
02. 神经网络
一、人工神经网络组成
人工神经网络(Artificial Neural Network, ANN)简称神经网络(NN),是一种模仿生物神经网络结构和功能的计算模型。大多数情况下,人工神经网络能在外界信息的基础上改变内部结构,是一种自适应系统,通俗地讲,就是具备学习功能。
在生物学中,神经元是神经系统是基本的结构和单位。神经元从树突接收其它神经元细胞发出的电化学刺激脉冲,这些脉冲叠加后,一旦强度达到临界值,这个神经元就会产生动作电位,沿着轴突发送电信号。轴突将刺激传到末端的突触,电信号触发突触上面的电压敏感蛋白,把一个内含神经递质的小泡(突触小体)推到突触的膜上,从而释放突触小体中的神经递质。这些化学物质会扩散到其它神经元的树突或轴突上。
人工神经网络中的神经元,一般可以对多个输入进行加权求和,再经过特定的 “激活函数” 转换后输出。
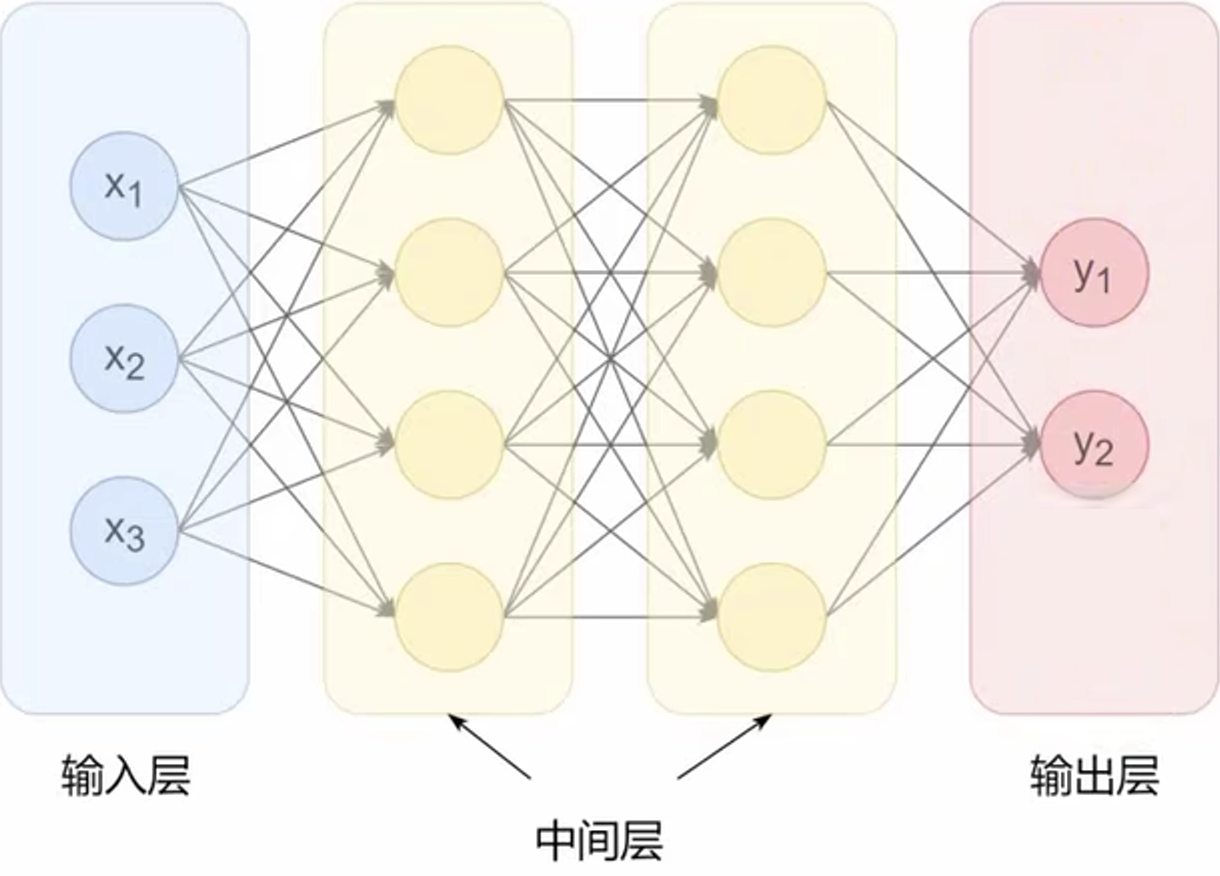
使用多个神经元就可以构建多层神经网络,最左边的一列神经元都表示输入,称为 输入层。最右边一列表示网络的输出,称为 输出层。输入层于输出层之间的层统称为 中间层(隐藏层)。相邻层的神经元相互连接(图中下一层每个神经元都于上一层所有神经元连接,称为 全连接),每个连接都会由一个 权重。神经元的信息逐层传递(一本称为 前向传播),上一层神经元的输出作为下一层神经元的输入。
二、激活函数
激活函数是连接感知机和神经网络的桥梁,在神经网络中起着至关重要的作用。如果没有激活函数,整个神经网络就等效于单层线性变换,无论如何加深层数,总是存在于之等效的无隐藏的神经网络。激活函数必须是非线性函数,也正是激活函数的存在为神经网络引入了非线性,使得神经网络能够学习和表示复杂的非线性关系。
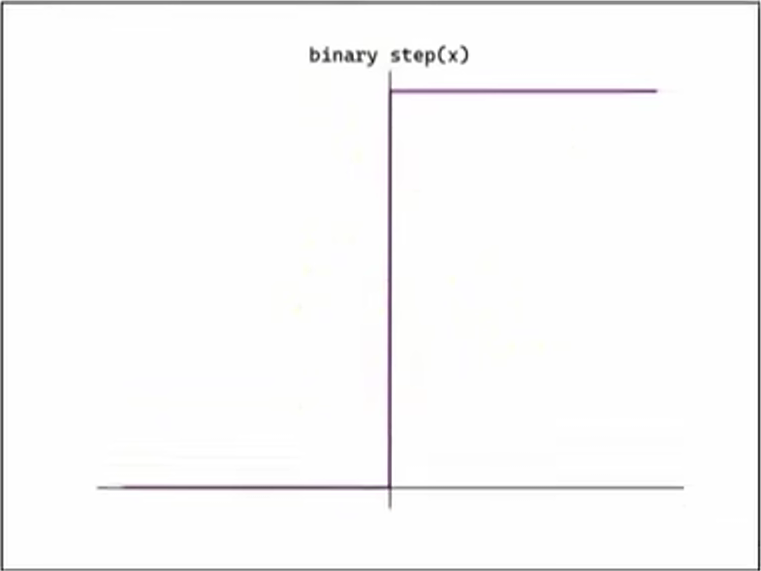
2.1、阶跃函数
阶跃函数是最简单的激活函数,它可以为输入设置一个阈值,一旦超过这个阈值,就切换输出(输出 0 或者 1)。
我们可以在终端中使用 pip 安装 NumPy 库。默认是从国外的主站上下载,因此,我们可能会遇到网络不好的情况导致下载失败。我们可以在 pip 指令后通过 -i 指定国内镜像源下载。
pip install numpy -i https://mirrors.aliyun.com/pypi/simple
国内常用的 pip 下载源列表:
- 阿里云 https://mirrors.aliyun.com/pypi/simple
- 豆瓣 http://pypi.doubanio.com/simple
- 清华大学 https://pypi.tuna.tsinghua.edu.cn/simple
- 中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple
import numpy as np
def step_function(x):
return np.array(x>0, dtype=np.int8)
if __name__ == '__main__':
x = np.array([0, 1, 2, 3, 4, 5, -1, -2, -3, -4, -5])
print(step_function(x))
2.2、Sigmoid函数
Sigmoid(也叫 Logistic 函数)是平滑的,可微的,能将任意输入映射到区间 (0, 1)。常用于二分类的输出层。但因其涉及指数计算,计算量相对较高。
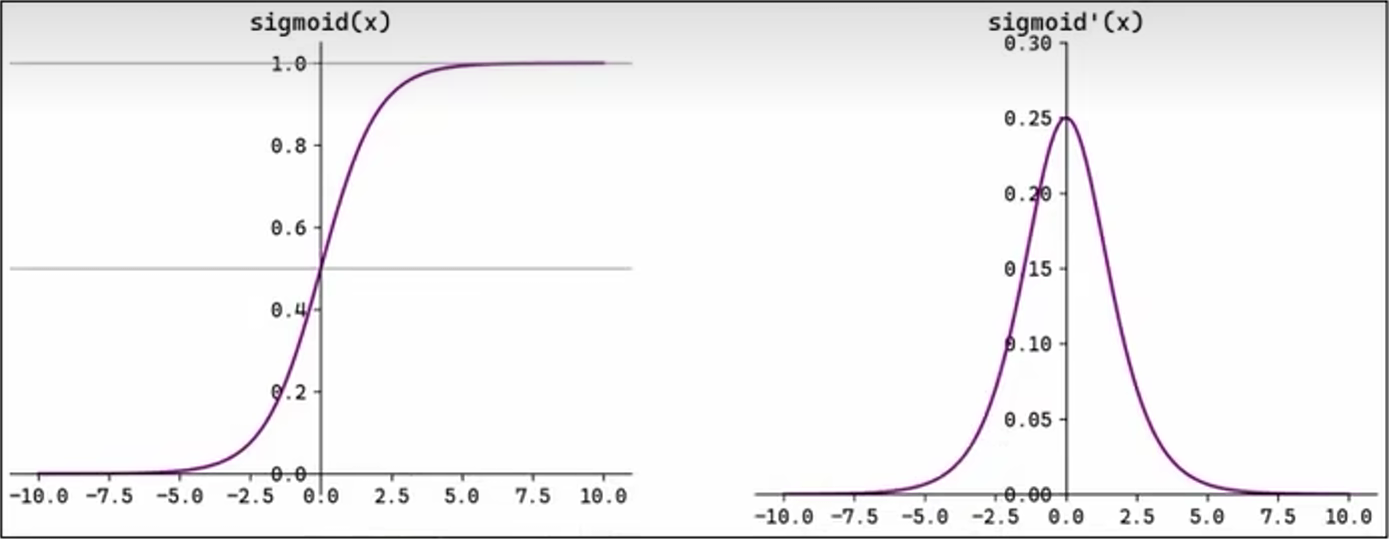
Sigmoid 函数的输入在 [-6, 6] 之外时,其输出值变化很小,可能导致信息丢失。Sigmoid 函数的输出并非以 0 为中心,其输出值均大于 0,导致后续层的输入始终未正,可能会影响到后续梯度更新方向。Sigmoid 函数的导数范围为 (0, 0.25),梯度很小。当输入在 [-6, 6] 之外时,导数接近 0,此时网络参数的更新将会及其缓慢。使用 Sigmoid 函数作为激活函数,可能会出现梯度消失(在逐层反向传播时,梯度会呈指数值衰减)。
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
if __name__ == '__main__':
x = np.array([0, 1, 2, 3, 4, 5, -1, -2, -3, -4, -5])
print(sigmoid(x))
2.3、Tanh函数
Tanh(双曲正切)函数将输入映射到区间 (-1, 1)。其关于原点中心对称。常用在隐藏层。
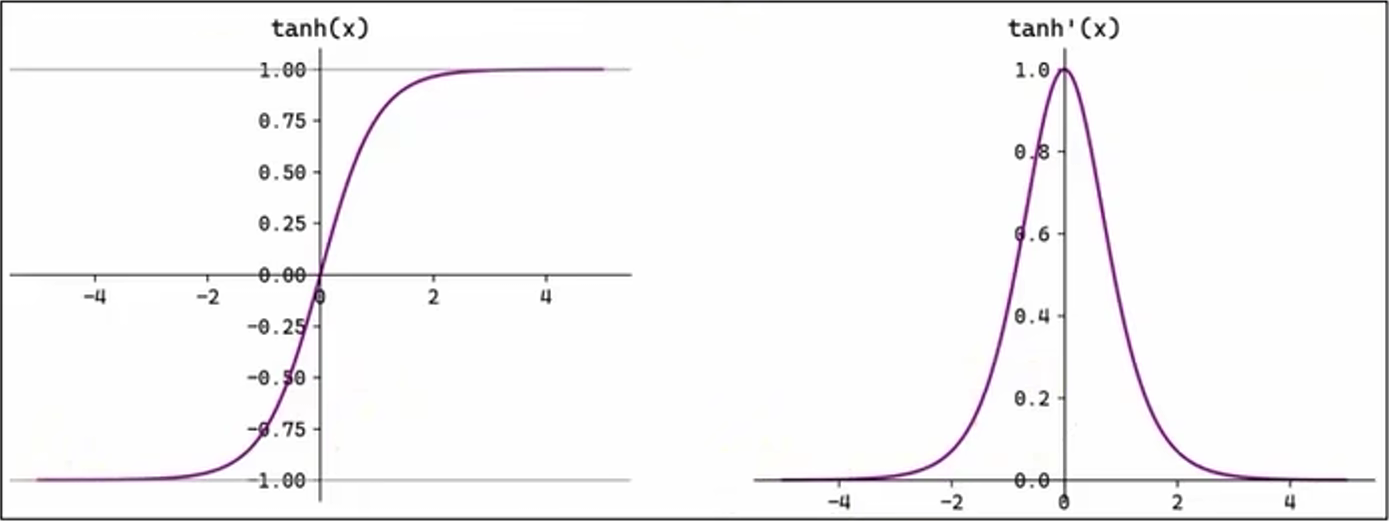
Tanh 函数的输入在 [-3, 3] 之外时,Tanh 函数的输出值变换很小,此时导数接近 0。Tanh 函数的输出以 0 为中心,且其梯度相较于 Sigmoid 更大,收敛速度相对更快。但同样也存在梯度消失现象。
import numpy as np
if __name__ == '__main__':
x = np.array([0, 1, 2, 3, 4, 5, -1, -2, -3, -4, -5])
print(np.tanh(x))
2.4、ReLU函数
ReLU(Rectified Linear Unit,修正线性单元)函数会将小于 0 的输入转换为 0,大于等于 0 的输入保持不变。ReLU 定义简单,计算量小,常用于隐藏层。
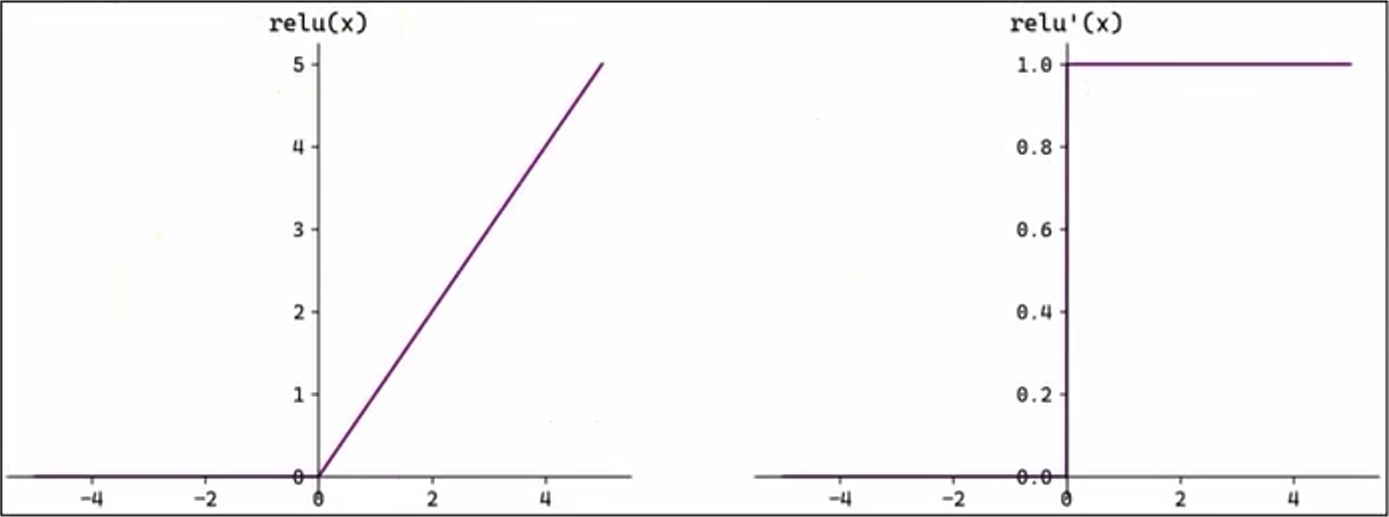
ReLU 函数作为激活函数不存在梯度消失。当输入小于 0 时,ReLU 函数的输出为 0,这意味着在神经网络中,ReLU 函数激活的节点只有部分是活跃的,这种稀疏性有助于减少计算量和提高模型的效率。
当神经元的输入持续为负数时,ReLU 函数的输出始终为 0。这意味着神经元可能永远不会被激活,从而导致神经元死亡的问题。这会影响模型的学习能力,特别是当大量的神经元都变成了死神经元时。为解决此问题,可使用 Leaky ReLu 函数代替 ReLU 函数作为激活函数。Leaky ReLU 函数在负数区引入一个小的斜率。
其中 \(\alpha\) 是很小的一个常数。
import numpy as np
def ReLU(x):
return np.maximum(0, x)
if __name__ == '__main__':
x = np.array([0, 1, 2, 3, 4, 5, -1, -2, -3, -4, -5])
print(ReLU(x))
2.5、Softmax函数
Softmax 函数将一个任意的实数向量转换为一个概率分布,确保输出值的总和为 1,是二分类激活函数 Sigmoid 函数在多分类上的推广。Softmax 函数常用于多分类问题的输出层,用来表示类别的预测概率。Softmax 函数会放大输入中较大的值,使得最大输入值对应的输出概率较大,其它较小的值会被压缩,即在类别之前起到了一定的区分作用。
import numpy as np
def Softmax(x):
# 如果是二维矩阵
if x.ndim == 2:
x = x.T
x = x - np.max(x, axis=0)
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
x = x - np.max(x)
return np.exp(x) / np.sum(np.exp(x))
if __name__ == '__main__':
x1 = np.array([0, 1, 2, 3, 4, 5, -1, -2, -3, -4, -5])
print(Softmax(x1))
x2 = np.array([[0, 1, 2], [3, 4, 5], [6, 7, 8], [-1, -2, -3]])
print(Softmax(x2))
三、损失函数
神经网络中,需要以某个指标为线索寻找最优权重参数,这个指标就是 损失函数。
3.1、分类任务损失函数
3.1.1、二元交叉损失函数
二元交叉损失函数(Binary Cross Entropy Loss):
其中,\(y_{i}\) 为 真实值,通常为 0 或 1。\(\hat{y_{i}}\) 为 预测值,表示样本 i 为 1 的概率。
3.1.2、交叉熵误差损失函数
交叉熵误差损失函数(Cross Entropy Error):
其中,\(\log\) 表示 自然对数,\(y_{i}\) 表示 神经网络的输出,\(t_{i}\) 表示 正确解标签,\(t_{i}\) 中只有正确解标签对应的值为 1,其它均为 0。
import numpy as np
def cross_entropy_error(y, t):
# 将y转换为二维
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
# 将t转换为顺序编码
if t.ndim == y.ndim:
t = t.argmax(axis=1)
n = y.shape[0]
return -np.sum(np.log(y[np.arange(n), t] + 1e-10))
3.1.3、多分类交叉熵损失函数
多分类交叉熵损失函数(Categorical Cross Entropy Loss),它是对每个类别的预测概率与真实标签之间差异的加权平均。
其中 C 是 类别数。\(y_{i,c}\) 是 真实值,表示 \(y_{i}\) 是否为类别 c,通常为 0 或 1。\(\hat{y_{i},c}\) 是 预测值,表示样本 i 为类别 c 的概率。
3.2、回归任务损失函数
3.2.1、平均绝对误差损失函数
平均绝对误差(Mean Absolutte Error, MAE)也称 L1 Loss:
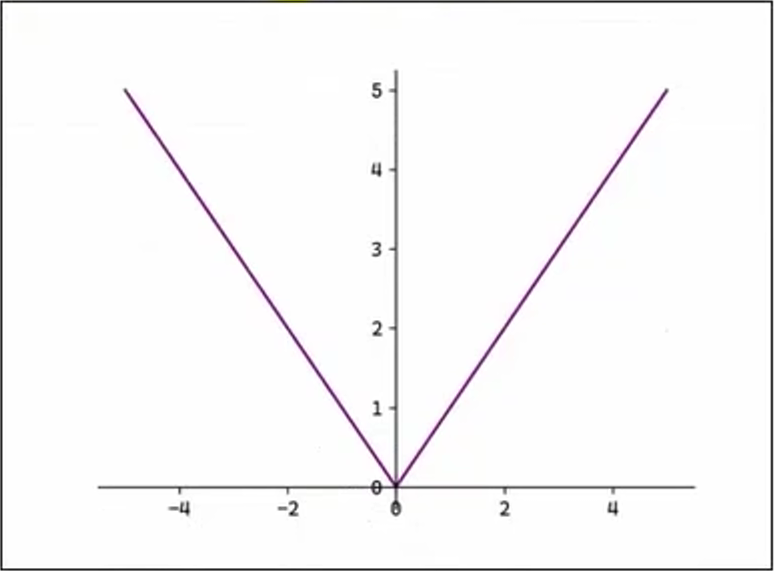
L1 Loss 对异常值有鲁棒性,但在 0 处不可导。
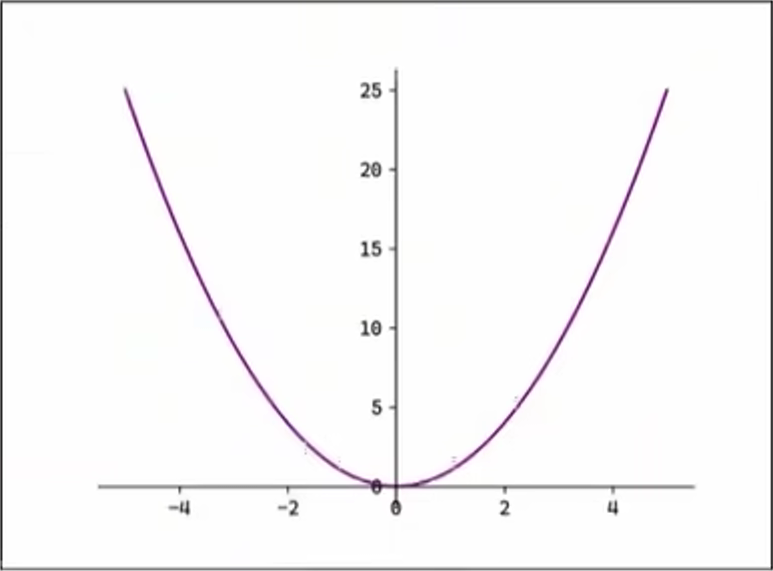
3.2.2、均方误差损失函数
均方误差(Mean Squraed Error, MSE),也称 L2 Loss。
其中,\(y_{i}\) 表示 神经网络的输出,\(t_{i}\) 表示 监督数据的标签(正确的解标签),n 是 数据的维度。对于固定维度的网络,前面的系数 n 不重要,因此公式有时可以写成:
import numpy as np
def mean_squared_error(y, t):
return 0.5 * np.sum((y - t) ** 2)
L2 Loss 对异常值敏感,遇到异常值时容发生梯度爆炸。
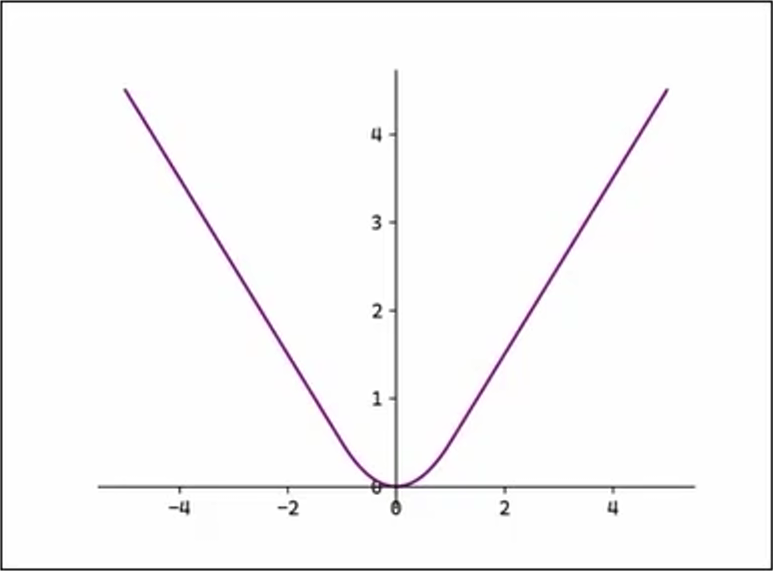
3.2.3、平滑L1损失函数
平滑 L1:
四、梯度下降法
梯度下降法(Gradient Descent)是一种用于最小目标函数的迭代优化算法。核心是沿着目标函数(如损失函数)的负梯度方向逐步调整参数,从而负梯度方向是函数下降最快的方向。具体来说,我们初始找到函数 \(f(x_{1}, x_{x})\) 的一个点 \((x_{1}, x_{2})\) 按下式进行更新:
这样就可以沿着负梯度方向,找到一个新的点 \((x_{1}', x_{2}')\),让函数值更小。这里的 \(\eta\) 表示每次的更新量,在神经网络的学习过程中,就代表了一次学习的步长(一次学习多少、多大程度去更新参数),称为 学习率。学习率需要预先设定好,过大或多小都会导致效果不佳。
import numpy as np
from typing import Callable
def _numerical_gradient(f:Callable, x:np.ndarray):
"""计算函数f在特征向量x处的数值梯度
Args:
f (Callable): 目标函数
x (np.ndarray): 输入特征向量
Returns:
np.ndarray: 函数f在特征向量x处的数值梯度
"""
h = 1e-4
grad = np.zeros_like(x)
for i in range(x.size):
tmp_val = x[i]
x[i] = tmp_val + h
fxh1 = f(x)
x[i] = tmp_val - h
fxh2 = f(x)
grad[i] = (fxh1 - fxh2) / (2 * h)
x[i] = tmp_val
return grad
def numerical_gradient(f:Callable, x:np.ndarray):
"""计算函数f在特征矩阵x处的数值梯度
Args:
f (Callable): 目标函数
x (np.ndarray): 输入特征矩阵
Returns:
np.ndarray: 函数f在特征矩阵x处的数值梯度
"""
if x.ndim == 1:
return _numerical_gradient(f, x)
else:
grad = np.zeros_like(x)
for i,x in enumerate(x):
grad[i] = _numerical_gradient(f, x[i])
return grad
def numerical_descent(f:Callable, x:np.ndarray, learn_rate:float=0.01, num_iters:int=1000):
"""_summary_
Args:
f (Callable): 目标函数
x (np.ndarray): 输入特征矩阵
learn_rate (float, optional): 学习率. Defaults to 0.01.
num_iters (int, optional): 迭代次数. Defaults to 1000.
Returns:
tuple: (最小值点, 迭代历史)
"""
x_history = []
for _ in range(num_iters):
x_history.append(x.copy())
grad = numerical_gradient(f, x) # 计算梯度
x -= learn_rate * grad # 更新参数
return x, np.array(x_history)
五、反向传播算法
5.1、什么是反向传播
反向传播(Backward Propagation,简称 BP)将局部导数反方向传递,传递的原理基于链式法则。反向传播时将信号乘以节点的局部导数,然后传递给下一个节点。
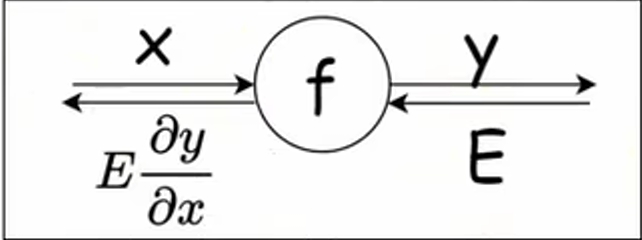
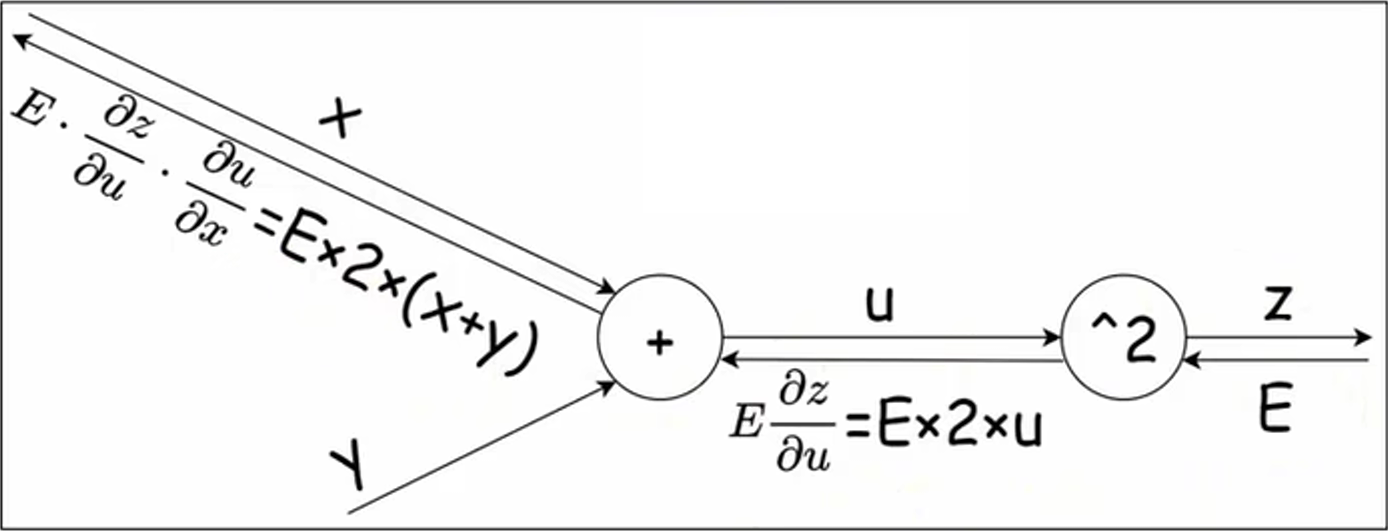
对于复合函数 \(z = (x + y)^{2}\),令 \(u = x + y\),则:
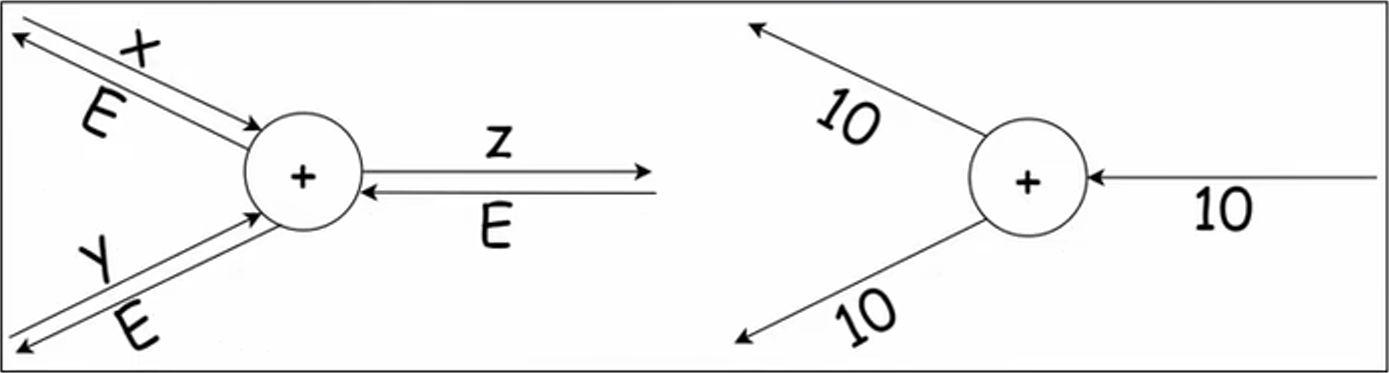
对于 \(z = x + y, \frac{\partial x}{\partial x} = 1, \frac{\partial z}{\partial y} = 1\),加法的反向传播会将上游传来的值原样向下游传递。
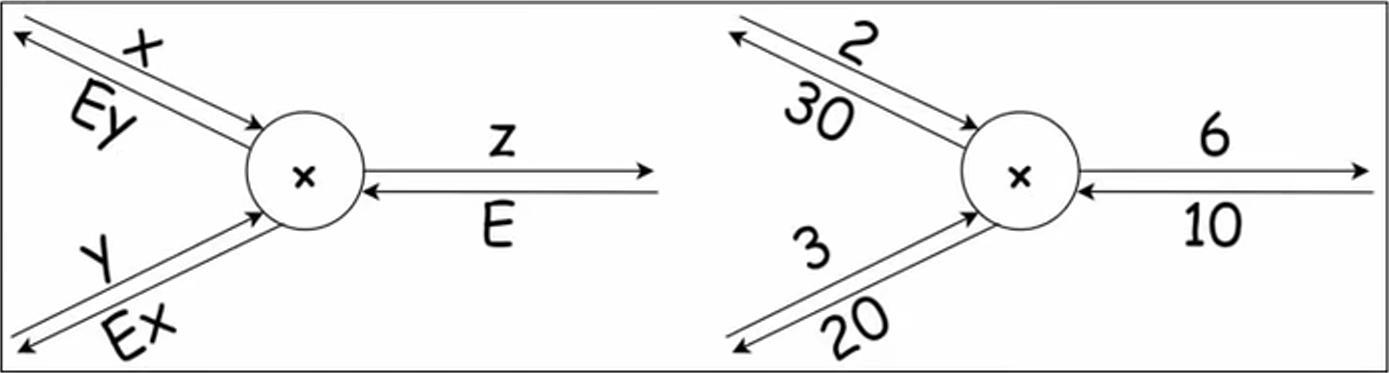
对于 \(z = xy, \frac{\partial z}{\partial x} = y, \frac{\partial z}{\partial y} = x\),乘法节点的反向传播会将上游传来的值乘以输入的翻转向下游传递。
5.2、激活层的反向传播
【1】、ReLU 的反向传播
对于 ReLU 函数:
其导数为:
反向传播的计算图如下:
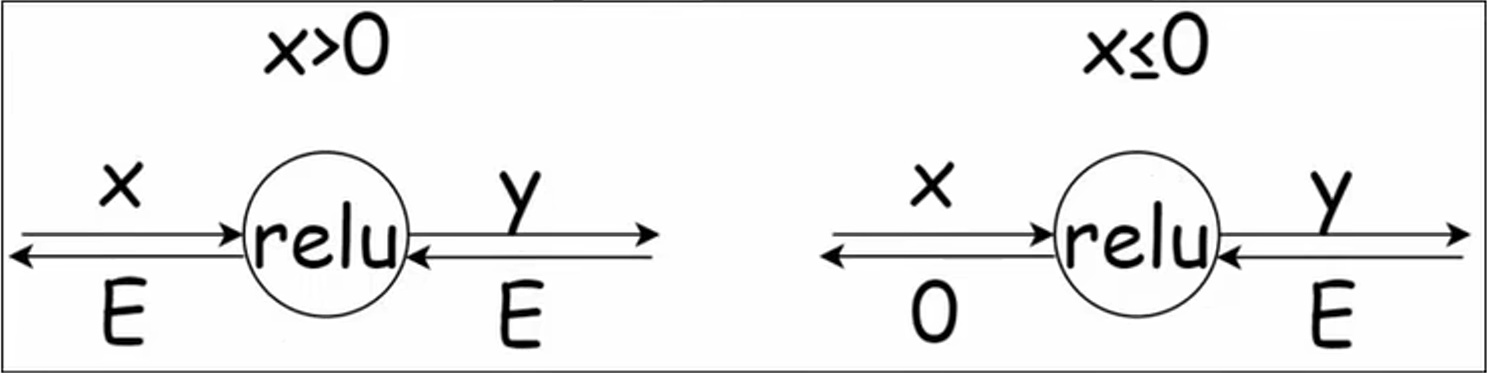
class Relu:
def __init__(self):
self.mask = None
# 前向传播
def forward(self, x):
self.mask = (x <= 0) # 大于0的部分为True,小于等于0的部分为False
y = x.copy()
y[self.mask] = 0
return y
# 反向传播
def backward(self, dout):
dx = dout.copy() # 复制 dout 到 dx
dx[self.mask] = 0 # 小于等于0的部分的梯度为0
return dx
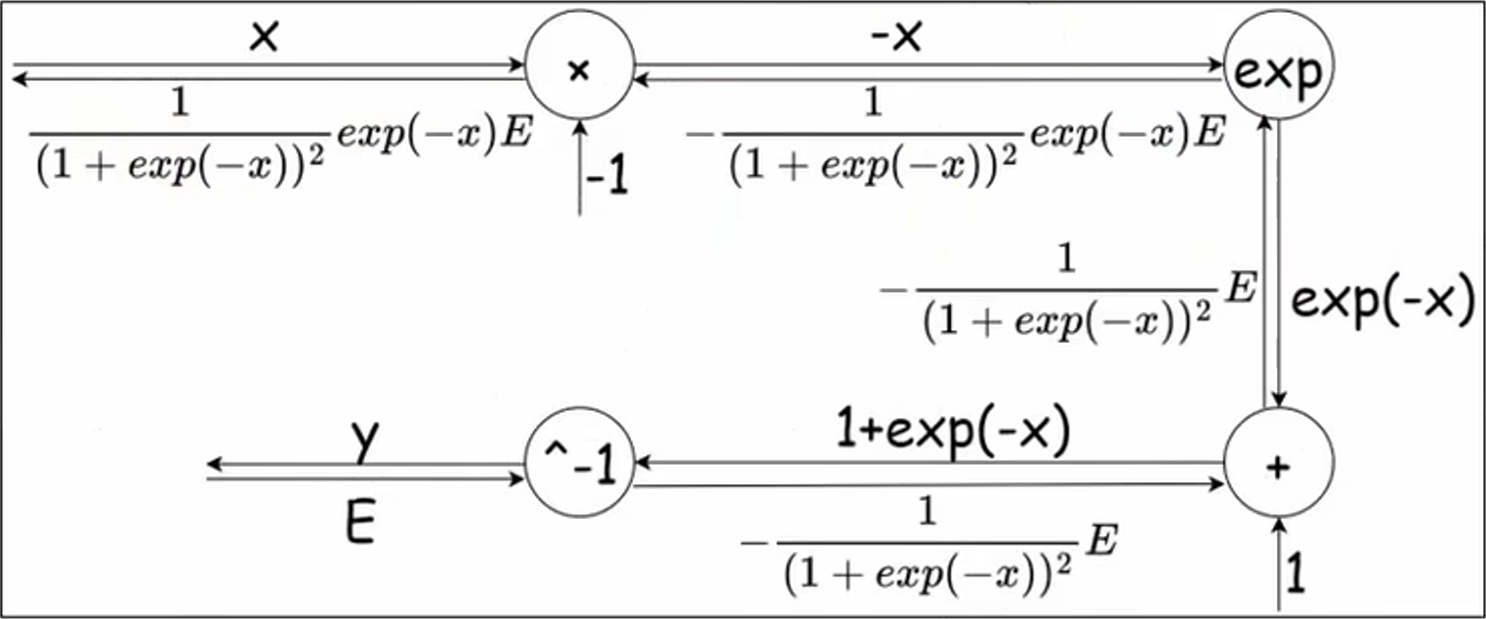
【2】、Sigmoid 的反向传播
对于 Sigmoid 函数:
其导数为:
反向传播的计算图如下:
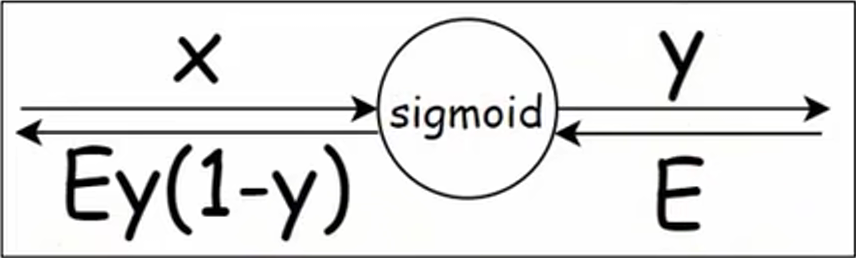
简化后,可得:
import numpy as np
class Sigmoid:
def __init__(self):
self.y = None
# 前向传播
def forward(self, x):
self.y = 1 / (1 + np.exp(-x))
return self.y
# 反向传播
def backward(self, dout):
dx = 0
if self.y:
dx = dout * (1.0 - self.y) * self.y
return dx
5.3、仿射变换的反向传播
在全连接层(Full Connected Layer, Dense Layer)中,每个输入节点与节点相连,通过权重矩阵和偏置进行线性变换,这种操作在几何领域称为 仿射变换(Affine transformation)。在几何领域中,仿射变换包括一次线性和一次平移,分别对应神经网络的加权求和运算和加偏置运算。考虑到 N 个数据一起进行正向传播的情况,写成矩阵计算形式:
这里的 X 是形状为 \(N \times m\) 的矩阵,m 就是 Affine 层输入神经元的个数,而 W 是形状为 \(m \times n\) 的权重矩阵,n 就是 Affine 层输出单元的个数。根据矩阵求导的运算法则,可以得到损失函数 L 关于 X、W 的偏导数:
用计算图的反向传播计算如下:
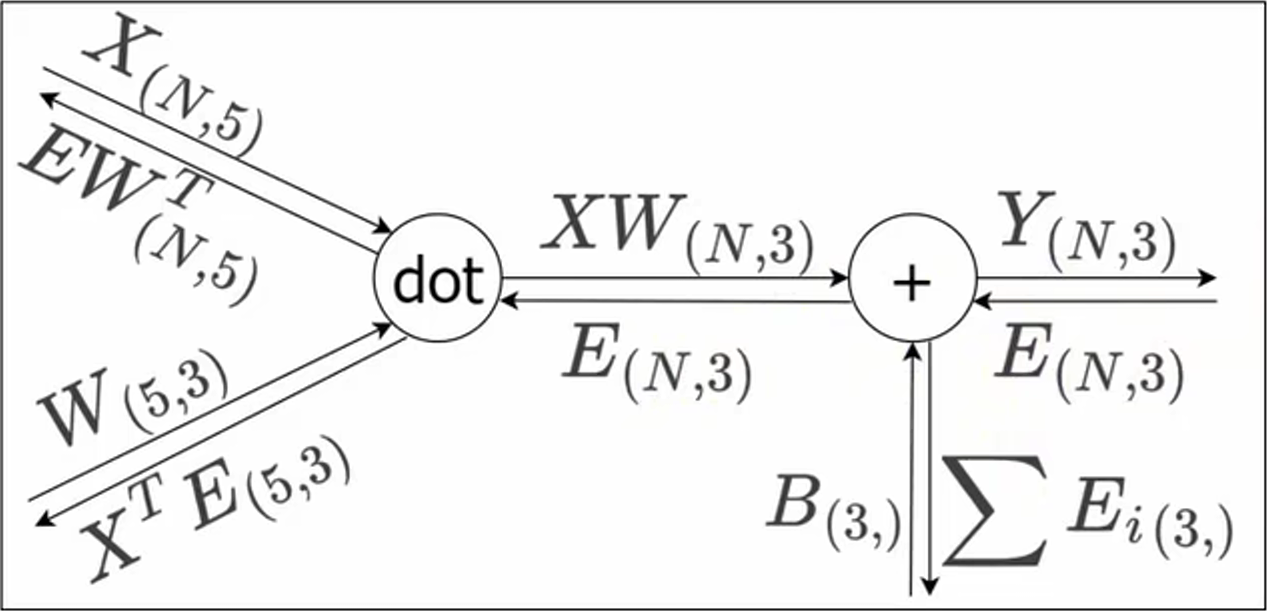
import numpy as np
class Affine:
def __init__(self, W, b):
self.W = W
self.b = b
self.X = None # 保存输入数据,方便反向传播时使用
self.origin_x_shape = None # 保存输入数据的形状,方便反向传播时使用
self.dW = None # 保存权重
self.db = None # 保存偏置
# 前向传播
def forward(self, X):
self.origin_x_shape = X.shape
self.X = X.reshape(X.shape[0], -1)
y = np.dot(self.X, self.W) + self.b
return y
# 反向传播
def backward(self, dout):
if self.origin_x_shape is None or self.X is None:
return
dx = np.dot(dout, self.W.T)
dx = dx.reshape(*self.origin_x_shape)
self.dW = np.dot(self.X.T, dout)
self.db = np.sum(dout, axis=0)
return dx.reshape(*self.origin_x_shape)
5.4、输出层的反向传播
在输出层,我们一般使用 Softmax 函数作为激活函数。
其偏导数为:
对于输出层,一般会直接将结果代入损失函数的计算。对于分类问题,这里选择交叉熵误差作为损失函数。用计算图的反向传播计算如下:
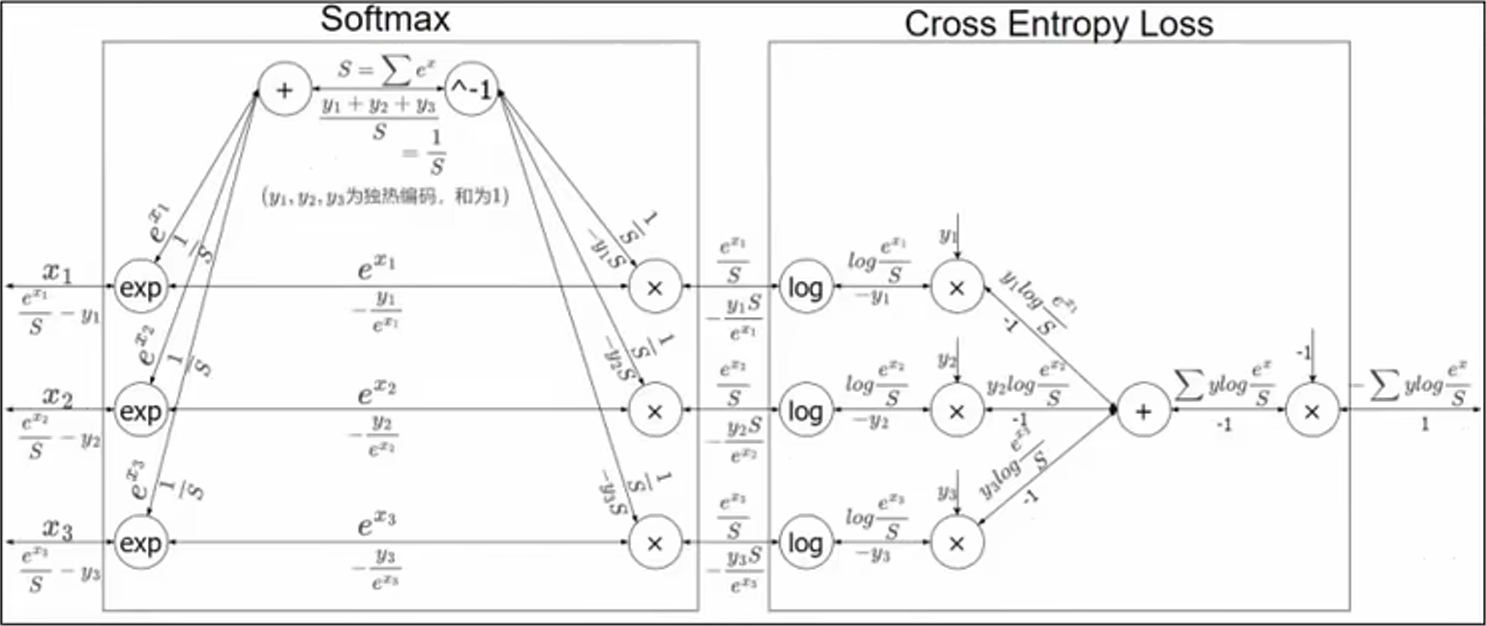
简化后,可得:
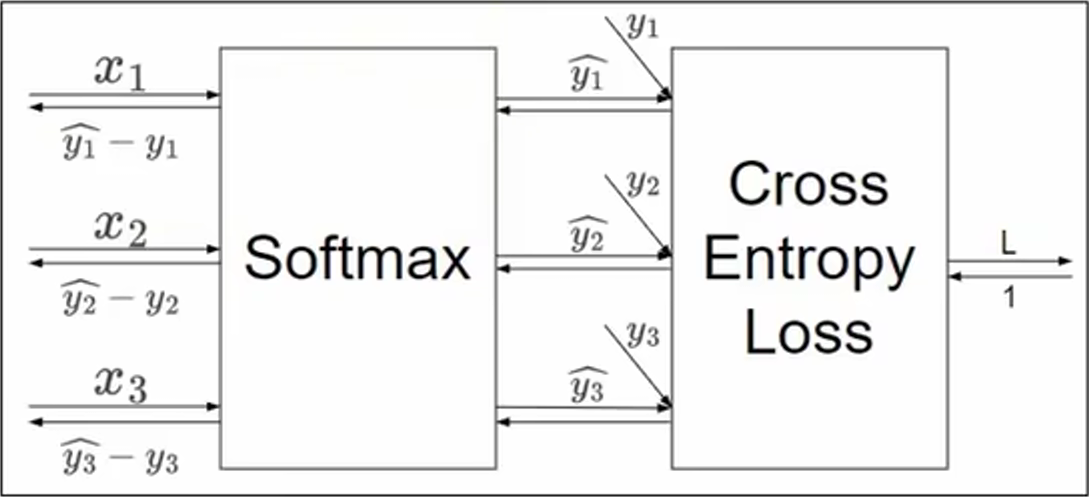
import numpy as np
class SoftmaxWithLoss:
def __init__(self):
self.loss = None
self.y = None
self.t = None
def softmax(self, x):
# 如果是二维矩阵
if x.ndim == 2:
x = x.T
x = x - np.max(x, axis=0)
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
x = x - np.max(x)
return np.exp(x) / np.sum(np.exp(x))
def cross_entropy_error(self,y, t):
# 将y转换为二维
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
# 将t转换为顺序编码
if t.ndim == y.ndim:
t = t.argmax(axis=1)
n = y.shape[0]
return -np.sum(np.log(y[np.arange(n), t] + 1e-10))
# 前向传播
def forward(self, X, t):
self.t = t
self.y = self.softmax(X)
self.loss = self.cross_entropy_error(self.y, self.t)
return self.loss
# 反向传播
def backward(self, dy=1):
dx = 0
n = self.t.shape[0] if self.t else 0
# 如果是独热编码的标签,就直接代入公式计算
if self.t and self.y and self.t.size == self.y.size:
dx = self.y - self.t
# 如果是顺序编码的标签,就需要找到分类号对应的值,然后相减
else:
if self.y:
dx = self.y.copy()
dx[np.arange(n), self.t] -= 1
return dx / n
六、深度学习的优化
6.1、神经网络出现的问题
在某些神经网络中,随着网络深度的增加,梯度在隐藏层反向传播时倾向于变小,这意味着,前面隐藏层中的神经元要比后面的学习起来更慢,这种现象被称为 梯度消失。
与此对应,如果我们进行一些特殊的调整(比如初始权重很大),可以让梯度反向传播时不会明显减少,从而解决梯度消失的问题。然而这样一来,前面层的梯度又会变得非常大,引起网络不稳定,无法再从训练数据中学习,这种现成称为 梯度爆炸。
基于梯度学习的深度神经网络中,梯度本身是不稳定的,前面层中的梯度可能消失,也可能爆炸。当反向传播进行很多层的时候,每一层都会对前一层梯度乘以一个系数,因此当这个系数比较小(小于 1),越往前传递,梯度就会越小、训练越慢,导致梯度消失。而如果这个系数比较大,则越往前传递就会越大,导致梯度爆炸。
所以,深度神经网络的训练是比较复杂的,会有一系列问题。研究表明,激活函数的选择、权重的初始化,甚至学习算法的实现方式都是影响因素。另外,网络的架构和其它一些超参数也有重要影响。
为了让深度神经网络的学习更加稳定、高效,我们需要考虑进一步改进需找最优参数的方法,以及如何设置参数初始值、如何设定超参数,此外还应该解决过拟合的问题。
6.2、更新参数方法的优化
【1】、动量法
原始的梯度下降法直接使用当前梯度来更新参数:
而动量法会保留历史梯度并给予一定的权重,使其也能参与到参数更新中:
其中,v 是 历史上(负)梯度的加权和,\(\alpha\) 是 历史梯度的权重,\(\nabla\) 是 当前梯度,即 \(\frac{\partial L}{\partial W}\),\(\eta\) 是 学习率。
动量法有时能够减缓优化过程中的震荡,加快优化的速度。因为其会累计历史梯度,也可以有效避免鞍点问题(鞍点 是一个多元函数的 临界点(即该点处所有一阶偏导数为零),但它 不是局部极值点。)。
import numpy as np
class Momentum:
def __init__(self, learn_rate=0.01, momentus=0.9) -> None:
self.learn_rate = learn_rate # 学习率
self.momentus = momentus # 动量
self.v = None # 历史负梯度的加权和
def update(self, params, grads):
# 对v进行初始化
if self.v is None:
self.v = {}
for key, value in params.items():
self.v[key] = np.zeros_like(value)
# 按照公式进行参数更新
for key in params.keys():
self.v[key] = self.momentus * self.v[key] - self.learn_rate * grads[key]
params[key] += self.v[key]
【2】、学习率衰减
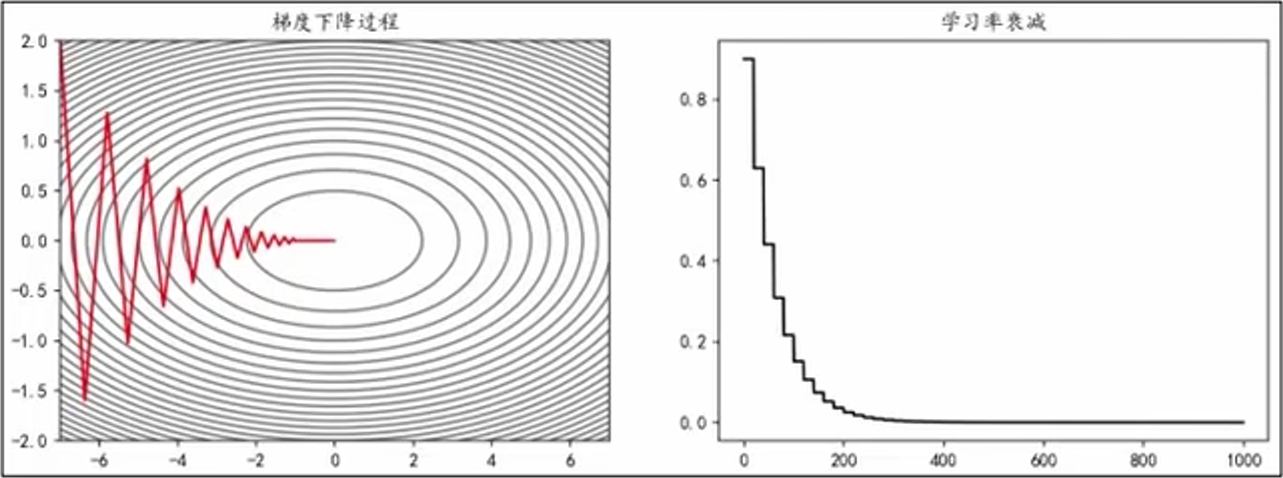
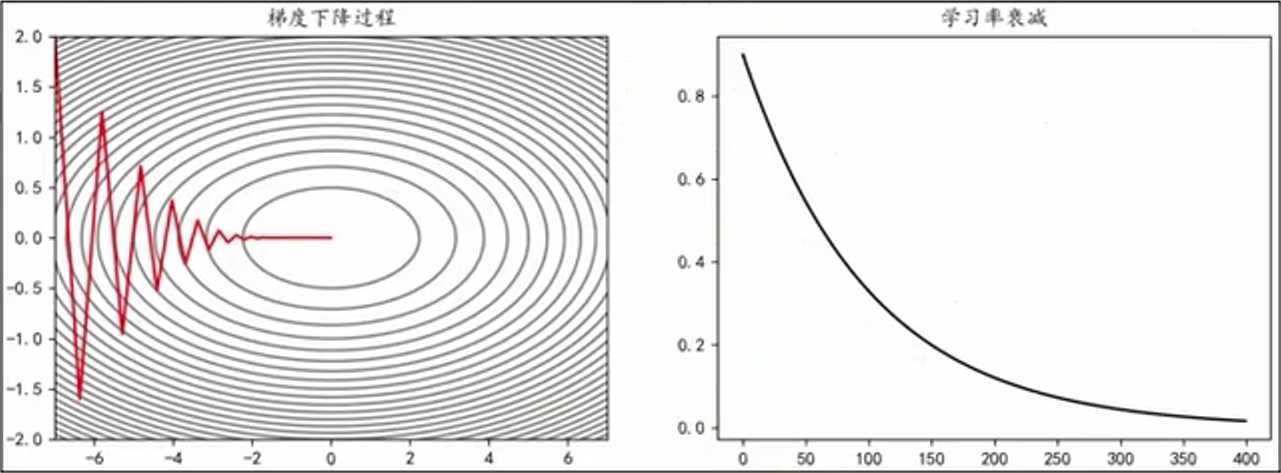
好的学习率可以使模型逐渐收敛并获得更好的精度。较大的学习率可以加快收敛速度,但可能在最优解附近震荡或者不收敛;较小的学习率可以提高收敛的精度,但训练模型速度慢。学习率衰减是一种平衡策略,初始使用较大学习率快速接近最优解,后期逐渐减少学习率,使参数更稳定地收敛到最优解。
(1)、等间隔衰减
每隔固定的训练周期,学习率按一定的比例下降,也称 “步长衰减”。
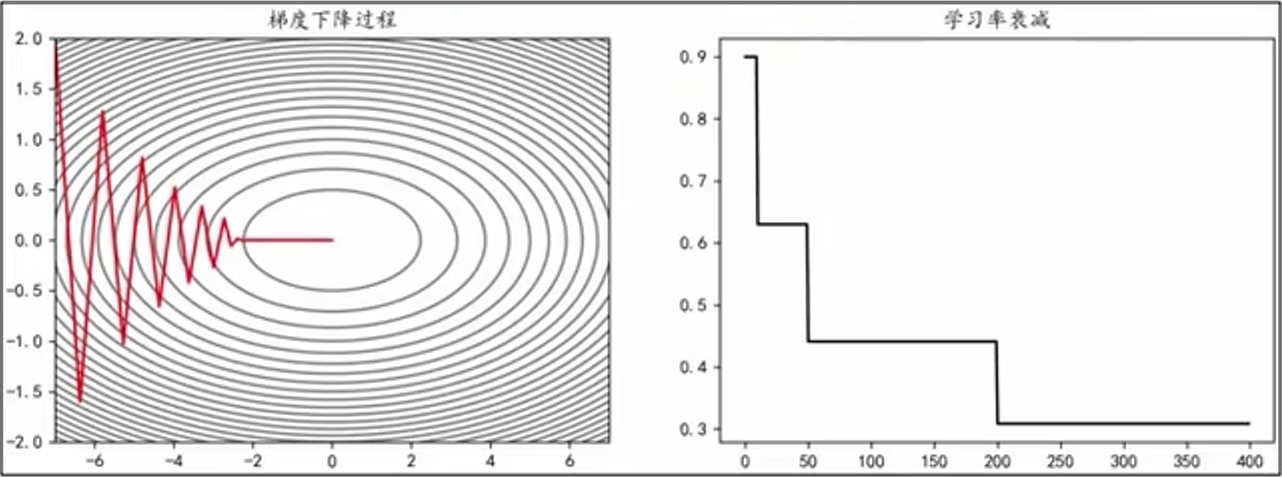
(2)、指定间隔衰减
在指定的训练周期,让学习率按照一定的系数衰减。
(3)、指数衰减
学习率按照指数函数 \(f(x) = a^{x}, a \lt 1\) 进行衰减。
【3】、自适应梯度
自适应梯度(Adaptive Gradient,AdaGrad)会为每个参数适当调整学习率,并且随着学习的进行,学习率会逐渐减小。
其中,h 是 历史梯度的平方和,\(\nabla ^ {2}\) 表示了 梯度的平方和,即 \(\frac{\partial L}{\partial W} \odot \frac{\partial L}{\partial W}\),\(\odot\) 表示 对应矩阵元素的乘法。
使用自适应梯度法,学习越深入,更新的幅度就越小。如果无止境地学习,更新量就会变为 0,完全不再更新。
import numpy as np
class AdaGrad:
def __init__(self, learn_rate=0.01):
self.learn_rate = learn_rate
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, value in params.items():
self.h[key] = np.zeros_like(value)
for key in params.keys():
self.h[key] += grads[key] ** 2
params[key] -= self.learn_rate * grads[key] / (np.sqrt(self.h[key]) + 1e-8)
【4】、均方根传播
均方根传播(Root Mean Square Propagation, RMSProp)是在 AdaGrad 基础上的改进,它并非将过去所有梯度一视同仁的相加,而是逐渐遗忘过去的梯度,采用指定移动加权平均,呈指数地减少梯度的尺度。
其中,h 是 历史梯度平方和的指数移动加权平均,\(\alpha\) 是 权重。
import numpy as np
class RMSProp:
def __init__(self, learn_rate=0.01, decay=0.9):
self.learn_rate = learn_rate
self.decay = decay
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, value in params.items():
self.h[key] = np.zeros_like(value)
for key in params.keys():
self.h[key] *= self.decay
self.h[key] += (1 - self.decay) * grads[key] ** 2
params[key] -= self.learn_rate * grads[key] / (np.sqrt(self.h[key]) + 1e-8)
【5】、自适应估计
自适应估计(Adaptive Moment Estimation, Adam)融合了 Momentm 和 AdaGrad 的方法。
其中,\(\eta\) 为 学习率,\(\alpha_{1}\)、\(\alpha_{2}\) 为 一次动量系数 和 二次动量系数,\(t\) 为 迭代次数,从 1 开始。
import numpy as np
class Adam:
def __init__(self, learn_rate=0.01, alpha1=0.9, alpha2=0.999):
self.learn_rate = learn_rate
self.alpha1 = alpha1
self.alpha2 = alpha2
self.v = None
self.h = None
self.t = 0
def update(self, params, grads):
if self.v is None:
self.v = {}
self.h = {}
for key, value in params.items():
self.v[key] = np.zeros_like(value)
self.h[key] = np.zeros_like(value)
self.t += 1 # 更新迭代次数
# 更新学习率
learn_rate = self.learn_rate * np.sqrt(1.0 - self.alpha2 ** self.t) / (1.0 - self.alpha1 ** self.t)
for key in params.keys():
# self.v[key] = self.alpha1 * self.v[key] + (1.0 - self.alpha1) * grads[key]
# self.h[key] = self.alpha2 * self.h[key] + (1.0 - self.alpha2) * grads[key] ** 2
self.v[key] += (1 - self.alpha1) * (grads[key] - self.v[key])
self.h[key] += (1 - self.alpha2) * (grads[key] ** 2 - self.h[key])
params[key] -= learn_rate * self.v[key] / (np.sqrt(self.h[key]) + 1e-8)
6.3、参数初始化
参数初始化对保持数值稳定性至关重要。我们选择哪个激活函数以及如何初始化参数,可以决定优化算法收敛的速度多快。
【1】、常数初始化
所有权重参数初始化为一个常数,即:
这里 J 为 全 1 的矩阵,k 为 初始化的参数。
这里将权重初始值设置为 0 将无法正确进行学习。严格来说,不能将权重初始值设成一样的值。因为这意味着反向传播时权重全部都会进行相同的更新,并更新为相同的值(对称的值),这使得神经网络拥有许多不同的全冲的意义丧失了。为了防止 “权重均一化”,必须随机生成初始的值。
【2】、秩初始化
权重参数初始化为单位矩阵,即:
这里的 I 为 单位矩阵,即主对角线上元素为 1, 其它元素为 0。
【3】、正太分布初始化
权重参数按指定 \(\mu\) 与标准差 \(\sigma\) 正太分布初始化。因为不能直接将权重初始化为相同的常数,所以需要对参数进行随机初始化。最常见的随机分布就是正太分布(也叫高斯分布),记作 \(X \sim N(\mu, \sigma^{2})\)。其概率密度函数为:
【4】、均匀分布初始化
权重参数在指定区间内均匀分布初始化。均匀分布一般记作 \(X \sim U(a, b)\)。其概率密度函数为:
【4】、Xavier 初始化(Glorot 初始化)
Xavier 初始化根据输入和输出的神经元数量调整权重的初始范围,确保每一层的输出方差与输入方差相近。
- Xavier 正太分布分数化:均值为 0,标准差为 \(\sqrt{\frac{2}{n_{in} + n_{out}}}\) 的正太分布。
- Xavier 均匀正太分布:区间 \([-\sqrt{\frac{6}{n_{in} + n_{out}}}, \sqrt{\frac{6}{n_{in} + n_{out}}}]\) 内均匀分布。
其中,\(n_{in}\) 表示 输入数,\(n_{out}\) 表示 输出数。
Xavier 初始化参数适用于 Sigmoid 和 Tanh 等激活函数,能有效缓解梯度消失或爆炸问题。
【5】、He 初始化(Kaiming 初始化)
He 初始化根据输入的神经元数量调整权重的范围。
- He 正太分布初始化:均值为 0,标准差为 \(\sqrt{\frac{2}{n_{in}}}\) 的正太分布。
- He 均值分布初始化:区间 \([-\sqrt{\frac{6}{n_{in}}}, \sqrt{\frac{6}{n_{in}}}]\) 内均匀分布。
其中,\(n_{in}\) 表示输入数。
He 初始化参数主要适用于 ReLU 及其变体(如 Leaky ReLU)激活函数。
6.4、正则化
在机器学习的过程中,我们可能会遇到过拟合问题。过拟合指的是能较好拟合训练数据,但不能很好地拟合不包含在训练数据中的其它数据。机器学习的目标是提高泛化能力,希望即便是不包含在训练数据里的未观测数据,模型也可以进行正确的预测,因此可以通过正则化方法抑制过拟合。
常用的正则化方法有批量标准换、权值衰减、随机失活、早停法。
【1】、批量标准化
批量标准化(Batch Normalization)调整各层的激活值分布使其拥有适当的广度,BN 层通常放在线性层(全连接层/卷积层)之后,激活函数之前,它有以下特点:
- 可以使学习快速进行。
- 不那么依赖初始值。
- 抑制过拟合。
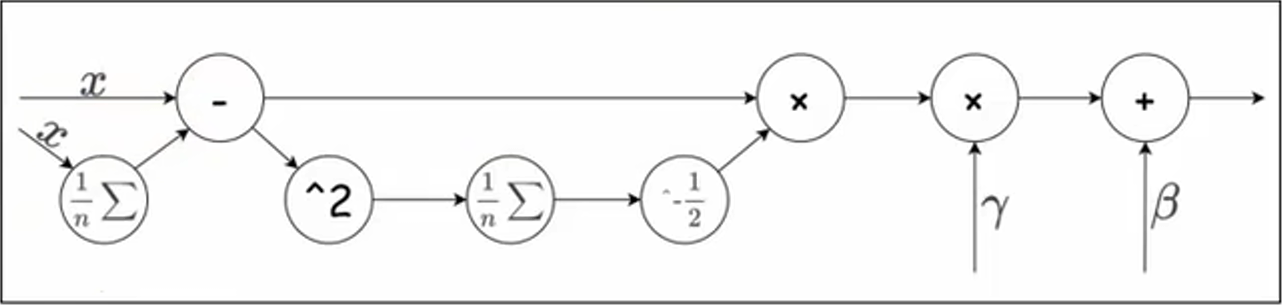
批量标准化会先对数据进行标准化,再对数据进行缩放和平移:
其中,\(\epsilon\) 为一个微小值,防止分母为 0。\(\gamma\) 为 系数,可通过学习调整。\(\beta\) 为偏重,可通过学习调整。
批量标准化的计算图如下:
【2】、权值衰减
通过在学习的过程中对大的权重进行惩罚,可以有效地抑制过拟合,这种方法称为 权值衰减。因为很多过拟合产生的原因就是权重参数取值过大。
一般对损失函数加上一个权重的📖,最常见的就是 L2 范数的平方。
其中 \(\begin{Vmatrix} W \end{Vmatrix}\) 表示 权重 \(W = (w_{1}, w_{2}, ..., w_{n})\) 的 L2 范式,即 \(\sqrt{w_{1}^{2} + w_{2}^{2} + ... + w_{n}^{2}}\),\(\lambda\) 控制正则化强度的超参数。惩罚项 \(\frac{1}{2} . \lambda \begin{Vmatrix} W \end{Vmatrix}\) 求导之后得到 \(\lambda W\),所以在求权重梯度时,需要为之前误差方向传播法的结果,在加上 \(\lambda\)W 。
【3】、随机失活
随机失活(暂退法,Dropout)是一种在学习的过程中随机关闭神经元的方法。训练时以概率 p 随机关闭神经元,迫使网络不依赖特定神经元,增强鲁棒性,同时未被关闭的神经元的输出值以 \(\frac{1}{1 - p}\) 的比例进行缩放,以保持期望值不变,而测试时通常不使用 Dropout,即所有神经元保持激活状态并且不进行缩放。Dropout 会有隐式集成的效果(每次迭代训练不同的子网络,测试时近似集成效果)。Dropout 在全连接层和卷积层均使用,尤其大规模网络效果显著。Dropout 通常放在激活函数之后,线性层(全连接层/卷积层)之前。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号