
python爬取NBA资料
amazing!我不知道应该怎么去形容这东西。使用它的感觉就像是野生动物第一次尝到了血的味道!
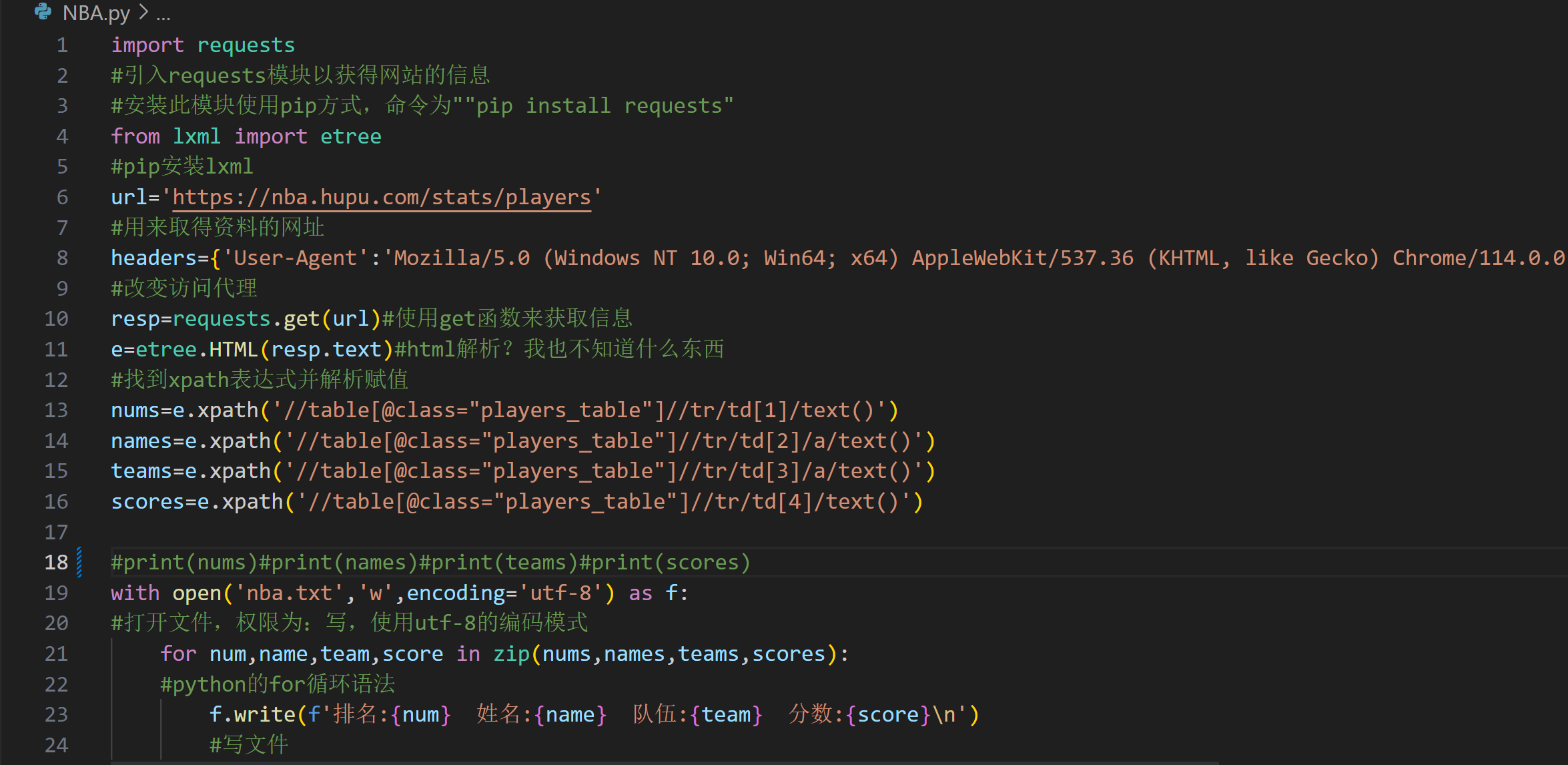
我成功用几行简单的代码实现了可用的功能,虽然很简单。
但是,一:他成功的和互联网上的一些信息进行了交互。2:他和一个本地需要环境的黑窗口比起来,泛用性相当高
我所学到的:
pip安装方式
如pip install requests
使我可以请求访问网站
xpath
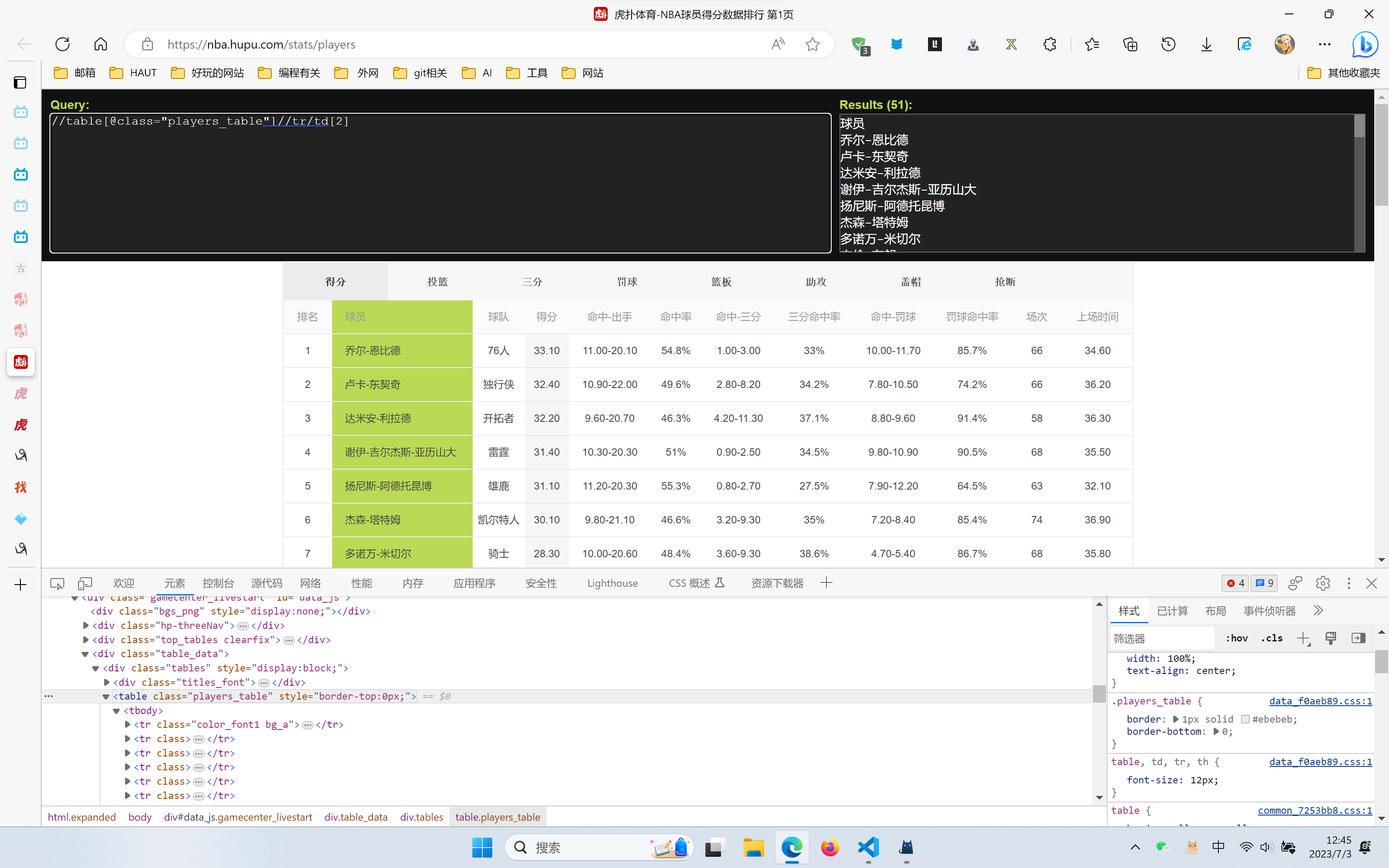
即使是我这种新手,也能再短短的时间内找到正确的xpath表达式
//table[@class="players_table"]//tr/td[2]
首先使用//开头,然后table[@class="对应元素所在"]//就像文件的地址一样,逐级找到对应的元素
xpath的安装
我到现在也没搞明白,但是我选择了xpath-help。安装方式是在github下载压缩包,解压后在edge扩展添加(需打开开发人员模式),添加解压后的文件即可。
在VS code或者什么其他的东西打开bar和content文件,更改快捷键(原快捷键与edge冲突)
这个小项目非常简单,即使加上了详细的注释也才20行左右。但真的非常好玩,能学到很多

 浙公网安备 33010602011771号
浙公网安备 33010602011771号