
kafka
需要依赖jdk,服务器需要安装jdk
注意:kafka哪怕只有一个节点也是集群形式
一、官网下载kafka以及zookeeper
本篇文章下载版本如下:

并解压到服务器
tar -zxvf kafka_2.11-2.4.0.tgz -C ../install 解压到指定目录下
二、启动zookeeper与kafka
2.1 启动ZK
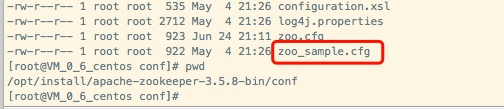
进入zookeeper目录下的conf文件夹,然后拷贝配置文件重命名
cp zoo_sample.cfg zoo.cfg
如下图所示,暂时不需要修改内容
然后进入zookeeper的bin目录启动zk:
./zkServer.sh start

2.2 启动kafka
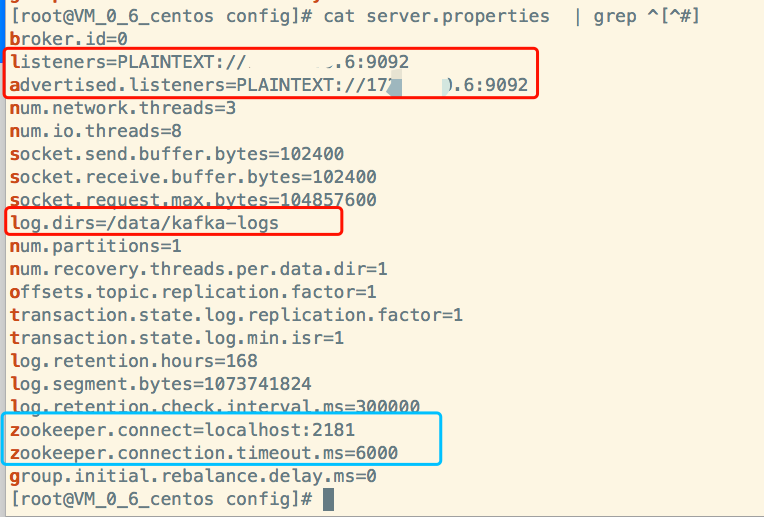
首先需要修改kafka的配置:
红色是要写成自己ip的配置,蓝色是zk,暂时只配置上面本机启动的
1、启动kafka bin/kafka-server-start.sh config/server.properties & 2、停止kafka bin/kafka-server-stop.sh 3、创建Topic bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic wanghao-topic 4、查看已经创建的Topic信息 bin/kafka-topics.sh --list --zookeeper localhost:2181 5、发送信息 bin/kafka-console-producer.sh --broker-list localhost:9092 --topic wanghao-topic 6、接收消息 bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic wanghao-topic --from-beginning
bin/kafka-console-consumer.sh --bootstrap-server 172.17.0.6:9092 --topic wanghao-topic --from-beginning
如果出现如下类似报错的话,需要把localhost改为ip

2.3 kafka的介绍
kafka的基本概念
Topic :一个虚拟的概念,由一个到多个Partitions组成
Partitions:实际消息存储单位
Producer:消息生产者
Consumer:消息消费者
2.4 模拟kafka
首先启动kafka
bin/kafka-server-start.sh config/server.properties &
创建Topic:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic wanghao-topic

创建之后使用查看Topic命令查看:
bin/kafka-topics.sh --list --zookeeper localhost:2181

发送信息
bin/kafka-console-producer.sh --broker-list 172.17.0.6:9092 --topic wanghao-topic
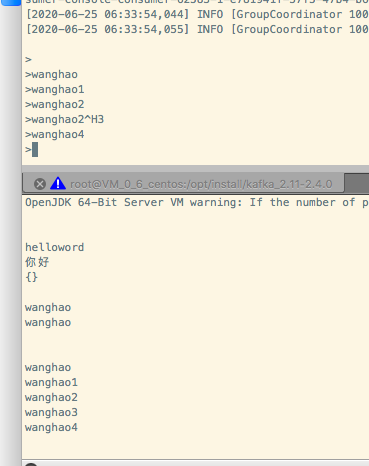
如下图所示:有>符号表示连接成功,我这边发送了三条信息,

接收消息
bin/kafka-console-consumer.sh --bootstrap-server 172.17.0.6:9092 --topic wanghao-topic --from-beginning
如下图所示:

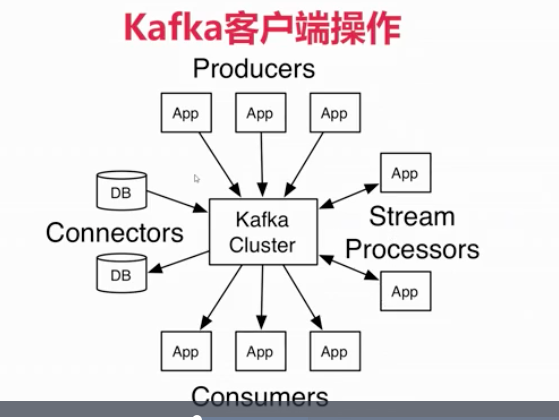
三、客户端操作kafka
3.1、 kafka客户端API类型
- AdminClient API:允许管理和检测topic、broker以及其它kafka对象
- Producer API:发布消息到一个或者多个topic
- Consumer API:订阅一个或者多个topic,并处理消息
- Streams API:高效地将输入流转换成输出流
- Connector API: 从一些原系统或者应用程序中拉取数据到kafka
3.2 AdminClient API介绍Demo
3.2.1 引入依赖并连接kafka
创建springboot项目并引入kafka依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.0</version>
</dependency>


package com.wh.springkafka.admin; import org.apache.kafka.clients.admin.Admin; import org.apache.kafka.clients.admin.AdminClient; import org.apache.kafka.clients.admin.AdminClientConfig; import java.util.Properties; public class AdminSample { public static void main(String[] args) { AdminClient adminClient = adminClient(); System.out.println(adminClient); } public static AdminClient adminClient(){ Properties properties = new Properties(); properties.setProperty(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG,"ip:9092"); AdminClient adminClient = AdminClient.create(properties); return adminClient; } }
确认kafka已经正常启动,然后运行main方法,如下图所示,链接还是很成功的:
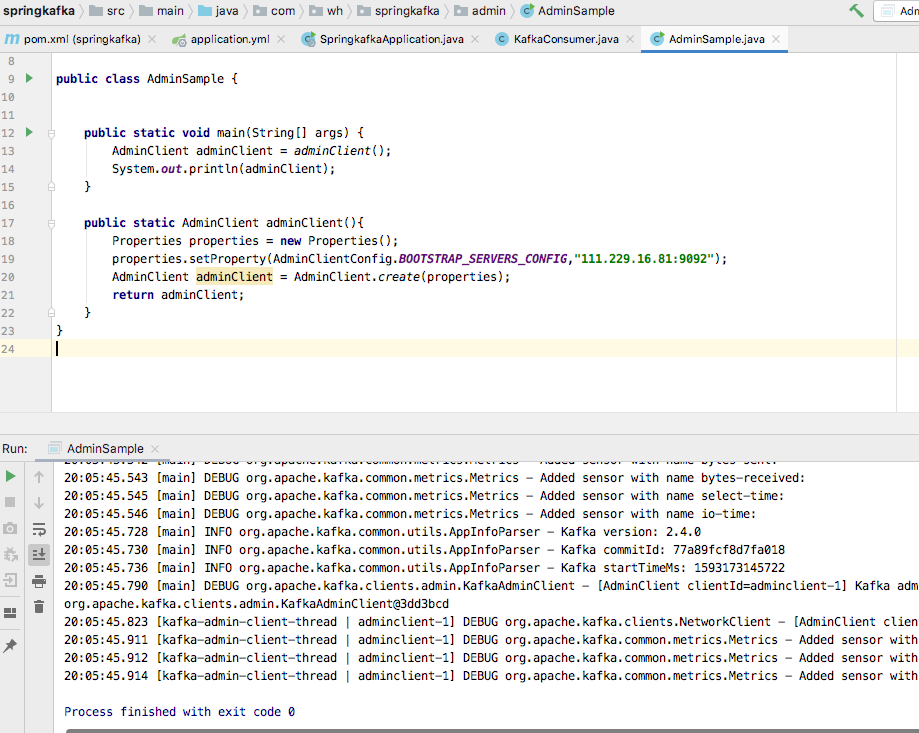
3.2.2 创建topic
api如下:
default CreateTopicsResult createTopics(Collection<NewTopic> newTopics) { return this.createTopics(newTopics, new CreateTopicsOptions()); }
使用上面的adminClient创建,参数是newTopic
创建方法,其中第二个参数1代表numPartitions数量:
// 创建topic实例 public static void createTopic(AdminClient adminClient){ // 副本因子 Short s = 1; NewTopic newTopic = new NewTopic(TOPIC_NAME,1,s); CreateTopicsResult result = adminClient.createTopics(Arrays.asList(newTopic)); System.out.println("CreateTopicsResult:" +result); }
3.3.3 查看topic列表
直接list即可
// 查询topic列表 public static void listTopic(AdminClient adminClient) { try { // 普通查看 Set<String> names = adminClient.listTopics().names().get(); System.out.println("names:"+names); // 过滤查看 Internal ListTopicsOptions options = new ListTopicsOptions(); options.listInternal(true); Set<String> names2 = adminClient.listTopics(options).names().get(); System.out.println("names{options}:"+names2); } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } }
3.3.4 删除topic
topic的name就相当于key键一样,所以删除使用name删除即可。
// 删除topic实例 public static void delTopic(AdminClient adminClient){ DeleteTopicsResult result = adminClient.deleteTopics(Arrays.asList(TOPIC_NAME)); try { System.out.println("DeleteTopicsResult:" +result.all().get()); } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } }
3.3.5 查看topic实例
// 获取topic实例 public static void descTopic(AdminClient adminClient){ DescribeTopicsResult describeTopicsResult = adminClient.describeTopics(Arrays.asList(TOPIC_NAME)); try { System.out.println(gson.toJson(describeTopicsResult.all().get())); } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } }
获取后的实例信息如下:
{ "wanghao-topic": { "name": "wanghao-topic", "internal": false, "partitions": [{ "partition": 0, "leader": { "id": 1001, "idString": "1001", "host": "kafkaHost", "port": 9092 }, "replicas": [{ "id": 1001, "idString": "1001", "host": "kafkaHost", "port": 9092 }], "isr": [{ "id": 1001, "idString": "1001", "host": "kafkaHost", "port": 9092 }] }], "authorizedOperations": [] } }
3.3.6 获取topic的配置信息
// 获取topic 配置信息 public static void descTopicConfig(AdminClient adminClient){ ConfigResource resource = new ConfigResource(ConfigResource.Type.TOPIC,TOPIC_NAME); DescribeConfigsResult describeConfigsResult = adminClient.describeConfigs(Arrays.asList(resource)); try { System.out.println(gson.toJson(describeConfigsResult.all().get())); } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } }
获取后的配置信息如下:
{ "ConfigResource(type=TOPIC, name='wanghao-topic')": { "entries": { "compression.type": { "name": "compression.type", "value": "producer", "source": "DEFAULT_CONFIG", "isSensitive": false, "isReadOnly": false, "synonyms": [] }, "leader.replication.throttled.replicas": { "name": "leader.replication.throttled.replicas", "value": "", "source": "DEFAULT_CONFIG", "isSensitive": false, "isReadOnly": false, "synonyms": [] }, "message.downconversion.enable": { "name": "message.downconversion.enable", "value": "true", "source": "DEFAULT_CONFIG", "isSensitive": false, "isReadOnly": false, "synonyms": [] }, "min.insync.replicas": { "name": "min.insync.replicas", "value": "1", "source": "DEFAULT_CONFIG", "isSensitive": false, "isReadOnly": false, "synonyms": [] }, "segment.jitter.ms": { "name": "segment.jitter.ms", "value": "0", "source": "DEFAULT_CONFIG", "isSensitive": false, "isReadOnly": false, "synonyms": [] }, "cleanup.policy": { "name": "cleanup.policy", "value": "delete", "source": "DEFAULT_CONFIG", "isSensitive": false, "isReadOnly": false, "synonyms": [] }, "flush.ms": { "name": "flush.ms", "value": "9223372036854775807", "source": "DEFAULT_CONFIG", "isSensitive": false, "isReadOnly": false, "synonyms": [] }, "follower.replication.throttled.replicas": { "name": "follower.replication.throttled.replicas", "value": "", "source": "DEFAULT_CONFIG", "isSensitive": false, "isReadOnly": false, "synonyms": [] }, "segment.bytes": { "name": "segment.bytes", "value": "1073741824", "source": "STATIC_BROKER_CONFIG", "isSensitive": false, "isReadOnly": false, "synonyms": [] }, "retention.ms": { "name": "retention.ms", "value": "604800000", "source": "DEFAULT_CONFIG", "isSensitive": false, "isReadOnly": false, "synonyms": [] }, "flush.messages": { "name": "flush.messages", "value": "9223372036854775807", "source": "DEFAULT_CONFIG", "isSensitive": false, "isReadOnly": false, "synonyms": [] }, "message.format.version": { "name": "message.format.version", "value": "2.4-IV1", "source": "DEFAULT_CONFIG", "isSensitive": false, "isReadOnly": false, "synonyms": [] }, "file.delete.delay.ms": { "name": "file.delete.delay.ms", "value": "60000", "source": "DEFAULT_CONFIG", "isSensitive": false, "isReadOnly": false, "synonyms": [] }, "max.compaction.lag.ms": { "name": "max.compaction.lag.ms", "value": "9223372036854775807", "source": "DEFAULT_CONFIG", "isSensitive": false, "isReadOnly": false, "synonyms": [] }, "max.message.bytes": { "name": "max.message.bytes", "value": "1000012", "source": "DEFAULT_CONFIG", "isSensitive": false, "isReadOnly": false, "synonyms": [] }, "min.compaction.lag.ms": { "name": "min.compaction.lag.ms", "value": "0", "source": "DEFAULT_CONFIG", "isSensitive": false, "isReadOnly": false, "synonyms": [] }, "message.timestamp.type": { "name": "message.timestamp.type", "value": "CreateTime", "source": "DEFAULT_CONFIG", "isSensitive": false, "isReadOnly": false, "synonyms": [] }, "preallocate": { "name": "preallocate", "value": "false", "source": "DYNAMIC_TOPIC_CONFIG", "isSensitive": false, "isReadOnly": false, "synonyms": [] }, "min.cleanable.dirty.ratio": { "name": "min.cleanable.dirty.ratio", "value": "0.5", "source": "DEFAULT_CONFIG", "isSensitive": false, "isReadOnly": false, "synonyms": [] }, "index.interval.bytes": { "name": "index.interval.bytes", "value": "4096", "source": "DEFAULT_CONFIG", "isSensitive": false, "isReadOnly": false, "synonyms": [] }, "unclean.leader.election.enable": { "name": "unclean.leader.election.enable", "value": "false", "source": "DEFAULT_CONFIG", "isSensitive": false, "isReadOnly": false, "synonyms": [] }, "retention.bytes": { "name": "retention.bytes", "value": "-1", "source": "DEFAULT_CONFIG", "isSensitive": false, "isReadOnly": false, "synonyms": [] }, "delete.retention.ms": { "name": "delete.retention.ms", "value": "86400000", "source": "DEFAULT_CONFIG", "isSensitive": false, "isReadOnly": false, "synonyms": [] }, "segment.ms": { "name": "segment.ms", "value": "604800000", "source": "DEFAULT_CONFIG", "isSensitive": false, "isReadOnly": false, "synonyms": [] }, "message.timestamp.difference.max.ms": { "name": "message.timestamp.difference.max.ms", "value": "9223372036854775807", "source": "DEFAULT_CONFIG", "isSensitive": false, "isReadOnly": false, "synonyms": [] }, "segment.index.bytes": { "name": "segment.index.bytes", "value": "10485760", "source": "DEFAULT_CONFIG", "isSensitive": false, "isReadOnly": false, "synonyms": [] } } } }
3.3.7 修改配置信息
这里模拟修改 preallocate 这个属性,属性初始化是false,修改为true。
第一种修改方法如下:
public static void updateTopicConfig(AdminClient adminClient){ Map<ConfigResource,Config> map = new HashMap<>(); ConfigResource resource = new ConfigResource(ConfigResource.Type.TOPIC,TOPIC_NAME); ConfigEntry entry = new ConfigEntry("preallocate","true"); Config config = new Config(Arrays.asList(entry)); map.put(resource,config); AlterConfigsResult alterConfigsResult = adminClient.alterConfigs(map); try { System.out.println(alterConfigsResult.all().get()); } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } }
执行结果如下图,看到刚开始是false,后来改为true
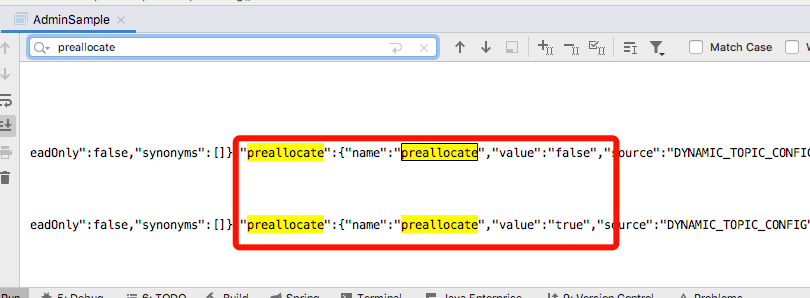
使用第二种方法进行修改,最新的方法
// 修改topic 配置信息 public static void updateTopicConfig2(AdminClient adminClient){ Map<ConfigResource,Collection<AlterConfigOp>> map = new HashMap<>(); ConfigResource resource = new ConfigResource(ConfigResource.Type.TOPIC,TOPIC_NAME); ConfigEntry entry = new ConfigEntry("preallocate","false"); Config config = new Config(Arrays.asList(entry)); AlterConfigOp op = new AlterConfigOp(entry,AlterConfigOp.OpType.SET); map.put(resource,Arrays.asList(op)); AlterConfigsResult alterConfigsResult = adminClient.incrementalAlterConfigs(map); try { System.out.println(alterConfigsResult.all().get()); } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } }
重新把该属性改为默认值false
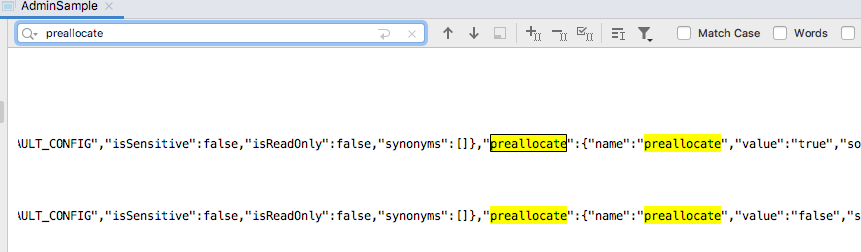
3.3.8 添加partitions
// 添加 partitions public static void addPartitions(AdminClient adminClient,int numPartitions){ NewPartitions partitions = NewPartitions.increaseTo(numPartitions); Map<String, NewPartitions> partitionsMap = new HashMap<>(); partitionsMap.put(TOPIC_NAME,partitions); adminClient.createPartitions(partitionsMap); }
3.3.9 完整代码
package com.wh.springkafka.admin; import com.google.gson.Gson; import org.apache.kafka.clients.admin.*; import org.apache.kafka.common.acl.AclBindingFilter; import org.apache.kafka.common.config.ConfigResource; import java.util.*; import java.util.concurrent.ExecutionException; public class AdminSample { public static final String TOPIC_NAME = "wanghao-topic"; public static final Gson gson = new Gson(); public static void main(String[] args) { // 创建AdminClient客户端 AdminClient adminClient = adminClient(); // createTopic(adminClient); // listTopic(adminClient); // delTopic(adminClient); // listTopic(adminClient); // descTopic(adminClient); // descTopicConfig(adminClient); // updateTopicConfig(adminClient); // descTopicConfig(adminClient); // updateTopicConfig2(adminClient); // descTopicConfig(adminClient); descTopic(adminClient); addPartitions(adminClient,2); descTopic(adminClient); } //创建AdminClient客户端 public static AdminClient adminClient(){ Properties properties = new Properties(); // 172.17.0.6 111.229.16.81 kafkaHost properties.setProperty(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG,"kafkaHost:9092"); AdminClient adminClient = AdminClient.create(properties); return adminClient; } // 创建topic实例 public static void createTopic(AdminClient adminClient){ // 副本因子 Short s = 1; NewTopic newTopic = new NewTopic(TOPIC_NAME,1,s); CreateTopicsResult result = adminClient.createTopics(Arrays.asList(newTopic)); System.out.println("CreateTopicsResult:" +result); } // 查询topic列表 public static void listTopic(AdminClient adminClient) { try { // 普通查看 Set<String> names = adminClient.listTopics().names().get(); System.out.println("names:"+names); // 过滤查看 Internal ListTopicsOptions options = new ListTopicsOptions(); options.listInternal(true); Set<String> names2 = adminClient.listTopics(options).names().get(); System.out.println("names{options}:"+names2); } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } } // 删除topic实例 public static void delTopic(AdminClient adminClient){ DeleteTopicsResult result = adminClient.deleteTopics(Arrays.asList(TOPIC_NAME)); try { System.out.println("DeleteTopicsResult:" +result.all().get()); } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } } // 获取topic实例 public static void descTopic(AdminClient adminClient){ DescribeTopicsResult describeTopicsResult = adminClient.describeTopics(Arrays.asList(TOPIC_NAME)); try { System.out.println(gson.toJson(describeTopicsResult.all().get())); } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } } // 获取topic 配置信息 public static void descTopicConfig(AdminClient adminClient){ ConfigResource resource = new ConfigResource(ConfigResource.Type.TOPIC,TOPIC_NAME); DescribeConfigsResult describeConfigsResult = adminClient.describeConfigs(Arrays.asList(resource)); try { System.out.println(gson.toJson(describeConfigsResult.all().get())); } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } } // 修改topic 配置信息 public static void updateTopicConfig(AdminClient adminClient){ Map<ConfigResource,Config> map = new HashMap<>(); ConfigResource resource = new ConfigResource(ConfigResource.Type.TOPIC,TOPIC_NAME); ConfigEntry entry = new ConfigEntry("preallocate","true"); Config config = new Config(Arrays.asList(entry)); map.put(resource,config); AlterConfigsResult alterConfigsResult = adminClient.alterConfigs(map); try { System.out.println(alterConfigsResult.all().get()); } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } } // 修改topic 配置信息 public static void updateTopicConfig2(AdminClient adminClient){ Map<ConfigResource,Collection<AlterConfigOp>> map = new HashMap<>(); ConfigResource resource = new ConfigResource(ConfigResource.Type.TOPIC,TOPIC_NAME); ConfigEntry entry = new ConfigEntry("preallocate","false"); Config config = new Config(Arrays.asList(entry)); AlterConfigOp op = new AlterConfigOp(entry,AlterConfigOp.OpType.SET); map.put(resource,Arrays.asList(op)); AlterConfigsResult alterConfigsResult = adminClient.incrementalAlterConfigs(map); try { System.out.println(alterConfigsResult.all().get()); } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } } // 添加 partitions public static void addPartitions(AdminClient adminClient,int numPartitions){ NewPartitions partitions = NewPartitions.increaseTo(numPartitions); Map<String, NewPartitions> partitionsMap = new HashMap<>(); partitionsMap.put(TOPIC_NAME,partitions); adminClient.createPartitions(partitionsMap); } }
四、Producer发送
4.1 Producer发送模式
同步发送(异步阻塞发送)
异步发送
异步回调发送
4.1.1 异步发送
/* Producer异步发送演示 */ public static void producerSend(){ Properties properties = new Properties(); properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"ip:9092"); /* acks 0: 最多一次 1:至少一次或者多次 all:有且仅有一次 (携带Id发送,bower会去重如果存过则收到存入成功,则拒收并告诉已经收过) 耗时最久,但是最可靠的 */ properties.setProperty(ProducerConfig.ACKS_CONFIG,"all"); // 重试 properties.setProperty(ProducerConfig.RETRIES_CONFIG,"0"); // 批次大小 properties.setProperty(ProducerConfig.BATCH_SIZE_CONFIG,"16384"); // 多长时间发送一个批次 properties.setProperty(ProducerConfig.LINGER_MS_CONFIG,"1"); // 缓存最大 properties.setProperty(ProducerConfig.BUFFER_MEMORY_CONFIG,"33554432"); // key 序列号 properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); // value 序列号 properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); // 自定义Partition 负载均衡 // properties.setProperty(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.wh.springkafka.producer.SamplePartition"); // producer的主对象 Producer<String,String> producer = new KafkaProducer<String, String>(properties); for (int i = 0; i < 10; i++) { // 消息对象- producerRecoder ProducerRecord<String,String> record = new ProducerRecord<String,String>(TOPIC_NAME,"key-"+i,"value-"+i); producer.send(record); } //所有通道打开都需要关闭 producer.close(); }
kafka 生产者ProducerRecord key 有什么意义
官网的解释是 A key/value pair to be received from Kafka. This consists of a topic name and a partition number, from which the record is being received and an offset that points to the record in a Kafka partition. 我的理解 kafka0.9客户端都以record为一条消息,进行发送,record包含一个键值对,分区和topic名。key像map中的key,只是一条record的一个传递属性,可有可无,你可以灵活的使用它,也可不使用。
If a valid partition number is specified that partition will be used when sending the record. If no partition is specified but a key is present a partition will be chosen using a hash of the key. If neither key nor partition is present a partition will be assigned in a round-robin fashion.
如果一个有效的partition属性数值被指定,那么在发送记录时partition属性数值就会被应用。如果没有partition属性数值被指定,而一个key属性被声明的话,一个partition会通过key的hash而被选中。如果既没有key也没有partition属性数值被声明,那么一个partition将会被分配以轮询的方式。
4.1.2 同步发送(异步阻塞发送)
利用发送的返回值
Future 是发出去就不管了了,直到get的时候才获取返回值,
所以如果每次发送都get一下,则就相当于阻塞等待返回值。
/* Producer异步阻塞(同步)发送 */ public static void producerSyncSend(){ Properties properties = new Properties(); properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"ip:9092"); /* acks 0: 最多一次 1:至少一次或者多次 all:有且仅有一次 (携带Id发送,bower会去重如果存过则收到存入成功,则拒收并告诉已经收过) 耗时最久,但是最可靠的 */ properties.setProperty(ProducerConfig.ACKS_CONFIG,"all"); // 重试 properties.setProperty(ProducerConfig.RETRIES_CONFIG,"0"); // 批次大小 properties.setProperty(ProducerConfig.BATCH_SIZE_CONFIG,"16384"); // 多长时间发送一个批次 properties.setProperty(ProducerConfig.LINGER_MS_CONFIG,"1"); // 缓存最大 properties.setProperty(ProducerConfig.BUFFER_MEMORY_CONFIG,"33554432"); // key 序列号 properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); // value 序列号 properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); // producer的主对象 Producer<String,String> producer = new KafkaProducer<String, String>(properties); for (int i = 0; i < 10; i++) { // 消息对象- producerRecoder ProducerRecord<String,String> record = new ProducerRecord<String,String>(TOPIC_NAME,"key-"+i,"value-"+i); /* Future 是发出去就不管了了,直到get的时候才获取返回值, 所以如果每次发送都get一下,则就相当于阻塞等待返回值。 */ Future<RecordMetadata> result = producer.send(record); try { result.get(); } catch (Exception e) { e.printStackTrace(); } } //所有通道打开都需要关闭 producer.close(); }
4.1.3 异步回调发送
/* Producer异步发送 带回调 */ public static void producerSyncSendAndCallBack(){ Properties properties = new Properties(); properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"ip:9092"); /* acks 0: 最多一次 1:至少一次或者多次 all:有且仅有一次 (携带Id发送,bower会去重如果存过则收到存入成功,则拒收并告诉已经收过) 耗时最久,但是最可靠的 */ properties.setProperty(ProducerConfig.ACKS_CONFIG,"all"); // 重试 properties.setProperty(ProducerConfig.RETRIES_CONFIG,"0"); // 批次大小 properties.setProperty(ProducerConfig.BATCH_SIZE_CONFIG,"16384"); // 多长时间发送一个批次 properties.setProperty(ProducerConfig.LINGER_MS_CONFIG,"1"); // 缓存最大 properties.setProperty(ProducerConfig.BUFFER_MEMORY_CONFIG,"33554432"); // key 序列号 properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); // value 序列号 properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); // producer的主对象 Producer<String,String> producer = new KafkaProducer<String, String>(properties); for (int i = 0; i < 10; i++) { // 消息对象- producerRecoder ProducerRecord<String,String> record = new ProducerRecord<String,String>(TOPIC_NAME,"key-"+i,"value-"+i); /* Future 是发出去就不管了了,直到get的时候才获取返回值, 所以如果每次发送都get一下,则就相当于阻塞等待返回值。 */ producer.send(record, new Callback() { @Override public void onCompletion(RecordMetadata recordMetadata, Exception e) { System.out.println(recordMetadata.toString()); } }); } //所有通道打开都需要关闭 producer.close(); }
4.1.4 自定义Partition 负载均衡
package com.wh.springkafka.producer; import org.apache.kafka.clients.producer.Partitioner; import org.apache.kafka.common.Cluster; import java.util.Map; public class SamplePartition implements Partitioner { @Override public int partition(String topid, Object key, byte[] keybates, Object value, byte[] valueBytes, Cluster cluster) { String keyStr = key+""; String keyInt = keyStr.substring(4); System.out.println(" SamplePartition keyStr: "+keyStr + "keyInt: "+keyInt); return Integer.parseInt(keyInt)%2; } @Override public void close() { } @Override public void configure(Map<String, ?> map) { } }
然后设置属性,class的路径为自定义类的路径。
properties.setProperty(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.wh.springkafka.producer.SamplePartition");
4.4.5 完整的代码
package com.wh.springkafka.producer; import org.apache.kafka.clients.producer.*; import java.util.Properties; import java.util.concurrent.Future; public class ProducerSample { public static final String TOPIC_NAME = "wanghao-topic"; public static void main(String[] args) { producerSend(); // producerSyncSend(); // producerSyncSendAndCallBack(); } /* Producer异步发送 带回调 */ public static void producerSyncSendAndCallBack(){ Properties properties = new Properties(); properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"111.229.16.81:9092"); /* acks 0: 最多一次 1:至少一次或者多次 all:有且仅有一次 (携带Id发送,bower会去重如果存过则收到存入成功,则拒收并告诉已经收过) 耗时最久,但是最可靠的 */ properties.setProperty(ProducerConfig.ACKS_CONFIG,"all"); // 重试 properties.setProperty(ProducerConfig.RETRIES_CONFIG,"0"); // 批次大小 properties.setProperty(ProducerConfig.BATCH_SIZE_CONFIG,"16384"); // 多长时间发送一个批次 properties.setProperty(ProducerConfig.LINGER_MS_CONFIG,"1"); // 缓存最大 properties.setProperty(ProducerConfig.BUFFER_MEMORY_CONFIG,"33554432"); // key 序列号 properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); // value 序列号 properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); // producer的主对象 Producer<String,String> producer = new KafkaProducer<String, String>(properties); for (int i = 0; i < 10; i++) { // 消息对象- producerRecoder ProducerRecord<String,String> record = new ProducerRecord<String,String>(TOPIC_NAME,"key-"+i,"value-"+i); /* Future 是发出去就不管了了,直到get的时候才获取返回值, 所以如果每次发送都get一下,则就相当于阻塞等待返回值。 */ producer.send(record, new Callback() { @Override public void onCompletion(RecordMetadata recordMetadata, Exception e) { System.out.println(recordMetadata.toString()); } }); } //所有通道打开都需要关闭 producer.close(); } /* Producer异步阻塞(同步)发送 */ public static void producerSyncSend(){ Properties properties = new Properties(); properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"111.229.16.81:9092"); /* acks 0: 最多一次 1:至少一次或者多次 all:有且仅有一次 (携带Id发送,bower会去重如果存过则收到存入成功,则拒收并告诉已经收过) 耗时最久,但是最可靠的 */ properties.setProperty(ProducerConfig.ACKS_CONFIG,"all"); // 重试 properties.setProperty(ProducerConfig.RETRIES_CONFIG,"0"); // 批次大小 properties.setProperty(ProducerConfig.BATCH_SIZE_CONFIG,"16384"); // 多长时间发送一个批次 properties.setProperty(ProducerConfig.LINGER_MS_CONFIG,"1"); // 缓存最大 properties.setProperty(ProducerConfig.BUFFER_MEMORY_CONFIG,"33554432"); // key 序列号 properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); // value 序列号 properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); // producer的主对象 Producer<String,String> producer = new KafkaProducer<String, String>(properties); for (int i = 0; i < 10; i++) { // 消息对象- producerRecoder ProducerRecord<String,String> record = new ProducerRecord<String,String>(TOPIC_NAME,"key-"+i,"value-"+i); /* Future 是发出去就不管了了,直到get的时候才获取返回值, 所以如果每次发送都get一下,则就相当于阻塞等待返回值。 */ Future<RecordMetadata> result = producer.send(record); try { result.get(); } catch (Exception e) { e.printStackTrace(); } } //所有通道打开都需要关闭 producer.close(); } /* Producer异步发送演示 */ public static void producerSend(){ Properties properties = new Properties(); properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"111.229.16.81:9092"); /* acks 0: 最多一次 1:至少一次或者多次 all:有且仅有一次 (携带Id发送,bower会去重如果存过则收到存入成功,则拒收并告诉已经收过) 耗时最久,但是最可靠的 */ properties.setProperty(ProducerConfig.ACKS_CONFIG,"all"); // 重试 properties.setProperty(ProducerConfig.RETRIES_CONFIG,"0"); // 批次大小 properties.setProperty(ProducerConfig.BATCH_SIZE_CONFIG,"16384"); // 多长时间发送一个批次 properties.setProperty(ProducerConfig.LINGER_MS_CONFIG,"1"); // 缓存最大 properties.setProperty(ProducerConfig.BUFFER_MEMORY_CONFIG,"33554432"); // key 序列号 properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); // value 序列号 properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); // 自定义Partition 负载均衡 properties.setProperty(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.wh.springkafka.producer.SamplePartition"); // producer的主对象 Producer<String,String> producer = new KafkaProducer<String, String>(properties); for (int i = 0; i < 10; i++) { // 消息对象- producerRecoder ProducerRecord<String,String> record = new ProducerRecord<String,String>(TOPIC_NAME,"key-"+i,"value-"+i); producer.send(record); } //所有通道打开都需要关闭 producer.close(); } }
package com.wh.springkafka.producer; import org.apache.kafka.clients.producer.Partitioner; import org.apache.kafka.common.Cluster; import java.util.Map; public class SamplePartition implements Partitioner { @Override public int partition(String topid, Object key, byte[] keybates, Object value, byte[] valueBytes, Cluster cluster) { String keyStr = key+""; String keyInt = keyStr.substring(4); System.out.println(" SamplePartition keyStr: "+keyStr + "keyInt: "+keyInt); return Integer.parseInt(keyInt)%2; } @Override public void close() { } @Override public void configure(Map<String, ?> map) { } }
五、Consumer客户端接收消息
5.1 自动commit提交offset
package com.wh.springkafka.consumer; import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import java.time.Duration; import java.util.Arrays; import java.util.Properties; public class ConsumerSample { public static final String TOPIC_NAME = "wanghao-topic"; public static void main(String[] args) { helloWorld(); } private static void helloWorld(){ Properties properties = new Properties(); properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"111.229.16.81:9092"); properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG,"test"); properties.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"true"); properties.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"1000"); properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String,String> consumer = new KafkaConsumer(properties); consumer.subscribe(Arrays.asList(TOPIC_NAME)); while (true){ ConsumerRecords<String,String> records = consumer.poll(Duration.ofMillis(10000)); for (ConsumerRecord<String,String> record :records){ System.out.printf("offset = %d, key = %s,value=%s%n " ,record.offset(),record.key(),record.value()); } } } }
5.2 手动commit提交offset
/* 手动提交版本 */ private static void manualCommit(){ Properties properties = new Properties(); properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"111.229.16.81:9092"); properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG,"test"); // 设置自动提交为false properties.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false"); properties.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"1000"); properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String,String> consumer = new KafkaConsumer(properties); // 消费者订阅某个topic或者几个Topic consumer.subscribe(Arrays.asList(TOPIC_NAME)); while (true){ // 定时间隔拉取 ConsumerRecords<String,String> records = consumer.poll(Duration.ofMillis(10000)); for (ConsumerRecord<String,String> record :records){ System.out.printf("partition = %d,offset = %d, key = %s,value=%s%n " ,record.partition(),record.offset(),record.key(),record.value()); } if(true){ // 如果成功则手动提交 consumer.commitAsync(); }else{ // 如果失败则回滚
// 不提交代表回滚
} } }
5.3 属性介绍
5.3.1 group.id
grop.id 也就是组id,不同的consumer指定相同的group.id,则在同一个消费分组。
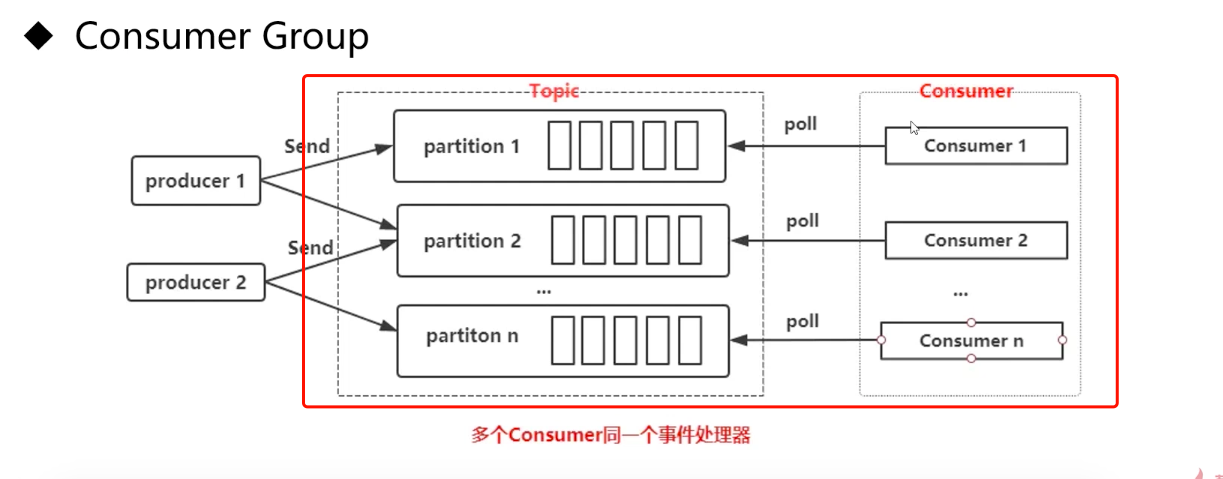
- 单个分区的消息只能由ConsumerGroup中的某一个Consumer消费。consumer一对多个partition,而partition对应多个group只能关联一个consumer
- 一个Consumer可以对应一个partition也可以对应多个partition,但是同一个partition只能对应同一个group下面的consumer。
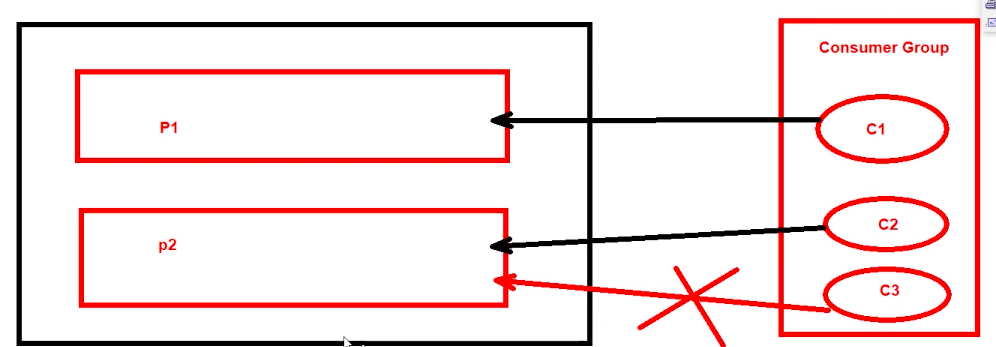
-
Consumer从partition中的消息顺序,默认从头消费
- 单个ConsumerGroup会消费所有的partition中的消息
5.4 根据partition消费
/* 根据partition分别消费并手动提交 */ private static void manualCommitForPartition(){ Properties properties = new Properties(); properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"111.229.16.81:9092"); properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG,"test"); // 设置自动提交为false properties.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false"); properties.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"1000"); properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String,String> consumer = new KafkaConsumer(properties); // 消费者订阅某个topic或者几个Topic consumer.subscribe(Arrays.asList(TOPIC_NAME)); while (true){ // 定时间隔拉取 ConsumerRecords<String,String> records = consumer.poll(Duration.ofMillis(10000)); Set<TopicPartition> partitions = records.partitions(); for (TopicPartition partition : partitions) { List<ConsumerRecord<String, String>> pRecords = records.records(partition); for (ConsumerRecord<String,String> record :pRecords){ System.out.printf("partition = %d,offset = %d, key = %s,value=%s%n " ,record.partition(),record.offset(),record.key(),record.value()); } if(true){ // 如果成功则手动提交 注意这个方法提交 Map<TopicPartition, OffsetAndMetadata> offsets = new HashMap<>(); // 参数2,获取最后一个元素的offset,然后加一就是下一次的起始位置 offsets.put(partition,new OffsetAndMetadata(pRecords.get(pRecords.size()-1).offset()+1)); consumer.commitSync(offsets); }else{ // 如果失败则回滚 } System.out.println("消费完成~~~~~~~~~~~partition "+partition.toString()+" end ~~~~~~~~~~~~~~~~"); } } }
代码如上所示,已经加了注释,执行后结果为:

5.5 直接订阅topic下面的分区
/* 直接订阅topic下面的分区partition */ private static void manualCommitForPartition2(){ Properties properties = new Properties(); properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"111.229.16.81:9092"); properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG,"test"); // 设置自动提交为false properties.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false"); properties.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"1000"); properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String,String> consumer = new KafkaConsumer(properties); // 消费者订阅某个topic或者几个Topic // consumer.subscribe(Arrays.asList(TOPIC_NAME)); TopicPartition p0 = new TopicPartition(TOPIC_NAME,0); TopicPartition p1 = new TopicPartition(TOPIC_NAME,1); consumer.assign(Arrays.asList(p0)); while (true){ // 定时间隔拉取 ConsumerRecords<String,String> records = consumer.poll(Duration.ofMillis(10000)); Set<TopicPartition> partitions = records.partitions(); for (TopicPartition partition : partitions) { List<ConsumerRecord<String, String>> pRecords = records.records(partition); for (ConsumerRecord<String,String> record :pRecords){ System.out.printf("partition = %d,offset = %d, key = %s,value=%s%n " ,record.partition(),record.offset(),record.key(),record.value()); } if(true){ // 如果成功则手动提交 注意这个方法提交 Map<TopicPartition, OffsetAndMetadata> offsets = new HashMap<>(); // 参数2,获取最后一个元素的offset,然后加一就是下一次的起始位置 offsets.put(partition,new OffsetAndMetadata(pRecords.get(pRecords.size()-1).offset()+1)); consumer.commitSync(offsets); }else{ // 如果失败则回滚 } System.out.println("消费完成~~~~~~~~~~~partition "+partition.toString()+" end ~~~~~~~~~~~~~~~~"); } } }
代码区别在于订阅这里,传的数组,所以可订阅多个topic下面的分区

5.6 Consumer与Group情景
5.6.1 新成员加入
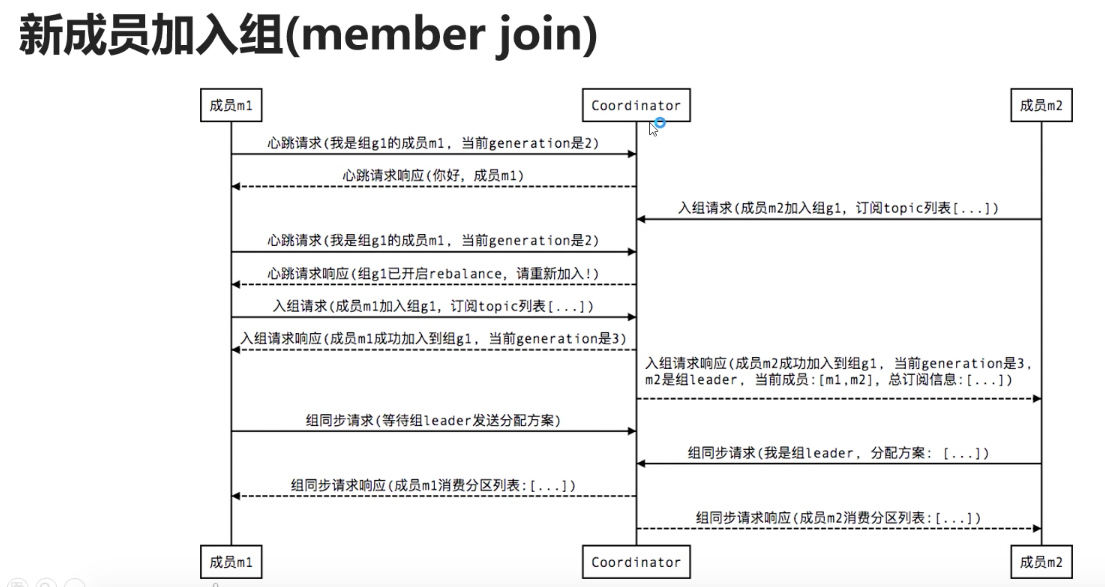
5.6.2 组成员奔溃失败
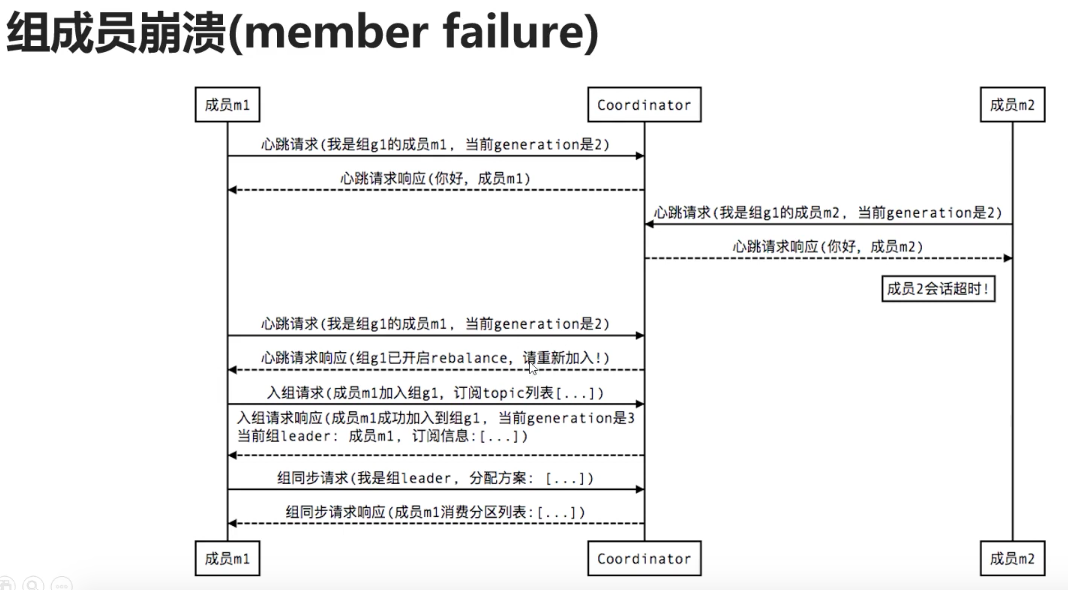
5.6.3 组成员主动离组
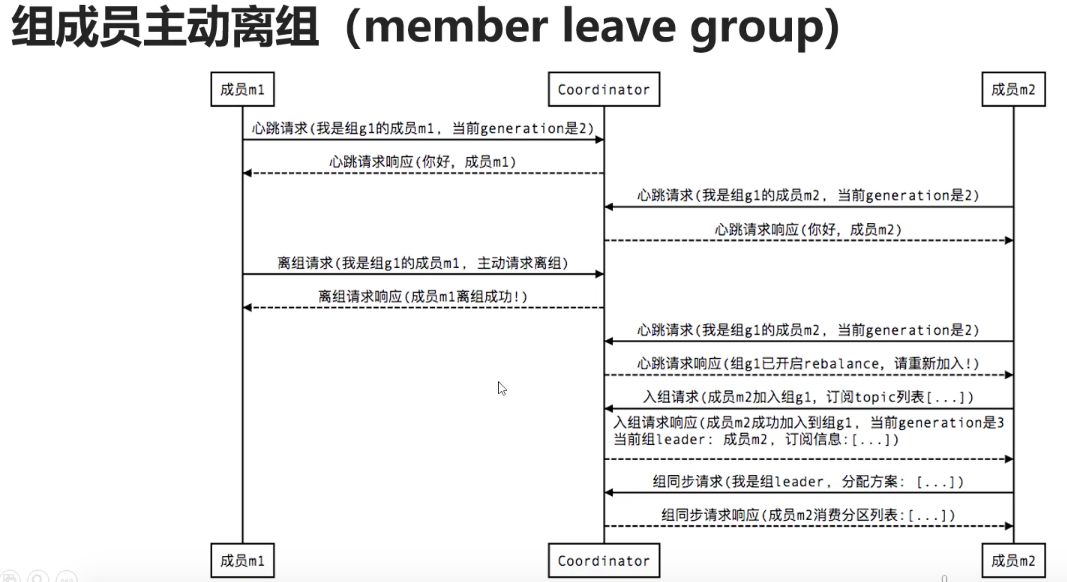
5.6.4 提交位移
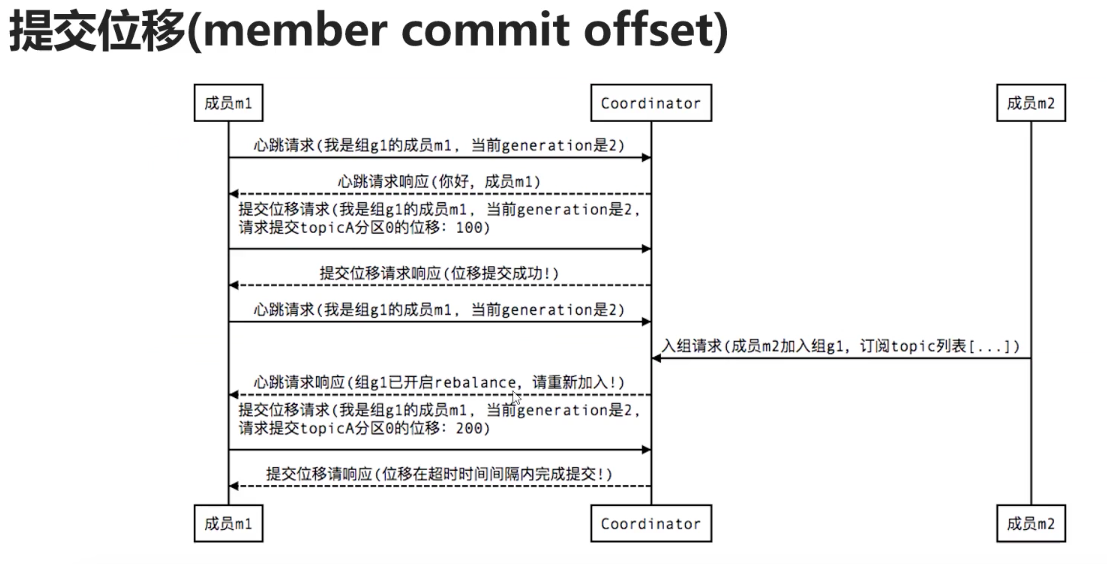
5.7 kafka限流与控制offset位置
5.7.1 kafka控制offset位置
api如下:
// 跳到指定位置 public void seek(TopicPartition partition, long offset) // 跳到指定位置 public void seek(TopicPartition partition, OffsetAndMetadata offsetAndMetadata) // 跳到起始位置 public void seekToBeginning(Collection<TopicPartition> partitions) // 跳到结束位置 public void seekToEnd(Collection<TopicPartition> partitions)
可以看到api控制offset的时候只能控制partition的位置。
代码实现如下。使用上面订阅partition的代码
/* 直接订阅topic下面的分区partition 并控制offset的位置 */ private static void manualCommitForPartitionSeekOffset(){ Properties properties = new Properties(); properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,kafkaServerIp+":9092"); properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG,"test"); // 设置自动提交为false properties.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false"); properties.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"1000"); properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String,String> consumer = new KafkaConsumer(properties); // 消费者订阅某个topic或者几个Topic // consumer.subscribe(Arrays.asList(TOPIC_NAME)); TopicPartition p0 = new TopicPartition(TOPIC_NAME,0); TopicPartition p1 = new TopicPartition(TOPIC_NAME,1); consumer.assign(Arrays.asList(p0)); while (true){ // 跳到p0分区的100 offset consumer.seek(p0,100); // 定时间隔拉取 ConsumerRecords<String,String> records = consumer.poll(Duration.ofMillis(10000)); Set<TopicPartition> partitions = records.partitions(); for (TopicPartition partition : partitions) { List<ConsumerRecord<String, String>> pRecords = records.records(partition); for (ConsumerRecord<String,String> record :pRecords){ System.out.printf("partition = %d,offset = %d, key = %s,value=%s%n " ,record.partition(),record.offset(),record.key(),record.value()); } if(true){ // 如果成功则手动提交 注意这个方法提交 Map<TopicPartition, OffsetAndMetadata> offsets = new HashMap<>(); // 参数2,获取最后一个元素的offset,然后加一就是下一次的起始位置 offsets.put(partition,new OffsetAndMetadata(pRecords.get(pRecords.size()-1).offset()+1)); consumer.commitSync(offsets); }else{ // 如果失败则回滚 } System.out.println("消费完成~~~~~~~~~~~partition "+partition.toString()+" end ~~~~~~~~~~~~~~~~"); } } }
5.7.2 kafka限流某个partition
// 停止partition public void pause(Collection<TopicPartition> partitions) // 恢复partition public void resume(Collection<TopicPartition> partitions)
这个跟线程挂起恢复类似,暂不写代码
六、kafka之Stream
kafka的stream是处理分析存储在kafka数据的客户端程序库
kafka的stream是通过state store(存储状态更能容错)可以实现高效状态操作
支持原语Processor和高层抽象DSL
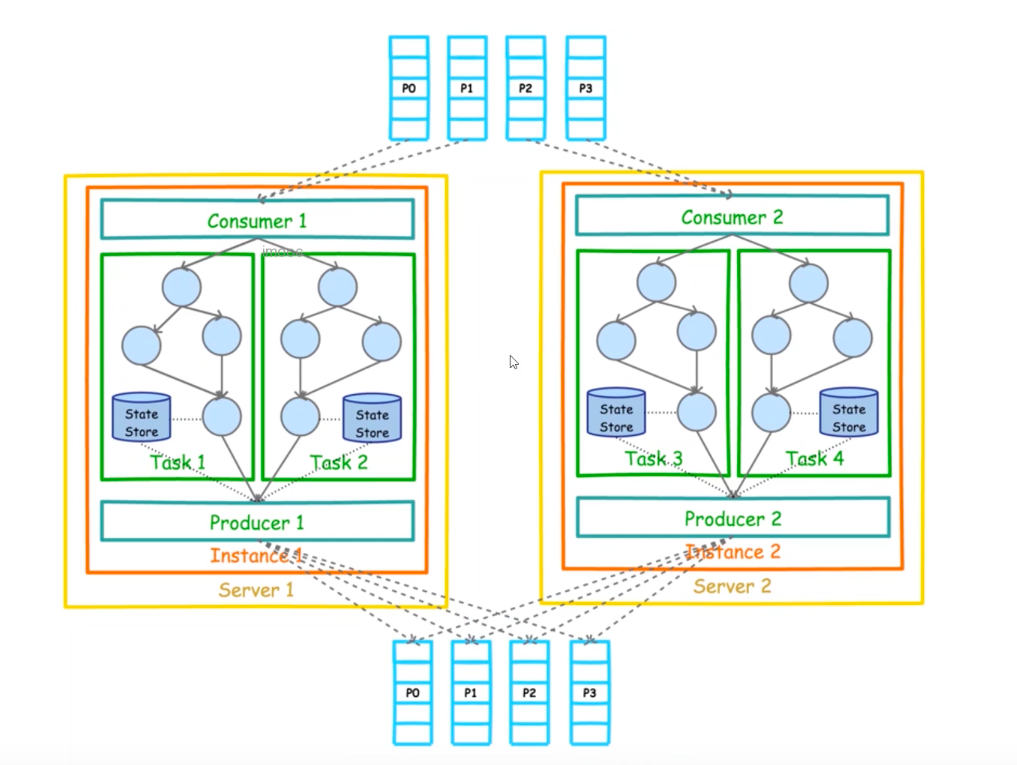
Kafka Stream关键词
- 流及流处理器
- 流处理拓扑(拓扑图)
- 源处理器及Sink处理器
流:及消息的走向如上图task中的箭头
流处理器:如上图所示每个Task中的⭕️就是流处理器及处理消息的逻辑
流处理拓扑图:从源头到结果整个处理的过程,就是流处理拓扑图,包含多个处理器
源处理器:数据的源头
Sink处理器:最终的数据结果
如下图官方文档所示:
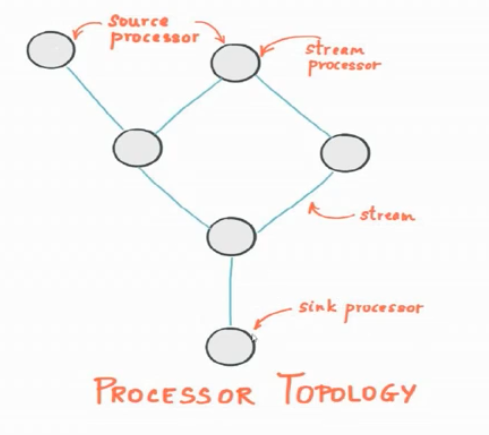
代码示例:
首先需要引入kafka-streams包
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>2.4.0</version>
</dependency>
然后创建两个新的Topic,可以使用上面的AdminClient创建(wanghao-topicIn/wanghao-topicOut)
package com.wh.springkafka.stream; import com.wh.springkafka.util.PropertyManager; import org.apache.kafka.common.serialization.Serdes; import org.apache.kafka.streams.KafkaStreams; import org.apache.kafka.streams.StreamsBuilder; import org.apache.kafka.streams.StreamsConfig; import org.apache.kafka.streams.kstream.KStream; import org.apache.kafka.streams.kstream.KTable; import org.apache.kafka.streams.kstream.Produced; import java.util.Arrays; import java.util.Locale; import java.util.Properties; public class StreamSample { public static final String TOPIC_NAME_IN = "wanghao-topicIn"; public static final String TOPIC_NAME_OUT = "wanghao-topicOut"; public static final String kafkaServerIp = PropertyManager.getProperty("KafkaZKServerIp"); public static void main(String[] args) { Properties props = new Properties(); props.setProperty(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,kafkaServerIp+":9092"); props.setProperty(StreamsConfig.APPLICATION_ID_CONFIG,"wordcount-app"); props.setProperty(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName()); props.setProperty(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName()); // 如果构建流结构拓扑 final StreamsBuilder builder = new StreamsBuilder(); // 构建Wordcount procescc wordcountStream(builder); final KafkaStreams streams = new KafkaStreams(builder.build(), props); streams.start(); } static void wordcountStream(final StreamsBuilder builder){ KStream<String,String> source = builder.stream(TOPIC_NAME_IN); // Hell World imooc KTable<String, Long> count = source .flatMapValues(value -> Arrays.asList(value.toLowerCase(Locale.getDefault()).split(" "))) .groupBy((key, value) -> value) .count(); count.toStream().to(TOPIC_NAME_OUT, Produced.with(Serdes.String(),Serdes.Long())); } }
启动如上代码,然后拷贝如下命令,打开两个窗口一个发送一个接受,代码作用是中专处理消息。
// 发送消息 bin/kafka-console-producer.sh --broker-list localhost:9092 --topic wanghao-topicIn // 接收消息 bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic wanghao-topicOut --property print.key=true --property print.value=true --property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer --property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer --from-beginning
注意第二条不能 有回车不然命令中断,有些属性未添加
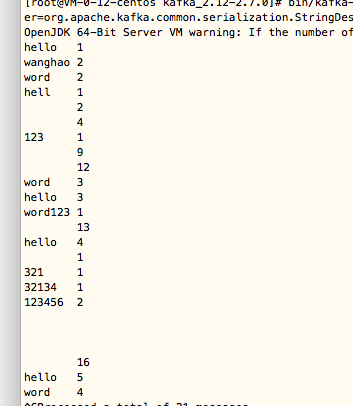
通过代码测试后发现,消息输入到Topic(wanghao-topicIn)然后被Stream接收到并处理,并发给Out,所以out就接收到了。如下所示:
七、Kafka Connect
kafka Connect是kafka流式计算的一部分
kafka Connect主要用来与其他中间件建立流式通道
kafka Connect支持流式和批量处理集成
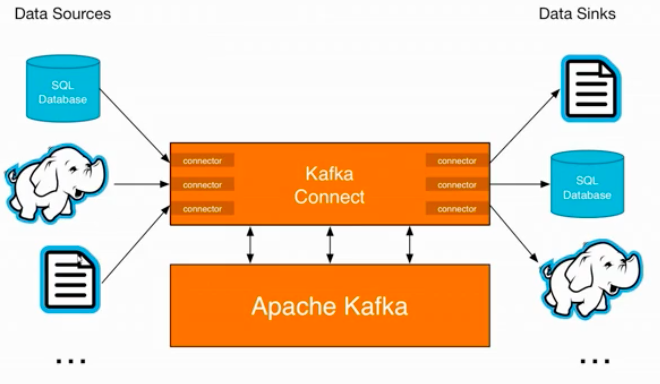
如上图所示类似桥梁或者通道一样的东西。
代码演示DataBase数据写入kafkaConnector中
首先建立一个数据库进行演示
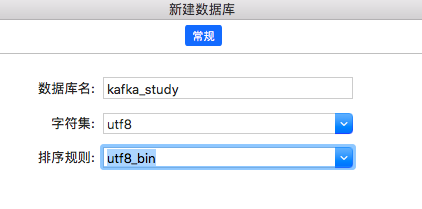
如下代码创建两个表,并给t_user插入两条数据
create table t_user( id int PRIMARY key AUTO_INCREMENT, name varchar(20), age int ); create table t_user_bak as SELECT * from t_user; INSERT INTO `kafka_study`.`t_user`( `name`, `age`) VALUES ( 'w', 1); INSERT INTO `kafka_study`.`t_user`( `name`, `age`) VALUES ( 'w2', 2);
然后到这个网站下载链接jdbc的工具
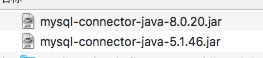
如果是mysql的话,则需要自己准备驱动包,我这里准备5*和8*的版本
然后上传到服务器,我这里上传到/opt/plugins下面,然后解压zip包如下图所示:

并把mysql驱动拷贝到confluentinc的lib目录下:
cd /opt/plugins/confluentinc-kafka-connect-jdbc-10.0.1/lib cp /opt/plugins/mysql-connector-java-*.jar ./
然后进入config目录进行配置文件修改,如下是connect的配置文件,有单机版和集群版,我们一般使用集群版
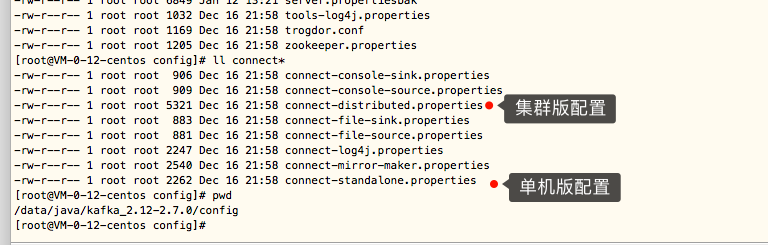
vim connect-distributed.properties
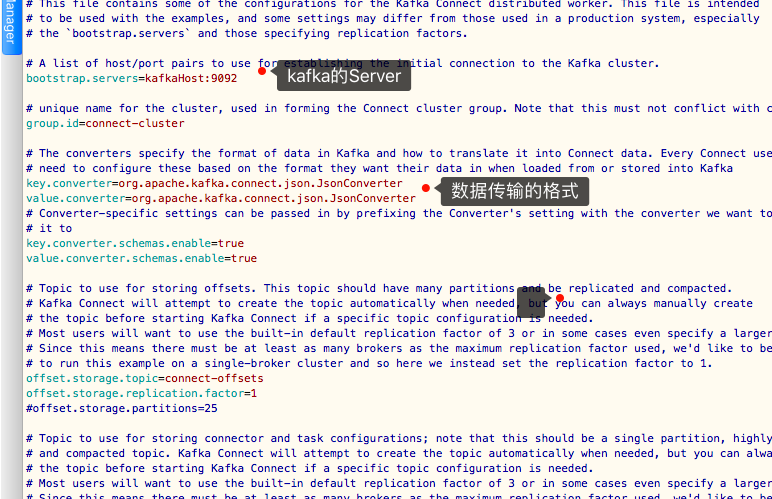
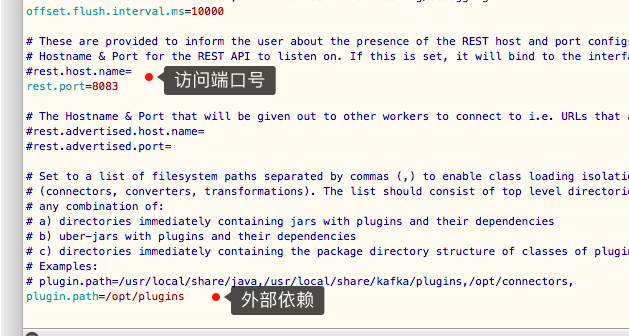
然后使用命令启动:
// 后台运行 bin/connect-distributed.sh -daemon config/connect-distributed.properties // 控制台运行 bin/connect-distributed.sh config/connect-distributed.properties
然后访问下面路径,端口为上面配置文件的端口:
http://ip:8083/connector-plugins
显示如下:

就算运行正常。
然后访问一下路径显示当前任务,
http://42.192.128.100:8083/connectors

执行下面命令添加任务:
curl -H "Content-Type: application/json" -X POST -d '{"name":"load-mysql-data","config":{"connector.class":"io.confluent.connect.jdbc.JdbcSourceConnector","connection.url":"jdbc:mysql://ip:3306/kafka_study?user=root&password=beishang886","table.whitelist":"t_user","incrementing.column.name":"id","mode":"incrementing","topic.prefix":"test-mysql-jdbc-"}}' http://ip:8083/connectors
JdbcSourceConnector一些配置说明
connection.url,mysql数据库连接
mode:timestamp && "timestamp.column.name":"login_time",表示识别根据login_time时间列来识别增量数据,一旦这一列值发生变化,就会有一天新的记录写到kafka主题
mode:incrementing && "incrementing.column.id":"id",适合还有自增列的表,一旦有新的记录入mysq,就会有新的记录写到kafka主题
topic.prefix:mysql.,表示写到kafka的主题为mysql.表名
上面语句拼接出来的topicname为:test-mysql-jdbc-t_user
然后访问上面查询任务链接显示如下,新增了一个任务:
http://42.192.128.100:8083/connectors

然后订阅这个topic,可以看到里面有我们之前插入的两条数据,转为json格式的消息存储到topic里面了

这里已经完成Source写入kafkaConnector中。
代码演示kafkaConnector写入DataBase
首先我们要创建一个任务,从kafka写入DataBase中,
curl -H "Content-Type: application/json" -X POST -d '{ "name":"load-data-mysql", "config":{ "connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector", "connection.url":"jdbc:mysql://ip:3306/kafka_study?user=root&password=beishang886", "topics":"test-mysql-jdbc-t_user", "auto.create":"false", "insert.modu":"upsert", "pk.mode":"record_value", "pk.fields":"id", "table.name.format":"t_user_bak" } }' http://ip:8083/connectors

执行任务后,返回如下:
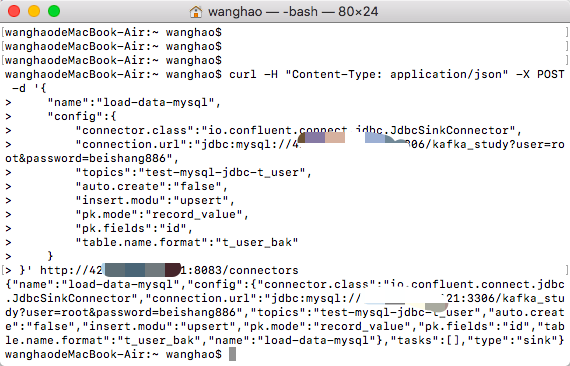
然后查看任务就多出来了一条。如下图:

然后查看数据库,已经自动插入bak表两条。
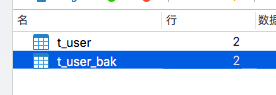
你可以重新在t_user表插入数据,然后bak会自动进行同步
到此就完成了Connect的读写,
错误汇总:
1、刚装好kafka和zk,依次启动zk和kafka
启动kafka的时候报错如下提示:
error='Cannot allocate memory' (errno=12)
该提示错误是内存不足,我使用下面命令查看占内存最大的前几个进程,杀死了两个后重新启动了
ps aux|head -1;ps aux|grep -v PID|sort -rn -k +4|head
2、kafka与zk启动成功并创建Topic,发送信息的时候报错如下:

解决办法:把localhost改为本机IP,因为是使用本机IP启动
3、发送消息之后接收消息报错如下:
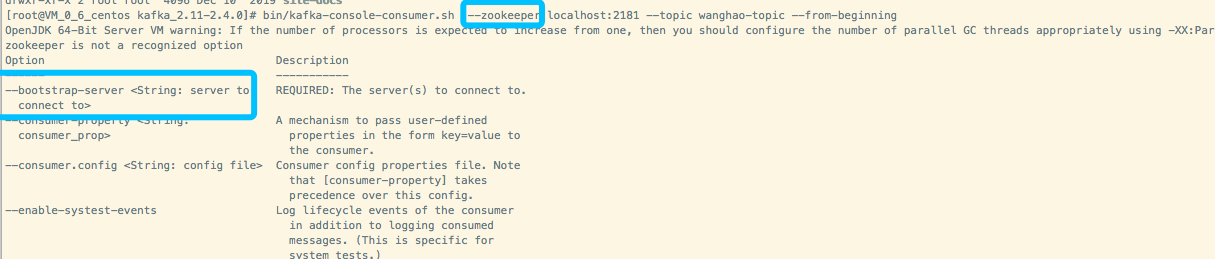
这是因为kafka版本不一样命令也不一样,根据提示修改为可识别的命令。
注意:如果使用bootstrap-server的话,则需要使用kafka的ip和端口,所以命令改为:
bin/kafka-console-consumer.sh --bootstrap-server 172.17.0.6:9092 --topic wanghao-topic --from-beginning
4、使用java链接kafka客户端的时候报错如下:
java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.TimeoutException: Timed out waiting to send the call.
Caused by: org.apache.kafka.common.errors.TimeoutException: Timed out waiting to send the call.
是因为我的服务器是内外网,kafka配置的网络与java程序链接的ip不一致。
解决方法:
服务器的kafka配置域名,然后使用host映射然后重启项目
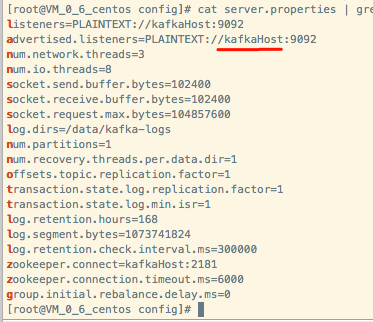
配置服务器域名ip映射,
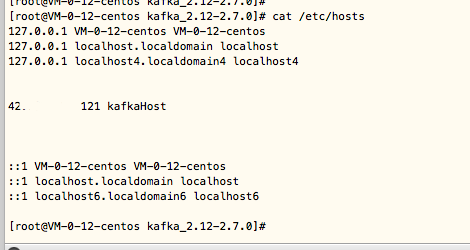
配置本机域名ip映射。
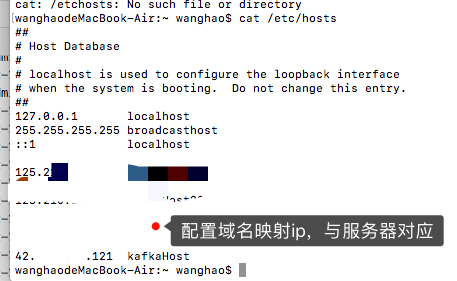
5、使用java链接kafka的显示详情的时候,出现错误如下:
org.apache.kafka.common.errors.UnknownTopicOrPartitionException: This server does not host this topic-partition
报错内容:分区数据不在
原因分析:producer向不存在的topic发送消息,用户可以检查topic是否存在 或者设置auto.create.topics.enable参数
6、使用Consumer消费消息的时候,报错如下:
java.net.ConnectException: Operation timed out
我这里故意把kafka的配置服务地址写成固定IP,因为内外网的原因两个ip不一致导致了这个问题,
解决方法同上面第四个。正常情况4解决后就不会出现这种情况,我只是测试下固定ip是否影响消费者
7、服务器没有安装jdk,启动zk报错如下:
Error: JAVA_HOME is not set and java could not be found in PATH.
TODO:测试这个例子:
网上看的到错误汇总:https://www.cnblogs.com/tree1123/p/11531524.html
kafka介绍网上,里面介绍挺全的记录下来:https://www.orchome.com/kafka/index
文章参考:https://www.cnblogs.com/darange/p/9857698.html
https://www.cnblogs.com/laoqing/p/11927958.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号