

个人项目作业
| 这个作业属于哪个课程 | 软件工程 |
| ---- | ---- | ---- |
| 这个作业要求在哪里 | 个人项目作业 |
| 这个作业的目标| 设计论文查重算法;独立完成一次编程项目;学会使用PSP表格记录时间;学会用GitHub进行源代码管理;设计测试用例并编写单元测试对自己的项目进行测试 |
1.GitHub链接
2.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 30 |
| Estimate | 估计这个任务需要多少时间 | 60 | 50 |
| Development | 开发 | 600 | 700 |
| Analysis | 需求分析(包括学习新技术) | 150 | 240 |
| Design Spec | 生成设计文档 | 20 | 30 |
| Design Review | 设计复审 | 15 | 10 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 20 | 60 |
| Design | 具体设计 | 50 | 70 |
| Coding | 具体编码 | 180 | 240 |
| Code Review | 代码复审 | 60 | 90 |
| Test | 测试(自我测试,修改代码,提交修改 | 60 | 120 |
| Reporting | 报告 | 60 | 120 |
| Test Repor | 测试报告 | 60 | 80 |
| Size Measurement | 计算工作量 | 10 | 20 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进机计划 | 20 | 30 |
| 合计 | 1385 | 1890 |
3.计算模块接口的设计与实现过程
3.1开发环境
●编程语言: Java
●IDE:Eclipse IDE
●项目构建工具:maven
●单元测试:JUnit-4
●性能分析工具:JProfiler 9.2
3.2整体流程

3.3类
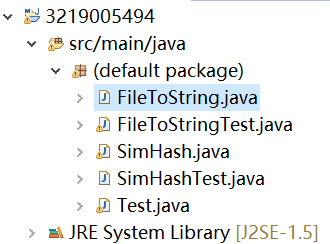
●FileToString类:实现将文件的文字内容转换成字符串
●SimHash类:算法核心所在
●FileToStringTest类和SimHash类:分别为单元测试
●Test类:性能测试
3.4算法原理
使用simhash以及海明距离判断内容相似程度
基于传统的IR方法,先将文章转换为一组加权的特征值构成的向量。
初始化一个f维的向量V,其中每一个元素初始值为0。
对于文章的特征向量集中的每一个特征,做如下计算:
利用传统的hash算法映射到一个f-bit的签名。对于这个f- bit的签名,如果签名的第i位上为1,则对向量V中第i维加上这个特征的权值,否则对向量的第i维减去该特征的权值。对整个特征向量集合迭代上述运算后,根据V中每一维向量的符号来确定生成的f-bit指纹的值,如果V的第i维为正数,则生成f-bit指纹的第i维为1,否则为0。
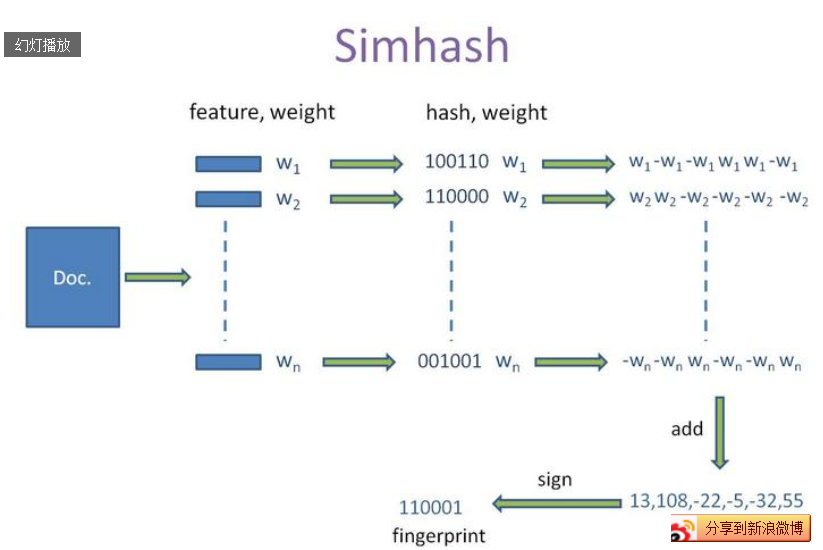
3.4.1 Simhash算法
simhash算法的输入是一个向量,输出是一个 f 位的签名值。为了陈述方便,假设输入的是一个文档的特征集合,每个特征有一定的权重。比如特征可以是文档中的词,其权重可以是这个词出现的次数。
simhash 算法如下:
(1)将一个 f 维的向量 V 初始化为 0 ; f 位的二进制数 S 初始化为 0 ;
(2)对每一个特征:用传统的 hash 算法对该特征产生一个 f 位的签名 b 。
对 i=1 到 f :
如果b 的第 i 位为 1 ,则 V 的第 i 个元素加上该特征的权重;
否则,V 的第 i 个元素减去该特征的权重;
(3)如果 V 的第 i 个元素大于 0 ,则 S 的第 i 位为 1 ,否则为 0 ;
(4)输出 S 作为签名。
3.4.2 比较相似度
●海明距离: 两个码字的对应比特取值不同的比特数称为这两个码字的海明距离。一个有效编码集中, 任意两个码字的海明距离的最小值称为该编码集的海明距离。举例如下: 10101 和 00110 从第一位开始依次有第一位、第四、第五位不同,则海明距离为 3。
●异或: 只有在两个比较的位不同时其结果是1 ,否则结果为 0 。
对每篇文档根据SimHash 算出签名后,再计算两个签名的海明距离(两个二进制异或后 1 的个数)即可。根据经验值,对 64 位的 SimHash ,海明距离在 3 以内的可以认为相似度比较高。
假设对64 位的 SimHash ,我们要找海明距离在 3 以内的所有签名。我们可以把 64 位的二进制签名均分成 4 块,每块 16 位。根据鸽巢原理(也成抽屉原理,见组合数学),如果两个签名的海明距离在 3 以内,它们必有一块完全相同。
我们把上面分成的4 块中的每一个块分别作为前 16 位来进行查找。 建立倒排索引
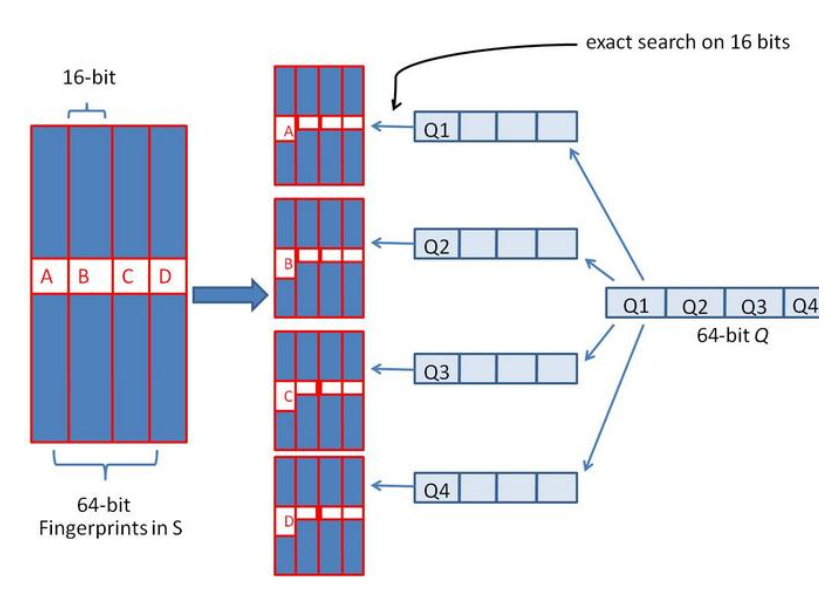
如果库中有2^34 个(大概 10 亿)签名,那么匹配上每个块的结果最多有 2^(34-16)=262144 个候选结果 (假设数据是均匀分布, 16 位的数据,产生的像限为 2^16 个,则平均每个像限分布的文档数则 234/216 = 2^(34-16)) ,四个块返回的总结果数为 4* 262144 (大概 100 万)。原本需要比较 10 亿次,经过索引,大概就只需要处理 100 万次了。由此可见,确实大大减少了计算量。
资料来源
使用simhash以及海明距离判断内容相似程度
simHash 简介以及java实现
3.5 运行结果

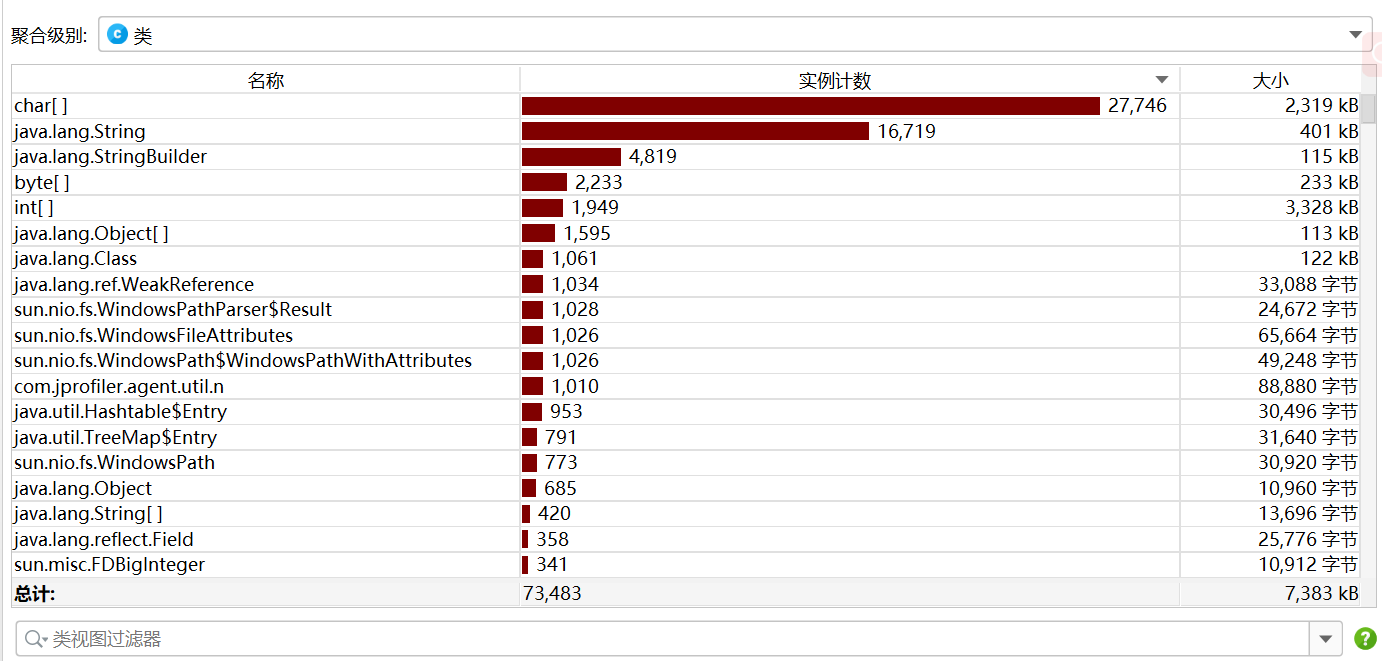
4.计算模块接口部分的性能改进
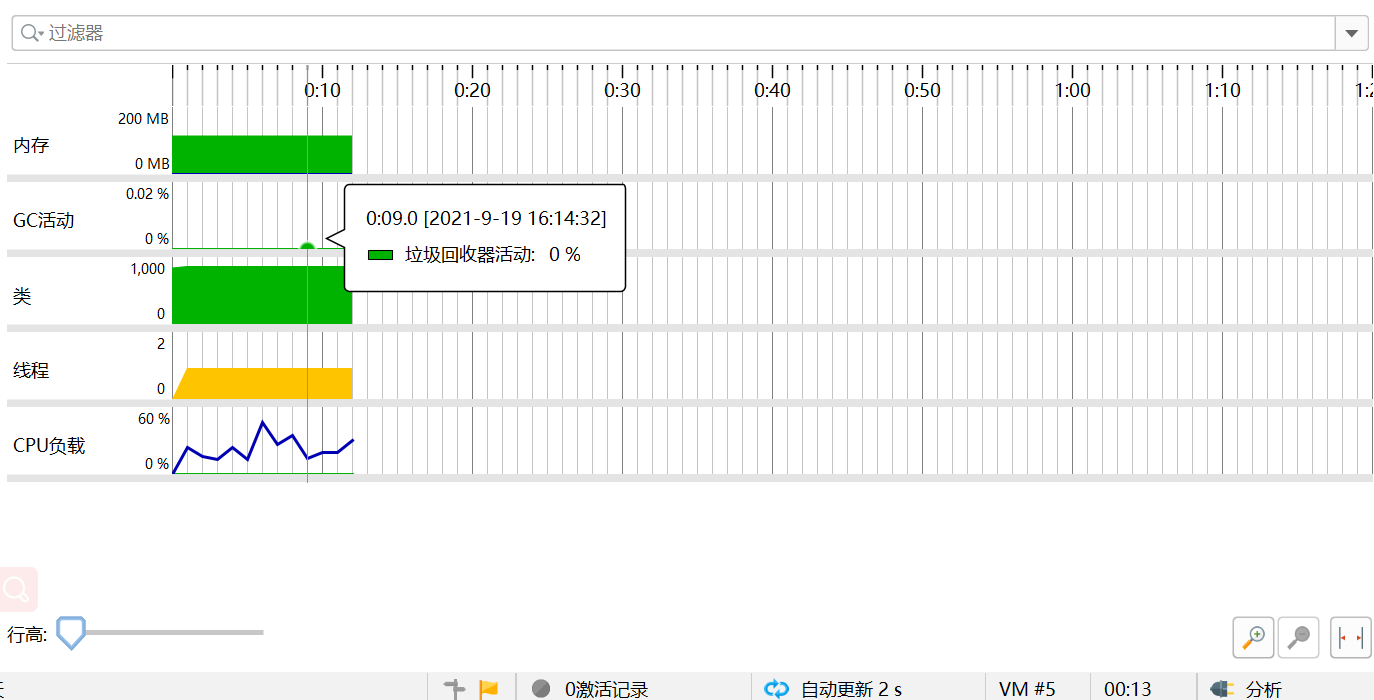
5.计算模块部分单元测试展示
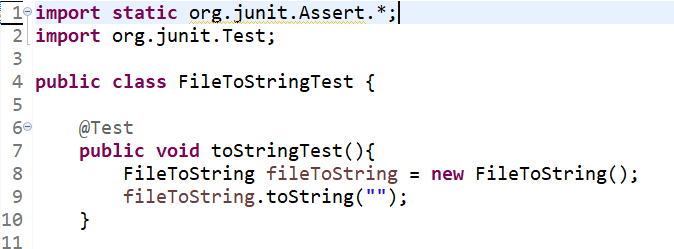
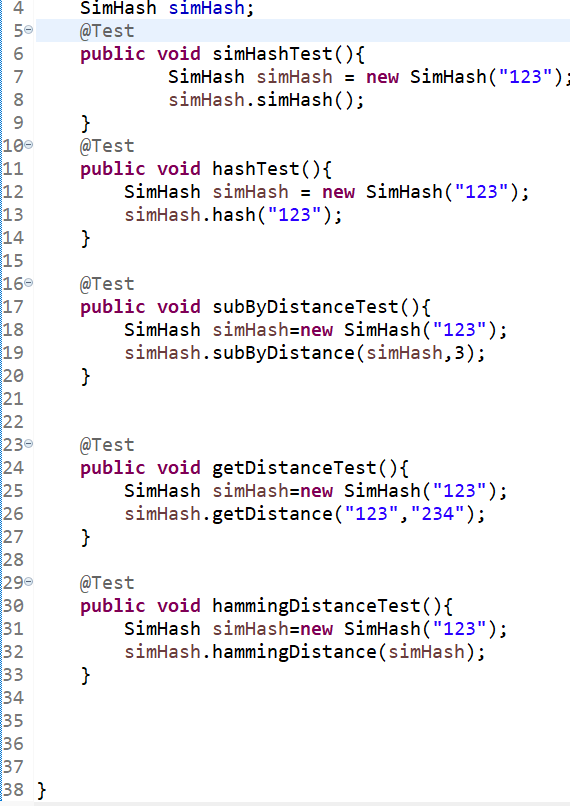
5.1 测试部分代码
—————————————————————————————————————————————————————————————————————————————————————————————
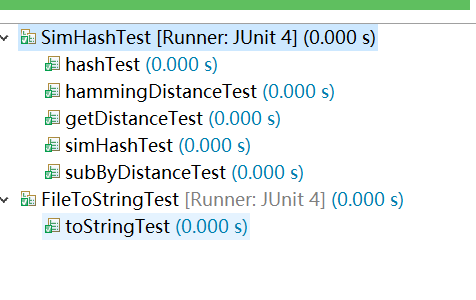
5.2 单元测试截图
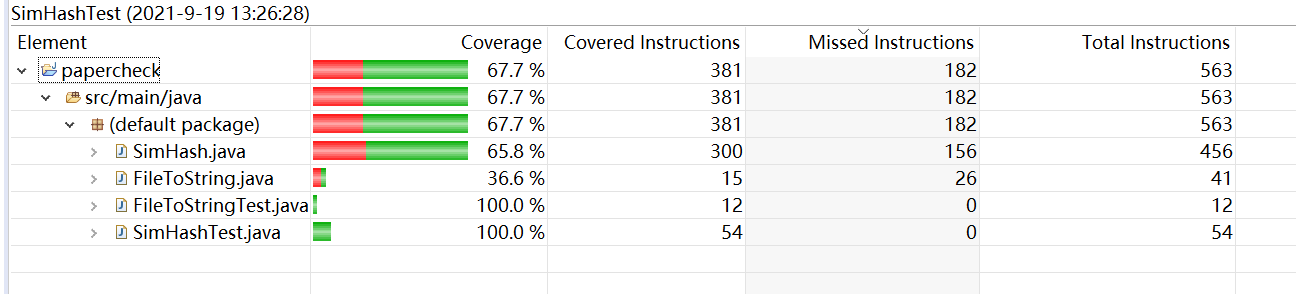
5.3 单元覆盖率截图
6.计算模块部分异常处理说明
文件路径输错会报错,要管理好文件所在路径。
7.个人总结
本次作业过程中,个人学到了很多东西,对java的学习又多了一点。对比于自己以前的编程写码能力感觉有了挺大的一个提升,本次大部分的时间主要是花费在学习新技术(各类查重算法的学习以及比较)上,还有就是对本次程序的算法设计上,以及编码的过程中。在实现的过程中,遇到很多困难,如一开始建立的java项目,而不是maven,浪费了很多时间,当然比较搞心态的无非是由于网络不稳定所引起的GitHub的网页无法打开。总的来说,还是要多实践,多动手,同时理论知识也要抓紧学。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号