
006爬虫之xpath获取猪八戒网商家信息
今天来学习一个之后会一直用到的解析方式:xpath,这个是重点,必须会。
首先我们需要安装lxml模块:
pip install lxml
用法:
1、将要解析的html内容构造出etree对象;
2、使用etree对象的xpath()方法配合xpath表达式来完成对数据的提取。
我们先来看看xpath的语法,首先给出一组网页的结构:
<book>
<id>1</id>
<name>野花遍地香</name>
<price>1.23</price>
<nick>臭豆腐</nick>
<author>
<nick id="10086">周大强</nick>
<nick id="10010">周芷若</nick>
<nick class="jay">周杰伦</nick>
<nick class="jolin">蔡依林</nick>
<div>
<nick>惹了</nick>
</div>
</author>
<partner>
<nick id="ppc">胖胖陈</nick>
<nick id="ppbc">胖胖不陈</nick>
</partner>
</book>
可以看到网页的源码都是按照这种层级式的方式编写的,接下来看xpath的语法:
/book /表示根节点
/book/name 在xpath里中间的/表示下一级节点
/book/name/text() text()表示拿文本,默认是一个列表,在后面加[0]表示提取列表中的第一个
/book//nick //表示所有的子孙后代
/book/*/nick/text() *是通配符,表示下一节点都可以
/book/author/nick[@class='jay']/text() []表示属性筛选,@属性值=值
/book/partner/nick/@id 最后一个/表示拿到nick里面的id的内容,@属性,可以直接拿到属性的值
接下来我们简单看一个处理网页的代码:
# xpath处理HTML
from lxml import etree
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>Title</title>
</head>
<body>
<ul>
<li><a href="http://www.baidu.com">百度</a></li>
<li><a href="http://www.google.com">谷歌</a></li>
<li><a href="http://www.sogou.com">搜狗</a></li>
</ul>
<ol>
<li><a href="feiji">飞机</a></li>
<li><a href="dapao">大炮</a></li>
<li><a href="huoche">火车</a></li>
</ol>
<div class="job">李嘉诚</div>
<div class="common">胡辣汤</div>
</body>
</html>
"""
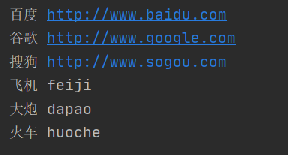
et = etree.HTML(html)
li_list = et.xpath("//li")
for li in li_list:
href = li.xpath("./a/@href")[0] # ./表示当前节点
text = li.xpath("./a/text()")[0]
print(text, href)
# 后续的爬虫工作可以继续。。。
运行结果如下:
以上就是xpath的基本语法,可以多多练习,后面基本都是用这个去提取数据。接下来我们看一个实际的例子,那就是爬取猪八戒网的相关信息。
爬取的网址为:https://beijing.zbj.com/search/f/?type=new&kw=saas&r=2
爬取的内容为:商家标的价格、服务内容、销量、公司名称

抓取的思路其实和用正则表达式是一样的,第一步先获取页面源代码,第二步通过解析页面源代码获取想要的信息,下面是具体的代码:
"""
1. 拿到页面源代码
2. 从页面源代码中提取你需要的数据,价格,名称,公司名称
"""
import requests
from lxml import etree
url = "https://beijing.zbj.com/search/f/?type=new&kw=saas&r=2"
resp = requests.get(url)
resp.encoding = "utf-8"
# print(resp.text)
# 提取数据
et = etree.HTML(resp.text)
divs = et.xpath("//div[@class='search-result-list-service search-result-list-service-width']/div")
for div in divs:
# 此时的div就是一条数据,对应一个商品信息
# price = div.xpath("./div/div[2]/div[1]/span/text()") # 这里存在一个问题就是第一个和第二个取的时候存在差异,可以用下面的语句解决
# 商品价格
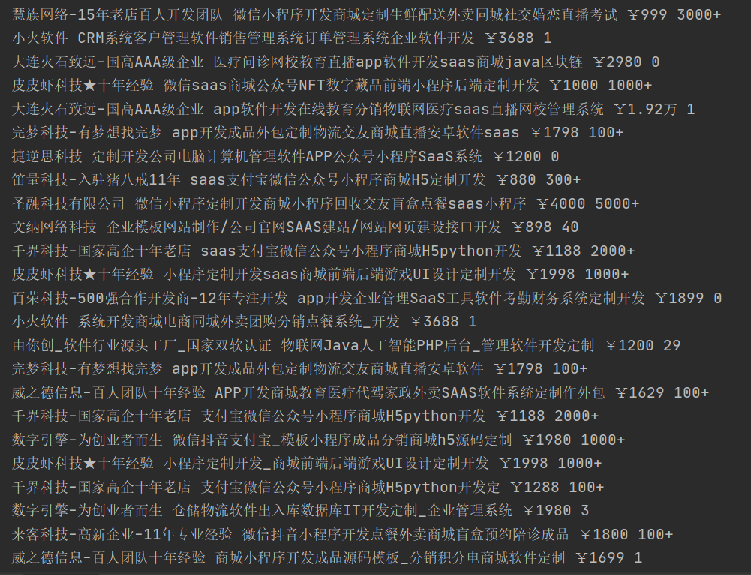
price = div.xpath("./div//div[@class='bot-content']/div[1]/span/text()")[0]
# 服务名称
serve_name = "_".join(div.xpath("./div//div[@class='bot-content']/div[2]/a/text()"))
# 售出数量
sale_num = div.xpath("./div/div[@class='bot-content']/div[4]/div[2]/div/span[2]/text()")[0]
# 公司名称
company = div.xpath("./div/a/div[2]/div/div/text()")[0]
print(company, serve_name, price, sale_num)
这个网页的源代码有2万多行,我们只用快速定位到自己想要的内容,然后摘出来,再进一步进行解析,里面有一点需要注意的是第一个和第二个取的时候存在差异,需要向我上面那样进行处理,最终结果如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号