一、自定义频率类
# 我们之前写的频率类其实是可以继承两个的SimpleRateThrottle, BaseThrottle
# 只不过现继承BaseThrottle需要重写BaseThrottle方法 我们现在按照继承BaseThrottle然后自定义频率
class MyThrottling(BaseThrottle):
# 自定义的逻辑 {ip:[时间1,时间2]}
time_dic = {}
def __init__(self):
self.history = None
def allow_request(self, request, view):
pass
# (1)取出访问者ip
ip = request.META.get('REMOTE_ADDR')
# (2)判断当前ip不在访问字典里,添加进去,并且直接返回True,表示第一次访问,在字典里,继续往下走
import time
now_time = time.time()
if ip not in self.time_dic:
self.time_dic[ip] = [now_time, ]
return True
self.history = self.time_dic.get(ip)
# (3)循环判断当前ip的列表,有值,并且当前时间减去列表的最后一个时间大于60s,把这种数据pop掉,这样列表中只有60s以内的访问时间,
while self.history and now_time - self.history[-1] > 60:
self.history.pop()
# (4)判断,当列表小于3,说明一分钟以内访问不足三次,把当前时间插入到列表第一个位置,返回True,顺利通过
if len(self.history) < 3:
self.history.insert(0, now_time)
return True
# (5)当大于等于3,说明一分钟内访问超过三次,返回False验证失败
else:
return False
# 然后在视图类中配置即可 但是现在错误信息不是中文的 需要重写wait方法才能显示中文
def wait(self):
import time
now_time = time.time()
return 60 - (now_time - self.history[-1]) # 用当前时间减去列表中最后一个时间 就是剩余时间
二、频率类源码分析
# 我们在继承了SimpleRateThrottle类 然后在写频率类 其实就是这个帮我们写了allow_request方法所以我们去看看这个源码写了啥
def allow_request(self, request, view):
if self.rate is None: # 首先判断了self.rate是否有值 rate在实例化对象的时候就已经赋值了 所以肯定有值
return True
self.key = self.get_cache_key(request, view)
# get_cache_key就是我们自己写的频率类重新写的方法 然后我们返回了用户的ip作为频率的限制 所以我们返回什么就以什么作为频率的限制
if self.key is None: # 所以这里为True做if判断
return True # 这里其实就是没有频率的限制 直接往下走
self.history = self.cache.get(self.key, []) # 通过缓存取出列表中用户ip的时间
self.now = self.timer() # 这个就是获取当前时间 self.timer()其实就是time.time
while self.history and self.history[-1] <= self.now - self.duration:
# 然后循环判断列表中是否有值, self.history就是列表最后一个时间就是最早的时间
# self.now就是当前时间 self.duration 就是我们配置的60
# 然后如果最早的时间如果小于 当前时间减去我们配置的时间那么 就要把最早的时间给pop掉
# 这样列表中就只剩下小于我们配置的时间
self.history.pop()
if len(self.history) >= self.num_requests: # 然后在计算列表中小于我们配置的时间 是否大于我们配置的频率次数
# 如果大于那么就要返回False
return self.throttle_failure() # 这里点进去其实就是返回了False 为了扩展性
# 否则返回True
return self.throttle_success()
def throttle_success(self):
self.history.insert(0, self.now) # 这个就是把当前时间插入到列表的开头
self.cache.set(self.key, self.history, self.duration) # 然后保存到缓存当中
return True # 返回True 就是没有限制
SimpleRateThrottle类
class SimpleRateThrottle(BaseThrottle):
timer = time.time
THROTTLE_RATES = api_settings.DEFAULT_THROTTLE_RATES
def __init__(self):
if not getattr(self, 'rate', None):
# 这里就是使用反射判断我们写的类中是否有rate方法 我们肯定没写 所以if判断为True 就会走这个判断
self.rate = self.get_rate()
# 然后self.rate有等于了self.get_rate() 所以我们根据查找顺序 要找到了该类下的get_rate方法
# 然后该方法返回了'3/m'
self.num_requests, self.duration = self.parse_rate(self.rate)
# 先执行了self.parse_rate方法 根据名字的查找顺序 最后还是在该类中找的该方法 然后该方法返回了3和60
# 所以self.num_requests等于3 self.duration等于60
# 这样就实例化完了
get_rate方法
def get_rate(self):
if not getattr(self, 'scope', None):
# 利用反射判断我们写的频率类中是否有scope方法或属性 我们是写的了所以if结果为False 所以不会走该if
msg = ("You must set either `.scope` or `.rate` for '%s' throttle" %
self.__class__.__name__)
raise ImproperlyConfigured(msg) # 如果没写就会抛异常 所以一定要写scope属性
try:
return self.THROTTLE_RATES[self.scope] # self.scope就是我们自己写的频率类中写的scope属性'luffy'
# THROTTLE_RATES根据上面的赋值其实就是这个就是我们在配置文件中配置的'DEFAULT_THROTTLE_RATES': {'luffy': '3/m'}字典
# 然后根据字典取值把'3/m'返回出去
except KeyError:
msg = "No default throttle rate set for '%s' scope" % self.scope
raise ImproperlyConfigured(msg)
parse_rate
def parse_rate(self, rate): # rate就是传进来的 '3/m'
if rate is None: # 所以rate肯定有值
return (None, None) # 没有就返回两个None
num, period = rate.split('/') # 然后根据 / 切割字符串'3/m'
# 然后有通过解压赋值 num=字符串的3, period=m
num_requests = int(num) # 将字符串的3转换为整型3 赋值给num_requests
duration = {'s': 1, 'm': 60, 'h': 3600, 'd': 86400}[period[0]] # period[0] 就是取出字符串索引为0的数据 那就是m
# 这个就是 duration = {} 然后duration['m'] 是一样的
# 然后通过字典的取值方法 取出k为m的Value 所以duration就是60
return (num_requests, duration) # 然后把3和60返回出去
总结
# 总结:以后要再写频率类,只需要继承SimpleRateThrottle,重写get_cache_key,配置类属性scope,配置文件中配置一下就可以了
三、分页功能
# 分页功能就只有获取全部的接口才会有分页,其他接口是没有分页功能的
# 然后后端的分页写法是固定的,只有前端展示的不一样而已
eg:
-pc端的上一页和下一页的点击
-app的上拉和下滑都是分页的功能
# drf的分页使用
-所以写一个类,然后继承drf提供的三个分页类之一
-然后配置属性
-然后在视图类中,视图类必须要继承GenericAPIView+ListModelMixin的子视图类上 因为只有GenericAPIView类有pagination_class属性
-如果继承的是APIView,需要自己写
page = MyPageNumberPagination()
res = page.paginate_queryset(qs, request)
代码演示
1.PageNumberPagination
# 自己写的分页类
class MyPageNumberPagination(PageNumberPagination):
page_size = 2 # 每页展示2条数据
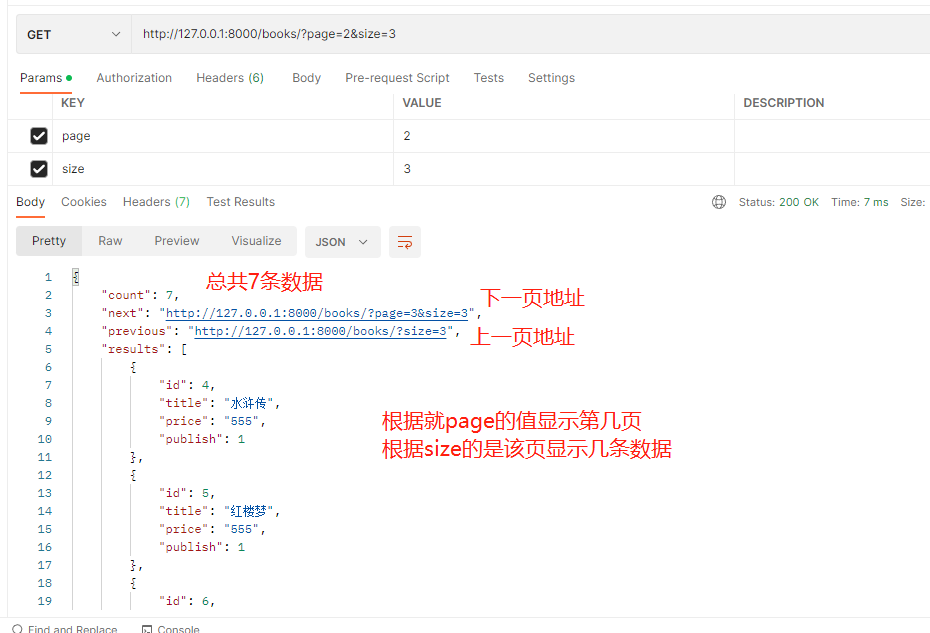
page_query_param = 'page' # 路径按照这样传入 books/?page=1 查询第几页
page_size_query_param = 'size' # 路径还可以这样写 books/?page=3&size=4 查询第三页,该页显示4条数据
max_page_size = 5 # size后面如果超出5 那么该页就按照5条数据显示,没有超出就按照写的条数显示
# 视图类配置
class BooksView(ViewSetMixin, GenericAPIView, ListAPIView):
queryset = Book.objects.all()
serializer_class = BookSerializer
pagination_class = MyPageNumberPagination # 在该类属性配置即可
# 然后通过 http://127.0.0.1:8000/books/?page=1路径即可访问第一页的数据
2.LimitOffsetPagination
class MyLimitOffsetPagination(LimitOffsetPagination):
default_limit = 2 # 每页显示的条数
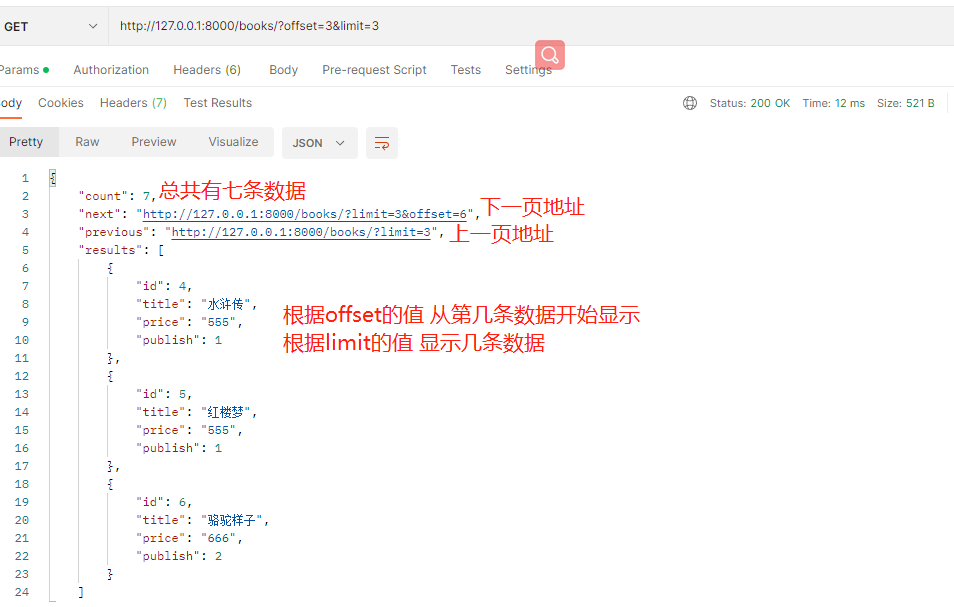
limit_query_param = 'limit' # 路径按照这样传入 books/?limit=4 这一页显示4条数据
offset_query_param = 'offset' # 路径还可以这样写 books/?offset=3&limit=4 # 我从第三条开始,然后取四条数据
max_limit = 5 # limit后面如果超出5 那么该页就按照5条数据显示,没有超出就按照写的条数显示
# 视图类
class BooksView(ViewSetMixin, GenericAPIView, ListModelMixin):
queryset = Book.objects.all()
serializer_class = BookSerializer
pagination_class = MyLimitOffsetPagination # 因为分页只能是一种方式 所以只需要替换即可
# 然后就可以根据这个路径访问了 http://127.0.0.1:8000/books/?offset=3&limit=3
3.CursorPagination
class MyCursorPagination(CursorPagination):
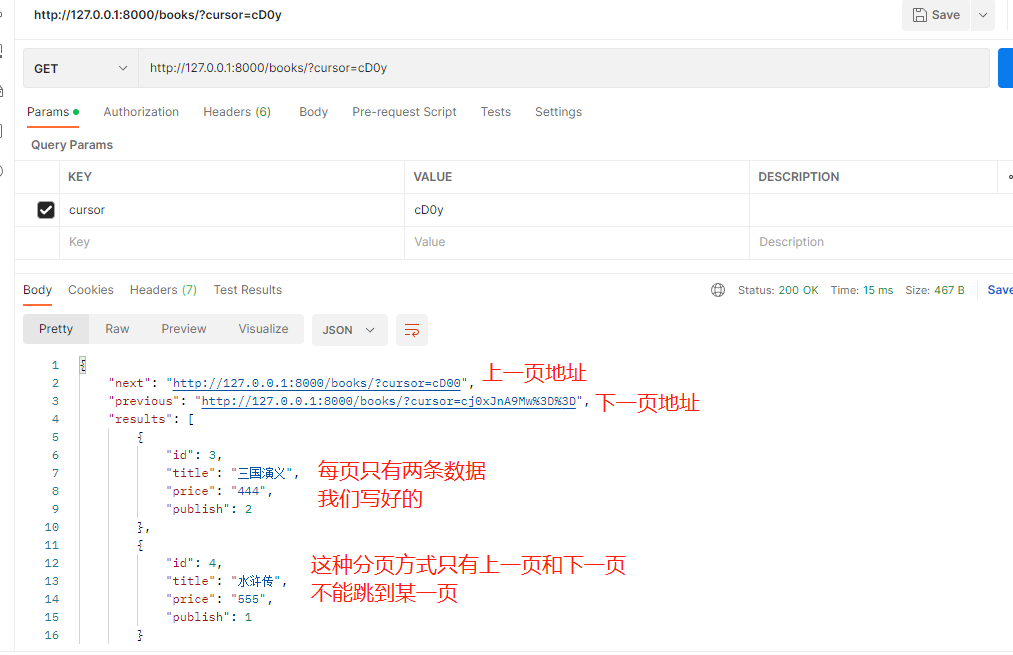
cursor_query_param = 'cursor'
page_size = 2 # 每页显示的条数
ordering = 'id' # 按照表中的某个字段排序 我们按照id排序 加负号就是降序
# 试图类
class BooksView(ViewSetMixin, GenericAPIView, ListModelMixin):
queryset = Book.objects.all()
serializer_class = BookSerializer
pagination_class = MyCursorPagination
# 这种分页方式 虽然不能跳到某一页 但是这种是效率最高的 适合大数据分页
四、排序功能
# 排序肯定也是 只有获取全部的接口需要排序
# 排序功能drf提供了给我们有排序类
from rest_framework.filters import OrderingFilter
使用
class BooksView(ViewSetMixin, GenericAPIView, ListModelMixin):
queryset = Book.objects.all()
serializer_class = BookSerializer
pagination_class = MyCursorPagination
# 排序类的配置
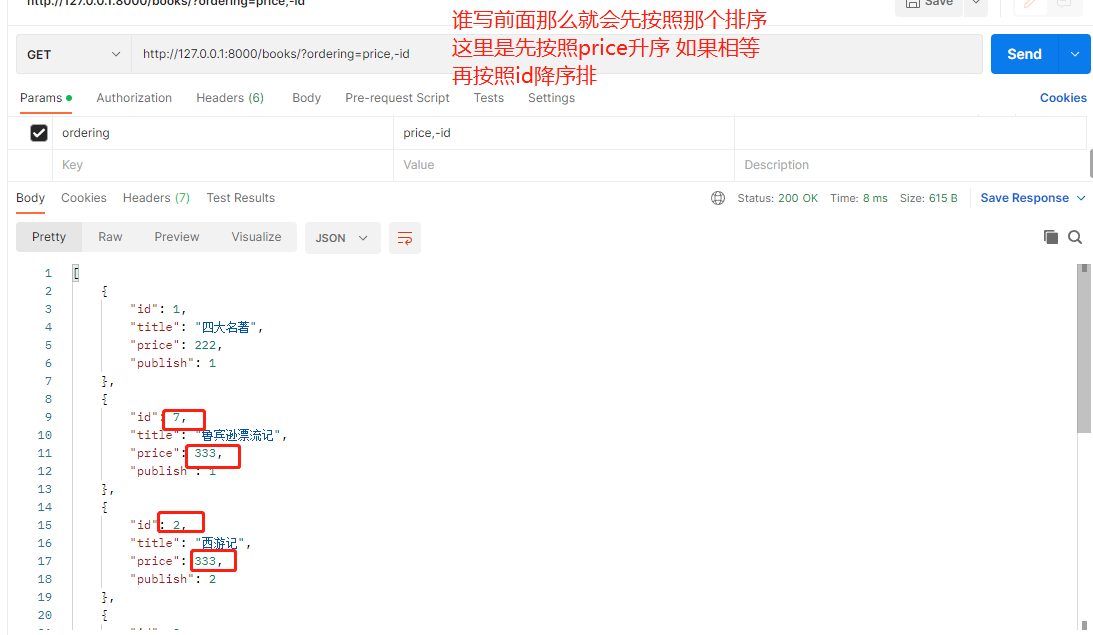
filter_backends = [OrderingFilter, ] # 可以放多个
# 指定那个字段排序
ordering_fields = ['id', 'price'] # 按照id排序也可以按照price排序
# 排序还可以跟分页一起使用 但是是先排序后分页
五、过滤功能
# 过滤功能也是一样的 只有获取全部需要过滤 其他接口不需要过滤
# restful规范中有一条,请求地址中带过滤条件:分页,排序,过滤统称为过滤
# 使用内置过滤类使用步骤 查询所有才涉及到排序,其它接口都不需要
# 必须是继承GenericAPIView+ListModelMixin的子视图类上
使用
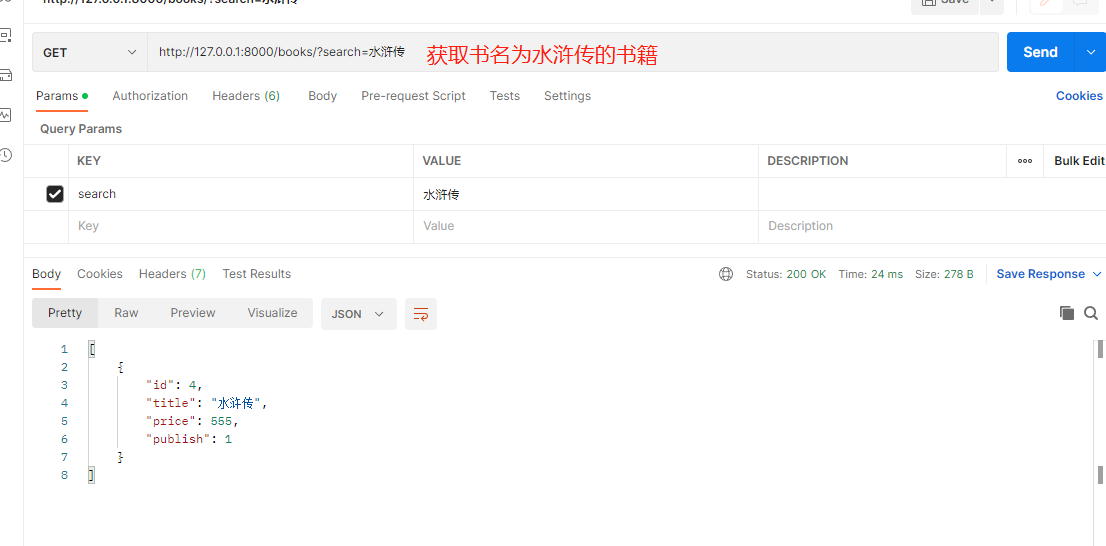
from rest_framework.filters import SearchFilter
class BooksView(ViewSetMixin, GenericAPIView, ListModelMixin):
queryset = Book.objects.all()
serializer_class = BookSerializer
# 过滤类的配置
filter_backends = [SearchFilter, ] # 这个因为是列表 所以可以跟排序一起使用 ,因为排序和过滤的类属性是一起的
# 指定那个字段过滤
search_fields = ['title'] # 使用那个字段过滤
# 过滤也是可以跟分页一起使用的 只不过先过滤在分页


 浙公网安备 33010602011771号
浙公网安备 33010602011771号