
一直知道插入排序在输入规模比较小时会有比较好的效率,但这个输入规模多少才算少却无从知晓,今天特意写了几个小程序分别测试了几种排序算法随输入规模增长的耗时情况。
测试环境
CPU 3.0GHz 双核 1G内存 centos虚拟机 g++ 4.9.1 -O3
预先构造100W个随机生成的整数数组,计算使用各种排序算法时的总耗时
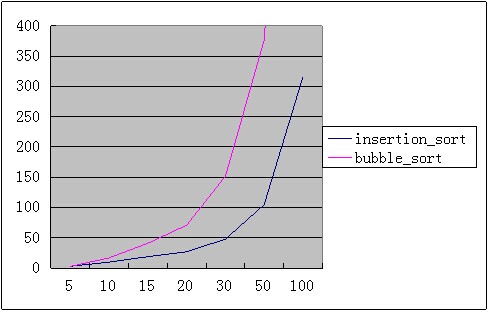
插入排序 vs 冒泡排序
不出所料,插入排序基本在任何输入规模均优于冒泡排序。
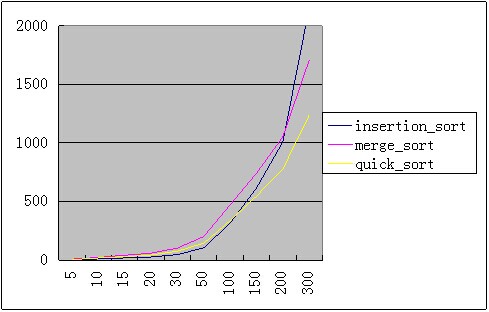
插入排序 vs 快速排序 vs 归并排序
由下图可以看出,在输入规模小于100时,插入排序要好于归并和快速排序。在输入规模小于200时,插入排序优于归并排序。规模在30以下时,插入排序效率要比快速排序高50%以上,规模在50以下时,插入排序比归并排序效率高90%以上。
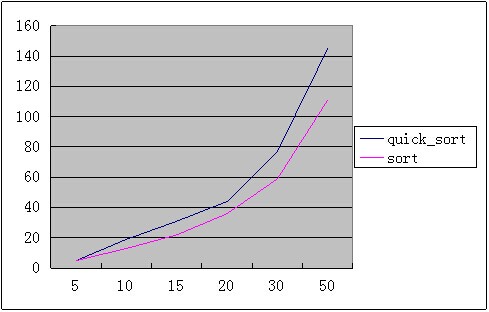
快速排序 vs std::sort
std::sort要比普通的快排速度快25%左右,简单阅读了一下stl的代码,std::sort的基本流程如下:
1.取begin(S),end(S),mid(S)的中位数s为基准,将序列S分割为两部分A={x≤s|x∈S} B={x>s|x∈S},然后分别对A、B执行2
2.1若子序列长度大于16,对子序列执行1
2.2若递归层数超出lg(n),对子序列执行堆排序 //递归层数太深,一般出现在拆分分布极不均匀的情况
3.对序列S执行插入排序 //此时S由≤16个元素的子序列或者已排序的子序列构成
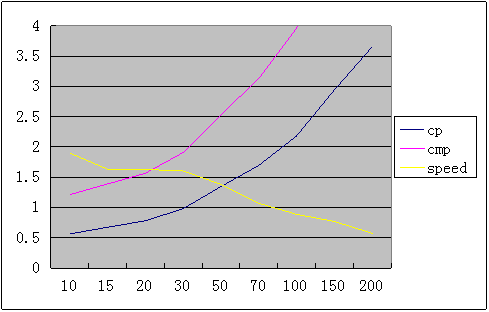
在std::sort的实现中,stl选择了16作为阈值,小于此值的子序列将采用插入排序进行优化。但在插入排序和快速排序的对比实验中,输入规模<100时插入排序总是优于快速排序,在30以下的时候尤其如此。stl为什么会选择16作为阈值呢?针对这个问题,做了一个小实验,将阈值作为参数加入快速排序中,针对10W个大小为2K的数组进行排序,得出排序效率与阈值之间的对应曲线:

从上图可以看出,在阈值15~100之间时,修改的快速排序要优于std::sort,在30~50左右时更是达到峰值。既然如此,std::sort为何要选择16作为阈值呢?
STL的实现人员肯定不会胡乱写个数字上去,对比了快排和插入排序的代码后,初步猜测可能是跟他们之间的对数据的比较和复制的次数有关。
下图是在不同的输入规模时插入排序与选择排序的比较次数之比、复制次数之比(快速排序swap操作当作3个复制操作计算)与时间效率之比,可以看出随着输入规模的增长,插入排序相比快速排序的效率优势在逐渐降低,而比较、移动次数却在呈指数级快速增长。对于一些自定义类型而言,他们的比较、复制操作的耗时往往是整数的数倍之多,对于以通用性为目标的std::sort而言,选择16作为阈值或许是一种中庸的选择。而在我们自己开发排序算法时,可以根据输入数据的性质灵活选择插入阈值,对于一些简单的数据结构可以选择相对较大的阈值(如30~50),而对于一些相对复杂的数据结构,则需要选择相对较小的阈值。
归并排序 vs std::stable_sort
std::stable_sort要比递归实现的归并排序效率高50%左右,这主要是由于:
1.stable_sort首先将输入序列以7个元素为单位分成若干小组,每小组内进行插入排序
2.合并插入排序构成的有序序列时,通过mergeto(A,B,step) && mergeto(B,A,step*2)的方式减少了一定的数据拷贝
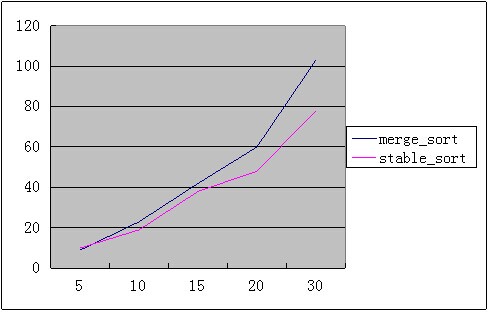
std::sort vs std::stable_sort
在输入规模较小时(<30),sort要比stable_sort效率高30%左右,这可能是由于在规模较小时sort可以更充分的利用插入排序带来的性能提升。
随着输入规模的增长,sort与stable_sort之间的差距逐渐缩小,大约在5%左右。
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号