
springboot集成jpa
一、搭建jpa环境
1、首先引入jpa的依赖包
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency>
2、配置数据库及jpa
spring: jpa: hibernate: ddl-auto: update show-sql: true datasource: username: root password: beishang886 url: jdbc:mysql://localhost:3306/jpa driver-class-name: com.mysql.cj.jdbc.Driver
3、创建简单实体类
package cn.wh.springjpaTest.entity; import lombok.Data; import javax.persistence.Column; import javax.persistence.Entity; import javax.persistence.GeneratedValue; import javax.persistence.Id; @Data @Entity(name = "t_user") public class User { @Id // 表明id @GeneratedValue // 自动生成 private Integer userId; private String userName; @Column(name = "password") private String passwd; private String role; }
解释:
@Data:是lombak携带的升生成getset等方法。
@Entity:标识是个实体类,如果不用指定名字,则默认跟类名一样。
@Id :该表主键
@GeneratedValue:自增长
@Column(name = "password"):列名映射,如果名称一样则可以不写。
启动springboot项目后可以看到日志创建了序列当做自增并且列名一一对应。

到数据库查看,可以看到不是我们想要的那种MySQL自动增长模式。
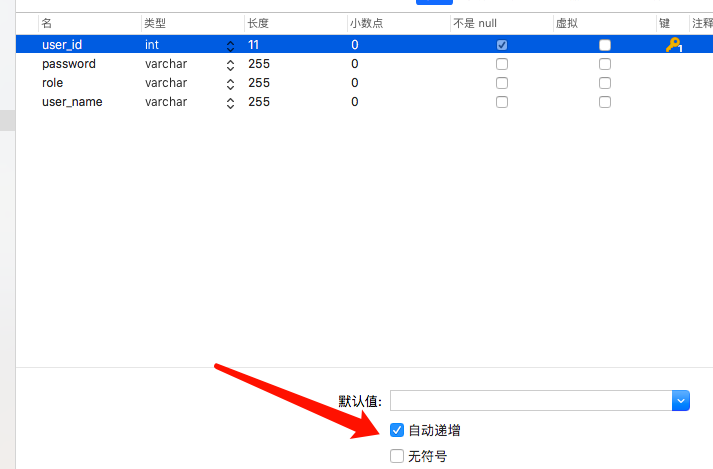
所以在id主键后面添加
strategy= GenerationType.IDENTITY
GenerationType的四种类型
TABLE:使用一个特定的数据库表格来保存主键。
SEQUENCE:根据底层数据库的序列来生成主键,条件是数据库支持序列。
IDENTITY:主键由数据库自动生成(主要是自动增长型)
AUTO:主键由程序控制。
删除之前生成的表,重新启动代码,可以看到日志只创建了表而没创建序列。

到数据库查看,使我们想要的那种MySQL自动增长。
二、初试JPA
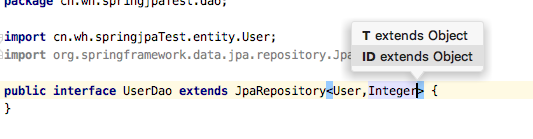
1、创建userDao
创建userDao并集成JpaRepository接口
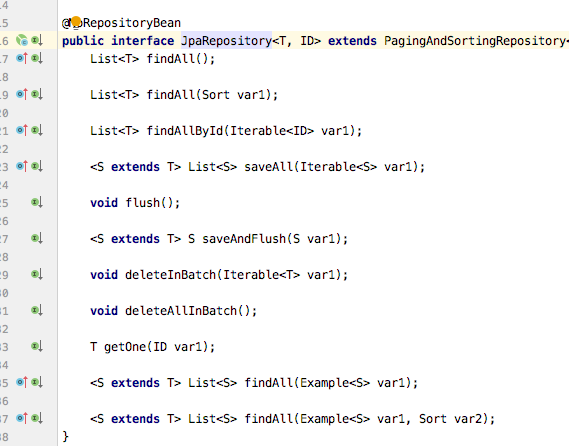
该接口已经实现了很多常用的方法,我们可以直接调取使用
2、创建Service以及创建Controller进行调用
我现在写了两个方法,一个查询一个添加
@RequestMapping("/findAll")
private List<User> findAll(){
return userService.findAll();
}
@RequestMapping("/save")
private User save(User user){
return userService.save(user);
}
3、测试调用
先进行保存调用,然后查询
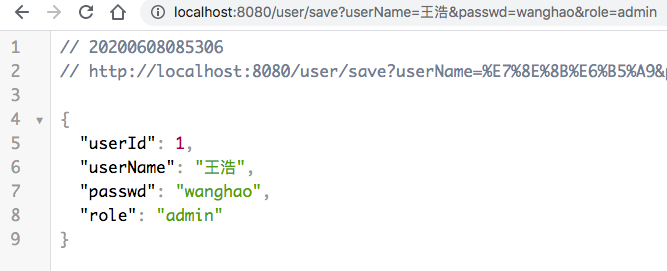

测试完成。成功调用
四、Jpa提供的四个接口
1、Repository接口 2、CrudRepository接口 3、PagingAndSortingRepository接口 4、JpaRepository接口 5、JPASpecificationExecutor接口
上面我们使用的第四个,现在依次使用
1、Repository
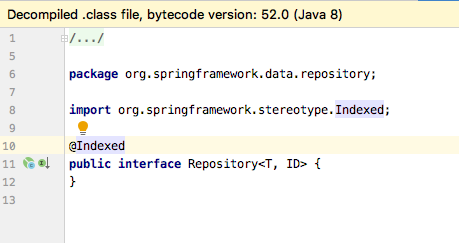
可以看到该接口没有方法。所以我们要在userDao中写需要的抽象方法
改造后的UserDao如下:
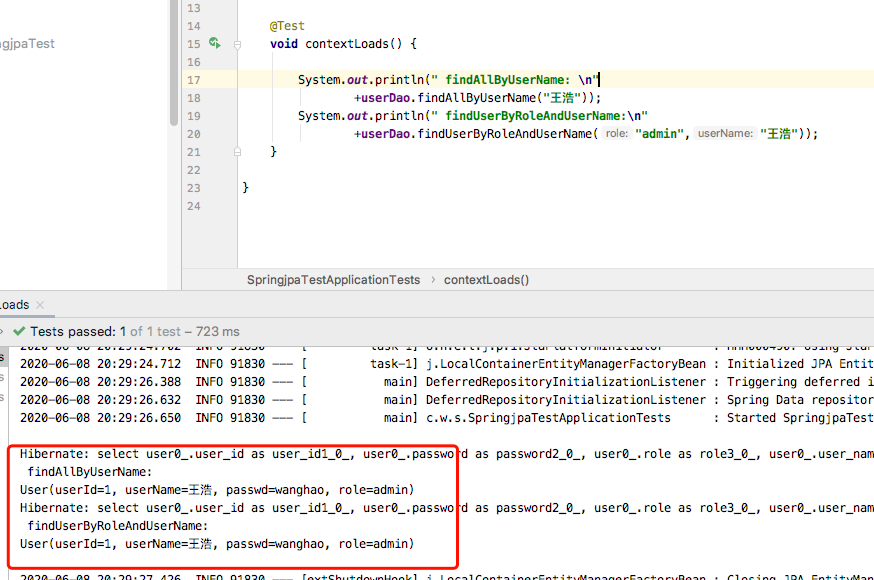
package cn.wh.springjpaTest.dao; import cn.wh.springjpaTest.entity.User; import org.springframework.data.repository.Repository; public interface UserDao extends Repository<User,Integer> { User findAllByUserName(String userName); User findUserByRoleAndUserName(String role,String userName); }
去测试类里面测试结果如下:
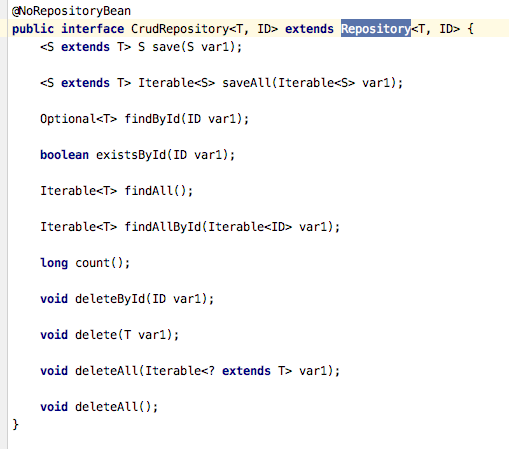
2、CrudRepository
可以看到该接口继承了Repository,主要是一些增删操作
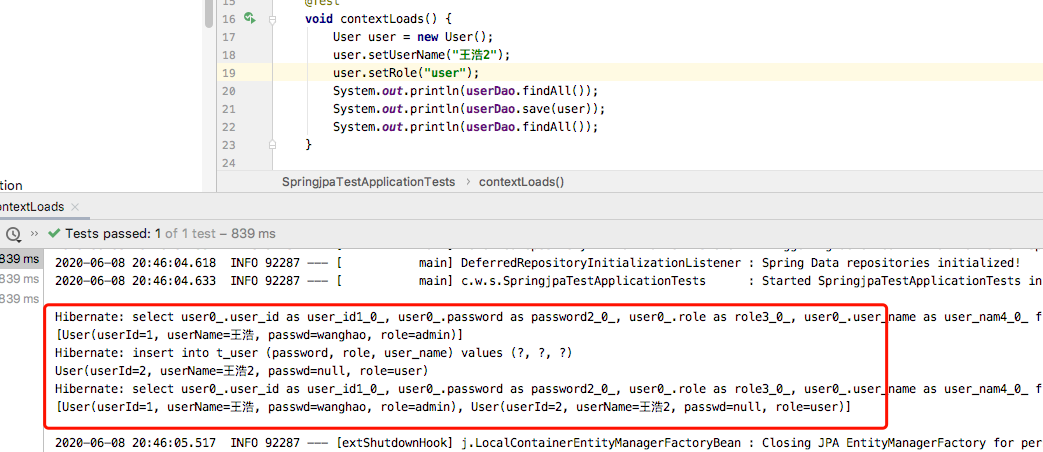
测试如下:
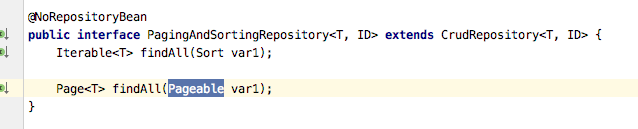
3、PagingAndSortingRepository
该接口继承了CrudRepository接口,主要用于分页和排序,如下图所示:
测试如下:
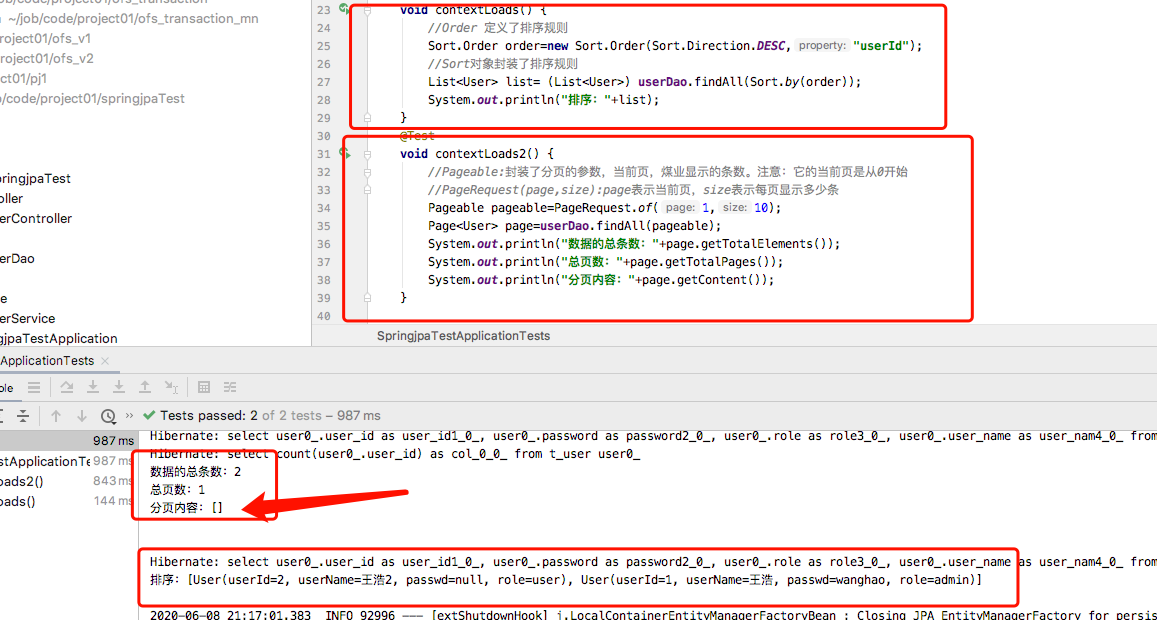
测试如上,至于为什么page.getContent 未定位出来。如果有知道原因的,麻烦说下
4、JpaRepository
这个接口也是上面使用过的接口,该接口继承了PagingAndSortingRepository。对继承的父接口中方法的返回值进行适配。
依次继承关系:
JpaRepository --> PagingAndSortingRepository --> CrudRepository --> Repository
相当于该接口包含上面所有的。
此处不再演示。
5、JpaSpecificationExecutor
该接口是独立存在的,跟其他四个接口没有联系,该接口主要是提供了多条件查询的支持,并且可以在查询中添加排序与分页。
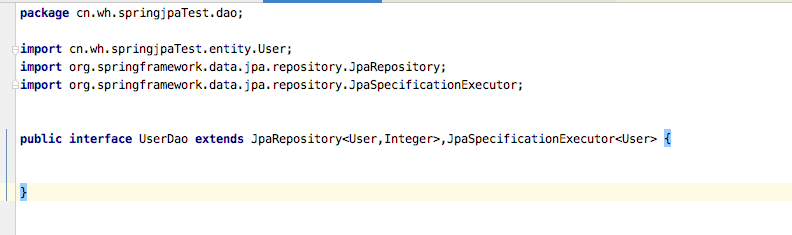
然后测试类进行调用:
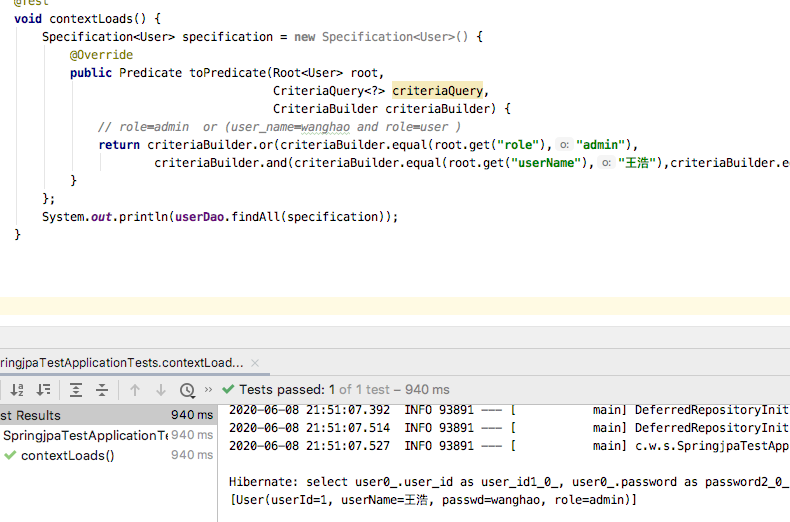
5.1 单条件查询
Specification<User> specification = new Specification<User>() { @Override public Predicate toPredicate(Root<User> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder criteriaBuilder) { return criteriaBuilder.equal(root.get("role"),"admin"); } }; System.out.println(userDao.findAll(specification));

5.2 多条件查询如下
多条件查询一、
Specification<User> specification = new Specification<User>() { @Override public Predicate toPredicate(Root<User> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder criteriaBuilder) { // role=admin or (user_name=wanghao and role=user ) return criteriaBuilder.or(criteriaBuilder.equal(root.get("role"),"admin"), criteriaBuilder.and(criteriaBuilder.equal(root.get("userName"),"王浩"),criteriaBuilder.equal(root.get("role"),"user"))); } }; System.out.println(userDao.findAll(specification));
多条件查询二、
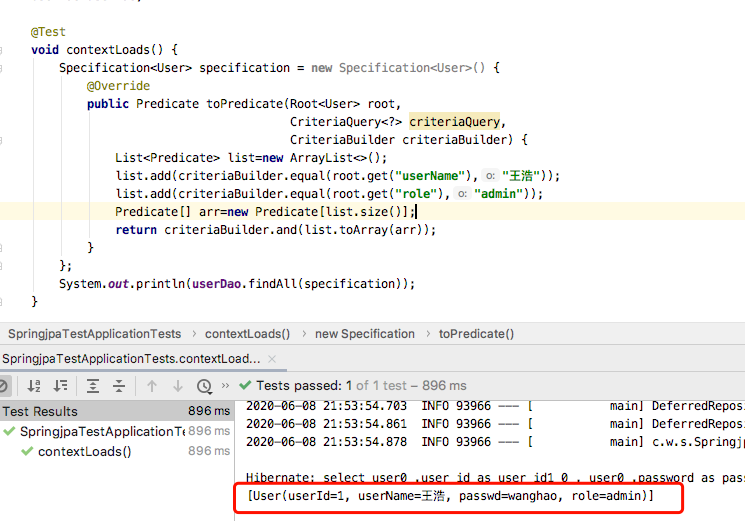
Specification<User> specification = new Specification<User>() { @Override public Predicate toPredicate(Root<User> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder criteriaBuilder) { List<Predicate> list=new ArrayList<>(); list.add(criteriaBuilder.equal(root.get("userName"),"王浩")); list.add(criteriaBuilder.equal(root.get("role"),"admin")); Predicate[] arr=new Predicate[list.size()]; return criteriaBuilder.and(list.toArray(arr)); } }; System.out.println(userDao.findAll(specification));
备注(未测试):
| 方法名 | sql中的符号 |
|---|---|
| between | between and |
| equal | = |
| gt | > |
| ge | < |
| lt | |
| le | |
| like | like |
-eq :equal(相等)
-ne :not equal(不等)
-gt :greater than(大于)
-ge :greater than or equal(大于或等于)
-lt :less than(小于)
-le :less than or equal(小于或等于)
五、jpa多表查询
1、Hibernate注解实现多表查询
1.2 多对一查询
使用注解:@ManyToOne
| 属性 | 必须 | 说明 |
| cascade |
默认情况下,JPA 不会将任何持续性操作层叠到关联的目标。 如果希望某些或所有持续性操作层叠到关联的目标,请将 cascade 设置为一个或多个 CascadeType 实例,其中包括: · ALL — 针对拥有实体执行的任何持续性操作均层叠到关联的目标。 · MERGE — 如果合并了拥有实体,则将 merge 层叠到关联的目标。 · PERSIST — 如果持久保存拥有实体,则将 persist 层叠到关联的目标。 · REFRESH — 如果刷新了拥有实体,则 refresh 为关联的层叠目标。 · REMOVE — 如果删除了拥有实体,则还删除关联的目标。 |
|
| fetch |
默认值:FetchType.EAGER。 默认情况下,JPA 持续性提供程序使用获取类型 EAGER:这将要求持续性提供程序运行时必须迫切获取数据。 如果这不适合于应用程序或特定的持久字段,请将 fetch 设置为 FetchType.LAZY:这将提示持续性提供程序在首次访问数据(如果可以)时应不急于获取数据。 |
|
| optional |
默认值:true。 默认情况下,JPA 持续性提供程序假设所有(非基元)字段和属性的值可以为空。 如果这并不适合于您的应用程序,请将 optional 设置为 false。 |
|
| targetEntity |
默认值:JPA 持续性提供程序从被引用的对象类型推断出关联的目标实体 如果持续性提供程序无法推断出目标实体的类型,则将关联拥有方上的 targetEntity 元素设置为作为关系目标的实体的 Class。 |
备注:optional=true 相当于 left join 允许返回NULL, optional=false 相当于 inner join
摘自:https://blog.csdn.net/qq_34042441/article/details/80281654 表格
下面一个测试案例,现在有用户和角色两张表。一个用户对应一个觉得,一个角色对应多个用户
首先编写Role角色实体了:
package cn.wh.springjpaTest.entity; import lombok.Data; import javax.persistence.Entity; import javax.persistence.GeneratedValue; import javax.persistence.GenerationType; import javax.persistence.Id; @Data @Entity(name = "t_role") public class Role { @Id @GeneratedValue(strategy= GenerationType.IDENTITY) private Integer Id; private String name; }
然后编写dao
package cn.wh.springjpaTest.dao; import cn.wh.springjpaTest.entity.Role; import cn.wh.springjpaTest.entity.User; import org.springframework.data.jpa.repository.JpaRepository; import org.springframework.data.jpa.repository.JpaSpecificationExecutor; public interface RoleDao extends JpaRepository<Role,Integer>,JpaSpecificationExecutor<Role> { }
参考:https://blog.csdn.net/qq_39086296/article/details/90485645
https://blog.csdn.net/qq_34042441/article/details/80281654

 浙公网安备 33010602011771号
浙公网安备 33010602011771号