
005爬虫之获取电影天堂必看热片电影的下载地址
今天还是继续用正则表达式提取电影天堂电影的下载地址,这里有一点不同的是需要先获取主页面的源代码,然后通过解析主页源代码再获取子页面的源代码,最后通过解析子页面的源代码获取电影的下载地址。
还是按照思路编写:
1.提取到主页面中的每一个电影的背后的那个url地址
1.1 拿到“2022必看热片”那一部分的HTML代码
1.2 从刚才拿到的HTML代码中提取到href的值
2.访问子页面,提取电影的名称及下载地址
2.1 拿到子页面的页面源代码
2.2 数据提取
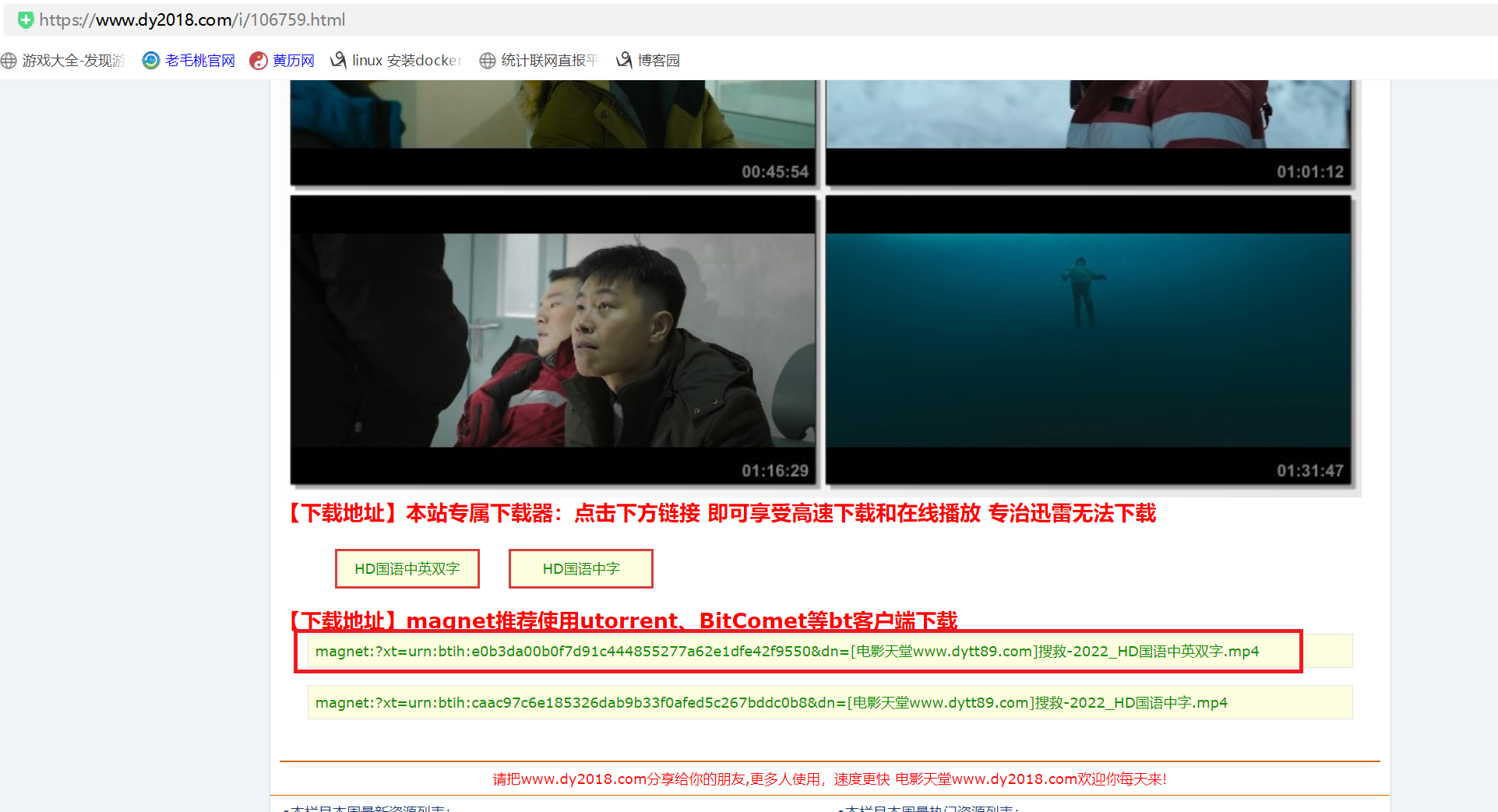
网页的信息截图:
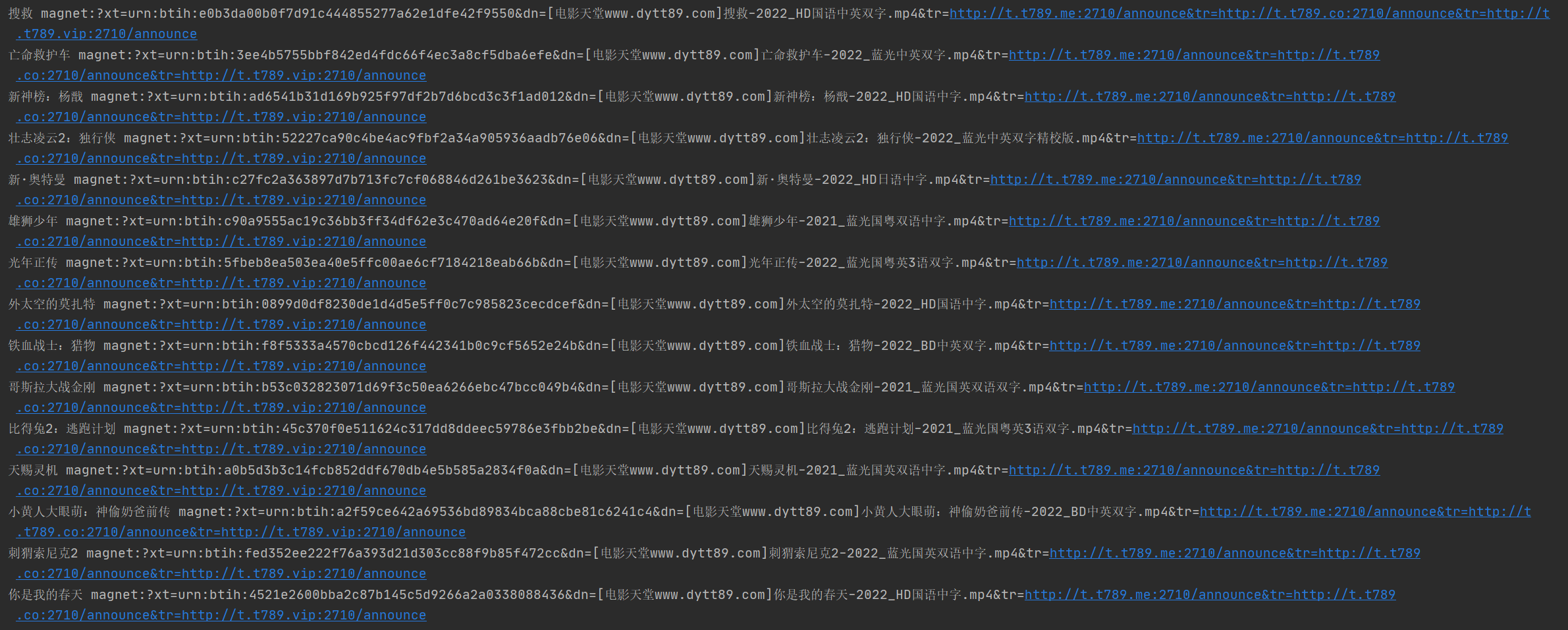
经过爬取后数据的结果:
下面是详细的代码,里面有相关的注释,里面有几个关键的知识点大家可以细细的揣摩一下,比如:urljoin,obj.search()。下面是详细的代码,有什么不懂的可以直接在下面留言。最后建议大家自己敲的时候不要一次性全部敲完,每编写一步进行验证:
"""
1.提取到主页面中的每一个电影的背后的那个url地址
1.1 拿到“2022必看热片”那一部分的HTML代码
1.2 从刚才拿到的HTML代码中提取到href的值
2.访问子页面,提取电影的名称及下载地址
2.1 拿到子页面的页面源代码
2.2 数据提取
"""
import requests
import re
from urllib.parse import urljoin # 进行url拼接
url = "https://www.dy2018.com/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36"
}
resp = requests.get(url, headers=headers)
resp.encoding = "gbk"
pageSource = resp.text
# 1,拿到“2022必看热片”那一部分的HTML代码
obj = re.compile(r'2022必看热片.*?<ul>(?P<html>.*?)</ul>', re.S)
html = obj.search(pageSource)
source2 = html.group("html")
# 2. 提取a标签中href的值
obj1 = re.compile(r"href='(?P<href>.*?)' title=.*?《(?P<moviename>.*?)》")
result1 = obj1.finditer(source2)
# 3.获取电影完整的下载链接
obj2 = re.compile(r'<div id="downlist" style="display:none">.*?<a href="(?P<href1>.*?)">', re.S)
for item in result1:
moviename = item.group("moviename")
# 获取下载页面的访问页面,这里拼接网页可以使用urljoin,也可以使用直接拼接,这里推荐用urljoin
child_url = urljoin(url, item.group("href"))
# child_url = url.strip("/") + item.group("href") # 也可以进行拼接
# print(moviename, child_url)
child_resp = requests.get(child_url)
child_resp.encoding = "gbk"
# 获取子页面的源代码
pageSource1 = child_resp.text
# 获取子页面中电影的下载地址
result2 = obj2.search(pageSource1)
href1 = result2.group("href1")
print(moviename, href1)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号