【论文阅读】Enhancing Protocol Fuzzing via Diverse Seed Corpus Generation (TSE PSG 2025)
Title:
Enhancing Protocol Fuzzing via Diverse Seed Corpus Generation
Zhengxiong Luo∗, Qingpeng Du†, Yujue Wang‡, Abhik Roychoudhury∗, and Yu Jiang‡
∗National University of Singapore †Beijing University of Posts and Telecommunications ‡Tsinghua University
研究背景与意义
协议模糊测试是发现网络协议实现漏洞的关键技术,而高质量、多样化的种子语料库是模糊测试效果的核心保障。但现有方案受限于初始种子语料库(Seed Corpus)的质量和多样性,在极大程度上会导致模糊测试难以发现隐藏在罕见逻辑中的漏洞。
RFC 作为协议格式的权威来源,却因非机器可读性、抽象性强,无法直接转化为机器可用的种子。因此,如何利用 RFC 生成覆盖全格式的多样化种子,成为提升协议模糊测试有效性的关键问题,对保障网络协议安全具有重要意义。
研究现状
基于三类方法:
目前种子生成主要基于三类方法:
•基于真实流量的方法:如 AFLNet 依赖捕获的网络流量生成种子,但真实流量存在消息分布偏差,仅能覆盖协议规范中少量常见格式,无法触发罕见但关键的处理逻辑;
•基于形式化语法的方法:以 BooFuzz 为代表,需用户手动定义协议语法模型,但不同协议(文本 / 二进制)语法差异大,且协议版本迭代时语法模型需持续手动维护,通用性与扩展性差;
•基于 LLM 直接生成的方法:部分工作尝试让 LLM 直接生成协议消息(如 ChatAFL 的种子增强模块),但 LLM 存在知识不完整、生成准确性低的缺陷,无法独立完成高质量种子生成。
研究目标:
提出PSG系统以提高种子质量
提出PSG(Protocol Seed Generator)系统,通过大语言模型(LLM)增强技术,将 RFC 转化为高质量、多样化的协议种子语料库,突破传统种子的多样性瓶颈,最终提升协议模糊测试的代码覆盖与漏洞发现能力。
存在的挑战:
如何处理庞大的 RFC 文档以实现有效的 LLM 增强?
问题: LLM 现有知识不完整,需要进行协议特定的知识增强。
难点: 每个协议对应的 RFC 文档数量多、相互关系复杂且内容极其庞杂,导致 LLM 难以直接理解和有效利用这些信息来指导输入生成。
如何高效地为多种协议生成合法输入?
问题: 生成合法的协议输入很困难,因为消息格式复杂,且字段之间存在多层依赖关系。
难点: 不同协议的格式高度定制化,需要一种通用且灵活的方法,既能跨越多种协议类型,又能同时确保生成结果的准确性和效率。
解决方案
PSG(Protocol Seed Generator)
实现的三个思想:LLM 增强 + 结构化知识工程 + 迭代优化
两大核心模块:
知识库构建(Knowledge Base Construction)和
无语法输入生成(Grammar-Free Input Generation)
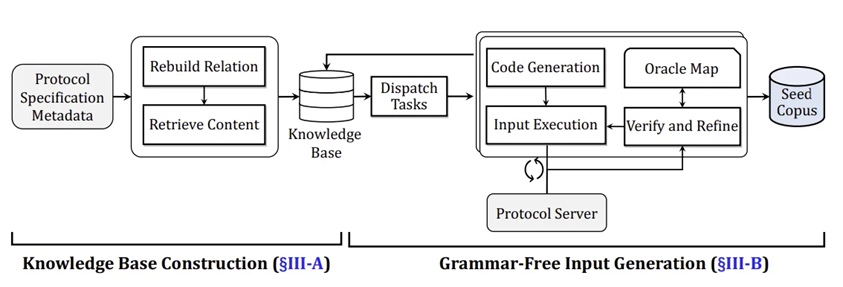
技术路线:
但是实际上这里涉及到的信息很重要,原文对这里的描述会清晰很多,建议直接看原文III. SYSTEM DESIGN
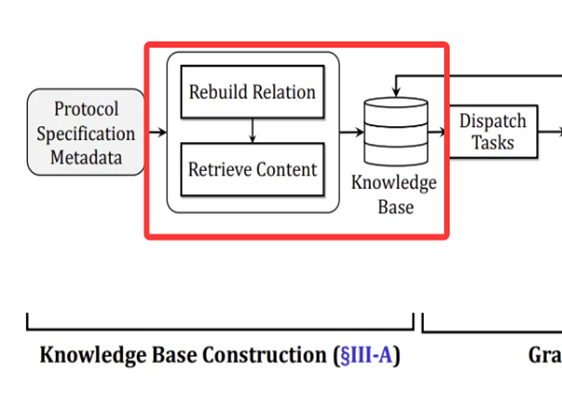
构建知识库:
(i)如何处理庞大的 RFC 文档以实现有效的 LLM 增强?
构建知识库:
(1)关系重建(Rebuild Relation)
重新提取协议参数与归属关系、更新参考 RFC、构建层级化格式视图
(2)内容检索(Retrieve Content)
RFC 分段(确保分段完整性)、相关性筛选与依赖识别(LLM+投票机)、存储关键信息(筛选后存储)
无语法输入生成:
(ii) 如何高效地为多种协议生成合法输入?
无语法输入生成(Grammar-Free Input Generation)
基于知识库增强 LLM,通过代码生成中间层 + 迭代精炼,生成符合协议规范的种子
这里无语法其实指的也就是直接依赖llm生成的东西作为输入
(1)任务调度(Dispatch Tasks)
- 按依赖生成任务
基于知识库中的格式依赖关系,确定生成顺序(如先生成 “OPEN” 消息,再生成依赖它的 “KEEPALIVE” 消息),确保生成的消息能被协议服务器正确接收;
- 构建前缀消息序列(Π_F)
为生成目标格式 F,先构造使服务器进入接收状态的消息序列,前缀序列从知识库中已生成的有效消息中选取。
(2)代码生成(Code Generation)
- Python为中间层
并非直接由llm生成二进制/文本信息,而是由llm生成对应python函数,利用这个函数返回目标字节流
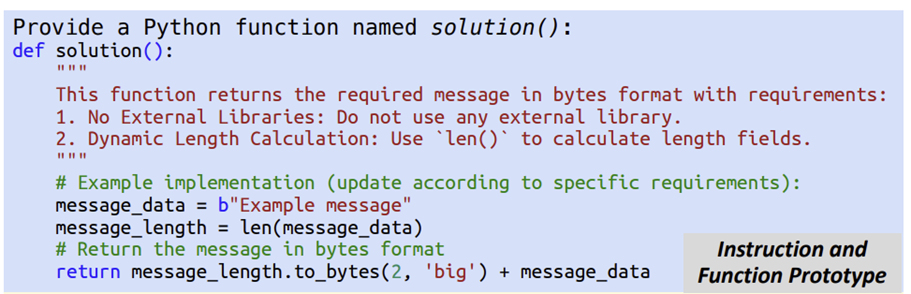
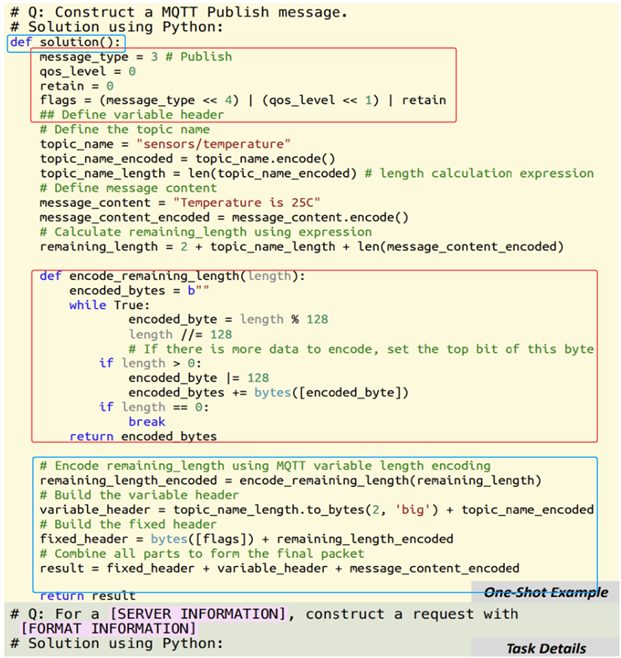
- 提示词设计
包含服务器信息、格式详情(从知识库获取的 RFC 内容)、函数原型要求,并通过(One-Shot Learning)提供示例
(3)输入执行与反馈获取(Input Execution)
*生成消息并发送至服务器
执行 LLM 生成的 Python 代码,得到具体消息(M_F),结合前缀序列(Π_F)发送给协议服务器;
*提取针对性反馈
仅保留与目标消息 M_F 直接相关的服务器响应,通过响应判断消息有效性
(4)验证与迭代精炼(Verify and Refine)
* 验证消息有效性:通过 LLM 分析服务器响应,判断消息是否合法
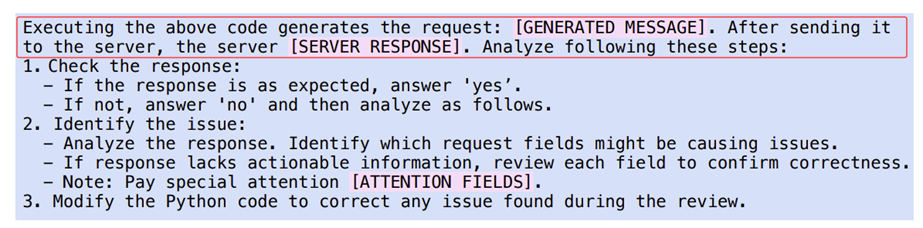
*多轮精炼优化:若消息无效,进入迭代精炼(这里最多为两轮):
错误定位:结合服务器反馈和 “Oracle Map”(记录历史精炼经验的动态映射表,LLM 定位问题字段(如 BGP “Opt Param Length” 计算错误);
代码修正:LLM 修正 Python 代码
反馈学习:精炼成功后,通过 “消息对齐”(对比原始与修正后的消息字节差异)和 “轻量级探针分析”( instrumentation 代码追踪字段修改对字节的影响),更新 Oracle Map,为后续生成规避同类错误;
反馈学习的两个核心部分:
- “消息对齐”:
在接受到原始消息(llm第一次生成)和精炼之后(llm迭代的)的消息之后,直接比较会比较困难。所以会用上这种消息对齐的技术
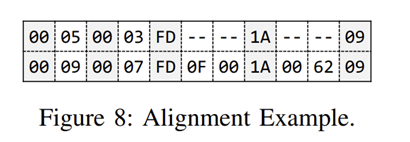
比如这样按需添加填充字节来对齐消息的字节,以在最大化共同性的同时揭示细微差别。对齐后,两条消息的长度相同,从而可以进行逐字节比较。
定义了一个指标函数最终实现映射,其结果会包含标识精炼之后的消息显示差异的字节索引,辅助后续回溯修改
- 轻量级探针分析(Lightweight Probe Analysis)
这个就主要为了解决追溯字段这个问题(就是我的代码到底哪里导致我生成的消息错误)。
使用这种方法就会生成代码的字段赋值语句,并单独修改它们,以观察其对 solution() 函数输出结果的影响。

比如这样,核心会关注常量赋值(Const)和表达式赋值(Expression)的部分。
•最终生成种子:
合法消息与前缀序列拼接,形成完整的种子序列),存入语料库。
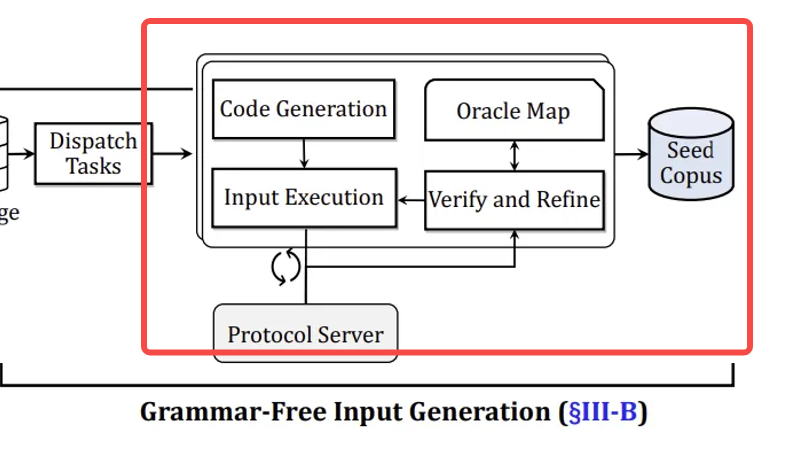
完整的算法逻辑展示:

实验评估:
两个维度:
1、生成种子语料库的有效性
*** Q1:** PSG 在生成更具多样性的种子语料库方面效果如何?
*** Q2:** PSG 的两大模块对系统的整体有效性有何贡献?
2、生成的种子语料库如何增强最先进的协议模糊测试工具的性能
*** Q3:** PSG 能否帮助最先进的协议模糊测试工具探索更多的代码区域(代码覆盖率的提高)
*** Q4:** 当协议模糊测试工具通过 PSG 增强后,在发现真实世界协议实现中的新漏洞方面效果如何?
•基于7种主流协议(包括 BGP、CoAP、SSH、DNS、HTTP、RTSP 和 FTP)和13 种实现(如 OpenSSH、FRR、Lighttpd)
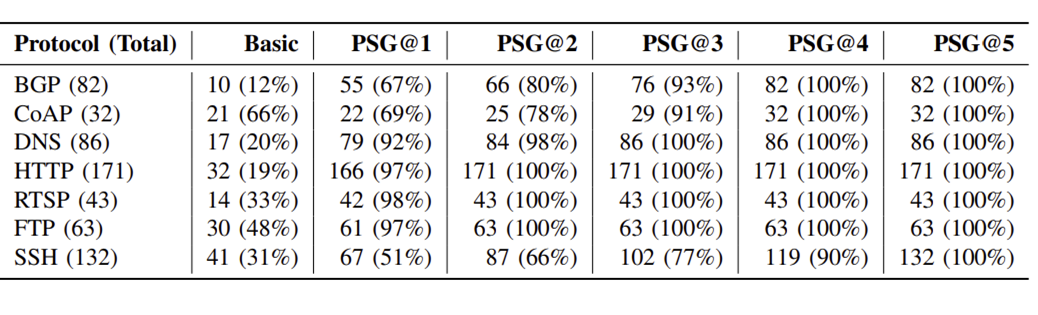
Q1: 种子多样性评估:
对比 “基础种子库”(基于真实流量)和 PSG 在不同生成尝试次数下的格式覆盖(Format coverage),结果如表所示:
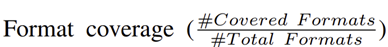
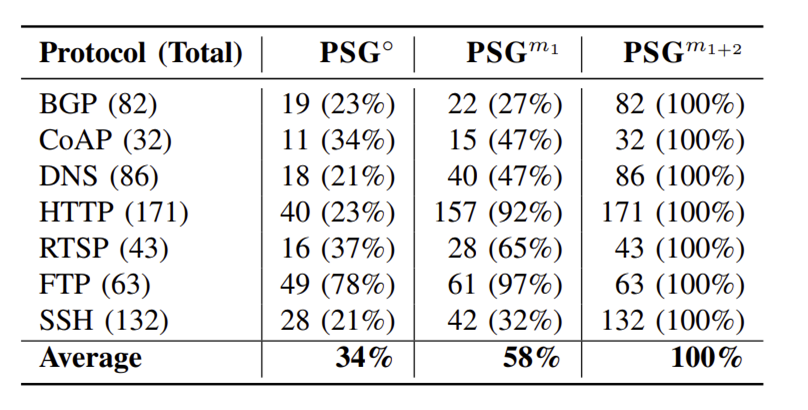
Q2: PSG两大模块的作用:
消融实验,以评估 PSG 的两个模块
(m1:知识库构建 和 m2:无语法输入生成)
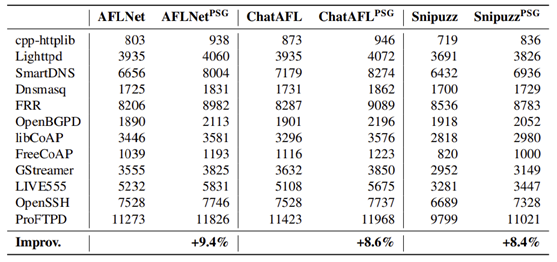
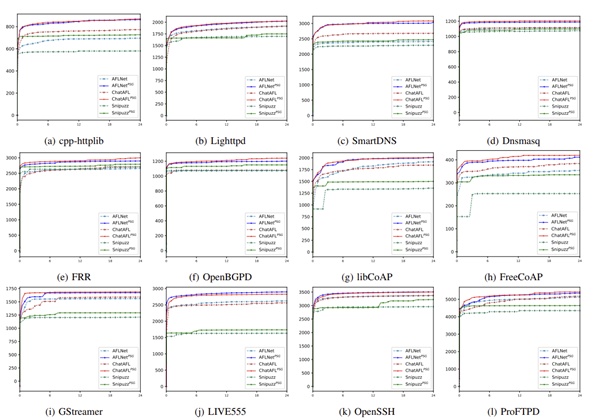
Q3:PSG 种子是否提升代码覆盖?
将 PSG 生成的种子用于三种主流协议模糊测试工具(AFLNet、ChatAFL、Snipuzz),对比基础种子库的代码覆盖:
Q4:PSG 种子是否能发现新漏洞?
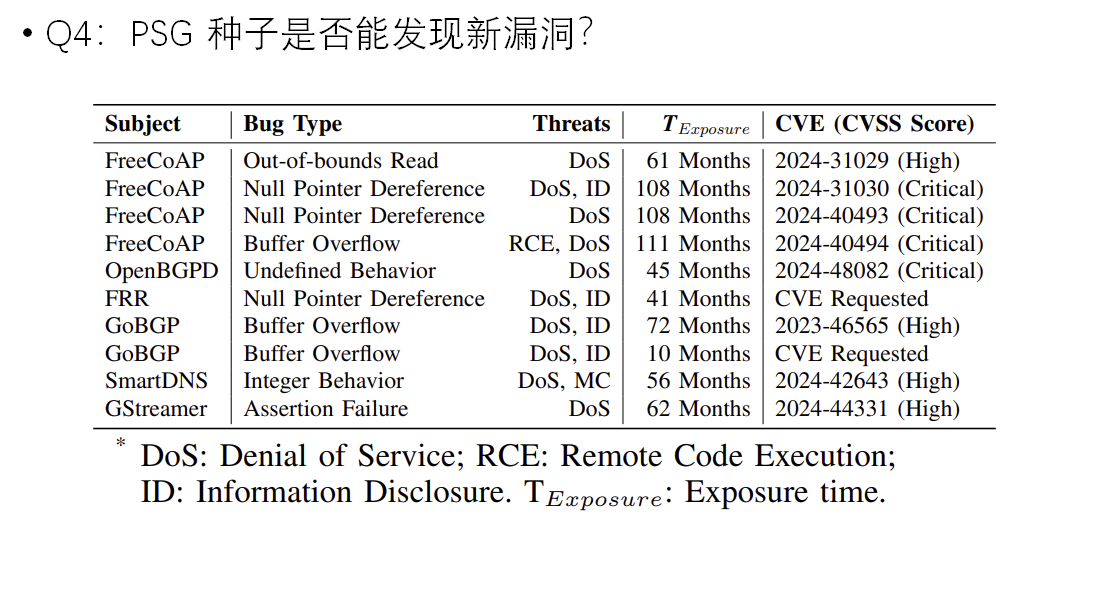
总结:
PSG系统的三大创新点:
知识增强:
方法: 系统地组织和检索外部、精确的协议知识(RFC 内容)。
目的: 用于 LLM 的任务规划和精确知识补充,解决了 LLM 固有知识不足的问题。
代码生成作为中间桥梁:
方法: 利用 LLM 的编程能力,将代码生成作为中间步骤。
目的: 成功连接了自然语言(RFC)和二进制/文本消息,实现了协议无关的通用性。
反馈驱动的迭代精炼:
方法: 结合对生成的代码进行轻量级程序分析和服务器的实时反馈。
目的: 协同引导 LLM 进行迭代修正,显著提高了生成协议消息的准确性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号