
Celery分布式任务队列原理,用法
提交一个耗时的请求, 立即返回ID,
拿着这个ID去查询任务处理进程
自己想到的方案:
前端请求接口a,(接口a立即开始处理任务,把任务的处理到哪一步放在redis中)
前端请求接口b,(接口b立即返回redis中进行到哪一步)
前端先调用接口a(此时接口a阻塞)
前端继续轮询接口b获取a进行到哪一步了
当接口a成功返回结果,停止轮询
Alex讲的方案
前端请求接口a,接口立马生成一个任务id,然后启动一个进程执行这个任务,然后把id返回给前端(为什么不是线程?如果启动子线程执行任务,主线程同样会卡主,一样阻塞,如果是守护线程,主线程执行完,守护线程也结束了,所以这两种线程都不行),
把任务执行过程写在redis/数据库/文件里 whatever,
前端可以请求接口b,接口b拿着这个任务id去redis里找到结果并返回就OK了。(假设存在redis里)
这个方案看似没有问题,实际上有个坑,就是不能支持高并发,为什么呢?
Alex的原话是:你提供的这个任务管理可能有多个用户都用它,对不对?比如一个用户,执行100台并发,20个用户同时,每个人执行100台,就是2000个并发,你觉得你的这个任务服务器撑得住吗?肯定不行的,是不是?
你现在是直接在任务服务器上调的脚本(调脚本就视为一个耗时的任务),随着并发的用户越多,机器会越来越慢,第21个用户可能都打不开网站了。这就是个坑
一开始就不该把任务执行的模块,放到任务分发的服务器上,
一开始就该分清楚,谁负责任务分发,谁负责任务执行。
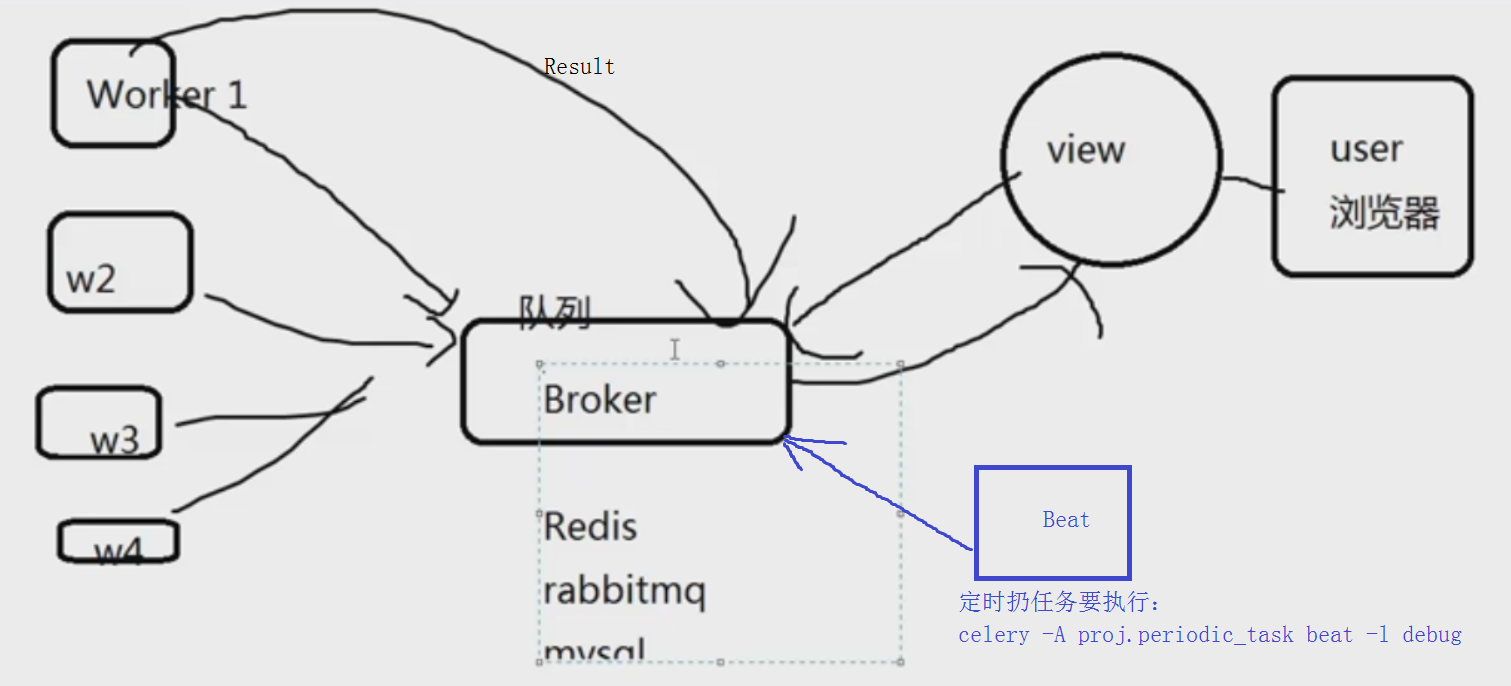
意思是:一台服务器a分发任务(任务按先后顺序放在队列里),后面四台服务器b,c,d,e从a上从队列里拿任务去执行
Celery工作原理:
自己的领悟:首先由五台机器,view是1台机器,后面有4台worker,拿Excel表入库的任务来说
用户将Excel文件发给view,view要将文件放入队列中,4台worker从队列中拿excel文件,那么必须要在4台worker上启动某个程序
拿到文件解析入库,成功后将信息写到队列中(是不是也可以在执行的过程中将执行的进度写入队列里?),可以和excel文件的队列一样,也可以不一样。
Celery 扮演生产者和消费者的角色,brokers 就是生产者和消费者存放/拿取产品的地方(队列)
但是`放产品`这个动作还是需要客户端来做,例如:tasks.add.delay(1,2) 或者使用beat: celery -A proj beat -l info
celery在windows上不好使。要用linux,
启动一台linux服务器,IP:192.168.1.10
`pip3 install celery`
`yum install redis`
定义tasks.py:
from celery import Celery
import time
# worker上能执行的任务是提前定义好的,这个任务就是用app来定义,app包括哪些任务呢,就是@app.task,broker是生产者队列,backend是结果队列
app = Celery('tasks', broker='redis://localhost', backend='redis://localhost')
@app.task
def add(x, y):
time.sleep(5)
return x + y
`redis-server`
`celery -A tasks worker-l debug` # tasks是tasks.py省略扩展名,worker是角色,-l日志级别

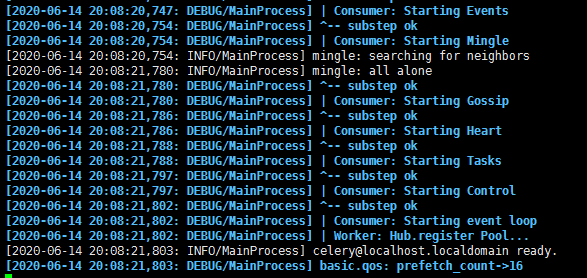
重新启动一个终端:
[root@localhost ~]# python3
Python 3.6.8 (default, Apr 2 2020, 13:34:55)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-39)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import tasks
>>> tasks.add(3,4)
7
>>> t= tasks.add.delay(3,4)
>>> t # 返回的是AsyncResult对象
<AsyncResult: 4ffaa775-0823-470b-b245-f3465dd921f8>
>>> t.ready()
False
>>> t.ready()
False
>>> t.ready()
True
>>> t.get()
7
>>>t.get(timeout=1) # 给任务设置等待时间,提高用户体验
>>> t.get() #如果任务出错
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.6/site-packages/celery/result.py", line 228, in get
on_message=on_message,
File "/usr/local/lib/python3.6/site-packages/celery/backends/asynchronous.py", line 202, in wait_for_pending
return result.maybe_throw(callback=callback, propagate=propagate)
File "/usr/local/lib/python3.6/site-packages/celery/result.py", line 333, in maybe_throw
self.throw(value, self._to_remote_traceback(tb))
File "/usr/local/lib/python3.6/site-packages/celery/result.py", line 326, in throw
self.on_ready.throw(*args, **kwargs)
File "/usr/local/lib/python3.6/site-packages/vine/promises.py", line 244, in throw
reraise(type(exc), exc, tb)
File "/usr/local/lib/python3.6/site-packages/vine/five.py", line 195, in reraise
raise value
NameError: name 'aa' is not defined
>>> t.get(propagate=False) # 出错只取结果
NameError("name 'aa' is not defined",)
>>> tt.traceback # 错误结果
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'tt' is not defined
>>>
celery接收到任务:
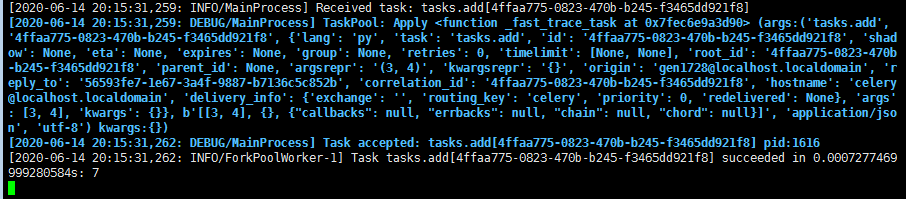
启动一个celery的worker,有5个进程,一个主进程3575 , 和4个工作进程,都是由主进程启动的。工作进程用来执行任务

工作进程应该可以设置, `celery -A proj worker -l info --concurrency=4 `

所以,执行`celery -A proj worker -l debug`命令2次,启动2个worker,就是10个celery进程,每个worker5个进程(一个主进程和四个工作进程)
如果在项目中使用Celery?
在项目中使用Celery,之前是配置和任务写在一起,现在把配置和任务分开
proj/__init__.py
/celery.py /tasks.py /periodic_task.py #定时任务

from __future__ import absolute_import, unicode_literals #导入安装的celery(所以上面要写绝对导入),而不是自己导自己(from .celery) from celery import Celery app = Celery('proj', broker='redis://', backend='redis://', include=['proj.tasks', 'proj.periodic_task']) # 这个celery管理了哪些task文件可以有多个,其中有个定时任务periodic_task # Optional configuration, see the application user guide. # update方法更新配置,也可以直接写在上面初始化Celery里面 app.conf.update( result_expires=3600, # 任务结果一小时内没人取就丢弃 ) if __name__ == '__main__': app.start()
from __future__ import absolute_import, unicode_literals from .celery import app @app.task def add(x, y): return x + y @app.task def mul(x, y): return x * y @app.task def xsum(numbers): return sum(numbers)
from __future__ import absolute_import, unicode_literals from .celery import app from celery.schedules import crontab #该装饰器的作用是celery一连上就执行被装饰的函数 @app.on_after_configure.connect def setup_periodic_tasks(sender, **kwargs): # 每10秒执行test('hello') sender.add_periodic_task(10.0, test.s('hello'), name='add every 10') # 每30秒执行test('world') sender.add_periodic_task(30.0, test.s('world'), expires=10) # 每周一上午7:30执行 sender.add_periodic_task( crontab(hour=7, minute=30, day_of_week=1), test.s('Happy Mondays!'), ) @app.task def test(arg): print(arg)
worker启动:`celery -A proj worker -l debug`
发起任务:
from proj import tasks,tasks1 #要cd到proj的上一层目录
t1 = tasks.add.delay(2,4)
t2 = tasks1.get_rand.delay(1,20)
启动定时任务调度器beat:
`celery -A proj.periodic_task beat -l debug`

celery单独启动一个进程来定时发起这些任务,就是beat, 注意, 这里是发起任务,不是执行,这个进程只会不断的去检查你的任务计划, 每发现有任务需要执行了,就发起一个任务调用消息,交给celery worker去执行

上面是通过调用函数添加定时任务,也可以像写配置文件 一样的形式添加, 下面是每30s执行的任务
app.conf.beat_schedule = { 'add-every-30-seconds': { 'task': 'proj.tasks.add', 'schedule': 30.0, 'args': (16, 16) }, } app.conf.timezone = 'UTC'
复杂的,例如:每周1的早上7.30执行tasks.add任务
from celery.schedules import crontab app.conf.beat_schedule = { # Executes every Monday morning at 7:30 a.m. 'add-every-monday-morning': { 'task': 'proj.tasks.add', 'schedule': crontab(hour=7, minute=30, day_of_week=1), 'args': (16, 16), }, }
可以在1台服务器上启动4个worker (后台运行)
[root@localhost ~]# celery multi start w1 -A proj -l debug celery multi v4.4.5 (cliffs) > Starting nodes... > w1@localhost.localdomain: OK [root@localhost ~]# celery multi start w2 -A proj -l debug celery multi v4.4.5 (cliffs) > Starting nodes... > w2@localhost.localdomain: OK [root@localhost ~]# celery multi start w3 -A proj -l debug celery multi v4.4.5 (cliffs) > Starting nodes... > w3@localhost.localdomain: OK [root@localhost ~]# celery multi start w4 -A proj -l debug celery multi v4.4.5 (cliffs) > Starting nodes... > w4@localhost.localdomain: OK [root@localhost ~]#
可以在多台服务器上运行worker,只需要修改redis配置就行。他们都从同一个redis领任务
重启 w1 w2 :`celery multi restart w1 w2 -A proj`
停止w1 w2:`celery multi stop w1 w2 -A proj`

 浙公网安备 33010602011771号
浙公网安备 33010602011771号