Django中ORM介绍和字段及字段参数
ORM介绍
ORM概念
对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术。
简单的说,ORM是通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到关系数据库中。
ORM在业务逻辑层和数据库层之间充当了桥梁的作用。
ORM由来
让我们从O/R开始。字母O起源于"对象"(Object),而R则来自于"关系"(Relational)。
几乎所有的软件开发过程中都会涉及到对象和关系数据库。在用户层面和业务逻辑层面,我们是面向对象的。当对象的信息发生变化的时候,我们就需要把对象的信息保存在关系数据库中。
按照之前的方式来进行开发就会出现程序员会在自己的业务逻辑代码中夹杂很多SQL语句用来增加、读取、修改、删除相关数据,而这些代码通常都是重复的。
ORM的优势
ORM解决的主要问题是对象和关系的映射。它通常把一个类和一个表一一对应,类的每个实例对应表中的一条记录,类的每个属性对应表中的每个字段。
ORM提供了对数据库的映射,不用直接编写SQL代码,只需像操作对象一样从数据库操作数据。
让软件开发人员专注于业务逻辑的处理,提高了开发效率。
ORM的劣势
ORM的缺点是会在一定程度上牺牲程序的执行效率。
ORM用多了SQL语句就不会写了,关系数据库相关技能退化...
ORM总结
ORM只是一种工具,工具确实能解决一些重复,简单的劳动。这是不可否认的。
但我们不能指望某个工具能一劳永逸地解决所有问题,一些特殊问题还是需要特殊处理的。
但是在整个软件开发过程中需要特殊处理的情况应该都是很少的,否则所谓的工具也就失去了它存在的意义。
Django中的ORM
Django项目使用MySQL数据库
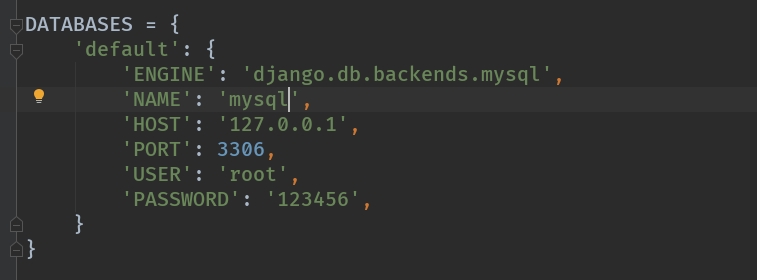
1. 在Django项目的settings.py文件中,配置数据库连接信息:
DATABASES = {
"default": {
"ENGINE": "django.db.backends.mysql",
"NAME": "你的数据库名称", # 需要自己手动创建数据库
"USER": "数据库用户名",
"PASSWORD": "数据库密码",
"HOST": "数据库IP",
"POST": 3306
}
}
2. 在Django项目的__init__.py文件中写如下代码,告诉Django使用pymysql模块连接MySQL数据库:
import pymysql pymysql.install_as_MySQLdb()

Model
在Django中model是你数据的单一、明确的信息来源。它包含了你存储的数据的重要字段和行为。通常,一个模型(model)映射到一个数据库表,
基本情况:
- 每个模型都是一个Python类,它是django.db.models.Model的子类。
- 模型的每个属性都代表一个数据库字段。
- Django为我们提供了一个自动生成的数据库访问API,详询官方文档链接。

快速入门
下面这个例子定义了一个 Person 模型,包含 first_name 和 last_name。
from django.db import models
class Person(models.Model):
first_name = models.CharField(max_length=30)
last_name = models.CharField(max_length=30)
first_name 和 last_name 是模型的字段。每个字段被指定为一个类属性,每个属性映射到一个数据库列。
上面的 Person 模型将会像这样创建一个数据库表:
CREATE TABLE myapp_person (
"id" serial NOT NULL PRIMARY KEY,
"first_name" varchar(30) NOT NULL,
"last_name" varchar(30) NOT NULL
);
一些说明:
- 表myapp_person的名称是自动生成的,如果你要自定义表名,需要在model的Meta类中指定 db_table 参数,强烈建议使用小写表名,特别是使用MySQL作为后端数据库时。
- id字段是自动添加的,如果你想要指定自定义主键,只需在其中一个字段中指定 primary_key=True 即可。如果Django发现你已经明确地设置了Field.primary_key,它将不会添加自动ID列。
- 本示例中的CREATE TABLE SQL使用PostgreSQL语法进行格式化,但值得注意的是,Django会根据配置文件中指定的数据库后端类型来生成相应的SQL语句。
- Django支持MySQL5.5及更高版本。
Django ORM 常用字段和参数
常用字段
AutoField
int自增列,必须填入参数 primary_key=True。当model中如果没有自增列,则自动会创建一个列名为id的列。
IntegerField
一个整数类型,范围在 -2147483648 to 2147483647。
CharField
字符类型,必须提供max_length参数, max_length表示字符长度。
DateField
日期字段,日期格式 YYYY-MM-DD,相当于Python中的datetime.date()实例。
DateTimeField
日期时间字段,格式 YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ],相当于Python中的datetime.datetime()实例。
自定义字段(稍微知道点就好)
class UnsignedIntegerField(models.IntegerField):
def db_type(self, connection):
return 'integer UNSIGNED'
自定义char类型字段:
class FixedCharField(models.Field):
"""
自定义的char类型的字段类
"""
def __init__(self, max_length, *args, **kwargs):
super().__init__(max_length=max_length, *args, **kwargs)
self.length = max_length
def db_type(self, connection):
"""
限定生成数据库表的字段类型为char,长度为length指定的值
"""
return 'char(%s)' % self.length
class Class(models.Model):
id = models.AutoField(primary_key=True)
title = models.CharField(max_length=25)
# 使用上面自定义的char类型的字段
cname = FixedCharField(max_length=25)
创建的表结构:

字段参数
null
用于表示某个字段可以为空。
unique
如果设置为unique=True 则该字段在此表中必须是唯一的 。
db_index
如果db_index=True 则代表着为此字段设置数据库索引。
default
为该字段设置默认值。
时间字段独有
DatetimeField、DateField、TimeField这个三个时间字段,都可以设置如下属性。
auto_now_add
配置auto_now_add=True,创建数据记录的时候会把当前时间添加到数据库。
auto_now
配置上auto_now=True,每次更新数据记录的时候会更新该字段。
关系字段
ForeignKey
外键类型在ORM中用来表示外键关联关系,一般把ForeignKey字段设置在 '一对多'中'多'的一方。
ForeignKey可以和其他表做关联关系同时也可以和自身做关联关系。
字段参数
to
设置要关联的表
to_field
设置要关联的表的字段
related_name
反向操作时,使用的字段名,用于代替原反向查询时的'表名_set'。
例如:
class Classes(models.Model):
name = models.CharField(max_length=32)
class Student(models.Model):
name = models.CharField(max_length=32)
theclass = models.ForeignKey(to="Classes")
当我们要查询某个班级关联的所有学生(反向查询)时,我们会这么写:
models.Classes.objects.first().student_set.all()
当我们在ForeignKey字段中添加了参数 related_name 后,
class Student(models.Model):
name = models.CharField(max_length=32)
theclass = models.ForeignKey(to="Classes", related_name="students")
当我们要查询某个班级关联的所有学生(反向查询)时,我们会这么写:
models.Classes.objects.first().students.all()
related_query_name
反向查询操作时,使用的连接前缀,用于替换表名。
on_delete
当删除关联表中的数据时,当前表与其关联的行的行为。
models.CASCADE
删除关联数据,与之关联也删除
models.DO_NOTHING
删除关联数据,引发错误IntegrityError
models.PROTECT
删除关联数据,引发错误ProtectedError
models.SET_NULL
删除关联数据,与之关联的值设置为null(前提FK字段需要设置为可空)
models.SET_DEFAULT
删除关联数据,与之关联的值设置为默认值(前提FK字段需要设置默认值)
models.SET
删除关联数据,
a. 与之关联的值设置为指定值,设置:models.SET(值)
b. 与之关联的值设置为可执行对象的返回值,设置:models.SET(可执行对象)
def func():
return 10
class MyModel(models.Model):
user = models.ForeignKey(
to="User",
to_field="id",
on_delete=models.SET(func)
)
db_constraint
是否在数据库中创建外键约束,默认为True。
OneToOneField
一对一字段。
通常一对一字段用来扩展已有字段。
示例
一对一的关联关系多用在当一张表的不同字段查询频次差距过大的情况下,将本可以存储在一张表的字段拆开放置在两张表中,然后将两张表建立一对一的关联关系。
class Author(models.Model):
name = models.CharField(max_length=32)
info = models.OneToOneField(to='AuthorInfo')
class AuthorInfo(models.Model):
phone = models.CharField(max_length=11)
email = models.EmailField()
字段参数
to
设置要关联的表。
to_field
设置要关联的字段。
on_delete
同ForeignKey字段。
ManyToManyField
用于表示多对多的关联关系。在数据库中通过第三张表来建立关联关系。
字段参数
to
设置要关联的表
related_name
同ForeignKey字段。
related_query_name
同ForeignKey字段。
symmetrical
仅用于多对多自关联时,指定内部是否创建反向操作的字段。默认为True。
举个例子:
class Person(models.Model):
name = models.CharField(max_length=16)
friends = models.ManyToManyField("self")
此时,person对象就没有person_set属性。
class Person(models.Model):
name = models.CharField(max_length=16)
friends = models.ManyToManyField("self", symmetrical=False)
此时,person对象现在就可以使用person_set属性进行反向查询。
through
在使用ManyToManyField字段时,Django将自动生成一张表来管理多对多的关联关系。
但我们也可以手动创建第三张表来管理多对多关系,此时就需要通过through来指定第三张表的表名。
through_fields
设置关联的字段。
db_table
默认创建第三张表时,数据库中表的名称。
多对多关联关系的三种方式
方式一:自行创建第三张表
class Book(models.Model):
title = models.CharField(max_length=32, verbose_name="书名")
class Author(models.Model):
name = models.CharField(max_length=32, verbose_name="作者姓名")
# 自己创建第三张表,分别通过外键关联书和作者
class Author2Book(models.Model):
author = models.ForeignKey(to="Author")
book = models.ForeignKey(to="Book")
class Meta:
unique_together = ("author", "book")
方式二:通过ManyToManyField自动创建第三张表
class Book(models.Model):
title = models.CharField(max_length=32, verbose_name="书名")
# 通过ORM自带的ManyToManyField自动创建第三张表
class Author(models.Model):
name = models.CharField(max_length=32, verbose_name="作者姓名")
books = models.ManyToManyField(to="Book", related_name="authors")
方式三:设置ManyTomanyField并指定自行创建的第三张表
class Book(models.Model):
title = models.CharField(max_length=32, verbose_name="书名")
# 自己创建第三张表,并通过ManyToManyField指定关联
class Author(models.Model):
name = models.CharField(max_length=32, verbose_name="作者姓名")
books = models.ManyToManyField(to="Book", through="Author2Book", through_fields=("author", "book"))
# through_fields接受一个2元组('field1','field2'):
# 其中field1是定义ManyToManyField的模型外键的名(author),field2是关联目标模型(book)的外键名。
class Author2Book(models.Model):
author = models.ForeignKey(to="Author")
book = models.ForeignKey(to="Book")
class Meta:
unique_together = ("author", "book")
注意:
当我们需要在第三张关系表中存储额外的字段时,就要使用第三种方式。
但是当我们使用第三种方式创建多对多关联关系时,就无法使用set、add、remove、clear方法来管理多对多的关系了,需要通过第三张表的model来管理多对多关系。
元信息
ORM对应的类里面包含另一个Meta类,而Meta类封装了一些数据库的信息。主要字段如下:
db_table
ORM在数据库中的表名默认是 app_类名,可以通过db_table可以重写表名。
index_together
联合索引。
unique_together
联合唯一索引。
ordering
指定默认按什么字段排序。
只有设置了该属性,我们查询到的结果才可以被reverse()。
复习
一. is和==的区别
1. id() 通过id()我们可以查看到⼀一个变量量表⽰示的值在内存中的地址.
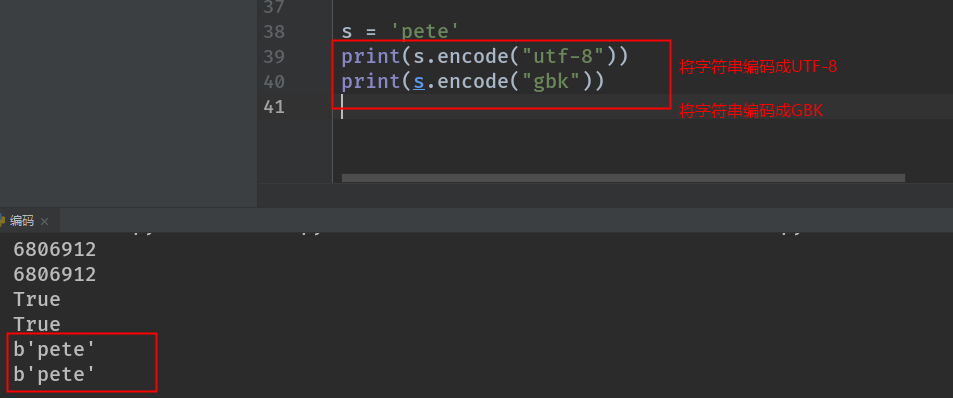
s = 'Pete'
print(id(s))
s = 'Pete'
print(id(s))
lst = [1, 2, 4]
print(id(lst))
# 以上可以发现.字符串的数据地址是一样的。而列表的数据地址是不一样的。
tup = (1,2)
tup1 = (1,2)
print(id(tup))
print(id(tup1))
print(id("a*100"))
s1 = "@1 2 "
s2 = "@1 2 "
print(id(s1))
print(id(s2))
# 结果⼀一致, 但是在终端中是不不⼀一致的. 所以在python中,命令⾏行行代码和py⽂文 件中的代码运⾏行行的效果可能是不不⼀一样的
⼩小数据池(常量量池):
把我们使⽤用过的值存储在⼩小数据池中.供其他的变量量使⽤用.
⼩小数据池给数字和字符串串使⽤用, 其他数据类型不存在.
对于数字: -5~256是会被加到⼩小数据池中的. 每次使⽤用都是同⼀一个对象.
对于字符串串:
1. 如果是纯⽂文字信息和下划线. 那么这个对象会被添加到⼩小数据池
2. 如果是带有特殊字符的. 那么不会被添加到⼩小数据池. 每次都是新的
3. 如果是单⼀一字⺟母*n的情况. 'a'*20, 在20个单位内是可以的. 超过20个单位就不会添加 到⼩小数据池中
TOP:
在py⽂文件中. 如果你只是单纯的定义⼀一个字符串串. 那么⼀一般情况下都是会 被添加到⼩小数据池中的. 我们可以这样认为: 在使⽤用字符串串的时候, python会帮我们把字符串串 进⾏行行缓存, 在下次使⽤用的时候直接指向这个字符串串即可. 可以节省很多内存.
. is比较的就是id()计算出来的结果. 由于id是帮我 们查看某数据(对象) 的内存地址. 那么is比较的就是数据(对象)的内存地址. 最终我们通过is可以查看两个变量量使⽤用的是否是同⼀一个对象
== 双等表⽰示的是判断是否相等, 注意. 这个双等比较的是具体的值.⽽而不是内存地址
s1 = "哈哈"
s2 = "哈哈"
print(s1 == s2) # True
print(s1 is s2) # True 原因是有⼩小数据池的存在 导致两个变量量指向的是同⼀一个对象
l1 = [1, 2, 3]
l2 = [1, 2, 3]
print(l1 == l2) # True, 值是⼀一样的 print(l1 is l2) # False, 值是假的
top: is 比较的是地址 == 比较的是值
编码的补充
1. python2中默认使⽤用的是ASCII码. 所以不⽀支持中⽂文. 如果需要在Python2中更更改编码. 需要在⽂文件的开始编写:
# -*- encoding:utf-8 -*
2. python3中: 内存中使⽤用的是unicode码.
2. GBK: 中⽂文国标码, ⾥里里⾯面包含了了ASCII编码和中⽂文常⽤用编码. 16个bit, 2个byte
3. UNICODE: 万国码, ⾥里里⾯面包含了了全世界所有国家⽂文字的编码. 32个bit, 4个byte, 包含了了 ASCII
4. UTF-8: 可变⻓长度的万国码. 是unicode的⼀一种实现. 最⼩小字符占8位
1.英⽂文: 8bit 1byte
2.欧洲⽂文字:16bit 2byte
3.中⽂文:24bit 3byte
综上, 除了了ASCII码以外, 其他信息不能直接转换.
在python3的内存中. 在程序运⾏行行阶段. 使⽤用的是unicode编码. 因为unicode是万国码. 什什么内 容都可以进⾏行行显⽰示. 那么在数据传输和存储的时候由于unicode比较浪费空间和资源. 需要把 unicode转存成UTF-8或者GBK进⾏行行存储. 怎么转换呢. 在python中可以把⽂文字信息进⾏行行编码. 编码之后的内容就可以进⾏行行传输了了. 编码之后的数据是bytes类型的数据.其实啊. 还是原来的 数据只是经过编码之后表现形式发⽣生了了改变⽽而已.
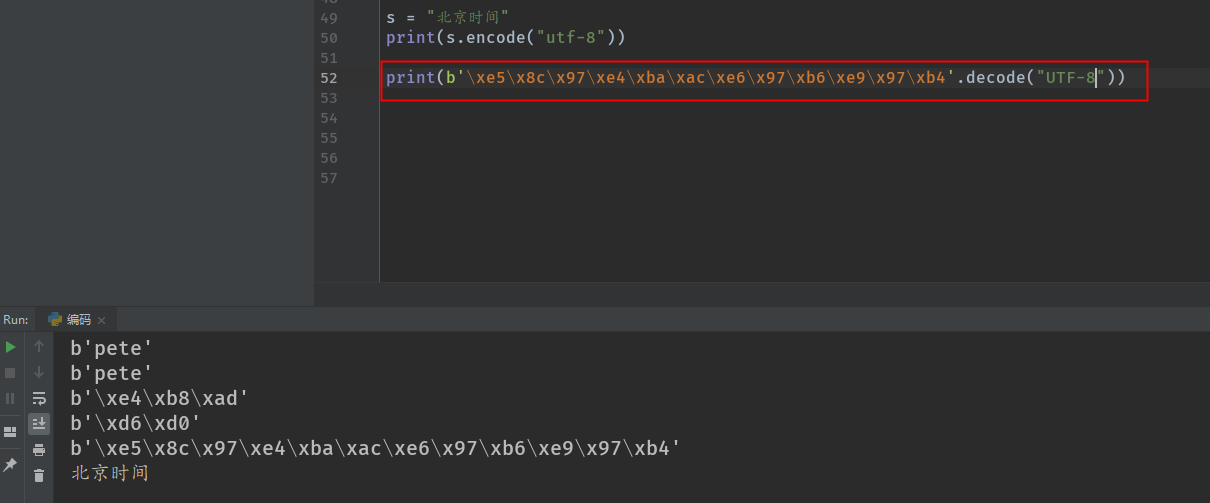
bytes的表现形式:
1. 英⽂文 b'alex' 英⽂文的表现形式和字符串串没什什么两样
2. 中⽂文 b'\xe4\xb8\xad' 这是⼀一个汉字的UTF-8的bytes表现形式
字符串串在传输时转化成bytes=> encode(字符集)来完成
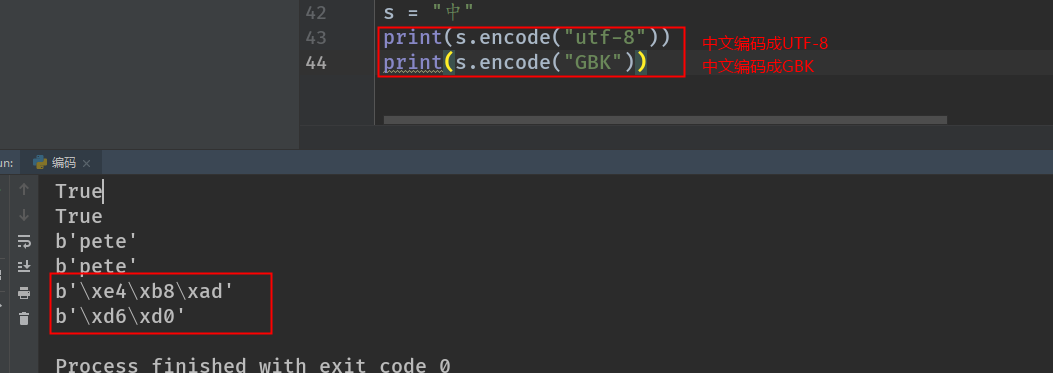
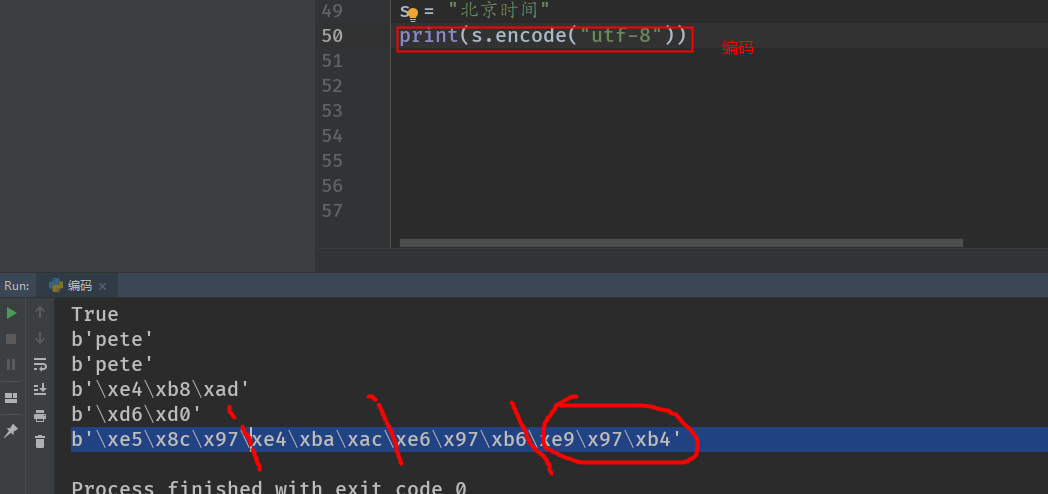
PS: ⼀一个中⽂文的UTF-8编码是3个字节. ⼀一个GBK的中⽂文编码是2个字节. 编码之后的类型就是bytes类型. 在⽹网络传输和存储的时候我们python是保存和存储的bytes类型. 那么在对⽅方接收的时候. 也是接收的bytes类型的数据. 我们可以使⽤用decode()来进⾏解 码操作
把bytes类型的数据还原能看懂的字符串
文件操作
⽤用python来读写⽂文件是非常简单的操作. 我们使⽤用open()函数来打开⼀一个⽂文件, 获取到⽂文 件句句柄. 然后通过⽂文件句句柄就可以进⾏行行各种各样的操作了了. 根据打开⽅方式的不同能够执⾏行行的操 作也会有相应的差异.
打开⽂文件的⽅方式: r, w, a, r+, w+, a+, rb, wb, ab, r+b, w+b, a+b 默认使⽤用的是r(只读)模式
#只读操作(r,rb)
file = open("a.txt",mode="r",encoding="utf-8")
content = file.read()
print(content)
file.close()
PS: 需要注意encoding表⽰示编码集. 根据⽂文件的实际保存编码进⾏行行获取数据, 对于我们⽽而⾔言. 更更 多的是utf-8.
rb. 读取出来的数据是bytes类型, 在rb模式下. 不能选择encoding字符集.
file = open("a.txt",mode="rb")
content = file.read()
print(content)
file.close()
rb的作⽤用: 在读取非⽂文本⽂文件的时候也就是说字节的时候使用
绝对路路径和相对路路径:
1. 绝对路路径:从磁盘根⽬目录开始⼀一直到⽂文件名.
2. 相对路路径:同⼀一个⽂文件夹下的⽂文件. 相对于当前这个程序所在的⽂文件夹⽽而⾔言. 如果在同 ⼀一个⽂文件夹中. 则相对路路径就是这个⽂文件名. 如果在上⼀一层⽂文件夹. 则要../
1. read() 将⽂文件中的内容全部读取出来. 弊端: 占内存. 如果⽂文件过⼤大.容易易导致内存崩溃

2.read(n) 读取n个字符. 需要注意的是. 如果再次读取. 那么会在当前位置继续去读⽽而不 是从头读, 如果使⽤用的是rb模式. 则读取出来的是n个字节

3. readline() ⼀一次读取⼀一⾏行行数据, 注意: readline()结尾, 注意每次读取出来的数据都会有⼀一 个\n 所以呢. 需要我们使⽤用strip()⽅方法来去掉\n或者空格

4. readlines()将每⼀一⾏行行形成⼀一个元素, 放到⼀一个列列表中. 将所有的内容都读取出来. 所以 也是. 容易易出现内存崩溃的问题.不推荐使⽤用
file = open("../del/a.txt",mode="r",encoding="utf-8")
lst = file.readlines()
print(lst)
for line in lst:
print(line.strip())
5. 循环读取. 这种⽅方式是组好的. 每次读取⼀一⾏行行内容.不会产⽣生内存溢出的问题.
file = open("../del/a.txt",mode="r",encoding="utf-8")
for line in file:
print(line.strip())
PS:读取完的⽂文件句句柄⼀一定要关闭 f.close()
写模式(w/wb)
写的时候注意. 如果没有⽂文件. 则会创建⽂文件, 如果⽂文件存在. 则将原件中原来的内容删除, 再 写入新内容
f = open("⼩小娃娃", mode="w", encoding="utf-8")
f.write("⾦金金⽑毛狮王")
f.flush()
f.close()
f = open("⼩小娃娃", mode="w", encoding="utf-8")
f.write("⾦金金⽑毛狮王")
f.read() # not readable 模式是w. 不不可以执⾏行行读操作
f.flush()
f.close()
wb模式下. 可以不指定打开⽂文件的编码. 但是在写⽂文件的时候必须将字符串串转化成utf-8的 bytes数据
f = open("⼩小娃娃", mode="wb")
f.write("⾦金金⽑毛狮王".encode("utf-8"))
f.flush()
f.close()
追加(a, ab)
在追加模式下. 我们写入的内容会追加在⽂文件的结尾.
f = open("⼩小娃娃", mode="a", encoding="utf-8")
f.write("麻花藤的最爱")
f.flush()
f.close()
读写模式(r+, r+b)
对于读写模式. 必须是先读. 因为默认光标是在开头的. 准备读取的. 当读完了了之后再进⾏行行 写入. 我们以后使⽤用频率最⾼高的模式就是r+
正确操作是:
f = open("⼩小娃娃", mode="r+", encoding="utf-8")
content = f.read()
f.write("麻花藤的最爱")
print(content)
f.flush()
f.close()
PS: r+模式下. 必须是先读取. 然后再写入
写读(w+, w+b)
先将所有的内容清空. 然后写入. 最后读取. 但是读取的内容是空的, 不常⽤
f = open("⼩小娃娃", mode="w+", encoding="utf-8")
f.write("哈哈")
content = f.read()
print(content)
f.flush()
f.close()
追加读(a+)
a+模式下, 不论先读还是后读. 都是读取不到数据的.
f = open("⼩小娃娃", mode="a+", encoding="utf-8")
f.write("⻢马化腾")
content = f.read()
print(content)
f.flush()
f.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号