

01. 初识数据分析
一、什么是数据分析
数据分析 是指使用适当的统计分析方法对收集来的大量数据进行分析,将其汇总、理解并消化,以求最大化地开发数据的功能,发挥数据的作用。数据分析的目的是提取有用信息并形成结论,从而帮助人们做出判断和采取适当行动。
数据分析的基本流程如下:
- 明确分析的目的,提出问题。只有弄清楚了分析的目的是什么,才能准确定位分析因子,提出有价值的问题,提供清晰的指引方向。
- 数据采集。收集原始数据,数据来源可能是丰富多样的,一般有数据库、互联网、市场调查等。具体办法可以通过加入“埋点”代码,或者使用第三方的数据统计工具。
- 数据清洗。对收集到的原始数据进行数据加工,主要包括数据清洗、数据分组、数据检索、数据抽取等处理方法。
- 数据转换。通过探索式分析检验假设值的形成方式,在数据之中发现新的特征,对整个数据集有个全面认识,以便后续选择何种分析策略。
- 数据分析。数据整理完毕,就要对数据进行综合分析和相关分析,需要对产品、业务、技术等了如指掌才行,常常用到分类、聚合等数据挖掘算法。Excel是最简单的数据分析工具,专业数据分析工具有FineBI、Python等。
- 数据可视化。借助可视化数据,能有效直观地表述想要呈现的信息、观点和建议,比如金字塔图、矩阵图、漏斗图、帕累托图等,同时也可以使用报告等形式与他人交流。
- 撰写分析报告。通过分析得出结论,并给出明确意见。
这里,我们使用 Python 进行数据分析,常用的数据分析的库为:NumPy + pandas + matplotlib
【1】NumPy
NumPy(https://numpy.org)是 Numerical Python(数值 Python)的简称,长期以来都是 Python 科学计算的基础包。它提供了多种数据结构、算法以及大部分涉及 Python 数值计算所需的接口。NumPy 还提供以下功能:
- 快速、高效的多维数组对象 ndarray。
- 用于对数组执行元素级计算以及直接对数组执行数学运算的函数。
- 用于读写硬盘上基于数组的数据集的工具。
- 线性代数运算、傅里叶变换,以及随机数生成。
- 成熟的 C API,用于 Python 扩展和原生 C、C++ 代码存取 NumPy 的数据结构和计算工具。
除了为 Python 提供快速的数组处理能力外,NumPy 在数据分析方面还有另外一个主要作用,即作为在算法和库之间传递数据的容器。对于数值型数据,NumPy 数组在存储和处理数据时要比内置的 Python 数据结构高效得多。此外,由底层语言(比如 C 和 Fortran)编写的库可以直接操作 NumPy 数组中的数据,无须将数据复制到其他内存中后再操作。
【2】、pandas
pandas(https://pandas.pydata.org)提供了快速便捷地处理结构化或表格型数据的高级数据结构和函数。pandas 兼具 NumPy 的高性能数组计算能力以及表格和关系型数据库(例如 SQL)的灵活数据操作功能。它提供了便捷的索引功能,可以完成重塑、切片、切块、连接和选取数据子集等操作。
【3】、matplotlib
matplotlib(https://matplotlib.org)是最流行的用于绘制图表和其他二维数据可视化的 Python 库。
二、Jupyter工具的使用
Jupyter Notebook 是基于网页的用于交互计算的应用程序。其可被应用于全过程计算:开发、文档编写、运行代码和展示结果。简而言之,Jupyter Notebook 是以网页的形式打开,可以在网页页面中 直接编写代码 和 运行代码 ,代码的运行结果 也会直接在代码块下显示的程序。如在编程过程中需要编写说明文档,可在同一个页面中直接编写,便于作及时的说明和解释。
这里,我们使用 VSCode + Jupyter 插件的方式来使用。我们首先在 VSCode 的插件市场上安装 Jupyter 插件。
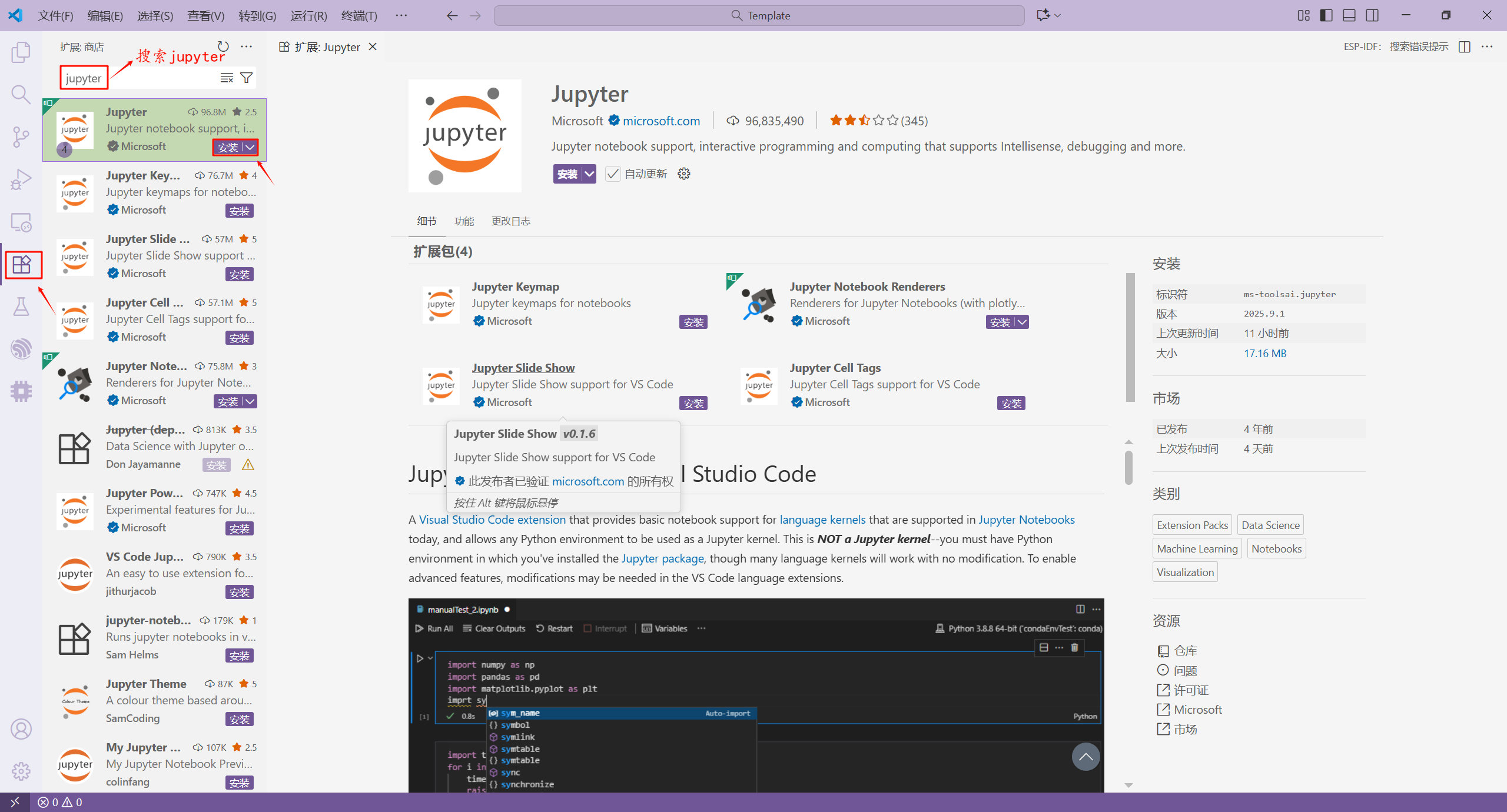
安装完插件之后,我们需要终端中使用 pip 安装 ipykernel 包。默认是从国外的主站上下载,因此,我们可能会遇到网络不好的情况导致下载失败。我们可以在 pip 指令后通过 -i 指定国内镜像源下载。
pip install ipykernel -i https://mirrors.aliyun.com/pypi/simple
国内常用的 pip 下载源列表:
- 阿里云 https://mirrors.aliyun.com/pypi/simple
- 中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple
- 清华大学 https://pypi.tuna.tsinghua.edu.cn/simple
- 中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple
然后,我们新建一个 Jypyter 文件,该文件以 .ipynb 后缀名。如果我们在创建这个 Jupyter 之后,它的内核不是 Python,我们需要手动将其设置为 Python。
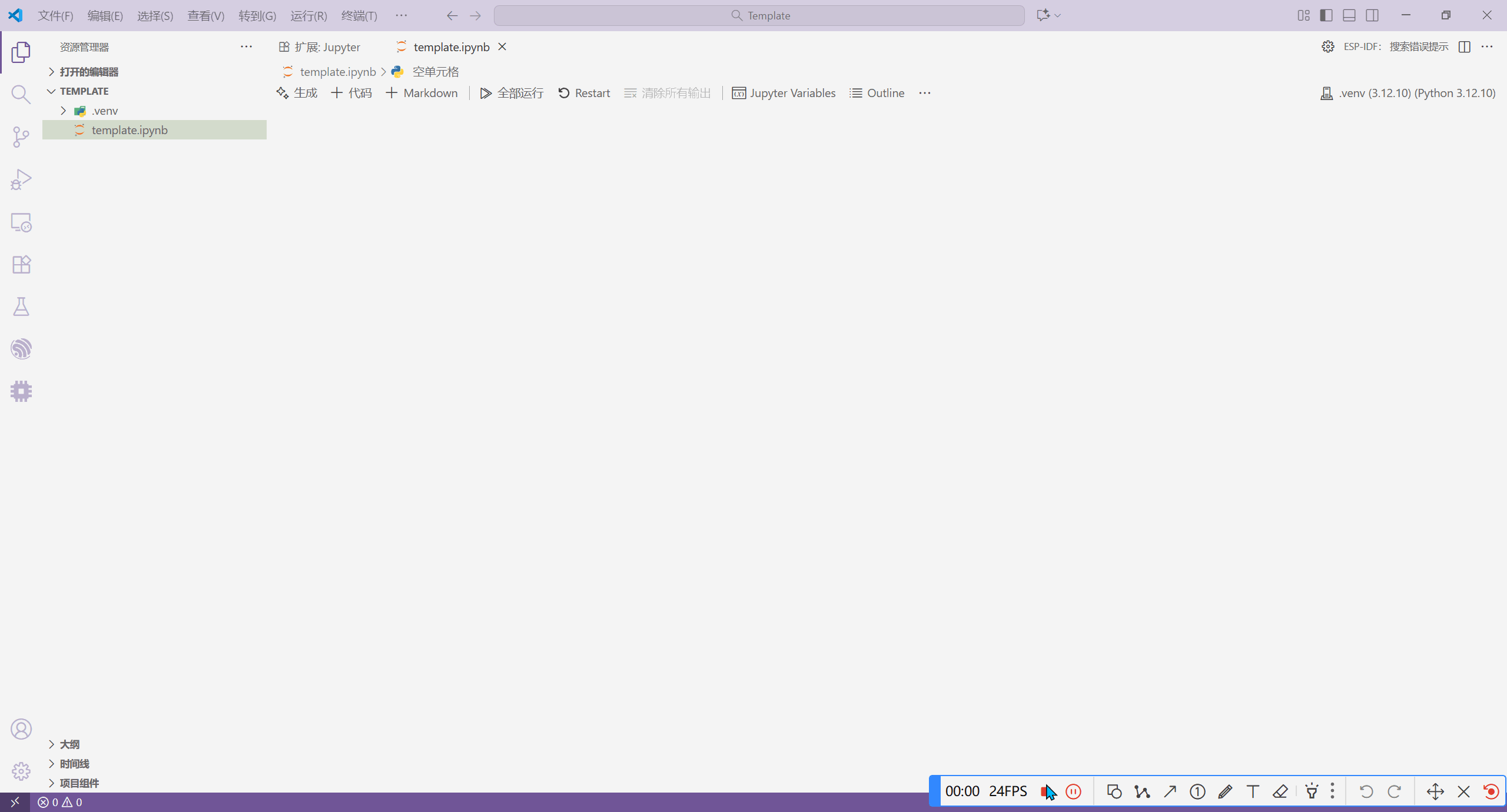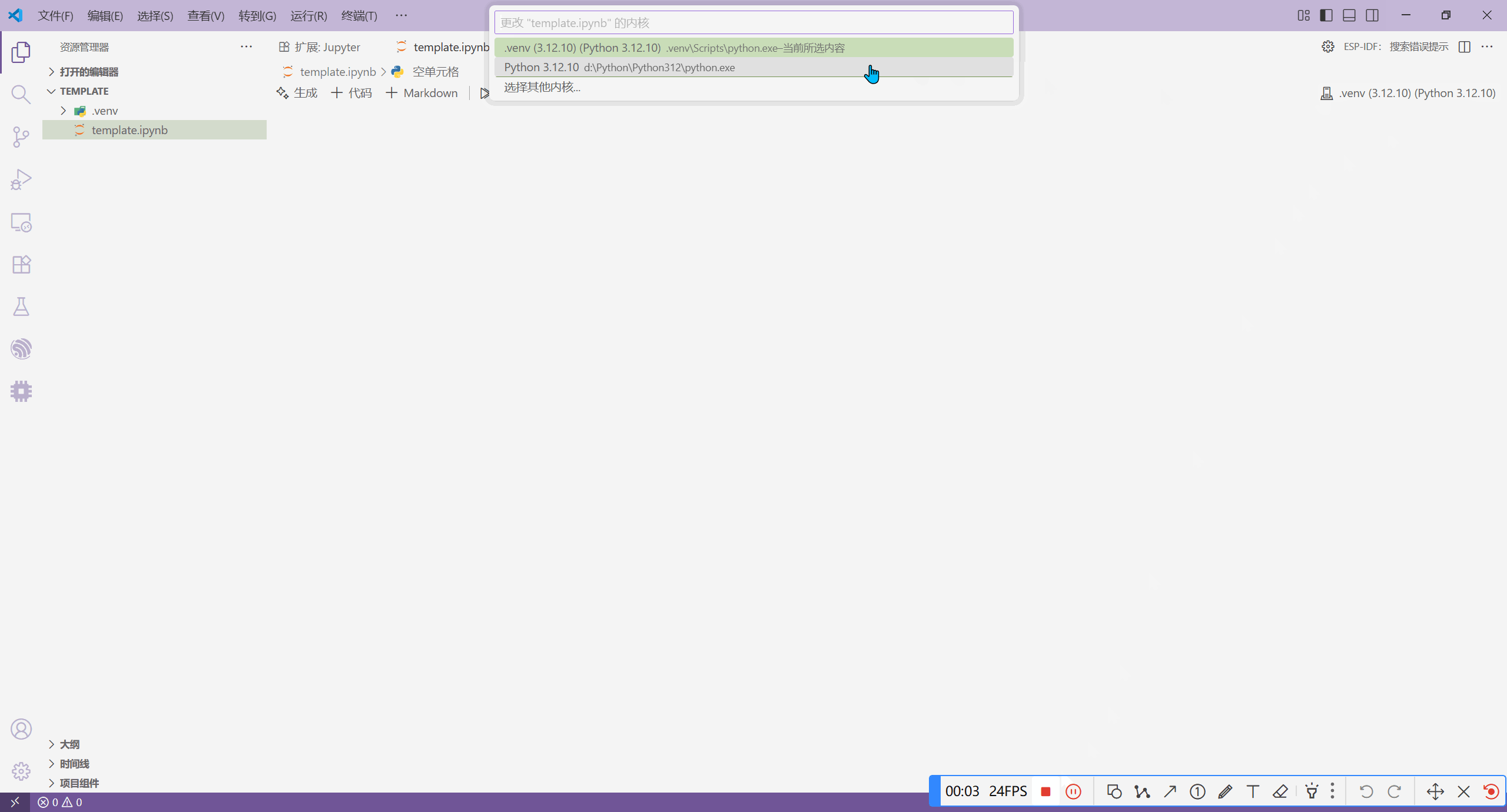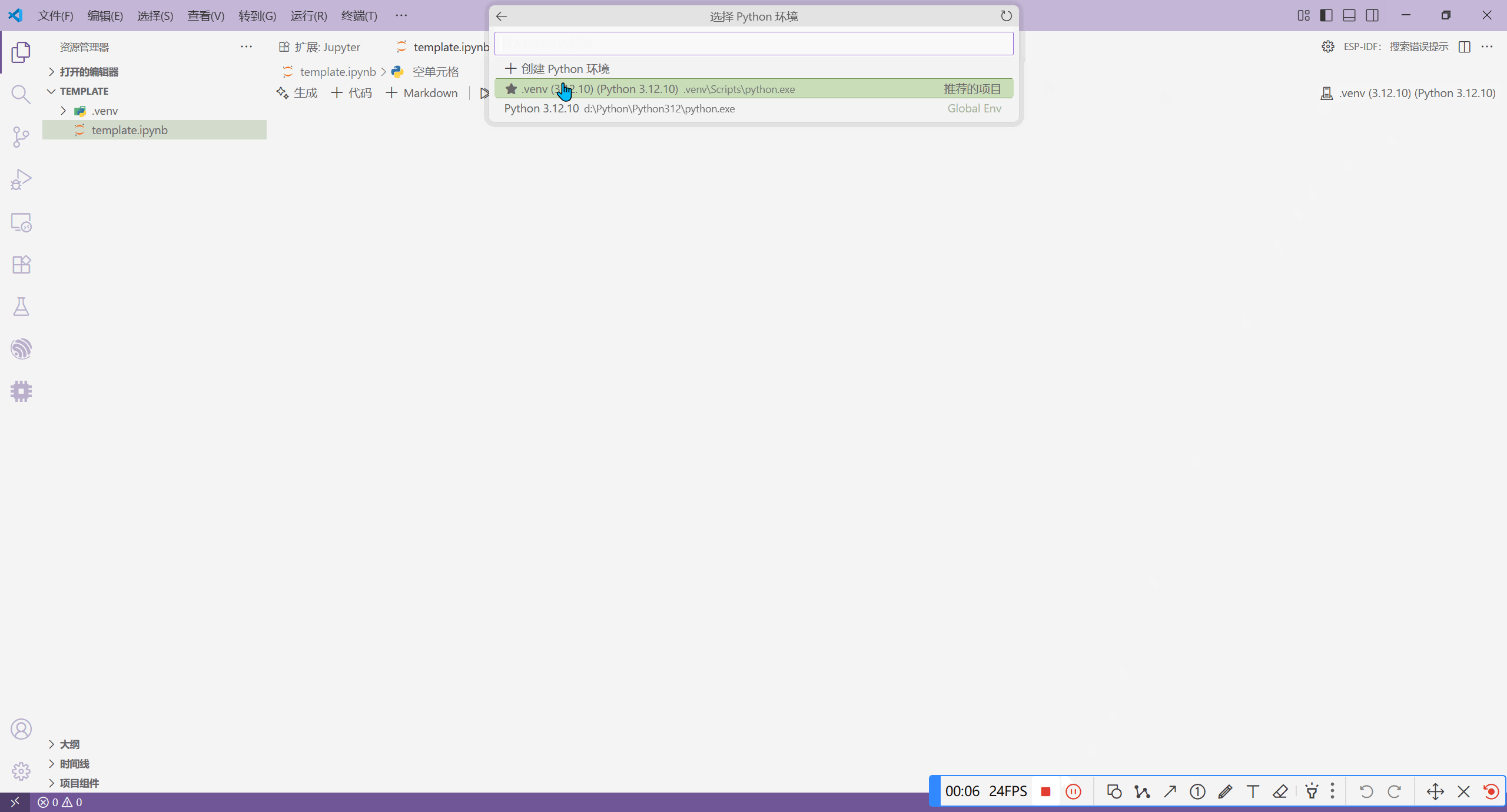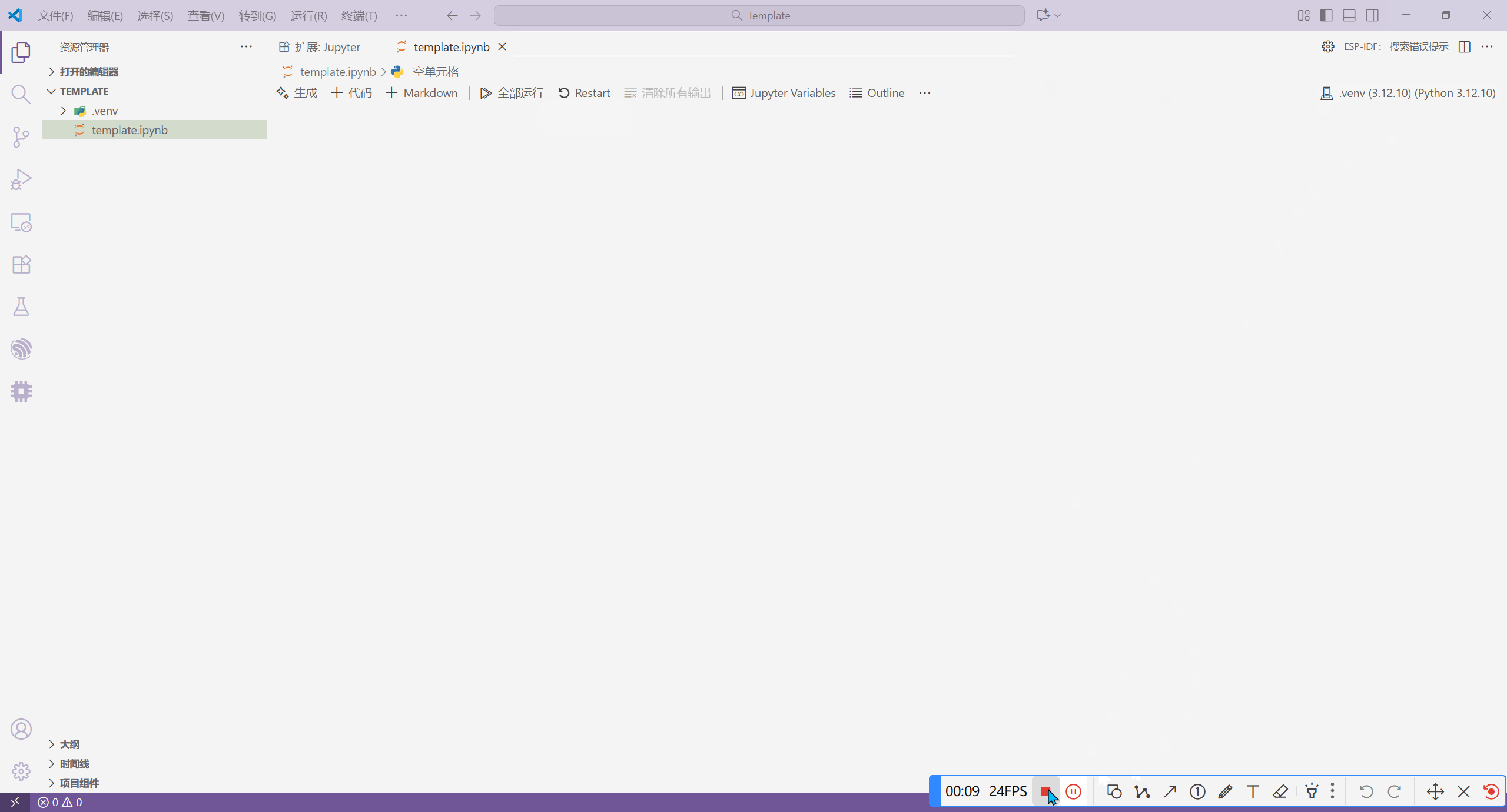
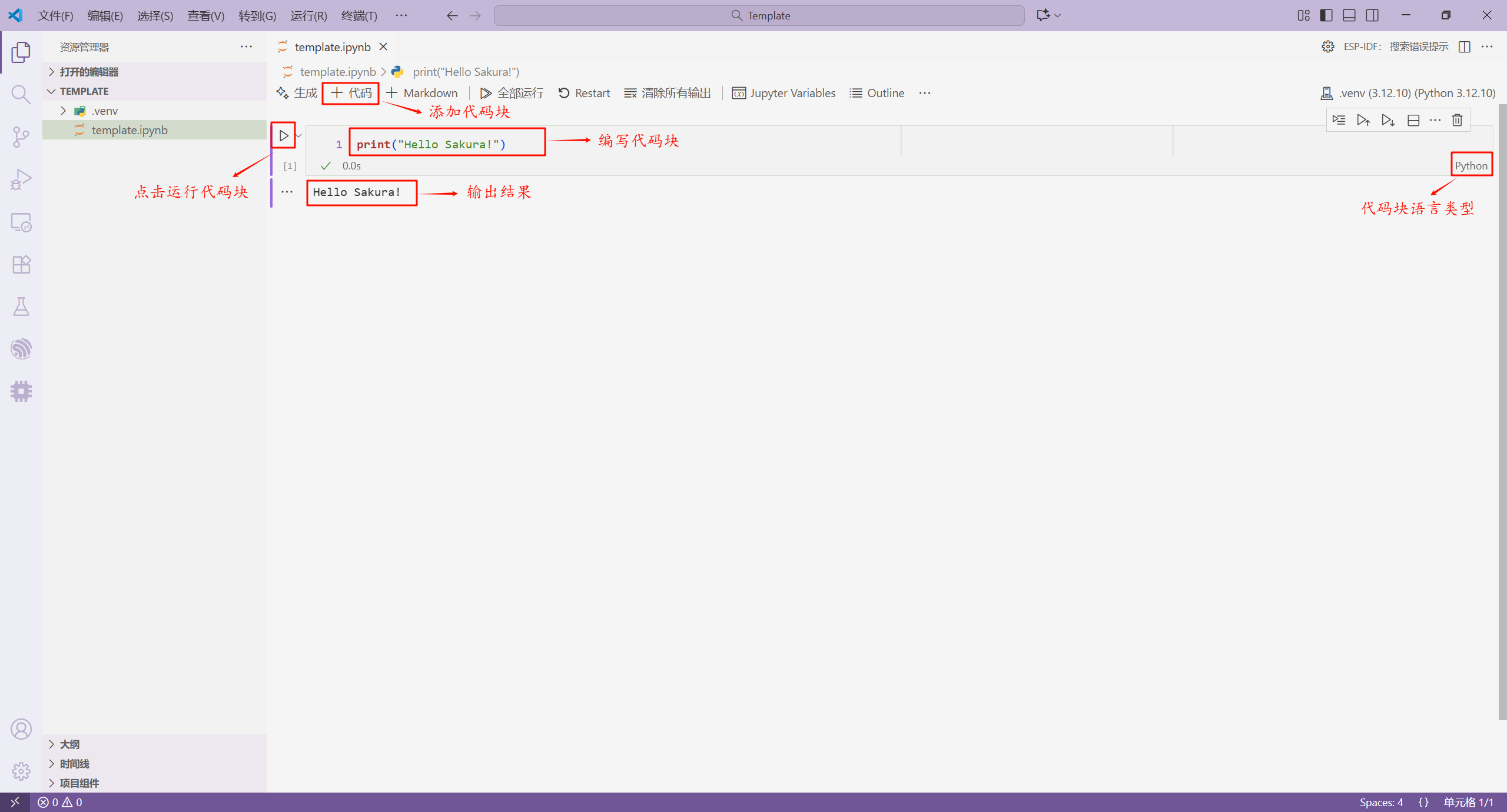
在确保 Jupyter 文件的内核为 Python 之后,我们添加 Python 代码块,并运行它。
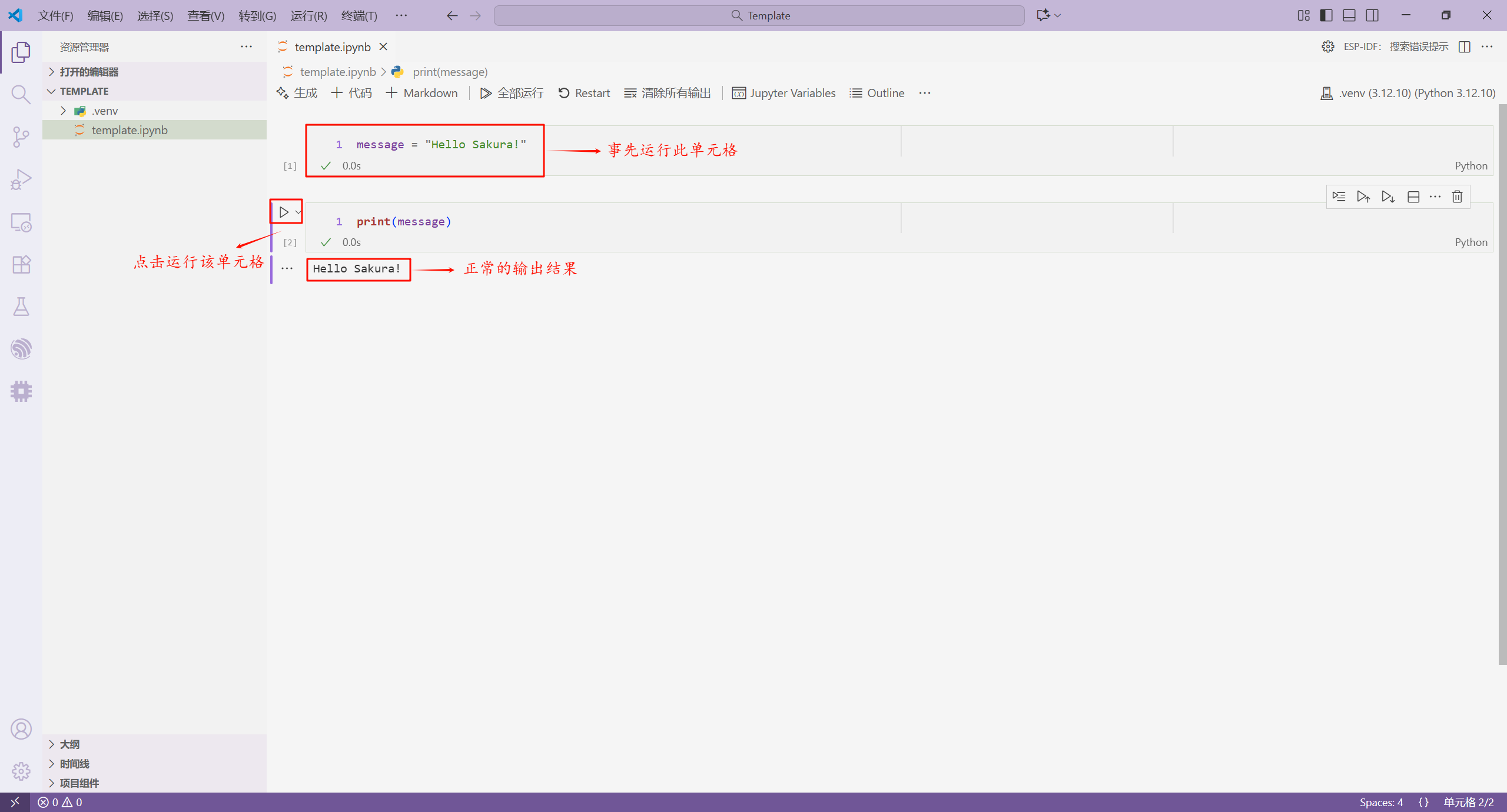
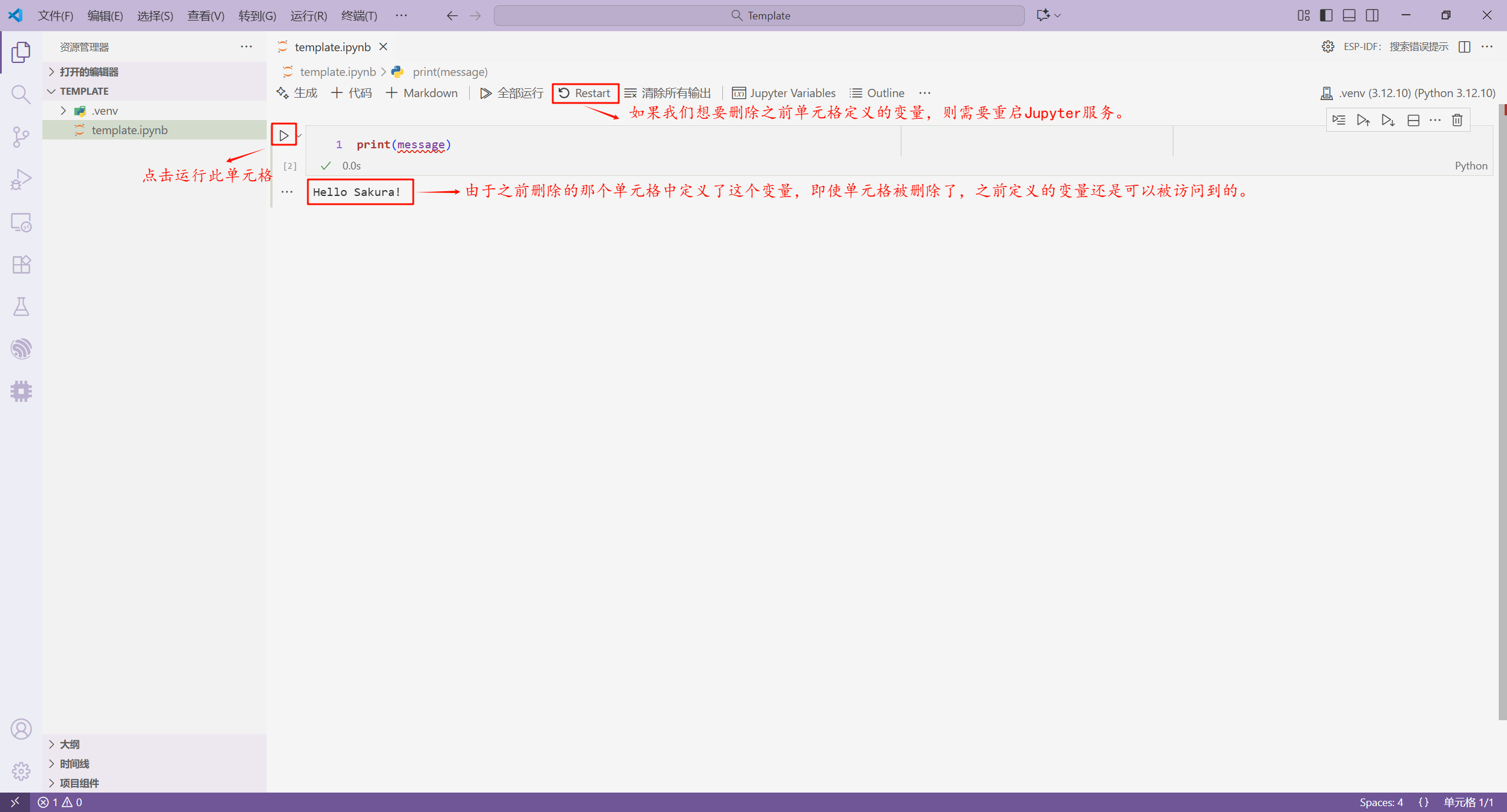
在 Jupyter 文件中,在一个单元格定义的变量并不是某个单元格独有的,我们可以在其它单元格中访问这个变量。如果我们要使用其它单元格中所使用的变量,首先需要运行那个变量所在的单元格,然后再运行这个单元格。
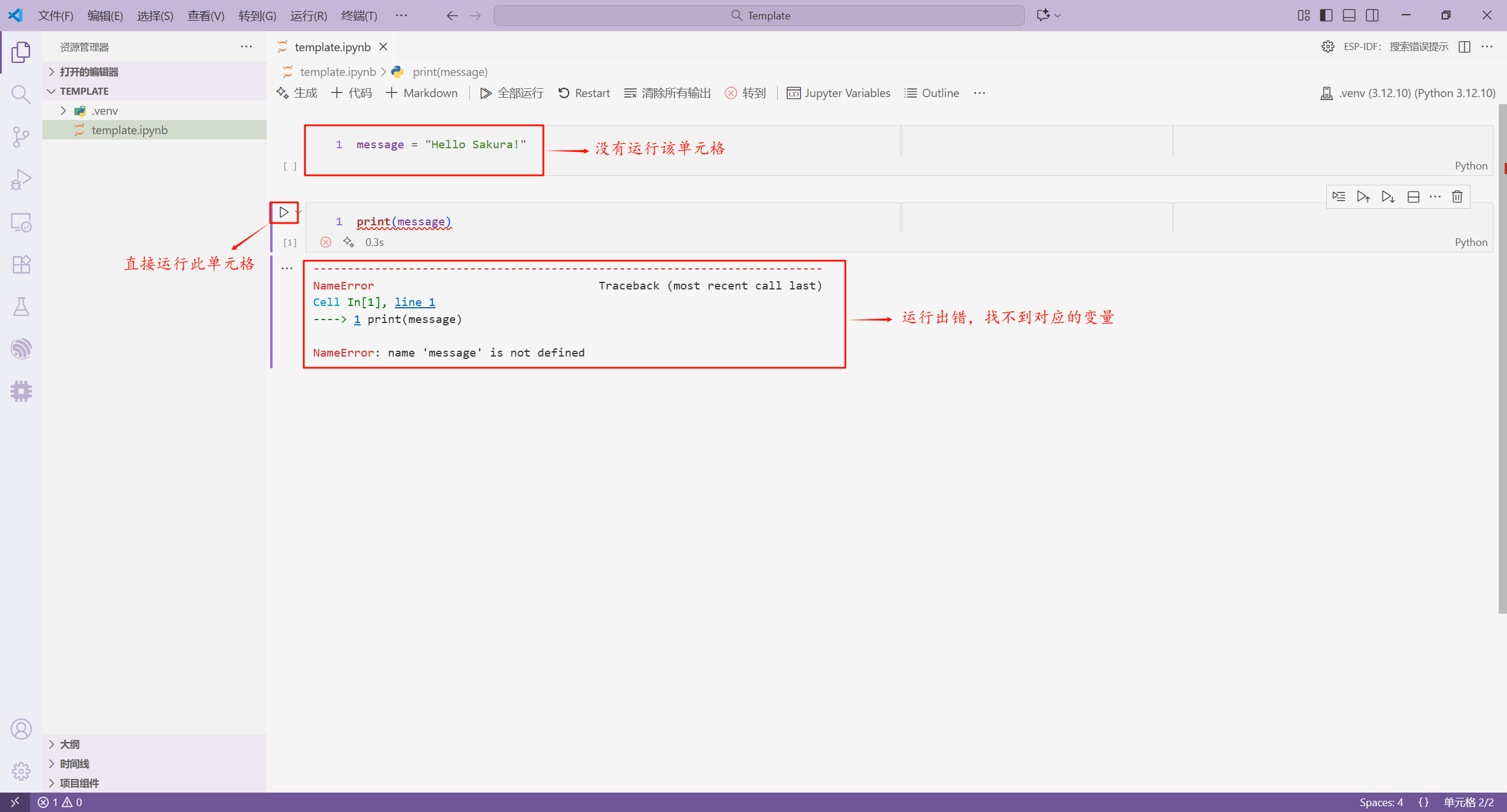
如果我们直接使用了其它单元格中没有运行的变量,会报 NameError 错误。
如果我们直接运行过其它单元格定义的变量,再删除该单元格后,这个变量还是存在的,如果我们想要删除这个变量,则需要重启 Jupyter 服务。
Jupyter 中常用的快捷键如下:
| 快捷键 | 功能 |
|---|---|
| Esc | 从输入模式退出到命令模式 |
| a | 在当前单元格上面创建一个新的单元格 |
| b | 在当前单元格下面创建一个新的单元格 |
| dd | 删除当前单元格 |
| m | 当前单元格切换到 Markdown 模式 |
| y | 当前单元格切换到代码模式 |
| Ctrl + Enter | 运行当前单元格 |
| Shift + Enter | 运行当前单元格并创建一个新的单元格 |
Jupyter 的快捷键(除了 Esc)需要在命令行模式中按下,因此我们可以先按下 Esc 键从输入模式退出到命令模式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号