
10. 聚类
一、聚类
聚类(Clustering)旨在将数据集的样本分为若干个簇,使得同一个簇内的对象彼此相似,不同簇间的对象差异较大。聚类是一种无监督学习算法,不需要预先标记数据的标签,完全依赖数据本身内在结构和特征来进行分组,最终簇所对应的概念语义需由是使用者来把握和命名。
聚类的核心是 “物以类聚”,具体通过以下几个步骤实现:
- 定义相似性:选择一个度量标准来衡量对象之间的相似性或距离。
- 分组:根据相似性将对象分配到不同的簇中。
- 优化:通过迭代或直接计算,调整簇的划分,使簇内相似性最大化,簇间差异最大化。
二、K均值聚类
K 均值聚类(K-means)是基于样本集合划分的聚类方法,将样本集合划分为 k 个子集构成 k 个簇,将 n 个样本分到 k 个簇中,每个样本到其所属簇的中心的距离最小。每个样本只能属于一个簇,所以 K 均值聚类是硬聚类。
K 均值聚类归结为样本集合的划分,通过最小化损失函数来选取最优的划分 C。
首先使用欧式距离平方作为样本间的距离:
定义样本与其所属簇的中心之间的距离总和作为损失函数:
其中,\(\bar{x_{l}}\) 是 第 l 个簇的中心,\(C(i) = l\) 是 第 i 个样本是否属于簇 l。
K 均值聚类就是求解最优化问题。相似的样本被聚到同一个簇时损失函数最小。这是一个组合优化问题,n 个样本分到 k 个簇,所有可能的分类数目 \(S(n, k) = \frac{1}{k!}\sum_{i=0}^{k}(-1)^{l}\begin{pmatrix} k \\ l\end{pmatrix}(k - l)^{n}\)。这个数目是指数级别的,我们可以使用迭代的方法求解。
- 初始化,随机选择 k 个样本点作为初始簇中心。
- 对样本进行迭代,计算每个样本到各个簇中心的距离,将每个样本分到与其最近的簇,构成聚类结果。
- 计算聚类结果中每个簇中所有样本的均值,作为新的簇中心。
- 使用新的簇中心重复上述过程,直到收敛或符合停止条件。
K 均值聚类的初始中心的选择会直接影响聚类结果,并且不适合非凸形状簇。K 均值聚类需要实现指定簇个数 k,而实际中最优的 k 值是不知道的,需要尝试使用不同的 k 值检验聚类结果质量,可以采用二分查找快速找到最优 k 值。聚类结果的质量可以用簇的平均直径来衡量,一般地,簇个数变小时平均直径会增加,簇个数变化超过某个值后平均直径会不变,而这个值正是最优的 k 值。
我们可以在终端中使用 pip 安装 sklearn 机器学习库和 matplotlib 绘图库。默认是从国外的主站上下载,因此,我们可能会遇到网络不好的情况导致下载失败。我们可以在 pip 指令后通过 -i 指定国内镜像源下载。
pip install scikit-learn matplotlib -i https://mirrors.aliyun.com/pypi/simple
国内常用的 pip 下载源列表:
- 阿里云 https://mirrors.aliyun.com/pypi/simple
- 中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple
- 清华大学 https://pypi.tuna.tsinghua.edu.cn/simple
- 中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple
import matplotlib.pyplot as plt
import sklearn.datasets
from sklearn.cluster import KMeans
# 设置中文字体
plt.rcParams["font.sans-serif"] = ["KaiTi"]
plt.rcParams["axes.unicode_minus"] = False
# 生成数据集
X, y = sklearn.datasets.make_blobs(n_samples=300, centers=3, cluster_std=2)
# 定义模型并聚类
kmeans = KMeans(n_clusters=3) # 定义模型
kmeans.fit(X) # 聚类
centers = kmeans.cluster_centers_ # 获取聚类中心
y_pred = kmeans.predict(X) # 预测聚类标签
# 画出散点图
fig, ax = plt.subplots(2, figsize=(8, 8))
ax[0].scatter(X[:, 0], X[:, 1], c="gray", s=50, label="原始数据")
ax[0].set_title("原始数据")
ax[0].legend()
ax[1].scatter(X[:, 0], X[:, 1], c=y_pred, s=50, label="聚类结果")
ax[1].scatter(centers[:, 0], centers[:, 1], c="red", s=200, alpha=0.5, label="聚类中心")
ax[1].set_title("聚类结果")
ax[1].legend()
plt.show()
三、层次聚类
层次聚类假设簇之间存在层次结构,将样本聚到层次化的簇中。层次聚类由 自下而上 的 聚合方法 和 自上而下 的 分裂方法。因为每个样本只属于一个簇,所以层次聚类属于硬聚类。
- 聚合聚类:从开始将每个样本各自分到一个簇,之后将相距最近的两个族合并,如此往复直到满足停止条件(例如达到预设的簇的个数、每个簇只包含一个样本、簇内样本相似性达到某个阈值等)。
- 分裂聚类:开始将整个数据集视作一个整体,之后根据某种距离或相似性度量,选择一个现有的簇将其分裂成两个簇,使分裂后子簇内相似性高、子簇间差异大,如果往复直至满足停止条件。
四、密度聚类
密度聚类假设聚类结构能通过样本分布的紧密程度确定。通常情况下,密度聚类算法从样本密度的角度来考察样本之间的可连接性,并基于可连接样本不断扩展簇以获得最终聚类效果。
DBSCAN 密度聚类是一种著名的密度聚类算法,基于领域参数来刻画样本分布的精密程度。对于给定数据集 \(D = \{x_{1}, x_{2}, ..., x_{n}\}\),定义以下几个概念:
- \(\epsilon\) - 邻域:对于 \(x_{i} \in D\),其 \(\epsilon\) - 邻域包含样本集 D 中于 \(x_{i}\) 的距离不大于 \(\epsilon\) 的样本。
- 核心对象:若 \(x_{i}\) 的 \(\epsilon\)- 邻域至少包含 \(MinPts\) 个对象,则 \(x_{i}\) 是一个核心对象。
- 密度直达:若 \(x_{j}\) 位于 \(x_{i}\) 的 \(\epsilon\)- 邻域中,且 \(x_{i}\) 是核心对象,则称 \(x_{j}\) 由 \(x_{i}\) 密度直达。
- 密度可达:对 \(x_{i}\) 和 \(x_{j}\),若存在样本序列 \(p_{1}, p_{2}, ..., p_{n}\),其中 \(p_{1} = x_{i}, p_{n} = x_{j}\),且 \(p_{i+1}\) 由 \(p_{i}\) 密度直达,则称 \(x_{j}\) 由 \(x_{i}\) 密度可达。
- 密度相连:对 \(x_{i}\) 和 \(x_{j}\),存在 \(x_{k}\) 使得 \(x_{i}\) 和 \(x_{j}\) 均由 \(x_{k}\) 密度可达,则称 \(x_{j}\) 与 \(x_{i}\) 密度相连。
- 噪声点:不属于任何簇的点,既不是核心对象也不在核心对象邻域内。
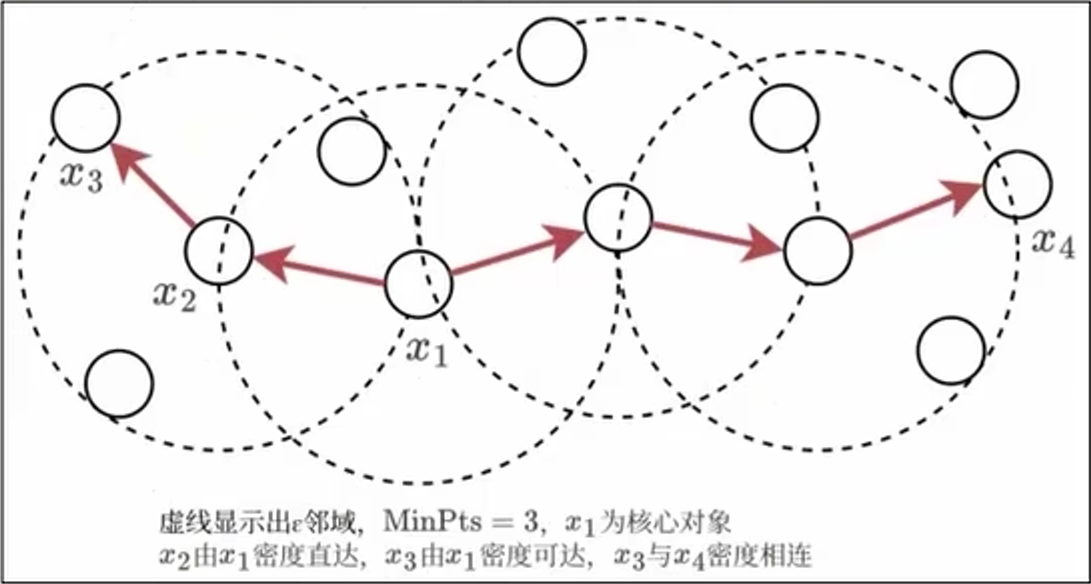
基于这些概念,DBSCAN 将簇定义为密度可达关系导出的最大密度相连样本集合。DBSCAN 先根据邻域参数 \({\epsilon、MinPts}\) 找出所有核心对象,再以任一核心对象为出发点找出其密度可达的样本生成一个簇,直到所有核心对象均被访问过为止。
密度聚类能识别任意形状的簇,可以自动识别并排除噪声点。但 \(\epsilon\)、\(MinPts\) 的选择会密度聚类结果较大,且密度聚类难以使用密度变化较大的数据集。
五、聚类模型评估
由于聚类任务没有预定义的标签(不像监督学习有真实类别可供比较),所以需要依赖聚类结果和原始数据来衡量模型的好坏,主要关注簇内的紧凑性和簇间的分离性。
【1】、轮廓系数
计算每个样本到同簇其它样本的平均距离(内聚度 \(a_{i}\))和到最近其它簇样本的平均距离(分离度 \(b_{i}\)),综合评价聚类紧密度和分离度。
\(s_{i}\) 的值越接近 1,聚类效果越好。总体轮廓系数是所有 \(s_{i}\) 的平均值。
import sklearn.datasets
import sklearn.metrics
from sklearn.cluster import KMeans
# 生成数据集
X, y = sklearn.datasets.make_blobs(n_samples=300, centers=3, cluster_std=2)
# 定义模型并聚类
kmeans = KMeans(n_clusters=3) # 定义模型
kmeans.fit(X) # 聚类
centers = kmeans.cluster_centers_ # 获取聚类中心
y_pred = kmeans.predict(X) # 预测聚类标签
silhouette = sklearn.metrics.silhouette_score(X, y_pred) # 计算轮廓系数
print(silhouette) # 打印聚类轮廓系数
【2】、簇内平方和
衡量簇内数据点到簇中心的总距离平方和,常用于 K-means。
其中,\(\mu_{k}\) 是第 k 个簇的中心。
【3】、肘部法
肘部法用于确定最佳簇数 K,在使用 K-means 时非常常见,它通过绘制簇数 K 和某个聚类质量指标(通常是簇内平方和)的关系曲线,找到一个拐点或 “肘部”,即增加簇数带来的收益是显著减少的点,这个点通常被认为是最佳的 K 值。
【4】、CH 指数
簇间和簇内分散度的比值,也称 方差比准则:
- BCSS:簇间平方和,\(n_{k}\) 是第 k 个簇的样本数,\(\mu{k}\) 为第 k 个簇的中心,\(\mu\) 是所有样本的中心。
- WCSS:簇内平方和。
import sklearn.datasets
import sklearn.metrics
from sklearn.cluster import KMeans
# 生成数据集
X, y = sklearn.datasets.make_blobs(n_samples=300, centers=3, cluster_std=2)
# 定义模型并聚类
kmeans = KMeans(n_clusters=3) # 定义模型
kmeans.fit(X) # 聚类
centers = kmeans.cluster_centers_ # 获取聚类中心
y_pred = kmeans.predict(X) # 预测聚类标签
silhouette = sklearn.metrics.calinski_harabasz_score(X, y_pred) # 计算Calinski-Harabasz指数
print(silhouette) # 打印Calinski-Harabasz指数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号