一致性哈希
摘要
在我工作的实际项目中,有一个 xmaster 组件,负责托管所有实例的分片,线上部署了 10 个 xmaster 服务,每个服务分别托管了一部分分片,所以当我们对某一个分片进行操作时,需要知道这个分片被哪个服务节点托管,从而将该请求发送到该服务节点进行操作。
原来采用的是没有引入虚拟节点的一致性哈希,导致每个服务节点的负载不同,本次通过引入虚拟节点进行优化,从而将每个服务节点的负载打平,提高整个系统的处理能力和稳定性。
这也是我写这篇文章的一个契机。那让我们接着往下看吧。
如何分配请求
通常而言,大多数网站背后肯定不是只有一台服务器提供服务,因为单机的并发量和数据量都是有限的,所以都会用多台服务器构成集群来对外提供服务。但是问题来了,现在有那么多个服务节点,要如何分配客户端的请求呢?
其实这个问题就是「负载均衡问题」。解决负载均衡问题的算法很多,不同的负载均衡算法,对应的就是不同的分配策略,适应的业务场景也不同。
最简单的方式,引入一个中间的负载均衡层,让它将外界的请求「轮流」的转发给内部的集群。比如集群有 3 个服务节点,外界请求有 3 个,那么每个服务节点都会处理 1 个请求,达到了分配请求的目的。

考虑到每个节点的硬件配置有所区别,我们可以引入权重值,将硬件配置更好的节点的权重值设高,然后根据各个节点的权重值,按照一定比重分配在不同的节点上,让硬件配置更好的节点承担更多的请求,这种算法叫做加权轮询。
加权轮询算法使用场景是建立在每个节点存储的数据都是相同的前提。所以,每次读数据的请求,访问任意一个节点都能得到结果。但是,加权轮询算法是无法应对「分布式系统」的,因为分布式系统中,每个节点存储的数据是不同的。因此,我们要想一个能应对分布式系统的负载均衡算法。
当我们想提高系统的容量,就会将数据水平切分到不同的节点来存储,也就是将数据分布到了不同的节点。比如一个分布式 KV(key-valu) 缓存系统,某个 key 应该到哪个或者哪些服务节点上获得,应该是确定的,不是说任意访问一个节点都可以得到缓存结果的。
使用哈希算法有什么问题
我们很容易想到用哈希算法。因为对同一个关键字进行哈希计算,每次计算都是相同的值,这样就可以将某个 key 确定到一个节点了,可以满足分布式系统的负载均衡需求。
哈希算法最简单的做法就是进行取模运算,比如分布式系统中有 3 个节点,基于 hash(key) % 3 公式对数据进行了映射。
如果客户端要获取指定 key 的数据,通过下面的公式可以定位节点:
hash(key) % 3
如果经过上面这个公式计算后得到的值是 0,就说明该 key 需要去第一个节点获取。
但是有一个很致命的问题,如果节点数量发生了变化,也就是在对系统做扩容或者缩容时,必须迁移改变了映射关系的数据,否则会出现查询不到数据的问题。要解决这个问题的办法,就需要我们进行数据迁移,比如节点的数量从 3 变化为 4 时,要基于新的计算公式 hash(key) % 4 ,重新对数据和节点做映射。
假设总数据条数为 M,哈希算法在面对节点数量变化时,最坏情况下所有数据都需要迁移,所以它的数据迁移规模是 O(M),这样数据的迁移成本太高了,所以,我们应该要重新想一个新的算法,来避免分布式系统在扩容或者缩容时,发生过多的数据迁移。
使用一致性哈希有什么问题
一致性哈希算法就很好地解决了分布式系统在扩容或者缩容时,发生过多的数据迁移的问题。
一致哈希算法也用了取模运算,但与哈希算法不同的是,哈希算法是对节点的数量进行取模运算,而一致哈希算法是对 2^32 进行取模运算,是一个固定的值。
我们可以把一致哈希算法是对 2^32 进行取模运算的结果值组织成一个圆环,就像钟表一样,钟表的圆可以理解成由 60 个点组成的圆,而此处我们把这个圆想象成由 2^32 个点组成的圆,这个圆环被称为哈希环,如下图:

一致性哈希要进行两步哈希:
- 对存储节点进行哈希计算,比如根据节点的 IP 地址进行哈希。
- 对数据进行存储或访问时,对数据进行哈希映射;
所以,一致性哈希是指将「存储节点」和「数据」都映射到一个首尾相连的哈希环上。
问题来了,对「数据」进行哈希映射得到一个结果要怎么找到存储该数据的节点呢?答案是,映射的结果值往顺时针的方向的找到第一个节点,就是存储该数据的节点。
比如,下图中的 k1 映射的位置,往顺时针的方向找到第一个节点就是节点 A。

所以,当需要对指定 key 的值进行读写的时候,要通过下面 2 步进行寻址:
- 对 key 进行哈希计算,确定此 key 在环上的位置。
- 从这个位置沿着顺时针方向走,遇到的第一节点就是存储 key 的节点。
知道了一致哈希寻址的方式,我们来看看,如果增加一个节点或者减少一个节点会发生大量的数据迁移吗?
假设节点数量从 3 增加到了 4,新的节点 D 经过哈希计算后映射到了下图中的位置:

可以看到,k1、k3 都不受影响,只有 k2 需要被迁移节点 D。
假设节点数量从 3 减少到了 2,比如将节点 A 移除:

可以看到,k2 和 k3 不会受到影响,只有 k1 需要被迁移节点 B。
因此,在一致哈希算法中,如果增加或者移除一个节点,仅影响该节点在哈希环上顺时针相邻的后继节点,其它数据也不会受到影响。
上面这些图中 3 个节点映射在哈希环还是比较分散的,所以看起来请求都会「均衡」到每个节点。但是一致性哈希算法并不保证节点能够在哈希环上分布均匀,这样就会带来一个问题,会有大量的请求集中在一个节点上。
比如,下图中 3 个节点的映射位置都在哈希环的右半边:

这时候有一半以上的数据的寻址都会找节点 A,也就是访问请求主要集中的节点 A 上,这肯定不行的呀,说好的负载均衡呢,这种情况一点都不均衡。
另外,在这种节点分布不均匀的情况下,进行容灾与扩容时,哈希环上的相邻节点容易受到过大影响,容易发生雪崩式的连锁反应。
上图中如果节点 A 被移除了,当节点 A 宕机后,根据一致性哈希算法的规则,其上数据应该全部迁移到相邻的节点 B 上,这样,节点 B 的数据量、访问量都会迅速增加很多倍,一旦新增的压力超过了节点 B 的处理能力上限,就会导致节点 B 崩溃,进而形成雪崩式的连锁反应。
所以,一致性哈希算法虽然减少了数据迁移量,但是存在节点分布不均匀的问题。
如何通过引入虚拟节点提高均衡度
要想解决节点能在哈希环上分配不均匀的问题,就是要有大量的节点,节点数越多,哈希环上的节点分布的就越均匀。但问题是,实际中我们没有那么多节点。所以这个时候我们就加入虚拟节点,也就是对一个真实节点做多个副本。
具体做法是,不再将真实节点映射到哈希环上,而是将虚拟节点映射到哈希环上,并将虚拟节点映射到实际节点,所以这里有「两层」映射关系。
比如对每个节点分别设置 3 个虚拟节点:
- 对节点 A 加上编号来作为虚拟节点:A-01、A-02、A-03
- 对节点 B 加上编号来作为虚拟节点:B-01、B-02、B-03
- 对节点 C 加上编号来作为虚拟节点:C-01、C-02、C-03
引入虚拟节点后,原本哈希环上只有 3 个节点的情况,就会变成有 9 个虚拟节点映射到哈希环上,哈希环上的节点数量多了 3 倍。

可以看到,节点数量多了后,节点在哈希环上的分布就相对均匀了。这时候,如果有访问请求寻址到「A-01」这个虚拟节点,接着再通过「A-01」虚拟节点找到真实节点 A,这样请求就能访问到真实节点 A 了。
另外,虚拟节点除了会提高节点的均衡度,还会提高系统的稳定性。当节点变化时,会有不同的节点共同分担系统的变化,因此稳定性更高。
当某个节点被移除时,对应该节点的多个虚拟节点均会移除,而这些虚拟节点按顺时针方向的下一个虚拟节点,可能会对应不同的真实节点,即这些不同的真实节点共同分担了节点变化导致的压力。而且,有了虚拟节点后,还可以为硬件配置更好的节点增加权重,比如对权重更高的节点增加更多的虚拟机节点即可。
因此,带虚拟节点的一致性哈希方法不仅适合硬件配置不同的节点的场景,而且适合节点规模会发生变化的场景。
具体实现
在具体实现的过程中,我们需要选取合适的数据结构,并且对其中存在的一些问题进行分析,最后给出了一个实现示例。
数据结构的选取
- 排序 + List
我想到的第一种思路是:算出所有待加入数据结构的节点名称的Hash值放入一个数组中,然后使用某种排序算法将其从小到大进行排序,最后将排序后的数据放入List中,采用List而不是数组是为了结点的扩展考虑。
之后,待路由的结点,只需要在List中找到第一个Hash值比它大的服务器节点就可以了,比如服务器节点的Hash值是[0,2,4,6,8,10],带路由的结点是7,只需要找到第一个比7大的整数,也就是8,就是我们最终需要路由过去的服务器节点。
时间复杂度:O(N)
- 二叉查找树
当然我们不能简单地使用二叉查找树,因为可能出现不平衡的情况。平衡二叉查找树有AVL树、红黑树等,这里使用红黑树,选用红黑树的原因有两点:
- 红黑树主要的作用是用于存储有序的数据,并且不会频繁进行平衡度的调整。
- JDK里面提供了红黑树的代码实现TreeMap,提供了 tailMap(K fromKey)方法,支持从红黑树中查找比fromKey大的值的集合,但并不需要遍历整个数据结构。当然其它语言也有支对应的操作。
使用红黑树,可以使得查找的时间复杂度降低为O(logN),比上面两种解决方案,效率大大提升。并且插入删除的复杂度也为O(logN)。
哈希值的重新计算
服务器节点我们肯定用字符串来表示,比如”192.168.1.1″、”192.168.1.2″,根据字符串得到其Hash值,那么另外一个重要的问题就是Hash值要重新计算,这个问题是我在测试String的hashCode()方法的时候发现的,不妨来看一下为什么要重新计算Hash值:
/**
* String的hashCode()方法运算结果查看
*
*/
public class StringHashCodeTest {
public static void main(String[] args) {
System.out.println("192.168.0.0:111的哈希值:" + "192.168.0.0:1111".hashCode());
System.out.println("192.168.0.1:111的哈希值:" + "192.168.0.1:1111".hashCode());
System.out.println("192.168.0.2:111的哈希值:" + "192.168.0.2:1111".hashCode());
System.out.println("192.168.0.3:111的哈希值:" + "192.168.0.3:1111".hashCode());
System.out.println("192.168.0.4:111的哈希值:" + "192.168.0.4:1111".hashCode());
}
}
192.168.0.0:111的哈希值:1845870087
192.168.0.1:111的哈希值:1874499238
192.168.0.2:111的哈希值:1903128389
192.168.0.3:111的哈希值:1931757540
192.168.0.4:111的哈希值:1960386691
这个就问题大了,[0,2^32-1] 的区间之中,5个 HashCode 值却只分布在这么小小的一个区间,什么概念?[0,2^32-1] 中有 4294967296 个数字,而我们的区间只有122516605,从概率学上讲这将导致 97% 待路由的服务器都被路由到 ”192.168.0.0″ 这个集群点上,简直是糟糕透了!
另外还有一个不好的地方:规定的区间是非负数,String的hashCode()方法却会产生负数(不信用”192.168.1.0:1111″试试看就知道了)。不过这个问题好解决,取绝对值就是一种解决的办法。
综上,String重写的hashCode()方法在一致性Hash算法中没有任何实用价值,得找个算法重新计算HashCode。这种重新计算Hash值的算法有很多,比如CRC32_HASH、FNV1_32_HASH、KETAMA_HASH等,其中KETAMA_HASH是默认的MemCache推荐的一致性Hash算法,用别的Hash算法也可以,比如FNV1_32_HASH算法的计算效率就会高一些。
代码实现示例
一般情况下,服务节点越多,我们需要引入的虚拟节点数量就越少,具体如下图所示:
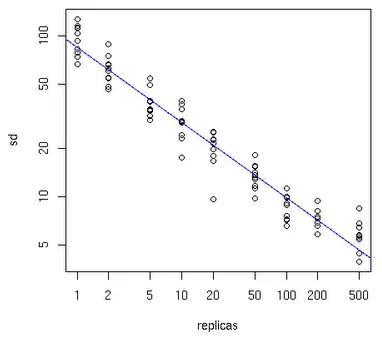
横坐标表示需要引入的虚拟节点数量,纵坐标表示物理节点数量。当我们有 10 个服务节点时,大概需要 100-200 个虚拟节点。当然,如果你是将虚拟节点存储到 红黑树中,你也许需要关注物理内存的使用情况,毕竟虚拟节点越多,占用的内存量越大。
/**
* 带虚拟结点的一致性Hash算法
*
*
*/
public class ConsistentHashWithVN {
/**
* 待加入Hash环的服务器列表
*/
private static String[] servers = { "192.168.0.0:111", "192.168.0.1:111", "192.168.0.2:111", "192.168.0.3:111",
"192.168.0.4:111" };
/**
* 真实结点列表,考虑到服务器上线、下线的场景,即添加、删除的场景会比较频繁,这里使用LinkedList会更好
*/
private static List<String> realNodes = new LinkedList<>();
/**
* key表示虚拟结点服务器的hash值,value表示虚拟结点服务器的名称
*/
private static SortedMap<Integer, String> virtualNodes = new TreeMap<>();
/**
* 虚拟结点数目(一个真实结点对应VN_SUM个虚拟结点)
*/
private static final int VN_SUM = 5;
/**
* 加所有服务器加入集合
*/
static {
for (int i = 0; i < servers.length; i++) {
realNodes.add(servers[i]);
}
for (String str : realNodes) {
for (int i = 0; i < VN_SUM; i++) {
String virtualNodeName = str + "&VN" + String.valueOf(i);
int hash = getHash(virtualNodeName);
System.out.println("虚拟节点[" + virtualNodeName + "]被添加, hash值为" + hash);
virtualNodes.put(hash, virtualNodeName);
}
}
System.out.println("\n===========路由映射==============\n");
}
/**
* 使用FNV1_32_HASH算法计算hash值
*
* @param str
* @return
*/
private static int getHash(String str) {
final int p = 16777619;
int hash = (int) 2166136261L;
for (int i = 0; i < str.length(); i++) {
hash = (hash ^ str.charAt(i)) * p;
}
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
// 如果算出来的值为负数则取其绝对值
if (hash < 0)
hash = Math.abs(hash);
return hash;
}
private static String matchServer(String node) {
// 待路由结点的Hash值
int hash = getHash(node);
// 得到大于该Hash值的子Map
SortedMap<Integer, String> subMap = virtualNodes.tailMap(hash);
// 顺时针的第一个Key
Integer i = subMap.firstKey();
// 截取
String virtualNode = subMap.get(i);
// 返回路由到的服务器名称
return virtualNode.substring(0, virtualNode.indexOf("&"));
}
public static void main(String[] args) {
String[] nodes = { "127.0.0.1:1111", "221.226.0.1:2222", "10.211.0.1:3333", "112.74.15.218:80" };
for (int i = 0; i < nodes.length; i++) {
System.out.println(
"[" + nodes[i] + "]的hash值为" + getHash(nodes[i]) + ",被路由到的服务器为[" + matchServer(nodes[i]) + "]");
}
}
}
总结
- 为了解决扩缩容大量数据需要搬迁的情况,引入了一致性哈希。
- 为了解决一致性哈希负载不均的问题,引入了虚拟节点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号