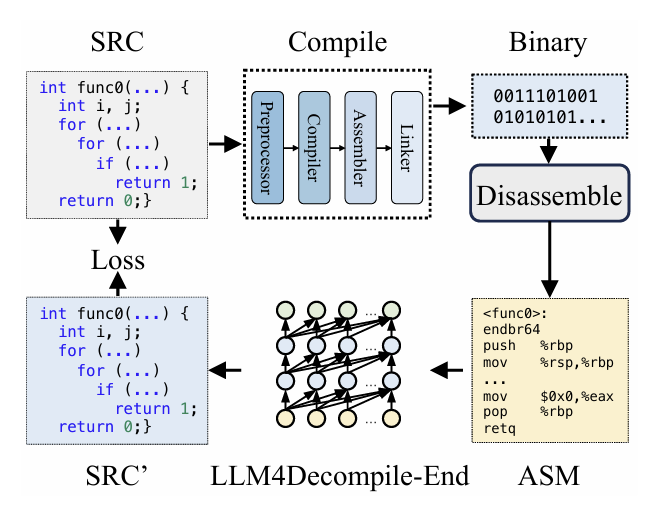
在编译阶段,预处理器对源代码(SRC)进行处理,以去除注释并展开宏或包含文件。经过处理的代码随后被传送到编译器,由编译器将其转换为汇编代码(ASM)。
汇编器将此汇编代码转换为二进制代码(0和1)。
链接器通过链接函数调用来完成整个过程,生成可执行文件。
另一方面,反编译则是将二进制代码转换回源文件的过程。大语言模型(LLMs)基于文本训练,无法直接处理二进制数据。因此,必须先用Objdump将二进制文件反汇编为汇编语言(ASM)。需要注意的是,二进制文件和反汇编得到的汇编代码是等价的,它们可以相互转换。因此,我们可以交替使用它们。
最后,通过计算反编译代码与源代码之间的损失来指导训练。
LLM4Decomplie-End优化:
三个关键步骤优化:
1、扩充训练语料库(trainging corpus) 2、提高数据质量(Data Quality) 3、引入two-state training
训练语料库(trainging corpus)
基于https://github.com/jordiae/exebench(Exebench)构建汇编-源代码对。同时考虑了常见的编译优化状态,编译优化涉及消除冗余指令、优化寄存器分配和循环转换等等。将源代码编译到所有四个阶段,即O0、O1、O2和O3,并将每个阶段的结果与源代码进行配对。
数据质量:
进行了清理训练集。遵循StarCoder的仿真,通过计算代码的MinHash并利用局部敏感哈希(LSH)来移除重复项
two-state training
主要目的是为了让模型学习二进制知识,包含了两个阶段:
第一阶段:使用大量可编译但不可链接(不可执行)的数据来训练模型。
这种可编译但是不可执行的数据很好获得,其次与它的可执行版本很相似只是缺少符号表。
第二阶段:对模型优化,以确保实用性。在后文中会介绍两个阶段训练的消融研究,附录b有对可编译数据与可执行数据之间的对比。
LLM4Decompile-Ref:
这部分主要是为了探索:如何通过传统的反编译工具Ghidra与大模型集成,从而显著提高工具。这部分旨在优化Ghidra的输出。
优化反编译框架:
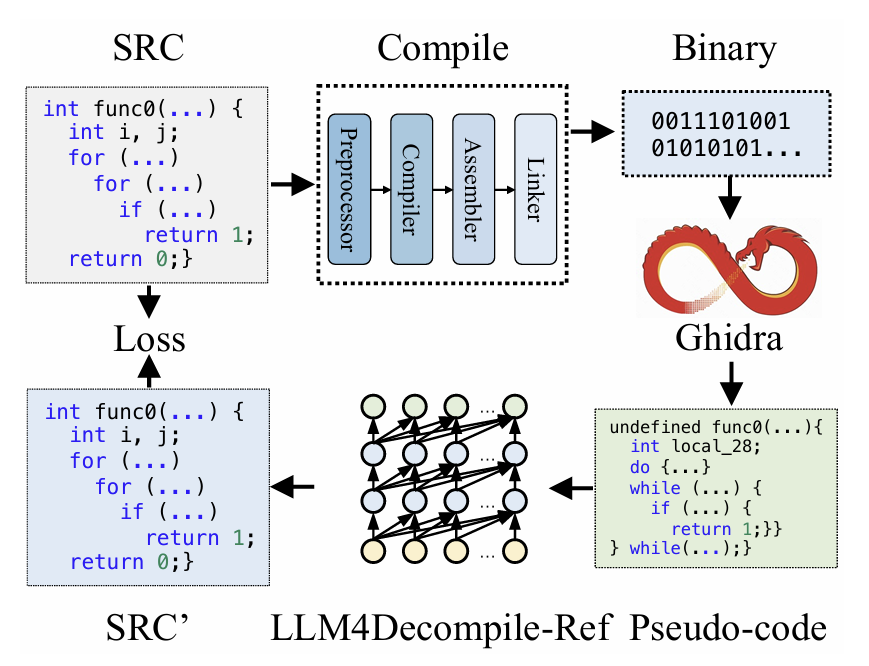
该方法与图2中的方法仅在大语言模型(LLM)的输入方面存在差异,在Refined-Decompile方法中,输入来自Ghidra的反编译输出。
具体来说,使用Ghidra对二进制文件进行反编译,然后对大语言模型进行微调,以优化Ghidra的输出。
虽然Ghidra生成的高级伪代码可能存在可读性问题和语法错误,但它有效地保留了底层逻辑。对这种伪代码进行优化,能显著减少理解晦涩汇编语言(ASM)所面临的挑战。
通过LLM4Decompile-Ref优化Ghidra:
- 使用Ghidra进行反编译:简而言之就是用Ghidra对不可执行文件进行反编译,能够让每个样本的时间缩短0.2s
- 优化策略:类似前文说到的编译选项上的优化,这里进一步使用LSH对数据进行过滤,来去掉重复
实验:
LLM4Decompile-end:
训练数据,如前文所说,基于Exebench,经过筛选。为了训练模型,采用了下面这种模板:
贴一下原文:
This is the assembly code: [ASM code] # What is the source code? [source code], where [ASM code] corre sponds to the disassembled assembly code from the binary, and [source code] is the original C func tion.
模板的选择不会影响性能,因为我们对模型进行微调以生成源码。
评估标准:引入HumanEval和Exebrench。将HumanEval的python解决方案和断言转换为C语言的,确保可以使用标准C库并且通过GCC编译,并通过所有断言。Exebrench自带真实的C函数,有输入和输出样例。
在评估上,沿用先前的研究来计算可重新执行率。在评估过程中,首先将C源代码编译为二进制文件,然后反汇编为汇编代码,并输入反编译系统以重构回C代码。接着,将此反编译得到的C代码与断言结合,检查其是否能够成功执行并通过这些断言。
模型配置:(这块建议看原文QAQ水平不够,LLM这块写的很模糊)
模型采用与DeepSeekCoder相同的架构,采用S2S预测(根据输入序列预测输出)。这里损失仅针对输出序列或者源码进行计算。
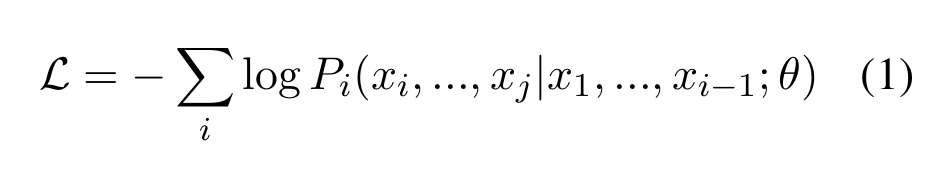
基线:两个基线进行比较,GPT-4o为代表的大语言模型;以及,DeepSeekCoder为代表的开源代码大语言模型。
实现:使用从Hugging Face获取的DeepSeek-Coder模型。
利用LLaMAFactory库训练模型,对于1.3B和6.7B模型,我们设置批处理大小为2048,学习率为(rate =2 e-5),并训练模型2个epochs(15B tokens)。实验在NVIDIA A100-80GB GPU集群上进行。在8×A100上,对1.3B和6.7B的LLM4DecompileEnd进行微调分别需要12天和61天。受资源限制,对于33B模型,我们仅训练2亿个token。在评估方面,使用vllm来加速生成(反编译)过程,最后采用贪婪解码以减少随机性。
实验结果:
Deepseek-Coder-33B的基础版本无法准确反编译二进制文件,会生成看似正确但是无法保留原始内容的代码;GPT-4o则是能够展现显著的反编译能力,对未优化的代码O0有着30.5%的成功率,但是对优化过的(O1-O3)成功率会大幅度下降。
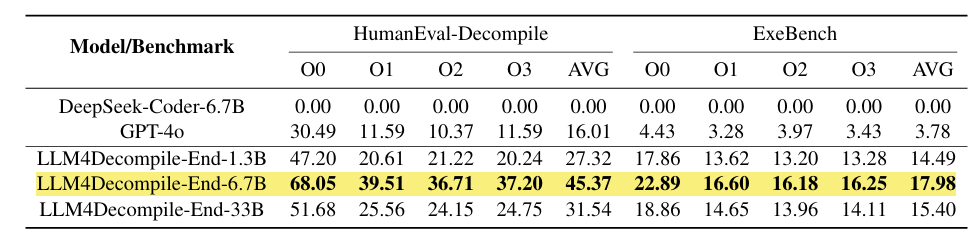
另一方面,LL4MDecomplie-End则表现出卓越的反编译能力,同时增大模型规模也很重要。
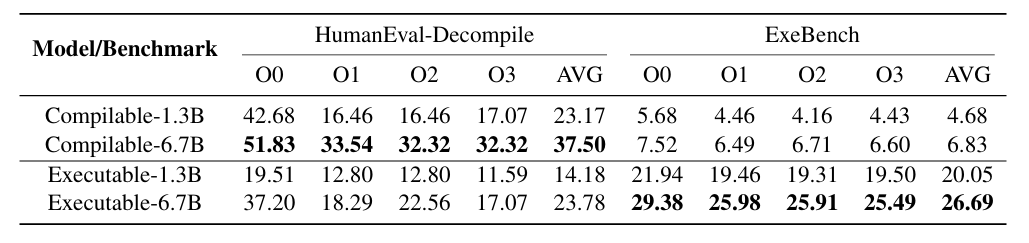
消融实验:
包含两个不同数据集720w个可编译函数和160w个可执行函数,实验结果如上所示。
函数调用在文本分布上与HumanEval-Decompile数据相似,由仅依赖标准C库的单个函数组成。因此,仅在可编译数据上训练的6.7B模型成功反编译了37.5%的HumanEval-Decompile函数,但在ExeBench上仅成功反编译了6.8%,因为ExeBench的特点是包含具有大量用户定义函数的真实函数。另一方面,仅在可执行数据上训练的6.7B模型在ExeBench测试集上的可重新执行率达到26.7%,但在处理单个函数时遇到了困难,由于训练语料库规模较小,在HumanEval-Decompile上的成功率仅为23.8%。
这里在附录C中有进行原因的简单分析,一句话总结就是“训练数据的‘量 - 质 - 场景覆盖度’与测试需求不匹配” 导致的 “能力偏科”。
- 仅可编译数据训练的模型:因数据无真实项目依赖,无法处理复杂场景;
- 仅可执行数据训练的模型:因数据量不足,既没学好真实场景的深度规律,也丢了基础语义能力;这也正是论文后续提出 “两阶段训练”(先可编译数据打基础、再可执行数据补场景)的核心动机 —— 通过数据互补解决单一数据的 “场景盲区” 与 “量不足” 问题。
LLM4Decompoile-Ref:
实验设置:
数据集:使用ExeBench构建,采用Ghidra Headless对二进制目标文件进行反编译。受计算资源限制,仅使用40w个函数进行训练,在HumanEval上进行评估。模型训练细节和上面一样。
实验结果:
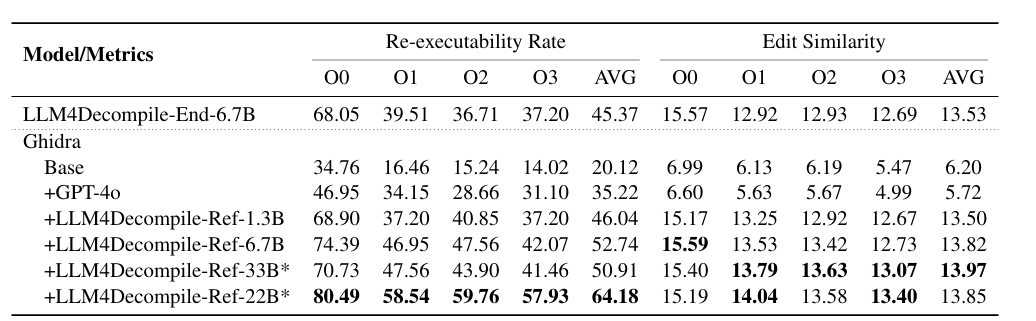
简而言之,对于Ghidra的输出石油显著提升的。
GPT-4o有助于优化此类伪代码并提升其质量。
LLM4Decompile-Ref模型相较Ghidra的输出有显著改进,其中6.7B模型使可重新执行性提升了160%。
同时,33B模型的性能优于1.3B模型,尽管其使用的训练数据明显更少。而且,它的性能仅比6.7B模型低3.6%,而6.7B模型得益于十倍于其的训练数据。与LLM4Decompile-End-6.7B相比,LLM4Decompile-Ref-6.7B模型尽管仅使用LLM4Decompile-Ref模型10%的数据进行训练,却展现出16.2%的性能提升,这表明Refined-Decompile方法具有更大的潜力。
这里简单说说附录D中提到的原因分析:
- 数据质量更高:简单说就是数据和测试场景更加匹配,过滤了部分非标准场景数据可以进一步提升性能
- 数据量:数据量适中,模型规模可以适当补充数据不足
- 基础模型选择:“反编译适配性” 比 “通用代码能力” 更重要
一点运行结果的展示比较:

在文本相似性方面,所有反编译输出都与原始源代码存在差异,编辑相似度在5.7%到14.0%之间,这主要是因为编译过程会移除变量名并优化逻辑结构。
Ghidra生成的伪代码可读性尤其差,平均编辑相似度为6.2%。有趣的是,经过GPT优化后(Ghidra+GPT-4o),编辑相似度略有下降。
GPT有助于修正诸如undefined4和ulong之类的类型错误(图4)。然而,它在准确重构for循环和数组索引方面存在困难。相比之下,LLM4Decompile-End和LLM4DecompileRef生成的输出更符合源代码的格式,也更易于理解。
混淆分析:

表中结果表明,基本的传统混淆技术足以阻止Ghidra和LLM4Decompile对经过混淆的二进制文件进行解码。
例如,最先进的模型LLM4Decompile-Ref-6.7B的反编译成功率在CFF下大幅下降90.2%(从0.5274降至0.0519),在BCF下下降78.0%(从0.5274降至0.1159)。
考虑到行业标准是在软件发布前采用多种复杂的混淆方法,表5中的实验结果减轻了人们对未经授权使用以侵犯知识产权的担忧。
小总结:
一点个人看法,总结一下论文中提到的这个end和ref之间的相同不同:
LLM4Decompile-Ref(优化式反编译)和 LLM4Decompile-End(端到端反编译)是论文针对反编译任务设计的两种互补技术路线,实验上的核心区别源于 “输入形式、训练目标、适用场景” 的根本差异,而单独拆分的核心目的是 “覆盖不同反编译需求、突破单一路线的性能瓶颈”。
LLM4Decompile-End是基于汇编,从无中生有,所以难度非常大;LLM4Decompile-Ref则是基于汇编伪代码,本身难度就要小一点,相当于对Ghidra的输出内容进行精细化加工。
| 对比维度 | LLM4Decompile-End(端到端) | LLM4Decompile-Ref(优化式) |
|---|---|---|
| 输入数据 | 二进制文件拆解后的汇编代码(ASM) 直接作为输入(无中间步骤) | 先通过 Ghidra 处理二进制,得到伪代码后作为输入(依赖传统工具的中间输出) |
| 训练数据与规模 | 基于 ExeBench 构建 “汇编 - 源代码” 对,训练数据量极大(720 万可编译样本 + 160 万可执行样本,共~85 亿 token) | 基于 ExeBench 构建 “Ghidra 伪代码 - 源代码” 对,训练数据量仅为前者的 10%(160 万样本,共~10 亿 token) |
| 训练目标 | 从底层汇编直接 “生成” 完整、可执行的高级源代码(需还原语法、结构、变量名等所有信息) | 对 Ghidra 输出的 “有逻辑但可读性差、有语法错误” 的伪代码进行 “优化修复”(无需从零生成,只需修正缺陷) |
| 核心实验指标表现 | - HumanEval-Decompile 平均可执行率 45.4%(6.7B 版本);- ExeBench 平均可执行率 18.0%;- 编辑相似度 13.53%,GPT 可读性评分 3.54 分 | - HumanEval-Decompile 平均可执行率 52.74%(6.7B 版本),比 End 高 16.2%;- 编辑相似度 13.85%(略高),可读性评分与 End 接近;- 对 Ghidra 伪代码的优化幅度达 160%(从 20.12%→52.74%) |
| 对编译优化级的适应性 | 优化级越高(O1-O3),性能下降越明显(O0 达 68.05%,O3 仅 37.20%) | 对优化级的敏感度更低(O0 达 74.39%,O3 达 42.07%),稳定性更强 |
| 错误类型分布(附录 C/D) | 主要错误是 “逻辑偏差”(如循环条件错误,占 HumanEval-Decompile 错误的 64%)和 “长序列语义丢失” | 主要错误是 “用户自定义组件还原失败”(占 ExeBench 错误的 40%),逻辑错误占比仅 25% |
| 训练成本(算力) | 极高:6.7B 模型需 8×A100 GPU 训练 61 天(因数据量巨大) | 较低:6.7B 模型仅需 8×A100 GPU 训练 8 天(数据量小,且输入是高层伪代码,学习难度低) |
局限:
仅限于x86平台的C语言编译与反编译。
成功对6.7B及以下规模的模型进行了全面微调,并利用小数据集对33B模型进行了初步探索,而70B及更大规模模型的探索则留待未来研究。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号