Java基础——集合
Java基础——常用集合
Collection体系集合:
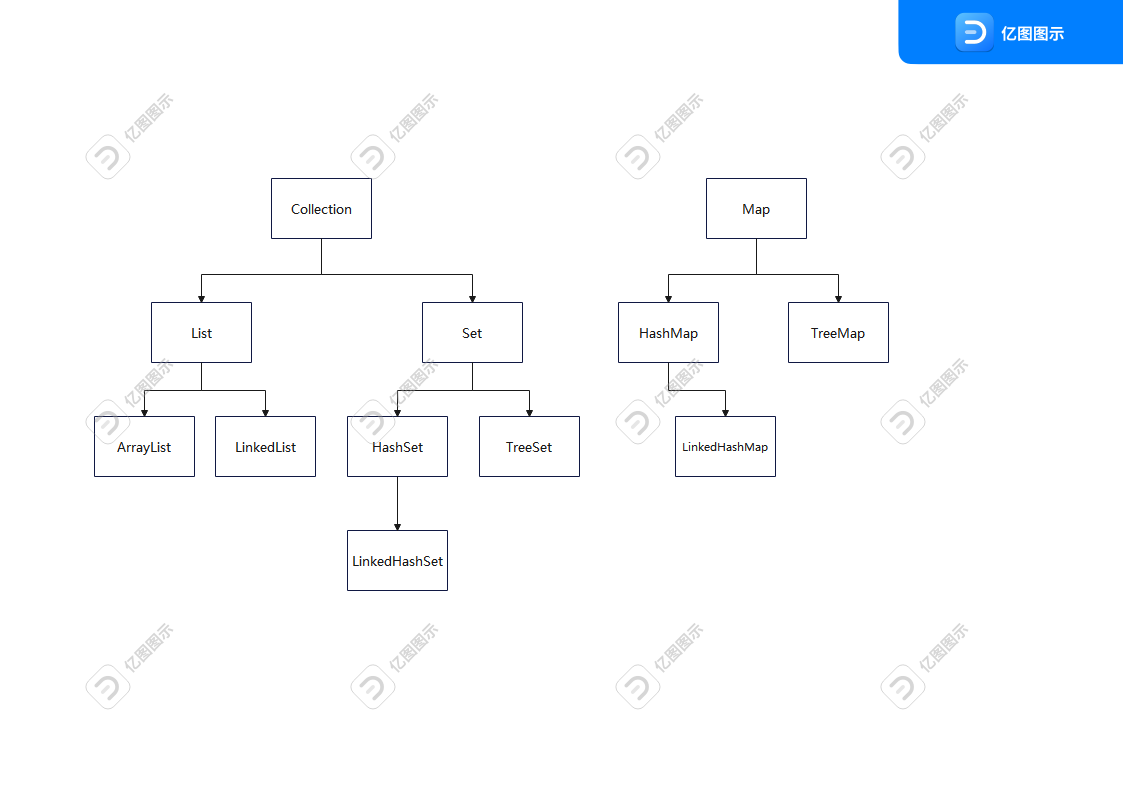
Collection接口存储一组不唯一、无序的对象
List接口存储一组不唯一,有序(索引顺序)的对象。
Set接口存储一组唯一,无序的对象。
Map接口存储一组键值对象,提供key到value的映射。
- key:唯一、无序
- value:不唯一、无序
1. List集合
主要实现类有ArrayList和LinkedList,分别由顺序表和链表实现。另外还包括栈和队列的实现类:Deque和Queue。
特点:有序、不唯一(可重复)
ArrayList
- 内存中分配连续空间,实现了长度可变的数组
- 优点:遍历元素和随机访问元素的效率比较高
- 缺点:添加和删除需要大量移动元素,按照内容查询效率低
LinkedList
- 采用双向链表存储方式
- 缺点:遍历和随机访问元素效率下降
- 有点:插入、删除元素效率比较高
几种遍历方式
for循环
for(int i = 0; i < list.size(); i++){
// ..
}
for-each循环
for(Object o: objects){
//...
}
Iterator迭代
Iterator it = list.iterator();
while(it.hasNext()){ // 是否还有元素
Object o = it.next(); // 取出来
// ...
}
Lambda表达式
list.forEach((i)->
//...
)
2. Set集合
主要有HashSet和TreeSet,LinkedHashSet三种。特点是唯一(不重复)、无序。
Set是无序的,相比Collection没有添加任何方法。而List相比Collection添加了索引相关的方法,比如get(i),remove(i)等等。
HashSet
- 采用哈希表存储结构
- 优点:添加速度快、查询速度快、删除速度快
- 缺点:无序
LinkedHashSet
是HashSet的子类。
- 采用哈希表存储结构,同时使用链表维护次序
- 有序(添加顺序)
TreeSet
- 采用二叉树(红黑树)的存储结构
- 优点:有序(自然顺序)、查询速度比List快(按照内容)、唯一
- 缺点:查询速度没有HashSet快
基本操作
// 添加
set.add(object);
// 大小
set.size();
// 删除
set.remove(object);
// 由于无序,无法通过for i 遍历
两个问题
- 为什么HashSet、LinkedHashSet存储String是唯一的,但是存储Student不唯一了?
- 为什么TreeSet存储String是有序的,但存储Student却报异常?
原因:
String是系统类,已经做了某些操作,而Student是自定义类,某些操作还没有做。
问题1解决:重写equals()和hashCode(),缺一不可。
问题2解决:实现一个Comparable的接口,之重写方法compareTo中指定比较规则。
哈希表原理
如何添加数据?
-
计算哈希码(调用hashCode),结果是一个int值,整数的哈希码取自身即可。
-
计算在哈希表中的存储位置:y=k(x)=x%11
x:哈希码,y:元素在哈希表中的存储位置
查询:
和添加过程类似。
3. Map集合
HashMap
- 优点:添加速度快、查询速度快、删除速度快
- 缺点:key无序
LinkedHashMap
- 采用哈希表存储结构,同时使用链表维护次序
- key有序
TreeMap
- 采用二叉树(红黑树)的存储结构
- 优点:key有序,查询速度比List快
- 缺点:查询速度没有HashMap快
基础操作
// 放入键值对
map.put("key", "value");
// 使用键获取值,未查找到则为null
value = map.get("key");
// 大小
map.size();
// 删除
map.remove("key");
// 遍历:三种方法:1.得到所有的key组成的set,遍历;2.得到所有Entry的set集合,然后使用iterator遍历

 浙公网安备 33010602011771号
浙公网安备 33010602011771号