2024数据采集与融合技术实践-作业4
一、Selenium+ MySQL爬取并存储股票信息
(一)步骤
爬取网站:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
step1:定义spider类,并初始化user_agent(浏览器伪装)、driver(Chrome WebDriver 实例)、data(暂时存储获取下来的数据)
def __init__(self):
# 设置 User-Agent,用于伪装浏览器,避免被网站反爬虫机制屏蔽
user_agent = "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Mobile Safari/537.36 Edg/131.0.0.0"
# 创建浏览器配置选项
chrome_options = webdriver.ChromeOptions()
# chrome_options.add_argument('--headless') # 可选:无头模式,不弹出浏览器
# chrome_options.add_argument('--disable-gpu') # 禁用 GPU
chrome_options.add_argument(f"user-agent={user_agent}") # 设置浏览器的 User-Agent
# 目标网站 URL
self.url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
# 创建 Chrome WebDriver 实例,并应用之前的配置
self.driver = webdriver.Chrome(options=chrome_options)
# 初始化存储数据的字典
self.data = {
"hs": { # hs 是一个板块的标识符
"xuHao": [],
"guPiaoDaiMa": [],
"guPiaoNingCheng": [],
"zuiXingBaoJia": [],
"zhangDieFu": [],
"zhangDieE": [],
"chengJiaoLiang": [],
"zhenFu": [],
"zuiGao": [],
"zuiDi": [],
"jinKai": [],
"zuoShou": [],
},
"sh": { # sh 是另一个板块的标识符
"xuHao": [],
"guPiaoDaiMa": [],
"guPiaoNingCheng": [],
"zuiXingBaoJia": [],
"zhangDieFu": [],
"zhangDieE": [],
"chengJiaoLiang": [],
"zhenFu": [],
"zuiGao": [],
"zuiDi": [],
"jinKai": [],
"zuoShou": [],
},
"sz": { # sz 是第三个板块的标识符
"xuHao": [],
"guPiaoDaiMa": [],
"guPiaoNingCheng": [],
"zuiXingBaoJia": [],
"zhangDieFu": [],
"zhangDieE": [],
"chengJiaoLiang": [],
"zhenFu": [],
"zuiGao": [],
"zuiDi": [],
"jinKai": [],
"zuoShou": [],
}
}
step2:确定爬取的形式,先爬取初始页面(沪深A股)若干页,再依次点击“上证A股”、“深证A股”板块对其股票信息的爬取
step3:找到下一页的按钮
代码:
self.driver.find_element(By.XPATH, '//*[@id="main-table_paginate"]/a[2]').click()
step4:找到跳转到“上证A股”、“深证A股”板块的按钮

step5:得到进程控制部分函数
注意:因为页面数据是动态加载的,所以要特别注意等待页面元素出现时再对数据进行获取或者是按钮的点击,这里我选用了隐式等待和time.sleep()强制等待,将time.sleep()加在加载稍微久一点的页面之前。至于为什么不选择使用显示等待呢,按理说显示等待是一个综合性最好的等待方式?因为页面的跳转没有特定的元素可以等待出现,所以直接用强制等待会好点。
# 处理页面数据,遍历不同板块并提取数据
def process(self, n, hs=True, sh=True, sz=True):
self.driver.implicitly_wait(10) # 设置隐式等待时间为 10 秒
self.driver.get(self.url) # 打开目标 URL
# 处理沪深 A 股板块
if hs:
select = 0 # hs 板块
for i in range(n): # n 代表需要抓取的页数
try:
self.parse(self.driver, select) # 解析当前页面的数据
if i == n - 1: # 如果是最后一页,则停止跳转
break
else:
# 点击分页按钮,跳转到下一页
self.driver.find_element(By.XPATH, '//*[@id="main-table_paginate"]/a[2]').click()
time.sleep(2) # 等待 2 秒以确保页面加载完成
except Exception as e:
print(e)
# 处理上海 A 股板块
if sh:
select = 1 # sh 板块
try:
self.driver.find_element(By.XPATH, "//li[@id='nav_sh_a_board']").click()
time.sleep(3)
for i in range(n):
self.parse(self.driver, select)
if i == n - 1:
break
else:
time.sleep(2)
self.driver.find_element(By.XPATH, '//*[@id="main-table_paginate"]/a[2]').click()
time.sleep(3)
except Exception as e:
print(e)
# 处理深圳 A 股板块
if sz:
select = 2 # sz 板块
try:
self.driver.find_element(By.XPATH, "//li[@id='nav_sz_a_board']").click()
time.sleep(3)
for i in range(n):
self.parse(self.driver, select)
if i == n - 1:
break
else:
time.sleep(2)
self.driver.find_element(By.XPATH, '//*[@id="main-table_paginate"]/a[2]').click()
time.sleep(3)
except Exception as e:
print(e)
step6:观察页面数据存储结构
step7:获取每一行tr
trs = driver.find_elements(By.XPATH, '//*[@id="table_wrapper-table"]/tbody/tr')
step8:解析每一行的数据
# 遍历每一行,将数据提取出来并添加到字典中
for tr in trs:
self.data[data_se]["xuHao"].append(tr.find_element(By.XPATH, "td[1]").text)
self.data[data_se]["guPiaoDaiMa"].append(tr.find_element(By.XPATH, "td[2]").text)
self.data[data_se]["guPiaoNingCheng"].append(tr.find_element(By.XPATH, "td[3]").text)
self.data[data_se]["zuiXingBaoJia"].append(tr.find_element(By.XPATH, "td[5]").text)
self.data[data_se]["zhangDieFu"].append(tr.find_element(By.XPATH, "td[6]").text)
self.data[data_se]["zhangDieE"].append(tr.find_element(By.XPATH, "td[7]").text)
self.data[data_se]["chengJiaoLiang"].append(tr.find_element(By.XPATH, "td[8]").text)
self.data[data_se]["zhenFu"].append(tr.find_element(By.XPATH, "td[10]").text)
self.data[data_se]["zuiGao"].append(tr.find_element(By.XPATH, "td[11]").text)
self.data[data_se]["zuiDi"].append(tr.find_element(By.XPATH, "td[12]").text)
self.data[data_se]["jinKai"].append(tr.find_element(By.XPATH, "td[13]").text)
self.data[data_se]["zuoShou"].append(tr.find_element(By.XPATH, "td[14]").text)
step9:效果展示

step10:将获取到的数据插入mysql数据库
# 将数据保存到 MySQL 数据库
def mySQL(self, name):
try:
# 连接到 MySQL 数据库
con = mysql.connector.connect(
host="localhost", # 数据库地址
user="root", # 数据库用户名
password="123456", # 数据库密码
database="DataAcquisition" # 数据库名称
)
cursor = con.cursor()
try:
# 如果表已存在,先删除
cursor.execute(f"DROP TABLE IF EXISTS {name}")
# 创建新表
sql = f"""
CREATE TABLE IF NOT EXISTS {name} (
xuHao VARCHAR(32) PRIMARY KEY,
guPiaoDaiMa VARCHAR(32),
guPiaoNingCheng VARCHAR(32),
zuiXingBaoJia VARCHAR(32),
zhangDieFu VARCHAR(32),
zhangDieE VARCHAR(32),
chengJiaoLiang VARCHAR(32),
zhenFu VARCHAR(32),
zuiGao VARCHAR(32),
zuiDi VARCHAR(32),
jinKai VARCHAR(32),
zuoShou VARCHAR(32)
)
"""
cursor.execute(sql)
except Exception as e:
print("Error creating table:", e)
# 准备插入数据的 SQL 语句
sql = f"""
INSERT INTO {name} (xuHao, guPiaoDaiMa, guPiaoNingCheng, zuiXingBaoJia, zhangDieFu, zhangDieE, chengJiaoLiang, zhenFu, zuiGao, zuiDi, jinKai, zuoShou)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
try:
# 遍历数据并插入到数据库
for i in range(len(self.data[name]["xuHao"])):
# 获取每一列的数据
xuHao = self.data[name]["xuHao"][i]
guPiaoDaiMa = self.data[name]["guPiaoDaiMa"][i]
guPiaoNingCheng = self.data[name]["guPiaoNingCheng"][i]
zuiXingBaoJia = self.data[name]["zuiXingBaoJia"][i]
zhangDieFu = self.data[name]["zhangDieFu"][i]
zhangDieE = self.data[name]["zhangDieE"][i]
chengJiaoLiang = self.data[name]["chengJiaoLiang"][i]
zhenFu = self.data[name]["zhenFu"][i]
zuiGao = self.data[name]["zuiGao"][i]
zuiDi = self.data[name]["zuiDi"][i]
jinKai = self.data[name]["jinKai"][i]
zuoShou = self.data[name]["zuoShou"][i]
# 执行插入操作
cursor.execute(sql, (xuHao, guPiaoDaiMa, guPiaoNingCheng, zuiXingBaoJia, zhangDieFu, zhangDieE, chengJiaoLiang, zhenFu, zuiGao, zuiDi, jinKai, zuoShou))
except Exception as err:
print("Error inserting data:", err)
# 提交事务并关闭连接
con.commit()
con.close()
except Exception as err:
print("Error:", err)
step11:启动程序
# 创建爬虫对象
stock = spider()
# 开始抓取数据,抓取两页数据(n=2),同时抓取沪深A股、上证A股、深证A股
stock.process(n=2, hs=True, sh=True, sz=True)
# 获取抓取的数据
data = stock.getData()
# 将数据保存到 MySQL 数据库中
stock.mySQL("hs")
stock.mySQL("sh")
stock.mySQL("sz")
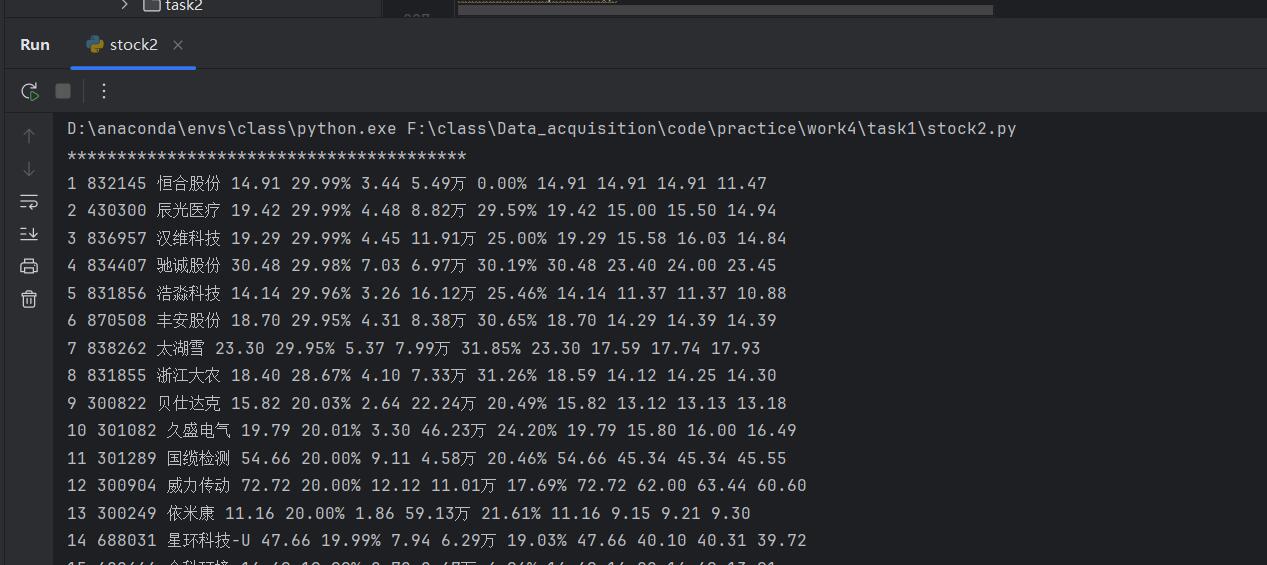
step12:数据库中查看结果
🍔沪深A股
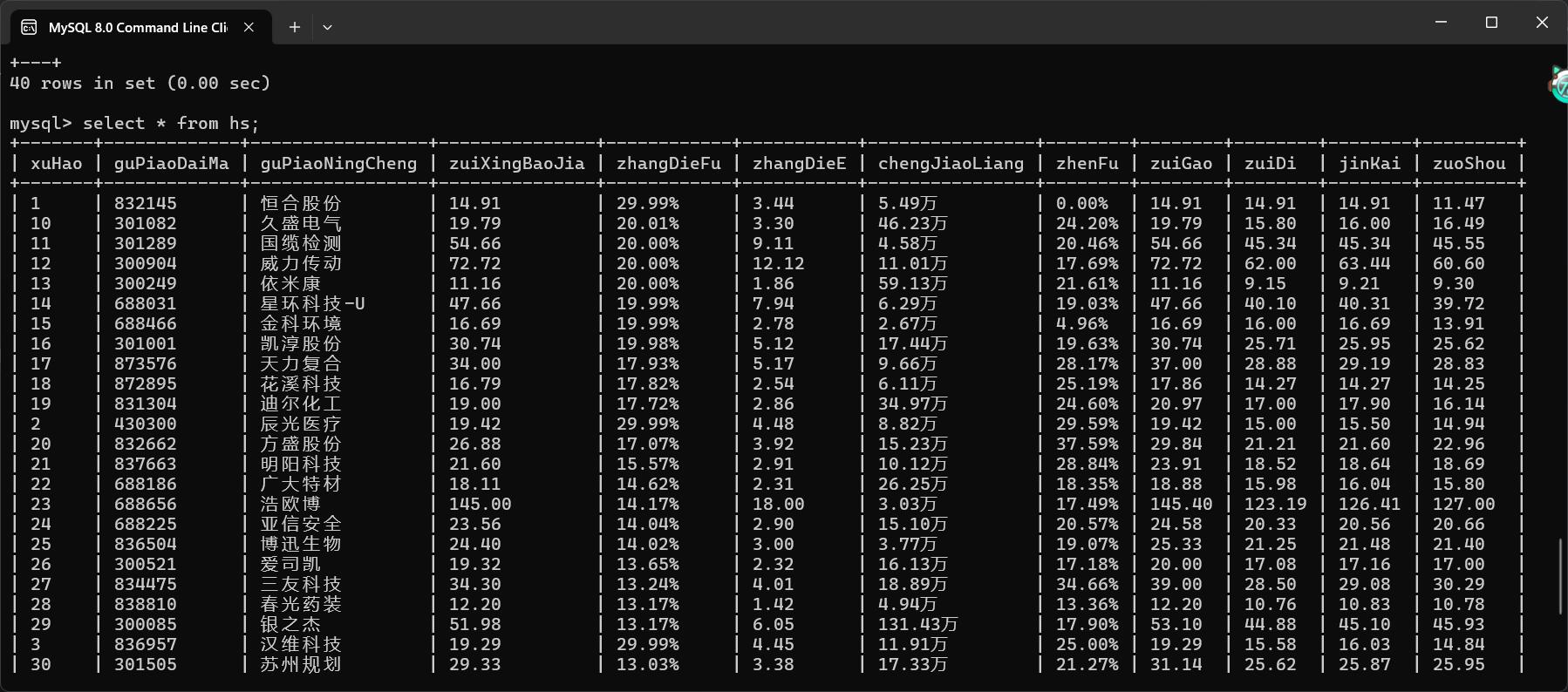
🥟上证A股
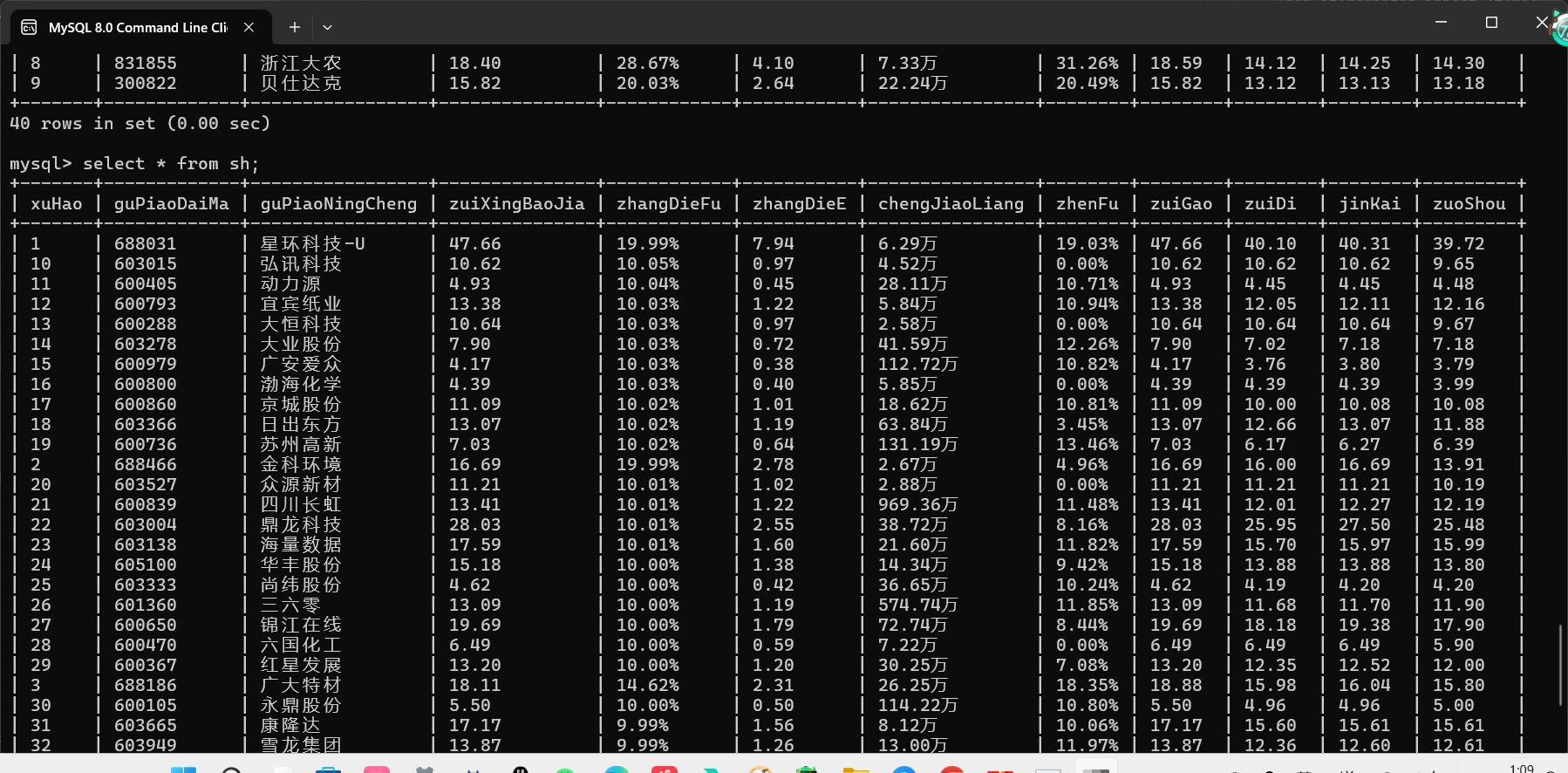
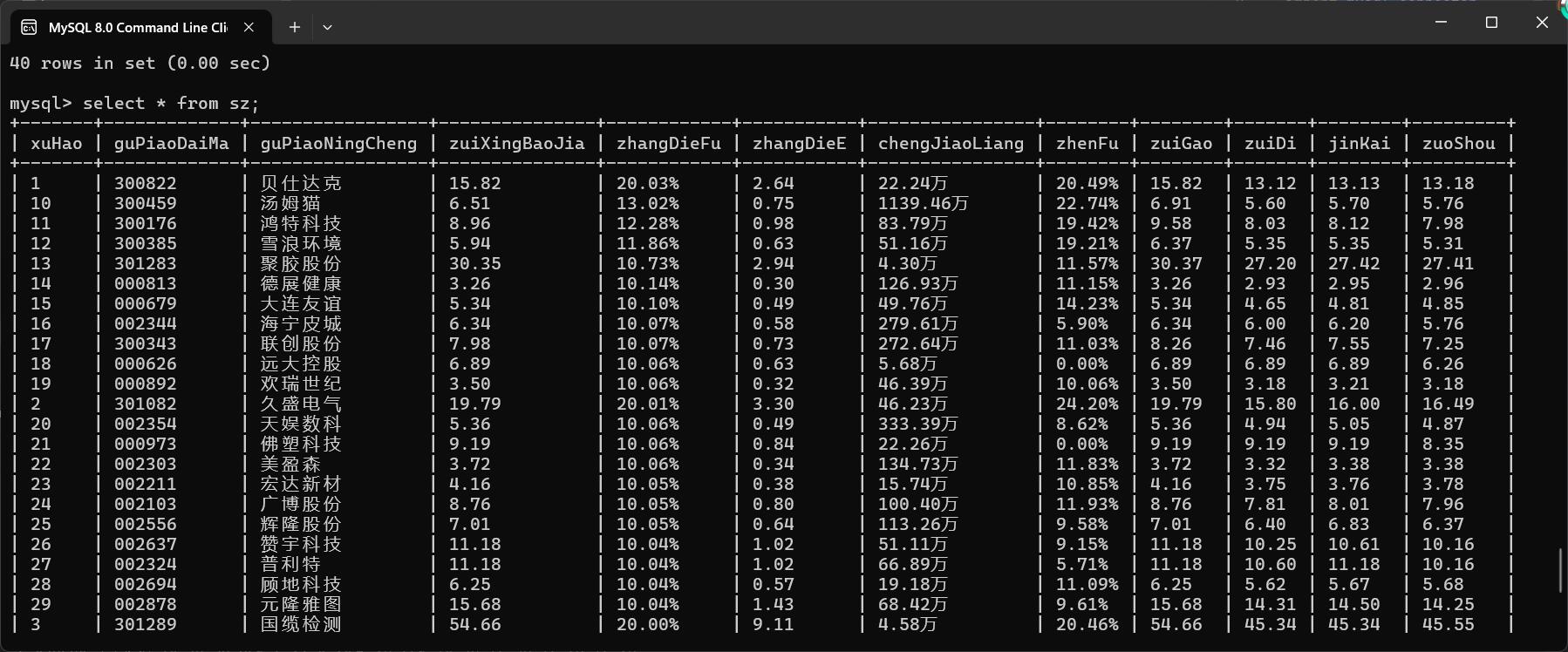
🍟深证A股
(二)心得
对于本次基于Selenium和MySQL的股票信息爬取项目,我深入了解了如何利用Selenium模拟浏览器操作来抓取动态加载的网页数据,并将抓取的数据存储到MySQL数据库中。由于目标网页的数据是动态加载的,我特别注意了等待机制,使用了隐式等待和time.sleep()来确保页面加载完成,从而获取到完整的数据。数据抓取过程中,我通过XPath定位页面中的股票信息,将每一行的数据提取并存储在字典中,包括股票代码、名称、价格、涨跌幅等多个字段。其次,我将抓取到的数据通过Python的mysql.connector库插入到MySQL数据库中,首先创建数据表,然后批量插入每一条股票记录。过程中,我还增加了异常处理机制,确保在出现错误时不会导致整个程序崩溃,例如在点击分页按钮或获取元素时发生异常时,程序能够捕获并输出错误信息。
尽管如此,爬虫仍面临一些优化空间。例如,使用time.sleep()来强制等待并不是最优方案,显式等待可以更精确地控制页面加载时间,提高效率,不过该网站没有合适的显示等待的元素,所以我并没有采用显示等待控制页面加载时间;另外,随着数据量的增加,爬取速度和存储效率也需要进一步优化,例如通过并发技术提升抓取速度或使用批量存储减少内存压力。
总体而言,这次实践不仅让我深入了解了Selenium和MySQL的应用,还让我意识到爬虫开发中的挑战,尤其是在应对动态加载和反爬虫机制时需要细致的技术方案。通过本次项目,我积累了不少经验,也对未来提升爬虫效率和稳定性充满信心。
二、Selenium+ MySQL爬取并存储中国mooc网课程资源信息
(一)步骤
爬取网站:https://www.icourse163.org
step1:定义spider类并进行初始化
def __init__(self):
# 设置一个自定义的User-Agent,避免被网站识别为机器人
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"
# 创建一个Chrome浏览器选项对象
chrome_options = webdriver.ChromeOptions()
# 设置为无头模式
# chrome_options.add_argument('--headless')
# chrome_options.add_argument('--disable-gpu')
# 使用自定义的User-Agent
chrome_options.add_argument(f"user-agent={user_agent}")
# 设置目标网址
self.url = "https://www.icourse163.org"
# 初始化浏览器驱动对象,使用自定义的选项
self.driver = webdriver.Chrome(options=chrome_options)
# 用于存储抓取的数据
self.data = {
"cousrseID": [], # 课程ID
"courseName": [], # 课程名称
"courseCollege": [], # 所属学院
"teacherMain": [], # 主讲老师
"teacherS": [], # 其他讲师
"number": [], # 学生人数
"progress": [], # 学习进度
"brief": [] # 课程简介
}
step2:先解决登陆问题,找到登陆按钮
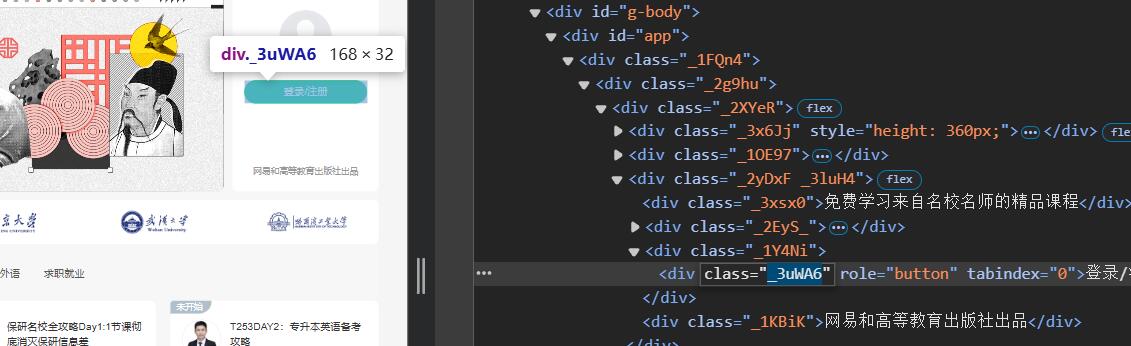
代码:
self.driver.find_element(By.XPATH, "//div[@class='_3uWA6']").click()
step3:查找并进入iframe
iframe,即内联框架(Inline Frame),是HTML中的一个元素,它允许在当前HTML页面中嵌入另一个独立的HTML文档。这个元素在网页设计中非常有用,尤其是当需要在一个页面中显示另一个页面的内容时。所有主流浏览器都支持iframe标签。

代码:
# 查找并切换到登录框的iframe
iframe = self.driver.find_element(By.XPATH,
"/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div[1]/div/iframe")
self.driver.switch_to.frame(iframe)
step4:查找输入框和登陆按钮
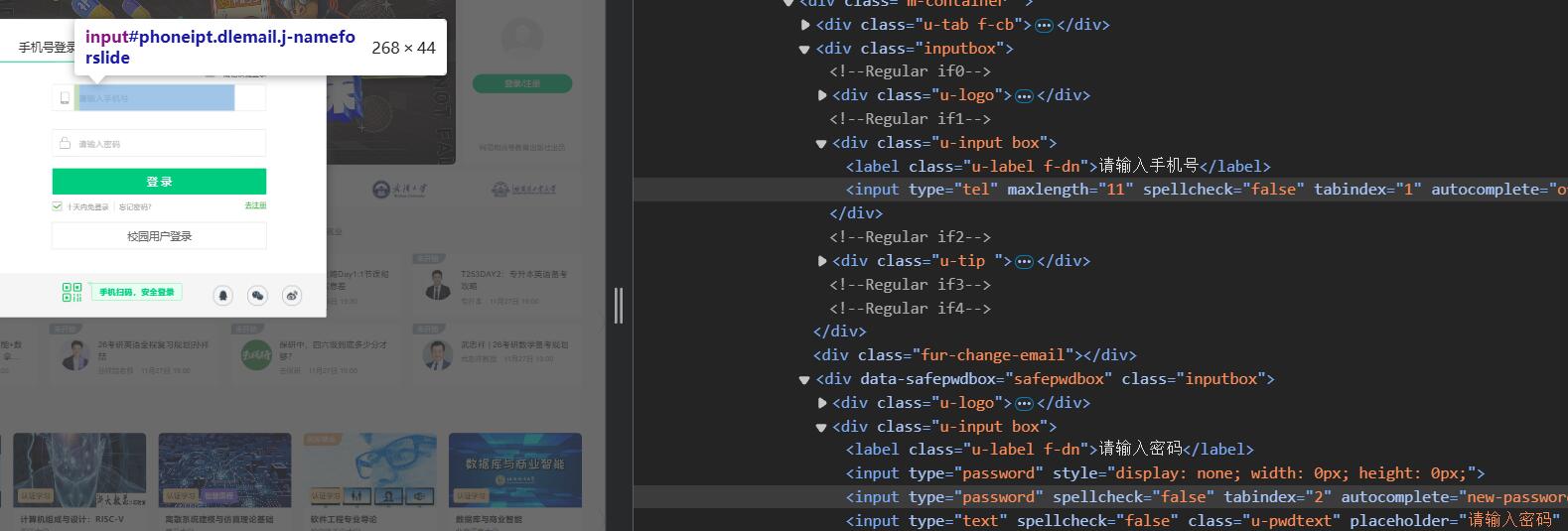
代码:
# 输入手机号和密码进行登录
self.driver.find_element(By.XPATH, '//*[@id="phoneipt"]').send_keys("手机号")
self.driver.find_element(By.XPATH, '//*[@id="login-form"]/div/div[4]/div[2]/input[2]').send_keys("密码")
# 点击登录按钮
self.driver.find_element(By.XPATH, '//a[@id="submitBtn"]').click()
step5:要注意,登陆后要退出iframe,使driver切回至主页面
# 切换回主页面
self.driver.switch_to.default_content()
step6:成功登陆后,想要在输入框中输入课程并查找,就得先同意它的隐私条款,这里就是要找到同意的button并点击
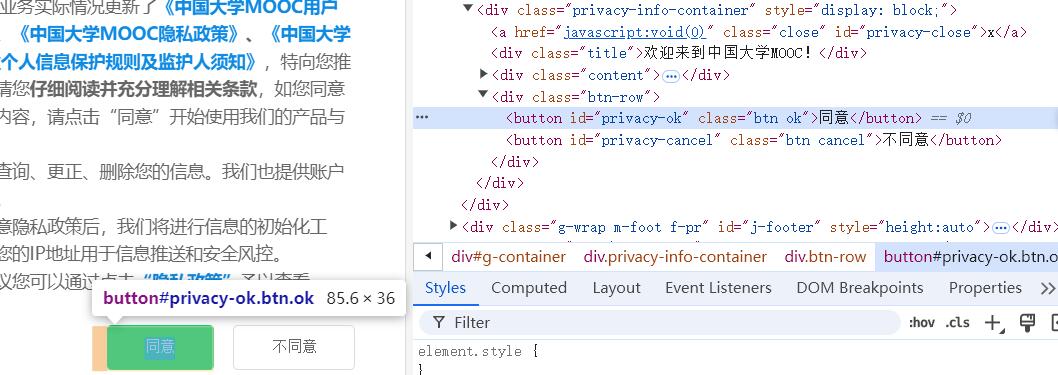
代码:
# 等待隐私条款同意按钮加载完成并点击
WebDriverWait(self.driver, 10, 0.5).until(
EC.element_to_be_clickable((By.XPATH, '//button[@id="privacy-ok"]'))
)
self.driver.find_element(By.XPATH, '//button[@id="privacy-ok"]').click()
step7:找到搜索框,并向其输入关键字
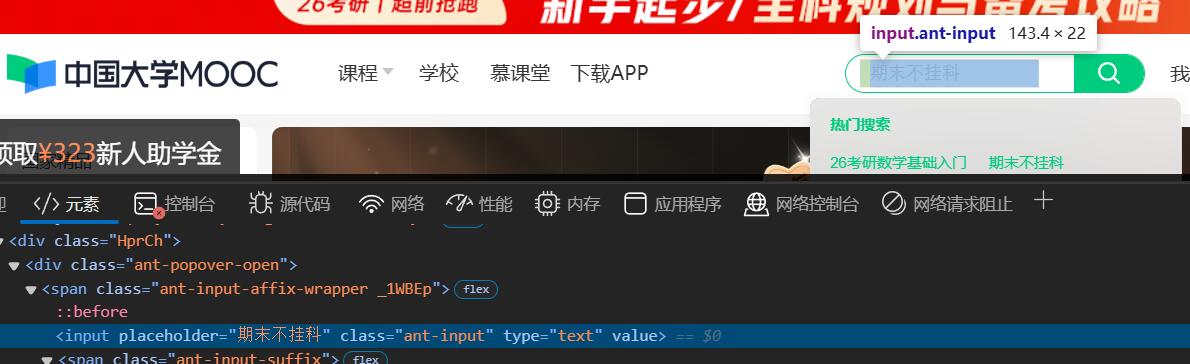
代码:
# 搜索课程函数
def search(self, course):
# 向搜索框输入课程名称
self.driver.find_element(By.XPATH, '//input[@class="ant-input"]').send_keys(course)
# 点击搜索按钮
self.driver.find_element(By.XPATH, '//span[@class="E3Zsq"]').click()
step8:成功搜索
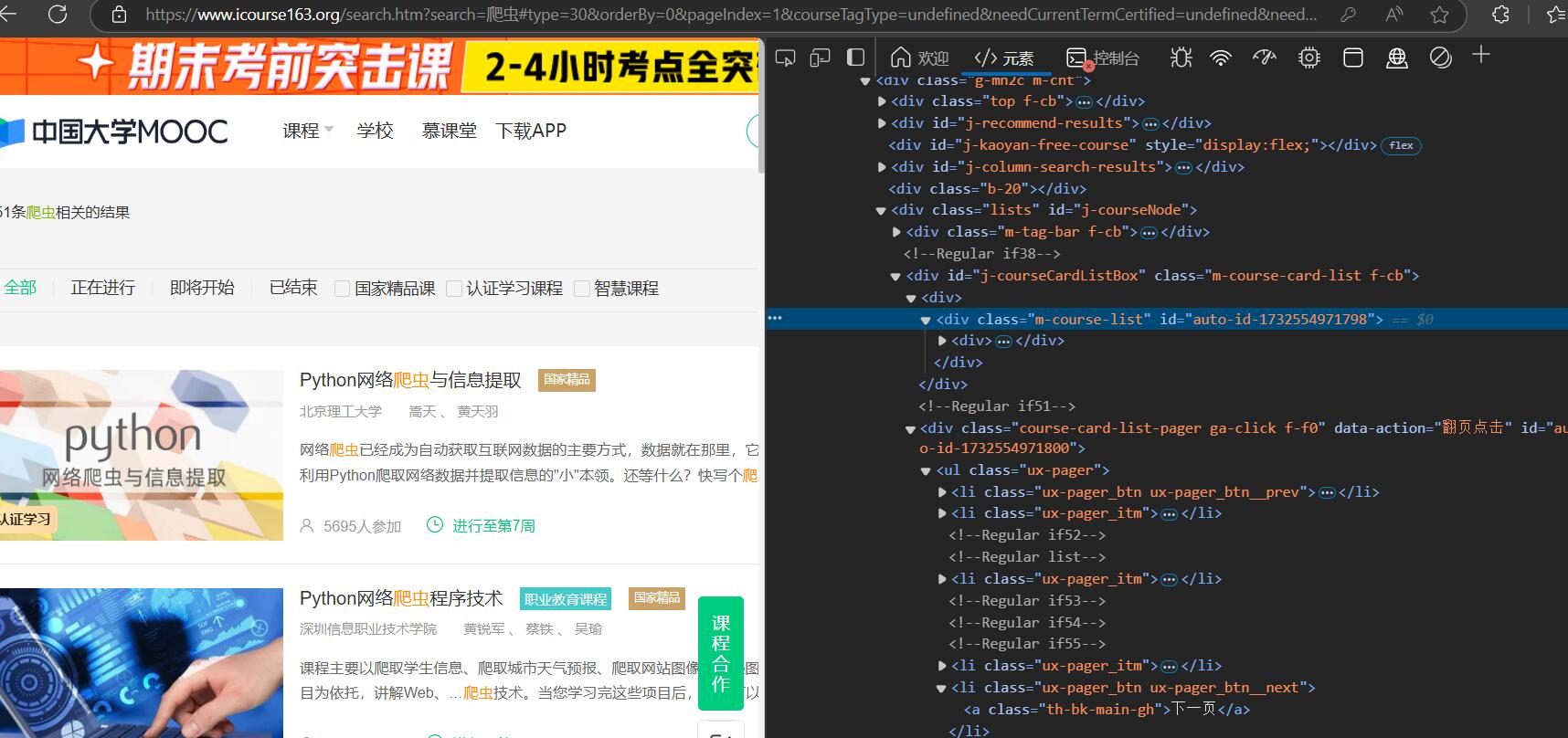
step9:接下来就是解析网页,分析需求,我们需要获取网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介),其中的课程号没有在页面上直接显示,但是我们可以分析课程的url可以发现,其课程对应的url的一部分就是课程号,比如url"//www.icourse163.org/course/BIT-1001870001?from=searchPage&outVendor=zw_mooc_pcssjg_",其课程号为BIT-1001870001
step10:提取课程号
href = mooc.find_element(By.XPATH, './/div[@class="g-mn1c"]/div/div/a[1]').get_attribute("href")
cousrseID = re.search(r'course/([^?&]+)', href).group(1)
step11:其它信息则使用xpath对页面解析直接获取
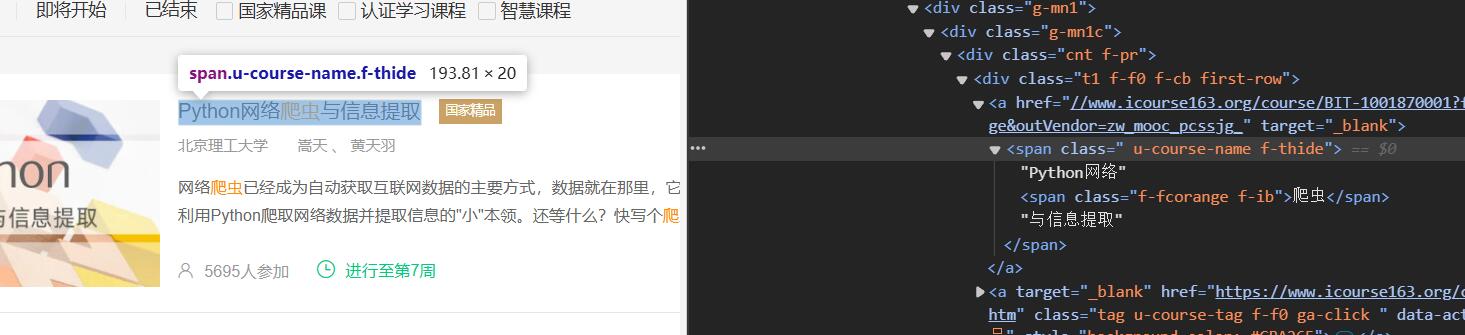
代码:
moocsList = self.driver.find_elements(By.XPATH, '//div[@class="m-course-list"]/div/div')
for mooc in moocsList:
try:
href = mooc.find_element(By.XPATH, './/div[@class="g-mn1c"]/div/div/a[1]').get_attribute("href")
cousrseID = re.search(r'course/([^?&]+)', href).group(1)
courseName = mooc.find_element(By.XPATH, './/div[@class="g-mn1c"]/div/div/a[1]/span').text
courseCollege = mooc.find_element(By.XPATH, './/div[@class="g-mn1c"]/div/div[2]/a[1]').text
teachers = mooc.find_elements(By.XPATH, './/a[@class="f-fc9"]')
teacherMain = teachers[0].text
teacherS = ""
for teacher in teachers[1:]:
teacherS = teacher.text + "、" + teacherS
# print(teacher.text)
if teacherS.endswith("、"):
teacherS = teacherS[:-1]
number = mooc.find_element(By.XPATH, './/div[@class="g-mn1c"]//span[@class="hot"]').text
progress = mooc.find_element(By.XPATH, './/div[@class="g-mn1c"]//span[@class="txt"]').text
brief = mooc.find_element(By.XPATH, './/div[@class="g-mn1c"]/div/a/span').text
step11.5:进行翻页处理,找到翻页的按钮并进行点击
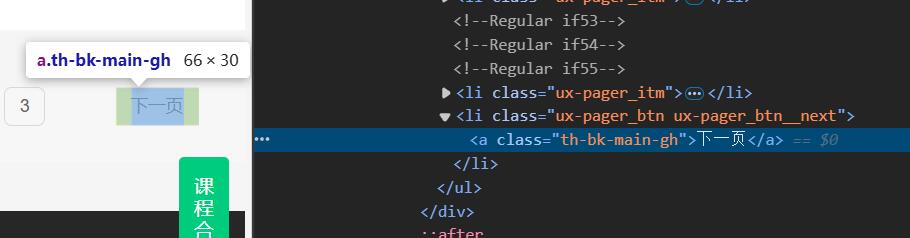
代码:
for i in range(1, page + 1):
self.parse()
if i==page:
break
else:
self.driver.find_element(By.XPATH, '//ul[@class="ux-pager"]/li[5]/a').click()
step12:解析出数据并打印
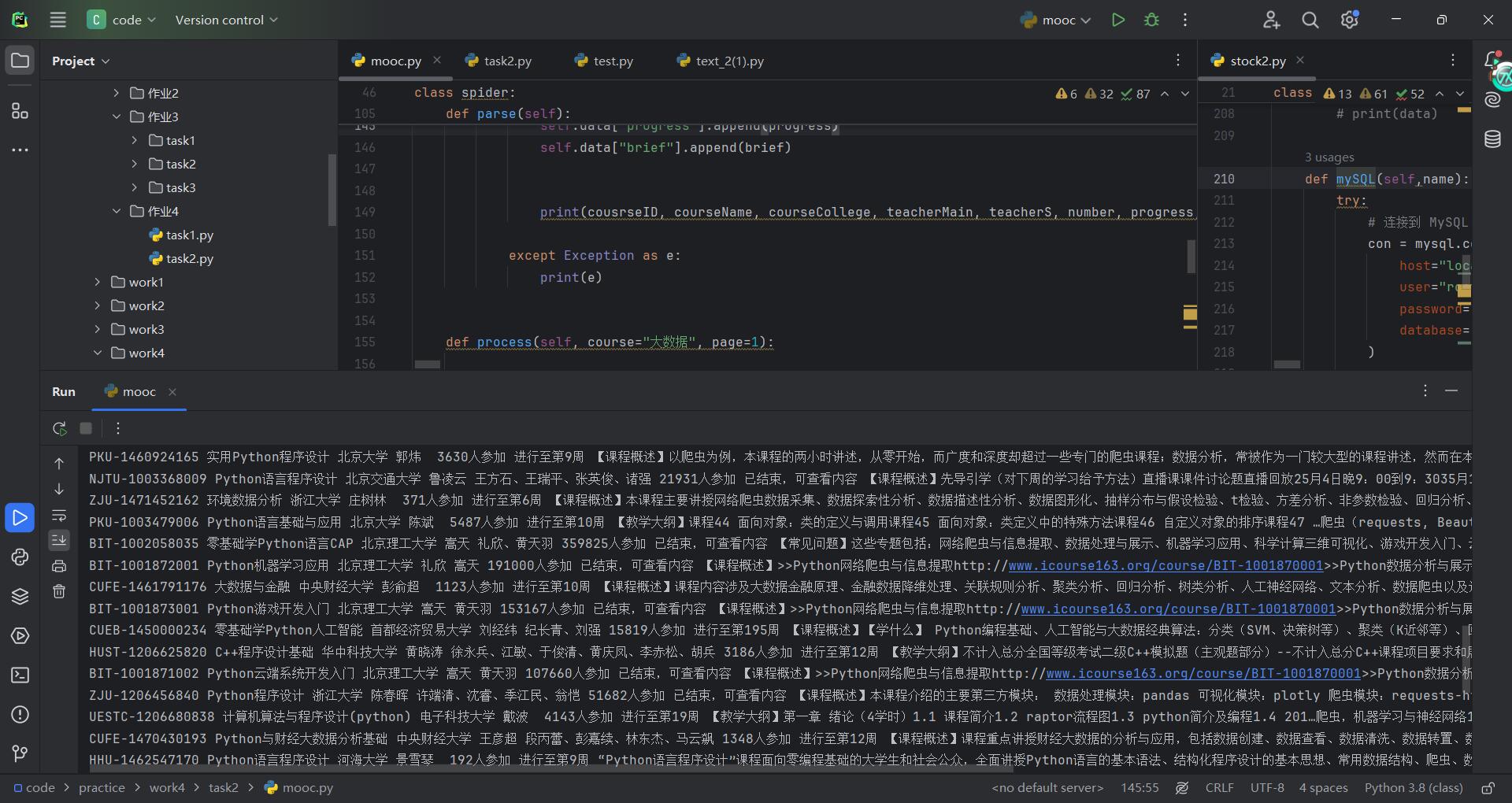
step13:存储到MySQL中,编写插入函数
def mySQL(self):
try:
# 连接到 MySQL 数据库(修改为你的数据库配置)
con = mysql.connector.connect(
host="localhost", # 数据库地址
user="root", # 数据库用户名
password="123456", # 数据库密码
database="DataAcquisition" # 你数据库的名称
)
cursor = con.cursor()
try:
# 删除旧表(如果存在)
cursor.execute(f"DROP TABLE IF EXISTS mooc")
# 创建表结构
sql = f"""
CREATE TABLE IF NOT EXISTS mooc (
cousrseID VARCHAR(32) PRIMARY KEY,
courseName VARCHAR(32),
courseCollege VARCHAR(32),
teacherMain VARCHAR(32),
teacherS VARCHAR(32),
number_ VARCHAR(32),
progress VARCHAR(32),
brief VARCHAR(256)
)
"""
cursor.execute(sql)
except Exception as e:
print("Error creating table:", e)
# 准备插入数据
sql = f"""
INSERT INTO mooc (cousrseID, courseName, courseCollege, teacherMain, teacherS, number_, progress, brief)
VALUES (%s, %s, %s, %s, %s, %s,%s, %s)
"""
try:
for i in range(len(self.data["cousrseID"])):
cousrseID = self.data["cousrseID"][i]
courseName = self.data["courseName"][i]
courseCollege = self.data["courseCollege"][i]
teacherMain = self.data["teacherMain"][i]
teacherS = self.data["teacherS"][i]
number = self.data["number"][i]
progress = self.data["progress"][i]
brief = self.data["brief"][i]
# 执行 SQL 插入语句
cursor.execute(sql, (cousrseID, courseName, courseCollege, teacherMain, teacherS, number, progress, brief))
except Exception as err:
print("Error inserting data:", err)
# 提交事务并关闭连接
con.commit()
con.close()
except Exception as err:
print("Error:", err)
step14:使用类进行调度,运行代码
mooc = spider()
mooc.process(course="爬虫", page=2)
mooc.mySQL()
step15:效果展示
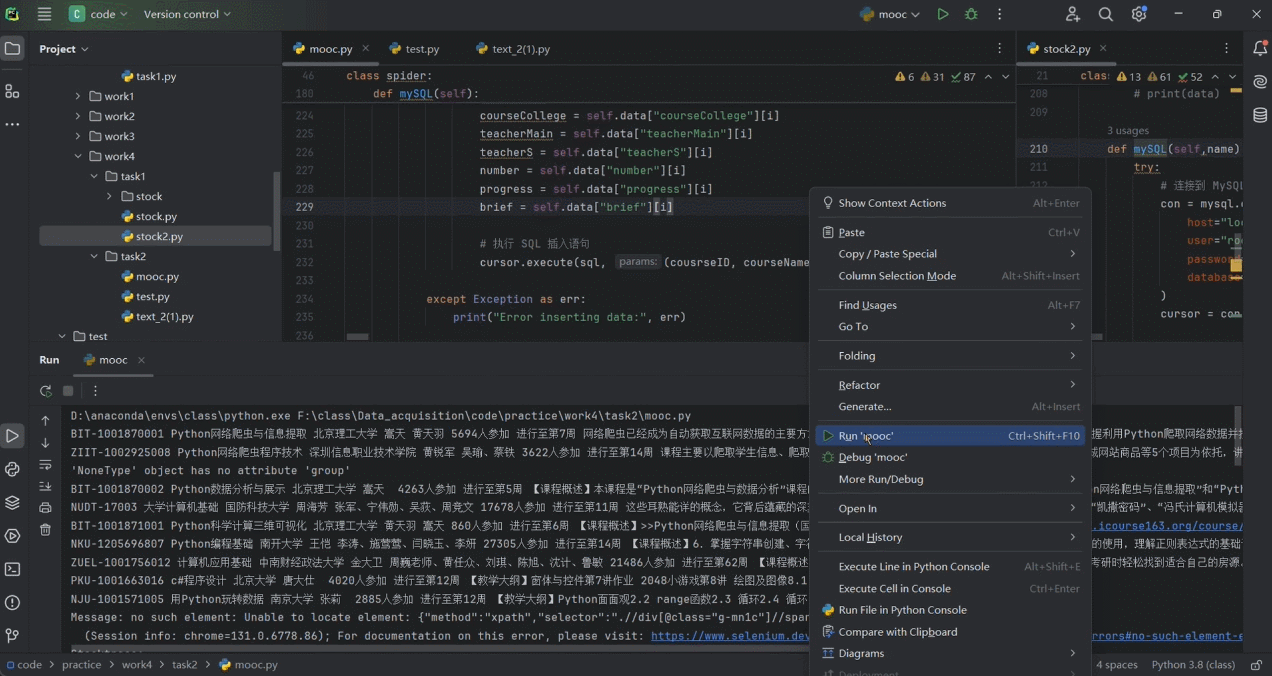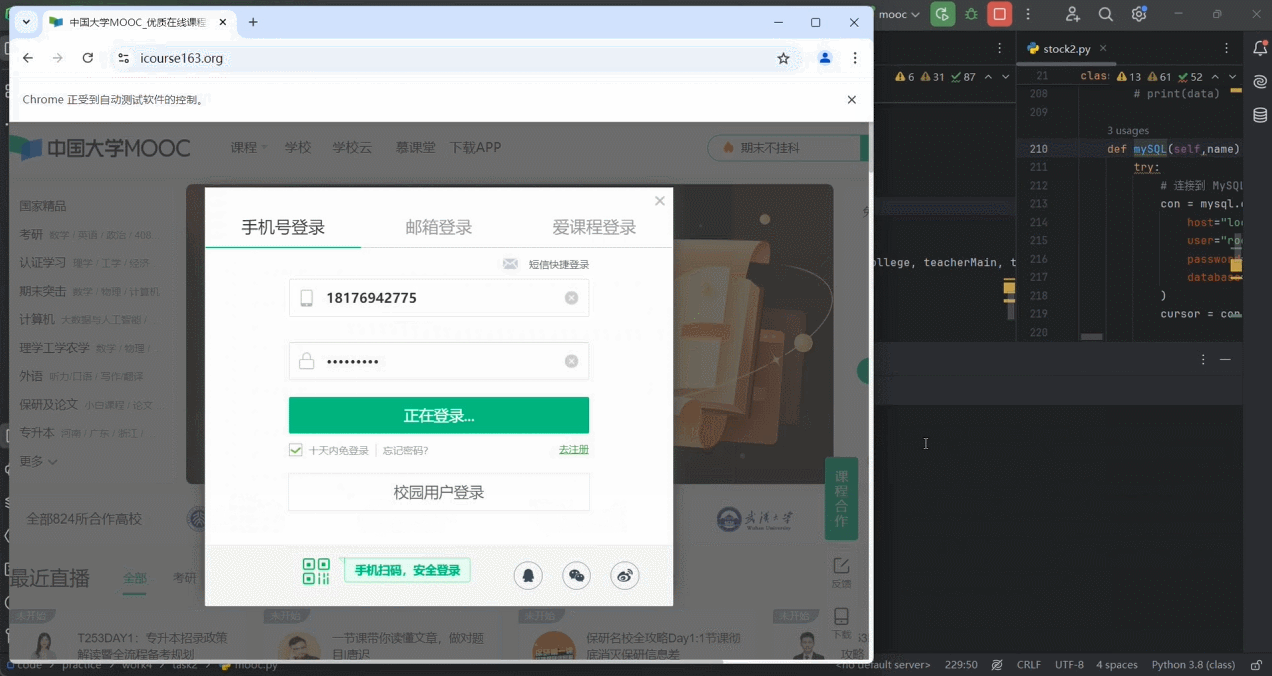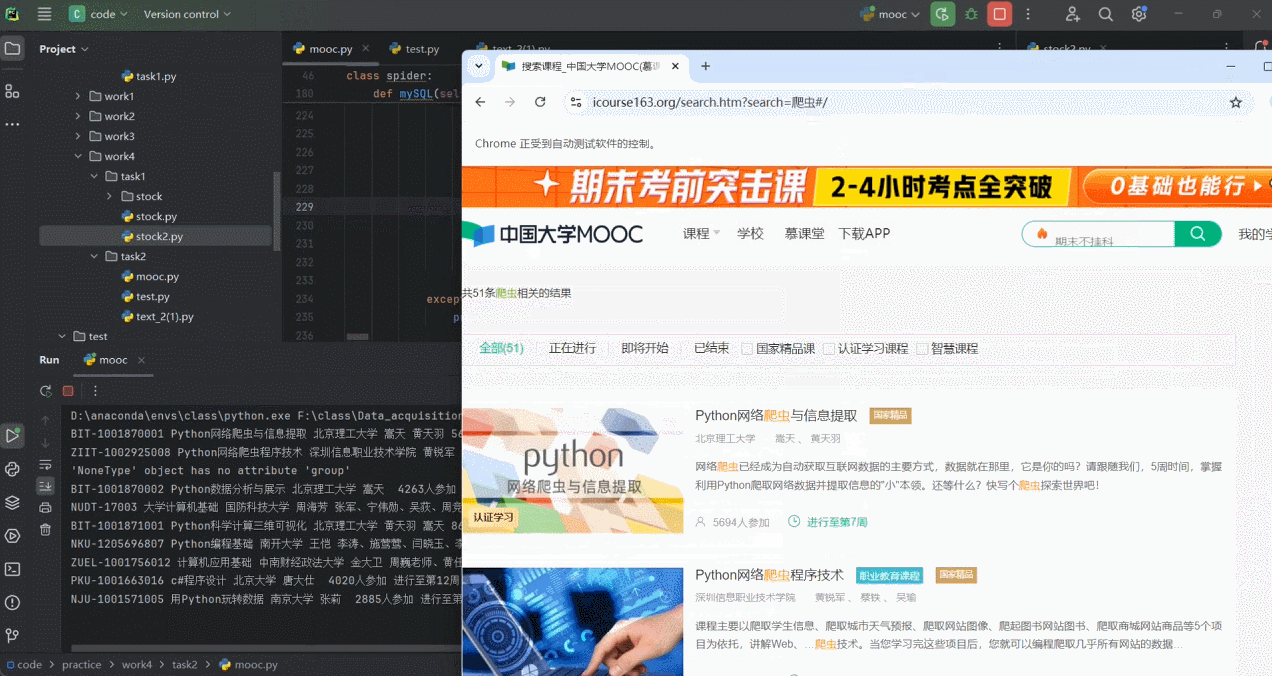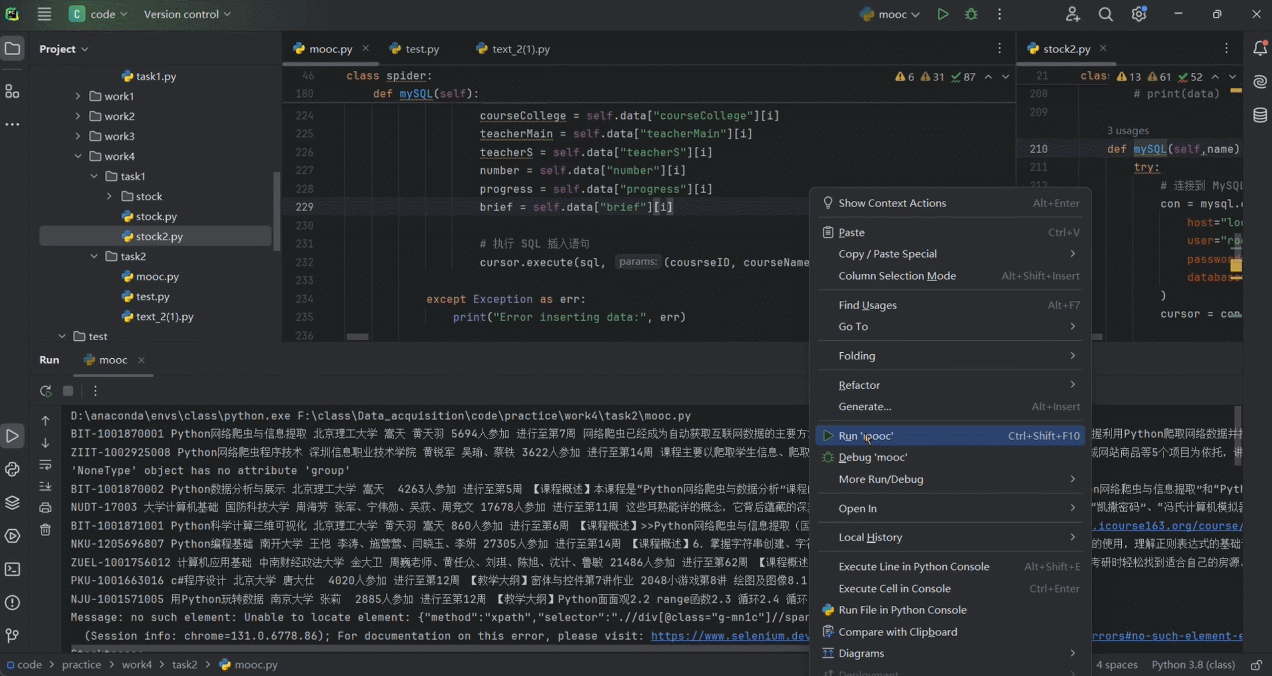
step16:数据库中查看(排版有点丑不要介意🤕)
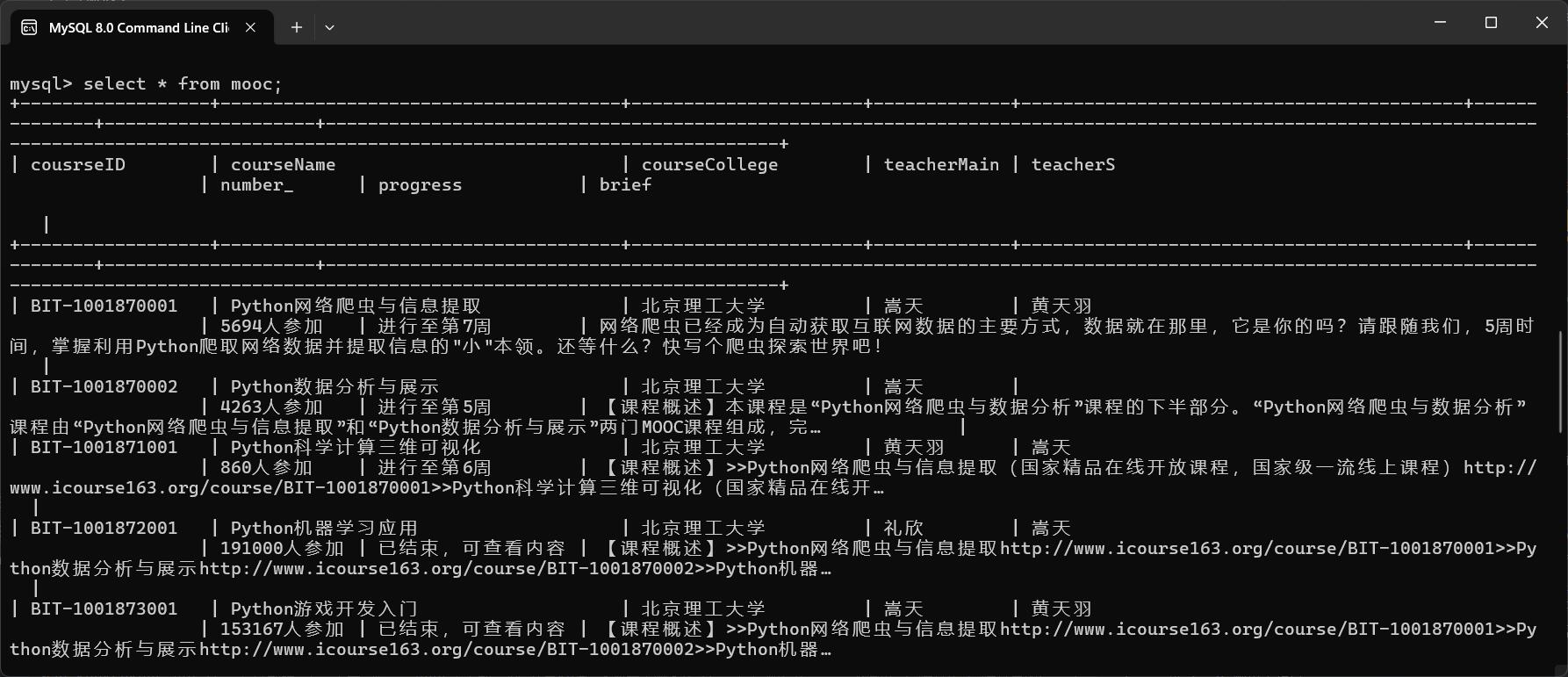
(二)心得
🍩对于Selenium的应用
首先,Selenium作为一个强大的自动化测试工具,在网页爬取过程中发挥了至关重要的作用。在爬取MOOC网站的数据时,初步遇到的问题是如何正确模拟用户登录。由于MOOC网站有复杂的登录框架和iframe结构,我需要通过XPath准确定位登录按钮及输入框。尤其是在使用iframe时,必须先切换到相应的iframe内,进行操作后再切换回主页面,这一过程需要较为细致的调试。
🍪对于数据的抓取与解析
抓取课程信息时,我不仅需要从网页元素中提取基础信息(如课程名、学院、讲师、学生人数等),还需要通过分析URL来提取课程ID。这种从URL中提取关键信息的技巧,帮助我规避了直接在页面上找不到课程ID的难题。
Selenium提供了灵活的定位方式,除了可以直接通过XPath提取信息,还能通过find_element或find_elements等方法获取单个或多个元素。通过对MOOC课程页面的分析,我能够准确提取出每一门课程的详细信息,并保存在一个字典中,待后续存储到数据库。
🍰对于翻页与异步处理
MOOC网站的课程信息是分页显示的,因此在抓取数据时需要处理翻页问题。为了能够抓取多页数据,我使用了Selenium的翻页操作,通过找到“下一页”按钮并模拟点击,来循环抓取每一页的数据。这个操作非常考验代码的鲁棒性,因为如果翻页过程中遇到元素加载慢,可能会导致错误。
通过使用WebDriverWait和EC.element_to_be_clickable方法,我确保了每次翻页操作都能等待页面完全加载后再进行,避免了因为页面未完全加载而导致的抓取失败。
🍫对于数据存储与MySQL
在完成数据的抓取和解析后,我将结果存储到MySQL数据库中。为了避免重复插入数据,我首先删除了数据库中已有的表,并创建了一个新的表结构。然后,通过INSERT INTO语句将抓取到的数据逐条插入数据库。
这个过程并不复杂,但需要注意数据的准确性和格式问题,例如如何处理空值、特殊字符等。虽然Selenium能够抓取到页面上的内容,但在存储到数据库时,仍然需要对数据进行一定的清洗和格式化,确保其能够正确存储和查询。
🍭总结
虽然本次实践的过程中我成功抓取并存储了数据,但仍然存在一些问题,比如在处理网页加载缓慢或翻页时出现的异常情况。在今后的工作中,我将进一步优化爬虫的稳定性和效率,例如通过使用多线程技术提高爬取速度,或者加入更强的异常处理机制,提升程序的容错能力。
总之,这次项目不仅提高了我在自动化爬虫和数据存储方面的技能,也让我深刻认识到爬虫技术在实际开发中的重要性和挑战性。
三、Flume日志采集
(一)步骤
3.1 Python脚本生成测试数据
3.2 下载安装并配置Kafka
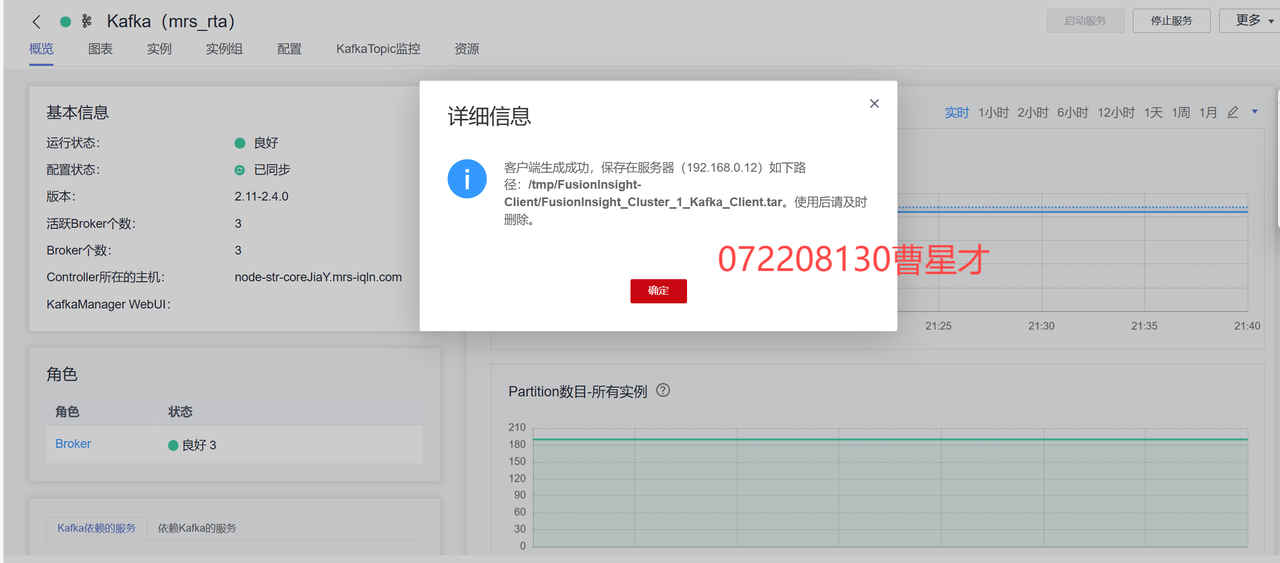
3.2.1 下载kafka客户端
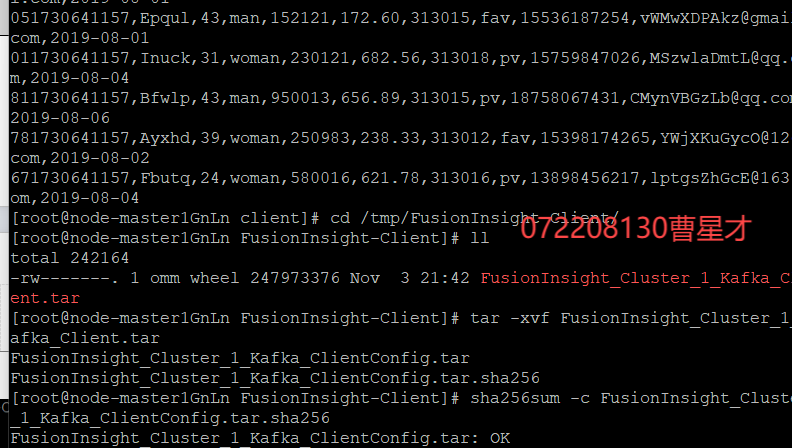
3.2.2 校验下载的客户端文件包
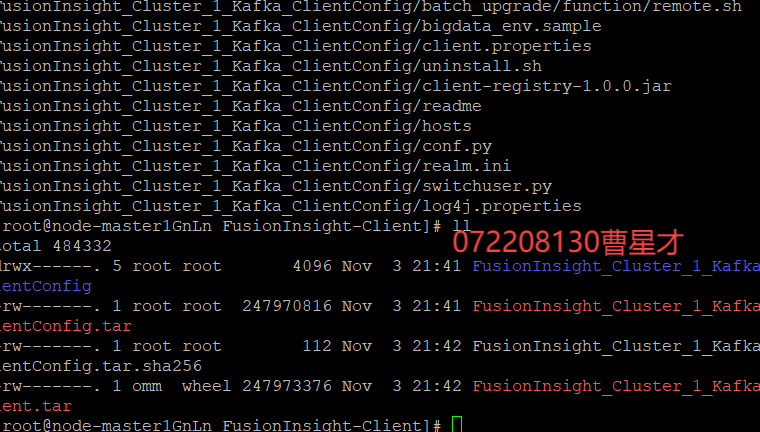
3.2.3 安装kafka运行环境
3.2.4 查看topic信息
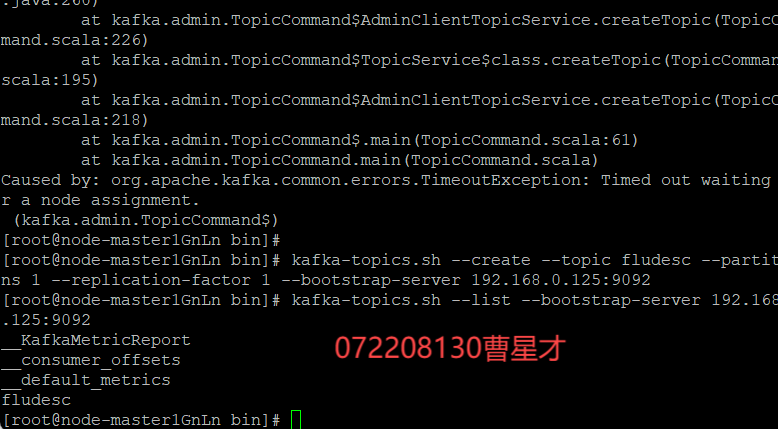
3.3 安装Flume客户端
3.3.1 下载Flume客户端
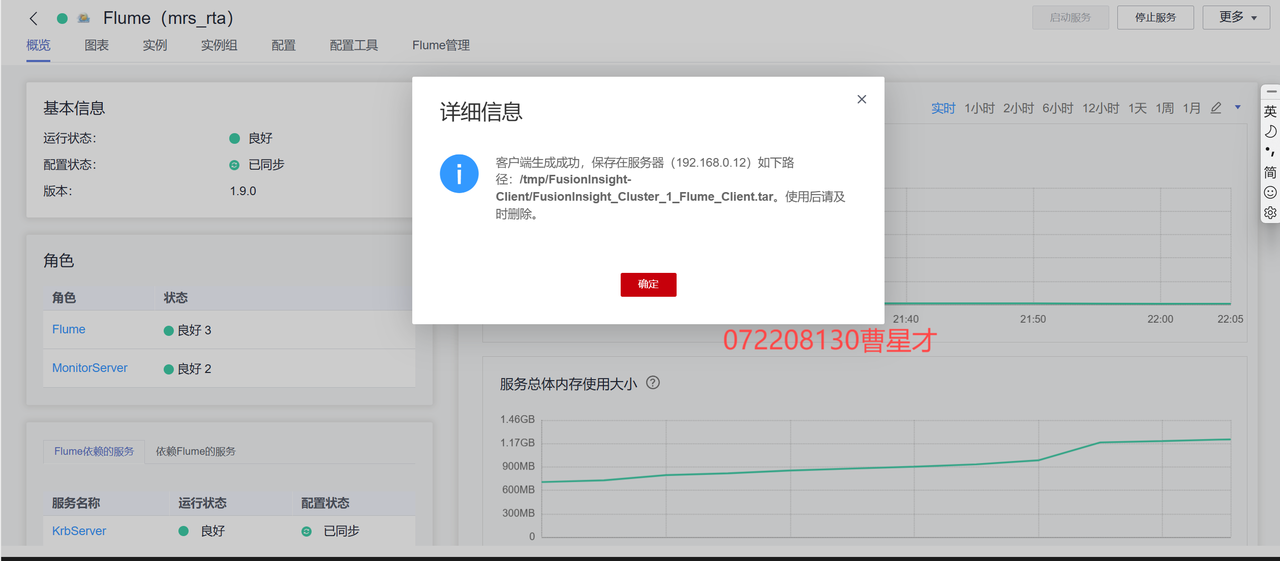
3.3.2 校验下载的客户端文件包
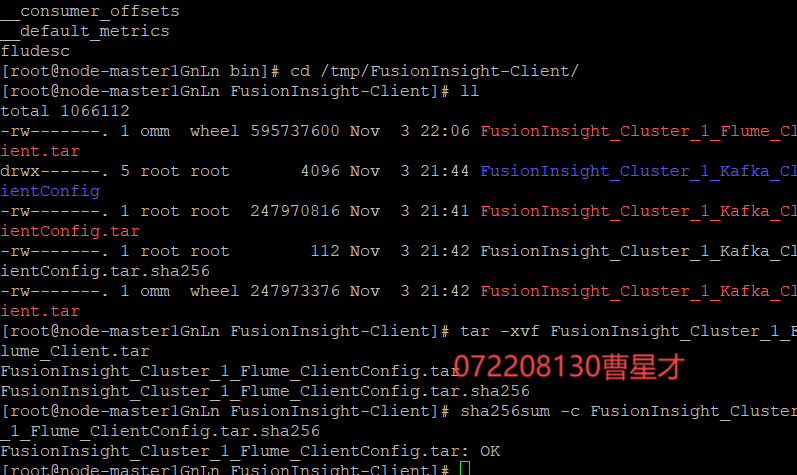
3.3.3 重启Flume服务
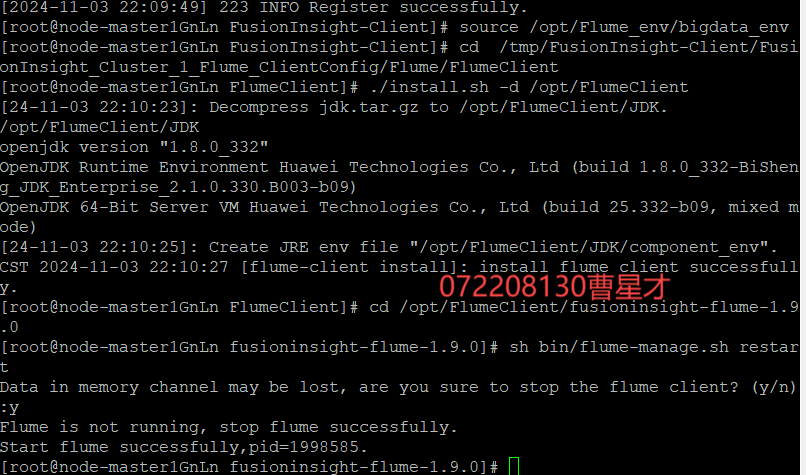
3.4 配置Flume采集数据
3.5 MySQL中准备结果表与维度表数据
3.5.1 创建维度表并插入数据
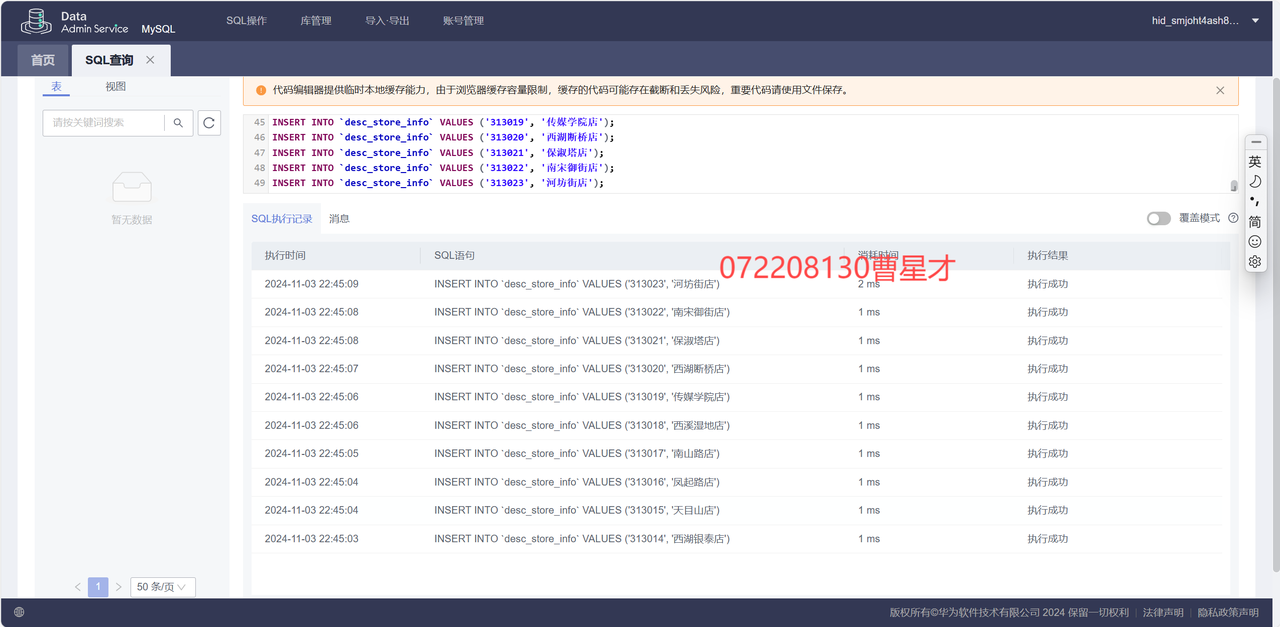
3.5.2 创建Flink作业的结果表
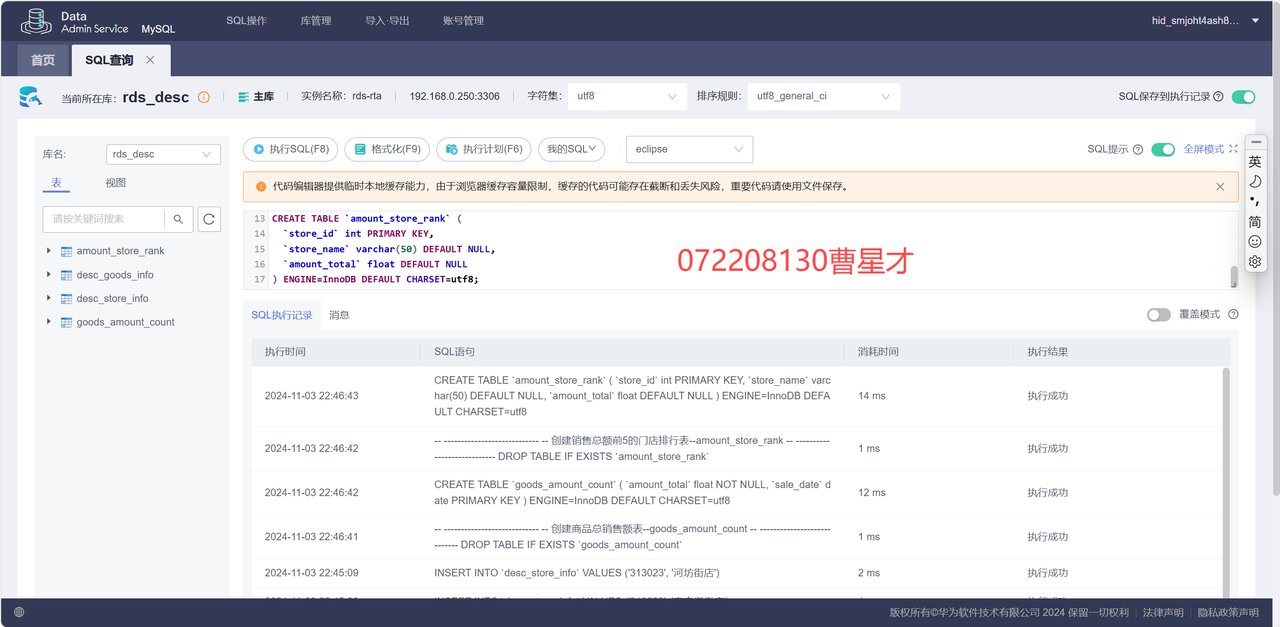
3.6 使用DLI中的Flink作业进行数据分析
3.6.1 测试网络连通性

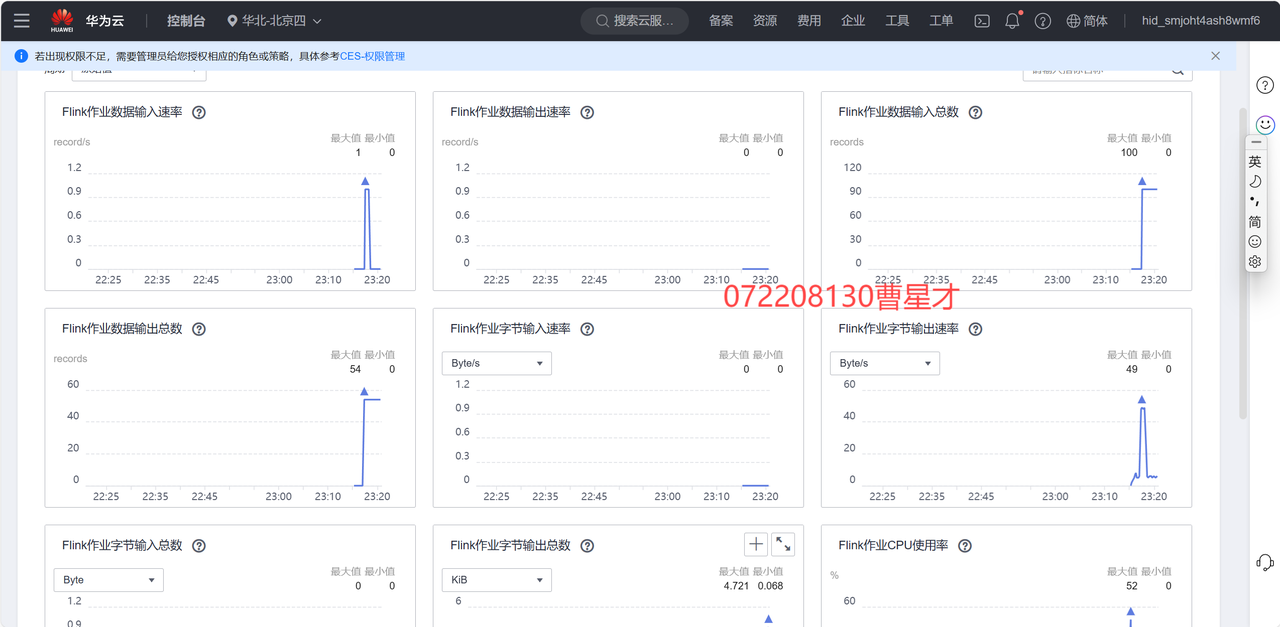
3.6.2 运行Flink作业
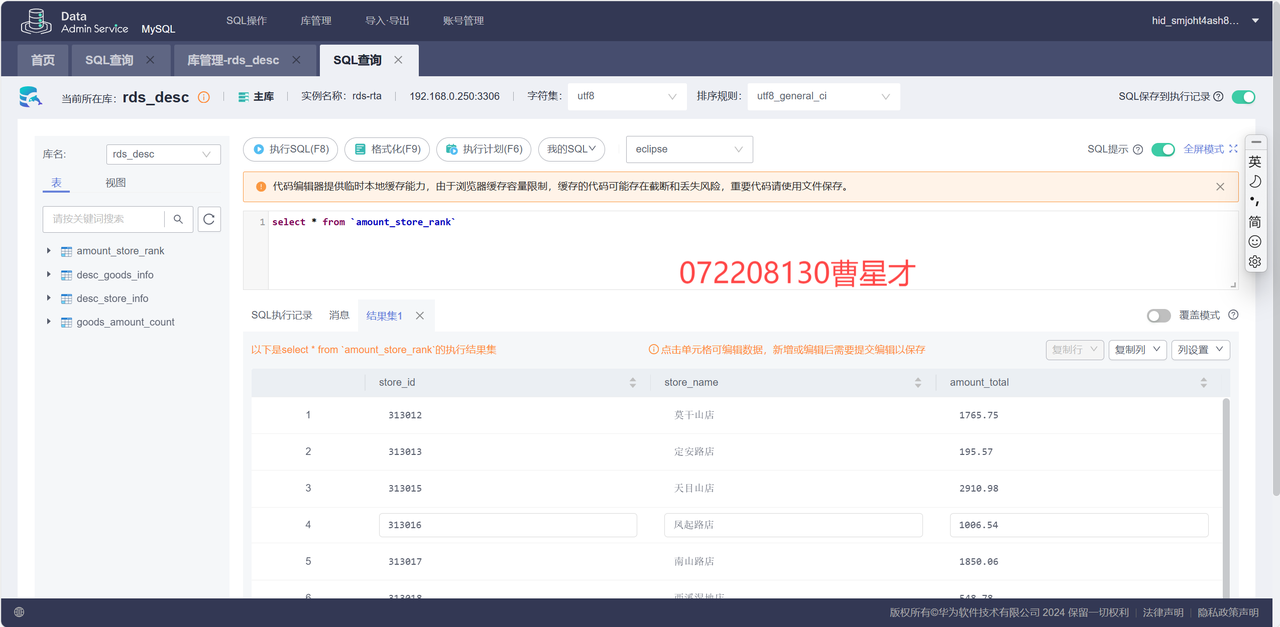
验证数据分析:
SQL查询:
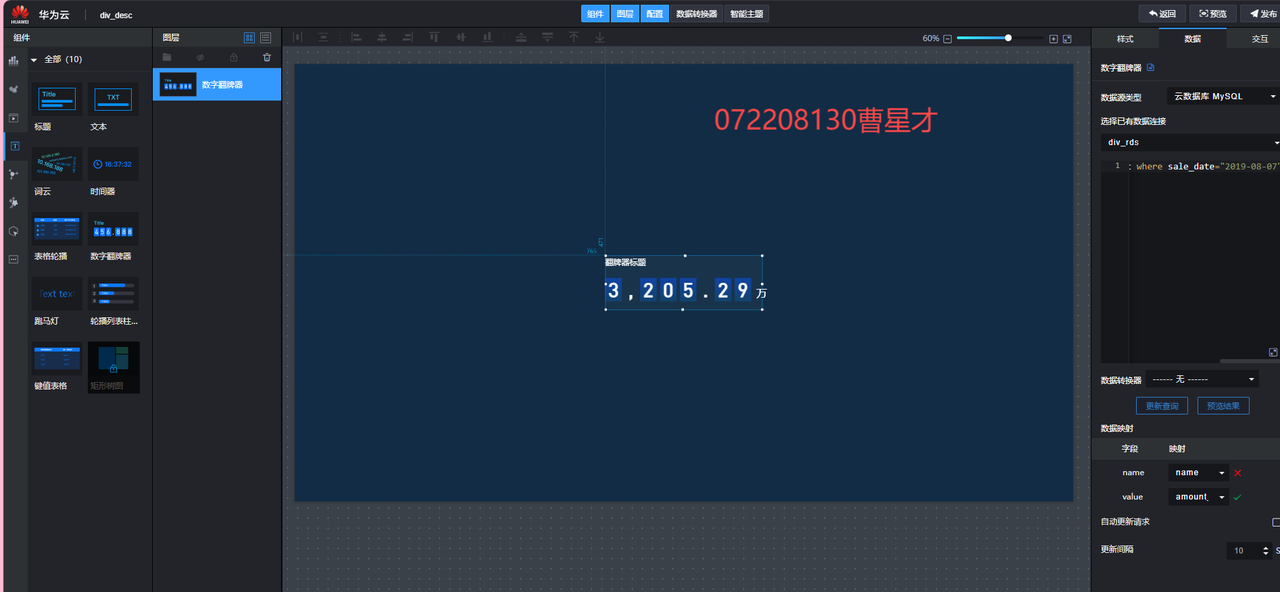
3.7 DLV数据可视化
3.7.1 数字翻拍器及其设置
3.7.2 定时执行数据生成脚本
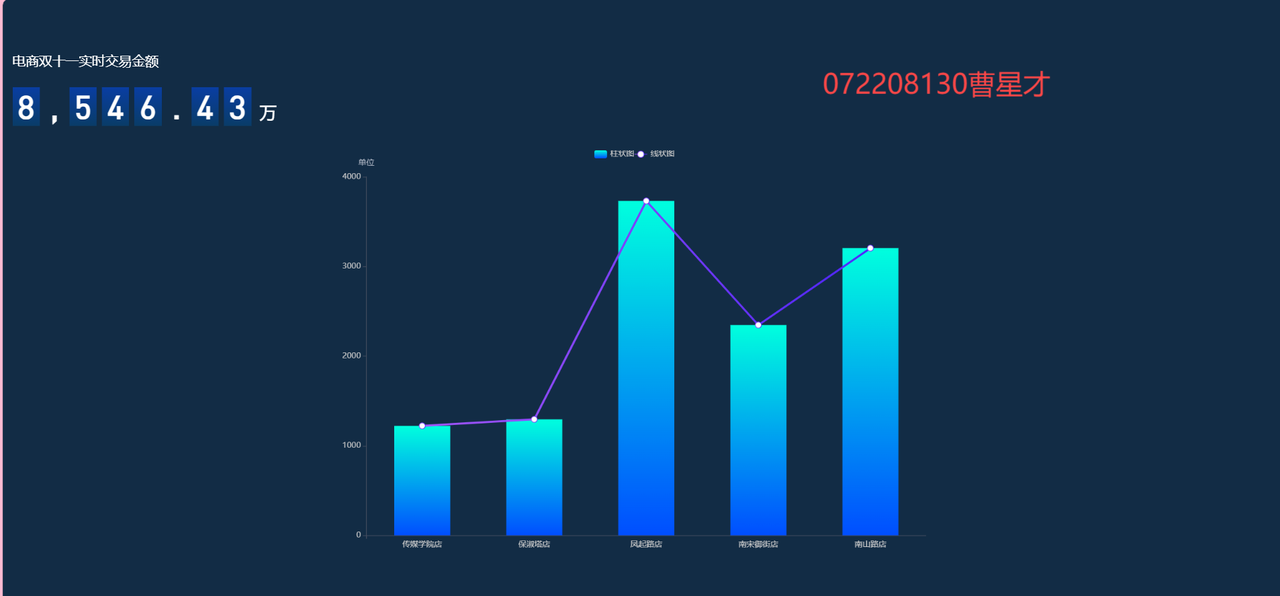
10秒后:
(二)心得体会
整个实验过程让我更加深入地了解了大数据技术的各个方面,尤其是在数据传输、实时数据处理与分析、以及可视化展示等环节的应用。我认识到,搭建一个高效的大数据处理平台并不仅仅是一个技术问题,它还涉及到如何有效配置资源、如何处理不同系统之间的数据流动与交互,以及如何确保系统在运行过程中的高效与稳定。
通过这次实验,我不仅掌握了Kafka、Flume、Flink等大数据处理工具的使用,还学会了如何在实际的工作环境中搭建和维护大数据分析系统。此外,我还提升了自己对大数据平台架构的整体理解,尤其是在云平台服务与数据流转方面的运用。
这次实验为我今后在大数据领域的学习和工作奠定了坚实的基础,也激发了我对大数据技术的进一步探索与实践的兴趣。我将继续学习更多先进的大数据处理技术,以应对未来更复杂的技术挑战。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号