自用django笔记
自用django笔记
django的本质就是基于socket通信

一。127.0.0.1 本地回环地址 后面:8001是端口号 /ppt是根目录下的ppt子网页
二。/当前网站的客户端(根目录)
例如:
127.0.0.1/#默认80可以不写
手写一个mange.py django配置环境(脚本)
manage.py写法
import os
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "dj.settings")#应用当前项目的settings配置
test.py 手动配置django环境 (脚本)
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "dj.settings")#应用当前项目的settings配置
django.setup()
from app01 import models#非内置引用需要在setup之后
web框架的功能;
1.使用socket收发信息
2.根据不同路径返回不同的内容
3. 返回动态的数据(字符串的替换 模板的渲染)
流程
1.http:www.s24.com:80-dns 解析地址 为ip地址 这是客户端
2.通过切割获得对应地址
3.发送响应成功
4.然后for循环进行path取值
5.从对应的服务端获取到对应的路径 访问视图

web框架的几个开源版本
low版web框架
import socket
server=socket.socket()
server.bind(('127.0.0.1',8001))
server.listen()
while 1:
conn,addr=server.accept()
from_brower_msg=conn.recv(1024)
path=from_brower_msg.decode('utf-8').split(' ')[1]#对收到消息编码转换成字符串,切割成列表【0】是方法【1】是对应的页面
#GET / HTTP/1.1
#/是本页面的主页面 /后面的home page什么的都是对应的子页面
print(path)
conn.send(b'http/1.1 200 ok\r\n\r\n')
if path=='/':#读取文件都用rb
with open("04test.html",'rb')as f:
data=f.read()
elif path=='/style.css':#判断路径是否存在
with open('style.css','rb')as f:
data=f.read()
elif path == '/mi.png':#每遇到一个url都会请求一次
with open('mi.png', 'rb') as f:
data = f.read()
elif path=="./test.js":
with open("test.js","rb")as f:
data=f.read()
conn.send(data)
conn.close()
html页面
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<link rel="stylesheet" href="./style.css"><!--从上往下执行 遇到io(地址主动向服务端发送请求)-->
</head>
<body>
<h2>24期官网</h2>
<div>
<img src="./mi.png" alt=""><!--从上往下执行 遇到io(地址主动向服务端发送请求)-->
</div>
<script src="test.js"></script><!--从上往下执行 遇到io(地址主动向服务端发送请求)-->
</body>
</html>
只要跳出html文件就会出问题
升级函数版多线程
import socket
from concurrent.futures import ThreadPoolExecutor
server=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
server.bind(("127.0.0.1",8848))
server.listen()
#一定记得关闭连接 等待下一个连接请求
#处理页面请求的函数
def home(conn):
with open('04test.html','rb')as f:
data=f.read()
conn.send(data)
conn.close()#关闭连接等待下一个请求
#处理页面link( <link rel="stylesheet" href="test.css">)标签href属性值是本地路径的时候的请求
def css(conn):
with open('style.css','rb')as f:
data=f.read()
conn.send(data)
conn.close()#关闭连接
#处理页面script(<script src="test.js"></script>)标签src属性值是本地路径的时候的请求
def js(conn):
with open("test.js","rb")as f:
data=f.read()
conn.send(data)
conn.close()
#处理页面img标签src属性值是本地路径的时候的请求
def pic(conn):
with open("mi.png","rb")as f:
data=f.read()
conn.send(data)
conn.close()#关闭
while 1:
conn,addr=server.accept()
from_brower_msg = conn.recv(1024)
# print(from_brower_msg)
path = from_brower_msg.decode('utf-8').split(' ')[1]
print(path)
conn.send(b'HTTP/1.1 200 ok\r\n\r\n')
urlpatterns = [
('/',home),
('/style.css',css),
('/test.js',js),
('/mi.png',pic)
]
#线程池
for url in urlpatterns:
if path ==url[0]:
# ret=url)[1](
t=ThreadPoolExecutor()#开启一个线程池
t.submit(url[1],conn)#
break
else:
conn.send(b'404')
············································ #多线程
for url in urlpatterns:
if path == url[0]:
t = Thread(target=url[1],args=(conn,))
t.start()
break
else:
conn.send(b'404')
jinja2 第三方内置框架和wsgiref类似socketserver
jinja2 (浏览器渲染)本质是字符串替换
把数据库中查询到的内容进行文本的替换,读取用r
字符串替换replace
用jinja2独有的渲染方法 flask 里面的东西 没有渲染 利用jinja2渲染
wsgiref和jinja
from wsgiref.simple_server import make_server
from jinja2 import Template
def index():
# 把数据库中查询到的内容进行文本的替换,读取用r
with open("index2.html", "r",encoding='utf-8') as f:
data = f.read()
template = Template(data) # 生成模板文件
ret = template.render({"name": "于谦", "hobby_list": ["烫头", "泡吧"]}) # 把数据填充到模板里面
return [bytes(ret, encoding="utf8"), ]
# 定义一个url和函数的对应关系
URL_LIST = [
("/index/", index),
]
#environ返回的是一个字典
def run_server(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html;charset=utf8'), ]) # 设置HTTP响应的状态码和头信息
url = environ['PATH_INFO'] # 取到用户输入的url
func = None # 将要执行的函数
for i in URL_LIST:
if i[0] == url:
func = i[1] # 去之前定义好的url列表里找url应该执行的函数
break
if func: # 如果能找到要执行的函数
return func() # 返回函数的执行结果
else:
return [bytes("404没有该页面", encoding="utf8"), ]
if __name__ == '__main__':
httpd = make_server('', 8000, run_server)
print("Serving HTTP on port 8000...")
httpd.serve_forever()#发送给浏览器
html
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta http-equiv="x-ua-compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Title</title>
</head>
<body>
<h1>姓名:{{name}}</h1>#第一种写法
<h1>爱好:</h1>
<ul>
{% for hobby in hobby_list %}#第二种写法循环键值对
<li>{{hobby}}</li>
{% endfor %}
</ul>
</body>
</html>
reponse
wsgiref框架
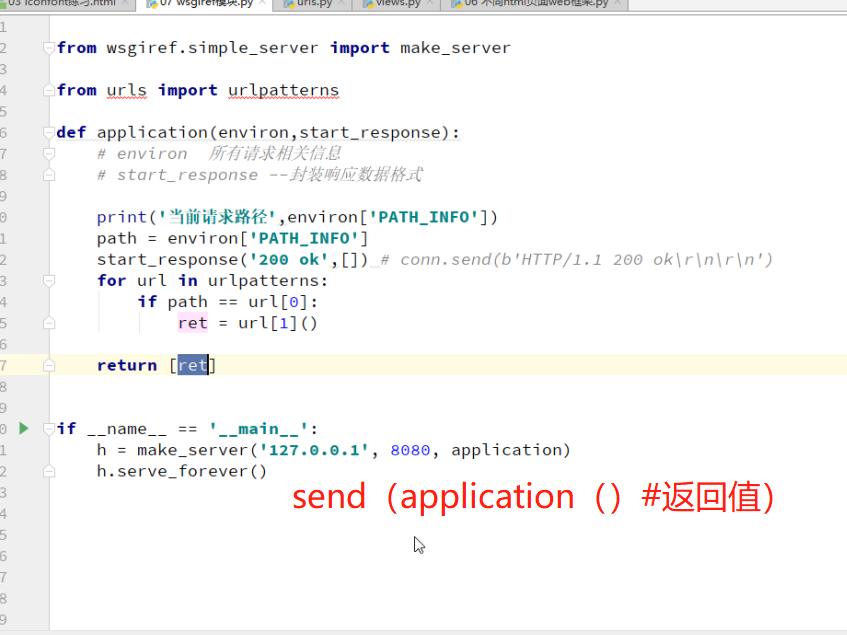
http 规定请求和响应的标准
get获取数据 post 提交数据
1.客户端链接web服务器 connect
2.发送http请求
3.服务器接收请求并返回http响应
4.释放链接tcp连接
5.客户端浏览器解析html内容
http的分为两种
短链接和无连接 无状态
无连接发送完就断开链接,
无连接有两种模式
短链接
发送完数据等待几秒客户端的操作
无状态
不会保留状态
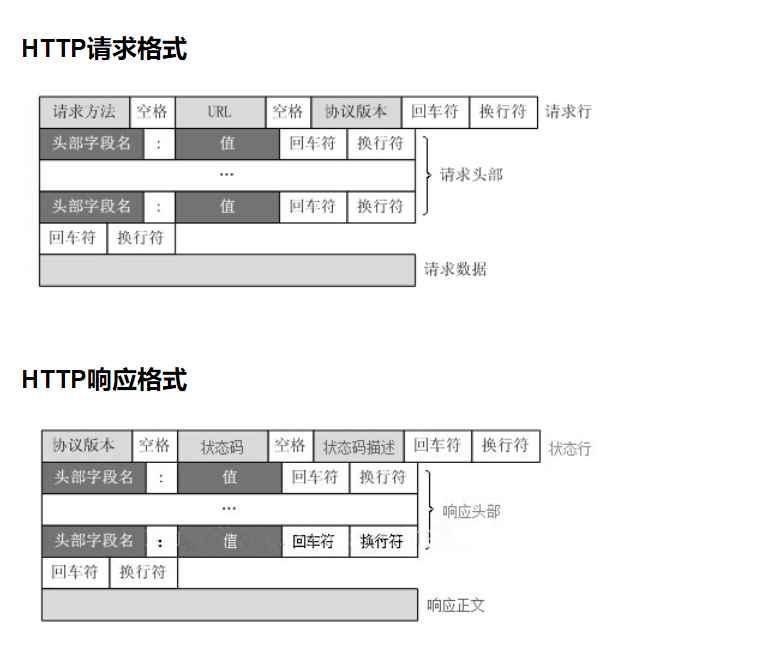
http
http协议
请求信息格式
GET / HTTP/1.1 请求行
Host: 127.0.0.1:8003 请求头
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36
指定 浏览器格式
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
#空行br
请求数据 username=ziwen password=666
get请求 请求数据部分是没有数据的,get请求的数据在url上,在请求行里面,有大小限制,常见的get请求方式: 浏览器输入网址,a标签
post请求 请求数据在请求体(请求数据部分) ,数据没有大小限制, 常见方式:form表单提交数据
HTTP协议定义Web客户端如何从Web服务器请求Web页面,以及服务器如何把Web页面传送给客户端。HTTP协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据.
以下是 HTTP 请求/响应的步骤:
1. 客户端连接到Web服务器
一个HTTP客户端,通常是浏览器,与Web服务器的HTTP端口(默认为80)建立一个TCP套接字连接。例如,http://www.luffycity.com。
2. 发送HTTP请求
通过TCP套接字,客户端向Web服务器发送一个文本的请求报文,一个请求报文由请求行、请求头部、空行和请求数据4部分组成。
3. 服务器接受请求并返回HTTP响应
Web服务器解析请求,定位请求资源。服务器将资源复本写到TCP套接字,由客户端读取。一个响应由状态行、响应头部、空行和响应数据4部分组成。
4. 释放连接TCP连接
若connection 模式为close,则服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP连接;若connection 模式为keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求;
5. 客户端浏览器解析HTML内容
客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据HTML,根据HTML的语法对其进行格式化,并在浏览器窗口中显示。
````````````````````````````````````
在浏览器地址栏键入URL,按下回车之后会经历以下流程:
1.浏览器向 DNS 服务器请求解析该 URL 中的域名所对应的 IP 地址;
2.解析出 IP 地址后,根据该 IP 地址和默认端口 80,和服务器建立TCP连接;
3.浏览器发出读取文件(URL 中域名后面部分对应的文件)的HTTP 请求,该请求报文作为 TCP 三次握手的第三个报文的数据发送给服务器;(根据不同路径返回不同数据)
4.服务器对浏览器请求作出响应,并把对应的 html 文本发送给浏览器;
5.释放 TCP连接;(conn.close())因为tcp是长连接 http协议的特点
6.浏览器将该 html 文本并显示内容;
请求方法
八种动作
常用get post
#GET
//向指定的资源发出“显示”请求。使用GET方法应该只用在读取数据,而不应当被用于产生“副作用”的操作中,例如在Web Application中。其中一个原因是GET可能会被网络蜘蛛等随意访问。
#HEAD//
//与GET方法一样,都是向服务器发出指定资源的请求。只不过服务器将不传回资源的本文部分。它的好处在于,使用这个方法可以在不必传输全部内容的情况下,就可以获取其中“关于该资源的信息”(元信息或称元数据)。
#POST
//向指定资源提交数据,请求服务器进行处理(例如提交表单或者上传文件)。数据被包含在请求本文中。这个请求可能会创建新的资源或修改现有资源,或二者皆有。(把信息放入了请求数据)
PUT
//向指定资源位置上传其最新内容。
DELETE
//请求服务器删除Request-URI所标识的资源。
TRACE
//回显服务器收到的请求,主要用于测试或诊断。
OPTIONS
//这个方法可使服务器传回该资源所支持的所有HTTP请求方法。用'*'来代替资源名称,向Web服务器发送OPTIONS请求,可以测试服务器功能是否正常运作。
#CONNECT
//HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。通常用于SSL加密服务器的链接(经由加密的HTTP代理服务器)。
patch
局部更新数据

http状态码
1xx消息——请求已被服务器接收,继续处理
2xx成功——请求已成功被服务器接收、理解、并接受
3xx重定向——需要后续操作才能完成这一请求
4xx请求错误——请求含有词法错误或者无法被执行
5xx服务器错误——服务器在处理某个正确请求时发生错误
重定向
例如一个http:jd.com/auth
1.输入 username和passwerd 提交数据
2.判断用户是否合法
3.如果是重定向 3xx
4.浏览器拿到网址,get请求获取对应的html
首页 http:www.jd.com
mvc和mtv框架
mvc
M --- models 数据库相关
v --- views 视图相关(逻辑)
C -- controller url控制器(url分发器,路由分发)
django-mtv
M -- models 数据库相关
T -- templates HTML相关 html就是模板
V -- views 视图相关(逻辑)s
+ controller url控制器(url分发器,路由分发)
url
https默认 443端口
http默认 80端口
查询参数
?k1=v1&k2=v2 get获取
注意点
url('^login/$'),views.视图函数,name='别名',
# $用于为防止被前面,相似的路径进行错误匹配到使用$进行限制
超文本传输协议(HTTP)的统一资源定位符将从因特网获取信息的五个基本元素包括在一个简单的地址中:
传送协议。
层级URL标记符号(为[////],固定不变)
访问资源需要的凭证信息(可省略)
1.服务器。
#//(通常为域名,有时为IP地址(dns解析))
2.端口号。
//(以数字方式表示,若为HTTP的默认值“:80”可省略)
路径。
//(以“/”字符区别路径中的每一个目录名称)
查询。
//(GET模式的窗体参数,以“?”字符为起点,每个参数以“&”隔开,再以“=”分开参数名称与数据,通常以UTF8的URL编码,避开字符冲突的问题)
片段。(锚点)
//以“#”字符为起点
····································
以http://www.luffycity.com:80/news/index.html?id=250&page=1 为例, 其中:
1. http,是协议;
2. www.luffycity.com,是服务器;
3. 80,是服务器上的网络端口号;
4. /news/index.html,是路径;
5. ?id=250&page=1,是查询。
大多数网页浏览器不要求用户输入网页中“http://”的部分,因为绝大多数网页内容是超文本传输协议文件。同样,“80”是超文本传输协议文件的常用端口号,因此一般也不必写明。一般来说用户只要键入统一资源定位符的一部分(www.luffycity.com:80/news/index.html?id=250&page=1)就可以了。
常见的请求头
user_agent:用什么浏览器访问的网站 发送的请求
content-type:application/json或application
#指定请求体的格式 (服务端按照格式要求进行解析)
响应格式
url是127.0.0.1 /路径
响应可以不写头部字段 在回复信息的时候可以定制响应头
django请求生命周期
wsgi协议web服务网关接口
wsgi 是一种规范定义python的接口规范 可以搭配不同的应用程序
1.wsgiref本地做测试用,请求来了只能处理一个请求不能并发
2.uwsgi linux和项目部署的时使用
浏览器向服务器请求数据(b/s架构)
本质是一个socket通信
1.浏览器请求发送到服务端 wsgi把接收到的请求 转发给django
2.到达路由系统 进行路由匹配
3.到达视图进行业务处理 可以用orm从数据库中读取数据,调用模板进行渲染 渲染完成之后的字符串
4.通过wsgi 用send发送给客户端浏览器
请求(网址访问,提交数据等等) request
响应(回复页面,回复数据等等) response
下载安装django
pip3 install django==1.11.23
django创建项目
命令行
下载安装django
pip3 install django==1.11.23
pip3 install django==1.11.23 http://mirrors.aliyun.com/pypi/simple/
创建项目
python36 manage.py runserver#开启django项目
python36 manage.py runserver 80 把端口号改成默认80
python36 manage.py runserver 0.0.0.0:80 其他人就可以访问了
创建app
python manage.py startapp app名称
指令船舰app需要的配置
项目的settings配置文件中,installapps的列表,添加一个app名称作为配置
pycharm 创建完app之后,
如果在向创建新的app,需要指定创建app命令配置,
pycharm会自动配置app路径
djnago的py文件的分类
1.manage.py ----- Django项目里面的工具,通过它可以调用django shell和数据库,启动关闭项目与项目交互等,不管你将框架分了几个文件,必然有一个启动文件,其实他们本身就是一个文件。
2.settings.py ---- 包含了项目的默认设置,包括数据库信息,调试标志以及其他一些工作的变量。
3.urls.py ----- 负责把URL模式映射到应用程序w。
4.wsgi.py ---- runserver命令就使用wsgiref模块做简单的web server,后面会看到renserver命令,所有与socket相关的内容都在这个文件里面了
子项目的文件分类
views是写视图函数 视图类 代码逻辑
models是数据库的源 写与数据库相关的的
templatses 是模板 放置html xml等网络文件
wsgi用于书写socket
utils文件用于放置插件
django基本操作
request对象 封装了所有请求
request.method是当前请求方法
````````````````````````````````````
.post 获取post请求的数据#请求体 类字典的requset字典
.get 获取get请求的数据#问号以后的值
request.GET.get('pwd') 获取get 字典的值 获得对应url?的参数
request.POST.get('pwd')获取post 字典的值 获取请求体的值
#post.get('键')取得的值是一个字符串
注意'django.middleware.csrf.CsrfViewMiddleware',#安全机制
返回一个字典 获取值要把一个安全机制注释才能过
视图函数
视图函数
def articles(request,year,month): # 位置参数(形参) 2019 9
print(year,type(year)) #2019 <class 'str'>
#匹配出来的所有数据都是字符串
print(month)
return HttpResponse(year+'年'+ month +'月' +'所有文章')
# 无名分组参数
url(r'^articles/(\d+)/(\d+)/', views.articles), #articles/2019/9/
# 有名分组参数
url(r'^articles/(?P<xx>\d+)/(?P<oo>\d+)/', views.articles), #articles/2019/9/
#xx=2019 oo=9 关键字传参
def articles(request,oo,xx): # 关键字传参 2019 9
print(xx,type(xx)) #2019 <class 'str'> #匹配出来的所有数据都是字符串
print(oo)
return HttpResponse(xx+'年'+ oo +'月' +'所有文章')
有名分组参数
# 有名分组参数
写了分组必须传参 不然报错
#关键字传参 和 ?<xx>里面的名字一一对应 相当于 函数的关键字传参
url(r'^articles/(?P<xx>\d+)/(?P<oo>\d+)/', views.articles), #articles/2019/9/
#xx=2019 oo=9 关键字传参
def articles(request,oo,xx): # 关键字传参 2019 9
print(xx,type(xx)) #2019 <class 'str'> #匹配出来的所有数据都是字符串
print(oo)
return HttpResponse(xx+'年'+ oo +'月' +'所有文章')
无名分组参数
# 无名分组参数
url(r'^articles/(\d+)/(\d+)/', views.articles), #articles/2019/9/
正则分组/(\d+)/(\d+)/会把匹配的 一一对应单独存储一个变量
(\d+)正则贪婪 满足一个或多个整数
具体示例
例如
html写法
<a href="/articles/2019/9">2019.9</a>#会把路径进行正则匹配
#(要一一对应)
url(r"^articles/(\d+)/(\d+)/",views.articles),
#匹配的时候,返回对应的匹配的内容,
#articles是返回路径 后面匹配两个参数(正则匹配路径)
视图函数(request请求)补充
request是wsgirequest实例化的对象
1.print(request)打印出来的是--str--的返回值
requesrt这个对象含有————str————
#返回的都是字符串
2.print(request.path) #/home/ 纯路径
3.print(request.path_info) #/home/ 纯路径
4.print(request.get_full_path()) #/home/?a=1&b=2 全路径(不包含ip地址和端口)
5.print(request.body) 能够拿到请求数据部分的数据(post,get没有),get数据的内容在url里
6.print(request.META)
是一个Python字典,包含了所有本次HTTP请求的Header信息
查看需要在线json转换
user-agent返回
7.print(request.GET)返回get请求的数据类似字典的值
8.print(request.POST)返回get请求的数据类似字典的值
request.POST.dict()#会转换成python字典
访问其他路径服务端会返回状态信息(状态码)
response响应的三个方法
三个方法都需要模块的引用
底部都有一个httpResponse 把字符串传入页面
form django.shortcuts import render,HttpResponse,redirect
1.HTTPResponse('字符串')#传入一个字符串 向浏览器返回一个页面
render 和redirect都是通过httpresponse传递给浏览器
2.render(request,'xx.html')返回浏览器一个xx.html
#模板渲染 模板就是html页面 渲染就是字符串替换
'''
示例
'''
#home.html页面
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>24期官网</h1>
<h2>{{ namxx }}</h2>
</body>
</html>
#views视图.py (render有第三个参数是html传参使用)
def home(request):
name = 'chao'
return render(request, 'home.html', {'namxx':name,}) #模板渲染(先把字符串替换了),这是在回复给浏览器之前做的事情
·······································
3.redirect 重定向
用法 redirect(路径) 示例:redirect('/index/')
会返回浏览器3xx一个重定向 返回一个redirect('/index/')路径
redirect示例
浏览器访问/index/#例如127.0.0.1/index/
urls.py
from django.conf.urls import url
from django.contrib import admin
from Django_test import views#引用 视图函数模块
urlpatterns = [
url(r'^index/', views.index),
]
def home(request):
print('xxxxx')
return redirect('/index/') #重定向路径

FBV和CBV 视图(视图函数和视图类)
FBV是视图函数
def 函数名(request):
函数体#进行判断
return 要一个返回值返回给浏览器
CBV是视图类
本质也是一个函数
urls写法
url(r'^login',views.LoginView.as_view())
1.加载到这一句的时候LoginView这个类直接调用执行类方法,LoginView没有as_view方法 去父类View去寻找这个方法
2.执行完之后返回一个view方法名
3.相当于视图函数#执行url(r'^login',views.view)
4.等待源码调用view方法(函数)
views视图类的写法
from django.views import View#引用View方法
class LoginView(View):#创建一个类 继承父类view
def get(self,request):##处理get请求直接定义get方法,不需要自己判断请求方法了,源码中用dispatch方法中使用了反射来处理的
print('小小小小')
return render(request,'login.html')
def post(self,request)
view源码简化分析
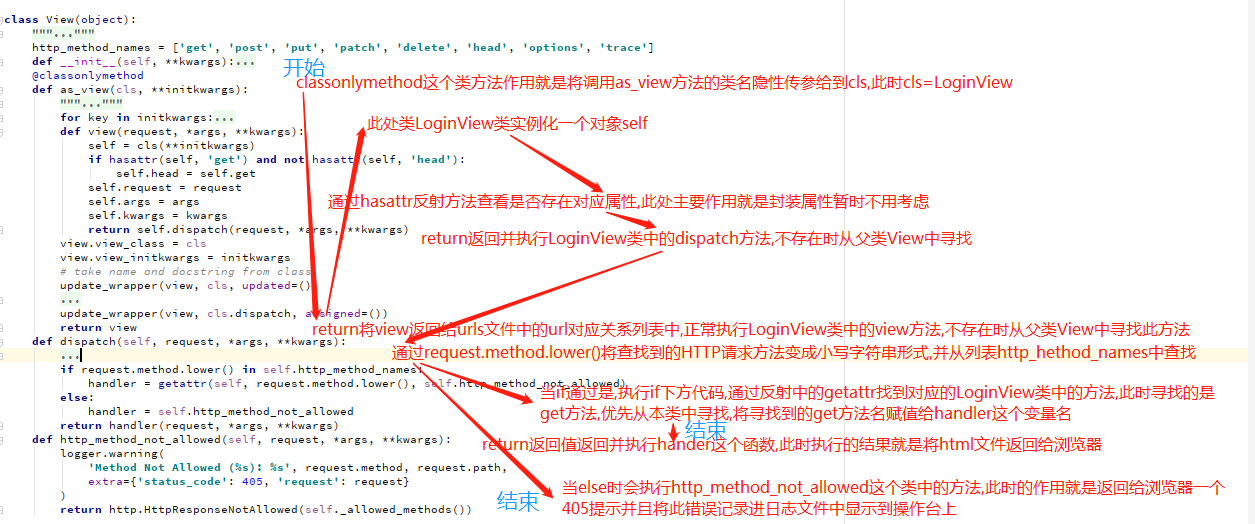
执行步骤:
1.加载类名去调用执行as_view方法#views.loginview.as_view()#as_view
2.as_view返回一个view方法名
3.urls执行view方法
4.寻找到as_view函数里有view方法self = cls(**initkwargs)#实例化一个对象cls对应的就是 LoginView视图类
5. 继续往下执行return self.dispatch(request, *args, **kwargs)#这时self是LoginView视图类的实例化对象 去LoginView类中去寻找dispatch方法
6.LoginView视图类没有找到去对应的父类View去寻找
dispatch方法
7.找到http_method_names对应属性里面有各类方法
8.请求的方法名在这个属性中继续往下执行反射
9.利用反射去寻找对应的方法,如果找不到对应方法执行第三个参数报错
#注意
getattr 第二个参数找不到就执行第三个参数 执行第三个方法直接报错返回 日志打印405
父类view
class View(object):
http_method_names = ['get', 'post', 'put', 'patch', 'delete', 'head', 'options', 'trace']
@classonlymethod
def as_view(cls, **initkwargs):
for key in initkwargs:
if key in cls.http_method_names:
raise TypeError("You tried to pass in the %s method name as a "
"keyword argument to %s(). Don't do that."
% (key, cls.__name__))
if not hasattr(cls, key):
raise TypeError("%s() received an invalid keyword %r. as_view "
"only accepts arguments that are already "
"attributes of the class." % (cls.__name__, key))
2.#as_view里面有一个view方法
def view(request, *args, **kwargs):
self = cls(**initkwargs)
3.#实例化cls方法(就是LoginView视图类) 拿到自己类的对象
if hasattr(self, 'get') and not hasattr(self, 'head'):
self.head = self.get
self.request = request
self.args = args
self.kwargs = kwargs
return self.dispatch(request, *args, **kwargs)
4.#执行到这发现 类调用一个方法 去视图类(LoginView)寻找dispatch方法,没有这个方法就去继承的父类去寻找 执行
view.view_class = cls
view.view_initkwargs = initkwargs
update_wrapper(view, cls, updated=())
update_wrapper(view, cls.dispatch, assigned=())
return view 1.#返回一个view方法
"""
dispatch方法
"""
5.找到dispatch方法执行
def dispatch(self, request, *args, **kwargs):
#request.method.lower()取得请求对应的方法 方法名都是大写的所以需要小写对应
#http_method_names去LoginView类去找,找不到去在源码中寻找(也就是继承的父类)
if request.method.lower() in self.http_method_names:
#请求的方法名在这个http_method_names属性中继续往下执行反射
#http_method_names = ['get', 'post', 'put', 'patch', 'delete', 'head', 'options', 'trace']
handler = getattr(self, request.method.lower(), self.http_method_not_allowed)
#利用反射去寻找对应的方法
#getattr 第二个参数找不到就执行第三个参数 执行第三个方法直接报错返回 日志打印405
else:
handler = self.http_method_not_allowed
return handler(request, *args, **kwargs)
#为什么第三个参数返回405
handler = getattr(self, request.method.lower(), self.http_method_not_allowed)
getattr 第二个参数找不到就执行第三个参数
'''http_method_not_allowed方法'''#为什么第三个参数返回405
def http_method_not_allowed(self, request, *args, **kwargs):
logger.warning(
'Method Not Allowed (%s): %s', request.method, request.path,
extra={'status_code': 405, 'request': request}
)
return http.HttpResponseNotAllowed(self._allowed_methods())
```
想法 在进行分发操作之前想要执行一些命令
自己重构父类的时候必须执行父类的分发操作
如果没有这个方法他会报错
### (重构父类dispatch方法)
```python
from django.views import View
class LoginView(View):
def dispatch(self,request,*args,**kwargs):
print("xxx请求来了")
ret=super(LoginView,self).dispatch(request,*args,**)
重构父类(view)的dispatch方法
#def dispatch(self, request, *args, **kwargs):
# if request.method.lower() in self.http_method_names:
#handler = getattr(self,request.method.lower(),
#self.http_method_not_allowed)
# else:
#handler = self.http_method_not_allowed
#return handler(request, *args, **kwargs)
#执行对应方法 获得返回值
print("执行结束")
return ret
#相当于执行return handler(request, *args, **kwargs)
def get(self,request):
print('xxxx')
return render(request,"login.html")
def post(self,request):
print(request.POST)
return HttpResponse('登录成功')
```
### 图解
## 装饰器
有三种方式
在类上面必须指定请求方法
```python
from django.utils.decorators import method_decorator
#必须引用django封装的装饰器
```
```python
def wrapper(func):
def inner(*args, **kwargs):
print(11111)
ret = func(*args, **kwargs)
print(22222)
return ret
return inner
类装饰器
@method_decorator(wrapper,name='get')#第一种方式
class LoginView(View):
def get(self,request):
print('xxxx')
return render(request,"login.html")
@method_decorator(wrapper) #方式2
def dispatch(self, request, *args, **kwargs):
print('xx请求来啦!!!!')
ret = super().dispatch(request, *args, **kwargs)
print('请求处理的逻辑已经结束啦!!!')
return ret
@method_decorator(wrapper)#方式3
def post(self,request):
print(request.POST)
return HttpResponse('登录成功')
```
## 模板渲染
通过views视图函数对html页面进行渲染
```python
标签{{ 变量 }}/标签 {% 逻辑 %} -- 标签
```
### 万能的点
```python
<h1>91李业网</h1>
<h2>{{ name }}</h2>
<h2>{{ d1.items }}</h2>
<h2>我是"{ {{ l1.1 }} }"</h2>#三个括号必须加空格
<h2>{{ num }}</h2>
<h2>{{ obj.p }}</h2> #如果调用的方法需要显性传参,可以隐性传参
#不能显性传参
传入一个对象可以点里面的属性
<h1>{{ 对象.属性 }}</h1>
例如字段。
注意点
可以嵌套点
可以自动执行函数
```
```python
locals()函数会以字典类型返回当前位置的全部局部变量
return render(request,'home.html',locals())
字典类型的数据传入home.html
return render(request,'home.html',{'name':name,})#指定传入html
可以直接拿来引用
```
## 过滤器
在模板渲染的基础上进行过滤
注意传值必须 过滤器 :指定值
### default**
**如果一个变量是false或者为空,使用给定的默认值。 否则,使用变量的值。**
```
{{ value(变量)|default:"nothing"}}
```
如果value没有传值或者值为空的话就显示nothing
### **length**
**返回值的长度,作用于字符串和列表。**
{{ value|length }}
返回value的长度,如 value=['a', 'b', 'c', 'd']的话,就显示4.
### **filesizeformat**
将值格式化为一个 “人类可读的” 文件尺寸 (例如 `'13 KB'`, `'4.1 MB'`, `'102 bytes'`, 等等)。例如:
```python
{{ value(变量)|filesizeformat }}
```
如果 value 是 123456789,输出将会是 117.7 MB。
### **slice**
切片,如果 value="hello world",还有其他可切片的数据类型
```python
{{value(变量)|slice:"2:-1"}}
```
### **date**
格式化,如果 value=datetime.datetime.now(
```python
{{ value(变量)|date:"Y-m-d H:i:s"}}
```
关于时间日期的可用的参数(除了Y,m,d等等)还有很多,有兴趣的可以去查查看看。
### **safe**(识别成标签)
Django的模板中在进行模板渲染的时候会对HTML标签和JS等语法标签进行自动转义,原因显而易见,这样是为了安全,django担心这是用户添加的数据,比如如果有人给你评论的时候写了一段js代码,这个评论一提交,js代码就执行啦,这样你是不是可以搞一些坏事儿了,写个弹窗的死循环,那浏览器还能用吗,是不是会一直弹窗啊,这叫做xss攻击,所以浏览器不让你这么搞,给你转义了。但是有的时候我们可能不希望这些HTML元素被转义,比如我们做一个内容管理系统,后台添加的文章中是经过修饰的,这些修饰可能是通过一个类似于FCKeditor编辑加注了HTML修饰符的文本,如果自动转义的话显示的就是保护HTML标签的源文件。为了在Django中关闭HTML的自动转义有两种方式,如果是一个单独的变量我们可以通过过滤器“|safe”的方式告诉Django这段代码是安全的不必转义。
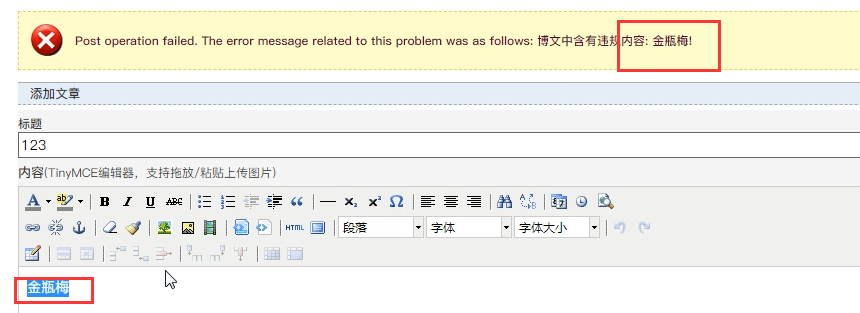
我们去network那个地方看看,浏览器看到的都是渲染之后的结果,通过network的response的那个部分可以看到,这个a标签全部是特殊符号包裹起来的,并不是一个标签,这都是django搞得事情。

比如:
value = "<a href='#'>点我</a>" 和 value="<script>alert('123')</script>"
```
{{ value(变量标签)|safe}}
```
很多网站,都会对你提交的内容进行过滤,一些敏感词汇、特殊字符、标签、黄赌毒词汇等等,你一提交内容,人家就会检测你提交的内容,如果包含这些词汇,就不让你提交,其实这也是解决xss攻击的根本途径,例如博客园:
### truncatechars
如果字符串字符多于指定的字符数量,那么会被截断。截断的字符串将以可翻译的省略号序列(“...”)结尾。
参数:截断的字符数
```python
{{ value|truncatechars:9}}
#注意:最后那三个省略号也是9个字符里面的,也就是这个9截断出来的是6个字符+3个省略号,有人会说,怎么展开啊,配合前端的点击事件就行啦
```
### truncatewords
在一定数量的字后截断字符串,是截多少个单词。
例如:‘hello girl hi baby yue ma’,
```python
{{ value|truncatewords:3}}
#上面例子得到的结果是 'hello girl h1...' 以空格为分界点
```
### **cut**
**移除value中所有的与给出的变量相同的字符串**
```
{{ value|cut:' ' }}
```
如果value为'i love you',那么将输出'iloveyou'.
**join**
使用字符串连接列表,{{ list|join:', ' }},就像Python的str.join(list)**
```python
<h1>{{ name|join:"+"}}</h1>
```
**timesince(了解)**
将日期格式设为自该日期起的时间(例如,“4天,6小时”)。
采用一个可选参数,它是一个包含用作比较点的日期的变量(不带参数,比较点为现在)。 例如,如果blog_date是表示2006年6月1日午夜的日期实例,并且comment_date是2006年6月1日08:00的日期实例,则以下将返回“8小时”:
```
{{ blog_date|timesince:comment_date }}
```
分钟是所使用的最小单位,对于相对于比较点的未来的任何日期,将返回“0分钟”。
### timeuntil(了解)
似于timesince,除了它测量从现在开始直到给定日期或日期时间的时间。 例如,如果今天是2006年6月1日,而conference_date是保留2006年6月29日的日期实例,则{{ conference_date | timeuntil }}将返回“4周”。
使用可选参数,它是一个包含用作比较点的日期(而不是现在)的变量。 如果from_date包含2006年6月22日,则以下内容将返回“1周”:
```
{{ conference_date|timeuntil:from_date }}
```
### 标签
#### for循环标签
```python
#循环列表等
{% for person in person_list %}
<p>{{ person.name }}</p> <!--凡是变量都要用两个大括号括起来-->
{% endfor %}
#循环字典
{% for key,val in dic.items %}
<p>{{ key }}:{{ val }}</p>
{% endfor %}
#循环字符串
{% for i in name %}
<h2>{{ i }}</h2>
{% endfor %}
#empty
{% for person in person_list %}
<p>{{ person.name }}</p> <!--凡是变量都要用两个大括号括起来-->
{% empty %}
<p>没有找到东西!</p>
{% endfor %}
forloop.counter 当前循环的索引值(从1开始),forloop是循环器,通过点来使用功能
forloop.counter0 当前循环的索引值(从0开始)
forloop.revcounter 当前循环的倒序索引值(从1开始)
forloop.revcounter0 当前循环的倒序索引值(从0开始)
forloop.first 当前循环是不是第一次循环(布尔值)
forloop.last 当前循环是不是最后一次循环(布尔值)
forloop.parentloop 本层循环的外层循环的对象,再通过上面的几个属性来显示外层循环的计数等
示例:
{% for i in d2 %}
{% for k,v in d1.items %}
<li>{{ forloop.counter }}-- {{ forloop.parentloop.counter }} === {{ k }} -- {{ v }}</li>
{% endfor %}
{% endfor %}
```
#### if判断标签
```python
{% if num > 100 or num < 0 %}
<p>无效</p> <!--不满足条件,不会生成这个标签-->
{% elif num > 80 and num < 100 %}
<p>优秀</p>
{% else %} <!--也是在if标签结构里面的-->
<p>凑活吧</p>
{% endif %}
if语句支持 and 、or、==、>、<、!=、<=、>=、in、not in、is、is not判断,注意条件两边都有空格。
```
#### with(起别名)
```python
方法1
{% with total=business.employees.count %} #注意等号两边不能有空格
{{ total }} <!--只能在with语句体内用-->
{% endwith %}
方法2
{% with business.employees.count as total %}
{{ total }}
{% endwith %}
```
render
locals 返回当前页面的所有变量 以字典形式展示
模板语法
## 模板继承
目的是:减少代码的冗余
常用于左侧菜单栏
把父类对应标签直接拿过来使用
```python
{% block content(变量可以随便命名)%}
{{block.super}}#延续父类的变量
包裹什么就修改什么
{% endblock %}
可以修改
继承页面{% extends 'base.html' %}
```
```python
1.创建一个xx.html页面作为模板,其他页面来继承他
2。在母版中定义block块
{% block content %}<!--预留钩子。供其他html页面使用,自定义自己内容>
3 其他子页面继承写法
{% extends 'base.html' %}必须放在页面开头 #相当于继承子页面的声明
4 页面中写和母版中名字相同的block块,从而来显示自定义的内容
{% block content %} <!-- 预留的钩子,共其他需要继承它的html,自定义自己的内容 -->
{{ block.super }} #这是显示继承的母版中的content这个快中的内容
这是xx1
{% endblock %}
```
## 组件
插件比组件小
```python
1 创建html页面,里面写上自己封装的组件内容,xx.html
2 新的html页面使用这个组件
{% include 'xx.html' %}
```
组件 直接拿来使用相当于外部引入 但是不能直接修改
```python
{% include 'xx.html' %}
```
## 自定义标签和过滤器
**注意传值必须一一对应**
自定义标签和过滤器都必须创建一个文件夹在文件夹下面的py文件里面写 def 函数
```python
1 在应用下django文件夹下创建一个叫做templatetags的文件夹(名称不能改),在里面创建一个py文件,例如xx.py
2 在xx.py文件中引用django提供的template类,写法
from django import template
register = template.Library() #register变量名称不能改
```
### 定义过滤器
```python
1 在应用下django文件夹下创建一个叫做templatetags的文件夹(名称不能改),在里面创建一个py文件,例如xx.py
2 在xx.py文件中引用django提供的template类,写法
from django import template
register = template.Library() #register变量名称不能改
3.@register.filter#自定义过滤器的声明,装上这个装饰器解释过滤器了 参数至多两个
def xx(v1,v2):
#{{name(外部传参第一个值)|xx(过滤器名称):第二个值}}
return v1+"xx"#自定义过滤 返回值
#结果 v1xx
使用:
{% load xx %}#开头引用
内容
{{ name|xx:'oo' }}
```
### 自定义标签
```python
templatetags
-- xx.py
{% load xx %}使用%进行调用
过程:
name是一个值 5是第二个值
#def huxtag(n1(第一个值),n2(第二个值))
前端:{% huxtag name 5 %}
# 自定义标签 没有参数个数限制
后端:@register.simple_tag
def huxtag(n1,n2): #冯强xx '牛欢喜'
'''
:param n1: 变量的值 name前面的
:param n2: 对应5传的参数 如果不需要传参,就不要添加这个参数
:return:
'''
return n1+n2
```
#### 自定义标签的一种
```python
用于把自定义标签写活
执行过程:
1.通过urls的函数返回li.html
2.执行到{% res name %}开始执行res自定义标签
3.把name值传给自定义标签
4.最后把渲染过标签返回给li.html(通过res函数处理过的数据)
#urls.py分发
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^index/',views.index),
]
#views.py 写法
def index(request):
a='子文1234'
return render(request,'rusult.html',{'name':a})
#li.html写法
'''
{% load xx %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
{% xx name %}
</body>
</html>
'''
#result.html页面代码
'''
<body>
{% for i in li %}
<div>{{ i }}</div>
{% endfor %}
</body>
'''
# inclusion_tag 返回html片段的标签
-app01
--templatetags
-----xx.py写法
@register.inclusion_tag('result.html')
def xx(n1): #n1 : ['aa','bb','cc']
return {'li':n1 }#必须是一个字典
#注意点 return 必须是字典
键是可以for循环的
字典里面值是渲染给对应页面的值
循环加值 把对应html的值进行处理
1.html
{% tage data %}
2.自定义标签
-app01
--templatetags
-----xx.py写法
@register.inclusion_tag('xxxx.html')#返回的页面
def tage(data):
li=[]
for i in data:
i=i+'a'
li.append(i)
return {'li': li}
2.view.py
def home(request):
data = ['菜单一', '菜单二', '菜单三']
return render(request, 'home.html', {'data': data})
```
模板渲染结束替换字符串
## 静态文件
严格要求
```python
static#静态文件夹
---css#存放自己设定的css样式
---img#存放图片
---plugins#外部引用文件
STATIC_URL = '/static/' # 别名利用这个别名去查找对应文件
例
查找方式
link href
href 或者src /static/plugins/xxx/xxx.文件类型
settings.py
#必须这个名字
STATICFILES_DIRS = [
os.path.join(BASE_DIR, 'static')
]
STATICFILES_DIRS = [ #按照列表的顺序进行查找
os.path.join(BASE_DIR, 'x1'),
os.path.join(BASE_DIR, 'static'),
os.path.join(BASE_DIR, 'x2')
]
```
## url别名和反向解析(别名)
```python
别名写法
url(r'^index2/', views.index,name='index'),
#name=别名
反向解析
通过reverse 解析出路径
后端(py文件):
from django.urls import reverse
reverse('别名')
例如:reverse('index') -- /index2/
html:
{% url '别名' %} --
例如:{% url 'index' %} -- /index2/
```
### 带参数的反向解析
```python
后端:
from django.urls import reverse
reverse('index',args=(10))--/index2/10
html:
带参数的反向解析
{% url '别名' 参数1 参数二 %}
例如
{% url 'index' 10 %}--/index2/10
<a href='/index2/10'>hhh</a>
示例
html页面a标签写法
<a href="{% url 'app01:index' 10 %}">hhh</a>
app01下面视图函数(views.py)写法
from django.shortcuts import render,HttpResponse,redirect
from django.urls import reverse
def ppt(request):
return redirect(reverse('app01:index',args=(10)))
app01下面路径(urls.py)写法
from django.conf.urls import url,include
from django.contrib import admin
from app01 import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^index/(\d+)/',views.index,name="index",
url(r'^home/',views.home,name="home"),
]
```
## url命名空间
### 路由分发 include
路由分发就是把很多的路径分给每个对应app下的页面,便于统一管理
```python
#注意include是模块里面的方法要引用才能发挥作用
1 在每个app下创建urls.py文件,写上自己app的路径
2 在项目目录下的urls.py文件中做一下路径分发,看下面内容
在主文件夹里面的urls分发
from django.conf.urls import url,include
from django.contrib import admin
urlpatterns = [
# url(r'^admin/', admin.site.urls),
#app01/home/直接跳转到对应app01下面的urls
url(r'^app01/',include('app01.urls')),
url(r'^app02/', include('app02.urls')),
]
```
### 命名空间namespace
为了避免url别名冲突 从而产生的一种规则
```python
使用格式:
后端(py文件):reverse('命名空间名称:别名')
-- reverse('app01:home')
hmtl:{% url '命名空间名称:别名' %}
-- {% url 'app01:home' %}
from django.conf.urls import url,include
from django.contrib import admin
django下面的文件夹urls.py写法
urlpatterns = [
# url(r'^admin/', admin.site.urls),
url(r'^app01/', include('app01.urls',namespace='app01')),#app01/home/
url(r'^app02/', include('app02.urls',namespace='app02')),
]
app01下面的urls.py 写法
from django.conf.urls import url
from django.contrib import admin
from app01 import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^home2/', views.home,name="home"),
url(r'^index/', views.index,name="index"),
url(r'^ppt/', views.ppt,name="ppt1"),
]
'''
app01下views.py写法
'''
from django.shortcuts import render,HttpResponse,redirect
from django.urls import reverse
#render的三个参数 是在html 之前就渲染好了 例如 {"name":name}
# 模板X HttpResponse("字符串") 返回一个字符串页面
# Create your views here.
def home(request):
return render(request,"home2.html")
def index(request):
return render(request,"index.html")
def ppt(request):
return redirect(reverse("app01:index"))
```
## app项目的创建
### 新建APP
```python
python manage.py startapp app名称
```
### 注册APP
在settings中
```python
INSTALLED_APPS = [
'app01',
'app01.apps.App01Config', # 推荐写法
]
```
## 开源的djnago初识
**重要**
遇见路径的时候 需要向服务端发送请求
服务端给html页面 返回对应文件
```python
示例
<link rel="" href="这里的路径会向服务端请求文件">
```
### low版登陆跳转页面
### 思路
```python
1.开启django 配置好路径
2.在浏览器访问路径例如:#127.0.0.1(回环地址)/后面写路径
3.路径的相应的请求 去urls这个文件去寻找相应匹配的路径 ,调用相应视图函数(views是视图函数)
4.根据对应匹配的函数 返回浏览器相应的页面
render(requset,返回页面)
第一个为 固定requset
例如#return render(request,"home.html")
```
## django的setting解释
```python
from 项目名 import settings 局部配置文件
from django.conf import sttings 整个django的配置文件(全局配置)
#注意
如果局部配置文件和全局配置重复 使用局部配置文件的配置
以后引用可以使用全局配置 以防引用配置的时候报错(局部没有配置的时候)
调用配置文件
print(settings.STATIC_URL)获取对应的STATIC_UR的值L#静态文件路径别名
```
# orm(对象关系映射)
对象是指 orm的models类名实例化的对象
关系是指 orm中的数据模型和数据库的关系
```python
类----------------》表 #models.py中的类对应数据库中的表
对象--------------》记录(数据行) #obj=models.User.objects.get(id=1) obj对应数据库表中的行数据
属性--------------》字段 #models.py类中的属性对应数据库表中的字段
```
映射 orm其实就是将models.类名.object.filter类对象的语法通过orm翻译翻译成sql语句的一个引擎
### 字段介绍
```python
'''
<1> CharField
字符串字段, 用于较短的字符串.
CharField 要求必须有一个参数 maxlength, 用于从数据库层和Django校验层限制该字段所允许的最大字符数.
<2> IntegerField
#用于保存一个整数.
<3> DecimalField
一个浮点数. 必须 提供两个参数:
参数 描述
max_digits 总位数(不包括小数点和符号)
decimal_places 小数位数
举例来说, 要保存最大值为 999 (小数点后保存2位),你要这样定义字段:
models.DecimalField(..., max_digits=5, decimal_places=2)
要保存最大值一百万(小数点后保存10位)的话,你要这样定义:
models.DecimalField(..., max_digits=17, decimal_places=10) #max_digits大于等于17就能存储百万以上的数了
admin 用一个文本框(<input type="text">)表示该字段保存的数据.
<4> AutoField
一个 IntegerField, 添加记录时它会自动增长. 你通常不需要直接使用这个字段;
自定义一个主键:my_id=models.AutoField(primary_key=True)
如果你不指定主键的话,系统会自动添加一个主键字段到你的 model.
<5> BooleanField
A true/false field. admin 用 checkbox 来表示此类字段.
<6> TextField
一个容量很大的文本字段.
admin 用一个 <textarea> (文本区域)表示该字段数据.(一个多行编辑框).
<7> EmailField
一个带有检查Email合法性的 CharField,不接受 maxlength 参数.
<8> DateField
一个日期字段. 共有下列额外的可选参数:
Argument 描述
auto_now 当对象被保存时(更新或者添加都行),自动将该字段的值设置为当前时间.通常用于表示 "last-modified" 时间戳.
auto_now_add 当对象首次被创建时,自动将该字段的值设置为当前时间.通常用于表示对象创建时间.
(仅仅在admin中有意义...)
<9> DateTimeField
一个日期时间字段. 类似 DateField 支持同样的附加选项.
<10> ImageField
类似 FileField, 不过要校验上传对象是否是一个合法图片.#它有两个可选参数:height_field和width_field,
如果提供这两个参数,则图片将按提供的高度和宽度规格保存.
<11> FileField
一个文件上传字段.
要求一个必须有的参数: upload_to, 一个用于保存上载文件的本地文件系统路径. 这个路径必须包含 strftime #formatting,
该格式将被上载文件的 date/time
替换(so that uploaded files don't fill up the given directory).
admin 用一个<input type="file">部件表示该字段保存的数据(一个文件上传部件) .
注意:在一个 model 中使用 FileField 或 ImageField 需要以下步骤:
(1)在你的 settings 文件中, 定义一个完整路径给 MEDIA_ROOT 以便让 Django在此处保存上传文件.
(出于性能考虑,这些文件并不保存到数据库.) 定义MEDIA_URL 作为该目录的公共 URL. 要确保该目录对
WEB服务器用户帐号是可写的.
(2) 在你的 model 中添加 FileField 或 ImageField, 并确保定义了 upload_to 选项,以告诉 Django
使用 MEDIA_ROOT 的哪个子目录保存上传文件.你的数据库中要保存的只是文件的路径(相对于 MEDIA_ROOT).
出于习惯你一定很想使用 Django 提供的 get_<#fieldname>_url 函数.举例来说,如果你的 ImageField
叫作 mug_shot, 你就可以在模板中以 {{ object.#get_mug_shot_url }} 这样的方式得到图像的绝对路径.
<12> URLField
用于保存 URL. 若 verify_exists 参数为 True (默认), 给定的 URL 会预先检查是否存在( 即URL是否被有效装入且
没有返回404响应).
admin 用一个 <input type="text"> 文本框表示该字段保存的数据(一个单行编辑框)
<13> NullBooleanField
类似 BooleanField, 不过允许 NULL 作为其中一个选项. 推荐使用这个字段而不要用 BooleanField 加 null=True 选项
admin 用一个选择框 <select> (三个可选择的值: "Unknown", "Yes" 和 "No" ) 来表示这种字段数据.
<14> SlugField
"Slug" 是一个报纸术语. slug 是某个东西的小小标记(短签), 只包含字母,数字,下划线和连字符.#它们通常用于URLs
若你使用 Django 开发版本,你可以指定 maxlength. 若 maxlength 未指定, Django 会使用默认长度: 50. #在
以前的 Django 版本,没有任何办法改变50 这个长度.
这暗示了 db_index=True.
它接受一个额外的参数: prepopulate_from, which is a list of fields from which to auto-#populate
the slug, via JavaScript,in the object's admin form: models.SlugField
(prepopulate_from=("pre_name", "name"))prepopulate_from 不接受 DateTimeFields.
<13> XMLField
一个校验值是否为合法XML的 TextField,必须提供参数: schema_path, 它是一个用来校验文本的 RelaxNG schema #的文件系统路径.
<14> FilePathField
可选项目为某个特定目录下的文件名. 支持三个特殊的参数, 其中第一个是必须提供的.
参数 描述
path 必需参数. 一个目录的绝对文件系统路径. FilePathField 据此得到可选项目.
Example: "/home/images".
match 可选参数. 一个正则表达式, 作为一个字符串, FilePathField 将使用它过滤文件名.
注意这个正则表达式只会应用到 base filename 而不是
路径全名. Example: "foo.*\.txt^", 将匹配文件 foo23.txt 却不匹配 bar.txt 或 foo23.gif.
recursive可选参数.要么 True 要么 False. 默认值是 False. 是否包括 path 下面的全部子目录.
这三个参数可以同时使用.
match 仅应用于 base filename, 而不是路径全名. 那么,这个例子:
FilePathField(path="/home/images", match="foo.*", recursive=True)
...会匹配 /home/images/foo.gif 而不匹配 /home/images/foo/bar.gif
<15> IPAddressField
一个字符串形式的 IP 地址, (i.e. "24.124.1.30").
<16> CommaSeparatedIntegerField
用于存放逗号分隔的整数值. 类似 CharField, 必须要有maxlength参数.
'''
```
### 元类型 META
```python
class Meta(object):
# 定义表名
db_table = "department"
# 定义在管理后台显示的名称
verbose_name = '部门'
# 定义复数时的名称(去除复数的s)
verbose_name_plural = verbose_name
```
### 属性介绍
```python
(1)null
如果为True,Django 将用NULL 来在数据库中存储空值。 默认值是 False.
(1)blank
如果为True,该字段允许不填。默认为False。
要注意,这与 null 不同。null纯粹是数据库范畴的,而 blank 是数据验证范畴的。
如果一个字段的blank=True,表单的验证将允许该字段是空值。如果字段的blank=False,该字段就是必填的。
(2)default
字段的默认值。可以是一个值或者可调用对象。如果可调用 ,每有新对象被创建它都会被调用,如果你的字段没有设置可以为空,那么将来如果我们后添加一个字段,这个字段就要给一个default值
(3)primary_key
如果为True,那么这个字段就是模型的主键。如果你没有指定任何一个字段的primary_key=True,
Django 就会自动添加一个IntegerField字段做为主键,所以除非你想覆盖默认的主键行为,
否则没必要设置任何一个字段的primary_key=True。
(4)unique
如果该值设置为 True, 这个数据字段的值在整张表中必须是唯一的
(5)choices
由二元组组成的一个可迭代对象(例如,列表或元组),用来给字段提供选择项。 如果设置了choices ,默认的表单将是一个选择框而不是标准的文本框,<br>而且这个选择框的选项就是choices 中的选项。
(6)db_index
如果db_index=True 则代表着为此字段设置数据库索引。
DatetimeField、DateField、TimeField这个三个时间字段,都可以设置如下属性。
(7)auto_now_add
配置auto_now_add=True,创建数据记录的时候会把当前时间添加到数据库。
(8)auto_now
配置上auto_now=True,每次更新数据记录的时候会更新该字段,标识这条记录最后一次的修改时间。
```
1.MVC或者MVC框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库,这极大的减轻了开发人员的工作量
2.ORM是“对象-关系-映射”的简称。
3.执行流程
类对象--orm-->sql--->pymysql--->mysql服务端--->磁盘
orm其实就是将类对象的语法翻译成sql语句的一个引擎
orm语句 -- sql -- 调用pymysql客户端发送sql -- mysql服务端接收到指令并执行

## django 连接mysql顺序
### 1 settings配置文件中
```sql
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql', # 引擎
'NAME': 'day53', # 数据库名称
'HOST': '127.0.0.1', # IP
'PORT': 3306, # 端口号
'USER': 'root', # 用户名
'PASSWORD': '123' # 密码
}
}
单个app配置
'app01': { #可以为每个app都配置自己的数据,并且数据库还可以指定别的,也就是不一定就是mysql,也可以指定sqlite等其他的数据库
'ENGINE': 'django.db.backends.mysql',
'NAME':'bms', # 要连接的数据库,连接前需要创建好
'USER':'root', # 连接数据库的用户名
'PASSWORD':'', # 连接数据库的密码
'HOST':'127.0.0.1', # 连接主机,默认本级
'PORT':3306 # 端口 默认3306
}
}
```
### 2 项目文件夹下的init文件中写上下面内容,
作用:用pymysql替换mysqldb(djnago自带的)
mysqldb 不能python3.4以上的版本
需要使用第三方模块pymysql进行替换
**app01**中的--init--文件
### 补充
```python
MySQLdb的是一个接口连接到MySQL数据库服务器从Python
MySQLdb并不支持Python3.4之后版本
```
```python
原因:
#python默认连接的MySQLdb并不支持Python3.4之后版本
解决办法:
#12使用第三方模块pymysql进行替换
import pymysql
pymysql.install_as_MySQLdb()
```
### 3 models文件中创建一个类(类名就是表名)
```python
#引用一个模块 from django.db import models
class UserInfo(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=10)
bday = models.DateField()
checked = models.BooleanField()
# 1 翻译成sql语句
# 2 django内置的一个sqlite客户端将sql语句发给sqlite服务端
# 3 服务端拿到sql,到磁盘里面进行了数据操作(create table app01_userinfo(id name...))
```
### content-type
```python
model和app之间的关系 ,每次同步数据库信息都会记录在表中
适用于一张表与多张表同时做关联的时候。直接导入就可以使用了
```
### related_name
```python
Django使用详解:ORM 的反向查找(related_name)
class level(models.Model):
l_name = models.CharField(max_length=50,verbose_name="等级名称")
def __str__(self):
return self.l_name
class userinfo(models.Model):
u_name = models.CharField(max_length=50,verbose_name="用户名称")
u_level = models.ForeignKey(level,related_name="lev")
def __str__(self):
return self.u_name
#利用related_name 反向查表名
level.objects.get(pk=1).lev.all()
```
****
### 4.执行数据库同步指令,
添加字段的时候别忘了,该字段不能为空,所有要么给默认值,要么设置它允许为空 null=True
```python
#注意在每次增加字段时候都需要执行一遍这个方法
python manage.py makemigrations#创建一个表记录
python版本号
python manage.py migrate 执行记录
```
**数据库问题mysql 更改时区和改变版本号mysql for 5.1**
### 5 创建记录
(实例一个对象,调用save方法)
models.py
```mysql
#创建一条记录,增
def query(request):
new_obj = models.UserInfo(
id=2,
name='子文',
bday='2019-09-27',
checked=1,
)
new_obj.save()
#翻译成sql语句,
#然后调用pymysql,发送给服务端
相当于执行insert into app01_userinfo values(2,'子文','2019-09-27',1)
return HttpResponse('xxx')
```
### 6.字段约束
```sql
通过选项实现对字段的约束,选项如下:
null:如果为True,表示允许为空,默认值是False。
blank:如果为True,则该字段允许为空白,默认值是False。
对比:null是数据库范畴的概念,blank是表单验证证范畴的。
db_column:字段的名称,如果未指定,则使用属性的名称。
db_index:若值为True, 则在表中会为此字段创建索引,默认值是False。
default:默认值。
primary_key:若为True,则该字段会成为模型的主键字段,默认值是False,一般作为AutoField的选项使用。
unique:如果为True, 这个字段在表中必须有唯一值,默认值是False。
```
### 配置数据库
```sql
python3 manage.py makemigrations 创建脚本
python3 manage.py migrate 迁移
```
创建app01中的--init--文件
```python
class Book(models.Model): #必须要继承的
nid = models.AutoField(primary_key=True) #自增id(可以不写,默认会有自增id AutoField是自增)
title = models.CharField(max_length=32)
publishDdata = models.DateField() #出版日期
author = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5,decimal_places=2) #一共5位,保留两位小数
```
替换数据库的时候需要重新创建表记录
更改字段时候也需要
```python
python36 manage.py makemigrations 创建脚本
python36 manage.py migrate 迁移
```
## 在配置里面设置显示orm的操作的原生sql语句
```python
```
## 数据库的操作(django)
创建字段django特殊说明
```python
1.字段的值默认是不为空的 需要手动设置 不然会报错
2.主键无需手动添加 自动生成id字段(主键)
3.引用模块from django.db import models
```
获取id字段的两种方式
```python
1.表名.id
例
book.id
2.表名.pk
例
book.pk
```
### 增:
```mysql
方式1:
new_obj = models.UserInfo(#直接表名创建
过程
#1.先实例化产生对象,2.然后调用save方法保存
id=2,
name='子文',
bday='2019-09-27',
checked=1,
)
new_obj.save()
方式2:
# ret 是创建的新的记录的model对象(重点)
ret = models.UserInfo.objects.create(
name='卫贺',
bday='2019-08-07',
checked=0
外键object=对象
外键_id=对象_id
)
print(ret) #UserInfo object
print(ret.name) #UserInfo object
print(ret.bday) #UserInfo object
```
### 时间问题
```mysql
import datetime
current_date=datetime.datetime.now()
models.UserInfo.objects.create(
name='杨泽涛2',
bday=current_date,
# now=current_date, 直接插入时间没有时区问题
checked=0
)
但是如果让这个字段自动来插入时间,就会有时区的问题,auto_now_add创建记录时自动添加当前创建记录时的时间,存在时区问题
now = models.DateTimeField(auto_now_add=True,null=True)
解决方法:
settings配置文件中将USE_TZ的值改为False
# USE_TZ = True
USE_TZ = False # 告诉mysql存储时间时按照当地时间来寸,不要用utc时间
使用pycharm的数据库客户端的时候,时区问题要注意
```
### 删
```mysql
from django.db import models
简单查询:filter() -- 结果是queryset类型的数据里面是一个个的model对象,类似于列表
models.UserInfo.objects.filter(id=7).delete() #queryset对象调用
models.UserInfo.objects.filter(id=7)[0].delete() #model对象调用
```
### 改
```mysql
方式1:update
# models.UserInfo.objects.filter(id=2).update(
# name='篮子文',
# checked = 0,
#
# )
# 错误示例,model对象不能调用update方法
# models.UserInfo.objects.filter(id=2)[0].update(
# name='加篮子+2',
# # checked = 0,
# )
方式2
ret = models.UserInfo.objects.filter(id=2)[0]
ret.name = '加篮子+2'
ret.checked = 1
ret.save()
更新时的auto_now参数
# 更新记录时,自动更新时间,创建新纪录时也会帮你自动添加创建时的时间,但是在更新时只有使用save方法的方式2的形式更新才能自动更新时间,有缺陷,放弃
now2 = models.DateTimeField(auto_now=True,null=True)
```
### 批量添加数据(bulk_create)
```python
步骤
1.把查询的对象放入字典里一次性传入前端进行交互
# bulk_create
obj_list = []
for i in range(20):
obj = models.Book(#一一对应添加
title=f'金梅{i}',
price=20+i,
publish_date=f'2019-09-{i+1}',
publish='24期出版社'
)
obj_list.append(obj)
models.Book.objects.bulk_create(obj_list) #批量创建
2.添加数据choice
import os
print(2)
if __name__ == '__main__':
print(1)
print(os.environ['DJANGO_SETTINGS_MODULE'])
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "ignb.settings")
import django
django.setup()
import random
from sales import models
sex_type = (('male', '男性'), ('female', '女性'))
source_type = (('qq', "qq群"),
('referral', "内部转介绍"),
('website', "官方网站"),
('baidu_ads', "百度推广"),
('office_direct', "直接上门"),
('WoM', "口碑"),
('public_class', "公开课"),
('website_luffy', "路飞官网"),
('others', "其它"),)
course_choices = (('LinuxL', 'Linux中高级'),
('PythonFullStack', 'Python高级全栈开发'),)
obj_list=[]
print(random.choice(sex_type))
for i in range(30):
obj=models.Customer(
qq=f"{i}884338",
name=f'子文{i}',
sex=random.choice(sex_type)[0],
source=random.choice(source_type)[0],
course=random.choice(course_choices)[0],
)
obj_list.append(obj)
models.Customer.objects.bulk_create(obj_list)
```
### form表单提交之字典
```python
request.POST -- querydict类型 {'title': ['asdf '], 'price': ['212'], 'publish_date': ['2019-09-12'], 'publish': ['asdf ']}
data = request.POST.dict() -- 能够将querydict转换为普通的python字典格式
创建数据
models.Book.objects.create(
## title=title, #title='asdf '
## price=price, #price='212'
## publish_date=publish_date,
#'publish_date': ['2019-09-12']
## publish=publish,
#publish=['asdf ']
**data#通过打散把键和值转换成以上数据
)
```
### 查询api
**筛选基本都是queryset类型**
reservse 必须要排序才能反转
#### 1.all()
查询对应表名的所有对象,结果是对象列表
结果为queryset类型
```python
写法
models.表名.object.all()
例如
all_books = models.Book.objects.all()
数量过多会自动截断
```
#### 2.filter条件查询
过滤出符合条件的数据
```python
filter 条件查询
ret = models.Book.objects.filter(title='金梅7',publish='24期出版社') #相当于mysql数据库中and多条件查询
查询条件不能匹配到数据时,不会报错,返回一个空的queryset,<QuerySet []>,如果没有写查询条件会获取所有数据,queryset类型的数据还能够继续调用fitler方法
```
#### 3.get()
得到一个满足条件的model对象 有且只有一个
```python
ret = models.Book.objects.get() #得到的是一个model对象,有且只能有一个
1. 查不到数据会报错 :Book matching query does not exist.
2. 超过一个就报错 :returned more than one Book -- it returned 13!
```
#### 4.exclude()#排除
```python
#除了这个之外
models.BOOK.objects.exclude(title__startswith=('金梅'))
#model类型不能使用这个方法
1.object能够调用,models.Book.objects.exclude(title__startswith='金梅')
2.queryset类型数据能够调用, models.Book.objects.all().exclude(title__startswith='金梅')
```
#### 5.order by()排序
```python
models.Book.objects.all().order_by('-price','id')
#sql语句写法 orderby price desc,id asc;
models类型不能使用
排序order by 加上-字段名 不加是升序
```
#### 6.reverse() 反转
```python
models.Book.objects.all().order_by('id').reverse() #数据排序之后才能反转
```
#### 7.count()
计数,统计返回结果的数量
```python
models.Book.objects.all().count()
sql语句 聚合函数
```
#### 8.first()
```python
类似于models.类名(表名).objects.filter(条件判断)[0]
models.类名(表名).objects.filter(条件判断).first()
#返回满足条件的第一条数据
```
返回第一条数据,结果是model对象类型
#### 9.last()
返回最后一条数据,结果是model对象类型
```python
ret = models.Book.objects.all().first()
ret = models.Book.objects.all().last()
```
#### 10.exists()
判断返回结果集是不是有数据
```python
models.Book.objects.filter(id=9999).exists()
#有结果就是True,没有结果就是False
```
#### 11.values
(返回的queryset类型,里面是字典类型数据)
#### 12.values_list
(返回的queryset类型,里面是数组类型数据)
```python
ret = models.Book.objects.filter(id=9).values('title','price')
ret = models.Book.objects.all().values_list('title','price')
ret = models.Book.objects.all().values()
ret = models.Book.objects.values() #调用values或者values_list的是objects控制器,那么返回所有数据
```
#### 13.distinct()
去重,配置values和values_list来使用,不能带有id 因为id默认唯一
```python
models.Book.objects.all().values('publish').distinct()
```
### filter双下划线查询
queryset类型 筛选出来的是queryset类型
get筛选出来一个是model对象
**queryset 类型的方法可以多次调用使用**
13个api能调用的函数和方法(重点)
```python
# ret = models.Book.objects.all().values('publish').distinct()
# ret = models.Book.objects.filter(price__gt=35) #大于
# ret = models.Book.objects.filter(price__gte=35) # 大于等于
# ret = models.Book.objects.filter(price__lt=35) # 小于等于
# ret = models.Book.objects.filter(price__lte=35) # 小于等于
# ret = models.Book.objects.filter(price__range=[35,38]) # 大于等35,小于等于38 # where price between 35 and 38
# ret = models.Book.objects.filter(title__contains='金梅') # 字段数据中包含这个字符串的数据都要
# ret = models.Book.objects.filter(title__contains='金梅')
# ret = models.Book.objects.filter(title__icontains="python") # 不区分大小写
ret = models.Book.objects.filter(title__isnull=True) # 判断为空的筛选出来
# from app01.models import Book
# ret = models.Book.objects.filter(title__icontains="python") # 不区分大小写
# ret = models.Book.objects.filter(title__startswith="py") # 以什么开头,istartswith 不区分大小写
# ret = models.Book.objects.filter(publish_date='2019-09-15')
某年某月某日(对于日期的修改):
ret = models.Book.objects.filter(publish_date__year='2018')
ret = models.Book.objects.filter(publish_date__year__gt='2018')#2018写数字也可以
ret = models.Book.objects.filter(publish_date__year='2019',publish_date__month='8',publish_date__day='1')
找字段数据为空的双下滑线
models.Book.objects.filter(publish_date__isnull=True) #这个字段值为空的那些数据
```
## 多表查询
多表是会为减少数据的冗余 加速查询的效率
models.字段类型()
### 表结构
```python
rom django.db import models
# Create your models here.
class Author(models.Model):
"""
作者表
"""
name=models.CharField( max_length=32)
age=models.IntegerField()
#一对一 authorDetail=models.OneToOneField(to="AuthorDetail",to_field="nid",on_delete=models.CASCADE) #
#一对一
au=models.OneToOneField("AuthorDetail",on_delete=models.CASCADE)
class AuthorDetail(models.Model):
"""
作者详细信息表
"""
birthday=models.DateField()
telephone=models.CharField(max_length=11)
addr=models.CharField(max_length=64)
# class Meta:
# db_table='authordetail' #指定表名
# ordering = ['-id',]
class Publish(models.Model):
"""
出版社表
"""
name=models.CharField( max_length=32)
city=models.CharField( max_length=32)
class Book(models.Model):
"""
书籍表
"""
title = models.CharField( max_length=32)
publishDate=models.DateField()
price=models.DecimalField(max_digits=5,decimal_places=2)
#一对多
publishs=models.ForeignKey(to="Publish",on_delete=models.CASCADE,)
多对多
authors=models.ManyToManyField('Author',)
```
### 注意事项
```python
#重中之重 不要把表名和库名设置成一样的
1.不写字段默认外键默认连接id
2.创表默认创建主键 无需手动创建
3.oneto one 一对一#OneToOneField
4.id可以省略(自动连接另一个表的id字段(主键))
5.djnago1.0版本可以不写外键 默认级联删除
6.djnago2.0版本必须写on_delete=models.CASCADE
7.int类型不能进行模糊搜索 例如 电话去模糊匹配 前三位
字段名__startwith='151'
8.外键字段是赋值变量名=变量名_id
9.class AuthorDetail(models.Model) 创建表结构时 要继承 models.Model方法
完整版写法:
authorDetail=models.ForeignKey(to="AuthorDetail",to_field="nid",on_delete=models.CASCADE)
class meta:
指定创建表时的源信息
ordering 排序
db contrations 去除强制约束效果
```
### 多对多关系
```python
# 多对多没办法使用一个表的外键去设置
#多对多关系用第三张表存储关系
优点
存入字段数据少 数据库小 增加执行效率
1.manytomany #authors=models.ManyToManyField('Author',)
ManyToManyField不会加字段
book——author 一个表-另一个表
1.会生成一个表 字段会自己建立
2。一个字段是表名——id
3.下一个字段是另一个表——id
会自动创建 对应id字段,存入到一个属性中
使用方法
4.类名或者实例化对象(表名)去调用这个属性
```
### 一对一关系
```python
#注意事项
1.如果两张表数据不统一 是表数据少的去连接数据多的(数据多的是主表)
2.如果数据统一 建哪个东西
sql语句 把外键变成unique(唯一)格式一样
authorDetail=models.OneToOneField(to="AuthorDetail",to_field="nid",on_delete=models.CASCADE)
```
### 多对一
```python
1。对于外键不需要唯一性,
2。不建立外键唯一(使用models.OneToOneField)建立外键
```
### 外键
```python
1.完整版写法
authorDetail=models.ForeignKey(to="AuthorDetail",to_field="nid",on_delete=models.CASCADE)
2.id可以省略(自动连接另一个表的id字段(主键))
publishs=models.ForeignKey(to="Publish",on_delete=models.CASCADE,)
to=,to_field
#publishs是字段名
2.连接表的两种写法
第一种写法
to="加对应表名" 默认连接主键(id)
第二种写法
publishs=models.ForeignKey(to="Publish",on_delete=models.CASCADE,)
可以不写 直接写表名 但是如果加载在之后会报错因为没有预加载出来
```
## admin使用超级管理员
### 1.连接数据库
**注意**要先连接数据库才能进入admin页面输入密码进行操作
```python
创建与数据库之间的连接
1.在对应的app01 的models文件夹下创建好表,其中表包括(字段类型(约束大小限制)
1.2外键的创建#需要注意的是1.1默认创建 2.0版本需要手动添加
1.2.1 一对一创建外键约束 #属性名=OneToOneFlied(on_update=models.CASCADE)
一对多创建外键约束# 属性名=foreignKey()
也对就是对应的子程序的models
2.创建表记录
3.在对应子程序中把python默认支持的mysqldb 替换成pymysql
原因mysqldb不支持3.4以上版本
```
### 2.创建超级管理员
```python
写法 createsuperuser
两种写法
1.pycharm的一个控制台
#1.manage.py@dbcont > createsuperuser#一开始显示这个
使用createsuperuser创建管理员
2.python控制台
2.1python36 manage.py createsuperuser#创建超级管理员
2.2同理输入账号和密码 邮箱可以不用输入
```
**创建数据(记录)**
```python
1.把models的表导入到admin
在对应app01(子程序中)的admin.py文件中
2.from django.contrib import admin
from app01 import models
admin.site.register(models.表名)
admin.site.register(models.author)#格式 admin.site.reister(models.类名(表名))
```
### 增删改查
在对应子程序的view视图里写增删改查
注意要先引用models模块(对应的models.py文件)
### 增加
#### 一对一
```python
# 一对一
# au_obj = models.AuthorDetail.objects.get(id=4)
查询出对应的models对象 存入表类中
models.Author.objects.create(
name='海狗',
age=59,
# 两种方式
au_id=4
# au=au_obj
#属性对应的值是对应的models对象
)
```
#### 一对多
与一对一的区别
对于连接字段没有唯一的约束
```python
pub_obj = models.Publish.objects.get(id=3)
models.Book.objects.create(
title='xx2',
price=13,
publishDate='2011-11-12',
publishs=pub_obj,
#类属性作为关键字时,值为model对象
publishs_id=3
# 如果关键字为数据库字段名称,那么值为关联数据的值
)
```
#### 多对多
多对多关系表记录的增加
```python
ziwen = models.Author.objects.get(id=3)
haigou = models.Author.objects.get(id=5)
new_obj = models.Book.objects.create(
title='海狗产后护理第二部',
price=0.5,
publishDate='2019-09-29',
publishs_id=2,
)
new_obj是一个对象
#第一种写法
new_obj.authors.add(对应外键字段的值)#对象.属性.方法名添加add
new_obj.authors.add(3,5) #*args **kwargs
#添加的多个值用逗号隔开
new_obj.authors.add(*[3,5]) # 用的最多,
用法:
1.select 下拉框 的值是一个列表 使用name属性 查看对应value的值
2.多选的value值 是提交到后端是一个列表
3.使用*[value]打散#*[3,5]
#第二种写法 添加model对象
new_obj.authors.add(ziwen, haigou)
创建完字段之后要把对应的关系字段写到第三张表里
```
### 删除
#### 一对一
```python
models.AuthorDetail.objects.filter(id=3).delete()
models.Author.objects.filter(id=3).delete()
```
#### 一对多
默认级联删除
**关联的表是主表 主表删除子表的相对应的整条字段也被删除**
```python
models.Publish.objects.filter(id=3).delete()#Publish是主表
models.book.objects.filter(id=3).delete()
```
#### 多对多
```python
只操作对应第三张表
book_obj = models.Book.objects.get(id=2)
book_obj.authors.add() # 添加
book_obj.authors.remove(1) #删除括号里对应的外键关联的id
book_obj.authors.clear() # 清除,筛选出的所有的对应外键关系字段
book_obj.authors.set(['1','5']) # 先清除对应外键关系字段再添加,相当于修改
#易错点
不是在原位置修改是删除这条对应记录,再去添加新纪录
```
### 改
```python
# 改
ret = models.Publish.objects.get(id=2)
models.Book.objects.filter(id=5).update(
title='华丽丽',
#publishs=ret,
publishs_id=1,
)
两种方式
publishs=ret#使用属性 对应的值是model对象
publishs_id=1#对应的id值
```
## 基于对象的跨表查询
```python
obj=models.Author.objects.get(name='王洋')和filter用法一样出来的类型不一样
obj=models.Author.objects.filter(name='王洋').first()
```
****
#### get和filter的区别
```python
1.filter筛选出来的是queryset对象需要转成model对象
1.2如果是多个值 需要for循环取值转换
写法
a=models.Author.objects.filter()[0]
a查询出来多个值 这样使用就只能查出一个
需要for 循环取值
2.get是对应的model对象 可以直接拿来用
#获取单条数据,不存在就报错
```
#### 反向查询和正向查询的区别
````python
1.正向查询是创建外键关系的属性 在当前表中
用法
obj=models.Author.objects.get(name='王洋')
obj.对应的外键属性名.字段名
2.反向查询是表中没有对应创建外键关系的属性
用法·
obj=models.Author.objects.get(name='王洋')
obj.小写表名.字段名 #obj,表名找到对应表
取值
2.使用 for循环列表进行对象取值
举例
obj=models.表名.objects.filter(name='子文')
ret=obj.book_set.all()#查询出来的是个列表s
for i in ret:
print(i.title)
#注意:正向查和反向查有一些区别,
1.正相查结果为多个时,直接obj.对应的外键属性名.all()就可以,
2.反向查有一些不同obj.小写表名_set.all()
````
##### 注意
```python
如果 查询东西多
2.1需要注意:
正向查和反向查有一些区别,
1.当正相查结果为多个时,直接obj.对应的外键属性名.all()就可以,
写法
# 海狗的怂逼人生 是哪些作者写的 -- 正向查询
obj = models.Book.objects.filter(title='海狗的怂逼人生').first()
ret = obj.authors.all()#可以直接查询到作者对应的名字 (直接查询到)
2.但是反向查有一些不同obj.小写表名_set.all()
写法
#举例子文写了多少本书 --反向查询
obj=models.表名.objects.filter(name='子文')
ret=obj.book_set.all()
```
<hr>
### 一对一
```python
# 一对一
正向查询 对象.属性
obj = models.Author.objects.filter(name='王洋').first()
ph = obj.au.telephone
print(ph)
# 查一下电话号码为120的作者姓名
# 反向查询 对象.小写的表名
obj = models.AuthorDetail.objects.filter(telephone=120).first()
ret = obj.author.name #陈硕
print(ret)
```
<hr>
### 一对多
```python
# 查询
# 一对多
# 查询一下 海狗的怂逼人生这本书是哪个出版社出版的 正向查询
obj = models.Book.objects.filter(title='海狗的怂逼人生').first()
ret = obj.publishs.name
print(ret) #24期出版社
# 查询一下 24期出版社出版过哪些书
obj = models.Publish.objects.filter(name='24期出版社').first()
ret = obj.book_set.all() #<QuerySet [<Book: 母猪的产后护理>, <Book: 海狗的怂逼人生>]>
for i in ret:
print(i.title)
```
<hr>
### 多对多
#### 关于多对多正向反向查询的的解释
```python
一句话概括
是两个的表的关系属性在哪个表里(类)哪个表就是查询正向查询 (不是外键字段存在哪个表)
解释
1.多对多需要建立在数据之上 因为没有数据的支持没办法建立外键,建立外键约束
2.多对多采用把关系存在第三张表里
3.基于对象的查询是根据属性查询
4.两个表的关系属性在哪个表里 哪个表就是正向查询
```
#### 具体事例
```python
# 多对多
如果post请求多个值使用getlist(字段)
写法
obj=request.POST.getlist("author_id")
#取得的是一个列表
# 海狗的怂逼人生 是哪些作者写的 -- 正向查询
obj = models.Book.objects.filter(title='海狗的怂逼人生').first()
ret = obj.authors.all()#可以直接查询到作者对应的名字 (直接查询到)
print(ret) #<QuerySet [<Author: 王洋>, <Author: 海狗>]>
for i in ret:
print(i.name)
# 查询一下海狗写了哪些书 -- 反向查询
obj = models.Author.objects.filter(name='海狗').first()
ret = obj.book_set.all()
print(ret)
for i in ret:
print(i.publishs.name)
print(i.title)
return HttpResponse('ok')
```
## 基于双下划线的跨表查询(join)
### **相当于mysql里的join链表**
原生sql**语句写法**
```sql
select emp.name from emp inner join dep on dep.id=emp.id where emp.name='技术部';
select emp.name from dep inner join emp on dep.id=emp.id where emp.name='技术部';
```
**注意**
```python
1.表的查询先后指定哪个表都可以
2.value里面是什么 查询出来字典的键就是什么,
3.可以查询出来多个不用.all() 返回一个字典
4.属性__字段 小写表名__字段 #字段都是关联表字段
```
### 写法
```python
表的查询先后指定哪个表都可以
#正向查询
写法
models.含有外键关联属性的表名.filter(本表字段=条件).value( 属性_ _外键字段)
海狗的怂逼人生这本书是哪个出版社出版的
#反向查询
写法
models.不含有外键关联属性的表名.filter(小写表名_ _字段='值').values('本表字段')
示例
海狗的怂逼人生这本书是哪个出版社出版的
ret = models.Publish.objects.filter(book__title='海狗的怂逼人生').values('name')
print(ret) #<QuerySet [{'name': '24期出版社'}]>
```
#### 返回多个值
````python
反向查询返回多个值
写法
models.不有外键关联属性的表名.filter(本表字段=条件).value( 小写表名_ _字段)
示例
查询一下24期出版社出版了哪些书
#反向查询返回多个值
ret = models.Publish.objects.filter(name='24期出版社').values('book__title')
print(ret) #<QuerySet [{'book__title': '华丽的产后护理'}, {'book__title': '海狗的怂逼人生'}]>
正向查询返回多个值
写法
models.含有外键关联属性的表名.filter(属性_ _字段).values('本表字段')
#示例
查询一下24期出版社出版了哪些书
#正向查询返回多个值
ret = models.Book.objects.filter(publishs__name='24期出版社').values('title')
print(ret) #<QuerySet [{'title': '华丽的产后护理'}, {'title': '海狗的怂逼人生'}]>
````
### 一对一
**示例**
```python
# 查询一下王洋的电话号码
#正向
ret = models.Author.objects.filter(name='王洋').values('au__telephone')
#反向
ret = models.AuthorDetail.objects.filter(author__name='王洋').values('telephone')
# print(ret) #<QuerySet [{'au__telephone': '110'}]> #<QuerySet [{'telephone': '110'}]>
```
### 一对多
**示例**
```python
海狗的怂逼人生这本书是哪个出版社出版的
#正向
ret = models.Book.objects.filter(title='海狗的怂逼人生').values('publishs__name')
print(ret) #<QuerySet [{'publishs__name': '24期出版社'}]>
#反向
ret = models.Publish.objects.filter(book__title='海狗的怂逼人生').values('name')
print(ret) #<QuerySet [{'name': '24期出版社'}]>
#返回多个值
查询一下24期出版社出版了哪些书
#反向查询返回多个值
ret = models.Publish.objects.filter(name='24期出版社').values('book__title')
print(ret) #<QuerySet [{'book__title': '华丽的产后护理'}, {'book__title': '海狗的怂逼人生'}]>
#正向查询返回多个值
ret = models.Book.objects.filter(publishs__name='24期出版社').values('title')
print(ret) #<QuerySet [{'title': '华丽的产后护理'}, {'title': '海狗的怂逼人生'}]>
```
### 多对多
**示例**
```python
海狗的怂逼人生 是哪些作者写的
正向 返回多个值
authors__name 是属性__外键字段
ret = models.Book.objects.filter(title='海狗的怂逼人生').values('authors__name')
print(ret)
反向 返回多个值
book__title 是小写表名__外键字段
ret = models.Author.objects.filter(book__title='海狗的怂逼人生').values('name')
print(ret) #<QuerySet [{'name': '王洋'}, {'name': '海狗'}]>
```
**补充**
## related_name
写法
```sql
related_name==xxx 别名 注意用了必须用 以后就代指这个字段
```
## 聚合查询
arregate 聚合
不分组聚合只取一个满足条件的
### 注意
```python
1.需要引用模块
2.聚合查询是orm结束符
3.查询出来的值是python的字典
4.不能再继续筛选
```
### 用法
```python
from django.db.models import AVG,SUM,Max
arregate (*args,**kwargs)聚合
1.单个聚合函数
ret=models.表名.objects.all().arregate(AVG('字段名'))
2.多个聚合函数
ret=models.表名.objects.all().arregate(AVG('字段名'),Max('字段名'))
```
### **示例**
```python
# 计算所有图书的平均价格
from app01.models import Book
from django.db.models import Avg
models.Book.objects.all().aggregate(Avg('price'))
Book.objects.all().aggregate(Avg('price'))
#或者给它起名字(查询出来字典显示的键):aggretate(a=Avg('price'))
{'price__avg': 34.35}
```
<hr>
## 分组查询
annotate其实就是对分组结果的统计
分组执行的顺序
```python
例如 models.Book.objects.value('id').annotate(max=Max('price')).arregate(Avg('max'))
#分组完进一步用聚合函数筛选
#跨表
1.以book的id进行分组
2.annotate(max=Max('price'))#以最高的价钱进行统计起一个别名max
3.arregate(Avg('max')#把筛选完的表名 进一步进行筛选
4.arregate是orm的最后结束符
```
**跨表分组查询本质就是将关联表join成一张表,再按单表的思路进行分组查询,,既然是join连表,就可以使用咱们的双下划线进行连表了。**
**注意**
```python
1.查询的平均值的字段必须要起别名 用values进行别名取值 vlues('别名')
2.values是分组的依据 可以属性可以字段
3.可以直接 model.表名.objects.annotate #默认依据表名的id主键进行分组
```
### 原生sql语句
```python
#单表
select dep,Count(*) from emp group by dep;
#多表
select dep.name,Count(*) from emp left join dep on emp.dep_id=dep.id group by dep.id;
```
### 用法
```python
两种写法
第一种 指定字段分组
models.分组的表名.objects.values('分组的字段').annotate(别名=聚合函数('字段名')).values('别名')
#别名取值
#示例
models.emp.objects.values("dep").annotate(c=Count("id")).values('c')
#对象.values()
models.dep.objetcs.values("id").annotate(c=Count("emp")).values("name","c")
'''
第二种 不指定values分组默认id进行分组
'''
models.分组的表名.objects.annotate(别名=聚合函数('字段名')).values('别名')
# 示例
ret = models.Publish.objects.annotate(a=Avg('book__price')).values('a')
# print(ret) #<QuerySet [{'a': None}, {'a': 71.166667}, {'a': 6.0}]>
```
## F查询
比较同一个 model (同一个表)实例中两个不同字段的值。
可以查询出来所有进行修改
### 用法
```python
from django.db.models import Avg, Sum, Max, Min, Count,F
F('本表字段')
#示例
from django.db.models import Avg, Sum, Max, Min, Count,F
#查询一下评论数大于点赞数的书
两个字段进行比较
ret = models.Book.objects.filter(comment__gt=F('good'))
print(ret)
查询出所有本表字段进行修改
将所有书的价格上调100块
# models.Book.objects.all().update(
# price=F('price')+100
# )
```
## Q查询
`filter()` 等方法中的关键字参数查询都是一起进行“AND” 的。 如果你需要执行更复杂的查询(例如`OR` 语句),你可以使用`Q 对象`。
### 写法
```python
或查询
q()
#注意
models.Book.objects.filter(Q(id=2),price=3)
不能写在Q()前面会报错
```
### 用法
```python
# Q(条件)
# Q(条件)&Q(条件) 与
# Q(条件)|Q(条件) 或
# ~Q(条件) 非
1.单层
q('字段'__比较=值)|q('字段'__比较=值)
2.多层嵌套 关键字必须 写在q查询之后会报错 想要写之前就要用q()
#示例
ret = models.Book.objects.filter(Q(id=2)&Q(Q(price__gt=112)|~Q(comment__lte=200)))
print(ret)
3.Q
拼接
```
### q查询补充
#### 字典的用法
```python
**{serch_field:keyword}#出来的关键字
**{serch_field+'__contains':keyword}#字符串的拼接
这个想法比较局限不能多条件查询
```
#### 单q查询和多q查询
```python
流程
1.因为双下模糊查询只能根据单个字段进行匹配 所以正常使用是根据字段双下写
例如
#name__contains=search_name
2.如果要使用想根据自己筛选的值进行变动 需要用
#Q()查询
使用 1.q=Q()实例化对象
2.根据实例化对象进行字段替换
#把name__contains 换成传入的search值 search__contains
#可以根据自己传入的字段进行替换
<option value="qq__contains">qq</option>
<option value="name__contains">姓名</option>
······················Q查询源码····························
class Q(tree.Node):
"""
Encapsulates filters as objects that can then be combined logically (using
`&` and `|`).
"""
# Connection types
AND = 'AND'
OR = 'OR'
default = AND
```
#### 小title多Q
**知识点**
```python
from django.db.models import Q
传入条件进行查询:
q1 = Q()
q1.connector = 'OR'
q1.children.append(('id', 1))
q1.children.append(('id', 2))
q1.children.append(('id', 3))
models.Tb1.objects.filter(q1)
两个q查询进行结合
合并条件进行查询:
con = Q()
q1 = Q()
q1.connector = 'OR'
q1.children.append(('id', 1))
q1.children.append(('id', 2))
q1.children.append(('id', 3))
q2 = Q()
q2.connector = 'OR'
q2.children.append(('status', '在线'))
con.add(q1, 'AND')
con.add(q2, 'AND')
models.Tb1.objects.filter(con)
```
实例
在django**中使用脚本实现**合并实现
```python
import os
if __name__ == '__main__':
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "test24.settings")
import django
django.setup()
from django.db.models import Q
from app01.models import Book
conn=Q()
q1 = Q()
q1.connector = 'OR'
q1.children.append(('id', 6))
q1.children.append(('id', 7))
q1.children.append(('id', 9))
q2=Q()
q2.connector='OR'
q2.children.append(('price',12))
conn.add(q1,'AND')
conn.add(q2,'AND')
print(q1)
print(q2)
print(conn)
print(Book.objects.filter(conn))
打印结果
'''
q1 (OR: ('id', 6), ('id', 7), ('id', 9))
q2 (OR: ('price', 12))
conn (AND: (OR: ('id', 6), ('id', 7), ('id', 9)), ('price', 12))
<QuerySet [<Book: 2019-10-02111>, <Book: 母猪的产后护理11>]>
'''
```
### crm示例
#### html页面写法
```python
传值
<div class="form-group">
<select name="search_field" id="" class="form-control">
<option value="qq__contains">qq</option>
<option value="name__contains">姓名</option>
</select>
<input type="text" class="form-control" id="search-word" placeholder="请输入" name="keyword">
</div>
```
##### view写法
```python
view写法
#单Q的使用
q=Q()
q.children.append([search,keyword])
#根据name对应的values值筛选
all_customers = models.Customer.objects.filter(q)
#多Q的使用
q=Q()
q.connector = 'or'#指定q对象中的查询条件的连接符,或的关系,默认是and
q.children.append([search,keyword])
#all_customers = models.Customer.objects.filter(Q(search(对应字段)__contains=search_name))
all_customers = models.Customer.objects.filter(q)
#具体代码
class Customers(View):
def get(self,request):
print(request.get_full_path()) #/customers/?page=3
path = request.path
recv_data = copy.copy(request.GET)
current_page_number = request.GET.get('page') # 当前页码
search_field = request.GET.get('search_field') # 搜索条件
keyword = request.GET.get('keyword') # 搜索数据 陈
if keyword:
q = Q() # 实例化q对象
q.children.append([search_field, keyword]) #
all_customers = models.Customer.objects.filter(q)
else:
all_customers = models.Customer.objects.all()
if path == reverse('sales:customers'):
# 筛选所有公户的客户信息
tag = '1'
all_customers = all_customers.filter(consultant__isnull=True)
else:
tag = '0'
all_customers = all_customers.filter(consultant__username=request.session.get('username'))
total_count = all_customers.count()
per_page_count = settings.PER_PAGE_COUNT
page_number_show = settings.PAGE_NUMBER_SHOW
page_obj = DQPage(current_page_number, total_count, per_page_count, page_number_show, recv_data)
all_customers = all_customers[page_obj.start_data_number:page_obj.end_data_number]
page_html = page_obj.page_html_func()
return render(request, 'customer/customers.html',
{'tag': tag, 'all_customers':
all_customers, 'page_html': page_html, 'keyword': keyword,
#再次传入查询关键字就会保留搜索的字段
'search_field': search_field})
```
#### 自定义q查询
```python
view写法
#单Q的使用
q=Q()
q.children.append([search,keyword])
#根据name对应的values值筛选
all_customers = models.Customer.objects.filter(q)
#多Q的使用
q=Q()
q.connector = 'or'#指定q对象中的查询条件的连接符,或的关系,默认是and
q.children.append([search,keyword])
#all_customers = models.Customer.objects.filter(Q(search(对应字段)__contains=search_name))
all_customers = models.Customer.objects.filter(q)
'''
con = Q()
q1 = Q()
q1.connector = 'OR'
q1.children.append(('id', 1))
q1.children.append(('id', 2))
q1.children.append(('id', 3))
q2 = Q()
q2.connector = 'OR'
q2.children.append(('status', '在线'))
con.add(q1, 'AND')
con.add(q2, 'AND')
models.Tb1.objects.filter(con)
'''
```
#### 使用自定义q查询
```python
class Customers(View):
def get(self,request):
print(request.get_full_path()) #/customers/?page=3
path = request.path
recv_data = copy.copy(request.GET)
current_page_number = request.GET.get('page') # 当前页码
search_field = request.GET.get('search_field') # 搜索条件
keyword = request.GET.get('keyword') # 搜索数据 陈
if keyword:
'''
q查询
'''
q = Q() # 实例化q对象
q.children.append([search_field, keyword]) #
all_customers = models.Customer.objects.filter(q)
else:
all_customers = models.Customer.objects.all()
if path == reverse('sales:customers'):
# 筛选所有公户的客户信息
tag = '1'
all_customers = all_customers.filter(consultant__isnull=True)
else:
tag = '0'
all_customers = all_customers.filter(consultant__username=request.session.get('username'))
total_count = all_customers.count()
per_page_count = settings.PER_PAGE_COUNT
page_number_show = settings.PAGE_NUMBER_SHOW
page_obj = DQPage(current_page_number, total_count, per_page_count, page_number_show, recv_data)
all_customers = all_customers[page_obj.start_data_number:page_obj.end_data_number]
page_html = page_obj.page_html_func()
return render(request, 'customer/customers.html',
{'tag': tag, 'all_customers': all_customers, 'page_html': page_html, 'keyword': keyword,
'search_field': search_field})
```
## orm的缺点
```python
遇到排序问题会查询出错
用聚合函数排序出来的价格不能跟书名进行匹配
每个作者出版的所有书的最高价格以及最高价格的那本书的名称
```
## orm执行原生sql语句
在模型查询API不够用的情况下,我们还可以使用原始的SQL语句进行查询。
Django 提供两种方法使用原始SQL进行查询:一种是使用raw()方法,进行原始SQL查询并返回模型实例;另一种是完全避开模型层,直接执行自定义的SQL语句。
```python
raw()# 取的是一个对象
写法
ret = models.Student.objects.raw('select * from app02_teacher', translations=d)
for i in ret:
print(i.id, i.sname, i.haha)
需要for 循环
```
### 自定义sql语句
django封装的
```python
from django.db import connection, connections
cursor = connection.cursor() # cursor = connections['default'].cursor()
cursor.execute("""SELECT * from auth_user where id = %s""", [1])
ret = cursor.fetchone()
```
### setting配置打印日志
```python
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
#脚本运行
import os
if __name__ == '__main__':
# 加载 Django 项目的配置信息 配置对应的表的信息
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "crmIGNB.settings")
# 导入 Django,并启动 Django 项目
import django
django.setup()
from sale import models
# 查询 Book 表中的所有数据
ret = models.Book.objects.filter()
print(ret)
```
## orm锁
### mysql的锁
```python
selec * from book where id=1 for update
```
### orm的锁
```python
写法
models.Book.objects.select_for_update().filter(id=1)
entries =models.Entry.objects.select_for_update().filter(author=request.user)
```
## orm事务
直接在单个sql加锁 执行结束锁结束
事务加锁 是事务里面的语句 完成才会释放
要完成
### mysql事务
```python
begin; start transaction;#开启事务的两种写法
select * from t1 where id=1 for update;
commit
rollback;
```
### django事务配置全局开启
### 执行流程
```python
1.当有请求过来时,Django会在调用视图方法前开启一个事务。
2.如果请求却正确处理并正确返回了结果,Django就会提交该事务。
3.否则,Django会回滚该事务。
```
### settings配置
```python
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'mxshop',
'HOST': '127.0.0.1',
'PORT': '3306',
'USER': 'root',
'PASSWORD': '123',
'OPTIONS': {
"init_command": "SET default_storage_engine='INNODB'",
#'init_command': "SET sql_mode='STRICT_TRANS_TABLES'", #配置开启严格sql模式
}
"ATOMIC_REQUESTS": True, #全局开启事务,每个视图的orm都会存在事务
"AUTOCOMMIT":False, #全局取消自动提交,慎用
},
'other':{
'ENGINE': 'django.db.backends.mysql',
......
} #还可以配置其他数据库
}
```
### django orm局部的开启
```python
#两种方式
第一种写法 装饰器
from django.db import transaction
@transaction.atomic
def viewfunc(request):
# This code executes inside a transaction.
执行内部代码
第二种写法 上下文管理#设置事务的保存点
def index(request):
with transaction.atomic():
xxxx
上下文管理的坑
```
### django事务管理代码流程
```python
下面是Django的事务管理代码:
1.进入最外层atomic代码块时开启一个事务;
2.进入内部atomic代码块时创建保存点;
3.退出内部atomic时释放或回滚事务;注意如果有嵌套,内层的事务也是不会提交的,可以释放(正常结束)或者回滚
4.退出最外层atomic代码块时提交或者回滚事务;
#你可以将保存点参数设置成False来禁止内部代码块创建保存点。
#如果发生了异常,Django在退出第一个父块的时候执行回滚,如果存在保存点,将回滚到这个保存点的位置,否则就是回滚到最外层的代码块。
#外层事务仍然能够保证原子性。
#然而,这个选项应该仅仅用于保存点开销较大的时候。
#毕竟它有个缺点:会破坏上文描述的错误处理机制
```
### transaction的其他方法
```python
@transaction.atomic
def viewfunc(request):
a.save()
# open transaction now contains a.save()
sid = transaction.savepoint() #创建保存点
b.save()
# open transaction now contains a.save() and b.save()
if want_to_keep_b:
transaction.savepoint_commit(sid) #提交保存点
# open transaction still contains a.save() and b.save()
else:
transaction.savepoint_rollback(sid) #回滚保存点
# open transaction now contains only a.save()
transaction.commit() #手动提交事务,默认是自动提交的,也就是说如果你没有设置取消自动提交,那么这句话不用写,如果你配置了那个AUTOCOMMIT=False,那么就需要自己手动进行提交。
```
### 事务的小原则(小细节)
```python
1.保持事务短小
2.尽量避免事务中rollback
3.尽量避免savepoint
4.默认情况下,依赖于悲观锁
5.为吞吐量要求苛刻的事务考虑乐观锁
6.显示声明打开事务
7.锁的行越少越好,锁的时间越短越好
```
# Ajax
## 基于jquery写法
Ajax现有标准新方法
### 单个ajax写法
不提交数据
```python
$.ajax({
url:'{% url "login" %}',#反向解析路径
type:'get',#请求格式 #默认不写是get
success:function (res) {#提交成功执行匿名函数 function
#res是接收后端返回的数据(返回的是请求ulr 视图返回的相关数据 )
#注意后端返回一个重定向不是路径 是对应的heml页面
console.log(res);
}
})
```
### ajax携带数据的写法
#### view视图写法
```python
def login(request):
if request.method == 'GET':
return render(request,'login.html')
else:
uname = request.POST.get('username')
pwd = request.POST.get('password')
if uname == 'dui' and pwd == 'gang':
return HttpResponse('1')#把数据传递到前端进一步进行判断
else:
return HttpResponse('0')#把数据传递到前端进一步进行判断
```
#### login.html写法
```python
<script>
$('#sub').click(function () {
var uname = $('#username').val();{# 获取username的值 #}
var pwd = $('#password').val();{# 获取password的值 #}
$.ajax({
url:'{% url "login" %}',#反向解析路径
type:'post',#请求格式
// data:{username:uname,password:pwd,csrfmiddlewaretoken:csrf},
data:{username:uname,password:pwd},
#自定义对象相当于python字典 相当于请求的数据
headers:{#把csrf封装到请求头
"X-CSRFToken":$.cookie('csrftoken'),
},
success:function (res) {#接收后台返回数据
#res是接收后端返回的数据(可以返回对应页面可以返回字典,一切)
console.log(res);
if (res === '1'){
$('.error').text('登录成功');
location.href = '/home/';
// 指定路径http://127.0.0.1:8000/home/
#跳转到指定路径 location.href 获取当前页面的路径
把路径返回给浏览器 浏览器去请求
}else{
$('.error').text('用户名密码错误!');
}
}
})
</script>
```
### Ajax的特点
```python
两种说法意思一样
1.最大的优点是在不重新加载整个页面的情况下,可以与服务器交换数据并更新部分网页内容
2.异步交互:#客户端发出一个请求后,无需等待服务器响应结束,就可以发出第二个请求
3.浏览器页面局部刷新(提高用户感受在不知不觉中完成请求 )
优点:
1.AJAX使用JavaScript技术向服务器发送异步请求;
2.AJAX请求无须刷新整个页面;
3.因为服务器响应内容不再是整个页面,而是页面中的部分内容,所以AJAX性能高;
```
## Ajax参数
### ajax之csrf_token
```python
csrf攻击的最直接的办法就是生成一个随机的csrftoken值,保存在用户的页面上,每次请求都带着这个值过来完成校验。
#django的csrf验证(django在post请求csrf认证)
1.token 前32位是盐 之后是加密的数据
2.浏览器form表单中的token每次都会变,而cookie中的token不便
3.django 认证会在后台随机生成csrftoken值,加在cookie里面
4.django会验证表单中的token和cookie中token是否能解出同样的secret
```
### form表单过csrf
#### 写法
```html
<form action="" method="post">
{% csrf_token %}
// form表单里面加上这个标签,模板渲染之后就是一个input标签,type=hidden name=csrfmiddlewaretoken value='asdfasdfasdf'
用户名: <input type="text" name="username">
密码: <input type="password" name="password">
<input type="submit">
</form>
```
### ajax请求设置csrf_token
##### 概念
```python
#官方解释检验token时,只比较secret是否和cookie中的secret值一样,而不是比较整个token。
1.csrf跨站请求伪造
1.1为什么要有csrf
攻击者通过HTTP请求江数据传送到服务器,从而盗取回话的cookie。盗取回话cookie之后,攻击者不仅可以获取用户的信息,还可以修改该cookie关联的账户信息。
所以解决csrf攻击的最直接的办法就是生成一个随机的csrftoken值,保存在用户的页面上,每次请求都带着这个值过来完成校验。
2.csrf的作用
1.可以确保是网站对应的登陆页面发送的
2.csrf是一个标识 根据标识确定用户信息
3.防止第三方页面进行跨站请求伪造 修改信息 例如银行信息
4.有了csrf可以通过标识符,保护用户信息的安全
django默认封装了一个配置
# 'django.middleware.csrf.CsrfViewMiddleware',#跨站请求伪造
```
### csrf在form表单的书写方式
```html
<form>
{% csrf_token %}#标识符
<!--html会渲染成 隐藏的input标签-->
用户名: <input type="text" id="username">
密码: <input type="password" id="password">
<button id="sub">提交</button>
<span class="error"></span>
</form>
```
### csrf在jquery种三种书写方式
注意 字段名不能更改 django封装的
```html
<!--三种方式-->
<第一种 通过获取隐藏的input标签中的csrfmiddlewaretoken值,放置在data中发送>
{% csrf_token %}
<button class="send_Ajax">send_Ajax</button>
<script>
$(".send_Ajax").click(function(){
var uname=$('#username').val();
var pwd=$('#password').val();
var csrf=$([name=csrfmiddlewaretoken]).val();#取到对应属性name的值
$.ajax({
url: "{% url 'index' %}",#对应url路径,通过别名反向解析
type: "POST",#请求方式
data: {
//#"username": "chao",#对应html的input标签的键
"username":uname,
//"password": 123456,#对应html的input标签的键
"password":pwd,
"csrfmiddlewaretoken":csrf,//和下一行的写法一样 下面是简化版
"csrfmiddlewaretoken": $("[name = 'csrfmiddlewaretoken']").val() // 使用jQuery属性选择器取出csrfmiddlewaretoken的值,拼接到data中
},
{# success提交成功之后执行匿名函数function #}
success: function (data) {
console.log(data);
}
})
</script>
<第二种 通过后端获取键值>
<script>
$(".send_Ajax").click(function(){
$.ajax({
url: "{% url 'index' %}",#对应url路径,通过别名反向解析
type: "POST",#请求方式
data: {
"username": "chao",#对应html的input标签的键
"password": 123456,#对应html的input标签的键
csrfmiddlewaretoken: '{{ csrf_token }}' // 获取出csrfmiddlewaretoken的值
},
{# success提交成功之后执行匿名函数function #}
success: function (data) {
console.log(data);
}
})
</script>
<第三种 写在请求头里>
第三种方式需要下载引用jquery.cookie模块
<script>
$.ajax({
url: "/cookie_ajax/",
type: "POST",
headers: {"X-CSRFToken": $.cookie('csrftoken')},
//其实在ajax里面还有一个参数是headers,自定制请求头,可以将csrf_token加在这里,我们发contenttype类型数据的时候,csrf_token就可以这样加,
//还可以加别的值 自定义对象类似python字典的形式存储
data: {"username": "chao", "password": 123456},
success: function (data) {
console.log(data);
}
</script>
```
### 浏览器和网站进行交互的过程
```python
1.浏览器正常在登陆页面存在封装好的token(用于防止跨站请求伪造)
2.银行系统会返回一个相应的cookie进行建立连接
3.用户在交互的过程不小心点击了第三方网站 第三方网站发送一个重定向 继续访问银行系统
4.浏览器接收重定向直接访问银行系统 但是没有相应的token只有相应的cookie就会报错
#注意只有在网站对应登陆页面才会返回相应cookie(cookie是建立会话的请求)
#如果只是单纯的访问页面,对应页面不会发送对应的cookie给浏览器
#正常访问登陆页面会存在对应token键值对
#对应网站的cookie会一直存在浏览器中 cookie会有一个时间段默认是两周
'''
跨站请求伪造的csrf可以理解为标识符 有了这个标识符才可以通过csrf认证
django里的{% csrf_token %}只有在正确访问页面时才会被替换
如果被第三方页面进行跨站伪造(利用跳转进行身份伪造)不会被替换,
相应的csrf验证也不会通过
'''
```
第三方攻击

### 问题 cookie和页面存储的csrf值不相等
#### 在浏览器发送post请求查看存在cookie对应的csrf键值对(数据)
#### 查看当前页面的csrf
##### 当前页面的csrf值和cookie存在的csrf值不相等 怎么进行判断
```python
#django的csrf验证是django封装的(django在post请求csrf认证)
1.token 前32位是盐 之后是加密的token
虽然加密值不一样但通过解密之后就可以比较token值是否相同
2.form表单中的token每次都会变,而cookie中的token不变
3.django 认证会在后台随机生成csrftoken值,加在cookie里面
4.django里面的csrf验证机制会验证表单中的token和cookie中token是否能解出同样的token值
#注意 cookie是里面的csrf验证是第一次访问页面 提供给浏览器的 ,访问会自动携带
```
## ajax之编辑删除
### 知识点
```python
var aa=$("button[bookid="+ id +"]").parent();
通过字符串拼接进行单条数据查询
```
### script写法
```python
<script src="/static1/js/jquery-3.4.1.js"></script>
<script src="/static1/pluin/bootstrap-3.3.7-dist/js/bootstrap.min.js"></script>
<script src="/static1/pluin/bootstrap-sweetalert-master/dist/sweetalert.min.js"></script>
<script>
$(".ajx").on("click", function () {
var ths = $(this);
#得到对应的id属性
var book_id = ths.attr('book_id');
console.log(book_id);
swal({
title: "你确定要删除吗?",
text: "删除可就找不回来了哦!",
type: "warning",
showCancelButton: true,
confirmButtonClass: "btn-danger",
confirmButtonText: "删除",
cancelButtonText: "取消",
closeOnConfirm: false
},
function () {
//var deleteId = $(this).parent().parent().attr("data_id");
//console.log(ths);
//console.log($(this));
var book_id = ths.attr('book_id');
console.log(book_id);
$.ajax({
url: "{% url 'app01:delete1' %}",
type: "post",
data: {"book_id": book_id, 'csrfmiddlewaretoken': "{{ csrf_token }}"},
success: function (data) {
if (data === 1) {
swal("删除成功!", "你可以准备跑路了!", "success");
// location.reload();
ths.parent().parent().remove();
$('#error').text('成功');
} else {
swal("删除失败", "你可以再尝试一下!", "error");
}
}
})
})
});
$('.ajx1').on('click', function () {
var thi = $(this);
var book_id = thi.attr('book_ip');
$.ajax({
url: "{% url 'app01:editor2' %}",
type: "get",
data: {"book_id": book_id, 'csrfmiddlewaretoken': "{{ csrf_token }}"},
success: function (data) {
console.log(data);
$('#id-book').val(data['title']);
$('#id-price').val(data['price']);
$('#id-publish').val(data['pubulish_ch']);
$('#id-date').val(data['publishDate']);
$('#id-author').val(data['author_ch']);
$('.ajax2').attr('id_1', data['id']);
}
})
});
$('.ajax2').on('click', function () {
var thi = $(this);
var book_id = thi.attr('id_1');
var book_title = $('#id-book').val();
var book_price = $('#id-price').val();
var book_publish = $('#id-publish').val();
var book_date = $('#id-date').val();
var book_author = $('#id-author').val();
console.log('3333'+book_id);
$.ajax({
url: "{% url 'app01:editor2' %}",
type: "post",
traditional: true,
data: {
"id": book_id, 'price': book_price, 'title': book_title, 'publishs_id': book_publish,
'publishDate': book_date, 'authors_id': book_author, 'csrfmiddlewaretoken': "{{ csrf_token }}"
},
success: function (data) {
console.log(data);
if (data.status === 1) {
alert('修改成功');
var a = thi.attr('id');
var id=data.MSG_ID;
var aa=$("button[bookid="+ id +"]").parent();
console.log(aa)
} else {
alert('修改失败')
}
}
})
});
</script>
```
**具体代码详见博客园或者云盘的具体项目示例之 ajax之编辑删除****
## ajax之文件上传
Content-type数据消息格式
### form表单上传文件
### 1.x-www-form-urlencoded
```python
当action为get时候,浏览器用x-www-form-urlencoded的编码方式把form数据转换成一个字串(name1=value1&name2=value2…),
然后把这个字串append到url后面,
用?分割,加载这个新的url。
```
### 2.multipart/form-data
```python
当action为post时候,浏览器把form数据封装到http body中,然后发送到server。
如果没有type=file的控件,用默认的application/x-www-form-urlencoded就可以了。
<form> 表单的 enctype 等于 multipart/form-data, 修改对应请求头的格式
告诉浏览器消息一块一块进行上传
```
如果form表单提交为什么要修改请求头呢
```python
1.如果input是type=file的话,就要用到multipart/form-data了。
2.浏览器会把整个表单以控件为单位分割
3.每个部分加上Content-Disposition(form-data或者file),
Content-Type(默认为text/plain),
name(控件name)等信息,
并加上分割符(boundary)。
4.后端使用request.FILES.get('文件对应键或者name值') 获取对象
file_obj=request.FILES.get('文件对应键或者name值')
file_obj.name获取文件名
5.就可以利用这个文件名读取文件
```
```python
<form action="" method="post" enctype="multipart/form-data">
#enctype更改请求头消息格式
#multipart/form-data告诉浏览器文件一块一块上传 不一次性上传
#不然文件接收不到
{% csrf_token %}
用户名: <input type="text" name="username">
密码: <input type="password" name="password">
头像: <input type="file" name="file">
只能上传单个文件
上传文件: <input type="file" name="file" multiple>
#可以支持上传多个文件
<input type="submit">
</form>
```
### view form表单视图参数详解
```python
参数详解
def upload(request):
print(request.body) # 原始的请求体数据
print(request.GET) # GET请求数据
print(request.POST) # POST请求数据
file=request.FILES # 上传的文件数据
print(file) # 上传的文件数据
print(file.name)#获取文件名进行读取
```
### view.py写法
```python
def upload(request):
if request.method == 'GET':
print(settings.BASE_DIR) #/static/
return render(request,'upload.html')
else:
print(request.POST)
print(request.FILES)
uname = request.POST.get('username')
pwd = request.POST.get('password')
file_obj = request.FILES.get('file') #文件对象防止报错
print(file_obj.name) #开班典礼.pptx,文件名称
with open(file_obj.name,'wb') as f:
# for循环是一行一行的读--遇到/r/n算一行
# 遇到压缩文件或者没有/r/n的文件会一下全部取出
#为防止这一事件的产生 使用chunks读取上传的文件
# for i in file_obj:
# f.write(i)
for chunk in file_obj.chunks():#读的字节65535 限制读字节
f.write(chunk)
return HttpResponse('ok')
```
### 问题 如果想要保留form表单的样式不执行上传怎么办
```html
xx.html
<form action=''>
<input type='text' name=xxx>账号
<button></button>#默认支持type=submit<!--button默认支持提交-->
解决方法
<button type=button></button><!--改成普通的按钮-->
<!--[type=sumit]input type=sumit 和button 都可以选择-->
</form>
```
### Ajax文件上传
### 浏览器使用jquery获取文件名
```python
1.$('[type=file]') #获取对应的标签
2.$('[type=fiel]')[0]#转换成dom对象
3.$('[type=fiel]')[0].files#dom对象通过.files(属性)获取files的信息 默认取得是多个file_list
取得多个文件需要在input file标签里写上 multiple
写法
上传文件: <input type="file" name="file" multiple>
4.$('[type=fiel]')[0].files[0]#取得当前一个文件对象
``````````````````````````````````````````````````````````````````````````````
获取文件file属性
<input type=file id='pp'>
var file_obj = document.getElementsById('pp');#获取的直接就是dom对象
file_obj.file[0]获取对应的file值因为 file默认获取是一个file列表
jquery写法 需要转换成dom对象
$('#pp')[0].file[0]
```
### 请求头ContentType格式
#### 1 application/x-www-form-urlencoded
```python
常见post提交数据的方式了,浏览器的原生<form>表单,不设置enctype属性,那么最终会以默认格式
POST http://www.example.com HTTP/1.1
Content-Type: application/x-www-form-urlencoded;charset=utf-8
user=yuan&age=22 #这就是上面这种contenttype规定的数据格式,后端对应这个格式来解析获取数据,不管是get方法还是post方法,都是这样拼接数据,大家公认的一种数据格式,
如果你contenttype指定的是urlencoded类型,post请求体里面的数据是下面那种json的格式,那么就出错了,服务端没法解开数据
然后把这个字串append到url后面,用?分割,加载这个新的url。
需要格式转换
```
### ajax上传文件写法
### 概念补充formdata
```js
ajax 没有办法直接修改请求头 content-Type:multipart/form-data
需要使用FormData对象
FormData对象将数据编译成键值对,以便用XMLHttpRequest来发送数据。
1.独立于表单使用(异步上传文件)
2.其主要用于发送表单数据,但亦可用于发送带键数据(keyed data),
3.如果表单enctype属性设为multipart/form-data ,则会使用表单的submit()方法来发送数据,
写法
var formdata=new FormData()//创建一个formdata对象 默认支持multipart/form-data
//通过FormData构造函数创建一个空对象
var formdata=new FormData();
//可以通过append()方法来追加数据(以键值对的形式)
formdata.append("name","laotie");
processData:false, //不处理编码格式
contentType:false,//不设置处理contentType请求头#不写会报错
headers:{"X-CSRFToken":$.cookie('csrftoken'),},//请求头信息
```
#### formdata对象的增删改查
```js
formdata.append("name","laoliu");
//通过append()方法在末尾追加key为name值为laoliu的数据
formdata.set("name","laoli");
//如果key的值不存在会为数据添加一个key为name值为laoliu的数据
//存在会修改键name数据为laoli
formdata.has("name"));//true
//删除key为name的值
formdata.delete("name");
```
### upload.html写法
```js
<body>
用户名: <input type="text" name="username">
密码: <input type="password" name="password">
上传文件: <input type="file" name="file">
<input type="submit" id="sub">
<span class="error"></span>
</body>
{#<script src="/static/js/jquery.js"></script>#}
<script src="/static/js/jquery-3.4.1.js"></script>
#使用cookie需要引用jquery
<script src="https://cdn.bootcss.com/jquery-cookie/1.4.1/jquery.cookie.js"></script>
{#<script src="{% static 'js/jquery.js' %}"></script>#}
<script>
$('#sub').click(function () {
console.log('123');
//Ajax怎么修改请求头格式
var formdata=new FormData();//创建一个对象FormData
var username = $('#username').val();{# 获取username的值 #}
var password = $('#password').val();{# 获取password的值 #}
var file_obj=$('[type=file]')[0].files[0];#得到对应的jquery转换dom.files属性拿到对应的文件列表取值
formdata.append('username',username);//以键值对的形式添加到formdata对象中,逗号隔开
formdata.append('password',password);//以键值对的形式添加到formdata对象中
formdata.append('file',file_obj);//以键值对的形式添加到formdata对象中
$.ajax({
url:'{% url "upload" %}',//反向解析路径
type:'post',
data:formdata,//这里就可以直接放对象--因为字典是自定义对象
processData:false, //不处理数据
contentType:false,//不设置内容类型#有了这个两个数据告诉ajax不会对数据进行任何加工
//因为处理完之后会把请求头修改成 字符串拼接的格式也就是 application/x-www-form-urlencoded
headers:{
"X-CSRFToken":$.cookie('csrftoken'),
},//需要引用jquery.cookie
success:function (res) {
if (res === 'OK'){
{#$('.error').text('登录成功');#}
location.href = '/home/'; // http://127.0.0.1:8000/home/
}else{
$('.error').text('用户名密码错误!');
}
}
})
})
</script>
```
### view.py写法(后端)
```python
def upload(request):
if request.method=='GET':
return render(request,'upload.html')
else:
print(request.POST)#里面的file只是对应文件名字
print(request.FILES)#文件存储在内存中
uname=request.POST.get('username')#取得post请求过来的值
pwd=request.POST.get('password')#取得post请求过来的值
# file_obj是一个文件对象,相当于一个文件对象
file_obj=request.FILES.get('file')
print(file_obj.name)#取得文件名称
with open(file_obj.name,'wb') as f:
# for i in file_obj:#一行一行的读遇到/r/n算一行
# 遇到压缩文件或者没有/r/n的文件会一下全部取出
#为防止这一事件的产生
# f.write(i)
for chunk in file_obj.chunks():#读的字节65535 限制读字节
f.write(chunk)
return HttpResponse('OK')
```
## json
```python
#第一种写法
if request.method == 'GET':
return render(request,'jsontext.html')
else:
username = request.POST.get('username')
pwd = request.POST.get('password')
ret_data = {'status':None,'msg':None}#自定义一个消息对象
print('>>>>>',request.POST)
#<QueryDict: {'{"username":"123","password":"123"}': ['']}>
if username == 'chao' and pwd == '123':
ret_data['status'] = 1000 # 状态码
ret_data['msg'] = '登录成功'
ret_data_json=json.dumps(ret_data,ensure_ascii=False)
#对中文默认使用的ascii编码.想输出真正的中文需要指定ensure_ascii=False:
return HttpResponse(ret_data_json)#返回一个字典需要json进行处理 不然会把键相加进行传递
else:
ret_data['status'] = 1001 # 状态码
ret_data['msg'] = '登录失败'#相当于暴力添加字典的值
ret_data_json=json.dumps(ret_data,ensure_ascii=False)
#对中文默认使用的ascii编码.想输出真正的中文需要指定ensure_ascii=False:
return HttpResponse(ret_data)#返回一个字典需要json进行处理 不然会把键相加进行传递
第二种写法
ret_data = json.dumps(ret_data,ensure_ascii=False)#也需要反序列化
return HttpResponse(ret_data'application/json')
#传入前端一个字典自动json反序列化
```
### 后端
## jsonreponse
```python
ret_data = ['aa',22,'哈哈']
ret_data=['name':33,333]
return JsonResponse(ret_data,safe=false)#json认为不合法
#非字典类型数据需要给JsonResponse加上safe=false参数 才能发送成功
```
# django请求生命周期
浏览器上输入http://www.xxx.com 请求到 达django后发生了什么?
### 知识点
```python
wsgi协议web服务网关接口
1.wsgiref本地做测试用的请求来了只能处理一个请求不能并发
2.uwsgi linux和项目部署的时候使用
```
### 执行过程
```python
浏览器向服务器请求数据(b/s架构)
本质是一个socket通信
1.浏览器请求发送到服务端 wsgi把接收到的请求 转发给django
2.执行对应的process_request中间件方法
(也可以自定义中间件
如果自定义中间件的request方法 写了return 返回值除了none,
不会继续往下执行会直接执行对应的response方法
按照settings配置顺序倒序执行中间件
最后返回给浏览器 )
3.到达路由系统 进行路由匹配
4.到达视图进行业务处理 可以用orm从数据库中读取数据,调用模板进行渲染 渲染完成之后的字符串
5 经过中间件倒序执行process_response方法
6.最后通过wsgi 用send发送给客户端浏览器
```
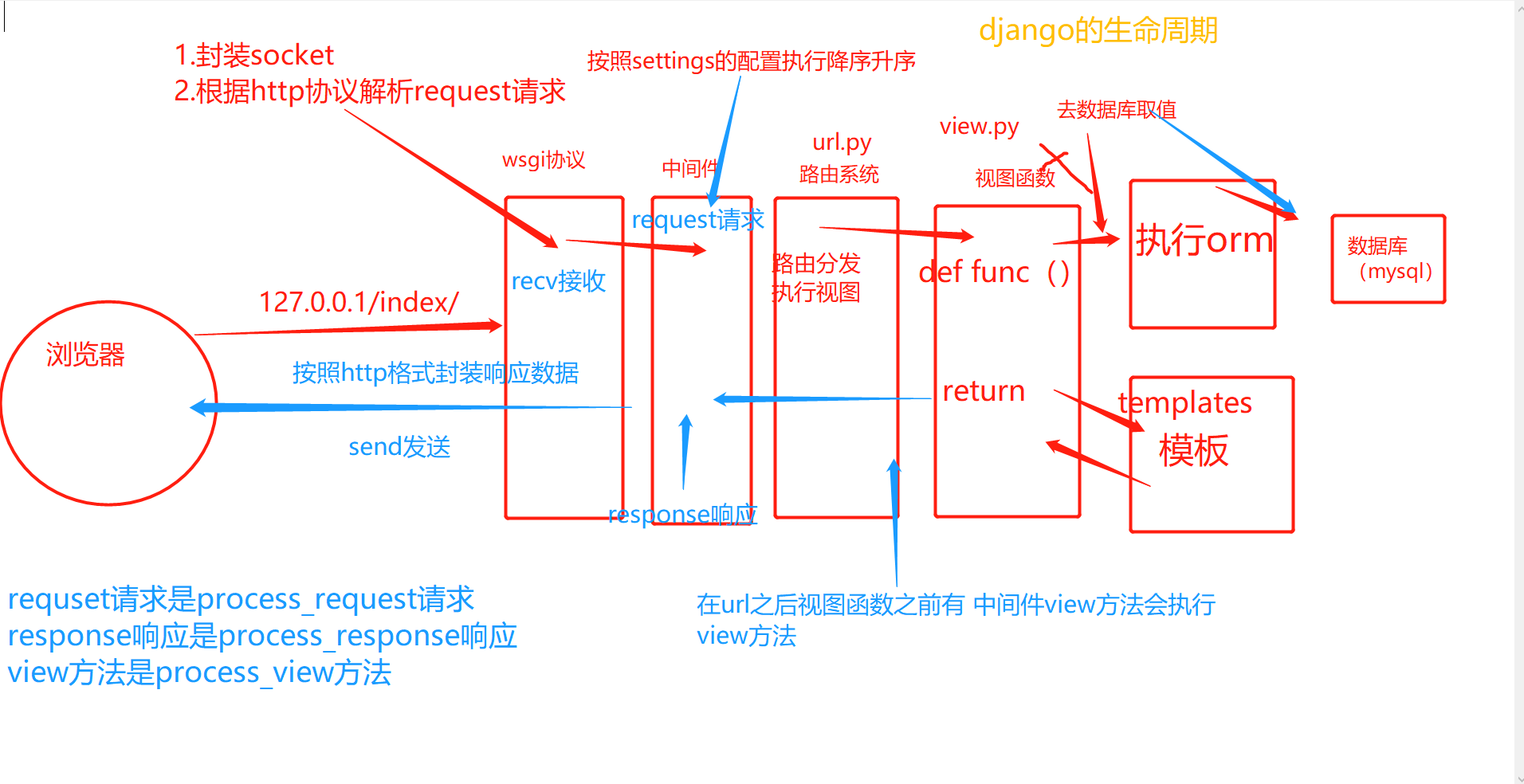
### 写法
```python
return render(request, "index.html", {"book": Book_obj})
#render进行模板渲染
1.把对应index.html页面读取出来
2.把用orm从数据库读取出来的数据 或者是查询出来的数据进行模板渲染
3.返回渲染过后的字符串(页面)发送给客户端浏览器
```
## 中间件Middleware
### Django中间件定义
```python
中间件顾名思义,是介于request与response处理之间的一道处理过程,相对比较轻量级,并且在全局上改变django的输入与输出。因为改变的是全局,所以需要谨慎实用,用不好会影响到性能。
```
### 官方定义
```python
Middleware is a framework of hooks into Django’s request/response processing. <br>It’s a light, low-level “plugin” system for globally altering Django’s input or output.
```
### 中间件的作用
```python
为了防止多次装饰器的使用(其中一点)
视图函数在执行之前会先执行中间件 在进行路由分发
作用于全局
```
### 中间件的配置
```python
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
'app01.middlewares.mymiddleware.LoginAuth',#需要去配置执行
'app01.middlewares.mymiddleware.MD1',
'app01.middlewares.mymiddleware.MD2',
]
#配置执行顺序
1.必须要进行配置 要不无法进行中间件的使用
2..正常从上至下依次执行
```
### 中间件的创建
```python
在对应项目中也就是app01
创建一个包,随便文件夹起名字,
一般都放在一个叫做utils的包里面,表示一个公用的组件,
在文件夹种创建一个py文件,随便起名字,例如叫做:middlewares.py
格式例如
app01项目文件夹下
--middlewares中间件文件夹
----middlewares.py
```
### 自定义中间件
```python
from django.utils.deprecation import MiddlewareMixin#必须要引用模块
class MD1(MiddlewareMixin):#必须要继承MiddlewareMixin类
#自定义中间件,
def process_request(self, request):#处理请求 如果没有写 会一层层网上找 对应的request方法
print("MD1里面的 process_request")
def process_response(self, request, response):#处理响应 如果没有写 会
print("MD1里面的 process_response")
return response
def process_view(self, request, view_func, view_args, view_kwargs):
#注意
处理请求request return none 和不写return效果一样
如果写了将中断视图函数执行 直接执行当前 中间的件 的response方法原路返回
```
### 5大方法
### 常用四大方法
```python
#常见四大方法
process_request(self,request)#处理请求数据
process_view(self, request, view_func, view_args, view_kwargs)#处理视图
process_exception(self, request, exception)#处理视图函数错误 没有出错不执行 倒序执行
process_response(self, request, response)#响应倒序执行
#第五种不常用
process_template_response(self,request,response)#用的比较少
```
### 五种方法
### process_request(self,request)
##### 介绍过程介绍
```python
def process_request(self, request):
#process_request方法里面不写返回值,默认也是返回None,如果你自己写了return None,也是一样的效果,不会中断你的请求
#不用写返回值写了返回值会截断
#写了除了 return none return其他会直接执行倒序执行对应response方法
```

### process_view(self, request, view_func, view_args, view_kwargs)
**写法**
```python
process_view(self,request,view_func, view_args, view_kwargs):
print(view_func, view_func.__name__)#就是url映射(匹配)到的那个视图函数,也就是说每个中间件的这个process_view已经提前拿到了要执行的那个视图函数 打印
ret = view_func(request) #提前执行视图函数,(不用到了上图的试图函数的位置再执行,如果你视图函数有参数的话,可以这么写 )view_func(request,view_args,view_kwargs)
return ret #直接就在MD1中间件这里这个类的process_response给返回了,就不会去找到视图函数里面的这个函数去执行了。
该方法有四个参数
request是HttpRequest对象。
view_func是Django即将使用的视图函数也就是路由系统匹配成功的view视图函数。 (它是实际的函数对象,而不是函数的名称作为字符串。)
view_args是将传递给视图的位置参数的列表.
view_kwargs是将传递给视图的关键字参数的字典。 view_args和view_kwargs都不包含第一个视图参数(request)。
Django会在调用视图函数之前调用process_view方法。
它应该返回None或一个HttpResponse对象。
#返回值
1.如果返回None,Django将继续处理这个请求,执行任何其他中间件的process_view方法,然后在执行相应的视图。
1.如果它返回一个HttpResponse对象,Django不会调用对应的视图函数。 它将执行中间件的process_response方法并将应用到该HttpResponse并返回结果。
```

### process_exception(self, request, exception)
```python
process_exception(self, request, exception)
该方法两个参数:
一个HttpRequest对象
一个exception是视图函数异常产生的Exception对象。
这个方法只有在视图函数中出现异常了才执行,它返回的值可以是一个None也可以是一个HttpResponse对象。
如果是HttpResponse对象,Django将调用模板和中间件中的process_response方法,并返回给浏览器,否则将默认处理异常。如果返回一个None,则交给下一个中间件的process_exception方法来处理异常。
#它的执行顺序也是按照中间件注册顺序的倒序执行。
```
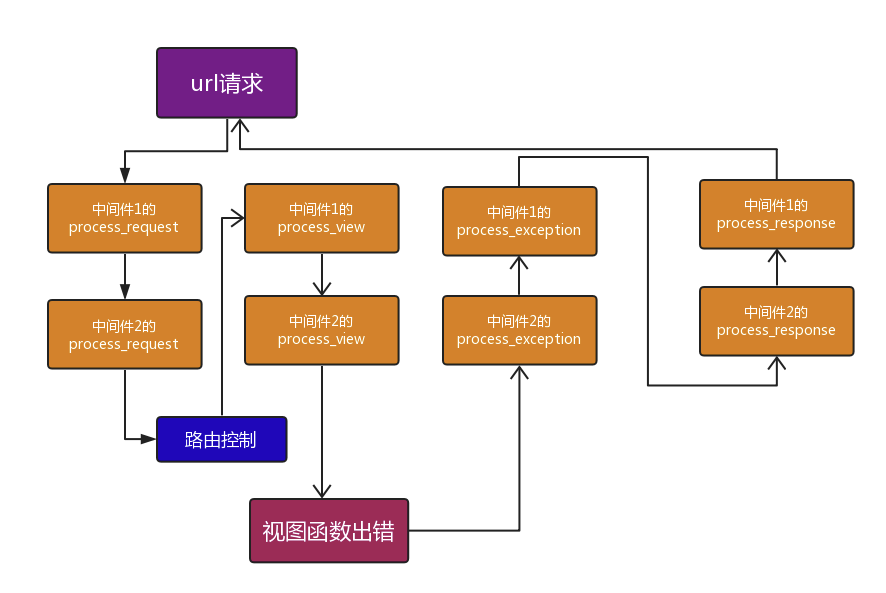
### process_response(self, request, response)
```python
def process_response(self,request,response):
response.content#查看返回内容
return response#必须写返回值
```
#### 多个中间件执行顺序

### 中间件之cookie认证
```python
from django.utils.deprecation import MiddlewareMixin#引用一个混合类
from django.shortcuts import HttpResponse,redirect
class LoginAuth(MiddlewareMixin):#必须要继承MiddlewareMixin
write_list = [reverse('login'),reverse('register')]#写一个路径
def process_request(self,request):
print('process')
path=request.path
if path not in self.write_list:#通过对象取值判断是否在这个列表里 类似白名单的东西
status=request.session.get('is_login')
if not status:
return redirect('/login/')
def process_response(self,request,response):
def process_response(self, request, response):
print(response.content) # 查看内容
return response # 必须写返回值
view.py写法
from django.shortcuts import render,redirect,HttpResponse
def login(request):
if request.method == 'GET':
print('这是login函数')
return render(request,'index.html')
else:
username = request.POST.get('username')
pwd = request.POST.get('password')
if username == 'chao' and pwd == '123':
request.session['is_login'] = True
return redirect('/home/')
else:
return redirect('/login/')
def home(request):
print('这是home函数')
return HttpResponse('home')
login.html
```
# cookie
```python
1.是保存在用户浏览器上的键值对,向服务端发送请求时会自动携带
浏览器访问服务端,带着一个空的cookie,然后由服务器产生内容(set_cookie), 浏览器收到相应后保存在本地;当浏览器再次访问时,浏览器会自动带上Cookie,这样 服务器就能通过Cookie的内容来判断这个是“谁”了。
2.cookie可以通过 浏览器进行cookie删除
max_age=None 多少秒之后自动失效
expires=None固定的时间#也是设置超时时间
path="/"
domain 可以设置指定域名
http=true 就可以设置cookie 能不能修改
https://www.cnblogs.com/wupeiqi/articles/11647089.html
3.加盐
cookie的设置
ret = reditect('index) / HttpResponse / render
不加盐的: ret.set_cookie(key,value)
加盐的: ret.set_signed_cookie(key,value,'盐')
cookie的获取
不加盐的: request.COOKIES.get() / 也可以当作字典取值 COOKIES['key']
加盐的: request.get_signed_cookie('key',salt='加密盐',default='获取不到显示的异常',max_age=None,有效时间(秒))
```
## cookie的使用
```python
1.获取cookie
request.COOKIES['KEY']//通过设置的键取值
2.设置cookie
设置路径
ret=redirect(/路径/)
ret.set_cookie('key',value,max_age)//最大过期时间
#删除cookie
ret.delete_cookie('键')
```
### 通过js设置cookie
```js
document.cookie="k1=wy222;path=/"#js写法
1.获取cookie
request.COOKIES['KEY']//通过设置的键取值
2.设置cookie
设置路径
ret=redirect(/路径/)
ret.set_cookie('key',value,max_age)//最大过期时间
#删除cookie
ret.delete_cookie('键')
#jquery写法
$.cookie("k1","wy222",{path:'/'})
1.添加
$.cookie('the_cookie', 'the_value');#添加一个cookie
2.创建一个cookie并设置有效时间为 7天
$.cookie('the_cookie', 'the_value', { expires: 7 });
这里指明了cookie有效时间,所创建的cookie被称为“持久 cookie (persistent cookie)”。注意单位是:天;
3.创建一个cookie并设置 cookie的有效路径
$.cookie('the_cookie', 'the_value', { expires: 7, path: '/' });
在默认情况下,只有设置 cookie的网页才能读取该 cookie。如果想让一个页面读取另一个页面设置的cookie,必须设置cookie的路径。cookie的路径用于设置能够读取 cookie的顶级目录。将这个路径设置为网站的根目录,可以让所有网页都能互相读取 cookie (一般不要这样设置,防止出现冲突)。
4.读取cookie
$.cookie('the_cookie');
5.删除cookie
$.cookie('the_cookie', null); //通过传递null作为cookie的值即可
6.可选参数
$.cookie('the_cookie','the_value',{
expires:7,
path:'/',
domain:'jquery.com',
secure:true
})
参数
expires:(Number|Date)有效期;设置一个整数时,单位是天;也可以设置一个日期对象作为Cookie的过期日期;
path:(String)创建该Cookie的页面路径;
domain:(String)创建该Cookie的页面域名;
secure:(Booblean)如果设为true,那么此Cookie的传输会要求一个安全协议,例如:HTTPS;
```
### path的作用
```python
path默认所有域名"/"
'/'是所有路径都能获得cookie
浏览器只会把cookie回传给带有该路径的页面,这样可以避免将
cookie传给站点中的其他的应用。
1./ 根目录当前网站的所有的url都能读取到此值
2.""只能在当前页面访问的到此数据
3./index/,只能在/index/xxx的网页中查看
后台默认在根目录也就是path=’/’
cookie修改需要指定根目录 "decument.cookie=121313 path= /"
不写默认path为""
```
不安全 可以使用浏览器进行修改可以获取到敏感数据
修改浏览器的cookie值
```python
cookie修改需要指定根目录
decument.cookie="121313 path= /"
$.cookie("k1","wy222",{path:'/'})
```
## 简单博客登陆
## 检查数据的库的密码是否正确
```python
view.py写法
def login(requset):
if requset.method=='GET':
return render(requset,'login.html',{'age':18})
# 获取用户提交的用户名和密码
user = request.POST.get('user')#获取键对应的值
pwd = request.POST.get('pwd')#获取键对应的值
#判断用户名和密码
user_object=models.UserInfo.objects.filter(username=user,password=pwd).first()
if user_object:
# 用户登录成功
result = redirect('/index/')
#在写入一个cookie
result.set_cookie('xxxxxxxx',user)
return result
# 用户名或密码输入错误
return render(request,'login.html',{'error':'用户名或密码错误'})
def index(request):
"""
博客后台首页
:param request:
:return:
"""
#拿到存到浏览器的cookie
user = request.COOKIES.get('xxxxxxxx')
if not user:#如果没有获得
return redirect('/login/')#返回页面
return render(request,'index.html',{'user':user})
```
**为防止通过url直接访问页面 使用cookie进行判断**
## 应用场景
- 投票
- 每页默认显示数据
- 登陆认证
避免把敏感数据存储在浏览器使用到了session
# session
### 依赖cookie
```python
是一种存储数据的方式,依赖于cookie,实现本质:
用户(浏览器(向服务端发送请求,服务端做两件事:
1.设置session值的时候生成随机字符串;
2.为此用户开辟一个独立的空间来存放当前用户独有的值(数据) django存放在数据库中
3.把生成的随机字符串作为值 sessionid作为键,发送给浏览器.
服务端回应
3.当浏览再次访问服务端的时候,会去寻找存放django_session表匹配随机字符串进行解密
4.取出用户存储的数据
```
## 在空间中如何想要设置值:
```python
request.session['x1'] = 123
request.session['x2'] = 456
request.session['x2']如果不存在会报错keyerror错误#在空间中取值:
request.session.get('x2')
#视图函数中的业务操作处理完毕,给用户响应,在响应时会 将随机字符串存储到用户浏览器的cookie中
session的删除
del request.session['k1'] django-session表里面同步删除
request.session.delete() 删除当前会话的所有Session数据
request.session.flush()
删除当前的会话数据并删除会话的Cookie。
```
### session**中的数据是根据用户相互隔离每个都是独立的**
```python
session中的数据是根据用户相互隔离.
示例
def login(request): # 获取用户提交的用户名和密码
user = request.POST.get('user') request.session['user_name'] = user
def index(request): print(request.session['user_name'])
```
## 应用场景
- 可以权限判断 放置权限
- 短信验证过期
- 登陆认证
## session和cookie的区别
```python
cookie是存储在客户端浏览器上的键值对,发送请求时浏览器会自动携带
session是一种存储数据方式 依赖cookie基于cookie实现,将数据存储在服务端 (django默认)
```
## 扩展 修改session默认存储位置
- ```python
- (默认在数据库)
- 小系统:默认放在数据库即可. 大系统:缓存(redis)
```
-
- #### 文件
- ```python
SESSION_ENGINE = 'django.contrib.sessions.backends.file' #引擎把session放入文件中
SESSION_FILE_PATH = '/ssss/' #在根目录的/ssss生成一个随机文件
```
- #### 缓存(内存)
- ```python
SESSION_ENGINE = 'django.contrib.sessions.backends.cache' SESSION_CACHE_ALIAS = 'default'
CACHES = {
'default': {
'BACKEND':'django.core.cache.backends.locmem.LocMem Cache',
'LOCATION': 'unique-snowflake',
}
}
```
- ### 缓存(redis)
- ```python
SESSION_ENGINE = 'django.contrib.sessions.backends.cache' SESSION_CACHE_ALIAS = 'default'
CACHES = {
"default": {
"BACKEND":"django_redis.cache.RedisCache", "LOCATION": "redis://127.0.0.1:6379", "OPTIONS": {
"CLIENT_CLASS":"django_redis.client.DefaultClient",
"CONNECTION_POOL_KWARGS": {
"max_connections": 100} # "PASSWORD": "密码", } }
}
```
-
## 简单博客登陆(session)
### 检查数据的库的密码是否正确
```python
from django.shortcuts import render,redirect
from app01 import models
def login(request):
"""
用户登录
:param request:
:return:
"""
if request.method == 'GET':
return render(request, 'login.html')
# 获取用户提交的用户名和密码
user = request.POST.get('user')
pwd = request.POST.get('pwd')
print(user,pwd)
# 去数据库检查用户名密码是否正确
user_object = models.UserInfo.objects.filter(username=user, password=pwd).first()
if user_object:
request.session['user_name']=user_object.username#名字存入session
request.session['user_id']=user_object.pk#id存入session
return redirect('/index/')#重定向页面
# 用户名或密码输入错误
return render(request,'login.html',{'error':'用户名或密码错误'})
def index(request):
"""
博客后台首页
:param request:
:return:
"""
name=request.session.get("user_name")
if not name:
return redirect('/login/')
return render(request,'index.html',{'user':name})
··············································
简化版为了减少登陆验证的重复#使用了装饰器
··············································
from django.shortcuts import render,redirect
from app01 import models
def login(request):
"""
用户登录
:param request:
:return:
"""
if request.method == 'GET':
return render(request, 'login.html')
# 获取用户提交的用户名和密码
user = request.POST.get('user')
pwd = request.POST.get('pwd')
print(user,pwd)
# 去数据库检查用户名密码是否正确
user_object = models.UserInfo.objects.filter(username=user, password=pwd).first()
if user_object:
request.session['user_name']=user_object.username#名字存入session
request.session['user_id']=user_object.pk#id存入session
return redirect('/index/')#重定向页面
# 用户名或密码输入错误
return render(request,'login.html',{'error':'用户名或密码错误'})
def auth(func):#防止多次判断 简化判断 装饰器
@functools.wraps(func)
def inner( request,*args,**kwargs):
name = request.session.get("user_name")#取得一个值 djano拿着这个值取对应的django的session表中按照 随机字符串为键 取得数据 进行解密 获取到对应的值
if not name:
return redirect('/login/')
return func(request,*args,**kwargs)
return inner
@auth
def index(request):
"""
博客后台首页
:param request:
:return:
"""
return render(request,'index.html')
```
## 后端操作session
```python
# 设置(添加&修改) request.session['x1'] = 123 request.session['x2'] = 456
# 读取
request.session['xx'] #读取不到会报key error错误
request.session.get('xx')#读取不到值返回none (不报错)
# 删除
del request.session['xx']
request.session.keys() #获取当前session的键
request.session.values() #获取当前session的值
request.session.items() #获取当前session的键值对
# 设置会话Session和Cookie的超时时间
request.session.set_expiry(value)
request.session.clear_expired(value)
* 如果value是个整数,session会在些秒数后失效。
* 如果value是个datatime或timedelta,session就会在这个时间后失效。
* 如果value是0,用户关闭浏览器session就会失效。
* 如果value是None,session会依赖全局session失效策略。
request.session.session_key 获取sessionid(随机字符串)的值
#删除cookie
第一种写法 del request.session["k1"]
第二种写法 request.session.flush()
def logout(request):
rep = redirect("/login/")
rep.delete_cookie("user") # 删除用户浏览器上之前设置的usercookie值
return rep
```
### 扩展 django和session相关的配置
```python
SESSION_COOKIE_NAME = "sessionid" # Session的cookie保存在浏览器上时的key可以修改,即: sessionid=随机字符串
SESSION_COOKIE_DOMAIN = None #session的cookie保存的域名(都可以在那个域名,子域名下可用 所有的域名都可用读取到)
# api.baidu.com /www.baidu.com/ xxx.baidu.com
SESSION_COOKIE_PATH = "/" # Session的cookie 保存的路径
SESSION_COOKIE_HTTPONLY = True # 是否 Session的cookie只支持http传输 只能读不能修改
SESSION_COOKIE_AGE = 1209600 # Session的 cookie失效日期(2周)
SESSION_EXPIRE_AT_BROWSER_CLOSE = False # 是否关闭浏览器使得Session过期
SESSION_SAVE_EVERY_REQUEST = False # 是否每 次请求都保存Session,默认修改之后才保存
request会刷新 ture 按照最后一次刷新时间 false 会在两周之后过期
```
### django中的session如何设置过期时间?
```python
SESSION_COOKIE_AGE = 1209600 # Session的 cookie失效日期(2周)
```
# form组件
```python
form组件和models创建的数据库表是分开的校验的
models是限制存入数据库的字段值的限制 form是提交数据的限制
运行顺序是 form组件校验完之后 把对应的数据存入数据库中
1.组件可以进行字段校验
2.组件不仅可以校验form对象生成的属性 form表单和ajax提交到后台的数据都可以进行校验
#get请求和post请求的的对象名要一致
#错误了也需要把post返回的数据返回对应的页面 (页面渲染)
form_obj=RegForm(data=request.POST)
if form_obj.is_valid():进行判断
3.对传入的数据进行处理校验 错误了返回错误信息和接收到的数据
4.校验正确存入数据库
```
### 总结一下,其实form组件的主要功能如下:
```python
1.前端页面是form类的对象生成的 -->生成HTML标签功能
2.当用户名和密码输入为空或输错之后 页面都会提示 -->用户提交校验功能
3.当用户输错之后 再次输入 上次的内容还保留在input框 -->保留上次输入内容
#主要用于校验
开辟
全局错误是所有字段的错误和
每一个字段的错误 空间
每一个字段的错误 会在当前显示
settings配置ch-ZN 就直接是中文
```
#### form配置:
```python
from django.core.exceptions import ValidationError # NOQA
from django.forms.boundfield import * # NOQA
from django.forms.fields import * # NOQA
from django.forms.forms import * # NOQA
from django.forms.formsets import * # NOQA
from django.forms.models import * # NOQA
from django.forms.widgets import * # NOQA 插件
```
## 必会知识点
```python
from django import forms#引用form组件
1.浏览器默认设置 requierd 字段 必须不能为空
2.widget='forms.属性'# 用于改变属性值 插件
2.widget=forms.PasswordInput(attrs='属性名':'属性值')设置 一个值
示例
widget=widgets.TextInput(attrs={'type':'date'})常见的
3.form组件 fileld字段是对后端的格式校验 ()
lable='显示字段'
4.插件
widget
passwordinput#插件
5.字段
IntegerField 整型
render_value=True 显示密码
6.Model是与数据库交互
class RegForm(forms.Form):#authors是字段名
authors = forms.ModelMultipleChoiceField(queryset=models.NNewType.objects.all())
7.如何取得
```
```python
常用CharFiled进行插件字段转换
默认是textInput
可以设置对应attrs属性
passwordinput
··············
ChoiceField进行插件(title)字段转换
···········
1.单选Select
2.多选Select
3.单选checkbox
4.多选checkbox
从数据库获取
ModelMultipleChoiceField(queryset=筛选值)多选从数据库获取数据
示例
from django import forms
class FInfo(forms.Form):
authors =form_db.ModelChoiceField(queryset=models.App01Author.objects.all())
def login(request):
PPT=FInfo()#实例化把响应的对象传入进去
return render(request,'login.html',{'foot':PPT})
```
### 实例化对象的属性
```python
form_obj=RegForm()#form_obj对应的form组件类实例化的对象
form_obj.fields 查询本类的所有字段
form_obj对应的所有字段生成的标签(也就是html页面)
```
### 页面显示的步骤
```python
1.views.py中导入forms模块:from django import froms
2.定义继承自forms.Form的类,类中定义字段(和models中的写法相同)
class auth(forms.Form)
字段名=forms.CharField
3.视图函数中创建该类的对象
4.如果是get请求,向页面中渲染form对象对应的标签。
post会把前端对应的值传入form_obj=RegForm(data=request.POST)
request.POST是前端的返回值
```
保存输入状态
```python
a.原理: 利用Form组件可以生成标签
GET:
obj = TestForm()
{{ obj.t1 }} 等效成 <input type="text" name="t1">
POST:
obj = TestForm(request.POST)
{{ obj.t1}} 等效成<input type="text" name="t1" value = "你提交的数据">
总之, 前端:{{ obj.t1 }}或者 {{obj.as_p}}
视图:无论get还是Post都将obj传给前端
```
#### 实例
```python
b.实例
# FormL类
class TestForm(Form):
t1 = fields.CharField(
required=True,
min_length=4,
max_length=8,
widget=widgets.TextInput,
label='用户名',
label_suffix=':',
help_text='4-8个字符',
initial='root'
)
t2 = fields.CharField(
required=True,
min_length=8,
widget=widgets.PasswordInput,
label='密码',
label_suffix=':',
initial='password'
)
#视图
def test(request):
if request.method == 'GET':
obj = TestForm()
return render(request, 'app02_test.html', {'obj': obj})
else:
obj = TestForm(request.POST)
if obj.is_valid():
# 数据库添加数据
return redirect("/app02_index.html")
else:
return render(request, 'app02_test.html', {'obj': obj})
# 前端
<form action="/app02/test" method="POST" novalidate>
{% csrf_token %}
{{ obj.as_p }}
<p><input type="submit" value="提交"></p>
</form>
补充
有些浏览器会对Input首先做了验证,所以要 先对form表单剔除掉浏览器的验证
<form novalidate>
```
### 写法
#### 单个form组件的写法
```python
class MyForm(forms.Form):
name = forms.Charfield(
required=True,
max_length=16,
min_length=8,
label='书名',
initial='xx',
error_messages={
'required':'不能为空',
'min_length':'不能太短',
}
widget=forms.PasswordInput(attrs={'class':'c1',type:'password'})
)
```
#### 视图view.py
```python
from django import forms
class RegForm(forms.Form):
name=forms.CharField(
label='用户名',
min_length=8,
initial='张三',#设置默认值
widget=forms.TextInput,
requierd=Flase,#可以设置默认可以为空
)
pwd=forms.CharField(label='密码',widget=forms.TextInput)
gender=forms.ChoiceField(choices=((1,'男'),(2,'女'),(3,'alex')))
gender1=forms.MultipleChoiceField(choices=((1,'男'),(2,'女'),(3,'alex'),),label=333)
def login(request):
form_obj=RegForm()
if request.method=='POST':
print(1)
# 实例化form对象的时候,把post提交过来的数据直接传进去
form_obj=RegForm(data=request.POST)#传过来的input标签的name属性值和form类对应的字段名是一样的,所以接收之后,form就取出对应的form字段名相同的数据进行form校验
#data就是实例化对象传的值
#form_obj=RegForm(data=reuest.POST)#实例化一个对象并传入data=数据
#因为位置参数第一个就是data所以不用写data=
#简写
#form_obj=RegForm(reuest.POST)
if form_obj.is_valid():#进行校验
print(form_obj.cleaned_data)#form_obj.clean_data 打印成功信息 打印校验正确的信息
return HttpResponse('注册成功')
else:
print(form.errors)#打印错误信息
```
#### 前端
```python
{{ form_obj.as_p }} # 展示所有的字段 p标签进行包裹
{{ form_obj.user }} # input框对应字段生成的属性
{{ form_obj.user.label }} # label标签的中文提示
{{ form_obj.user.id_for_label }} # input框的id和input标签进行绑定
{{ form_obj.user.errors }} # 一个字段的所有错误信息 显示一个列表
{{ form_obj.user.errors.0 }} # 一个字段的第一个错误信息 正常没有错误信息
{{ form_obj.errors }} # 所有字段的错误
浏览器默认 requierd 字段 必须不能为空 需要用novalidate
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>注册2</title>
</head>
<body>
<form action="/reg2/" method="post" novalidate autocomplete="off"> #novalidate 告诉前端form表单,不要对输入的内容做校验autocomplete="off"禁用填充
{% csrf_token %}
#{{ form_obj.as_p }} 直接写个这个,下面的用户名和密码的标签不自己写,你看看效果
#用p标签 包裹 创建字段
<div>
<label for="{{ form_obj.name.id_for_label }}">{{ form_obj.name.label }}</label>
{{ form_obj.name }} {{ form_obj.name.errors.0 }} #errors是这个当前字段所有的错误,我就用其中一个错误提示就可以了,再错了再提示,并且不是给你生成ul标签了,单纯的是错误文本
{{ form_obj.errors }} #这是全局的所有错误,找对应字段的错误,就要form_obj.字段名
</div>
<div>
<label for="{{ form_obj.pwd.id_for_label }}">{{ form_obj.pwd.label }}</label>
{{ form_obj.pwd }} {{ form_obj.pwd.errors.0 }}
</div>
<div>
<input type="submit" class="btn btn-success" value="注册">
</div>
</form>
</body>
</html>
```
## 常用form字段属性
### **error_messages**
重写错误信息
```python
class LoginForm(forms.Form):
username = forms.CharField(
min_length=8,
label="用户名",
initial="张三",
error_messages={
"required": "不能为空",
"invalid": "格式错误",
"min_length": "用户名最短8位"
}
)
pwd = forms.CharField(min_length=6, label="密码")
```
### **password和email**
```python
class LoginForm(forms.Form):
...
pwd = forms.CharField(
min_length=6,
label="密码",
widget=forms.widgets.PasswordInput(attrs={'class': 'c1'}, render_value=True) #这个密码字段和其他字段不一样,默认在前端输入数据错误的时候,点击提交之后,默认是不保存的原来数据的,但是可以通过这个render_value=True让这个字段在前端保留用户输入的数据
)
email = forms.EmailField(
min_length=6,
label="密码",
widget=forms.widgets.EmailInput(attrs={'class': 'c1'}, render_value=True)
error_messages={'invalid':'邮箱格式错误'}
```
### **initial**
```python
class LoginForm(forms.Form):
username = forms.CharField(
min_length=8,
label="用户名",
initial="张三" # 设置默认值
)
pwd = forms.CharField(min_length=6, label="密码",
widget=forms.widgets.PasswordInput(
render_value=True
)
)
pwd = forms.CharField(min_length=6, label="密码",
widget=forms.widgets.PasswordInput(
render_value=True
)
)
gender = forms.fields.ChoiceField(#radioselect
choices=((1, "男"), (2, "女"), (3, "保密")),
label="性别",
initial=3,
widget=forms.widgets.RadioSelect()
)
class LoginForm(forms.Form):
...
hobby = forms.fields.MultipleChoiceField(
choices=((1, "篮球"), (2, "足球"), (3, "双色球"),),
label="爱好",
initial=[1, 3],
widget=forms.widgets.CheckboxSelectMultiple()
#CheckboxSelectMultiple多选checkbox
)
```
### **radioselect**
```python
class LoginForm(forms.Form):
username = forms.CharField( #其他选择框或者输入框,基本都是在这个CharField的基础上通过插件来搞的
min_length=8,
label="用户名",
initial="张三",
error_messages={
"required": "不能为空",
"invalid": "格式错误",
"min_length": "用户名最短8位"
}
)
pwd = forms.CharField(min_length=6, label="密码")
gender = forms.fields.ChoiceField(#radioselect
choices=((1, "男"), (2, "女"), (3, "保密")),
label="性别",
initial=3,
widget=forms.widgets.RadioSelect()
)
```
## input字段与数据库进行交互
```python
from django import forms
from app01 import models
from django.shortcuts import render
class AddBookForm(forms.Form):
title=forms.CharField(
initial=models.Book.objects.all().first()
)
def editor1(request):
return render(request,'editor2.html',{'book_model_obj':PP})
```
## choice字段**
```python
class LoginForm(forms.Form):
...
hobby = forms.fields.ChoiceField( #注意,单选框用的是ChoiceField,并且里面的插件是Select,不然验证的时候会报错, Select a valid choice的错误。
choices=((1, "篮球"), (2, "足球"), (3, "双色球"), ),
label="爱好",
initial=3,
widget=forms.widgets.Select()
)
```
### 单选checkbox
```python
#单选的checkbox
class TestForm2(forms.Form):
keep = forms.ChoiceField(
choices=(
('True',1),
('False',0),
),
label="是否7天内自动登录",
initial="1",
widget=forms.widgets.CheckboxInput(),
)
选中:'True' #form只是帮我们做校验,校验选择内容的时候,就是看在没在我们的choices里面,里面有这个值,表示合法,没有就不合法
没选中:'False'
---保存到数据库里面 keep:'True'
if keep == 'True':
session 设置有效期7天
else:
pass
```
### **多选checkbox**
```python
class LoginForm(forms.Form):
...
hobby = forms.fields.MultipleChoiceField(
choices=((1, "篮球"), (2, "足球"), (3, "双色球"),),
label="爱好",
initial=[1, 3],
widget=forms.widgets.CheckboxSelectMultiple()
#CheckboxSelectMultiple多选checkbox
)
```
### choice字段注意事项
多选择框和单选框 值直接写就固定死了 需要与数据库进行关联
### 方式一
```python
from django.forms import Form
from django.forms import widgets
from django.forms import fields
class MyForm(Form):#Form类
user = fields.ChoiceField(
# choices=((1, '上海'), (2, '北京'),),
initial=2,
widget=widgets.Select
)
对象在运行之前的三件事 拓展init的方法 批量添加样式
def __init__(self, *args, **kwargs):
super(MyForm,self).__init__(*args, **kwargs) #注意重写init方法的时候,执行myFORM父类的方法 默认可以不写
#*args和**kwargs一定要给人家写上,不然会出问题,并且验证总是不能通过,还不显示报错信息
# self.fields['user'].choices = ((1, '上海'), (2, '北京'),)
# 或self是类的实例化对象
self.fields['user'].choices = models.Classes.objects.all().values_list('id','caption')
```
### 方式二
```python
#ModelMultipleChoiceField 与数据库交互
from django import forms
from django.forms import fields
from app01 import models
from django.forms import models as form_model
class FInfo(forms.Form):
authors = forms.ModelMultipleChoiceField(queryset=models.NNewType.objects.all())
# 多选
#或者下面这种方式,通过forms里面的models中提供的方法也是一样的。
authors = form_model.ModelMultipleChoiceField(queryset=models.NNewType.objects.all())
# 单选
#或者,forms.ModelChoiceField(queryset=models.Publisth.objects.all(),widget=forms.widgets.Select()) 单选
authors = forms.ModelMultipleChoiceField(
queryset=models.Author.objects.all(),
widget = forms.widgets.Select(attrs={'class': 'form-control'}
))
#如果用这种方式,别忘了model表中,NNEWType的__str__方法要写上,不然选择框里面是一个个的object对象
```
### date类型**
```python
from django import forms
from django.forms import widgets
class BookForm(forms.Form):
date = forms.DateField(widget=widgets.TextInput(attrs={'type':'date'}))
#必须attr添加指定type,不然不能渲染成选择时间的input框
```
### 字段参数
```python
initial 初始值
label 中文显示
error_messages 错误提示
min_length 最小长度
widget 插件
下拉框
choices 可选择的值
charfiled
#示例
choices=((1, "篮球"), (2, "足球"), (3, "双色球"),)
```
## **四 字段校验**
```python
正确数据clean_data不包含csrf数据
因为检验值针对对应字段
属性封装的校验不够用使用校验器
```
### 正则校验器
### 写法
```python
校验信息
from django.core.validators import RegexValidator 引用一个模块
validators=[RegexValidator(r'正则格式','错误信息'),RegexValidator(r'正则格式','错误信息')#(第二个正则匹配)]
validators=[RegexValidator(r'^[0-9]+$', '请输入数字'), RegexValidator(r'^159[0-9]+$', '数字必须以159开头')],
```
### 示例
```python
from django.forms import Form
from django.forms import widgets
from django.forms import fields
from django.core.validators import RegexValidator #正则错误
class MyForm(Form):
user = fields.CharField(
validators=[RegexValidator(r'^[0-9]+$', '请输入数字'), RegexValidator(r'^159[0-9]+$', '数字必须以159开头')],
)
```
### 简单的自定义校验器
```python
from django.core.exceptions import ValidationError#自定义 校验器 异常
def check_user(value):
# 通过校验器的校验 不做任何操作
# 不通过校验器的校验 抛出ValidationError异常
if 'alex' in value:
raise ValidationError('alex 不配!! ')
validators=[check_user]
```
### 自定义正则校验器
```python
validators=[校验器函数名, ]#使用校验器规则
validators=[mobile_validate]会把当前字段键值对传给 自定义函数
标签对应的value值
import re
from django.forms import Form
from django.forms import widgets
from django.forms import fields
import re
from django.core.exceptions import ValidationError# 错误信息
re.compile 创建匹配规则
# 自定义验证规则
def mobile_validate(value):
#把规则赋值给了变量mobile_re
mobile_re = re.compile(r'^(13[0-9]|15[012356789]|17[678]|18[0-9]|14[57])[0-9]{8}$')
if not mobile_re.match(value):#如果没有返回none
raise ValidationError('手机号码格式错误')
#自定义验证规则的时候,如果不符合你的规则,需要自己发起错误
class PublishForm(Form):
title = fields.CharField(max_length=20,
min_length=5,
error_messages={'required': '标题不能为空',
'min_length': '标题最少为5个字符',
'max_length': '标题最多为20个字符'},
widget=widgets.TextInput(attrs={'class': "form-control",
'placeholder': '标题5-20个字符'}),)
# 使用自定义验证规则
phone = fields.CharField(validators=[mobile_validate, ]#使用自定义验证规则,
error_messages={'required': '手机不能为空'},
widget=widgets.TextInput(
attrs={
'class': "form-control", 'placeholder': u'手机号码'}))
email = fields.EmailField(required=False,
error_messages={'required': u'邮箱不能为空','invalid': u'邮箱格式错误'},
widget=widgets.TextInput(attrs={'class': "form-control", 'placeholder': u'邮箱'}))
```
### 内置校验器
### 知识点
```python
from django.core.validators
#django默认封装了很多内置装饰器 import 直接引用
```
### 示例
```python
from django.core.validators import validate_email, RegexValidator
phone = forms.CharField(validators=[RegexValidator(r'^1[3-9]\d{9}$', '手机号格式不正确')])
#正则校验器
```
## modelform
form和modelform的区别
```python
不同点
1.modelform属于form的升级版
2.form在提交保存的时候需要取值修改 增加
2.1model有一个的方法可以直接进行 对象.save保存到数据库中
3.modelform和数据库有关
form和数据库是分开的 form可以只用于校验
相同点
1.modelform和form都会通过is_vield 进行校验
2.都具有全局钩子,局部钩子
3.都可以自定义校验规则
```
如果不够用可以在meta上面
生成一个字段自定义校验
```python
instance=一个对象
#可以找到对应编辑那一行数据
可以通过modelform和对应的model建立关系
1.
{{ form_obj.user.id_for_label }} # input框的id和input标签进行绑定**
1.和form使用一样 把form和数据库进行关联
2.错误信息获取一样
3.也是通过is_vield进行校验
缺点 封装的属性过少需要借用钩子
注意 因为是和对应的model数据库模型产生关联
需要引用一个模块
from app01 import models
对应的字段翻译成对应的字段属性
外键也可以进行关联寻找响应的对象
4校验完之后传入数据库中
自行数据库校验 剔除一下
```
### 写法
```python
from django import forms
from app01 import models
class bookform(form.ModelForm)
# 直接创建优先级比较高 用于书写自定义属性
# title = forms.CharField(
# label='书名2',
# )
class Meta:
model:models.book
fields='__all__'
labels={#创建lable属性
'字段名':'字符串'
}
}
widgets={#插件
widegets=forms.Textinput(attrs={'type',})
}
示例
labels={
'title':'署名'
}
widgets={#插件
'publishDate':forms.TextInput(attrs={'type':'date'}),
}
def clean_title(self):#定义的要和class mata平齐 局部钩子
# pass
def clean(self):#全局钩子
# pass
#批量添加类型
def __init__(self,*args,**kwargs):
super().__init__(*args,**kwargs)
for field_name,field in self.fields.items():
field.widget.attrs.update({'class':'form-control'})
def login(request):
form_obj=BookModelForm()
if request.method=='POST':
print(1)
也可以把ajax的错误 拿来使用
# 实例化form对象的时候,把post提交过来的数据直接传进去
form_obj=RegForm(data=request.POST)#传过来的input标签的name属性值和form类对应的字段名是一样的,所以接收之后,form就取出对应的form字段名相同的数据进行form校验
#request.POST可以直接自行取值 校验
#data就是实例化对象传的值
#form_obj=RegForm(data=reuest.POST)#实例化一个对象并传入data=数据
#因为位置参数第一个就是data所以不用写data=
#简写
#form_obj=RegForm(reuest.POST)
if form_obj.is_valid():#进行校验
print(form_obj.cleaned_data)#form_obj.clean_data 打印成功信息 打印校验正确的信息
return HttpResponse('注册成功')
else:
print(form.errors)#打印错误信息
return render(request,'login.html',{'bookform':bookform})
```
#### 添加编辑.py写法
```python
def addcustomer(request):
if request.method == 'GET':
book_form_obj = myforms.CustomerModelForm()
return render(request,'customer/addcustomer.html',{'book_form_obj':book_form_obj})
else:
book_form_obj = myforms.CustomerModelForm(request.POST)
if book_form_obj.is_valid():
book_form_obj.save()
return redirect('customers')
else:
return render(request, 'customer/addcustomer.html', {'book_form_obj': book_form_obj})
def editcustomer(request,n):
old_obj = models.Customer.objects.filter(pk=n).first()
if request.method == 'GET':
book_form_obj = myforms.CustomerModelForm(instance=old_obj)
return render(request, 'customer/editcustomer.html', {'book_form_obj': book_form_obj})
else:
book_form_obj = myforms.CustomerModelForm(request.POST,instance=old_obj)
if book_form_obj.is_valid():
book_form_obj.save()
return redirect('customers')
else:
return render(request, 'customer/editcustomer.html', {'book_form_obj': book_form_obj})
```
### 批量添加
```python
from sales import models
from django import forms
class CustomerModelForm(forms.ModelForm):
class Meta:
model = models.Customer
fields = '__all__'
exclude=['字段名']
#排除
def __init__(self,*args,**kwargs):
super().__init__(*args,**kwargs)
for field_name,field in self.fields.items():
print(type(field))
from multiselectfield.forms.fields import MultiSelectFormField
if not isinstance(field,MultiSelectFormField):
field.widget.attrs.update({'class':'form-control'})
```
### 联合写法
**编辑和添加一起写**
```python
def addEditCustomer(request,n=None):
old_obj = models.Customer.objects.filter(pk=n).first()
label = '编辑页面' if n else '添加页面'
if request.method == 'GET':
book_form_obj = myforms.CustomerModelForm(instance=old_obj)
return render(request, 'customer/editcustomer.html', {'book_form_obj': book_form_obj,'label':label})
else:
book_form_obj = myforms.CustomerModelForm(request.POST,instance=old_obj)
if book_form_obj.is_valid():
book_form_obj.save()
return redirect('customers')
else:
return render(request, 'customer/editcustomer.html', {'book_form_obj': book_form_obj,'label':label})
```
### html页面
```html
<form action="" method="post">
{% csrf_token %}
{% for field in book_model_obj %}
<div class="form-group">
<label for="{{ field.id_for_label }}">{{ field.label }}</label>
{{ field }}
<span class="text-danger">{{ field.errors.0 }}</span>
</div>
{% endfor %}
```
## 局部钩子
可以获得上一个字段的值
**满足自定义或者内置条件规则之后校验规则**
validators=[mobile_validate, ]
按顺序执行
从上往下 局部钩子可以取得上一个字段的数据
字段属性校验完毕之后才会校验
```python
# 局部钩子 针对当前字段
django.core.exceptions import ValidationError
def clean_gender(self): 必须写这个名字
'''
源码
if hasattr(self, 'clean_%s' % name):
value = getattr(self, 'clean_%s' % name)()
源码里面的文件,
'''
self.cleaned_data 是一个字典 里面存储经过属性校验
value = self.cleaned_data.get('gender')#拿到对应的标签的值
# 局部钩子 针对当前字段
# 不通过校验 抛出异常(被django源码中的异常捕获捕获) 数据剔除
# 通过校验 必须返回当前字段的值
# 不返回字段的值 cleaned_data正确字典数据里面当前字段数据就没有了
if "666" in value:
raise ValidationError("光喊666是不行的")
else:
return value#必须要写返回值
#不写return 会把 self.cleaned_data.get('gender') 对应get数据剔除
```
### 局部钩子对应的django源码
```python
执行流程
1.is_valid是所有校验的入口
2.获得return 返回值return self.is_bound and not self.errors
3.去寻找对象对应的的is_bound 属性值
self.is_bound = data is not None or files is not None
数据不为空或者文件不为空就是ture
#data就是实例化对象传的值
#实例化对象传入的值就是none
#form_obj=RegForm(data=reuest.POST)#实例化一个对象并传入data=数据
#因为位置参数第一个就是data所以不用写data=简写
#form_obj=RegForm(reuest.POST)
4.再去寻找 先从自己创建的类找 找不到去父类找对应errors #errors做了一个属性伪装
5.找到了 对应errors 发现有一个if判断 进入full_clean
6.发现full_clean
#有一个执行语句self._errors = ErrorDict()返回空对象 默认为空
#条件成立
7.继续执行full_clean
8.if not self.is_bound 参数如果传递进去 该项为false 所以不成立
具体代码
9.进入full_clean #self.fields
10.第一步进入校验入口
def is_valid(self):
"""
Returns True if the form has no errors. Otherwise, False. If errors are
being ignored, returns False.
"""
return self.is_bound and not self.errors
#两边都为ture errors是存放的容器 去找is_bound属性和errors是伪装成属性
#errors是伪装成属性
··································is_bound·····························
class BaseForm(object):#BaseForm 是class PublishForm(Form):
#Form默认继承 BaseForm 执行对应 __init__方法
default_renderer = None
field_order = None
prefix = None
use_required_attribute = True
def __init__(self, data=None, files=None, auto_id='id_%s', prefix=None,initial=None, error_class=ErrorList, label_suffix=None,
empty_permitted=False, field_order=None, use_required_attribute=None, renderer=None):
self.is_bound = data is not None or files is not None
#找到对应is_bound属性 数据不为空 文件不为空就是ture
#实例化对象传入的值就是data
#form_obj=RegForm(data=reuest.POST)#实例化一个对象并传入data=数据
#因为位置参数第一个就是data所以不用写data=简写
#form_obj=RegForm(reuest.POST)
···························errors·························
@property#伪装成了属性
def errors(self):
if self._errors is None: #因为对象值为空所以条件成立
self.full_clean()
return self._errors
·············full_clean······························
def full_clean(self):
self._errors = ErrorDict()#返回一个错误信息字典
if not self.is_bound:
#参数如果传递进去 该项为false 所以不成立
#不执行return
return
self.cleaned_data = {}#clean_data封装了一个字典
if self.empty_permitted and not self.has_changed():
return
执行校验顺序
1.self._clean_fields()
2.self._clean_form()
3.self._post_clean()
·····························_clean_fields···················
def _clean_fields(self):
for name, field in self.fields.items():
#self是实例化的对象 self.fields 把对象对应标签的所有属性打印出来 以字段名为键 字段属性为字段对象
['字段名',django对应字段对象]
例如:orderedDict([('username',<django.forms.fields.Charfiled>),])
if field.disabled:#没有设置 先不考虑
value = self.get_initial_for_field(field, name)
else:
value = field.widget.value_from_datadict(self.data, self.files, self.add_prefix(name))
try:
if isinstance(field, FileField):#执行字段属性规则
initial = self.get_initial_for_field(field, name)
value = field.clean(value, initial)
else:
value = field.clean(value)
self.cleaned_data[name] = value
#之后执行局部钩子
#cleaned_data['字段名']=post过来的值
if hasattr(self, 'clean_%s' % name):
#反射clean_字段名 判断有没有写
#def clean_gender(self): 这个方法必须写
#执行 def clean_gender(self) 必须返回对应的vlues值
#不写返回none 打印正确结果就会把该字段剔除 (不打印)
value = getattr(self, 'clean_%s' % name)()
self.cleaned_data[name] = value
#这是为什么必须写对应return vlues
except ValidationError as e:
self.add_error(name, e)
```
## 全局钩子
```python
from django.core.exceptions import ValidationError#引用一个异常
因为源码里报错信息是ValidationError所以抛出用这个异常类型
def clean(self): #源码里自动调用这个 函数 全局 必须执行
# 全局钩子 对所有字段进行校验
# 不通过校验 抛出异常
# 通过校验 必须返回所有字段的值 self.cleaned_data
pwd = self.cleaned_data.get('pwd')
re_pwd = self.cleaned_data.get('re_pwd')
if pwd != re_pwd:
self.add_error('re_pwd','两次密码不一致!')
#把错误加到指定字段之后
#如果不写就会加到全局错误字段
{{对象.errors}}
raise ValidationError('两次密码不一致')
#主动抛出 错误异常
return self.cleaned_data#验证成功返回正确的值
```
## form组件对应判断的py
```python
# 使用form组件实现注册方式
def register2(request):
form_obj = RegForm()
if request.method == "POST":
# 实例化form对象的时候,把post提交过来的数据直接传进去
form_obj = RegForm(data=request.POST) #既然传过来的input标签的name属性值和form类对应的字段名是一样的,所以接过来后,form就取出对应的form字段名相同的数据进行form校验
# 调用form_obj校验数据的方法
if form_obj.is_valid():#执行校验的开始
return HttpResponse("注册成功")
return render(request, "register2.html", {"form_obj": form_obj})
```
## form组件执行校验流程
```python
1.字段内部属性相关校验--
2.局部钩子校验---
3/然后循环下一个字段进行上面两步校验 --
4.最后执行全局钩子
```
## form小技巧
### low版form组件
#### views.py文件
```python
``````````````````````````````````````````
from django import forms#引用form组件
class AddBookForm(forms.Form):
title = forms.CharField(
label='书名',
)
price=forms.DecimalField(
label='价格',
max_digits=5,
decimal_places=2 , #999.99
# 单个添加属性比较麻烦
# widget = forms.TextInput(attrs={'class':'form-control'}),
)
publishDate=forms.CharField(
label='出版日期',
widget=forms.TextInput(attrs={'type':'date'}),
)
publish_id 取的是对应的值
authors 直接存入表中 值 对象都可以
# publishs_id = forms.ChoiceField(
# choices=models.Publish.objects.all().values_list('id','name'), #[(),()]
# )
# authors=forms.MultipleChoiceField(
# choices=models.Author.objects.all().values_list('id','name')
#
# )
publishs = forms.ModelChoiceField(
queryset=models.Publish.objects.all(),
)
authors = forms.ModelMultipleChoiceField(
queryset=models.Author.objects.all(),
)
# csrfmiddlewaretoken = forms.ChoiceField
# 批量添加属性样式
def __init__(self,*args,**kwargs):
super().__init__(*args,**kwargs)
for field_name,field in self.fields.items():
# 源码里 print(对象.fields)#打印出来的是有序字典
#orderdict(('username',charfield对象))
field.widget.attrs.update({'class':'form-control'})
#field 是对应的字段对象 .widget.attr(添加属性).update(更新{'class:'form-control'})
字典的.update更新 有就不进行操作 没有就添加
``````````````````````````视图函数执行`````````````````````````````````````````````
def addbook(request):
if request.method == 'GET':
book_obj = AddBookForm()#需要Form实例化对象 对象可以拿到对应字段
return render(request,'addbook.html',{'book_obj':book_obj})
#实例化一个对象 把对应的对象传入 html
else:
book_obj = AddBookForm(request.POST)
print(request.POST)
if book_obj.is_valid():#校验 属性 和锚点
print(book_obj.cleaned_data)
data = book_obj.cleaned_data
authors = data.pop('authors')
new_book = models.Book.objects.create(
**data
# publishs = 对象
# publishs_id=值
)
new_book.authors.add(*authors)
# return HttpResponse('ok')
return redirect('showbooks')
else:
return render(request,'addbook.html',{'book_obj':book_obj})
编辑页面使用modelform比较容易
```
### html页面写法
```python
{% load static %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<link rel="stylesheet" href="{% static 'bootstrap-3.3.7-dist/css/bootstrap.min.css' %}">
</head>
<body>
<h1>添加书籍</h1>
<div class="container">
<div class="row">
<div class="col-md-8 col-md-offset-2">
<form action="" method="post" novalidate>
{% csrf_token %}
#book_obj是form组件类 实例化出来的对象
#book_obj.字段.label 是对应的字段label属性
#book_obj.字段是生成对应的input标签
<div class="form-group">
<label for="title">书名</label>
<input type="text" class="form-control" id="title" placeholder="书名" name="title">
{{ book_obj.title.label }}
{{ book_obj.title }}
</div>
<div class="form-group">
{{ book_obj.price.label }}
{{ book_obj.price }}
<label for="price">价格</label>
<input type="text" class="form-control" id="price" placeholder="价格" name="price">
</div>
<div class="form-group">
{{ book_obj.publishDate.label }}
{{ book_obj.publishDate }}
<label for="publishDate">出版日期</label>
<input type="date" class="form-control" id="publishDate" name="publishDate">
</div>
<div class="form-group">
{{ book_obj.publishs.label }}
{{ book_obj.publishs }}
<label for="title">出版社</label>
<select name="publishs_id" id="publishs" class="form-control">
{% for publish in all_publish %}
<option value="{{ publish.id }}">{{ publish.name }}</option>
{% endfor %}
</select>
</div>
<div class="form-group">
{{ book_obj.authors.label }}
{{ book_obj.authors }}
<label for="title">作者</label>
<select name="authors" id="authors" multiple class="form-control">
{% for author in all_authors %}
<option value="{{ author.id }}">{{ author.name }}</option>
{% endfor %}
</select>
</div>
<button type="submit" class="btn btn-success pull-right">提交</button>
</form>
</div>
</div>
</div>
</body>
</html>
```
### 高大上版html写法
```python
{% load static %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<link rel="stylesheet" href="{% static 'bootstrap-3.3.7-dist/css/bootstrap.min.css' %}">
</head>
<body>
<h1>添加书籍</h1>
<div class="container">
<div class="row">
<div class="col-md-8 col-md-offset-2">
<form action="" method="post" novalidate>
{% for field in book_obj %}
#for循环对象 就能拿到所有的filed
<div class='form-group'>
{{field.label}}#filed代表所有的field
{{field}}
<span class="text-danger">{{ field.errors.0 }}</span>
</div>
{% endfor %}
<button type="submit" class="btn btn-success pull-right">提交</button>
</form>
</div>
</div>
</div>
</body>
</html>
{% for field in book_obj %}
<div class='form-group'>
{{field.label}}
{{field}}
1.for 循环对象会执行对应的__iter__方法
2.self是对应的实例化对象.fields 拿到全部标签对象
3.self['username'] #字典取值
4.执行__getitem__()#name是字段名
def __iter__(self):
for name in self.fields:
#{'username':charfiled对象,'password':charfiled对象}
yield self[name] #self['username']
def __getitem__(self, name):
"Returns a BoundField with the given name."
try:
field = self.fields[name]
except KeyError:
raise KeyError(
"Key '%s' not found in '%s'. Choices are: %s." % (
name,
self.__class__.__name__,
', '.join(sorted(f for f in self.fields)),
)
)
if name not in self._bound_fields_cache:#是一个空字典
self._bound_fields_cache[name] = field.get_bound_field(self, name)
#self当前实例化对象 把对应的name是字段名称传入
return self._bound_fields_cache[name]#
def get_bound_field(self, form, field_name):
#form对应的是实例化对象 field_name 是字段名称
return BoundField(form, self, field_name)#把对应的值传入进去
`````````````````````````````````````````````````````````
class BoundField(object):#回到最初赋值
"A Field plus data"
def __init__(self, form, field, name):
self.form = form
self.field = field# 把封装的对象重新赋值 fieled
self.name = name #name是字段
self.html_name = form.add_prefix(name)
self.html_initial_name = form.add_initial_prefix(name)
self.html_initial_id = form.add_initial_prefix(self.auto_id)
跨域同源
django做跨域同源 需要把csrf去掉 跨站请求伪造
同源
同源机制:域名、协议、端口号相同的同源
简单请求
不写头部请求 跨域会拦截报错缺少请求信息
(1) 请求方法是以下三种方法之一:(也就是说如果你的请求方法是什么put、delete等肯定是非简单请求)
HEAD
GET
POST
(2)HTTP的头信息不超出以下几种字段:(如果比这些请求头多,那么一定是非简单请求)
Accept
Accept-Language
Content-Language
Last-Event-ID
Content-Type:只限于三个值application/x-www-form-urlencoded、multipart/form-data、text/plain,也就是说,如果你发送的application/json格式的数据,那么肯定是非简单请求,vue的axios默认的请求体信息格式是json的,ajax默认是urlencoded的。
#vue.js axios -- $.ajax ajax和axios都是基于js的封装框架
支持跨域,简单请求
服务器设置响应头:Access-Control-Allow-Origin = '域名' 或 '*'
复杂请求
不在简单范围内的请求头和请求方法
写法
access-contorl-allow-origin 请求头
写了斜杠http://127.0.0.1/ 只能路径之后才可以访问
直接写ip地址http://127.0.0.1 是全路径下
复杂请求有option请求 进行预警’
contype是规定以什么格式进行上传
支持跨域,复杂请求
由于复杂请求时,首先会发送“预检”请求'options'请求方法,如果“预检”成功,则发送真实数据。
“预检”请求时,允许请求方式则需服务器设置响应头:Access-Control-Request-Method
“预检”请求时,允许请求头则需服务器设置响应头:Access-Control-Request-Headers
res['Access-Control-Allow-Origin'] = 'http://127.0.0.1:8001'
res['Access-Control-Allow-Headers'] = 'content-type'#请求头部信息
# res['Access-Control-Allow-Methods'] = 'PUT'#请求方法
# res['Access-Control-Allow-Origin'] = '*
全部网址都可以进行访问
请求头部信息是需要按照 指定的要求文件格式
GIT版本管理工具
集中式的版本管理工具 是把所有项目上线到项目中 集中管理 蹦了之后项目就崩了
分布式 可以直接把整个版本down下来进行开发 但是你开发的东西基于其他人就没办法进行操作 又要等着上传
drf
问题
前后端分离
1.常用vue.js
2.后端给前端json数据
3.后端要想使用drf组件**request.data
4.需要前端返回json数据类型
5.self封装了request属性
self.request.method
移动端盛行
PC端应用
crm项目,前端后端一起写,运行在浏览器上
第二部分 任务
以前会使用很多url绑定视图函数返回
http://127.0.0.1:8000/info/get/
http://127.0.0.1:8000/info/add/
http://127.0.0.1:8000/info/update/
http://127.0.0.1:8000/info/delete/
请求方法
http://127.0.0.1:8000/info/
get,获取数据
post,添加
put,更新
delete,删除
现在要遵循restful规范
restful是什么
resultful是一种前后端约定俗称的一种规则,用于程序之间进行数据交换的约定
详细说明
1。url中一般用名词:http:www。baidu.com/article/面向资源编程,网络上东西都视为资源
1.5筛选条件在url参数中进行传递例如
#http://www.baidu.com/article/?page=1&category
2.是一套规则,用于程序之间进行数据交换的约定。
3.他规定了一些协议,对我们感受最直接的的是,以前写增删改查需要写4个接口,restful规范的就是1 个接口,根据method的不同做不同的操作,比如:
4.get/post/delete/put/patch/delete. 初次之外,resetful规范还规定了:
- 数据传输通过json
扩展:前后端分离、app开发、程序之间(与编程语言无关)
5- URL中一般用名词:
http://www.luffycity.com/article/ (面向资源编程,网络上东西都视为资源)
6建议加上api标识
url写法
http://www.luffycity.com/api/v1....(建议,因为他不会存在跨域的问题)
注意:版本还可以放在请求头中 http://www.luffycity.com/api/ accept: ...
7建议用https代替http
#为了保证数据的安全
9.要返回给用户状态码(建议)
from rest_formwork import status
status.HTTP_200_OK 返回状态码
或者在字典里面返回自定义code状态码
#例data{
# code:10000
status:radom_string
#}
- 200,成功
- 300,301永久 /302临时
- 400,403拒绝 /404找不到
- 500,服务端代码错误
10新增的数据返回值(建议)
要返回多个列表套字典格式
GET HTTP:..WWW.xxx.com/api/user/
[
{"id":1,"name":"xxx","age":19}
{"id":1,name}
]
单条返回字典
11 操作异常要返回错误信息
{
error:"Invalid API key"
}
12 对于下一个请求要返回一些接口:Hypermedia AP
{
'id':2,
'name':'alex',
'age':19,
'depart': "http://www.luffycity.com/api/user/30/"
}
json数据:
JSON: {
name:'alex',
age:18,
gender:'男'
}
以前用webservice,数据传输格式xml
以前用webservice,数据传输格式xml。
XML
<name>alex</name>
<age>alex</age>
<gender>男</gender>
使代码更加专业
不使用drf框架
返回json类型数据
django创建一个项目叫做api '接口'
通过jsonresopnese(data,safe=Flase)
jsonresopnese默认支持字典 非字典需要使用safe
约定俗成的返回数据要返回json类型
只使用一个url cbv格式
#只使用一个url cbv格式
get 获取数据
post添加
put更新
patch局部更新
delete删除 请求方法
基于django可以实现遵循restful规范的接口开发规范
- fbv 实现比较麻烦
- cbv 相比较fbv比较简单 根据method做了不同的区分
- 使用drf比较方便
初识drf
drf是一个基于django开发的组件,本质是一个django的app。 drf可以办我们快速开发出一个遵循restful规范的程序
写接口的时候用到drf
视图
使用CBV
from django.views import View
之前django是继承view
继承apiview
from rest_framework import Apiview
from rest_framework.views import APIView
知识点
继承apiview
1.请求来了先执行视图的dispatch方法
2.版本处理
3.认证
4.权限
5.节流
6.解析器
'''
-解析器,根据用户请求体格式不同进行数据解析,解析之后放在request.data中
如果content-type:x-www-urlencoded,那么drf会根据 & 符号分割的形式去处理请 求体。 user=wang&age=19
如果content-type:application/json,那么drf会根据 json 形式去处理请求体。
{"user":"wang","age":19}
'''
7.序列化
'''
- 序列化serlizer类 .data,可以对QuerySet进行序列化,也可以对用户提交的数据进行校验。
'''
8.筛选器
9.分页
10.渲染器
- 渲染器,可以帮我们把json数据渲染到页面上进行友好的展示。(内部会根据请求设备不同做不同的 展示)
1.安装地址
pip3 install djangorestframework
2.需要先注册app!!!
如果有新建的app也需要进行注册,要不然不识别
admin不会自动加载
model数据库表结构也不会执行同步
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'rest_framework'
]
3.写路由
from django.conf.urls import url
from django.contrib import admin
from api import views
urlpatterns = [
url(r'^drf/info/', views.DrfInfoView.as_view()),
]
#as_view()执行as_view方法和函数一样执行
4.写视图上
然后进行引用 模块
内置response代替了 django的jsonresponse
from django.shortcuts import render
from rest_framework.response import Response
from rest_framework.views import APIView
from hula import models
# Create your views here.
class DrfCategoryView(APIView):
def post(self, request, *args, **kwargs):
#接收 有名传参(关键字传参) 无名传参(位置传参)
obj = request.POST.get('data')
if obj:
models.Category.objects.create(**obj)
return Response('OK成功')
知识点总结
resful规范
#基于cbv操作 也就是视图类
1.给别人提供一个URL,根据URL请求方式的不同,做不同操作。
get,获取
post,增加
put,全部更新
patch,局部更新
delete,删除
2.数据传输基于json格式。
潜规则
因为不论什么请求方式,都需要给前端返回对象内容,就是json格式的
类的约束
如果出现 NOTmplementedError错误 说明必须实现实现发
方法
drf框架
不基于drf也可以是实现resful规范来开发接口程序
使用drf之后,可以快速帮我们开发resful规范来开发接口
初始化数据库
1.迁移数据库
外键需要使用为空或者给一个默认值
blank=True Null=True
2.url路由
from django.conf.urls import url
from django.contrib import admin
from api import views
urlpatterns = [
url(r'^drf/category/', views.DrfCategoryView.as_view()),
]
from rest_framework.views import APIView
from rest_framework.response import Response
class DrfCategoryView(APIView):
pass
3.FBV
接口:访问接口时,创建一个文章类型(post增加)
from django.shortcuts import render
from rest_framework.response import Response
from rest_framework.views import APIView
from hula import models
# Create your views here.
class DrfCategoryView(APIView):
def post(self, request, *args, **kwargs):
#接收 有名传参(关键字传参) 无名传参(位置传参)
obj = request.POST.get('data')
if obj:
models.Category.objects.create(**obj)
return Response('OK成功')
假设写后端
4.开发完毕告诉前端访问
http://127.0.0.1:8000/drf/category/
5.模拟前端访问数据下载软件postman
默认使用x-www-urlencoded
拼接成 value&value
requesr.body获取请求体
request.POST获取的是POST请求的所有数据
#字典类型
#QueryDict: {'title': ['摩擦'], 'id': ['1']}>
request.body: name=alex&age=19&gender=12
request.POST: {'name': ['alex'], 'age': ['19'], 'gender': ['12']}
在postman使用raw原生json发送
json(一般使用json)
注意点
#request.body获取是bytes类型
request.body: b'{"id":1,"name":"ALEX","AGE"}'
1.decode解码成json字符串
2.loads成可以给python处理的字典(json序列化)
json.loads(request.body.decode('utf-8'))
#json格式字符串是双引号
前端json的值
requesr.body获取请求体里面的数据
request.POST获取的是POST请求的所有数据
request.body: b'{"ID":1,"name":"Alex","age":19}'
request.POST: 没有值
drf使用
对象类型转换成字典类型
from django.forms import model_to_dict
model_to_dict#转换
obj = models.Category.objects.filter(pk=pk).first()
obj=model_to_dict(obj)
默认封装了 request.data(django没有) 进行了解码序列化
视图 APIview
request.data中有一个解析器
解析器,根据用户请求体格式不同进行数据解析,解析之后方法
在进行解析时候,drf会读取http
路径
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^info/$', views.InfoView.as_view()),
url(r'^drf/info/$', views.DrfInfoView.as_view()),
url(r'^drf/category/$', views.DrfCategoryView.as_view()),
url(r'^drf/category/(?P<pk>\d+)/$', views.DrfCategoryView.as_view()),
]
直接全部文章get
class DrfCategoryView(APIView):
def get(self,request,*args,**kwargs):
#obj=models.Article.objects.values()
#obj=models.Article.objects.all()
# obj=models.Article.objects.all.values('id','name')
obj=list(obj)
return Response(obj)
?format=json 可以直接序列化json
单独的文章发送
不使用序列化器
from django.forms import model_to_dict
model_to_dict把model对象转换成字典
def get(self,request,*args,**kwargs):
pk=kwargs.get('pk')
# print(1)
if not pk:#判断有没有取到值
obj=models.Article.objects.values()
# obj=models.Article.objects.all.values('id','name')
obj=list(obj)
return Response(obj)
else:
print(1)
obj = models.Article.objects.filter(pk=pk).first()
obj=model_to_dict(obj)
return Response(obj)
删除delete
from api import models
from django.forms.models import model_to_dict
class DrfCategoryView(APIView):
def delete(self,request,*args,**kwargs):
"""删除"""
pk = kwargs.get('pk')
models.Category.objects.filter(id=pk).delete()
return Response('删除成功')
更新put
知识点
request.data 可以进行序列化和解码
序列化和编码过程
json格式字符串是双引号
request.body: b'{"id":1,"name":"ALEX","AGE"}'
先进行解码
json序列化
json.loads(request.body.decode('utf-8'))
request.data可以接受json 和 &的数据
视图写法
from api import models
from django.forms.models import model_to_dict
class DrfCategoryView(APIView):
def put(self,request,*args,**kwargs):
"""更新"""
pk = kwargs.get('pk')
models.Category.objects.filter(id=pk).update(**request.data)
return Response('更新成功')
增加post
from api import models
from django.forms.models import model_to_dict
class DrfCategoryView(APIView):
def post(self,request,*args,**kwargs):
"""增加一条分类信息"""
#利用model对象之间点create 需要一条一条添加
#因此需要打散字典变成关键字形式
models.Category.objects.create(**request.data)
return Response('成功')
序列化器serializer
查看正确的值
is.vild()
print(ser.validated_data)
多种情况使用多个serileiter进行区分 随机应变
是一个类
#知识点
1.model 指定哪一个model
2.fields 表示需要序列化的字段,"__all__"全部字段
3.depth 向下查找一层。指对外键关系会继续遍历外键对象的全部属性。
category=serializers.CharField(source='get_字段_display',required=False)
source可以自动查询是不是可执行的 自动加括号()
展示特殊的数据(choices、FK、M2M)可使用
depth source,无需加括号,在源码内部会去判断是否可执行,如果可执行自动加括号。【fk/choice】 SerializerMethodField,定义钩子方法。【m2m】
知识点
增
data=request.data 指定关键字传参 把提交的数据增加到数据库中
from rest_framework import serializers
class NewCategorySerializer(serializers.ModelSerializer):
class Meta:
model = models.Category
# fields = "__all__"
fields = ['id','name']
def get_date(self,obj):
return obj.date.strftime('%Y-%m-%d %H:%M')
def post(self,request,*args,**kwargs):
ser = NewCategorySerializer(data=request.data)
if ser.is_valid():
ser.save()
return Response(ser.data)
return Response(ser.errors)
删
def delete(self, request, *args, **kwargs):
pk = kwargs.get("pk")
if pk:
obj=models.Article.objects.filter(pk=pk).delete()
print(obj)
return Response('删除成功')
return Response('删除失败')
改
def put(self,request,*args,**kwargs):
pk = kwargs.get('pk')
category_object = models.Category.objects.filter(id=pk).first()
ser = NewCategorySerializer(instance=category_object,data=request.data)
if ser.is_valid():
ser.save()
return Response(ser.data)
return Response(ser.errors)
查
知识点
1.ser.data可以把quest类型变为字典
ser.data
2.序列化对象 instance=对应的旧值
3.many=true允许查询多个表必须指定的值
NewCategorySerializer(instance=queryset,many=True)
具体查询写法
class NewCategoryView(APIView):
def get(self,request,*args,**kwargs):
pk = kwargs.get('pk')
#多条数据查询
if not pk:
queryset = models.Category.objects.all()
ser = NewCategorySerializer(instance=queryset,many=True)
return Response(ser.data)
else:
#单条数据查询
model_object = models.Category.objects.filter(id=pk).first()
ser = NewCategorySerializer(instance=model_object, many=False)
return Response(ser.data)
引用类似局部钩子
1.model 指定哪一个model
2.fields 表示需要序列化的字段,"__all__"全部字段
3.depth 向下查找一层。指对外键关系会继续遍历外键对象的全部属性。
category=serializers.CharField(source='get_字段_display',required=False)
source可以自动查询是不是可执行的 自动加括号()
展示特殊的数据(choices、FK、M2M)可使用
depth
source,无需加括号,在源码内部会去判断是否可执行,如果可执行自动加括号。
【fk/choice】 SerializerMethodField,定义钩子方法。【m2m】
#datetime数据类型的显示
定义一个钩子
date=serializers.SerializerMethodField()
def get_date(self,obj):
return obj.date.strftime(%Y-%m-%d %H:%M:%S) if obj.date else ""
获取外键对应的字段值
from rest_framework import serializers
from api import models
使用这个
class ArticleSerializer(serializers.ModelSerializer):
source='属性.跨表字段'
#名字可以写成和model字段一样用于覆盖 字段名对应的值
category=serializers.CharField(source='category.name',required=False)
class Meta:
model = models.Article
fields = "__all__"
#如果要写fields="__all__"
#需要指定字段 是从获取字段名对应的值
def get_x1(self,obj):
return obj.category.name
#查出来对象 可以点属性
source可以自动查询是不是可执行的 自动加括号()
获取choice选择框对应值
获取choice选择框对应值
from rest_framework import serializers
from api import models
获取对应的列表的名称
class ArticleSerializer(serializers.ModelSerializer):
#第一种
status_txt = serializers.CharField(source='get_status_display',required=False)
#第二种
x2 = serializers.SerializerMethodField()#类似一个钩子
def get_x2(self,obj):
return obj.get_status_display()
#跨表
class ArticleSerializer(serializers.ModelSerializer):
x1 = serializers.SerializerMethodField()
class Meta:
model = models.Article
# fields = "__all__"
fields =
['id','title','summary','content','category','category_txt','x1','status','status_txt','x2']
#如果放入fields
#如果不写required=False或者read_onlye=False 会进行判断不为空
def get_x1(self,obj)
#obj当前表的对象
#return 对象.字段属性.跨表字段
return obj.category.name
多对多
SerializerMethodField,定义钩子方法。【m2m】
class NewArticleSerializer(serializers.ModelSerializer): tag_info = serializers.SerializerMethodField() class Meta:
model = models.Article
fields = ['title','summary','tag_info']
#钩子取出每一个字典
def get_tag_info(self,obj):
return [row for row in obj.tag.all().values('id','title')]
class FormNewArticleSerializer(serializers.ModelSerializer): class Meta:
model = models.Article
fields = '__all__'
要想只更新一个字段
使用patch
partial=True#允许部分更新
partial=True
def patch(self,request,*args,**kwargs):
"""局部"""
pk = kwargs.get('pk')
article_object = models.Article.objects.filter(id=pk).first()
ser = serializer.ArticleSerializer(instance=article_object, data=request.data,partial=True)
if ser.is_valid():
ser.save()
return Response(ser.data)
return Response(ser.errors)
多对多关系
NewArticleSerializer写法
使用钩子
class NewArticleSerializer(serializers.ModelSerializer):
tag_info = serializers.SerializerMethodField()
class Meta:
model = models.Article
fields = ['title','summary','tag_info']
def get_tag_info(self,obj):
return [row for row in obj.tag.all().values('id','title')]
class FormNewArticleSerializer(serializers.ModelSerializer):
class Meta:
model = models.Article
fields = '__all__'
视图类写法
class NewArticleView(APIView):
def get(self,request,*args,**kwargs):
pk = kwargs.get('pk')
if not pk:
queryset = models.Article.objects.all()
ser = serializer.NewArticleSerializer(instance=queryset,many=True)
return Response(ser.data)
article_object = models.Article.objects.filter(id=pk).first()
ser = serializer.NewArticleSerializer(instance=article_object, many=False)
return Response(ser.data)
def post(self,request,*args,**kwargs):
ser = serializer.FormNewArticleSerializer(data=request.data)
if ser.is_valid():
ser.save()
return Response(ser.data)
return Response(ser.errors)
def put(self, request, *args, **kwargs):
"""全部更新"""
pk = kwargs.get('pk')
article_object = models.Article.objects.filter(id=pk).first()
ser = serializer.FormNewArticleSerializer(instance=article_object, data=request.data) if ser.is_valid():
ser.save()
return Response(ser.data)
return Response(ser.errors)
def patch(self,request,*args,**kwargs):
"""局部"""
pk = kwargs.get('pk')
article_object = models.Article.objects.filter(id=pk).first()
ser = serializer.FormNewArticleSerializer(instance=article_object,data=request.data,partial=True)
if ser.is_valid():
ser.save()
return Response(ser.data)
return Response(ser.errors)
def delete(self,request,*args,**kwargs):
pk = kwargs.get('pk')
models.Article.objects.filter(id=pk).delete()
return Response('删除成功')
分页
PageNumberPagination
用于固定页面显示
获取多条数据
知识点
"count": 54,#每页显示多少条数据
#下一页
"next": "http://127.0.0.1:8000/drf/article/?page=2",
#上一页
"previous": null,
类的约束
必须写指定的功能
# 约束子类中必须实现f1 class Base(object):
def f1(self):
raise NotImplementedError('asdfasdfasdfasdf')
class Foo(Base):
def f1(self):
print(123)
obj = Foo()
obj.f1()
1.可以重写pagesize的类 pagenumber 继承
引用模块
from rest_framework.pagination import PageNumberPagination#引用分页模块
from rest_framework import serializers#引用序列化模块
class pagesize(PageNumberPagination):
page_size=1
class PageArticleView(APIView):
def get(self,request,*args,**kwargs):
queryset=models.Article.objects.all()
page_obj = pagesize()#实例化一个页面大小
#进行分页
result = page_obj.paginate_queryset(queryset, request, self)
#把分页的数据写入序列化器
ser = PageArticleerializer(instance=result, many=True)
return page_obj.get_paginated_response(ser.data)
2.直接更改setting配置文件
REST_FRAMEWORK = {
"PAGE_SIZE":2
}
class PageArticleView(APIView):
def get(self,request,*args,**kwargs):
queryset=models.Article.objects.all()
page_obj=PageNumberPagination()
result=page_obj.paginate_queryset(queryset,request,self)
ser=PageArticleerializer(instance=result,many=True)
return Response(ser.data)
LimitOffsetPagination
offset 0 limit 1
从offset开始数limit条数
用于滑动灵活运用
可以限制max_limit=2
from rest_framework.pagination import PageNumberPagination
from rest_framework.pagination import LimitOffsetPagination
from rest_framework import serializers
class PageArticleSerializer(serializers.ModelSerializer):
class Meta:
model = models.Article
fields = "__all__"
#重写父类
class HulaLimitOffsetPagination(LimitOffsetPagination):
max_limit = 2
class PageArticleView(APIView):
def get(self,request,*args,**kwargs):
queryset = models.Article.objects.all()
page_object = HulaLimitOffsetPagination()
result = page_object.paginate_queryset(queryset, request, self)
ser = PageArticleSerializer(instance=result, many=True)
return Response(ser.data)
listapiview
url写法
url(r'^page/view/article/$', views.PageViewArticleView.as_view()),
视图写法
from rest_framework.generics import ListAPIView
class PageViewArticleSerializer(serializers.ModelSerializer):
class Meta:
model = models.Article
fields = "__all__"
class PageViewArticleView(ListAPIView):
queryset = models.Article.objects.all()
#指定类
serializer_class = PageViewArticleSerializer
setting配置
#通过源码里面的配置进行分页的选择
REST_FRAMEWORK = { "PAGE_SIZE":2,
#分页的选择
"DEFAULT_PAGINATION_CLASS":"rest_framework.pagination.PageNumberPagination"
}
呼啦圈的设置
CMS系统格式
内容管理系统。CMS通常用作企业的数字信息管理系统,
功能的实现
1 增加文章(可以不写) #编写人员进行撰写 写入数据库
2 文章列表
3 文章详细
4 评论列表
1.没有变化的类型不需要创建一张表
2.数据量大的类似详细内容 需要另外开辟一张表,如果表中列(字段)太多 水平分表 进行一对一
3.图片路径存入数据库
4.自关联具有相同数据的表
#不是必须的
可以不需要写外键提高查询效率
1.url路径
urlpattent+=[]#为了区分增加的路径
from django.conf.urls import url
from api import views
urlpatterns = [
url(r'^Atricle/$', views.AtricleView.as_view()),
]
urlpatterns+=[
url(r'^Atricle/(?P<pk>\d+)/$', views.AtricleView.as_view()),
url(r'^Comment/$', views.CommentView.as_view()),
url(r'^Comment/(?P<pk>\d+)/$', views.CommentView.as_view()),
]
2.model 表结构
from django.db import models
class UserInfo(models.Model):
""" 用户表 """
username = models.CharField(verbose_name='用户名',max_length=32)
password = models.CharField(verbose_name='密码',max_length=64)
class Article(models.Model):
""" 文章表 """
category_choices = (
(1,'咨询'),
(2,'公司动态'),
(3,'分享'),
(4,'答疑'),
(5,'其他'),
)
category = models.IntegerField(verbose_name='分类',choices=category_choices)
title = models.CharField(verbose_name='标题',max_length=32)
image = models.CharField(verbose_name='图片路径',max_length=128) # /media/upload/....
summary = models.CharField(verbose_name='简介',max_length=255)
comment_count = models.IntegerField(verbose_name='评论数',default=0)
read_count = models.IntegerField(verbose_name='浏览数',default=0)
author = models.ForeignKey(verbose_name='作者',to='UserInfo')
date = models.DateTimeField(verbose_name='创建时间',auto_now_add=True)
class ArticleDetail(models.Model):
article = models.OneToOneField(verbose_name='文章表',to='Article')
content = models.TextField(verbose_name='内容')
class Comment(models.Model):
""" 评论表 """
article = models.ForeignKey(verbose_name='文章',to='Article')
content = models.TextField(verbose_name='评论')
user = models.ForeignKey(verbose_name='评论者',to='UserInfo')
# parent = models.ForeignKey(verbose_name='回复',to='self', null=True,blank=True)
3.serlizer序列化器
知识点补充
1.#序列化器写法
exclude=['字段']去除不进行校验
2.#序列化器内部的值
ser是序列化器实例化的对象
ser=序列化器(
1.instance=旧值(查询的值,数据库本类就有的)
2.data=要添加的值,提交的值(post请求,put,patch请求提交的值) )
3.查询的时候 需要指定many=True 查询多个值必须要指定
ser.is_valid():
'''
注意只打印存在字段的校验,
传入多的值不会进行打印和数据库的写入
ser.errors是所有字段校验错误的信息
'''
print(ser.validated_data)#相当于modelform form校验的值
ser.save()#存入数据库 括号里可以写值 由其他字段传入的
#article=ser.save()#aricle是新增这条数据的对象
``````````````````````
多个序列化器
#接收前端发送的所有数据但只校验 序列化器含有的字段
ser=AtricleSeriALIZER(data=request.data)
ser_detail=ArtcleDetaili(data=request.data)
if ser.is_valid() and ser_detail.is_valid()
article=ser.save(author=1)
ser_detail.save(article=article)
#可以等于对象=对象
#也可等于id=id(内容回顾)
ser_detail.save(article.id=article.id)
4.view视图写法
post请求
(编写数据的人员去写)
知识点
1.多个serlizer序列化器进行保存
2.save里面可以添加参数
可以添加对应字段的id和对象类型的数据
没有办法直接添加外键对应的值 可以通过save(对应的值或者对象)
3.序列化的对象就是对应文章的对象
4.作者是登陆成功存入session的值 不需要手动传入
序列化器写法
exclude=['author']#去除作者不进行校验
#为了把字段写活request.session获取值进行匹配取得匹配的文章
#查询对应文章对象不能直接post写死 因为不知道对应的文章
class AtricleSerializers(serializers.ModelSerializer):
class Meta:
model = models.Article
exclude = ['author', ]#外键字段不进行校验
#request.session 登陆用户明进行匹配
class AtricledetailSerializer(serializers.ModelSerializer):
class Meta:
model = models.ArticleDetail
exclude = ['article', ]
#外键字段不进行校验
2#文章对象或者文章值来确定 来确定添加对应的文章详细信息
view视图写法
两个序列化器进行校验
def post(self, request, *args, **kwargs):
ser = AtricleSerializers(data=request.data)
serDetail = AtricledetailSerializer(data=request.data)
print(request.data)
if ser.is_valid() and serDetail.is_valid():
# 因为作者id是根据登陆的id进行存储(例如session)
print(ser.validated_data)
atricle = ser.save(author_id=1)
serDetail.save(article=atricle)
return Response(f'{ser.data}{serDetail.data}')
return Response('错误')
文章列表显示排序
先添加在显示
序列化写法
class AtiricleliST(serializers.ModelSerializer):
class Meta:
model = models.Article
fields = "__all__"
很多文章的获取get请求
多条数据
1.先进行实例化分页
2.把查询的数据进行分页,
3.放入序列化器里面进行处理显示
def get(self, request, *args, **kwargs):
pk=kwargs.get("pk")
if not pk:
Article_obj = models.Article.objects.all().order_by('-date')
Page_obj = PageNumberPagination()
Page = Page_obj.paginate_queryset(Article_obj, request, self)
print(Page)
ser = AtiricleliST(instance=Page, many=True)
print(3)
return Page_obj.get_paginated_response(ser.data)
文章筛选
前端的url
全部:http://127.0.0.1:8000/hg/article/
筛选:http://127.0.0.1:8000/hg/article/?category=2
视图
#筛选文章的数据
class ArticleView(APIView):
""" 文章视图类 """
def get(self,request,*args,**kwargs):
""" 获取文章列表 """
pk = kwargs.get('pk')
if not pk:
condition = {}#存储对应筛选
category =
#从前端url获取值
request.query_params.get('category')
if category:#如果由就进行过滤
condition['category'] = category
queryset =
#**condition 字典打散然后进行筛选 分类为这个id的
models.Article.objects.filter(**condition).order_by('-date')
pager = PageNumberPagination()
result = pager.paginate_queryset(queryset,request,self)
ser = ArticleListSerializer(instance=result,many=True)
return Response(ser.data)
article_object = models.Article.objects.filter(id=pk).first()
ser = PageArticleSerializer(instance=article_object,many=False)
return Response(ser.data)
文章详细
#去除对应的外键关联字段的验证article
#只有文章创建了之后才能创建文章详情
#author对应的是用户id值,例如session
#因为文章详细不能直接创建需要通过文章对象关联创建
class AtricledetailSerializer(serializers.ModelSerializer):
class Meta:
model = models.ArticleDetail
exclude = ['article', ]
class AtricleSerializers(serializers.ModelSerializer):
class Meta:
model = models.Article
exclude = ['author', ]
查询一条数据的详细
view视图写法
def get(self, request, *args, **kwargs):
pk=kwargs.get("pk")
if not pk:
Article_obj = models.Article.objects.all().order_by('-date')
Page_obj = PageNumberPagination()
Page = Page_obj.paginate_queryset(Article_obj, request, self)
print(Page)
ser = AtiricleliST(instance=Page, many=True)
print(3)
return Page_obj.get_paginated_response(ser.data)
#正文开始 else是一条 if是多条
else:
Article_obj=models.Article.objects.filter(pk=pk).first()
#使用序列化处理一条数据
ser=AtiricleDetail(instance=Article_obj,many=False)
return Response(ser.data)
·································
文章详细 文章表反向小写表名查询详细表
Article_obj=models.Article.objects.filter(pk=pk).first()
属性.小写表名.外键关联表属性
print(Article_obj.articledetaili.content)
评论
1.访问get请求
http://127.0.0.1:8000/hg/comment/?article=2
request.query_params.get('article')
#相当于request.GET。get 获取url的值
query_params获取?后面值
reqeust.data 相当于post
序列化器
class MmentSerialiser(serializers.ModelSerializer):
class Meta:
model=models.Comment
fields="__all__"
view视图
通过前端发送url进行筛选
# http://127.0.0.1:8000/hg/comment/?article=2
def get(self,request,*args,**kwargs):
'''
request.query_params.get()
相当于request.GET.get()
'''
coment=request.query_params.get('article')
coment_obj=models.Comment.objects.filter(article_id=coment)
show_coment=MmentSerialiser(instance=coment_obj,many=True)
return Response(show_coment.data)
2.添加文章评论post请求
#去掉对应外键字段硬不需要进行关联
#request.session可以直接获取登陆的用户名
class CommentSerialiser(serializers.ModelSerializer):
class Meta:
model=models.Comment
exclude=['user']
锁定单个文章的评论增加
前端写法
#返回数据的写法
#第一种
http://127.0.0.1:8000/hg/comment/
{
article:1,
content:'xxx'
}
#第二种
http://127.0.0.1:8000/hg/comment/?article=1
{
content:'xxx'
}
view视图写法
#文章由前端直接返回因为只有有了文章才能进行评论
#通过前端数据进行返回
def post(self,request,*args,**kwargs):
ser=CommentSerialiser(data=request.data)
if ser.is_valid():
print(ser.validated_data)
ser.save(user_id=1)
return Response(ser.data)
print(ser.errors)
过滤器
对查询出来的数据进行筛选可写可不写
from rest_framework.filters import BaseFilterBackend
源码
'''
def filter_queryset(self, request, queryset, view):
#继承了这个类必须写这个方法不然报错
raise NotImplementedError(".filter_queryset() must be overridden.")
'''
view是当前视图self
queryset是筛选之后的数据
request 就是request
def filter_queryset(self,request,queryset,view):
pass
使用方法
对查询出来的数据进行筛选可写可不写
#第一部分
from rest_framework.filters import BaseFilterBackend
#继承类
class MyFilterBack(BaseFilterBackend):
def filter_queryset(self,request,queryset,view):
val = request.query_params.get('cagetory')
return queryset.filter(category_id=val)
#先实例化一个
class Indexview(APIview):
def get(self,request,*arg,**kwargs):
#就是查询一个表不理他
queryset=models.News.objects.all()
#实例化一个类对象
obj=MyFilterBack()
#传值顺序request,queryset,self
result=obj.filter_queryset(request,queryset,self)
return Response('...')
视图类
F查询
def get(self,request,*args,**kwargs):
# 1.获取单挑数据再做序列化
result = super().get(request,*args,**kwargs)
# 2.对浏览器进行自加1
pk = kwargs.get('pk')
models.Article.objects.filter(pk=pk).update(read_count=F('read_count')+1)
# 3.对浏览器进行自加1
# instance = self.get_object()
# instance.read_count += 1
# instance.save()
return result
apiview
提供了公共方法
request.data 是request.post的封装 json序列化
dispatch()分发
self封装了request属性
self.request.method
apiview的使用
from rest_framework.views import APIView
源码剖析
@classmethod
def as_view(cls, **initkwargs):
if isinstance(getattr(cls, 'queryset', None), models.query.QuerySet):
def force_evaluation():
raise RuntimeError(
'Do not evaluate the `.queryset` attribute directly, '
'as the result will be cached and reused between requests. '
'Use `.all()` or call `.get_queryset()` instead.'
)
cls.queryset._fetch_all = force_evaluation
#执行父类的as_view方法
view = super().as_view(**initkwargs)
#执行父类的super().as_view(**initkwargs)
view.cls = cls
view.initkwargs = initkwargs
#闭包 csrf_exempt免除csrftoken的认证
return csrf_exempt(view)
--------------------------------------
@classonlymethod
def as_view(cls, **initkwargs):
"""
Main entry point for a request-response process.
"""
for key in initkwargs:
if key in cls.http_method_names:
raise TypeError("You tried to pass in the %s method name as a "
"keyword argument to %s(). Don't do that."
% (key, cls.__name__))
if not hasattr(cls, key):
raise TypeError("%s() received an invalid keyword %r. as_view "
"only accepts arguments that are already "
"attributes of the class." % (cls.__name__, key))
def view(request, *args, **kwargs):
self = cls(**initkwargs)
if hasattr(self, 'get') and not hasattr(self, 'head'):
self.head = self.get
self.request = request
self.args = args
self.kwargs = kwargs
#执行本类的self.dispatch
return self.dispatch(request, *args,**kwargs)
#执行view
return view
-------------apiview的dispatch--------
def dispatch(self, request, *args, **kwargs):
"""
`.dispatch()` is pretty much the same as Django's regular dispatch,
but with extra hooks for startup, finalize, and exception handling.
"""
self.args = args
self.kwargs = kwargs
#封装老值request
request = self.initialize_request(request, *args, **kwargs)
self.request = request
self.headers = self.default_response_headers # deprecate?
try:
self.initial(request, *args, **kwargs)
# Get the appropriate handler method
if request.method.lower() in self.http_method_names:
handler = getattr(self, request.method.lower(),
self.http_method_not_allowed)
else:
handler = self.http_method_not_allowed
response = handler(request, *args, **kwargs)
except Exception as exc:
response = self.handle_exception(exc)
self.response = self.finalize_response(request, response, *args, **kwargs)
return self.response
GenericAPIView
#一 初识
from rest_framework.generics import GenericAPIView
GenericAPIview继承了APIview
class NewView(GenericAPIview):
querset=model.News.objects.all()
def get(self,request,*arg,**kwargs):
#self对应NewView的对象
self.filter_queryset(self.queryset)
1.执行对应的filter_queryset方法
2.本类没有去寻找父类GenericAPIview
'''
def filter_queryset(self, queryset):
for backend in list(self.filter_backends):
queryset = backend().filter_queryset(self.request, queryset, self)
return queryset
'''#所以默认返回原来的queryset
3.寻找filter_backends
'''
filter_backends = api_settings.DEFAULT_FILTER_BACKENDS
filter_backends是空的
'''
1. 本类重写filter_backends
from rest_framework.generics import GenericAPIView
#GenericAPIview继承了APIview
class NewFiltrBackend(BaseFilterBackend):
def filter_queryset(self,request,queryset,view):
val = request.query_params.get('cagetory')
return queryset.filter(category_id=val)
class NewView(GenericAPIview):
querset=model.News.objects.all()
filter_backends=[NewFiltrBackend ,]
def get(self,request,*arg,**kwargs):
#self对应NewView的对象
v=self.get_queryset()
queryset=self.filter_queryset(v)
1.执行对应的filter_queryset方法
2.本类没有去寻找父类GenericAPIview
'''
源码 继承类不写self.queryset会报错
assert self.queryset is not None, (
"'%s' should either include a `queryset` attribute, "
"or override the `get_queryset()` method."
% self.__class__.__name__
)
'''
'''
def filter_queryset(self, queryset):
for backend in list(self.filter_backends):
queryset = backend().filter_queryset(self.request, queryset, self)
return queryset
'''4.backend等于对应NewFiltrBackend类名() 实例化对象
·· 执行NewFiltrBackend里面的filter_queryset方法
3.寻找filter_backends,本类的filter_backends
#filter_backends=[NewFiltrBackend ,]
5.queryset=self.filter_queryset(self.queryset)是筛选之后的结果
#v=self.get_queryset()
queryset=self.filter_queryset(v)
6.寻找对应get_queryset
'''
源码
queryset = self.queryset
if isinstance(queryset, QuerySet):
# Ensure queryset is re-evaluated on each request.
queryset = queryset.all()
return queryset
'''#返回等于筛选之后的queryset
#queryset=self.filter_queryset(queryset)
#queryset=get_queryset()
·········self.get_serializer()···············
class Newserializers(serializers.ModelSerializer):
class Meta:
model=models.News
fields="__all__"
class NewFiltrBackend(BaseFilterBackend):
def filter_queryset(self,request,queryset,view):
val = request.query_params.get('cagetory')
return queryset.filter(category_id=val)
class NewView(GenericAPIview):
querset=model.News.objects.all()
filter_backends=[NewFiltrBackend ,]
def get(self,request,*arg,**kwargs):
#self对应NewView的对象
v=self.get_queryset()
queryset=self.filter_queryset(v)
self.get_serializer()#本类没有去父类找
#代替了 ser=Newserializers(instance=queryset,many=True)
#ser.data
1.寻找get_serializer()
2.
'''
源码
def get_serializer(self, *args, **kwargs):
serializer_class = self.get_serializer_class()
kwargs['context'] = self.get_serializer_context()
return serializer_class(*args, **kwargs)
'''
3.进行寻找get_serializer_class()本类没有去父类找
#serializer_class = self.get_serializer_class()
4.
'''
def get_serializer_class(self):
assert self.serializer_class is not None, (
"'%s' should either include a `serializer_class` attribute, "
"or override the `get_serializer_class()` method."
% self.__class__.__name__
)
return self.serializer_class
''' #return self.serializer_class 返回serializer_class
#get_serializer()=serializer_class
在本类定义seializer_class
seializer_class=Newserializers
相当于 #ser=Newserializers(instance=queryset,many=True)
#ser.data
ser=self.get_serializer(instance=queryset,many=True)
ser.data
``````````````````````````````
分页
querset=model.News.objects.all()
pagination_class =PageNumberPagination
self.paginate_queryset(queryset)
'''
源码
self.paginate_queryset()
self._paginator = self.pagination_class()
需要定义
def paginator(self):
if not hasattr(self, '_paginator'):
if self.pagination_class is None:
self._paginator = None
else:
self._paginator = self.pagination_class()
return self._paginator
'''pagination_class()需要本地定义
pagination_class =PageNumberPagination
GenericAPIView源码总结
源码的剖析
def get_queryset(self):
"""
Get the list of items for this view.
This must be an iterable, and may be a queryset.
Defaults to using `self.queryset`.
This method should always be used rather than accessing `self.queryset`
directly, as `self.queryset` gets evaluated only once, and those results
are cached for all subsequent requests.
You may want to override this if you need to provide different
querysets depending on the incoming request.
(Eg. return a list of items that is specific to the user)
"""
assert self.queryset is not None, (
"'%s' should either include a `queryset` attribute, "
"or override the `get_queryset()` method."
% self.__class__.__name__
)
queryset = self.queryset
if isinstance(queryset, QuerySet):
# Ensure queryset is re-evaluated on each request.
queryset = queryset.all()
return queryset
def get_object(self):
"""
Returns the object the view is displaying.
You may want to override this if you need to provide non-standard
queryset lookups. Eg if objects are referenced using multiple
keyword arguments in the url conf.
"""
queryset = self.filter_queryset(self.get_queryset())
# Perform the lookup filtering.
lookup_url_kwarg = self.lookup_url_kwarg or self.lookup_field
assert lookup_url_kwarg in self.kwargs, (
'Expected view %s to be called with a URL keyword argument '
'named "%s". Fix your URL conf, or set the `.lookup_field` '
'attribute on the view correctly.' %
(self.__class__.__name__, lookup_url_kwarg)
)
filter_kwargs = {self.lookup_field: self.kwargs[lookup_url_kwarg]}
obj = get_object_or_404(queryset, **filter_kwargs)
# May raise a permission denied
self.check_object_permissions(self.request, obj)
return obj
def get_serializer(self, *args, **kwargs):
"""
Return the serializer instance that should be used for validating and
deserializing input, and for serializing output.
"""
serializer_class = self.get_serializer_class()
kwargs['context'] = self.get_serializer_context()
return serializer_class(*args, **kwargs)
def get_serializer_class(self):
"""
Return the class to use for the serializer.
Defaults to using `self.serializer_class`.
You may want to override this if you need to provide different
serializations depending on the incoming request.
(Eg. admins get full serialization, others get basic serialization)
"""
assert self.serializer_class is not None, (
"'%s' should either include a `serializer_class` attribute, "
"or override the `get_serializer_class()` method."
% self.__class__.__name__
)
return self.serializer_class
def get_serializer_context(self):
"""
Extra context provided to the serializer class.
"""
return {
'request': self.request,
'format': self.format_kwarg,
'view': self
}
def filter_queryset(self, queryset):
"""
Given a queryset, filter it with whichever filter backend is in use.
You are unlikely to want to override this method, although you may need
to call it either from a list view, or from a custom `get_object`
method if you want to apply the configured filtering backend to the
default queryset.
"""
for backend in list(self.filter_backends):
queryset = backend().filter_queryset(self.request, queryset, self)
return queryset
源码解释
from rest_framework.generics import GenericAPIView
from rest_framework.filters import BaseFilterBackend
from rest_framework import serializers
GenericAPIview继承了APIview
class Newserializers(serializers.ModelSerializer):
class Meta:
model=models.News
fields="__all__"
class NewFiltrBackend(BaseFilterBackend):
def filter_queryset(self,request,queryset,view):
val = request.query_params.get('cagetory')
return queryset.filter(category_id=val)
class NewView(GenericAPIview):
querset=model.News.objects.all()
filter_backends=[NewFiltrBackend ,]
seializer_class=Newserializers
def get(self,request,*arg,**kwargs):
#self对应NewView的对象
v=self.get_queryset()
queryset=self.filter_queryset(v)
self.get_serializer(instance==queryset,many=True)
retutn Response(ser.data)
'''
1.querset=model.News.objects.all()
2.filter_backends=[NewFiltrBackend ,]
3.seializer_class=Newserializers
4.pagination_class =PageNumberPagination
1.查询
self.get_queryset()#等于querset=model.News.objects.all()
2.序列化
self.get_serializer()等于seializer_class=Newserializers()
3.筛选
self.filter_queryset()
等于filter_backends=[NewFiltrBackend ,]
内部有一个for循环列表 同等与NewFiltrBackend()
4.分页
self.paginate_queryset(queryset)
等于page_obj=PageNumberPagination()
'''
基于GenericAPIView
listapiview查看
基于GenericAPIView
模拟get请求
1.queryset
2.分页
#settings的配置
paginator.paginate_queryset(queryset, self.request, view=self)
"DEFAULT_PAGINATION_CLASS":"rest_framework.pagination.PageNumberPagination",
"PAGE_SIZE":2,
3.序列化
4.返回序列化数据
源码剖析
#源码
def get(self, request, *args, **kwargs):
return self.list(request, *args, **kwargs)
1.执行list
def list(self, request, *args, **kwargs):
queryset = self.filter_queryset(self.get_queryset())
#self.get_queryset()执行自定的
#queryset=model.News.objects.all()
#self.filter_queryset()筛选执行
#filter_backends=[NewFiltrBackend ,]
#执行对应本类的filter_queryset
2. page = self.paginate_queryset(queryset)
#分页
#执行 pagination_class =PageNumberPagination
if page is not None:
3.serializer = self.get_serializer(page, many=True)
#序列化 执行seializer_class=Newserializers
return self.get_paginated_response(serializer.data)
serializer = self.get_serializer(queryset, many=True)
return Response(serializer.data)
#最后返回序列化的数据
RetrieveAPIView单条查看
模拟get请求
执行流程
1. #对应获得对象 自己要定义单条数据 queryset
2. #序列化
3. #返回数据
源码剖析
class RetrieveAPIView(mixins.RetrieveModelMixin,
GenericAPIView):
#从左往右继承
def get(self, request, *args, **kwargs):
return self.retrieve(request, *args, **kwargs)
#去找retrieve这个方法
class RetrieveModelMixin:
"""
Retrieve a model instance.
"""
def retrieve(self, request, *args, **kwargs):
#对应获得对象
instance = self.get_object()
#序列化
serializer = self.get_serializer(instance)
#返回数据
return Response(serializer.data)
执行
def get_object(self):
"""
Returns the object the view is displaying.
You may want to override this if you need to provide non-standard
queryset lookups. Eg if objects are referenced using multiple
keyword arguments in the url conf.
"""
queryset = self.filter_queryset(self.get_queryset())
# Perform the lookup filtering.
lookup_url_kwarg = self.lookup_url_kwarg or self.lookup_field
assert lookup_url_kwarg in self.kwargs, (
'Expected view %s to be called with a URL keyword argument '
'named "%s". Fix your URL conf, or set the `.lookup_field` '
'attribute on the view correctly.' %
(self.__class__.__name__, lookup_url_kwarg)
)
return obj
基于GenericAPIView
createapiview创建
基于GenericAPIView
封装了post请求
执行流程
1.序列化
2.序列化验证
3.保存数据
源码剖析
def post(self, request, *args, **kwargs):
return self.create(request, *args, **kwargs)
1.执行create
def create(self, request, *args, **kwargs):
serializer = self.get_serializer(data=request.data)
#序列化
serializer.is_valid(raise_exception=True)
#序列化验证
self.perform_create(serializer)
'''
保存数据
def perform_create(self, serializer):
serializer.save()
'''
headers = self.get_success_headers(serializer.data)
return Response(serializer.data, status=status.HTTP_201_CREATED, headers=headers)
示例使用
#第一种写法重写create书写 多条序列化器
def create(self, request, *args, **kwargs):
article = articleseralizer(data=request.data)
articleDetail = atricleDetaliser(data=request.data)
if article.is_valid() and articleDetail.is_valid():
article_obj = article.save(author=request.user)
print(">>>>>>>>>", request.user, type(request.user))
articleDetail.save(article=article_obj)
return Response('修改成功')
else:
return Response(f"{article.errors},{articleDetail.errors}")
#第二种方式
重写序列化器分发
def get_serializer_class(self):
self.request.method=="POST":
return 对应序列化器
self.request.method=="GET":
return 对应序列化器
def perform_create(self,serializer):
Aritlel=serializer.save(author)
serializer_second=AricleSerializer(data=request.data)
serializer.save(aritle=Aritlel)
字段对象=对象
UpdateAPIView全局局部
封装了局部更新和全局更新
基于GenericAPIView
执行流程
1.获取更新那条数据的对象
2.序列化
2.序列化校验
3.校验成功更新
源码剖析
def put(self, request, *args, **kwargs):
return self.update(request, *args, **kwargs)
'''
def update(self, request, *args, **kwargs):
partial = kwargs.pop('partial', False)
instance = self.get_object()
'''
#执行queryset查询处理的model对象
#相当于
#queryset=model.表名.object.filter(pk=pk).frist()
'''
serializer = self.get_serializer(instance, data=request.data, partial=partial)默认不为Ture
#执行对应的序列化
serializer.is_valid(raise_exception=True)
#序列化验证
self.perform_update(serializer)
'''
# def perform_update(self, serializer):
#serializer.save()
def patch(self, request, *args, **kwargs):
return self.partial_update(request, *args, **kwargs)
'''
def partial_update(self, request, *args, **kwargs):
kwargs['partial'] = True
return self.update(request, *args, **kwargs)
'''
执行
'''
def update(self, request, *args, **kwargs):
partial = kwargs.pop('partial', False)
instance = self.get_object()
'''
#执行queryset查询处理的model对象
#相当于
#queryset=model.表名.object.filter(pk=pk).frist()
'''
serializer = self.get_serializer(instance, data=request.data, partial=partial)
kwargs['partial'] = True 局部更新
#执行对应的序列化
serializer.is_valid(raise_exception=True)
#序列化验证
self.perform_update(serializer)
'''
# def perform_update(self, serializer):
#serializer.save()
删除DestroyAPIView
执行流程
1.传入对象
2.执行def perform_destroy(self, instance):
3.删除
源码剖析
def delete(self, request, *args, **kwargs):
return self.destroy(request, *args, **kwargs)
def destroy(self, request, *args, **kwargs):
instance = self.get_object()
#c传入对象删除
self.perform_destroy(instance)
return Response(status=status.HTTP_204_NO_CONTENT)
def perform_destroy(self, instance):
instance.delete()#删除
Viewset视图类
是APIview视图类的继承对象
createapiview
UpdateAPIview。。。。等等
使用方法
1.直接继承即可
2.因为没有封装对应get post等请求方法 一点点去找父类的方法
3.GenericViewSet(ViewSetMixin)它继承的ViewSetMixin
4.重写了asview()需要传参
5.使用两个类进行id和没有id的区分
6.可以指定多个
url(r'^article/$',article.AtricleView.as_view({"get":"list"}))
url(r'^article/(?P<pk>\d+)/$',article.AtricleView.as_view({"get":"retrieve"}))
知识点
from rest_framework.viewsets import GenericVIewSet
class GenericViewSet(ViewSetMixin,generics.GenericAPIView
):
默认继承GenericAPIView
def get_serializer_class(self):
pk = self.kwargs.get('pk')
if pk:
return ArticleDetailSerializer
return ArticleSerializer
ListModelMixin添加
源码
def list(self, request, *args, **kwargs):
queryset = self.filter_queryset(self.get_queryset())
page = self.paginate_queryset(queryset)
if page is not None:
serializer = self.get_serializer(page, many=True)
return self.get_paginated_response(serializer.data)
serializer = self.get_serializer(queryset, many=True)
return Response(serializer.data)
RetrieveModelMixin单条查询
源码
def retrieve(self, request, *args, **kwargs):
instance = self.get_object()
serializer = self.get_serializer(instance)
return Response(serializer.data)
UpdateModelMixin更新
源码
def update(self, request, *args, **kwargs):
partial = kwargs.pop('partial', False)
instance = self.get_object()
serializer = self.get_serializer(instance, data=request.data, partial=partial)
serializer.is_valid(raise_exception=True)
self.perform_update(serializer)
if getattr(instance, '_prefetched_objects_cache', None):
# If 'prefetch_related' has been applied to a queryset, we need to
# forcibly invalidate the prefetch cache on the instance.
instance._prefetched_objects_cache = {}
return Response(serializer.data)
def perform_update(self, serializer):
serializer.save()
#
def partial_update(self, request, *args, **kwargs):
kwargs['partial'] = True
return self.update(request, *args, **kwargs)
class
DestroyModelMixin:
删除
源码
class DestroyModelMixin:
"""
Destroy a model instance.
"""
def destroy(self, request, *args, **kwargs):
instance = self.get_object()
self.perform_destroy(instance)
return Response(status=status.HTTP_204_NO_CONTENT)
def perform_destroy(self, instance):
instance.delete()
版本
setting配置
default_version = api_settings.DEFAULT_VERSION
#默认版本
allowed_versions = api_settings.ALLOWED_VERSIONS
#指定版本
version_param = api_settings.VERSION_PARAM
#url版本传输关键字
#指定版本类类
"DEFAULT_VERSIONING_CLASS":"rest_framework.versioning.URLPathVersioning",
知识点
dispath 老的request 封装了很多功能
request.version#版本
scheme#版本对象
#执行返回一个版本元组 第一个是版本第二个是版本对象
def determine_version(self, request, *args, **kwargs):
"""
If versioning is being used, then determine any API version for the
incoming request. Returns a two-tuple of (version, versioning_scheme)
"""
if self.versioning_class is None:
return (None, None)
scheme = self.versioning_class()
return (scheme.determine_version(request, *args, **kwargs), scheme)
request.version, request.versioning_scheme = version, scheme
源码执行流程
class APIView(View):
versioning_class = api_settings.DEFAULT_VERSIONING_CLASS
def dispatch(self, request, *args, **kwargs):
# ###################### 第一步 ###########################
"""
request,是django的request,它的内部有:request.GET/request.POST/request.method
args,kwargs是在路由中匹配到的参数,如:
url(r'^order/(\d+)/(?P<version>\w+)/$', views.OrderView.as_view()),
http://www.xxx.com/order/1/v2/
"""
self.args = args
self.kwargs = kwargs
"""
request = 生成了一个新的request对象,此对象的内部封装了一些值。
request = Request(request)
- 内部封装了 _request = 老的request
"""
request = self.initialize_request(request, *args, **kwargs)
self.request = request
self.headers = self.default_response_headers # deprecate?
try:
# ###################### 第二步 ###########################
self.initial(request, *args, **kwargs)
执行视图函数。。
def initial(self, request, *args, **kwargs):
# ############### 2.1 处理drf的版本 ##############
version, scheme = self.determine_version(request, *args, **kwargs)
request.version, request.versioning_scheme = version, scheme
...
def determine_version(self, request, *args, **kwargs):
if self.versioning_class is None:
return (None, None)
#是版本类的实例化对象
scheme = self.versioning_class()
# obj = XXXXXXXXXXXX()
return (scheme.determine_version(request, *args, **kwargs), scheme)
class OrderView(APIView):
versioning_class = URLPathVersioning
def get(self,request,*args,**kwargs):
print(request.version)
print(request.versioning_scheme)
return Response('...')
def post(self,request,*args,**kwargs):
return Response('post')
1.局部配置
视图写法
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework.request import Request
from rest_framework.versioning import URLPathVersioning
class OrderView(APIView):
versioning_class = URLPathVersioning
def get(self,request,*args,**kwargs):
print(request.version)
print(request.versioning_scheme)
return Response('...')
def post(self,request,*args,**kwargs):
return Response('post')
setting配置
REST_FRAMEWORK = {
"ALLOWED_VERSIONS":['v1','v2'],
'VERSION_PARAM':'version'
}
2.全局配置
不用手动一个个加全部都配置上
url
url(r'^(?P<version>[v1|v2]+)/users/$', users_list, name='users-list'),
url(r'^(?P<version>\w+)/users/$', users_list, name='users-list'),
settings配置
REST_FRAMEWORK = {
指定版本类 必须要写要些路径 "DEFAULT_VERSIONING_CLASS":"rest_framework.versioning.URLPathVersioning",
#限制版本范围
"ALLOWED_VERSIONS":['v1','v2'],
#指定url有名分组的关键字
'VERSION_PARAM':'version'
}
认证
自定义认证token
把数据库的user拿出来比较
如果想使用**request.data 就要把他变为字典 所以前端要返回json数据类型
源码写法
#配置
authentication_classes = api_settings.DEFAULT_AUTHENTICATION_CLASSES
局部配置
和登陆配合使用
import uuid
from django.shortcuts import render
from django.views import View
from django.views.decorators.csrf import csrf_exempt
from django.utils.decorators import method_decorator
from rest_framework.versioning import URLPathVersioning
from rest_framework.views import APIView
from rest_framework.response import Response
class Loginview(APIView):
versioning_class = None
#认证写法
authentication_classes = [Myauthentication, ]
def post(self,request,*args,**kwargs):
user_object = models.UserInfo.objects.filter(**request.data).first()
if not user_object:
return Response('登录失败')
random_string = str(uuid.uuid4())
user_object.token = random_string
user_object.save()
return Response(random_string)
class MyAuthentication:
def authenticate(self, request):
"""
Authenticate the request and return a two-tuple of (user, token).
"""
token = request.query_params.get('token')
user_object = models.UserInfo.objects.filter(token=token).first()
if user_object:
return (user_object,token)
return (None,None)
class OrderView(APIView):
authentication_classes = [MyAuthentication, ]
def get(self,request,*args,**kwargs):
print(request.user)
print(request.auth)
return Response('order')
class UserView(APIView):
authentication_classes = [MyAuthentication,]
def get(self,request,*args,**kwargs):
print(request.user)
print(request.auth)
return Response('user')
···············手写认证类····························
class Myauthentication:
# 认证
# versioning_class = None
#手写认证
def authenticate(self, request):
token = request.query_params.get('token')
print(token)
user_object = models.UserInfo.objects.filter(token=token).first()
print(user_object)
if user_object:
print(1)
#必须返回一个元组的形式
#返回对应的user_object和token值
return (user_object, token)
else:
print(2)
return (None, None)
----------------------
为什么要返回元组
----------------------
#为什么要返回元组
def _authenticate(self):
"""
Attempt to authenticate the request using each authentication instance
in turn.
"""
for authenticator in self.authenticators:
try:
user_auth_tuple =
#到这返回为什么可以执行对应的方法
authenticator.authenticate(self)
except exceptions.APIException:
self._not_authenticated()
raise
if user_auth_tuple is not None:
#把查询出来的元组
self._authenticator = authenticator
#给user和auth进行赋值
self.user, self.auth = user_auth_tuple#必须返回一个元组的形式
return#结束函数
self._not_authenticated()
def _not_authenticated(self):
"""
Set authenticator, user & authtoken representing an unauthenticated request.
Defaults are None, AnonymousUser & None.
"""
self._authenticator = None
if api_settings.UNAUTHENTICATED_USER:
#user 没有设置返回none
self.user =
#匿名用户
api_settings.UNAUTHENTICATED_USER()
else:
self.user = None
if api_settings.UNAUTHENTICATED_TOKEN:
self.auth =
#对应author没有设置返回none
api_settings.UNAUTHENTICATED_TOKEN()
else:
self.auth = None
全局配置
DEFAULT_AUTHENTICATION_CLASSES=['写一个认证的类手写的']
class Myauthentication:
# 认证
# versioning_class = None
#手写认证
def authenticate(self, request):
token = request.query_params.get('token')
print(token)
user_object = models.UserInfo.objects.filter(token=token).first()
print(user_object)
if user_object:
print(1)
#必须返回一个元组的形式
#返回对应的user_object和token值
return (user_object, token)
else:
print(2)
return (None, None)
'''
# raise Exception(), 不在继续往下执行,直接返回给用户。
# return None ,本次认证完成,执行下一个认证
# return ('x',"x"),认证成功,不需要再继续执行其他认证了,继续往后权限、节流、视图函数
'''
view视图写法
class LoginView(APIView):
authentication_classes = []
def post(self,request,*args,**kwargs):
user_object = models.UserInfo.objects.filter(**request.data).first()
if not user_object:
return Response('登录失败')
random_string = str(uuid.uuid4())
user_object.token = random_string
user_object.save()
return Response(random_string)
class OrderView(APIView):
# authentication_classes = [TokenAuthentication, ]
def get(self,request,*args,**kwargs):
print(request.user)
print(request.auth)
if request.user:
return Response('order')
return Response('滚')
class UserView(APIView):
同上
源码执行流程
'''
当请求发过来的实话会先执行 apiview里面的dispath方法
1.执行认证的dispatch的方法
2.dispatch方法会执行initialize_request方法封装旧的request对象
3.在封装的过程中会执行
get_authenticators(self): 并实例化列表中的每一个认证类
如果自己写的类有对应的认证类 会把认证类的实例化对象封装到新的request当中
继续执行initial
会执行认证里面的perform_authentication 执行request.user
会执行循环每一个对象执行对应的authenticate方法
会有三种返回值
# raise Exception(), 不在继续往下执行,直接返回给用户。
# return None ,本次认证完成,执行下一个认证
# return ('x',"x"),认证成功,不需要再继续执行其他认证了,继续往后权限、节流、视图函数
里面会执行四件事
版本
认证
权限
节流
'''
def dispatch(self, request, *args, **kwargs):
"""
`.dispatch()` is pretty much the same as Django's regular dispatch,
but with extra hooks for startup, finalize, and exception handling.
"""
self.args = args
self.kwargs = kwargs
#封装旧的request
request = self.initialize_request(request, *args, **kwargs)
self.request = request
self.headers = self.default_response_headers # deprecate?
循环自定义的认证
#request封装旧的request执行initialize_request
def initialize_request(self, request, *args, **kwargs):
"""
Returns the initial request object.
"""
parser_context = self.get_parser_context(request)
return Request(
request,
parsers=self.get_parsers(),
authenticators=self.get_authenticators(),
negotiator=self.get_content_negotiator(),
parser_context=parser_context
)
def get_authenticators(self):
"""
Instantiates and returns the list of authenticators that this view can use.
"""
return [auth() for auth in self.authentication_classes]
def initial(self, request, *args, **kwargs):
"""
Runs anything that needs to occur prior to calling the method handler.
"""
self.format_kwarg = self.get_format_suffix(**kwargs)
# Perform content negotiation and store the accepted info on the request
neg = self.perform_content_negotiation(request)
request.accepted_renderer, request.accepted_media_type = neg
# Determine the API version, if versioning is in use.
version, scheme = self.determine_version(request, *args, **kwargs)
request.version, request.versioning_scheme = version, scheme
# Ensure that the incoming request is permitted
self.perform_authentication(request)
self.check_permissions(request)
self.check_throttles(request)
#执行完四件事在执行视图
权限
message=消息 自定义错误消息
可以自定义错误信息
'''
for permission in self.get_permissions():
if not permission.has_permission(request, self):
self.permission_denied(
request, message=getattr(permission, 'message', None)
)
'''
本质上自定义和
return Flase
单条验证
验证两次
不写url_kwarg默认封装识别pk关键字
重写错误信息的两种方式
第一种
message={"code":"恭喜你报错了"}
第二种
from rest_framework.permissions import BasePermission
from rest_framework import exceptions
class MyPermission(BasePermission):
#第一种
message = {'code': 10001, 'error': '你没权限'}
def has_permission(self, request, view):
#request.user执行认证
if request.user:
return True
#自定义错误信息
raise exceptions.PermissionDenied({'code': 10001, 'error': '你没权限'})
return False
def has_object_permission(self, request, view, obj):
"""
Return `True` if permission is granted, `False` otherwise.
"""
return False
#对应源码
相当于重写了错误信息
#执行顺序
dispatch---》intital--》check_permissions--》permission_denied
def permission_denied(self, request, message=None):
"""
If request is not permitted, determine what kind of exception to raise.
"""
if request.authenticators and not request.successful_authenticator:
raise exceptions.NotAuthenticated()
raise
#等于message 或者自定义错误函数
#raise exceptions.PermissionDenied({'code': 10001, 'error': '你没权限'})
exceptions.PermissionDenied(detail=message)
················源码··················
def check_permissions(self, request):
for permission in self.get_permissions():
if not permission.has_permission(request, self):
self.permission_denied(
request, message=getattr(permission, 'message', None)
)
源码剖析
执行流程
apiview
---
dispatch
---
initial
---
执行权限判断
如果自己写了权限类 会先循环权限类并实例化存在列表当中
然后循环列表对象,如果权限判断返回不为Ture机会进行主动抛出异常
可以自定义错误信息
具体代码
class APIView(View):
permission_classes = api_settings.DEFAULT_PERMISSION_CLASSES
def dispatch(self, request, *args, **kwargs):
封装request对象
self.initial(request, *args, **kwargs)
通过反射执行视图中的方法
def initial(self, request, *args, **kwargs):
版本的处理
# 认证
self.perform_authentication(request)
# 权限判断
self.check_permissions(request)
self.check_throttles(request)
#执行认证
def perform_authentication(self, request):
request.user
def check_permissions(self, request):
# [对象,对象,]
self.执行
'''
def get_permissions(self):
return [permission() for permission in self.permission_classes]
'''
for permission in self.get_permissions():
if not permission.has_permission(request, self):
self.permission_denied(request, message=getattr(permission, 'message', None))
def permission_denied(self, request, message=None):
if request.authenticators and not request.successful_authenticator:
raise exceptions.NotAuthenticated()
raise exceptions.PermissionDenied(detail=message)
#
class UserView(APIView):
permission_classes = [MyPermission, ]
def get(self,request,*args**kwargs):
return Response('user')
使用
class MyPermission(BasePermission):
message = {'code': 10001, 'error': '你没权限'}
def has_permission(self, request, view):
#request.user执行认证
if request.user:
return True
raise exceptions.PermissionDenied({'code': 10001, 'error': '你没权限'})
return False
def has_object_permission(self, request, view, obj):
"""
Return `True` if permission is granted, `False` otherwise.
"""
return False
class UserView(APIView):
先执行上面的数据
permission_classes = [MyPermission, ]
#再执行
def get(self,request,*args**kwargs):
return Response('user')
源码流程
def dispatch(self, request, *args, **kwargs):
"""
`.dispatch()` is pretty much the same as Django's regular dispatch,
but with extra hooks for startup, finalize, and exception handling.
"""
self.args = args
self.kwargs = kwargs
request = self.initialize_request(request, *args, **kwargs)
self.request = request
self.headers = self.default_response_headers # deprecate?
try:
#走这
self.initial(request, *args, **kwargs)
`````````````````def initial``````````````````````````
def initial(self, request, *args, **kwargs):
"""
Runs anything that needs to occur prior to calling the method handler.
"""
self.format_kwarg = self.get_format_suffix(**kwargs)
# Perform content negotiation and store the accepted info on the request
neg = self.perform_content_negotiation(request)
request.accepted_renderer, request.accepted_media_type = neg
# Determine the API version, if versioning is in use.
version, scheme =
'''
第三步
'''
self.determine_version(request, *args, **kwargs)
request.version, request.versioning_scheme = version, scheme
# Ensure that the incoming request is permitted
self.perform_authentication(request)
self.check_permissions(request)
self.check_throttles(request)
---------------------------------------
# 第二步
def check_permissions(self, request):
# [对象,对象,]
self.执行
'''
def get_permissions(self):
return [permission() for permission in self.permission_classes]
'''
for permission in self.get_permissions():
if not permission.has_permission(request, self):
self.permission_denied(request, message=getattr(permission, 'message', None))
def permission_denied(self, request, message=None):
if request.authenticators and not request.successful_authenticator:
raise exceptions.NotAuthenticated()
raise exceptions.PermissionDenied(detail=message)
第三步
def determine_version(self, request, *args, **kwargs):
if self.versioning_class is None:
return (None, None)
scheme = self.versioning_class()
return (scheme.determine_version(request, *args, **kwargs), scheme)
单挑数据的验证
单挑数据
def has_object_permission(self, request, view, obj):
"""
Return `True` if permission is granted, `False` otherwise.
"""
return False
#在执行RetrieveAPIView 会执行单挑数据的验证
def get_object(self):
queryset = self.filter_queryset(self.get_queryset())
# Perform the lookup filtering.
#不写url_kwarg默认封装识别pk关键字
lookup_url_kwarg = self.lookup_url_kwarg or self.lookup_field
assert lookup_url_kwarg in self.kwargs, (
'Expected view %s to be called with a URL keyword argument '
'named "%s". Fix your URL conf, or set the `.lookup_field` '
'attribute on the view correctly.' %
(self.__class__.__name__, lookup_url_kwarg)
)
filter_kwargs = {self.lookup_field: self.kwargs[lookup_url_kwarg]}
obj = get_object_or_404(queryset, **filter_kwargs)
# May raise a permission denied
#检验单挑数据的权限
self.check_object_permissions(self.request, obj)
return obj
···················check_object_permissions··········
def check_object_permissions(self, request, obj):
"""
Check if the request should be permitted for a given object.
Raises an appropriate exception if the request is not permitted.
"""
for permission in self.get_permissions():
if not permission.has_object_permission(request, self, obj):
self.permission_denied(
request, message=getattr(permission, 'message', None)
)
执行has_object_permission
def has_object_permission(self, request, view, obj):
return True
版本认证权限执行流程
1.首先所有方法都执行父类的apiview方法
2.执行dispatch方法
3.进行
def get_authenticators(self):
return [auth() for auth in self.authentication_classes]
4.
intiail request.user
如果代码中出现了CSRF使用装饰器即可
from django.views.decorators.csrf import csrf_exempt
from django.utils.decorators import method_decorator
def csrf_exempt(view_func):
"""
Marks a view function as being exempt from the CSRF view protection.
"""
# We could just do view_func.csrf_exempt = True, but decorators
# are nicer if they don't have side-effects, so we return a new
# function.
def wrapped_view(*args, **kwargs):
return view_func(*args, **kwargs)
wrapped_view.csrf_exempt = True
return wraps(view_func, assigned=available_attrs(view_func))(wrapped_view)
drf访问频率的限制
- 匿名用户,用IP作为用户唯一标记,但如果用户换代理IP,无法做到真正的限制。
- 登录用户,用用户名或用户ID做标识。可以做到真正的限制
知识点
当前这个字典存放在django的缓存中
{
throttle_anon_1.1.1.1:[100121340,],
1.1.1.2:[100121251,100120450,]
}
限制:60s能访问3次
来访问时:
1.获取当前时间 100121280
2.100121280-60 = 100121220,小于100121220所有记录删除全部剔除
3.判断1分钟以内已经访问多少次了? 4
判断访问次数
4.无法访问
停一会
来访问时:
1.获取当前时间 100121340
2.100121340-60 = 100121280,小于100121280所有记录删除
3.判断1分钟以内已经访问多少次了? 0
4.可以访问
执行流程
在视图类中配置 throttle_classes= [] 这是一个列表
实现 allow_request 方法 wait 是一个提示方法
返回 True/False。
True 可以继续访问,
False 表示限制
全局配置
DEFAULT_THROTTLE_CLASSE,节流限制类
DEFAULT_THROTTLE_RATES 表示频率限制,比如 10/m 表示 每分钟 10 次
源码在 initial 中实现 check_throttles 方法
在进行节流之前已经做了版本认证权限
#dispatch分发
def initial(self, request, *args, **kwargs):
#版本
version, scheme = self.determine_version(request, *args, **kwargs)
request.version, request.versioning_scheme = version, scheme
# Ensure that the incoming request is permitted
#认证
self.perform_authentication(request)
#权限
self.check_permissions(request)
#频率限制
self.check_throttles(request)
1.先找allow_request本类没有去父类找 同dispatch
2.执行对应的rate获取对应scope 节流的频率
2.key是获取ip值
3.history是获取ip地址 获取对应的访问时间记录
'''
self.history = self.cache.get(self.key, [])
'''
4.对应的访问记录等于ture获取到值,
把当前的时间减去一个自己设定的时间戳
'''
while self.history and self.history[-1] <= self.now - self.duration:
#条件满足 把最后一个值删除
#再去循环判断
self.history.pop()
'''
5.然后判断访问次数有没有大于自己设定的值
'''
if len(self.history) >= self.num_requests:
满足条件走这
return self.throttle_failure()
不满足条件走这
return self.throttle_success()
'''
6.成功 def throttle_success(self):
"""
Inserts the current request's timestamp along with the key
into the cache.
"""
self.history.insert(0, self.now)
self.cache.set(self.key, self.history, self.duration)
return True
6.失败
def throttle_failure(self):
"""
Called when a request to the API has failed due to throttling.
"""
return False#不可以访问
7如果返回false进入等待时间
def wait(self):
"""
Returns the recommended next request time in seconds.
"""
if self.history:
remaining_duration = self.duration - (self.now - self.history[-1])
else:
remaining_duration = self.duration
available_requests = self.num_requests - len(self.history) + 1
if available_requests <= 0:
return None
return remaining_duration / float(available_requests)
源码
#dispatch分发
def initial(self, request, *args, **kwargs):
#版本
version, scheme = self.determine_version(request, *args, **kwargs)
request.version, request.versioning_scheme = version, scheme
# Ensure that the incoming request is permitted
#认证
self.perform_authentication(request)
#权限
self.check_permissions(request)
#频率限制
self.check_throttles(request)
def check_throttles(self, request):
throttle_durations = []
for throttle in self.get_throttles():
#找到当前类的allow_request
if not throttle.allow_request(request, self):
throttle_durations.append(throttle.wait())
if throttle_durations:
durations = [
duration for duration in throttle_durations
if duration is not None
]
duration = max(durations, default=None)
self.throttled(request, duration)
#执行类的allow_request
def allow_request(self, request, view):
"""
Implement the check to see if the request should be throttled.
On success calls `throttle_success`.
On failure calls `throttle_failure`.
"""
if self.rate is None:
return True
获取
'''
def __init__(self):
if not getattr(self, 'rate', None):
self.rate = self.get_rate()
self.num_requests, self.duration = self.parse_rate(self.rate)
当前这个类有一个获取rate的方法
'''
#执行get_rate
读取settings设置的配置文件
'''
def get_rate(self):
#如果不设置会进行报错
try:
#设置了就进行键取值
return self.THROTTLE_RATES[self.scope]
except KeyError:
msg = "No default throttle rate set for '%s' scope" % self.scope
raise ImproperlyConfigured(msg)
'''
#通过键去取值/进行分割获取值
'''
def parse_rate(self, rate):
if rate is None:
return (None, None)
num, period = rate.split('/')
num_requests = int(num)
duration = {'s': 1, 'm': 60, 'h': 3600, 'd': 86400}[period[0]]
return (num_requests, duration)
'''
#这步继续往下执行继承类的get_cache_key
self.key = self.get_cache_key(request, view)
#匿名
#继承了class AnonRateThrottle(SimpleRateThrottle):
'''
scope = 'anon'
def get_cache_key(self, request, view):
if request.user.is_authenticated:
return None # Only throttle unauthenticated requests.
return self.cache_format % {
'scope': self.scope,
'ident': self.get_ident(request)
}
}
#返回字符串格式化
throttle_(匿名)anon_(ip地址的拼接)1.1.1.1:[100121340,],
'''
#根据用户进行判断 重写get_cache_key
'''
'''
if self.key is None:
return True
self.history = self.cache.get(self.key, [])
self.now = self.timer()
# Drop any requests from the history which have now passed the
# throttle duration
while self.history and self.history[-1] <= self.now - self.duration:
self.history.pop()
#元组返回的值num_requests
if len(self.history) >= self.num_requests:
#不可以访问
return self.throttle_failure()
#可以访问
return self.throttle_success()
'''
6.成功 def throttle_success(self):
#成功把访问的当前时间插入history
self.history.insert(0, self.now)
self.cache.set(self.key, self.history, self.duration)
return True
6.失败
def throttle_failure(self):
"""
Called when a request to the API has failed due to throttling.
"""
return False#不可以访问
'''
默认配置文件写法settings
REST_FRAMEWORK = {
throttle_classes = [AnonRateThrottle,]
"DEFAULT_THROTTLE_RATES":{"anon":"3/m"}
#这样写的原因 源码
#通过匿名
scope = 'anon'
def get_cache_key(self, request, view):
if request.user.is_authenticated:
return None # Only throttle unauthenticated requests.
return self.cache_format % {
'scope': self.scope,
'ident': self.get_ident(request)
}
}
#获取全局设置的步骤
def __init__(self):
if not getattr(self, 'rate', None):
#第一步
self.rate = self.get_rate()
'''
以设置的键进行取值获取时间
def get_rate(self):
如果不设置就进行报错
try:
return self.THROTTLE_RATES[self.scope]
except KeyError:
msg = "No default throttle rate set for '%s' scope" % self.scope
raise ImproperlyConfigured(msg)
'''
self.num_requests, self.duration = self.parse_rate(self.rate)
#后面设置值格式
#例 "DEFAULT_THROTTLE_RATES":{"anon":"3/m"}
以/分割 前面是限制的次数 后面的是访问限制的时间
'''
def parse_rate(self, rate):
if rate is None:
return (None, None)
num, period = rate.split('/')
num_requests = int(num)
duration = {'s': 1, 'm': 60, 'h': 3600, 'd': 86400}[period[0]]
return (num_requests, duration)
'''
之后执行对应字典的取值
key=throttle_(匿名)anon_(ip地址的拼接)1.1.1.1:
[100121340,],#值
self.key = self.get_cache_key(request, view)
if self.key is None:
return True
self.history = self.cache.get(self.key, [])
self.now = self.timer()
# Drop any requests from the history which have now passed the
# throttle duration
while self.history and self.history[-1] <= self.now - self.duration:
self.history.pop()
if len(self.history) >= self.num_requests:
return self.throttle_failure()
return self.throttle_success()
根据匿名用户和id进行判断
全局配置
REST_FRAMEWORK = {
'DEFAULT_THROTTLE_CLASSES': [
'api.utils.throttles.throttles.LuffyAnonRateThrottle',
'api.utils.throttles.throttles.LuffyUserRateThrottle',
],
'DEFAULT_THROTTLE_RATES': {
#不重写的默认走这
'anon': '10/day',
'user': '10/day',
'luffy_anon': '10/m',
'luffy_user': '20/m',
},
}
settings
url写法
from django.conf.urls import url, include
from web.views.s3_throttling import TestView
urlpatterns = [
url(r'^test/', TestView.as_view()),
]
urls.py
settings写法局部
REST_FRAMEWORK = {
'UNAUTHENTICATED_USER': None,
'UNAUTHENTICATED_TOKEN': None,
'DEFAULT_THROTTLE_RATES': {
'luffy_anon': '10/m',
'luffy_user': '20/m',
},
}
settings.py
根据匿名ip或者user 进行判断
视图写法
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework.throttling import SimpleRateThrottle
class LuffyAnonRateThrottle(SimpleRateThrottle):
"""
匿名用户,根据IP进行限制
"""
scope = "luffy_anon"
def get_cache_key(self, request, view):
# 用户已登录,则跳过 匿名频率限制
if request.user:
return None
return self.cache_format % {
'scope': self.scope,
'ident': self.get_ident(request)
}
class LuffyUserRateThrottle(SimpleRateThrottle):
"""
登录用户,根据用户token限制
"""
#重写scope
scope = "luffy_user"
def get_ident(self, request):
"""
认证成功时:request.user是用户对象;request.auth是token对象
:param request:
:return:
"""
# return request.auth.token
return "user_token"
def get_cache_key(self, request, view):
"""
获取缓存key
:param request:
:param view:
:return:
"""
# 未登录用户,则跳过 Token限制
if not request.user:
return None
return self.cache_format % {
'scope': self.scope,
'ident': self.get_ident(request)
}
class TestView(APIView):
throttle_classes = [LuffyUserRateThrottle, LuffyAnonRateThrottle, ]
def get(self, request, *args, **kwargs):
# self.dispatch
print(request.user)
print(request.auth)
return Response('GET请求,响应内容')
def post(self, request, *args, **kwargs):
return Response('POST请求,响应内容')
def put(self, request, *args, **kwargs):
return Response('PUT请求,响应内容')
```````````````````````````````````````````
#源码
class AnonRateThrottle(SimpleRateThrottle):
scope = 'anon'
def get_cache_key(self, request, view):
if request.user.is_authenticated:
return None
# Only throttle unauthenticated requests.
return self.cache_format % {
'scope': self.scope,
'ident': self.get_ident(request)
}
#
def get_cache_key(self, request, view):
return self.get_ident(request)#获取对应的ip值
settings
# settings.py
'DEFAULT_THROTTLE_RATES': {
'Vistor': '3/m',
'User': '10/m'
},
drf总结
django'中后端可以免除csrftoken的认证
from django.views.decorators.csrf import csrf_exempt
from django.shortcuts import HttpResponse
@csrf_exempt def index(request):
return HttpResponse('...')
# index = csrf_exempt(index)
urlpatterns = [
url(r'^index/$',index),
]
drf中view进行csrftoken的认证
urlpatterns = [ url(r'^login/$',account.LoginView.as_view()),
]
class APIView(View):
@classmethod
def as_view(cls, **initkwargs):
view = super().as_view(**initkwargs)
view.cls = cls
view.initkwargs = initkwargs
# Note: session based authentication is explicitly CSRF validated,
# all other authentication is CSRF exempt.
return csrf_exempt(view)
1.写视图的方法
-
第一种:原始APIView
url(r'^login/$',account.LoginView.as_view()),from rest_framework.views import APIView from rest_framework.response import Response from rest_framework_jwt.settings import api_settings from rest_framework.throttling import AnonRateThrottle from api import models class LoginView(APIView): authentication_classes = [] def post(self,request,*args,**kwargs): # 1.根据用户名和密码检测用户是否可以登录 user = models.UserInfo.objects.filter(username=request.data.get('username'),password=request.data.get('password')).first() if not user: return Response({'code':10001,'error':'用户名或密码错误'}) # 2. 根据user对象生成payload(中间值的数据) jwt_payload_handler = api_settings.JWT_PAYLOAD_HANDLER payload = jwt_payload_handler(user) # 3. 构造前面数据,base64加密;中间数据base64加密;前两段拼接然后做hs256加密(加盐),再做base64加密。生成token jwt_encode_handler = api_settings.JWT_ENCODE_HANDLER token = jwt_encode_handler(payload) return Response({'code': 10000, 'data': token}) -
第二种:ListApiView等
url(r'^article/$',article.ArticleView.as_view()), url(r'^article/(?P<pk>\d+)/$',article.ArticleDetailView.as_view()),from rest_framework.throttling import AnonRateThrottle from rest_framework.response import Response from rest_framework.generics import ListAPIView,RetrieveAPIView from api import models from api.serializer.article import ArticleSerializer,ArticleDetailSerializer class ArticleView(ListAPIView): authentication_classes = [] # throttle_classes = [AnonRateThrottle,] queryset = models.Article.objects.all() serializer_class = ArticleSerializer class ArticleDetailView(RetrieveAPIView): authentication_classes = [] queryset = models.Article.objects.all() serializer_class = ArticleDetailSerializer -
第三种:
url(r'^article/$',article.ArticleView.as_view({"get":'list','post':'create'})), url(r'^article/(?P<pk>\d+)/$',article.ArticleView.as_view({'get':'retrieve','put':'update','patch':'partial_update','delete':'destroy'}))from rest_framework.viewsets import GenericViewSet from rest_framework.mixins import ListModelMixin,RetrieveModelMixin,CreateModelMixin,UpdateModelMixin,DestroyModelMixin from api.serializer.article import ArticleSerializer,ArticleDetailSerializer class ArticleView(GenericViewSet,ListModelMixin,RetrieveModelMixin,CreateModelMixin,UpdateModelMixin,DestroyModelMixin): authentication_classes = [] throttle_classes = [AnonRateThrottle,] queryset = models.Article.objects.all() serializer_class = None def get_serializer_class(self): pk = self.kwargs.get('pk') if pk: return ArticleDetailSerializer return ArticleSerializer
drf 相关知识点梳理
-
装饰器
def outer(func): def inner(*args,**kwargs): return func(*args,**kwargs) return inner @outer def index(a1): pass index()def outer(func): def inner(*args,**kwargs): return func(*args,**kwargs) return inner def index(a1): pass index = outer(index) index() -
django中可以免除csrftoken认证
from django.views.decorators.csrf import csrf_exempt from django.shortcuts import HttpResponse @csrf_exempt def index(request): return HttpResponse('...') # index = csrf_exempt(index) urlpatterns = [ url(r'^index/$',index), ]urlpatterns = [ url(r'^login/$',account.LoginView.as_view()), ] class APIView(View): @classmethod def as_view(cls, **initkwargs): view = super().as_view(**initkwargs) view.cls = cls view.initkwargs = initkwargs # Note: session based authentication is explicitly CSRF validated, # all other authentication is CSRF exempt. return csrf_exempt(view) -
面向对象中基于继承+异常处理来做的约束
class BaseVersioning: def determine_version(self, request, *args, **kwargs): raise NotImplementedError("must be implemented") class URLPathVersioning(BaseVersioning): def determine_version(self, request, *args, **kwargs): version = kwargs.get(self.version_param, self.default_version) if version is None: version = self.default_version if not self.is_allowed_version(version): raise exceptions.NotFound(self.invalid_version_message) return version -
面向对象封装
class Foo(object): def __init__(self,name,age): self.name = name self.age = age obj = Foo('汪洋',18)class APIView(View): def dispatch(self, request, *args, **kwargs): self.args = args self.kwargs = kwargs request = self.initialize_request(request, *args, **kwargs) self.request = request ... def initialize_request(self, request, *args, **kwargs): """ Returns the initial request object. """ parser_context = self.get_parser_context(request) return Request( request, parsers=self.get_parsers(), authenticators=self.get_authenticators(), # [MyAuthentication(),] negotiator=self.get_content_negotiator(), parser_context=parser_context ) -
面向对象继承
class View(object): pass class APIView(View): def dispatch(self): method = getattr(self,'get') method() class GenericAPIView(APIView): serilizer_class = None def get_seriliser_class(self): return self.serilizer_class class ListModelMixin(object): def get(self): ser_class = self.get_seriliser_class() print(ser_class) class ListAPIView(ListModelMixin,GenericAPIView): pass class UserInfoView(ListAPIView): pass view = UserInfoView() view.dispatch()class View(object): pass class APIView(View): def dispatch(self): method = getattr(self,'get') method() class GenericAPIView(APIView): serilizer_class = None def get_seriliser_class(self): return self.serilizer_class class ListModelMixin(object): def get(self): ser_class = self.get_seriliser_class() print(ser_class) class ListAPIView(ListModelMixin,GenericAPIView): pass class UserInfoView(ListAPIView): serilizer_class = "汪洋" view = UserInfoView() view.dispatch()class View(object): pass class APIView(View): def dispatch(self): method = getattr(self,'get') method() class GenericAPIView(APIView): serilizer_class = None def get_seriliser_class(self): return self.serilizer_class class ListModelMixin(object): def get(self): ser_class = self.get_seriliser_class() print(ser_class) class ListAPIView(ListModelMixin,GenericAPIView): pass class UserInfoView(ListAPIView): def get_seriliser_class(self): return "咩咩" view = UserInfoView() view.dispatch() -
反射
class View(object): def dispatch(self, request, *args, **kwargs): # Try to dispatch to the right method; if a method doesn't exist, # defer to the error handler. Also defer to the error handler if the # request method isn't on the approved list. if request.method.lower() in self.http_method_names: handler = getattr(self, request.method.lower(), self.http_method_not_allowed) else: handler = self.http_method_not_allowed return handler(request, *args, **kwargs) -
发送ajax请求
$.ajax({ url:'地址', type:'GET', data:{...}, success:function(arg){ console.log(arg); } }) -
浏览器具有 "同源策略的限制",导致
发送ajax请求+跨域存在无法获取数据。- 简单请求,发送一次请求。
- 复杂请求,先options请求做预检,然后再发送真正请求
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <h1>常鑫的网站</h1> <p> <input type="button" value="点我" onclick="sendMsg()"> </p> <p> <input type="button" value="点他" onclick="sendRemoteMsg()"> </p> <script src="https://cdn.bootcss.com/jquery/3.4.1/jquery.min.js"></script> <script> function sendMsg() { $.ajax({ url:'/msg/', type:'GET', success:function (arg) { console.log(arg); } }) } function sendRemoteMsg() { $.ajax({ url:'http://127.0.0.1:8002/json/', type:'GET', success:function (arg) { console.log(arg); } }) } </script> </body> </html> -
如何解决ajax+跨域?
CORS,跨站资源共享,本质:设置响应头。 -
常见的Http请求方法
get post put patch delete options -
http请求中Content-type请起头
情况一: content-type:x-www-form-urlencode name=alex&age=19&xx=10 request.POST和request.body中均有值。 情况二: content-type:application/json {"name":"ALex","Age":19} request.POST没值 request.body有值。 -
django中F查询
-
django中获取空Queryset
models.User.object.all().none() -
基于django的fbv和cbv都能实现遵循restful规范的接口
def user(request): if request.metho == 'GET': pass class UserView(View): def get()... def post... -
基于django rest framework框架实现restful api的开发。
- 免除csrf认证 - 视图(APIView、ListAPIView、ListModelMinx) - 版本 - 认证 - 权限 - 节流 - 解析器 - 筛选器 - 分页 - 序列化 - 渲染器 -
简述drf中认证流程?
1.用户发来请求优先执行dispatch方法 2.内部会封装reqeustd1 -
简述drf中节流的实现原理以及过程?匿名用户/非匿名用户 如何实现频率限制?
-
GenericAPIView视图类的作用?
他提供了一些规则,例如: class GenericAPIView(APIView): serializer_class = None queryset = None lookup_field = 'pk' filter_backends = api_settings.DEFAULT_FILTER_BACKENDS pagination_class = api_settings.DEFAULT_PAGINATION_CLASS def get_queryset(self): return self.queryset def get_serializer_class(self): return self.serializer_class def filter_queryset(self, queryset): for backend in list(self.filter_backends): queryset = backend().filter_queryset(self.request, queryset, self) return queryset @property def paginator(self): if not hasattr(self, '_paginator'): if self.pagination_class is None: self._paginator = None else: self._paginator = self.pagination_class() return self._paginator 他相当于提供了一些规则,建议子类中使用固定的方式获取数据,例如: class ArticleView(GenericAPIView): queryset = models.User.objects.all() def get(self,request,*args,**kwargs): query = self.get_queryset() 我们可以自己继承GenericAPIView来实现具体操作,但是一般不会,因为更加麻烦。 而GenericAPIView主要是提供给drf内部的 ListAPIView、Create.... class ListModelMixin: def list(self, request, *args, **kwargs): queryset = self.filter_queryset(self.get_queryset()) page = self.paginate_queryset(queryset) if page is not None: serializer = self.get_serializer(page, many=True) return self.get_paginated_response(serializer.data) serializer = self.get_serializer(queryset, many=True) return Response(serializer.data) class ListAPIView(mixins.ListModelMixin,GenericAPIView): def get(self, request, *args, **kwargs): return self.list(request, *args, **kwargs) class MyView(ListAPIView): queryset = xxxx ser...总结:GenericAPIView主要为drf内部帮助我们提供增删改查的类LIstAPIView、CreateAPIView、UpdateAPIView、提供了执行流程和功能,我们在使用drf内置类做CURD时,就可以通过自定义 静态字段(类变量)或重写方法(get_queryset、get_serializer_class)来进行更高级的定制。 -
jwt以及其优势。
jwt前后端分离 用于用户认证 jwt的实现原理: -用户登陆成功,会给前端返回一个tokon值。 此token值只在前端保存 token值分为 一段类型和算法信息 第二段用户信息和超时时间 第三段前两段数据拼接之后进行has256再次加密+base64url -
序列化时many=True和many=False的区别?
-
应用DRF中的功能进行项目开发
***** 解析器:request.query_parmas/request.data 视图 序列化 渲染器:Response **** request对象封装 版本处理 分页处理 *** 认证 权限 节流- 基于APIView实现呼啦圈
- 继承ListAPIView+ GenericViewSet,ListModelMixin实现呼啦圈
跨域
- 域相同,永远不会存在跨域。
- crm,非前后端分离,没有跨域。
- 路飞学城,前后端分离,没有跨域(之前有,现在没有)。
- 域不同时,才会存在跨域。
- l拉勾网,前后端分离,存在跨域(设置响应头解决跨域)
由于浏览器具有同源策略的限制
对ajax请求的限制 javascript的src对应src不进行限制
同源同端口
不同源就是跨域
写了/api 不跨域 api访问django
api.xx.com跨域了访问django
简单请求
发一次请求
url视图写法
html写法
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body>
<p>
<input type="submit" onclick="JqSendRequest();" />
</p>
<script type="text/javascript" src="jquery-1.12.4.js"> </script>
<script>
function JqSendRequest(){
$.ajax({
url: "http://c2.com:8000/json/",
type: 'GET',
dataType: 'text',
success: function(data){
console.log(data);
}
})
}
</script>
</body>
</html>
view视图写法
设置响应头就可以解决
from django.shortcuts import render,HttpResponse
def json(request):
response = HttpResponse("JSONasdfasdf")
#下面这个响应头信息是告诉浏览器,不要拦着,我就给它,"*"的意思是谁来请求我,我都给
response['Access-Control-Allow-Origin'] = "*"
response["Access-Control-Allow-Origin"] = "http://127.0.0.1:8000" #只有这个ip和端口来的请求,我才给他数据,其他你浏览器帮我拦着
return response
复杂请求
预检option
请求
html写法
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body>
<p>
<input type="submit" onclick="JqSendRequest();" />
</p>
<script type="text/javascript" src="jquery-1.12.4.js"> </script>
<script>
function JqSendRequest(){
$.ajax({
url: "http://c2.com:8000/put_json/",
type: 'PUT',
dataType: 'text',
success: function(data){
console.log(data);
}
})
}
</script>
</body>
</html>
写法
from django.views.decorators.csrf import csrf_exempt
from django.utils.decorators import method_decorator
@csrf_exempt
def put_json(request):
response = HttpResponse("JSON复杂请求")
if request.method == 'OPTIONS':
# 处理预检
response['Access-Control-Allow-Origin'] = "*"
response['Access-Control-Allow-Methods'] = "PUT"
return response
elif request.method == "PUT":
return response
解决跨域:CORS
本质在数据返回值设置响应头
from django.shortcuts import render,HttpResponse
def json(request):
response = HttpResponse("JSONasdfasdf")
response['Access-Control-Allow-Origin'] = "*"
return response
通过jsonp
有一个弊端只能使用get方法
jsonp是json用来跨域的一个东西。原理是通过script标签的跨域特性来绕过同源策略。
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body>
<p>
<input type="button" onclick="Jsonp1();" value='提交'/>
</p>
<p>
<input type="button" onclick="Jsonp2();" value='提交'/>
</p>
<script type="text/javascript" src="jquery-1.12.4.js"></script>
<script>
function Jsonp1(){
var tag = document.createElement('script');
tag.src = "http://c2.com:8000/test/";
document.head.appendChild(tag);
document.head.removeChild(tag);
}
function Jsonp2(){
$.ajax({
url: "http://c2.com:8000/test/",
type: 'GET',
dataType: 'JSONP',
success: function(data, statusText, xmlHttpRequest){
console.log(data);
}
})
}
</script>
</body>
</html>
总结
条件:
1、请求方式:HEAD、GET、POST
2、请求头信息:
Accept
Accept-Language
Content-Language
Last-Event-ID
Content-Type 对应的值是以下三个中的任意一个
application/x-www-form-urlencoded
multipart/form-data
text/plain
注意:同时满足以上两个条件时,则是简单请求,否则为复杂请求
总结
1. 由于浏览器具有“同源策略”的限制,所以在浏览器上跨域发送Ajax请求时,会被浏览器阻止。
2. 解决跨域
- 不跨域
- CORS(跨站资源共享,本质是设置响应头来解决)。
- 简单请求:发送一次请求
- 复杂请求:发送两次请求
部署 collectstaic 收集静态文件
jwt

用于在前后端分离时,实现用户登录相关。
1.知识点
1.2jwt代替token 进行优化
用户登录成功之后,生成一个随机字符串,给前端。
- 生成随机字符串
加密信息
#{typ:"jwt","alg":'HS256'}
# 加密手段segments.append(base64url_encode(json_header))
98qow39df0lj980945lkdjflo.
#第二部分的信息 {id:1,username:'alx','exp':10}
#加密手段segments.append(base64url_encode(payload))
saueoja8979284sdfsdf.
#两个密文拼接加盐
asiuokjd978928374
- 类型信息通过base64加密
- 数据通过base64加密
- 两个密文拼接在h256加密+加盐
- 给前端返回token值只在前端
token是由。分割的三段组成
- 第一段:类型和算法信息
- 第二段。 用户的信息和超时时间
- 第三段:hs256(前两段拼接)加密 + base64url
- 以后前端再次发来信息时
- 超时验证
- token合法性校验
前端获取随机字符串之后,保留起来。
以后再来发送请求时,携带98qow39df0lj980945lkdjflo.saueoja8979284sdfsdf.asiuokjd978928375。
后端接收到之后
1.取出第二部分进行时间的判断
2. 把前面两个进行加密对第三个值进行加密
- token只在前端保存,后端只负责校验。
- 内部集成了超时时间,后端可以根据时间进行校验是否超时。 - 由于内部存在hash256加密,所以用户不可以修改token,只要一修改就认证失败。
一般在前后端分离时,用于做用户认证(登录)使用的技术。
jwt的实现原理:
- 用户登录成功之后,会给前端返回一段token。
- token是由.分割的三段组成。
- 第一段:类型和算法信心
- 第二段:用户信息+超时时间
- 第三段:hs256(前两段拼接)加密 + base64url
- 以后前端再次发来信息时
- 超时验证
- token合法性校验
优势:
- token只在前端保存,后端只负责校验。
- 内部集成了超时时间,后端可以根据时间进行校验是否超时。
- 由于内部存在hash256加密,所以用户不可以修改token,只要一修改就认证失败。
1.2token
用户登陆成功之后,生成一个随机字符串,自己保留一份,给前端返回一份。
以后前端再来发请求时,需要携带字符串
后端对字符串进行校验
流程
1.安装
pip3 install djangorestframework-jwt
2.注册
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'api.apps.ApiConfig',
'rest_framework',
'rest_framework_jwt']
3.源码剖析和实现流程
from rest_framework_jwt.views import obtain_jwt_token
具体流程
用户信息加密
jwt_payload_hander = api_settings.JWT_PAYLOAD_HANDLER
第三段信息的加密
jwt_encode_handler = api_settings.JWT_ENCODE_HANDLER
#解密
jwt_decode_handler = api_settings.JWT_DECODE_HANDLER
def jwt_payload_handler(user):
username_field = get_username_field()
username = get_username(user)
warnings.warn(
'The following fields will be removed in the future: '
'`email` and `user_id`. ',
DeprecationWarning
)
payload = {
'user_id': user.pk,
'username': username,
'exp': datetime.utcnow() +
#默认5分钟
api_settings.JWT_EXPIRATION_DELTA
#如果有email会把email配置上
if hasattr(user, 'email'):
payload['email'] = user.email
if isinstance(user.pk, uuid.UUID):
#如果有user_id会把pk值配置上
payload['user_id'] = str(user.pk)
payload[username_field] = username
#源码
settings= 'JWT_EXPIRATION_DELTA':datetime.timedelta(seconds=300)
,
}
加密的具体实现流程
api_settings.JWT_ENCODE_HANDLER -->
加密的具体实现
def jwt_encode_handler(payload):
#payload传入
key = api_settings.JWT_PRIVATE_KEY or jwt_get_secret_key(payload)
#加盐
#SECRET_KEY = '+gr4bbq8e$yqbd%n_h)2(osz=bmk1x2+o6+w5g@a4r1#3%q1n*'
return jwt.encode(
payload,#类型信息头信息
key,#加盐
#默认封装传入了hs256
api_settings.JWT_ALGORITHM
# 'JWT_ALGORITHM': 'HS256',
).decode('utf-8')
encode默认继承父类的
父类的encode方法
# Header
header = {'typ': self.header_typ, 'alg': algorithm}
#self.header_typ #-- 》 header_typ = 'JWT'
signing_input = b'.'.join(segments)#把类型信息和数据用.的形式拼接到了一起
try:
alg_obj = self._algorithms[algorithm]#执行算法
key = alg_obj.prepare_key(key)
signature = alg_obj.sign(signing_input, key)#把拼接起来的值进行二次加密 成为第三个信息
'''
except KeyError:
if not has_crypto and algorithm in requires_cryptography:
raise NotImplementedError(
"Algorithm '%s' could not be found. Do you have cryptography "
"installed?" % algorithm
)
else:
raise NotImplementedError('Algorithm not supported')
'''
segments.append(base64url_encode(signature))#再把第三个信息放入列表 对第三个信息进行base64进行加密
return b'.'.join(segments)#用.的形式再把第三个数据拼接起来 进行返回
98qow39df0lj980945lkdjflo.saueoja8979284sdfsdf.asiuokjd978928375
解密
将token分割成 header_segment、payload_segment、crypto_segment 三部分
对第一部分header_segment进行base64url解密,得到header
对第二部分payload_segment进行base64url解密,得到payload
对第三部分crypto_segment进行base64url解密,得到signature
对第三部分signature部分数据进行合法性校验
拼接前两段密文,即:signing_input
从第一段明文中获取加密算法,默认:HS256
使用 算法+盐 对signing_input 进行加密,将得到的结果和signature密文进行比较。
jwt的原理和优势
一般在前后端分离时,用于做用户认证(登录)使用的技术。
jwt的实现原理:
- 用户登录成功之后,会给前端返回一段token。
- token是由.分割的三段组成。
- 第一段:类型和算法信心
- 第二段:用户信息+超时时间
- 第三段:hs256(前两段拼接)加密 + base64url
- 以后前端再次发来信息时
- 超时验证
- token合法性校验
#优势:
- token只在前端保存,后端只负责校验。
- 内部集成了超时时间,后端可以根据时间进行校验是否超时。
- 由于内部存在hash256加密,所以用户不可以修改token,只要一修改就认证失败。
具体使用
用户登陆
import uuid
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework.versioning import URLPathVersioning
from rest_framework import status
from api import models
class LoginView(APIView):
"""
登录接口
"""
def post(self,request,*args,**kwargs):
# 基于jwt的认证
# 1.去数据库获取用户信息
from rest_framework_jwt.settings import api_settings
#头信息
jwt_payload_handler = api_settings.JWT_PAYLOAD_HANDLER
#第三个数据的加密
jwt_encode_handler = api_settings.JWT_ENCODE_HANDLER
user = models.UserInfo.objects.filter(**request.data).first()
if not user:
return Response({'code':1000,'error':'用户名或密码错误'})
'''
'user_id': user.pk,
'username': username,
'exp': datetime.utcnow() + api_settings.JWT_EXPIRATION_DELTA
'''
#头信息的处理
payload = jwt_payload_handler(user)
#对三段信息的编码 加密
token = jwt_encode_handler(payload)
return Response({'code':1001,'data':token})
#第二种方式
class LoginView(APIView):
authentication_classes = []
def post(self,request,*args,**kwargs):
# 1.根据用户名和密码检测用户是否可以登录
user = models.UserInfo.objects.filter(username=request.data.get('username'),password=request.data.get('password')).first()
if not user:
return Response({'code':10001,'error':'用户名或密码错误'})
# 2. 根据user对象生成payload(中间值的数据)
jwt_payload_handler = api_settings.JWT_PAYLOAD_HANDLER
payload = jwt_payload_handler(user)
# 3. 构造前面数据,base64加密;中间数据base64加密;前两段拼接然后做hs256加密(加盐),再做base64加密。生成token
jwt_encode_handler = api_settings.JWT_ENCODE_HANDLER
token = jwt_encode_handler(payload)
return Response({'code': 10000, 'data': token})
用户认证
开始解码
from rest_framework.views import APIView
from rest_framework.response import Response
# from rest_framework.throttling import AnonRateThrottle,BaseThrottle
class ArticleView(APIView):
# throttle_classes = [AnonRateThrottle,]
def get(self,request,*args,**kwargs):
# 获取用户提交的token,进行一步一步校验
import jwt
from rest_framework import exceptions
from rest_framework_jwt.settings import api_settings
#进行解码
jwt_decode_handler = api_settings.JWT_DECODE_HANDLER
#获取到加密之后的字符串
jwt_value = request.query_params.get('token')
try:
#对token进行解密
payload = jwt_decode_handler(jwt_value)
#判断签名是否过期
except jwt.ExpiredSignature:
msg = '签名已过期'
raise exceptions.AuthenticationFailed(msg)
#判断是否被篡改
except jwt.DecodeError:
msg = '认证失败'
raise exceptions.AuthenticationFailed(msg)
except jwt.InvalidTokenError:
raise exceptions.AuthenticationFailed()
print(payload)
return Response('文章列表')
settings设置
'JWT_EXPIRATION_DELTA':datetime.timedelta(seconds=300)
#默认五分钟有效
#自定义
import datetime
JWT_AUTH = {
"JWT_EXPIRATION_DELTA":datetime.timedelta(minutes=10)
}
视图的mixins写法
ListModelMixin
执行list方法
as_view 传参数
paramiko
用于帮助开发者通过代码远程连接服务器
公钥和私钥进行连接服务器 比较方便
$ssh -copy-id -i .ssh /id ras.pub
基于用户名密码连接:
需要一直去使用输入
import paramiko
# 创建SSH对象
ssh = paramiko.SSHClient()
# 允许连接不在know_hosts文件中的主机
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 连接服务器
ssh.connect(hostname='192.168.159.128', port=22, username='root', password='ziwen123')
# 执行命令
stdin, stdout, stderr = ssh.exec_command('df')
# 获取命令结果
result = stdout.read()
# 关闭连接
ssh.close()
``````````````````````````````````````````````````````
发送数据
import requests
requests.post(
url = "http://127.0.0.1:8000/api/v1/server/",
json={'server':data,'host':'192.16.12.66'}
)
远程执行命令【公钥和私钥】(公钥必须提前上传到服务器)
import paramiko
private_key = paramiko.RSAKey.from_private_key_file('/home/auto/.ssh/id_rsa')
# 创建SSH对象
ssh = paramiko.SSHClient()
# 允许连接不在know_hosts文件中的主机
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 连接服务器
ssh.connect(hostname='c1.salt.com', port=22, username='wupeiqi', key=private_key)
# 执行命令
stdin, stdout, stderr = ssh.exec_command('df')
# 获取命令结果
result = stdout.read()
# 关闭连接
ssh.close()
远程上传和下载文件【用户名和密码】
import paramiko
transport = paramiko.Transport(('hostname',22))
transport.connect(username='wupeiqi',password='123')
sftp = paramiko.SFTPClient.from_transport(transport)
# 将location.py 上传至服务器 /tmp/test.py
sftp.put('/tmp/location.py', '/tmp/test.py')
# 将remove_path 下载到本地 local_path
sftp.get('remove_path', 'local_path')
transport.close()
远程上传和下载文件【公钥和私钥】
import paramiko
private_key = paramiko.RSAKey.from_private_key_file('/home/auto/.ssh/id_rsa')
transport = paramiko.Transport(('hostname', 22))
transport.connect(username='wupeiqi', pkey=private_key )
sftp = paramiko.SFTPClient.from_transport(transport)
# 将location.py 上传至服务器 /tmp/test.py
sftp.put('/tmp/location.py', '/tmp/test.py')
# 将remove_path 下载到本地 local_path
sftp.get('remove_path', 'local_path')
transport.close()
补充:通过私钥字符串也可以连接远程服务器
key = """-----BEGIN RSA PRIVATE KEY----MIIG5AIBAAKCAYEAu0fkMInsVRnIBSiZcVYhKuccWCh6hapYgB1eSOWZLz3+xFGy G5p2z8HgiHzfT838gAm+5OajuyAuE4+fHI77LXSg+pLbr1FhPVKAP+nbsnLgvHty ykZmt74CKKvZ08wdM7eUWJbkdpRNWmkwHBi99LeO0zYbHdXQ+m0P9EiWfdacJdAV RDVCghQo1/IpfSUECpfQK1Hc0126vI8nhtrvT3V9qF420U1fwW9GJrODl71WRqvJ BgSsKsjV16f0RKARESNmtA2vEdvMeutttZoO4FbvZ+iLKpcRM4LGm2+odryr8ijv dCPCLVvoDExOPuqP1dgt5MWcCWf6ZNhMwAs/yvRHAKetvo5gtz8YvzwlikopCLM7 bS6C6woyppMHfIPjoGJ6JuKpeaWtAgugOw/oVvj1rRYoCv48R13NftqhkFD1KD8z km9CjDC8hv+2DmIedtjvVwUz2QF4PN/RC/i1jo3+3rbP1DLu9emTHiortBBrpQ5o K+y4Rzv+6NusD6DHAgMBAAECggGBAJ4hTaNOUaZpZmI0rZrsxoSbL2ugghNqid9i 7MFQW89v4TWSZXi5K6iwYw3bohKYMqNJl01fENBnk4AgvJA4ig0PdP0eEzAs3pYQ mwlcRIygQvHiqkHwv7pVTS1aLUqQBfgtAazre2xEPCwitOSEX5/JfWcJQEwoxZMt k1MIF0mZc67Zy5sT/Vwn+XScnDt2jbsEBFkPfg1aDto3ZYCQS5Aj/D21j0OauUdy 1SDIYkw1Kivx0IKsX1Kg0S6OOcnX/B6YrJvisrlQDeZnWlTsTyKSVTekIybJjUHE ZgLIIbifSbTW1Bv1iCkDAJBd4Cj4txjXPIgea9ylZ39wSDSV5Pxu0t/M3YbdA26j quVFCKqskNOC+cdYrdtVSij2Ypwov67HYsXC/w32oKO7tiRqy51LAs/WXMwQeS5a 8oWDZLiYIntY4TCYTVOvFlLRtXb+1SbwWKjJdjKvdChv4eo/Ov5JEXD2FVbVC/5E Qo3jyjIrt1lrwXUdpJa0/iz4UV33wQKBwQDprCPZVCI7yK/BWTmUvCcupotNk6CC +QIKDcvVxz63YFD5nXto4uG7ywXR6pEwOwmycO0CBuouvlPdSioQ3RYi6k0EO3Ch 9dybC5RZ3MENBHROHvU3mp01EWPUYnXAwNpvknujJqfXMxyURZvvox7hOnu/s3m4 C3eCBrMMg+uqNZDbLqAymw3pMGhHVWjy5oO8eLuLeJv6er+XoSSPNb21Da7StdQS fBPQ1H0/+RXnhFJOzANc4mRZcXMCNGVZX6MCgcEAzSz3evuCRQ47AaSOrDd89jAw PgpT+PG4gWw1jFZqHTbQ8MUl3YnElOVoaWRdIdDeslg9THg1cs5Yc9RrbIibyQjV F9k/DlXGo0F//Mgtmr7JkLP3syRl+EedRbu2Gk67XDrV7XIvhdlsEuSnEK9xOiB6 ngewM0e4TccqlLsb6u7RNMU9IjMu/iMcBXKsZ9Cr/DENmGQlTaRVt7G6UcAYGNgQ toMoCQWjR/HihlZHssLBj9U8uPyD38HKGy2OoXyNAoHBAKQzv9lHYusJ4l+G+IyJ DyucAsXX2HJQ0tsHyNYHtg2cVCqkPIV+8UtKpmNVZwMyaWUIL7Q98bA5NKuLIzZI dfbBGK/BqStWntgg8fWXx90C5UvEO2MAdjpFZxZmvgJeQuEmWVVTo5v4obubkrF5 ughhVXZng0AOZsNrO8Suqxsnmww6nn4RMVxNFOoTnbUawTXezUN71HfWa+38Ybl0 9UNWQyR0e3slz7LurrkWqwrOlBwlBrPtrsCflUbWVOXR6wKBwDFq+Dy14V2SnOG7 aeXPA5kkaCo5QJqAVglOL+OaWLqqnk6vnXwrl56pVqmz0762WT0phbIqbe02CBX1 /t3IVYVpTDIPUGG6hTqDJzmSWXGhLFlfD3Ulei3/ycCnAqh5eCUxwp8LVqjtgltW mWqqZyIx+nafsW/YgWqyYu4p1wKR/O+x5hSbsWDiwfgJ876ZgyMeCYE/9cAqqb6x 3webtfId8ICVPIpXwkks2Hu0wlYrFIX5PUPtBjJZsb00DtuUbQKBwF5BfytRZ0Z/ 6ktTfHj1OJ93hJNF9iRGpRfbHNylriVRb+hjXR3LBk8tyMAqR4rZDzfBNfPip5en 4TBMg8UATf43dVm7nv4PM2e24CRCWXMXYl7G3lFsQF/g7JNUoyr6bZQBf3pQcBw4
IJ38IcKV+L475tP4rfDrqyJz7mcJ+90a+ai5cSr9XoZqviAqNdhvBq5LjGOLkcdN bS0NAVVoGqjqIY/tOd2NMTEF6kVoYfJ7ZJtjxk/R3sdbdtajV3YsAg== -----END RSA PRIVATE KEY-----"""
import paramiko from io import StringIO
private_key = paramiko.RSAKey(file_obj=StringIO(key))
# 创建SSH对象 ssh = paramiko.SSHClient()
# 允许连接不在know_hosts文件中的主机 ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 连接服务器
ssh.connect(hostname='192.168.16.85', port=22, username='root', pkey=private_key)
# 执行命令
stdin, stdout, stderr = ssh.exec_command('df') # 获取命令结果
result = stdout.read()
# 关闭连接
ssh.close()
print(result)
生成
公司员工基于xshell连接服务器
用户名和密码 公钥和私钥(rsa)
生成公钥和私钥
ssh-keygen.exe -m pem
在当前用户家目录会生成:
.ssh/id_rsa.pub .ssh/id_rsa
把公钥放到服务器
ssh-copy-id -i ~.ssh/id_rsa.pub root@192.168.16.85
以后再连接服务器时,不需要在输入密码
ssh root@192.168.16.85
总结
···
什么是前后端分离
固定知识返回json数据
drf组件
帮助我们在django框架基础上快速搭建遵循restful规范接口的程序
drf组件的功能
解析器,解析请求体中的数据,将其变成我们想要的格式.request.data
序列化 对对象或者对象列表(queryset)进行序列化 操作以及表单验证的功能
视图 继承APIView(在内部apiview继承了django的view)
postman
模拟浏览器进行发送请求
查找模板的顺序
优先根目录下的templates
retframework 有一个templates
根据app的注册顺序去每个app的templates目录中找
个人补充
易错点
使用radom
步骤
1.把查询的对象放入字典里一次性传入前端进行交互
# bulk_create
# django外部文件使用django环境
import os
if __name__ == '__main__':
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "IGnb.settings")
import django
django.setup()
import random
from sales import models
sex_type = (('male', '男性'), ('female', '女性')) #
source_type = (('qq', "qq群"),
('referral', "内部转介绍"),
('website', "官方网站"),
('baidu_ads', "百度推广"),
('office_direct', "直接上门"),
('WoM', "口碑"),
('public_class', "公开课"),
('website_luffy', "路飞官网"),
('others', "其它"),)
course_choices = (('LinuxL', 'Linux中高级'),
('PythonFullStack', 'Python高级全栈开发'),)
print(random.choice(sex_type))
obj_list = []
for i in range(251):
obj = models.Customer(
qq=f"{i+1}236798",
name=f'liye{i}',
sex=random.choice(sex_type)[0],
source=random.choice(source_type)[0],
course=random.choice(course_choices)[0],
)
obj_list.append(obj)
models.Customer.objects.bulk_create(obj_list)
5 用什么形式发送就用什么解析
1.创建字段的时候要使用# , 进行隔开
配置静态文件要注意名字的命名
STATIC_URL = '/static1/'
STATICFILES_DIRS=[
os.path.join(BASE_DIR,'static')
]
多表图书管理系统的一个小技巧
1.可以先把查询出来的对象传到前端
2.利用对象.的方式 去进行查询、
利用ajax增加值
$('.ajx1').on('click',function () {
var thi=$(this);
var book_id=thi.attr('book_ip');
$.ajax({
url: "{% url 'app01:editor2' %}",
type: "get",
data: {"book_id": book_id,'csrfmiddlewaretoken':"{{ csrf_token }}"},
success: function (data) {
console.log(data);
$('#id-book').val(data['title']);#使用属性id选择器 获得值 传入
$('#id-price').val(data['price']);
$('#id-publish').val(data['pubulish_ch']);
$('#id-date').val(data['publishDate']);
$('#id-author').val(data['author_ch']);
$('.ajax2').attr('id_1',data['id']);
}
})
});
#利用ajax 编辑
$('.ajax2').on('click',function () {
var thi=$(this);
var book_id=thi.attr('id_1');
var book_title=$('#id-book').val();#把id对应的字段值取到
var book_price=$('#id-price').val();
var book_publish=$('#id-publish').val();
var book_date=$('#id-date').val();
var book_author=$('#id-author').val();
console.log(book_author);
$.ajax({
url: "{% url 'app01:editor2' %}",
type: "post",
traditional:true,
data: {"id": book_id,'price':book_price,'title':book_title,'publishs_id':book_publish,
'publishDate':book_date,'authors_id':book_author,'csrfmiddlewaretoken':"{{ csrf_token }}"},
success: function (data) {
console.log(data);
if (data==='1'){
alert('修改成功');
location.reload()
}
else {
alert('修改失败')
}
}
})
});
</script>
图书管理系统注意事项(易错点)
多选框选择多个作者用getlist('字段')
1.{{ value(变量)|date:"Y-m-d H:i:s"}} 把datetime.datetime.now()
date:"Y-m-d"
Sept 1,2019 转换成 2019 09-01
2.input type="number"设置了只能只能输入数值
添加
3.表单(需要写name)#因为需要取值 要设定一个键
不写的话提交没有携带数据
取值
例如
第一种方式:
前端:
后端:
def add_book
#get用键(对应标签的name属性的值)取值vluse
title=request.POST.get("title")
price=request.POST.get("price")
第二种方式:
data=request.POST.dict())#字典的形式
models.book(表名).object.create(
**data
)
return redirect('showbooks')
去和数据库进行交互
第三种方式
get
data=request.POST.get()#取到的是对应?后面的值
4.删除
前端:
<a href="{% url 'delete_book' book.pk %}" class="btn btn-danger">删除</a>
后端:
def delete_book(request,n):
models.Book.objects.filter(id=n).delete()
return redirect('showbooks')
5.for循环
放入标签里可以循环添加里面所有的标签
{% for book in all_books %}
标签
{% endfor %}
5.1if 循环
注意条件两边都有空格。
6.编辑易错点 必须要写键值 name值一定要写
ret1=models.Book.objects.values_list("critle").distinct()
print(ret1)
<QuerySet [('人民出版社',), ('江苏出版社',)]>
{%for i in li}
想要取出用 {{i.0}} 取出第一个
#因为是元组类型
如何确定编辑的行 把对应的id从前端传入后端
写法
#编辑
def editor1(request,n1):
if request.method == 'GET':
ret = models.Book.objects.filter(id=n1)[0]#筛选出id值
ret1=models.Book.objects.values_list("critle").distinct()
print(ret1)
print(ret)
return render(request,'editor1.html',{"li":ret,"li3":ret1})
else:
ret=request.POST.dict()
print(ret)
models.Book.objects.filter(id=n1).update(
**ret
)
return redirect(reverse('app01:library'))
在对应的book model里写一个
class Book(models.Model):
"""
书籍表
"""
title = models.CharField( max_length=32)
publishDate=models.DateField()
price=models.DecimalField(max_digits=5,decimal_places=2)
comment = models.FloatField(default=100) #评论数
good = models.FloatField(default=100) #点赞数
# publishs=models.ForeignKey(to="Publish",on_delete=models.CASCADE,related_name='xxx')
publishs=models.ForeignKey(to="Publish",on_delete=models.CASCADE,)
authors=models.ManyToManyField('Author',)
def __str__(self):
return self.title
def get_authors_name(self):
# authors = self.authors.all()
# name_list = []
# for i in authors:
# name_list.append(i.name)
#
# return ','.join(name_list)
return ','.join([i.name for i in self.authors.all()])
#查询出了所有作者 直接for循环可以进行直接引用
多表写法 low版
login.html页面
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>这是一个模板</title>
<link rel="stylesheet" href="/static1/pluin/bootstrap-3.3.7-dist/css/bootstrap.min.css">
</head>
<body>
<script src="/static1/js/jquery-3.4.1.js"></script>
<script src="/static1/pluin/bootstrap-3.3.7-dist/js/bootstrap.min.js"></script>
{#<script src="https://cdn.bootcss.com/jquery-cookie/1.4.1/jquery.cookie.js"></script>#}
<div class="container">
<div class="row">
<div class="col-md-offset-1">
<table class="table table-hover">
<thead>
<tr>
<th>姓名</th>
<th>密码</th>
<th>提交哦啊</th>
</tr>
</thead>
<tbody>
<tr>
<td><input type="text" id="login1">登陆</td>
<td><input type="password" id="password">密码</td>
<td><button type="submit" id="sub">提交</button></td>
<div id="error"></div>
</tr>
</tbody>
</table>
</div>
</div>
</div>
<script>
$("#sub").on("click",function () {
var name=$('#login1').val();
var password=$('#password').val();
console.log(name);
$.ajax({
url:'{% url "app01:login" %}',
type:'POST',
{#header:{"X-CSRFToken": $.cookie('csrftoken')},#}
data:{'user':name,'pwd':password,'csrfmiddlewaretoken': '{{ csrf_token }}' },
success:function (res) {
console.log(res,typeof res);
if (res.status===100){
{#$("#error").html("<a href=`{% url 'app01:index' %}`>子文</a>");#}
console.log('{% url 'app01:index' %}');
location.href='{% url "app01:index" %}';
{#location.href="/index/"#}
}
else {
$("#error").text('登陆失败')
}
}
}
)
})
</script>
</body>
</html>
高大上版
ajx代替form表单提交 异步提交局部刷新
$(".ajx").on("click", function () {
var ths = $(this);
var book_id = ths.attr('book_id');
console.log(book_id);
swal({
title: "你确定要删除吗?",
text: "删除可就找不回来了哦!",
type: "warning",
showCancelButton: true,
confirmButtonClass: "btn-danger",
confirmButtonText: "删除",
cancelButtonText: "取消",
closeOnConfirm: false
},
function () {
//var deleteId = $(this).parent().parent().attr("data_id");
//console.log(ths);
//console.log($(this));
var book_id = ths.attr('book_id');
console.log(book_id);
$.ajax({
url: "{% url 'app01:delete1' %}",
type: "post",
data: {"book_id": book_id,'csrfmiddlewaretoken':"{{ csrf_token }}"},
success: function (data) {
if (data=== 1) {
swal("删除成功!", "你可以准备跑路了!", "success");
// location.reload();
ths.parent().parent().remove();
$('#error').text('成功');
} else {
swal("删除失败", "你可以再尝试一下!", "error");
}
}
})
})
});
form表单
form必须写name和不然后端取值没办法取值 后端取值需要键
静态字段的别名
1.创建字段的时候要使用
# , 进行隔开 配置静态文件要注意名字的命名
STATIC_URL = '/static1/'
STATICFILES_DIRS=[
os.path.join(BASE_DIR,'static')
]
ajax
ajx代替form表单提交 异步提交局部刷新
$(".ajx").on("click", function () {
var ths = $(this);
var book_id = ths.attr('book_id'); console.log(book_id);
swal({ title: "你确定要删除吗?", text: "删除可就找不回来了哦!", type: "warning", showCancelButton: true, confirmButtonClass: "btn-danger", confirmButtonText: "删除", cancelButtonText: "取消", closeOnConfirm: false }, function () { //var deleteId = $(this).parent().parent().attr("data_id"); //console.log(ths); //console.log($(this)); var book_id = ths.attr('book_id'); console.log(book_id); $.ajax({ url: "{% url 'app01:delete1' %}", type: "post", data: {"book_id": book_id,'csrfmiddlewaretoken':"{{ csrf_token }}"}, success: function (data) { if (data=== 1) { swal("删除成功!", "你可以准备跑路了!", "success");
// location.reload(); ths.parent().parent().remove(); $('#error').text('成功');
} else {
swal("删除失败", "你可以再尝试一下!", "error"); }
}
})
})
})
import uuid
str(uuid.uuid4())#随机字符串
models.表名.objects.all().none() 返回是一个none
添加数据库
models.Disk.objects.create(**之后的字典,外键id=外键id)
settings里面的基本都是用import importlib
import importlib
利用字符串直接获得模块
sttings配置 code ="zh-cn"
登陆字段
models.py
input的blank=TRUE验证可以为空 null=True数据库可以为空 ,unique,唯一
charfiled choice=sex_type(等于一个元组) id是值 名字是键 ((键,值),(键,值)) max_length=16
verbose_name=’QQ昵称‘ 和label一样 显示作用于admin可以不写
models.forekey('self')自关联
multiselectField('咨询')需要第三方模块下载 多选下拉框
verbose_name='客户信息表' admin创建表的时候的表名显示的数据
unique_together=联合唯一 下载第三方模块 djangoMultiSelectField course = MultiSelectField("咨询课程", choices=course_choices) #多选,并且存成一个 列表的格式,通过modelform来用的时候,会成为一个多选框
水平分表
把数据比较多的平行分成两个表(分出来一个详细表)
mysqldb
mysqldb是一个接口连接到mysql数据库服务器
request是什么
#请求报文 由客户端发送,其中包含和许多的信息,而 django 将这些信息封装成了 HttpRequest 对 象,
请求报文 由客户端发送,其中包含和许多的信息,而 django 将这些信息封装成了HttpRequest 对象
1.该对象由 HttpRequest 祖类创建。
这个是wsgi是从属于类
2.每一个请求都会生成一个 HttpRequest 对象,
3.django会将这个对象自动传递给响应的视图函数,
4.视图函数第一个参数传给视图函数。这个参数就是django视图函数的第一个参数,通常写成request。
5.一般视图函数约定俗成地使用 request 参数承接这个对象
表删除
book_obj= 第一种 book_obj.objects.remove(1) 第二种 clear 清空 第三种 set(['1','5'])
# 先清除再添加,相当于修改
#把原来的删除重新添加进去,注意不是原位置
Form所有内置字段
Field
required=True, 是否允许为空
widget=None, HTML插件
label=None, 用于生成Label标签或显示内容
initial=None, 初始值
help_text='', 帮助信息(在标签旁边显示)
error_messages=None, 错误信息 {'required': '不能为空', 'invalid': '格式错误'}
validators=[], 自定义验证规则
localize=False, 是否支持本地化
disabled=False, 是否可以编辑
label_suffix=None Label内容后缀
CharField(Field)
max_length=None, 最大长度
min_length=None, 最小长度
strip=True 是否移除用户输入空白
IntegerField(Field)
max_value=None, 最大值
min_value=None, 最小值
FloatField(IntegerField)
...
DecimalField(IntegerField)
max_value=None, 最大值
min_value=None, 最小值
max_digits=None, 总长度
decimal_places=None, 小数位长度
BaseTemporalField(Field)
input_formats=None 时间格式化
DateField(BaseTemporalField) 格式:2015-09-01
TimeField(BaseTemporalField) 格式:11:12
DateTimeField(BaseTemporalField)格式:2015-09-01 11:12
DurationField(Field) 时间间隔:%d %H:%M:%S.%f
...
RegexField(CharField)
regex, 自定制正则表达式
max_length=None, 最大长度
min_length=None, 最小长度
error_message=None, 忽略,错误信息使用 error_messages={'invalid': '...'}
EmailField(CharField)
...
FileField(Field)
allow_empty_file=False 是否允许空文件
ImageField(FileField)
...
注:需要PIL模块,pip3 install Pillow
以上两个字典使用时,需要注意两点:
- form表单中 enctype="multipart/form-data"
- view函数中 obj = MyForm(request.POST, request.FILES)
URLField(Field)
...
BooleanField(Field)
...
NullBooleanField(BooleanField)
...
ChoiceField(Field)
...
choices=(), 选项,如:choices = ((0,'上海'),(1,'北京'),)
required=True, 是否必填
widget=None, 插件,默认select插件
label=None, Label内容
initial=None, 初始值
help_text='', 帮助提示
ModelChoiceField(ChoiceField)
... django.forms.models.ModelChoiceField
queryset, # 查询数据库中的数据
empty_label="---------", # 默认空显示内容
to_field_name=None, # HTML中value的值对应的字段
limit_choices_to=None # ModelForm中对queryset二次筛选
ModelMultipleChoiceField(ModelChoiceField)
... django.forms.models.ModelMultipleChoiceField
TypedChoiceField(ChoiceField)
coerce = lambda val: val 对选中的值进行一次转换
empty_value= '' 空值的默认值
MultipleChoiceField(ChoiceField)
...
TypedMultipleChoiceField(MultipleChoiceField)
coerce = lambda val: val 对选中的每一个值进行一次转换
empty_value= '' 空值的默认值
ComboField(Field)
fields=() 使用多个验证,如下:即验证最大长度20,又验证邮箱格式
fields.ComboField(fields=[fields.CharField(max_length=20), fields.EmailField(),])
MultiValueField(Field)
PS: 抽象类,子类中可以实现聚合多个字典去匹配一个值,要配合MultiWidget使用
SplitDateTimeField(MultiValueField)
input_date_formats=None, 格式列表:['%Y--%m--%d', '%m%d/%Y', '%m/%d/%y']
input_time_formats=None 格式列表:['%H:%M:%S', '%H:%M:%S.%f', '%H:%M']
FilePathField(ChoiceField) 文件选项,目录下文件显示在页面中
path, 文件夹路径
match=None, 正则匹配
recursive=False, 递归下面的文件夹
allow_files=True, 允许文件
allow_folders=False, 允许文件夹
required=True,
widget=None,
label=None,
initial=None,
help_text=''
GenericIPAddressField
protocol='both', both,ipv4,ipv6支持的IP格式
unpack_ipv4=False 解析ipv4地址,如果是::ffff:192.0.2.1时候,可解析为192.0.2.1, PS:protocol必须为both才能启用
SlugField(CharField) 数字,字母,下划线,减号(连字符)
...
UUIDField(CharField) uuid类型
ajax补充
traditional:true,
在ajax设置该属性就可以往后端传递数组
拓展性知识
ajax的traditional属性
ajax的traditional属性
jquery框架的ajax参数除了常用的
$.ajax({
url: 'xxx',
type: 'xxx',
data: 'xxx',
success: 'xxx'
...
})
另外还有一个参数需要特别注意下traditional默认值是false。
ajax做数据处理时,是通过jQuery.param( obj, traditional )该方法进行处理。
jquery1.4版本以后
traditional参数,默认false的时候如果是{a:{b:'value'}}是处理成a[b],这样形式,如果是数组:data:{a:[1,2]},是解析成a[]=1&a[]=2,这种方式后台确实要做兼容(取a[b]或a[])来取值。
在数组情况下把traditional参数设置成true,是解析成a=1&a=2,对后台直接通过a拿数据。但是实验了下object情况,把traditional设置成true,转成了a=[object+Object],这样就是费的了。false时解析成上面的形式应该就是类型指示作用,我看到这种格式就知道请求数据是Array还是object了,true就是按照form提交的方式传值。
当需要把多个checkbox的value值通过ajax传到servlet时就需要加上traditional参数并且为true,如下代码:
//批量删除
$("#alldel").click(function () {
var ids = $(".che:checked");
var items = new Array();
for (var i=0;i<ids.size();i++){
items.push(ids[i].value);
}
if (confirm("您确定要删除选中数据吗?")) {
$.ajax({
type: "post",
url: "UserServlet?action=deleteAll",
data:{items:items},
//防止深度序列化
traditional :true,
async: true,
success: function(data) {
var da = JSON.parse(data);
alert(da.msg)
app.count();
},
error: function(data) {
console.info("error: " + data.responseText);
}
});
}
});

在后台我们就可以用 String[] items = request.getParameterValues("items") 进行接收前端传过来的数组,如下图:
request.POST.get() #获取值
这样就可以用SQL语句 delete from xxx where id in(x,x) 多参数的形式进行操作了。
表结构很少有一对一之间的关系
很多时候都是1对多 多对多之间的关系
input 消除自动记忆功能
在html里就可以直接清除了<input type="text" autocomplete="off"> input 的autocomplete属性默认是on:其含义代表是否让浏览器自动记录之前输入的值 off:则关闭记录
查询多个用反向查询set
# 多对多
如果post请求多个值使用getlist(字段)
写法
obj=request.POST.getlist("author_id")
#取得的是一个列表
# 海狗的怂逼人生 是哪些作者写的 -- 正向查询
obj = models.Book.objects.filter(title='海狗的怂逼人生').first()
ret = obj.authors.all()#可以直接查询到作者对应的名字 (直接查询到)
print(ret) #<QuerySet [<Author: 王洋>, <Author: 海狗>]>
for i in ret:
print(i.name)
# 查询一下海狗写了哪些书 -- 反向查询
obj = models.Author.objects.filter(name='海狗').first()
ret = obj.book_set.all()
print(ret)
for i in ret:
print(i.publishs.name)
print(i.title)
return HttpResponse('ok')
1.filter双下方法
1.2用i不区分大小写
2.下拉框(select)选择出来的就是列表
如果post请求多个值使用getlist(字段) 写法 obj=request.POST.getlist("author_id") #取得的是一个列表
request.Get.get()取到的值是 ?后面对应
此写法的好处不需要添加多余的路径 不用分组路径 127.0.0.1/home?id=3 request.post.get()取到值是3
mysqldb是什么
mysqldb是一个接口连接到mysql数据库服务器从python
wsgiref
from wsgiref.simple_server import make_server
# wsgiref本身就是个web框架,提供了一些固定的功能(请求和响应信息的封装,不需要我们自己写原生的 socket了也不需要咱们自己来完成请求信息的提取了,提取起来很方便) #函数名字随便起
def application(environ, start_response):
'''
:param environ: 是全部加工好的请求信息,加工成了一个字典,通过字典取值的方式就能拿到很多 你想要拿到的信息
:param start_response: 帮你封装响应信息的(响应行和响应头),注意下面的参数
:return:
'''
start_response('200 OK', [('Content-Type', 'text/html'),('k1','v1')])
print(environ)
print(environ['PATH_INFO'])
#输入地址127.0.0.1:8000,这个打印的是'/',输入的是 127.0.0.1:8000/index,打印结果是'/index'
return [b'<h1>Hello, web!</h1>']
#和咱们学的socketserver那个模块很像啊
httpd = make_server('127.0.0.1', 8080, application)
print('Serving HTTP on port 8080...')
# 开始监听HTTP请求: httpd.serve_forever()#send application的返回值 一个列表
requset是什么
#请求报文 由客户端发送,其中包含和许多的信息,而 django 将这些信息封装成了 HttpRequest 对 象,
请求报文 由客户端发送,其中包含和许多的信息,而 django 将这些信息封装成了HttpRequest 对象
1.该对象由 HttpRequest 祖类创建。
这个是wsgi是从属于类
2.每一个请求都会生成一个 HttpRequest 对象,
3.django会将这个对象自动传递给响应的视图函数,
4.视图函数第一个参数传给视图函数。这个参数就是django视图函数的第一个参数,通常写成request。
5.一般视图函数约定俗成地使用 request 参数承接这个对象
示例
print(requset) <WSGIRequest: GET '/app01/library/'>
表删除
book_obj= 第一种 book_obj.objects.remove(1)
第二种 clear 清空
第三种 set(['1','5']) # 先清除再添加,相当于修改 #把原来的删除重新添加进去,注意不是原位置
知识点补充
http协议(重点ms)
关于连接
是大家都要去遵守的协议 存在应用层 B/S架构
浏览器访问网站 基于socket发送 给服务端
1.服务端等待连接
2.浏览器和服务端进行连接(短链接)
2.1发送http格式的数据
3.服务端recv接收数据 返回数据send
4.一次请求一次响应就断开连接体现了(短链接)(不记录状态)
关于格式
关于格式:
浏览器相关的信息
两个#\r\n\r\n 分割请求头和请求体(请求数据)
响应头响应体
请求头和请求体 get请求没有请求体(请求数据)
GET
get请求没有请求体(请求数据)#因为get请求的数据写在了对应的url上了
#url写法
(http:www.baidu.com/index/?a=123(请求数据))
host:域名名字
user_Agent="浏览器的设备,设备"
send("GET /INDEX/?a=123(请求数据) HTTP1.1\r\nhost:www.baidu.com,user_agent:Chrome\r\n\r\n ")
POST
响应头和响应体(响应数据)
提交的数据存储在响应体中
send("POST /INDEX HTTP1.1\r\nhost:www.baidu.com,user_agent:Chrome\r\n\r\nusername=alex(响应数据在请求体中) ")
\r\n\r\n网页看到的东西(响应体)
### 常见的请求头都有哪些
```python
user_agent:用什么浏览器访问的网站
content-type:application/json或application
#指定请求体的格式 (服务端按照格式要求进行解析)
常见的请求方式
get post
.post 获取post请求的数据#请求体数据
.get 获取get请求的数据#问号以后的值
get请求 请求数据部分是没有数据的,get请求的数据在url上,在请求行里面,有大小限制,常见的get请求方式: 浏览器输入网址,a标签
post请求 请求数据在请求体(请求数据部分) ,数据没有大小限制, 常见方式:form表单提交数据
关于http的面试具体总结
1.http是超文本传输协议
2.这个协议规定在连接过程中 一次请求 一次响应 就断开连接 其实就解释了http解释了是无状态短链接
3.数据传输格式 都包含了头和体 在请求中过程有请求头和请求体 请求头和请求头之间用/r/n区分 请求头和请求体用/r/n/r/n分开
响应头也是一样
403 django的安全csrf 禁止访问
502 系统出问题
django的第一个错误 403
403 django的安全csrf 禁止访问
django模块的整理
from django.shortcuts import render,redirect,HttpResponse
from django.urls import reverse
from django.utils.decorators import method_decorator
#装饰器CBV引用模块
from django.views import View
#CBV引用模块
from django import template #
register=template.Library()#
orm通过日志打印对应sql语句
import os
if __name__ == '__main__':
# 加载 Django 项目的配置信息 配置对应的项目名称
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "crmIGNB.settings")
# 导入 Django,并启动 Django 项目
import django
django.setup()
from sale import models
# 查询 Book 表中的所有数据
ret = models.Book.objects.filter()
print(ret)
settings的配置
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
使用raw执行原生sql语句
执行原生查询
raw()管理器方法用于原始的SQL查询,并返回模型的实例:
注意:raw()语法查询必须包含主键.
这个方法执行原始的SQL查询,并返回一个django.db.models.query.RawQuerySet 实例。 这个RawQuerySet 实例可以像一般的QuerySet那样,通过迭代来提供对象实例。
举个例子:
class Person(models.Model):
first_name = models.CharField(...)
last_name = models.CharField(...)
birth_date = models.DateField(...)
可以像下面这样执行原生SQL语句
>>> for p in Person.objects.raw('SELECT * FROM myapp_person'):
... print(p)
raw()查询可以查询其他表的数据。
举个例子:
ret = models.Student.objects.raw('select id, tname as hehe from app02_teacher')
for i in ret:
print(i.id, i.hehe)
raw()方法自动将查询字段映射到模型字段。还可以通过translations参数指定一个把查询的字段名和ORM对象实例的字段名互相对应的字典
d = {'tname': 'haha'}
ret = models.Student.objects.raw('select * from app02_teacher', translations=d)
for i in ret:
print(i.id, i.sname, i.haha)
原生SQL还可以使用参数,注意不要自己使用字符串格式化拼接SQL语句,防止SQL注入!
d = {'tname': 'haha'}
ret = models.Student.objects.raw('select * from app02_teacher where id > %s', translations=d, params=[1,])
for i in ret:
print(i.id, i.sname, i.haha)
直接执行自定义SQL
有时候raw()方法并不十分好用,很多情况下我们不需要将查询结果映射成模型,或者我们需要执行DELETE、 INSERT以及UPDATE操作。在这些情况下,我们可以直接访问数据库,完全避开模型层。
我们可以直接从django提供的接口中获取数据库连接,然后像使用pymysql模块一样操作数据库。
from django.db import connection, connections
cursor = connection.cursor()
cursor = connections['default'].cursor()
cursor.execute("""SELECT * from auth_user where id = %s""", [1])
ret = cursor.fetchone()
bootstrapSweetAlert插件
$(".btn-danger").on("click", function() {
swal({
title: "你确定要删除吗?",
text: "删除可就找不回来了哦!",
#标签显示的 type: "warning",
showCancelButton: true,
confirmButtonClass: "btn-danger",
confirmButtonText: "删除",
cancelButtonText: "取消",
closeOnConfirm: false
}, function() { #
注意当前的this是指谁调用了这个
var deleteId = $(this).parent().parent().attr("data_id");
$.ajax({
url: "/delete_book/",
type: "post",
data: {
"id": deleteId
},
success: function(data) {
if (data.status === 1) {
swal("删除成功!", "你可以准备跑路了!", "success");
} else {
swal("删除失败", "你可以再尝试一下!", "error")
}
}
})
});
})
装饰器的补充
flask路由会用 装饰器的原理 开放封闭原则 在不改变原函数代码的前提下, 在函数前函数后增加新的功能 手写简单装饰器
def wrapper(f):
def inner( * args, ** kwargs):
return f( * args, ** kwargs)
return inner
补充:
import functools
def wrapper(f):
@functools.wraps(f)
# 加了之后保留函数元数据( 名字和注释)
def inner(*args,**kwargs):
return f(*args,**kwargs)
return inner
'''
1.执行wrapper
2.返回inner重新赋值index
'''
index=wrapper(index)
@wrapper
def index(a1, a2):
return a1+a2
print(index.__name__) #查看函数名
print(index.__doc__) #查看注释
1.不加内部装饰器functools.wraps index执行的是inner 2.加了保留函数元数据(名字和注释)
orm补充
verbose_name#admin显示的名字
以后在model form 和form中使用
写法
name=models.CharField(verbose_name="出版社名称",max_length=32)
路由系统中记得加入终止符$
这种写法的好处: 防止/index/下的子页面访问路径被之前路径的匹配
在urls.py路由中写法 urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^index/$',views.index)
]
模板查找顺序
1.先从根目录去找templates
2.在根据app注册顺序去每个app的templates中找(从上往下)
django如何执行原生sql语句
orm执行原生sql语句
在模型查询API不够用的情况下,我们还可以使用原始的SQL语句进行查询。
Django 提供两种方法使用原始SQL进行查询:一种是使用raw()方法,进行原始SQL查询并返回模型实例;另一种是完全避开模型层,直接执行自定义的SQL语句。
raw()# 取的是一个对象
写法
ret = models.Student.objects.raw('select * from app02_teacher', translations=d)
for i in ret:
print(i.id, i.sname, i.haha)
需要for 循环
自定义sql语句
django封装的
from django.db import connection, connections
cursor = connection.cursor() # cursor = connections['default'].cursor()
cursor.execute("""SELECT * from auth_user where id = %s""", [1])
ret = cursor.fetchone()
setting配置打印日志
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
#脚本运行
import os
if __name__ == '__main__':
# 加载 Django 项目的配置信息 配置对应的表的信息
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "crmIGNB.settings")
# 导入 Django,并启动 Django 项目
import django
django.setup()
from sale import models
# 查询 Book 表中的所有数据
ret = models.Book.objects.filter()
print(ret)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号