
003爬虫之数据解析概述-正则表达式
当我们爬到了网页的源代码之后,我们就需要对指定的数据进行获取,比如上一篇中只获取电影名称和上映时间,这里我们需要对获取的数据进行解析,以下提供四种解析方式:
1. re解析
2. bs4解析
3. xpath解析
4. pyquery解析
第一个re解析就是正则表达式(Regular Expression),一种使用表达式的方式对字符串进行匹配的语法规则。
正则的优点: 速度快, 效率高, 准确性高。
正则的缺点: 新手上手难度有点儿高。
Python里面有正则表达式,excel里面也可以用。接下来我们一起聊聊正则表达式在excel和python中的使用。首先我们了解下正则的语法,使用元字符进行排列组合用来匹配字符串 在线测试正则表达式https://tool.oschina.net/regex/
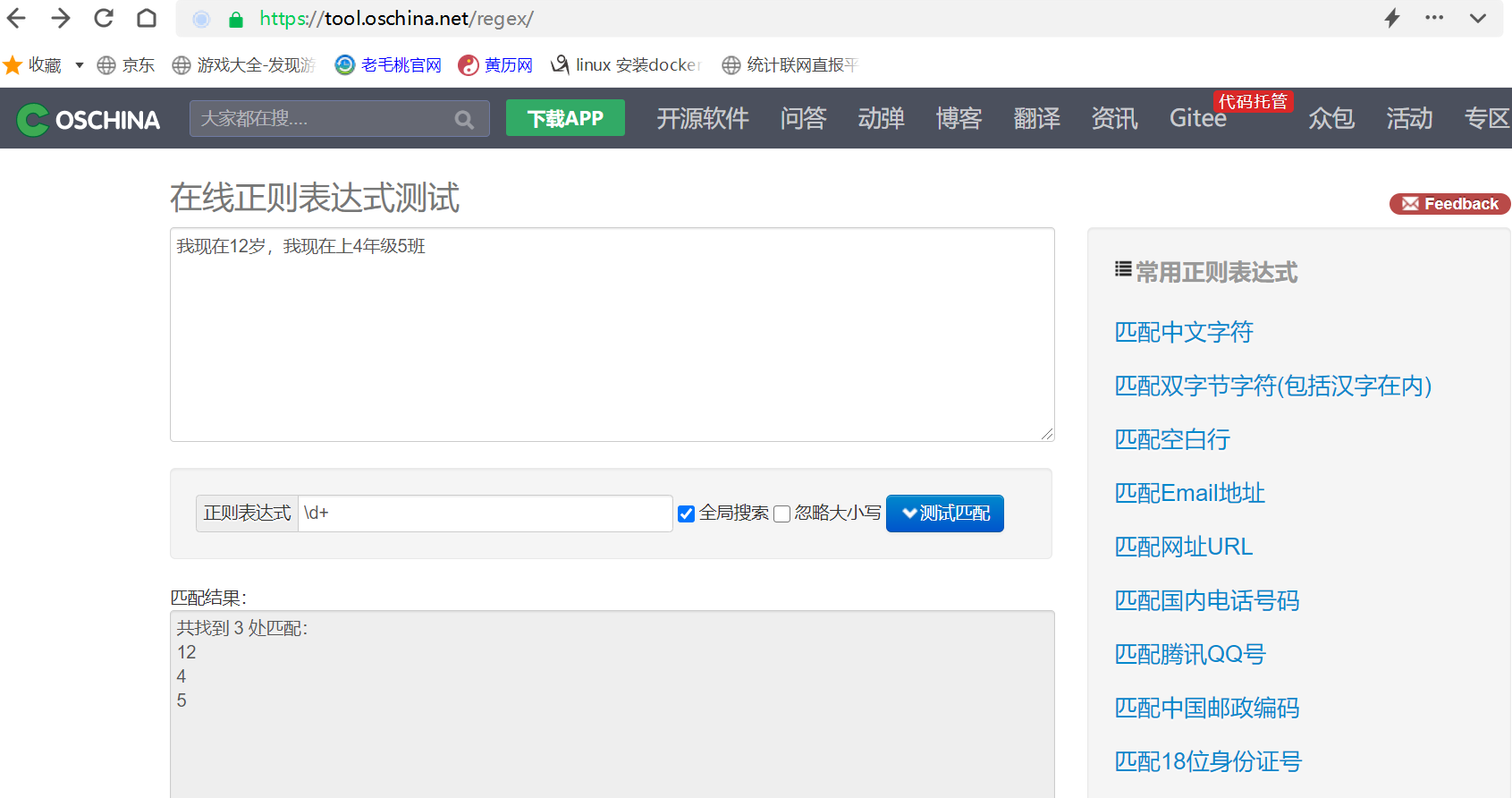
元字符: 具有固定含义的特殊符号
常用元字符:
. 匹配除换行符以外的任意字符, 未来在python的re模块中是一个坑.
\w 匹配字母或数字或下划线
\s 匹配任意的空白符
\d 匹配数字
\n 匹配一个换行符
\t 匹配一个制表符
^ 匹配字符串的开始
$ 匹配字符串的结尾
\W 匹配非字母或数字或下划线
\D 匹配非数字
\S 匹配非空白符
a|b 匹配字符a或字符b
() 匹配括号内的表达式,也表示一个组
[...] 匹配字符组中的字符
[^...] 匹配除了字符组中字符的所有字符
量词: 控制前面的元字符出现的次数
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
贪婪匹配和惰性匹配。
.* 贪婪匹配, 尽可能多的去匹配结果
.*? 惰性匹配, 尽可能少的去匹配结果 -> 回溯
这两个需要重点学习下,我这里举个例子大家参考。
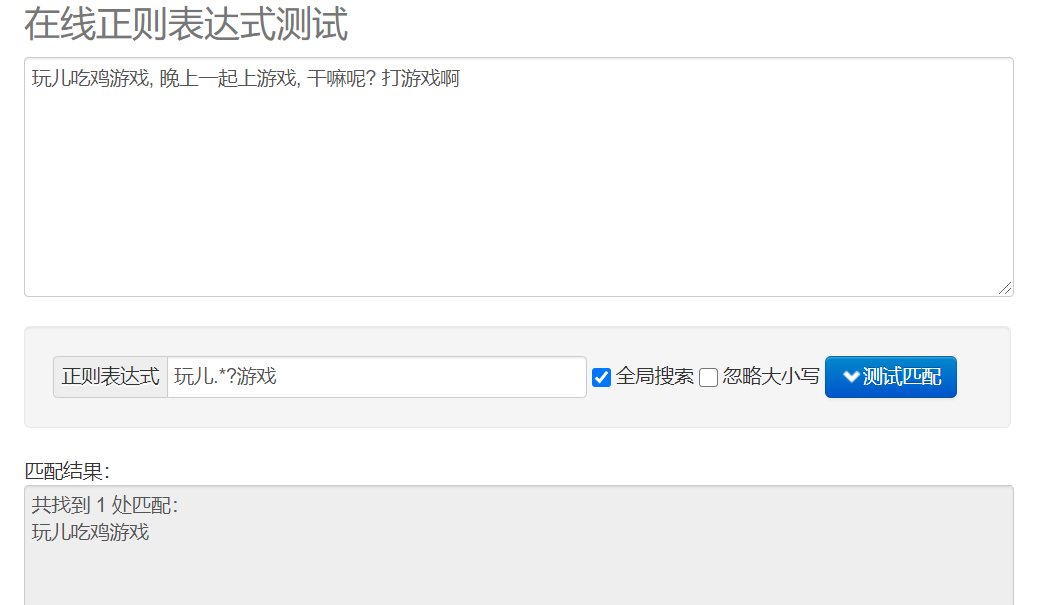
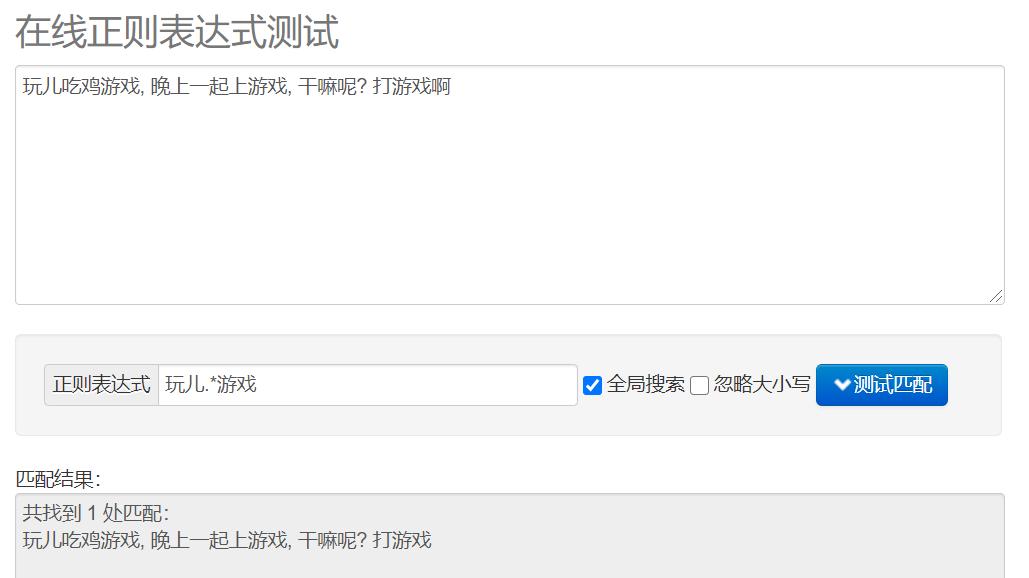
大家可以自行比对下上面的两张图的结果。.*? 表示尽可能少的匹配, .*表示尽可能多的匹配。
接下来我们看看正则表达式在excel中的使用。
比如:在excel中想获得“我的年龄12岁。”这句话中数字12,用其它的方式感觉都比较困难获取,这里通过正则表达式就非常简单。公式为:@RegexRlt(B5,"\d+",3,,,)。
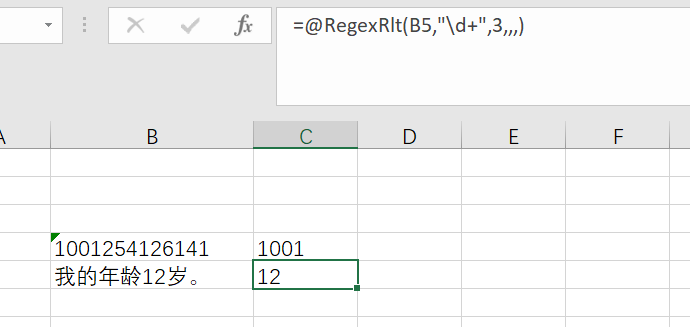
可能大家比较难以理解这个函数,我推荐大家一个excel嵌套工具:方方格子,然后导入公式向导,里面选择文本->正则表达式。
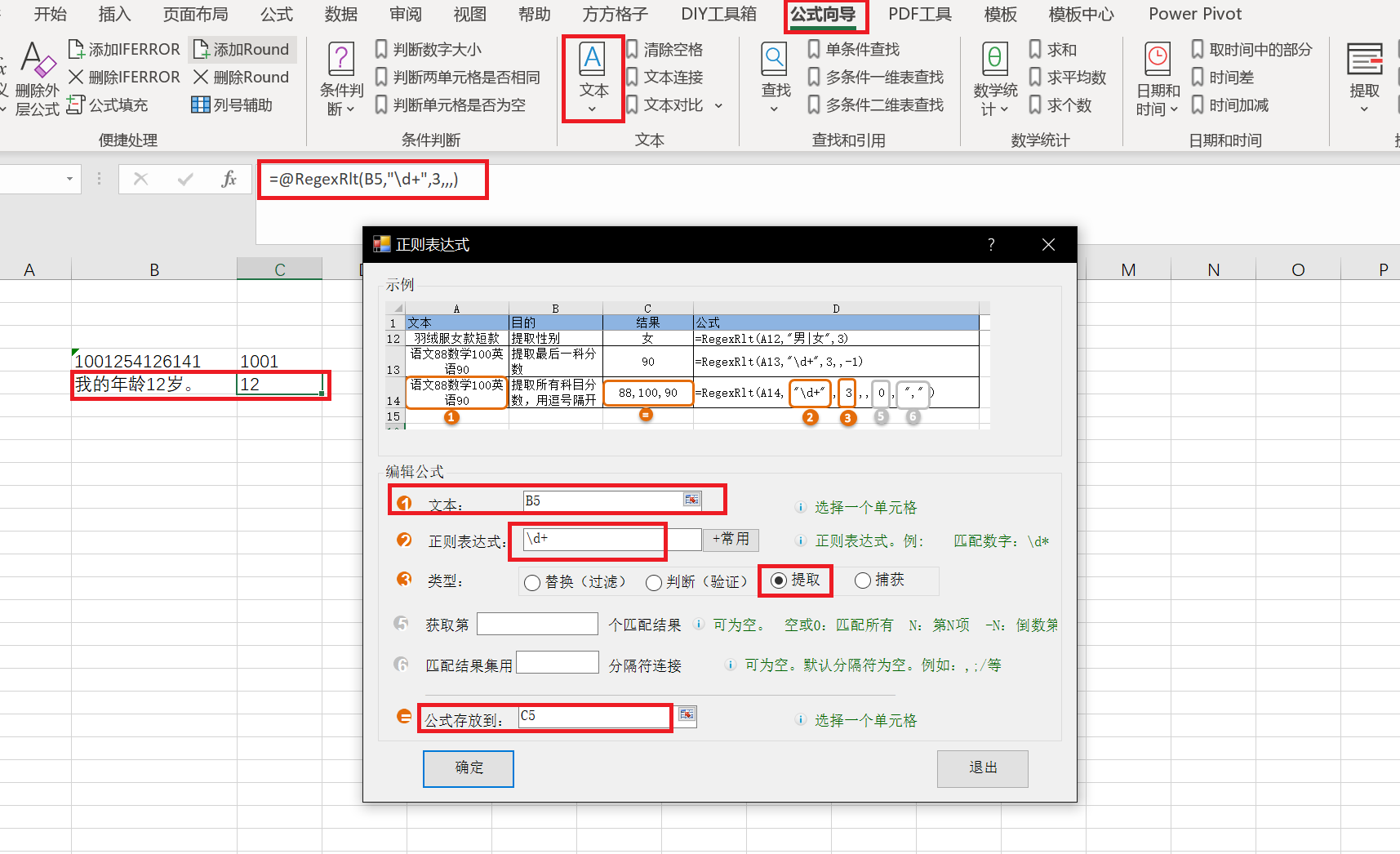
这样大家以后在excel里面需要处理字符串等问题就可以用正则表达式了。
接下来我们再看看正则表达式在Python中的使用。
我们用的模块是re模块,这个模块Python里面是自带的,无需下载。
接下来我们看看re模块我们可能会用到的几个功能:
1.findall查找所有,返回list
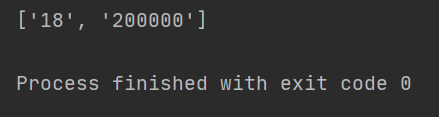
import re
result = re.findall(r"\d+", "我今年18岁,我有200000块")
print(result)
结果如下:
2.finditer, 和findall差不多. 只不过这时返回的是迭代器(需要重点学习)
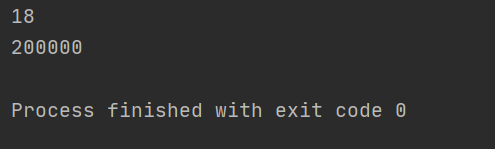
# 迭代器,可以提升程序的速度
result = re.finditer(r"\d+", "我今年18岁,我有200000块")
for item in result:
print(item.group()) # 从匹配到的结果拿到数据
结果如下:
3.search会进行匹配,但是如果匹配到了第一个结果,就会返回这个结果。如果匹配不上search返回的则是None。
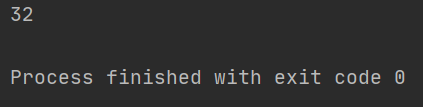
# search只会匹配到第一次匹配的内容
result = re.search(r"\d+", "我是周杰伦,今年32岁,我的班级是5年级4班")
print(result.group())
结果如下:
4.match只能从字符串的开头进行匹配。
# match在匹配的时候是从字符串的开头进行匹配的,类似于在正则前面加上^,用得特别少
result = re.match(r"\d+", "32岁,我的班级是5年级4班")
print(result.group())
结果如下:
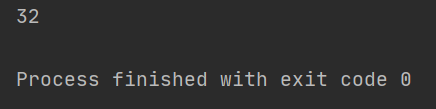
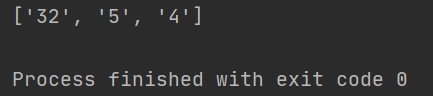
5.compile()将正则进行预加载,方便后面使用。这样用的原因为了防止每次使用的时候都去加载它,消耗资源。
# 预加载,提前把正则对象加载完毕
obj = re.compile(r"\d+")
# 直接把加载好的正则进行使用
result = obj.findall("我是周杰伦,今年32岁,我的班级是5年级4班")
print(result)
结果如下:
经过上面的案例之后,我们来学习一个比较贴近爬虫实际使用的例子。比如你爬到了如下的字符串文本,你如何进一步解析里面想要的内容获取10010,中国联通和10086,中国移动?
s = """
代码如下:
# 如何从正则中提取网页的数据
# 想要提取数据必须用小括号括起来,可以单独起名字
# (?P<名字>正则)
# 提取数据的时候,需要group("名字")
s = """
<div class='西游记'><span id='10010'>中国联通</span></div>
<div class='西游记'><span id='10086'>中国移动</span></div>
"""
obj = re.compile(r"<span id='(?P<id>\d+)'>(?P<name>.*?)</span>")
for item in obj.finditer(s):
id = item.group("id")
name = item.group("name")
print(id, name)
结果如下:
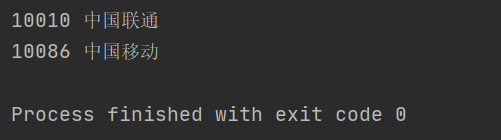
以上就是我们使用正则表达式初步做的一些尝试,以后处理字符串大家可以考虑用正则去处理,很强大。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号