集合
泛型:
集合中的元素可以是任意类型的对象,如果把某个对象放入集合,则会忽略他的类型,当做Object处理。
1、泛型集合中,不能添加泛型规定的类型及其子类型以外的对象,编译期间会进行类型检查
2、泛型使用for each方法遍历集合时,不需要用Object,直接使用原类型即可
3、泛型集合中的限定类型不能使用基本数据类型,可以通过使用包装类限定允许存入的基本数据类型
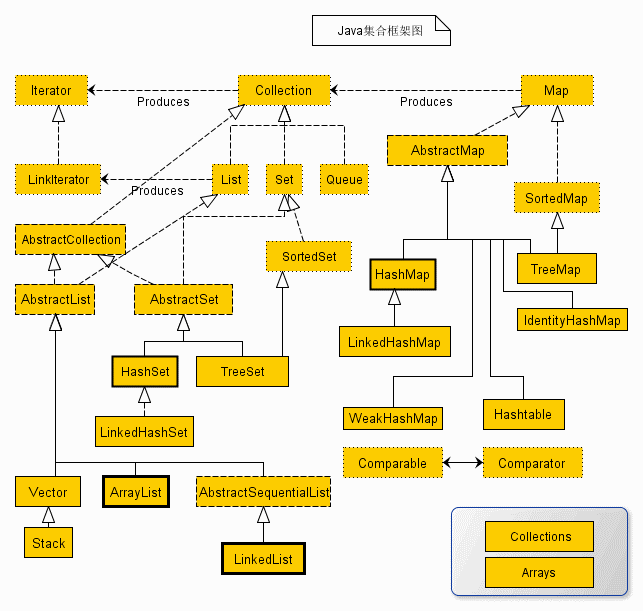
Java集合框架体系: java.util包
一、Collection是所有集合的顶层接口,所有集合的父类(List和Set是存储单列数据的集合,Map是存储键值对双列数据的集合)
-
List接口:元素有序,允许重复
①ArrayList实现类:底层数据结构是数组,查询快,增删慢,线程不安全,效率高,可以存储重复元素
②LinkedList实现类: 底层数据结构是链表,查询慢,增删快,线程不安全,效率高,可以存储重复元素
③Vector实现类:底层数据结构是数组,查询快,增删慢,线程安全,效率低,可以存储重复元素
-
Set接口:元素无序,不允许重复,元素在集合的位置由hashcode决定。同一个对象无论添加多少次,只有第一次会添加生效,可以添加null
①HashSet实现类:底层数据结构是哈希表,由HashMap实现,线程不安全
如何保证元素唯一性?-------- 依赖两个方法:hashCode() 和 equals()
②TreeSet实现类:底层数据结构是红黑树,存放有序(可排序),线程不安全
如何保证元素排序的呢?--------自然排序 比较器排序
如何保证元素唯一性? ---------根据比较的返回值是否是0来决定
③LinkedHashSet实现类:底层数据结构由链表和哈希表共同实现,线程不安全,效率高 -------由链表保证元素有序,由哈希表保证元素唯一。
3.Queue:元素有序,允许重复
二、Map下4个实现类:元素无序,键不允许重复,值允许重复。一个value可以对应多个key,一个key只能对应一个value
1.HashMap:基于hash表的map接口实现,线程不安全,高效,支持null值和null键,但只能有一个key为null,因为key不可重复
1.1.LinkedHashMap:线程不安全,是hashmap的一个子类,保存了记录的插入顺序
2.Hashtable:线程安全,低效,不支持null值和null键
3.TreeMap:线程不安全,能够把它保存的记录根据键排序,默认是键值的升序排序
三、Iterator迭代器
1.什么是迭代器?
1.1 当从集合中获取元素的时候,有一个通用的流程,将这个通用的流程描述成了一个接口,这个接口就是Iterator
2.2 通用流程:在取元素之前先要判断集合中有没有元素?
如果有,就把这个元素取出来,继续在判断,
如果还有就再取出出来。一直把集合中的所有元素全部取出。
这种取出方式专业术语称为迭代。
2.使用方式
-
Collection 接口描述了一个抽象方法 iterator 方法,所有 Collection 子类都实现了这个方法
-
iterator():返回在此collection的元素上进行迭代的迭代器
返回值是:Iterator<E>(E表示集合中的数据类型)
3. Iterator接口两个常用方法
1 .hasNext()方法
用来判断集合中是否有下一个元素可以迭代。如果返回 true,说明可以迭代。
2 .next()方法
用来返回迭代的下一个元素,并把指针向后移动一位,若集合中已经没有元素了还继续使用将报NoSuchElementException 没有集合元素的错误。
4.增强for循环
1.内部原理其实是个Iterator迭代器,所以在遍历的过程中,不能对集合中的元素进行增删操作,否则会出现并发修改异常
2.格式:for(元素的数据类型 变量名 : 被迭代的Collection 集合 or 数组){
//此时变量名代表被遍历到的数组或集合元素
}
3.如果要对数组的元素进行操作,使用老式for循环可以通过角标操作
5.补充
.length 属性:用于获取数组长度
.length()方法:用于获取字符串长度
.size()方法:用于获取泛型集合有多少个元素
List 遍历:
//方法1 集合类的通用遍历方式, 从很早的版本就有, 用迭代器迭代
Iterator it1 = list.iterator();
while(it1.hasNext()){
System.out.println(it1.next());
}
//方法2 集合类的通用遍历方式, 从很早的版本就有, 用迭代器迭代
for(Iterator it2 = list.iterator();it2.hasNext();){
System.out.println(it2.next());
}
//方法3 增强型for循环遍历
for(String value:list){
System.out.println(value);
}
//方法4 一般型for循环遍历
for(int i = 0;i < list.size(); i ++){
System.out.println(list.get(i));
}
Map遍历:
Map<Integer,String> map=new HashMap<>();
map.put(1,"美好的周一");
map.put(2,"美好的周二");
map.put(3,"美好的周三");
方法一:普通的foreach循环,使用keySet()方法,遍历key
for(Integer key:map.keySet()){
System.out.println("key:"+key+" "+"Value:"+map.get(key));
}
方法二:把所有的键值对装入迭代器中,然后遍历迭代器
Iterator<Map.Entry<Integer,String>> it=map.entrySet().iterator();
while(it.hasNext()){
Map.Entry<Integer,String> entry=it.next();
System.out.println("key:"+entry.getKey()+" "
+"Value:"+entry.getValue());
}
方法三:分别得到key和value
for(Integer obj:map.keySet()){
System.out.println("key:"+obj);
}
for(String obj:map.values()){
System.out.println("value:"+obj);
}
方法四,entrySet()方法
Set<Map.Entry<Integer,String>> entries=map.entrySet();
for (Map.Entry entry:entries){
System.out.println("key:"+entry.getKey()+" "
+"value:"+entry.getValue());
集合类原理:
ArrayList:底层就是一个Object数组,初始容量为10,每当元素要超过容量时,重新创建一个更大的数组,并把原数据拷到新数组中来
LinkedList:采用双向链表,集合中的每一个元素都会有两个成员变量prev和next,分别指向它的前一个元素和后一个元素
Vector:底层实现和ArrayList类似,区别在于在许多方法上加了synchronized关键字,来实现了多线程安全。但代价是性能的降低。由于加锁的是整个集合,所以并发情况下进行迭代会锁住很长时间。
Collection接口常见的成员方法
-
add(E e):将指定E类型的元素e添加到集合中,返回的是一个布尔类型的值
-
clear():删除此Collection中的所有元素(可选操作)
-
contains(Object o):如果此Collection包含指定的元素,则返回true(集合与元素o的比较)
-
equals(Object o) :比较此 collection 与指定对象是否相等。(通常用于两个集合对象的比较)
-
remove(Object o):从此Collection中移除指定元素的单个实例,如果存在的话(可选操作)
-
isEmpty() :如果此 collection 不包含元素,则返回 true
-
size() :返回此Collection中的元素数
-
toArray() :返回包含此Collection中所有元素的数组,返回值是一个Object类型的数组
HashMap底层原理
HashMap在JDK1.8之前的实现方式 数组+链表----结合使用就是链表散列
但是在JDK1.8之后进行了底层优化,改为数组+链表或者数值+红黑树实现,主要目的是提高查询效率

 浙公网安备 33010602011771号
浙公网安备 33010602011771号