


Java的数组,集合,数据结构,算法(一)
本人的愚见,博客是自己积累对外的输出,在学习初期或自己没有多少底料的情况下,与其总结写博客不如默默去搞自己的代码,但是学到集合这一块时,数组,集合,数据结构,算法这个概念搞的我比较混淆,所以不得已写这篇东西。
一,数组,数组和集合是Java中常用到的。
用Java去创建数组:
double[] myList;
这时myList 只是代表声明了一个只存放double类型的数组,并没有实体。
要想创建myList的实体,则要给它一个固定的大小,也就是说,数组存放数据的内存是一块连续的区间。
myList = new double[3];
double[0] = 5.62;
double[1] = 3.62;
double[2] = 3.32;
上面就是Java中数组的创建,那么我们看下常见数据结构有哪些?
大概八种,数组Array,栈Stack,队列Queue,链表Linked List,树Tree,哈希表Hash,堆Heap,图Graph.
其中就有数组Array,那么Java中的数组是不是数据结构?
我们看下百度定义:
数据结构是计算机存储、组织数据的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率。数据结构往往同高效的检索算法和索引技术有关。
https://www.cnblogs.com/ysocean/p/7889153.html#_label0_0
还有这个链接的见解,参考这俩个,数组是属于数据结构的。
二,集合。
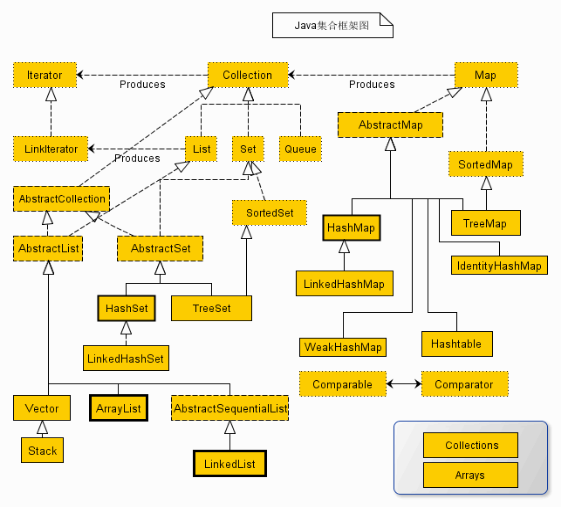
Collection
├List
│├LinkedList
│├ArrayList
│└Vector
│ └Stack
└Set
│ └SortedSet
└Queue
-Map
├HashTable
├HashMap
└WeakHashMap
如图所示:图中,实线边框的是实现类,折线边框的是抽象类,而点线边框的是接口
三,数据结构。
数据结构和算法是结合的基础。(个人见解)
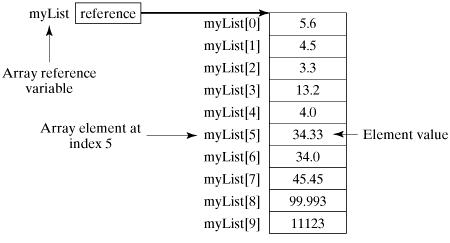
数组(Array)
数组存储的空间是连续不间断的。动态数组ArrayList底层是用数组实现的,那么就会有一个疑惑,数组是一个固定大小的利用连续空间存储的方式,为什么ArrayList能动态?因为当ArrayList要动态增加大小的时候,先是复制自己外加要增加的那部分(这部分暂存在某个缓存中?),然后在一片新的足够大的空间粘贴上去,之前的那段删掉。这种说法我不知道是不是错误的(这部分要在集合部分研究),我另外的想法:上面那种数据量大的时候,那个在中间暂时保存之前的ArrayList的缓存(或某个其他的中间介质)是不是也要足够大?这当然不现实的,所以ArrayList的做法是先寻找到一个足够大的空间,这个空间是之前的1.5陪,(ArrayList每次动态增加会增加自己的一半大小)直接从原来的位置复制到新的位置。
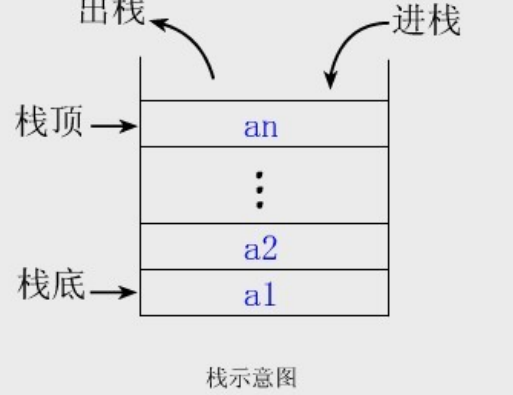
栈(Stack)
栈是Vector的一个子类,它实现了一个标准的后进先出的栈。堆栈只定义了默认构造函数,用来创建一个空栈。 堆栈除了包括由Vector定义的所有方法,也定义了自己的一些方法。可以参考http://www.runoob.com/java/java-stack-class.html。
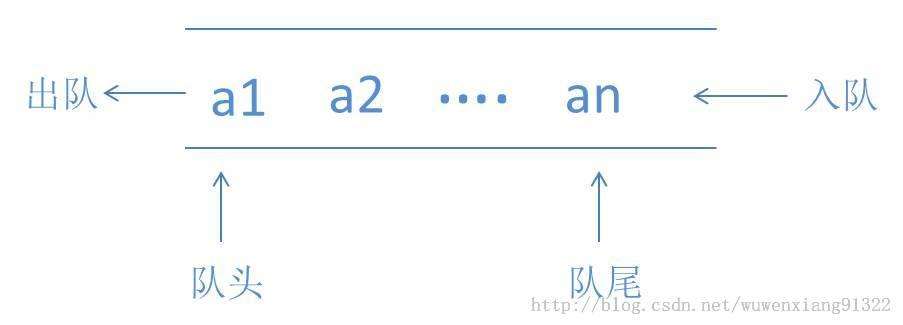
队列(Queue)
先进先出
链表(Linked List)
链表所占用的存储空间不是连续的,正因如此,会有一个链头,链头会有连个消息,一个要记录的元素,一个记录其下一个元素的指针(这是单向链,还有双向链'一头记录上一个元素的位置,一头记录下一个元素的位置,中间是自己要记录的元素',循环链等等)。这种利用空间的方式,可以让链表能快速进行增加元素的功能,毕竟那里有空间就让要增加的元素放在哪里好了(这里我有一个疑问,单向链表最后一个对象是的指针是指向null的,所以如果新增元素的时候,那里有空间就让要增加的元素放在哪里好了这句话是错的,如果这样,那么新增元素的上一个元素的指针的指向位置是已经固定的了,这样会有矛盾)所以链表最后一个元素的指针指向null,null的位置就是新增的元素的位置。删除,删除快,是对于删除最后一个元素而言的,在链表中间删除,根本就不快,要想想中间删掉一个,那么会有几步操作,先保存要删的链单位的指向下一个元素的指针,删掉要删的链单位,找到要删的链单位的上一个链单位,替换其指针,所以要删除链表中间的链单位,相当于查找俩次链单位,效率不快。查找,每次新的查找,都要从链头开始,数据量上去了,排在末尾的链单位要花费的时间越长。
树(Tree)
各种树,常见有二叉树:
红黑树:
2-3-4树:
哈希表(Hash)
https://www.cnblogs.com/s-b-b/p/6208565.html
哈希表很重要,是hashtable和hashmap实现的基础。
堆(Heap)
https://blog.csdn.net/juanqinyang/article/details/51418629
图(Graph)
https://www.cnblogs.com/moonlord/p/5938061.html
四,算法。
https://blog.csdn.net/qq_23994787/article/details/77951244
https://www.cnblogs.com/10158wsj/p/6782124.html?utm_source=tuicool&utm_medium=referral
冒泡,插入,选择排序等等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号