

sparkcore-sparksql数据清洗
数据格式
原格式
| 日期 | 时间 | 种类 | 监测站1数据 | 监测站…数据 |
|---|---|---|---|---|
| String | Int | String | Double | Double |
数据清洗
PM2.5表、O3表…
| 时间 | 监测站 | 数据 |
|---|---|---|
| String(“yyyy-MM-dd-HH“) | String | Double |
这样会出现大量数据冗余但是去掉了空值,并且以时间和监测站为主键更加容易操作。
源数据表节选:
| date | hour | type | 1001A | 1002A |
|---|---|---|---|---|
| 20150102 | 1 | AQI | 117 | 85 |
| 20150102 | 1 | PM2.5 | 88 | 34 |
| 20150102 | 1 | PM2.5_24h | 48 | 54 |
思路
先把第一行的表头提取出来,影响操作数据。
除去第一行表头,获取所有数据,对每行数据进行切分,把type作为RDD的主键,再以date+hour作为key,其余数据作为value拼接成map,map为RDD的值。为了区分map中的key和value,date和hour使用",“链接,多个value使用”-"链接。
既(PM2.5,(20150102,1,88-34))
使用filter只取某一个type的数据,然后去掉key,既(20150102,1,88-34)
对RDD进行行转列,对后排的数据进行切分,切分后格式为(20150102,1,Array[88,34])
然后再进行模式匹配,对切分后的数组进行拆分,既行转列(20150102,1,88),(20150102,1,34)
在表头中取出所有的监测站代码组成一个字符串数组
将每一列的数据和监测站代码一一对应。(20150102,1,1001A,88)
输出至文件中。
这个垃圾数据我日,大体上没有问题,具体的文件中全是报错,一定要把所有情况考虑清楚。
有的文件中最后几行没有任何数据,比如22点以后不进行检测的。这样你如果直接去拉去line(3),就会因为没有数据导致数组溢出。
有的文件表头不全,你明明切出来是1563个监测站,但是第1563个监测站就会报数组溢出,挺离谱的。
有的文件甚至连检测的污染物类型都没有,你一取line(2)数组溢出我是没想到的,日了狗了。
数据结构优化
| 日期 | 监测站 | 0时数据 | 1时数据 | …时数据 |
|---|---|---|---|---|
| String(“yyyy-MM-dd“) | String | Double | Double | Double |
减少了数据冗余,有效的减少存储量。因为一天一共就24个小时,合并成列也不算多。源数据两千八百多个列就挺尼玛离谱。
这样需要先进行行转列,把表头的监测站代码放进数据中,再列转行,把时间调整到表头,比较麻烦,但是既解决了空值问题,又减少了数据冗余。
既然第一步已经将数据格式化了,就可以存入hive进行操作了。
数据上传
先使用rz命令将数据上传到集群中,再上传至hdfs
hadoop fs -put air2015-2018/ /air/input
数据操作
package com.digitalchina
import java.io.IOException
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object AirQualityTest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
.setAppName("AirQuality")
val sc = new SparkContext(sparkConf)
val readRDD = sc.textFile(args(0))
val airRDD = readRDD.map(
line => {
//分割字符串
val lines = line.split(",")
//先判断到底是否有数据
if(lines.length>3) {
//以日期,时间为key
val key = lines(0) + "," + lines(1)
//剩下的所有数据为value,循环组成一个map
var value = lines(3)
for (i <- 4 to lines.length - 1) {
value = value + "-" + lines(i)
}
//以污染物为主键,map为值组成RDD
(lines(2), (key, value))
}else{
//如果没有数据,就直接给三个空字符串,后面会去掉空字符串,键值不要给污染物类型line(2)
//有的数据没有污染物的类型,尼玛离谱line(2)报了个数组溢出,表结构都没有为什么不丢弃啊?
("", ("", ""))
}
})
collectRDD(airRDD,"PM2.5",args(1))
collectRDD(airRDD,"PM10",args(1))
collectRDD(airRDD,"SO2",args(1))
collectRDD(airRDD,"NO2",args(1))
collectRDD(airRDD,"O3",args(1))
collectRDD(airRDD,"CO",args(1))
sc.stop()
}
def collectRDD(airRDD: RDD[(String, (String, String))],pollution:String,output:String) {
//取第一行表头(type,(date,hour,1001A,1002A,1003A))
val headRDD = airRDD.first()
//生成监测站代码数组(1001A,1002A,1003A,1004A,1005A,1006A)
val stations = headRDD._2._2.split("-")
//去除表头只保留数据
val valRDD = airRDD.filter(row => row != headRDD)
//例如(PM2.5,(20150102,1,88,34,82,100,126,85))
val PM25RDD = valRDD.filter(x=>{
//只取pollution的数据
x._1.equals(pollution)
}).map(
//进行行转列
x => {
//对后排的多列数据进行切分
(x._2._1,x._2._2.split("-"))
}
).map(
x=>{
var i= -1
x._2.map(
//把后排数据格式化,行转列拆分
//(20150102,1,88)
y=>
{
i=i+1
//判定i是否会溢出,有的数据没有表头,数据长度比表头长度要长,造成数组溢出
if(i<=stations.length-1) {
//取监测站代码,拼接,以时间+监测站为key,数值为value
(x._1, stations(i), y)
}else {
//如果有冗余字段找不到表头,就舍弃
(x._1,"","")
}
}
)
}
//最后再去除空值,完美
).flatMap(x=>x).filter(x=>x._3!="")
PM25RDD.map(
x=>{
//最后去掉括号(date,time,station,value)->date,time,station,value
x._1+","+x._2+","+x._3
}
//先将文件写入临时目录
).repartition(1).saveAsTextFile(output+"/"+pollution)
println("统计数据"+pollution+"成功")
}
}
注意这里打的jar包,就是target下面的那个几kb的jar,如果把你的依赖包全部导入以后,不仅jar变成了几百MB,而且会报错,因为saprk集群的环境会优先在你的jar依赖中寻找包。
java.lang.ClassNotFoundException: com.digitalchina.AirQualityTest.calss
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.spark.util.Utils$.classForName(Utils.scala:177)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:688)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:181)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:206)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:121)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
spark-submit --master yarn --class com.digitalchina.AirQualityTest airquality-1.0-SNAPSHOT.jar /air/input/*/* /air/output
注意这里的参数,第一个参数是数据的原路径,第二个参数是输出路径,spark运行是默认hdfs路径,如果–master local 默认本地路径。
还要注意集群中scala的版本,一定要和开发包的scala版本一致。
java.io.IOException: unexpected exception type
java.lang.NoSuchMethodError: scala.runtime.ObjectRef.create(Ljava/lang/Object;)Lscala/runtime/Object
以上两种错误都是scala编译版本和spark集群的scala版本不一致导致的,注意这里是spark中集成的scala,而不是你安装的scala。CDH默认安装的是spark1.6.0,建议重新安装spark2.x,spark2和spark1.6可以共存不冲突。pom中更改了scala版本后,在package前记得先运行一下,防止编译器从之前的缓存中拿修改前的配置打包。
spark-shell启动客户端,可以从日志信息中看到集成scala版本是2.10.5,把pom文件和global lib里的scala版本换成2.10.5即可。
运行过程
数据导入
package sparkSQL
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, sql}
object AirQualityHive {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "root")
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQLS")
val spark = new sql.SparkSession.Builder()
.enableHiveSupport()
.config(sparkConf)
.getOrCreate()
// loadHive("pm25",spark)
loadHive("pm10",spark)
loadHive("so2",spark)
loadHive("no2",spark)
loadHive("o3",spark)
loadHive("co",spark)
spark.stop()
}
def loadHive(pollution:String,spark:SparkSession): Unit = {
/**
* 参数1:污染物名称
* 参数2:sparkSession
*/
//TODO 建表
spark.sql("CREATE TABLE IF NOT EXISTS`"+pollution+
"""val`(
| `date` string,
| `hour` string,
| `stationid` string,
| `value` double)
|row format delimited fields terminated by ','
|""".stripMargin)
var a=""
if (pollution=="pm25"){
a="PM2.5"
}else {
a=pollution.toUpperCase
}
spark.sql("load data inpath 'hdfs://cdh01:8020/air/output/"+a+"/part-00000' into table "+pollution+"val")
var s = "CREATE TABLE IF NOT EXISTS "+pollution+""" as
|select date,stationid,
|sum(case when hour=0 then value end) as 0h,
|sum(case when hour=1 then value end) as 1h,
|sum(case when hour=2 then value end) as 2h,
|sum(case when hour=3 then value end) as 3h,
|sum(case when hour=4 then value end) as 4h,
|sum(case when hour=5 then value end) as 5h,
|sum(case when hour=6 then value end) as 6h,
|sum(case when hour=7 then value end) as 7h,
|sum(case when hour=8 then value end) as 8h,
|sum(case when hour=9 then value end) as 9h,
|sum(case when hour=10 then value end) as 10h,
|sum(case when hour=11 then value end) as 11h,
|sum(case when hour=12 then value end) as 12h,
|sum(case when hour=13 then value end) as 13h,
|sum(case when hour=14 then value end) as 14h,
|sum(case when hour=15 then value end) as 15h,
|sum(case when hour=16 then value end) as 16h,
|sum(case when hour=17 then value end) as 17h,
|sum(case when hour=18 then value end) as 18h,
|sum(case when hour=19 then value end) as 19h,
|sum(case when hour=20 then value end) as 20h,
|sum(case when hour=21 then value end) as 21h,
|sum(case when hour=22 then value end) as 22h,
|sum(case when hour=23 then value end) as 23h
|from
|""".stripMargin+pollution+"val group by date,stationid"
spark.sql(s)
}
}
这个主要看hql语句就行了,有时候idea里报错我就直接复制到hive里执行,问题不大。正常来讲是可以直接运行的。
结果数据
结果数据展示
| date | station | 0h | 1h | 2h | 3h | 4h | 5h | 6h | 7h | 8h | 9h |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 20150102 | 1001A | NULL | 88.0 | 94.0 | 82.0 | 47.0 | 34.0 | 18.0 | 9.0 | 10.0 | 7.0 |
| 20150102 | 1002A | NULL | 34.0 | 15.0 | 13.0 | 10.0 | 8.0 | 10.0 | 14.0 | 10.0 | 16.0 |
| 20150102 | 1003A | NULL | 82.0 | 81.0 | 68.0 | 36.0 | 16.0 | 8.0 | 5.0 | 4.0 | 3.0 |

数据导出
使用sqoop组件,将hive中计算后的数据导入到mysql中。
首先在mysql中创库建表这里注意表结构和hive中的一定要保持一致,以co表为例,其他表改改名就行了。
CREATE TABLE `co` (
`date` varchar(255) DEFAULT NULL,
`stationid` varchar(255) DEFAULT NULL,
`0h` double(10,3) DEFAULT NULL,
`1h` double(10,3) DEFAULT NULL,
`2h` double(10,3) DEFAULT NULL,
`3h` double(10,3) DEFAULT NULL,
`4h` double(10,3) DEFAULT NULL,
`5h` double(10,3) DEFAULT NULL,
`6h` double(10,3) DEFAULT NULL,
`7h` double(10,3) DEFAULT NULL,
`8h` double(10,3) DEFAULT NULL,
`9h` double(10,3) DEFAULT NULL,
`10h` double(10,3) DEFAULT NULL,
`11h` double(10,3) DEFAULT NULL,
`12h` double(10,3) DEFAULT NULL,
`13h` double(10,3) DEFAULT NULL,
`14h` double(10,3) DEFAULT NULL,
`15h` double(10,3) DEFAULT NULL,
`16h` double(10,3) DEFAULT NULL,
`17h` double(10,3) DEFAULT NULL,
`18h` double(10,3) DEFAULT NULL,
`19h` double(10,3) DEFAULT NULL,
`20h` double(10,3) DEFAULT NULL,
`21h` double(10,3) DEFAULT NULL,
`22h` double(10,3) DEFAULT NULL,
`23h` double(10,3) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
然后再linux中使用sqoop的shell命令将数据导出。
sqoop export \
--connect jdbc:mysql://cdh00:3306/airquality \
--username root \
--password root \
--table co \
--export-dir hdfs://cdh01:8020/user/hive/warehouse/co \
--input-fields-terminated-by '\001' \
--input-null-string '\\N' \
--input-null-non-string '\\N'
前面的数据库链接啥的就不说了,看一下–input-fields-terminated-by ‘\001’,这里是指hive的数据的分隔符,如果你在建hive表时没有设置分隔符的话默认是按照"\001"分割的,在notepad++中查看是SOH特殊字符。上面建表时我忘了更改分隔符row format delimited fields terminated by ‘,’,分隔符是默认的’\001’,所以这一条参数不加也不会报错。
一定要注意最后两行,如果不加最后两行会报错。
20/08/27 15:03:05 ERROR tool.ExportTool: Error during export:
Export job failed!
at org.apache.sqoop.mapreduce.ExportJobBase.runExport(ExportJobBase.java:439)
at org.apache.sqoop.manager.SqlManager.exportTable(SqlManager.java:931)
at org.apache.sqoop.tool.ExportTool.exportTable(ExportTool.java:80)
at org.apache.sqoop.tool.ExportTool.run(ExportTool.java:99)
at org.apache.sqoop.Sqoop.run(Sqoop.java:147)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:183)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:234)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:243)
at org.apache.sqoop.Sqoop.main(Sqoop.java:252)
这里的错误就是经典的hive和mysql的表结构不对应,sqoop把你的数据往mysql中塞的时候格式不符报错了,他就会返回这个错误。处理方式首先就应该检查两个表结构是否一致,在检查后我发现两个表结构是完全一致的,也有可能是上面说的hive的分隔符弄错了,检查后也没有问题,hive中确实使用用默认的’\001’作为分隔符,那为什么会报错嘞?
除了hive表结构之外,我们再检查一下hive的数据,在hdfs/user/hive/warehouse/co中,可以在linux中hadoop fs -cat /user/hive/warehouse/co查看,为了方便我这里选择在windows中下载查看。
201501122002A\N2.105
可以看到分隔符确实是"\001",但是double数据中有一个突兀的"\N"。因为hive中的null值默认是按照字符串"\N"存储的,所以在获取数据时出现字符串"\N",而"\N"是字符串格式不符合double类型导致报错。这里有两种处理方法,一种是将表结构统一改成varchar类型,但是这样"\N"就按照字符串存入了,不方便处理,所以加上后两条,在sqoop遇到"\N"后按照null进行插入处理。
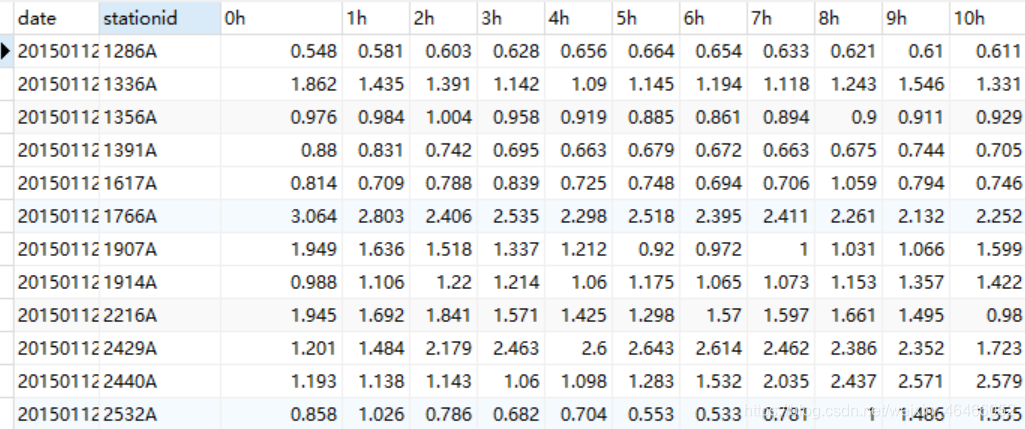
表结构转换后就很方便操作了。如果感觉有空值难以接受的话,可以用coval表进行操作。
